一种设备智能提醒方法与流程
本发明涉及人机交互领域,具体涉及一种设备智能提醒方法。
背景技术:
日常生活中,由于环境的嘈杂,手机不能根据环境自动设置铃音大小,我们很多时候会漏接电话,听不到备忘提示闹钟等重要信息提示。在一些特殊的场合如会议等,手机不能智能识别场景,若设置成静音后,会议结束忘记关闭静音如果有来对会漏接电话,若设置成响铃当会议过程中遇到来电,会违反会场礼仪,造成参会人员反感。
现有技术不能依据环境中的噪音和语音声音信息来判断用户所处的场景,自动设置手机的场景模式,对用户造成了诸多不便。
技术实现要素:
为了解决上述问题,本发明提供一种可以根据环境噪音和环境语音自动对响铃和震动进行设置的设备智能提醒方法,包括以下步骤:
s1获取环境声音信号;
s2对环境声音信号进行分析获取语音级别信息和噪音级别信息;
s3依据所述噪音级别信息和语音级别信息生成设备铃声大小信息和震动强度信息。
进一步的,
对环境声音信号进行分析包括,
对环境声音信号中的语音信号进行提取;
获取语音信号的梅尔频率倒谱系数mfcc;
获取语音信号的线性预测倒谱系数lpc。
进一步的,
所述获取语音信号的梅尔频率倒谱系数mfcc包括,
对语音信号通过以下公式预加重一个一阶高通滤波器,
语音信号为x[n],滤波器表示为y[n]=x[n]-μx[n-1],并且式中μ的值取0.87。
进一步的,
还包括在mfcc信号中,采用以下公式加窗使用边缘平滑降到0的汉明窗,
w[n]表示加窗后的语音信号,l为帧长。
进一步的,
对所述语音信号的频谱取模平方得到语音信号的功率谱;
通过以下公式对语音信号进行处理;
其中x(k)表示傅里叶变换后的数据,x(n)为采样的模拟信号,n表示傅里叶变换的点数;
采用以下公式应用mel滤波器组对语音信号进行处理,
式中f为频率,单位为hz。
进一步的,
所述噪音级别信息包括连续噪音信息和单次噪音信息;
所述连续噪音信息采用以下公式计算,
式中,n是测量的声级总个数,lai是采样到的第i个a声级,
所述单次噪音信息采用以下公式计算,
式中pa(t)为声压、p0为参考声压级,t1为噪声的起始时刻,t2为噪声的结束时刻,(t2-t1)为该噪声事件的时间间隔,t0为参考时间。
进一步的,
依据噪音级别信息和语音级别信息生成设备铃声大小信息和震动强度信息包括,
若噪音级别信息大于第一预设值则使用声音分贝大于噪音分贝的铃音并同时将震动强度设为机器最大值;
若噪音级别小于第二预设值且语音级别信息大于第三预设值则设备铃声大小信息设为静音,震动强度信息设为设备最大震动值的三分之一。
本发明的有益效果是,本发明通过对环境噪音和环境语音进行分析判断,智能设置场景模式,智能设置铃音大小和震动强度,提高了用户体验。
附图说明
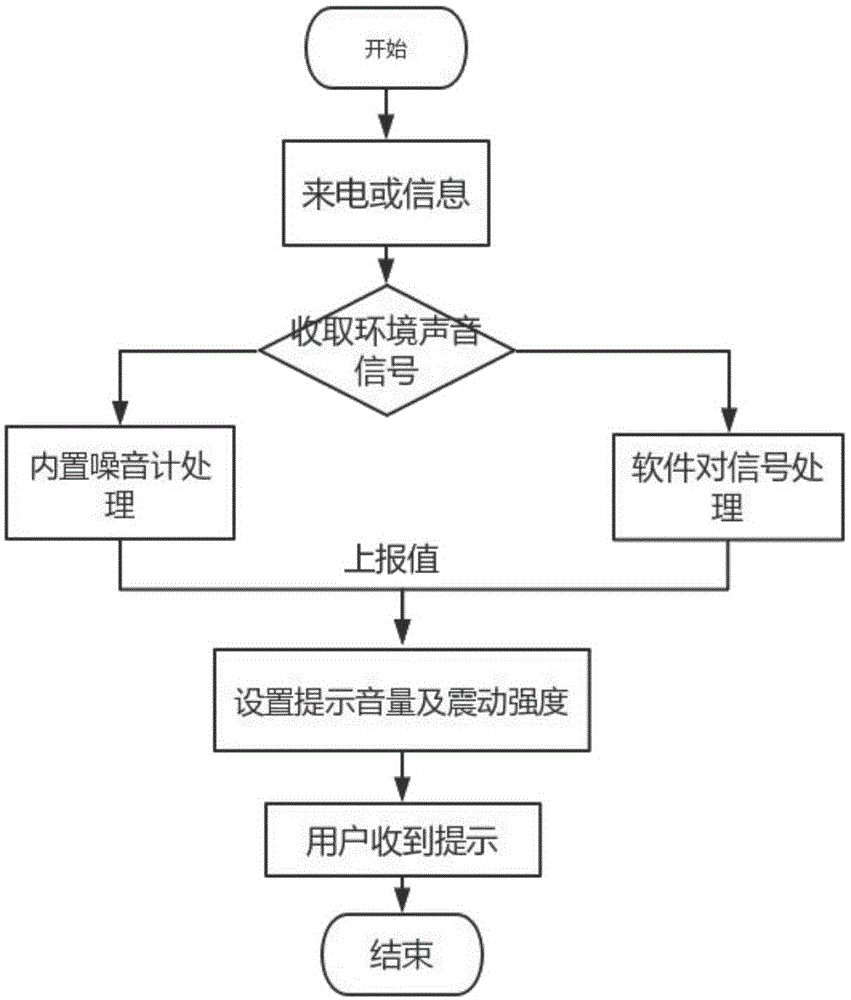
图1为本发明一实施例流程图。
具体实施方式
本发明解决背景技术中存在问题的发明思路之一是,通过侦测环境噪音和环境语音和预设值进行比较,判断用户所处的场景,智能设置语音铃声和震动强度,提高了用户体验。
如图1所示,本发明提供一种可以根据环境噪音和环境语音自动对响铃和震动进行设置的设备智能提醒方法,包括以下步骤:
获取环境声音信号;
在本发明具体实施过程中,环境声音信号可以通过手机或移动智能设备的麦克风来拾取。
对环境声音信号进行分析获取语音级别信息和噪音级别信息;
依据所述噪音级别信息和语音级别信息生成设备铃声大小信息和震动强度信息。
对环境声音信号进行分析包括,
对环境声音信号中的语音信号进行提取;
获取语音信号的梅尔频率倒谱系数mfcc;
获取语音信号的线性预测倒谱系数lpc。
在对语音信号进行分析和处理之前,必须对其进行预加重、分帧、加窗等预处理操作。这些操作的目的是消除因为人类发声器官本身和由于采集语音信号的设备所带来的混叠、高次谐波失真、高频等等因素,对语音信号质量的影响。尽可能保证后续语音处理得到的信号更均匀、平滑,为信号参数提取提供优质的参数,提高语音处理质量。
所述获取语音信号的梅尔频率倒谱系数mfcc包括,
对语音信号通过以下公式预加重一个一阶高通滤波器,
语音信号为x[n],滤波器表示为y[n]=x[n]-μx[n-1],并且式中μ的值取0.87。
人通过声道产生声音,声道的shape(决定了发出怎样的声音。声道的shape包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素phoneme进行准确的描述。梅尔频率倒谱系数mfcc可以将声道的形状在语音短时功率谱的包络中显示出来。
还包括在mfcc信号中,采用以下公式加窗使用边缘平滑降到0的汉明窗,
w[n]表示加窗后的语音信号。
由于语音信号具有短时平稳性,我们可以对信号进行分帧处理。紧接着还要对其加窗处理。窗的目的是可以认为对抽样n附近的语音波形加以强调而对波形的其余部分加以减弱。
对所述语音信号的频谱取模平方得到语音信号的功率谱;
通过以下公式对语音信号进行处理;
其中x(k)表示傅里叶变换后的数据,x(n)为采样的模拟信号,n表示傅里叶变换的点数;
采用以下公式应用mel滤波器组对语音信号进行处理,
式中f为频率,单位为hz。
通过mel滤波器可以将mel频率域的计算转换的时域计算,转换的关键就在cpp文件的开头定义的每个摩尔滤波器的中频率对应的时域中心频率列表和每个滤波器的带宽列表。
所述噪音级别信息包括连续噪音信息和单次噪音信息;
所述连续噪音信息采用以下公式计算,
式中,n是测量的声级总个数,lai是采样到的第i个a声级,
所述单次噪音信息采用以下公式计算,
式中pa(t)为声压、p0为参考声压级,t1为噪声的起始时刻,t2为噪声的结束时刻,(t2-t1)为该噪声事件的时间间隔,t0为参考时间。
在本发明一实施例中p0参考声压取2×10-5pa。
在本发明一实施例中噪声是通过不连续的采样进行测量,t1为采样起始时刻,t2为采样结束时刻。
在本发明一实施例中噪音级别信息由连续噪音信息和单次噪音信息取平均值获取。
依据噪音级别信息和语音级别信息生成设备铃声大小信息和震动强度信息包括,
若噪音级别信息大于第一预设值则使用声音分贝大于噪音分贝的铃音并同时将震动强度设为机器最大值;
若噪音级别小于第二预设值且语音级别信息大于第三预设值则设备铃声大小信息设为静音,震动强度信息设为设备最大震动值的三分之一。
第一预设值、第二预设值、第三预设值可以由用户主动设置。
本发明的有益效果是,本发明通过对环境噪音和环境语音进行分析判断,智能设置场景模式,智能设置铃音大小和震动强度,提高了用户体验。
本发明的有益效果是来电或有消息提示的时候,设备通过对环境声音信号处理,检测噪音级别,对应设置不同等级的铃声和震动提示用户,使用户即便在嘈杂的环境中也能听到或感受到提示,不会漏接电话等重要信息。当用户处于会议环境中,手机自动设置成震动并根据会议中发言人声音的大小自动设置震动强度,提高了用户体验,避免了用户忘记将手机切换到震动而违法会场礼仪。
- 还没有人留言评论。精彩留言会获得点赞!