助听系统、系统信号处理单元及用于产生增强的电音频信号的方法与流程
本发明涉及包括至少两个双耳听力系统的助听系统,每一双耳听力系统包括两个听力装置如助听器。本发明还涉及用于前述助听系统的系统信号处理单元和用于产生增强的电音频信号的方法。
背景技术:
听力是沟通的决定性的方面。发展有意义的关系和完全享乐的生活十分重要。更好的听力使人们能与其周围的人联系并参与任何情形下的社区生活。双耳听力装置可帮助用户感知和理解声学消息。双耳听力系统通常包括两个听力装置,用户的每只耳朵各一个听力装置。因而,双耳听力系统能够将空间信息传给助听器用户,尤其是关于声音相对于双耳听力系统的入射角的信息。双耳听力系统帮助恢复双耳听力特性以使用户受益于感知的空间信息。
形成双耳听力系统的两个听力装置通常设置在用户耳朵处或者靠近用户耳朵进行设置。因而,双耳听力系统的两个听力装置沿一轴彼此间隔开,所述轴垂直于用户两眼向前平视时的视线定向。
传入声音的入射角有助于使来自不同声源的声学消息彼此区分开。
众所周知,听力装置如助听器包括或者连接到用于捕获声音并提供电输入声音信号的传声器。电输入声音信号馈给处理单元例如处理电输入声音信号的数字信号处理器以产生电输出声音信号。之后,电输出声音信号可馈给变换器及将电输出声音信号转换为用户感知的输出信号的其它装置。输出变换器例如可以是扬声器或接收器,其将电输出声音信号转换为可被用户感知的声音。作为备选,电输出声音信号可被转换为电刺激,其可被馈给电极阵列以用于刺激例如耳蜗。
处于作为观众/听众的情形(电影院、会议、音乐会、培训、教育、教堂中的语音……)对于许多助听器用户来说是一个主要问题,即使具有先进的信号处理算法也是如此。因而,存在双耳听力系统的用户仍可能在理解声学消息方面有困难的情形。例如,如果用户坐在教室中的靠背凳子上,该用户在听和/或理解老师或教授讲话时仍可能存在困难。
对于这样的情形,可能向教授或老师提供一个远程传声器装置,其可拾取讲话者的话音并将表示讲话者的话音的电信号无线传给用户的双耳听力系统。然而,这需要讲话者配备有前述远程传声器系统且远程传声器系统与用户的听力系统兼容。远程传声器系统与单耳或双耳听力系统没有相依性。
总的来说,助听设备(ald)如远程传声器、感应线圈或fm系统被设计成增强有用信号与有害(噪声和混响)信号之间的比。这些设备需要额外的装备及特定安装:
-每一讲话者具有传声器;
-房间装备有可用的感应线圈或fm系统;
-助听器用户知道怎样及何时受益于前述安装。
所有这些要求戏剧性地限制了助听器用户可使用可用技术改善其听音体验的情形。
技术实现要素:
本发明的目标在于提供一种备选助听系统,其可帮助作为助听系统的一部分的各个双耳听力系统。
为实现该目标,提供用于包括至少两个双耳听力系统的助听系统的系统信号处理单元,其中至少两个双耳听力系统包括第一双耳听力系统和第二双耳听力系统。
每一双耳听力系统包括两个间隔开的听力装置。每一听力装置包括至少一用于捕获传入声音的输入变换器,两个间隔开的听力装置的输入变换器确定参考轴。每一双耳听力系统配置成确定传入声音相对于所述参考轴的系统入射角和/或相应双耳听力系统的两个听力装置的两个输入变换器的声音捕获之间的系统时间延迟。
传入声音的系统入射角用作到不是所述系统的一部分的声源的方向的度量,例如所述系统可由两人安装或佩戴的两套双耳助听器组成,两个双耳助听器系统协作以确定到远处声源如正讲话的第三人的方向和/或距离。可以预见,这使由至少两个个人佩戴的至少两个助听器系统能协作以使用助听器系统之一向两个个人中的至少一个提供增强的音频。此外,当两个前述助听器系统通信时,两个助听器系统在针对两个个人建立增强的音频时均可受益于组合的系统。更进一步地,两个以上助听器系统可通信以建立增强的音频。并非组合系统中的所有助听器系统均需要具有一样的规格,例如一个用户可使用双耳助听器,而另一用户可具有不同的配置。同样,各个助听器系统的助听器类型可以不同,例如一个用户可在一只耳朵处具有耳后式助听器及在对侧耳朵处具有另一类型的助听器。
系统信号处理单元包括或者在工作时连接到无线数据通信接口,用于与至少两个双耳听力系统中的至少一个无线通信。该系统信号处理单元配置成接收:
-第一系统电音频信号及与源自第一双耳听力系统的第一系统电音频信号有关的第一系统空间信息,所述第一系统空间信息包括传入声音的至少一第一系统入射角和第一助听器系统的两个间隔开的听力装置的声音捕获之间的第一系统时间延迟;及
-第二系统电音频信号及与源自第二双耳听力系统的第二系统电音频信号有关的第二系统空间信息,所述第二系统空间信息包括传入声音的至少一第二系统入射角和第二助听器系统的两个间隔开的听力装置的声音捕获之间的第二系统时间延迟。
也可能具有涉及两个以上系统电音频信号的系统信号处理。
该系统信号处理单元进一步配置成基于第一和第二系统空间信息处理第一和第二系统电音频信号及产生增强的电音频信号。
这样的系统处理单元可利用由任何双耳听力系统的任何输入变换器提供的任何输入信号用于提供增强的电音频信号。在某种程度上,任何输入变换器可用作用于助听系统的双耳听力系统的远程传声器,同时,另外能够考虑各个入射角。
系统信号处理单元可实施在智能助听器或智能电话或提供足够处理能力的任何其它便携甚或不动的设备中。
本发明包括具有更高处理能力和通信可能性的技术如智能电话变得更普及的认识。
优选地,第一和第二助听器系统均配置成,通过基于声音捕获之间的系统时间延迟和/或传入声音的系统入射角将传入声音归属于至少包括第一音频源和第二音频源的一组声源中的一个音频源而区分至少两个音频源。
系统信号处理单元可进一步配置成,通过基于第一和第二系统空间信息及第一和第二系统时间延迟数据使用三角法而针对第一双耳听力系统确定第一音频源与第一双耳听力系统之间的第一系统第一源距离,及通过基于第一和第二系统空间信息及第一和第二系统时间延迟数据使用三角法而针对第二双耳听力系统确定第一音频源与第二双耳听力系统之间的第二系统第一源距离。
在优选实施例中,系统信号处理单元进一步配置成确定至少两个音频源之中的目标音频源。这可通过将目标音频源确定为被分配给随时间一贯最强的系统电音频信号的音频源而实现。另外或者作为备选,目标声源可被确定为被分配给在与双耳听力系统的角度(即第一和第二角度)方面提供最小均方差(minimummeansquareerror,mmse)的系统电音频信号的音频源。
优选实施例因而使能自动确定目标声源。
在优选变型中,系统信号处理单元配置成通过计算argmax(sum{对于每一s(k)}sum{对于每一所接收的音频信号r(i)})而确定随时间一贯最强的系统电音频信号,其中sk为音频源。
作为备选或者另外,系统信号处理单元可配置成通过计算argmaxsum(angle(i)^2)
而确定跨从双耳听力系统接收的入射角提供最小均方差(mmse)的系统电音频信号。
优选地,系统信号处理单元配置成基于对应于和/或源自所确定的目标音频源的系统电音频信号产生增强的电音频信号。
本发明的目标还由助听系统实现,其包括上面提出的信号处理单元及包括至少两个双耳听力系统,其中每一双耳听力系统包括第一和第二听力装置。每一听力装置包括配置成接收声学声音信号并将所述声学声音信号转换为装置电输入音频信号的输入变换器,及配置成将听力装置电音频输出信号转换为用户可感知为声音的音频输出信号的输出变换器。相应双耳助听器系统的两个听力装置的输入变换器确定参考轴,其通常垂直于用户头部的矢面进行定向。
优选地,每一双耳听力系统包括:
-至少一无线接口单元,配置成与系统信号处理单元通信及从系统信号处理单元接收增强的电音频信号;及
-至少一助听器信号处理单元,其在工作时连接到所述输入变换器、所述输出变换器和所述无线接口,并配置成处理所述装置电输入音频信号和所述增强的电音频信号(从系统信号处理单元接收)以产生用于每一输出变换器的听力装置电输出音频信号。
助听器信号处理单元可配置成处理来自第一和第二听力装置的装置电输入音频信号,及确定音频源与相应双耳听力系统确定的参考值之间的第一入射角,其中所述入射角基于双耳听力系统的第一和第二听力装置处的两个装置电输入音频信号之间的时间延迟确定,因而产生所述空间信息。
系统信号处理单元可实施在服务器中或者单独的便携设备中,尤其是个人多用途便携设备如智能电话中。
根据本发明的另一方面,提供用于产生增强的电音频信号的方法。该方法包括步骤:
-接收第一系统电音频信号及与源自第一双耳听力系统的第一系统电音频信号有关的第一系统空间信息,所述第一系统空间信息包括传入声音的至少一第一系统入射角和第一助听器系统的两个间隔开的听力装置的声音捕获之间的第一系统时间延迟;及
-接收第二系统电音频信号及与源自第二双耳听力系统的第二系统电音频信号有关的第二系统空间信息,所述第二系统空间信息包括传入声音的至少一第二系统入射角和第二助听器系统的两个间隔开的听力装置的声音捕获之间的第二系统时间延迟;
-基于第一和第二系统空间信息处理第一和第二系统电音频信号;及
-从第一和第二系统电音频信号产生增强的电音频信号。
接收第一和第二系统电音频信号及第一和第二系统空间信息应同时或几乎同时发生,以保持信号和信息的时间相干性。
本发明方法还包括,通过基于声音捕获之间的时间延迟和/或传入声音的入射角将传入声音归属于至少包括第一音频源和第二音频源的一组声源中的一个音频源而区分至少两个音频源。
本发明还涉及助听器的运行方法和/或双耳助听器系统的运行方法和/或包括两个助听器系统的系统的运行方法和/或包括两个助听器系统及外部装置的系统的运行方法。这些方法中的每一个包括在此提及的其它方法的步骤,例如用于产生增强的电音频信号的步骤包括用于操作助听器或双耳助听器系统以获得前述增强的电音频信号所需的任何步骤。
在优选实施例中,本发明方法还包括:
-通过基于第一和第二系统空间信息及第一和第二系统时间延迟数据使用三角法而针对第一双耳听力系统确定第一音频源与第一双耳听力系统之间的第一系统第一源距离;及
-通过基于第一和第二系统空间信息及第一和第二系统时间延迟数据使用三角法而针对第二双耳听力系统确定第一音频源与第二双耳听力系统之间的第二系统第一源距离。
根据又一方面,数据存储设备包含表示软件代码的数据,所述软件代码当在个人移动设备上运行时执行上面提出的方法。
附图说明
本发明的各个方面将从下面结合附图进行的详细描述得以最佳地理解。为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在整个说明书中,同样的附图标记用于同样或对应的部分。每一方面的各个特征可与其他方面的任何或所有特征组合。这些及其他方面、特征和/或技术效果将从下面的图示明显看出并结合其阐明,其中:
图1为听力装置的示意性表示。
图2为说明形成双耳听力系统的两个听力装置的几何关系的示意图。
图3示出了包括多个听力装置的助听系统。
图4示出了声音改善计算可被分布。
图5示出了各个听力装置可接收不同于助听系统的另一听力装置的信号。
图6示出了一个听力装置可例如仅包括传声器和处理。
图7示出了为产生增强的电音频信号,多个系统电音频信号和系统空间信息的处理。
图8示出了每一个别听力装置的位置检测。
图9a-9c示出了影响听力装置相对于声源的相对位置的明确确定的某些配置。
图10示出了在具有多个声源的场景中,多个系统电音频信号和系统空间信息的处理。
具体实施方式
下面结合附图提出的具体描述用作多种不同配置的描述。具体描述包括用于提供多个不同概念的彻底理解的具体细节。然而,对本领域技术人员显而易见的是,这些概念可在没有这些具体细节的情形下实施。装置和方法的几个方面通过多个不同的块、功能单元、模块、元件、电路、步骤、处理、算法等(统称为“元素”)进行描述。根据特定应用、设计限制或其他原因,这些元素可使用电子硬件、计算机程序或其任何组合实施。
听力装置可包括适于通过接收来自用户周围的声学信号、生成对应的音频信号、可能对音频信号进行修正、并且将可能修正后的音频信号作为可听信号提供给用户耳朵中的至少一个来改善或加强用户的听力能力的助听器。“听力装置”还可指适于以电子方式接收音频信号、可能修改该音频信号、及将可能已修改的音频信号作为可听信号提供给用户的至少一只耳朵的头戴式耳机或耳麦。这些可听信号可以以向用户的外耳中辐射的声学信号、或者作为机械振动通过用户头部的骨结构和/或通过用户的中耳部分向用户的内耳传递的声学信号、或者直接或间接地向用户的耳蜗神经和/或听觉皮层传递的电信号的形式提供。
听力装置适于以任意已知的方式佩戴。这可以包括i)将听力装置的、具有引导空传声学信号的管和/或设置成靠近耳道或位于耳道中的接收器/扬声器的单元布置在耳后,例如在耳后型助听器或者耳内接收器式助听器中;和/或ii)将听力装置整个或部分布置在用户耳廓中和/或耳道中,例如在耳内式助听器或者耳道式/深耳道式助听器中;或者iii)将听力装置的单元布置成附着到植入颅骨中的固定装置,例如在骨锚式助听器或耳蜗植入件中;或者iv)将听力装置的单元布置为完全或部分植入的单元,例如在骨锚式助听器或耳蜗植入件中。
听力装置可以是“听力系统”的一部分,其指包括一个或两个本说明书中公开的听力装置的系统,及“双耳听力系统”是指包括两个听力装置的系统,其中,这些装置适于以协作的方式向用户的两个耳朵提供音频信号。听力系统或双耳听力系统还可以包括与至少一个听力装置进行通信的辅助设备,辅助设备影响听力装置的操作和/或从听力装置的工作中受益。在至少一个听力装置和辅助设备之间建立有线或无线通信链路,使得能够在至少一个听力装置和辅助设备之间交换信息(例如控制和状态信号、可能有音频信号)。辅助设备可以包括遥控器、遥控麦克风、音频网关设备、移动电话、公共广播系统、汽车音频系统或音乐播放器中的至少一个或其组合。音频网关适于诸如从像电视或音乐播放器的娱乐设备、像移动电话的电话装置或者计算机、pc接收大量音频信号。音频网关还适于选择和/或组合接收到的音频信号中的合适的一个(或信号的组合),用于传输到至少一个听力装置。遥控器可适于对至少一个听力装置的功能和操作进行控制。遥控器的功能可以在智能电话或其它电子设备中实现,智能电话/电子设备可能运行对至少一个听力装置的功能进行控制的应用。
总的来说,听力装置包括i)诸如麦克风的输入单元,用于接收来自用户周围的声学信号,并且提供对应的输入音频信号,和/或ii)接收单元,用于电子地接收输入音频信号。听力装置还包括用于对输入音频信号进行处理的信号处理单元和用于依据处理后的音频信号向用户提供可听信号的输出单元。
输入单元可以包括多个输入麦克风,例如用于提供依赖于方向的音频信号处理。这种定向麦克风系统适于增强用户环境中的大量声学源中的目标声学源。在一个方面,定向系统适于检测(例如自适应地检测)麦克风信号的特定部分源自哪个方向。这可以通过使用传统上已知的方法来实现。信号处理单元可以包括放大器,放大器适于对输入音频信号施加依赖于频率的增益。信号处理单元还可以适于提供诸如压缩、噪声降低等其它相关功能。输出单元可包括用于透皮或经皮向颅骨提供空气传播声学信号的诸如扬声器/接收器的输出转换器,或者用于提供结构传播或液体传播的声学信号的振动器。在一些听力装置中,输出单元可包括诸如人工耳蜗中的用于提供电信号的一个或多个输出电极。
应当理解,在本说明书全文中对“一个实施例”或者“实施例”或者“一方面”或者作为“可以”包括的特征的称谓,意为结合该实施例描述的特定特征、结构或特性包含在本发明的至少一个实施例中。此外,特定特征、结构或特性在本发明的一个或更多个实施例中可以适当地组合。提供了前面的描述,以使得任意本领域技术人员能够实施这里描述的各个方面。对这些方面的各种变形对于本领域技术人员是显而易见的,并且这里定义的通用原理可以应用于其它方面。
权利要求不旨在局限于这里示出的各方面,而应当符合与权利要求的语言一致的完整范围,其中,除非如此具体指出,否则对元素的单数称谓不旨在意为“一个并且仅为一个”,而是意为“一个或更多个”。除非另外具体指出,否则术语“一些”是指一个或更多个。
相应地,本发明的范围应当按照所附的权利要求来判断。
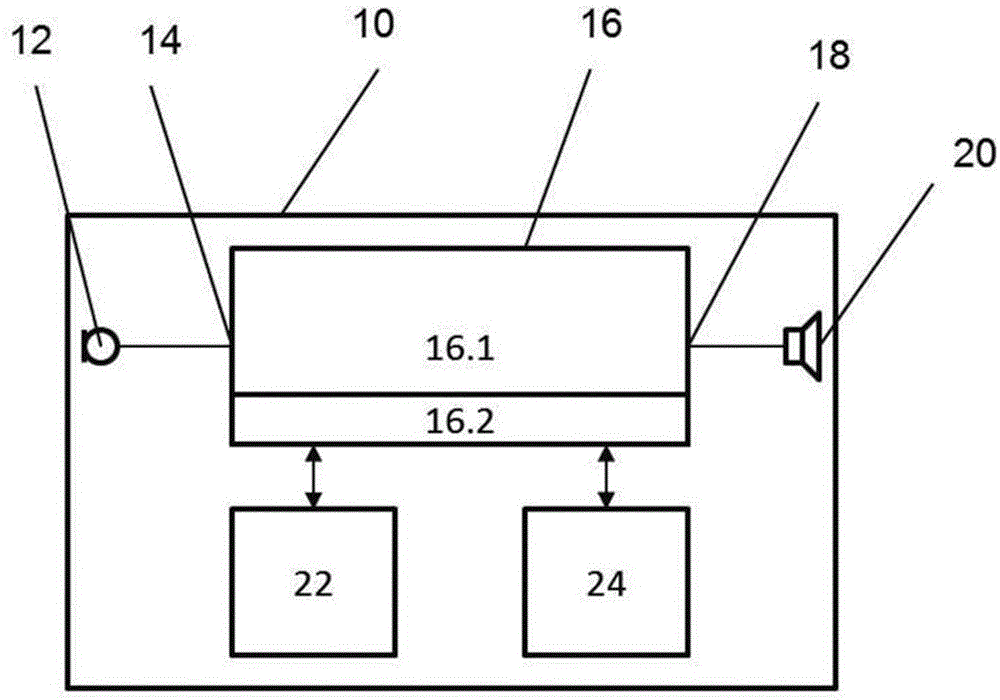
如图1中所示,听力装置10包括电连接到处理单元16的信号输入14的传声器12。传声器12向处理单元16提供电输入声音信号。电输入声音信号表示传声器12捕获或拾取的声音。
处理单元16配置成处理电输入声音信号以产生电输出声音信号,其被提供在处理单元16的信号输出18处。信号输出18在工作时连接到输出变换器20。输出变换器可以是扬声器或接收器,其将电输出声音信号转换为可由用户感知的声学声音,或者用于骨锚式或中耳植入件的悬浮块。
作为备选,输出变换器可以是耳蜗植入件的电极阵列,用于将刺激脉冲递送到耳蜗。
类似地,处理单元16的信号输入14可在工作时连接到其它电输入声音信号源如拾音线圈、蓝牙接收器、wi-fi接收器等。
助听器10还包括用于从另一助听器例如双耳听力系统的另一助听器接收数据和电声音信号的数据接口24。数据接口24可以是与外部发射器或收发器进行无线数据通信的无线收发器或接收器。
处理单元16配置成根据运行程序代码和/或存储器单元22中存储的运行参数值处理电输入声音信号。
具体地,处理单元16配置成从所述电输入声音信号及来自某个双耳听力系统的另一助听器的电声音信号产生第一系统电音频信号和第一系统空间信息。
图2示出了双耳听力系统30包括两个助听器10,每一助听器10分别设置在用户的右和左耳处或者靠近其设置。双耳助听器系统30的两个听力装置10确定参考轴32,其通常定向成垂直于用户头部36的矢面34。
图3示出了由多个听力装置42组成的助听系统40,每一听力装置包括听力装置10或者双耳听力系统30,可能及处理单元44。听力装置42的处理单元44可以是单独的设备如智能电话或者可集成在听力装置10中。
图3的助听系统40的目的在于对于助听系统40的所有听力装置42提供来自声源46的声音的增强呈现。
每一听力装置42包括用于至少确定该听力装置相对于助听系统40的其它听力装置的相对位置的装置。相对位置可基于gps、wifi、无线信号例如wlan或另一无线协议、蓝牙、声音-散列、附近检测到的设备等进行确定。
如上面指出的,听力装置42的处理单元可借助于听力装置或双耳听力系统的用户的智能电话或者类似移动设备44进行实施,其中用户的移动设备(例如智能电话)运行专门的应用软件,在下面称为“app”。app配置成使得助听系统40的相应移动设备44自动建立对等无线网络以在助听系统40的听力装置42之间进行低等待时间交互和传输。
app配置成使得助听系统40的相应移动设备44基于系统空间信息对处理系统电音频信号和产生增强的电音频信号起作用。
为此,助听系统40的听力装置42形成传声器阵列,其包括相应听力装置42中的听力装置10的传声器。因而所捕获的电声音信号在听力装置42之间共享。
图4示出了用于产生增强的电音频信号的声音改善计算可跨助听系统的处理单元分布。处理可基于任务(如波束形成、混响抑制、降噪、具有itd&ild的声源聚焦……)和/或基于频率划分动态拆分;但由于等待时间要求,可能不基于时间帧。分布处理在各个处理单元处较低能耗情形下提高了总计算能力。对于这些实时计算,低等待时间很重要,因为,例如晚于20ms的反射可导致音色着色。
在该例子中,助听系统40的听力装置42对聚焦于感兴趣的同一声源46有兴趣。所有听力装置42对表示增强的声学消息的、同一所得改善的输出声音信号有兴趣。然而,如图5中所示,专门的听力装置42’可能聚焦于另一声源48。
应注意,助听系统40根本不依赖于本地可用基础设施(ald,网络)。
另外还应注意,一些时间不重要的管理和数据分析可在受保护的云解决方案中进行。如果网络等待时间在接下来的一些年中将降低,处理单元44也可被扩展到云。因而,其也可使用精心设计的机器学习方法(例如,就像“深度学习机器”解决“鸡尾酒会问题”)进行增强。
在如图6中所示的另一变型中,听力装置42”可由处理单元44和音频输入源例如传声器或者视听设备的发射器组成。图6中的系统在一些方面类似于助听装置,但其对每一听力装置42提供更加增强的输出声音信号,因为从增强的电音频信号计算用于每一听力装置10的个别增强电输出声音信号考虑该个别听力装置42的相对空间位置和定向。
图7示出了为了产生增强的电音频信号,由各个听力装置42提供的多个系统电音频信号和系统空间信息的处理。在图7中,系统电音频信号和系统空间信息用r标记(rr:右耳听力装置;rl:左耳听力装置)并在下面称为“所接收的信号”。
所有所接收的信号在由助听系统40的听力装置42形成的网络上共享。
借助于分布式计算,确定有用的目标信号t~1,t=1。这涉及位置检测和信噪比优化。目标信号被再分布到听力装置42。
每一个体听力装置42执行个体立体声预处理,及在接收到再分布的目标信号之后,执行考虑该个体听力装置42相对于目标声源46的位置和定向的立体声再现。
图8示出了针对每一个体听力装置42的位置检测,其是检测距目标声源46的距离及相对于目标声源46的定向以实现上面指出的感知正确的再现。
位置检测包括找到所接收的信号r之间的相关信号并基于各个耳间时间差δt个别地估计方向角α:
其中τ为用户耳朵之间的距离并被估计为21cm。cs为声速,例如343m/s。
此外,距离d例如使用三角法进行计算。如果所有角度α和所有耳间时间差δt均被确定,可计算这些距离。具有所有αi_k和δti_k,可使用三角法得到缺失距离。具有r1,r2,t1,n1的样本四边形:{给定:α,β,γ,δ,a′,b′},用
位置检测的结果由个体听力装置42得出,因为具有数组(距离d和角度α)的向量空间提供相对于目标声源t1和噪声声源n1-ni的距离和角度。作为备选或者另外,该输出可包括每一个体听力装置相对于目标声源t1和噪声声源n1-ni的幅值衰减和时间延迟的估计。可被计算的噪声源的数量受助听系统40中的听力装置42的数量限制。弱噪声源可被处理为随机噪声。
从该信息可产生增强的电音频信号。这可通过系统信号处理单元进行,其被配置成基于对应于所确定的目标音频源的系统电音频信号产生增强的电音频信号。
在具有一个目标声源t1和一个噪声声源n1及其传声器提供电音频信号r1和r2的两个听力装置42的情形下,可应用下面的计算:
r1=(ar1,t1)t1+(ar1,t1)n1+随机噪声(r1)
r2=(ar2,t1)t1+(ar2,t1)n1+随机噪声(r2)
ar1,n1((ar2,t1)t1+随机噪声(r2)-r2)
=ar2,n1((ar1,t1)t1+随机噪声(r1)-r1)
ar1,n1((ar2,t1)t1-ar2,n1((ar1,t1)t1=ar2,n1(随机噪声(r1)-r1))+ar1,n1(随机噪声(r2)-r2))
假定
知道
具有两个听力装置的例子可用更多r和n扩展。应意识到,由于数学限制,最多(n-1)n可被淘汰,具有nr。
为应用上面的样本公式,假定电音频信号在时间方面同步以简化例示公式。
如果听力装置42与目标源46之间的距离太大,则由听力装置42提供的电音频信号ri将由于等待时间而不被考虑用于计算目标电音频信号t1,但是可用于有害噪声分类。
因而,相较于听力装置的电音频信号r,可计算限局性有害噪声已消除及平均随机噪声已减少的目标电音频信号
因而计算的目标电音频信号
延迟可计算如下:
电平(幅值衰减)计算如下:
如果到发出目标音频信号t1的目标声源46具有距离distancenear的最近的人(听力装置42)处的电平为lnear,则另一人(听力装置42)处的电平
在两只耳朵处:
图9a、9b和9c示出了影响听力装置相对于目标声源t或噪声声源n的相对位置的明确确定的某些配置。
如图9a中所示,仅具有两个听力装置,当处理所接收的信号r1和r2时,产生“假”声源定位。
对于具有至少三个听力装置且每一听力装置具有一个传声器的情形,当使用基本三角法时,通常可能明确确定声源位置,参见图9b。在自由场中的完美对称性下,如图9c中示意性所示,确定声音是来自前面还是后面将需要更多信息。
图10示出了在具有多个声源如多个讲话者的场景中,由各个听力装置42提供的多个系统电音频信号和系统空间信息的处理。
结合图7和8公开的解决方案专用于具有单一声源的情形,例如在教室、小会议室等中。
在其它情形下,感兴趣的信号(目标信号)t由多个扬声器设置再现,例如在教堂、电影院、大会议室等中,参见图10。
图10中所示的解决方案使用与上面所采用一样的基础设施(点对点对等无线信号网络)并被称为多讲话者辅助技术(multi-speakersassistivetechnology,msat)。该无线信号网络可基于wlan或者另一无线协议。
基本想法是通过自相关算法跨所有个体信号(对于每一听力装置)找到共同特征,以针对每一助听器分配衰减权重和时延并使用感应线圈再分布纯净信号。
在此描述的处理单元、方法和系统可帮助处于人群中并想要通过即使在拾音线圈不可用时也增大snr而提高听音质量的人。
如果两个以上听力装置用户被连接到所描述的助听系统并注意同一事件,则一用户可使用来自另一用户的信号增大有用和有害(噪声和混响)信号之间的对比。当更多用户接入助听系统时,对声音质量的好处增加。听力装置的所有传声器形成一个单一传声器阵列。
例如,用户可佩戴助听系统兼容的使用特定app的助听器并加入会议。该app将搜索注意该事件的所有app用户,他们将建立对等连接。如果用户迟到并坐在远离舞台的地方,则他或她可通过使用来自坐在前面的人的信号而增大信噪比。所有事情均自动进行,不需要改变程序或者检查感应线圈。
- 还没有人留言评论。精彩留言会获得点赞!