视频播放方法、装置、电子设备和介质与流程
本申请涉及计算机技术领域,具体涉及视频播放技术,尤其涉及一种视频播放方法、装置、电子设备和介质。
背景技术:
日常生活中,人们每天都需要收集大量的信息,以便对自己的生活,投资,兴趣或工作等进行各种规划,而新闻以其“新”、“准”等特点,牢牢吸引了大家,使它成为大家日常生活不可缺少的一部分。现代社会,人们想获得新闻,通常通过上网查询,以搜索到想要看到的新闻,并且现在的网络时代的到来在一定程度上方便了人们随时查询想要得知的新闻。
现有的新闻播报方法主要是将新闻的文字转换成语音进行播报,但是这种播报方法仅包含声音,无法给用户带来沉浸式体验。
技术实现要素:
本申请提供一种视频播放方法、装置、电子设备和介质,以解决现有新闻播报仅包含声音,无法给用户带来沉浸式体验的问题。
第一方面,本申请实施例公开了一种视频播放方法,所述方法包括:
在检测到语音播报的触发操作时,获取待播报文本的文本数据以及所述待播报文本对应的人物模型数据;
生成所述文本数据对应的语音数据,并基于所述人物模型数据生成包含播报主播形象的视频帧;
将所述语音数据和所述视频帧进行同步播放。
上述申请中的一个实施例具有如下优点或有益效果:通过获取待播报文本的文本数据以及待播报文本对应的人物模型数据,并相应生成语音数据以及包含播报主播形象的视频帧,最终将语音数据和视频帧进行同步播放,使得播报方式包含饱满的人物形象和人物动作,为用户提供了生动化、形象化和沉浸式的新闻播报体验。
可选的,所述人物模型数据包括:唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种;
相应的,基于所述人物模型数据生成包含播报主播形象的视频帧,包括:
根据所述唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种数据,渲染生成包含播报主播形象的视频帧。
上述申请中的一个实施例具有如下优点或有益效果:通过将唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种作为人物模型数据,并根据人物模型数据渲染生成包含播报主播形象的视频帧,完成了带有主播形象的视频帧的创建,为后续将视频帧与语音数据同步播放奠定了基础。
可选的,所述唇形数据按照如下步骤预先生成:
将所述文本数据输入预先训练的神经网络模型;
获取所述神经网络模型输出的所述文本数据对应的唇形数据;
其中,所述神经网络模型是预先基于多个样本数据训练得到的,所述样本数据包括:视频帧中包含人物形象的样本视频、以及所述样本视频对应播报语音的文本数据。
上述申请中的一个实施例具有如下优点或有益效果:通过基于多个样本数据训练得到神经网络模型,并将文本数据输入到训练好的神经网络模型,获取文本数据对应的唇形数据,实现了依据不同文本数据获取对应唇形数据的效果,进而使得根据唇型数据生成的主播形象与文本数据的语音数据的同步性更高。
可选的,获取待播报文本的文本数据以及所述待播报文本对应的人物模型数据,包括:
确定当前的播报进度,获取待播报文本中所述播报进度对应的文本数据、以及所述播报进度对应的人物模型数据。
上述申请中的一个实施例具有如下优点或有益效果:通过获取播报进度对应的文本数据、以及播报进度对应的人物模型数据,为后续生成播报进度对应的语音数据以及视频帧,奠定了基础,满足了用户对于不同播放进度的语音数据以及视频帧的播放需求。
可选的,确定当前的播报进度,包括:
基于用户对显示界面上播报进度条的操作或对播放时间的选择操作,确定所述当前的播报进度。
上述申请中的一个实施例具有如下优点或有益效果:通过基于用户对显示界面上播报进度条的操作或对播放时间的选择操作,确定当前的播报进度,为后续获取待播报文本中播报进度对应的文本数据、以及播报进度对应的人物模型数据,奠定了基础。
可选的,所述方法还包括:
在每次生成所述视频帧时,获取当前时刻对应的轮播图,并基于所述人物模型数据生成包含播报主播形象和所述轮播图的视频帧,以轮播展示多个轮播图。
上述申请中的一个实施例具有如下优点或有益效果:通过获取当前时刻对应的轮播图,并基于人物模型数据生成包含播报主播形象和轮播图的视频帧,使得可通过视频帧轮播展示多个轮播图,实现了将轮播图与主播形象相结合,使得视频帧更加直观化以及形象化的效果。
可选的,所述方法还包括:
获取背景音数据,在将所述语音数据和所述视频帧进行同步播放时,基于所述背景音数据播放背景音;和/或,
获取背景图,相应的,基于所述人物模型数据生成包含播报主播形象的视频帧,包括:基于所述人物模型数据生成包含播报主播形象和所述背景图的视频帧。
上述申请中的一个实施例具有如下优点或有益效果:通过在将语音数据和视频帧进行同步播放时,基于背景音数据播放背景音,使得更加生动化的同步播放语音数据和视频帧;通过基于人物模型数据生成包含播报主播形象和背景图的视频帧,使得视频帧更加美观,提高了用户的播报体验。
可选的,在获取待播报文本的文本数据以及所述待播报文本对应的人物模型数据之前,所述方法还包括:
获取串场词对应的文本数据,以及所述串场词对应的人物模型数据;
生成所述串场词对应的文本数据的语音数据,并基于所述串场词对应的人物模型数据生成包含播报主播形象的视频帧;
将所述串场词对应的文本数据的语音数据,与所述基于所述串场词对应的人物模型数据生成的包含播报主播形象的视频帧,进行同步播放。
上述申请中的一个实施例具有如下优点或有益效果:通过获取串场词,并将串场词对应的文本数据的语音数据,与基于串场词对应的人物模型数据生成的包含播报主播形象的视频帧,进行同步播放,使得播放待播报文本对应的语音数据和视频帧之前,会先播放串场词对应的语音数据和视频帧,增加了播报的前后连续性,为用户提供了沉浸式的播报体验。
可选的,所述方法还包括:
基于所述语音数据和所述视频帧生成播报视频,以针对所述播报视频提供播放、下载和/或分享的服务。
上述申请中的一个实施例具有如下优点或有益效果:通过基于语音数据和视频帧生成播报视频,以针对播报视频提供播放、下载和/或分享的服务,使得用户可以根据自身需求对播报视频执行不同的操作。
可选的,所述方法应用于应用程序app、或智能音箱,或智能电视。
上述申请中的一个实施例具有如下优点或有益效果:通过将所述方法应用于应用程序app、或智能音箱,或智能电视,使得可以随时随地的为用户提供生动化、形象化和沉浸式的播报体验,免去了时间和场地的限制。
第二方面,本申请实施例还公开了一种视频播放装置,该装置包括:
数据获取模块,用于在检测到语音播报的触发操作时,获取待播报文本的文本数据以及所述待播报文本对应的人物模型数据;
语音及视频生成模块,用于生成所述文本数据对应的语音数据,并基于所述人物模型数据生成包含播报主播形象的视频帧;
同步播放模块,用于将所述语音数据和所述视频帧进行同步播放。
第三方面,本申请实施例还公开了一种电子设备,包括:
至少一个处理器;以及
与所述至少一个处理器通信连接的存储器;其中,
所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本申请任意实施例所述的视频播放方法。
第四方面,本申请实施例还公开了一种存储有计算机指令的非瞬时计算机可读存储介质,所述计算机指令用于使所述计算机执行本申请任意实施例所述的视频播放方法。
上述可选方式所具有的其他效果将在下文中结合具体实施例加以说明。
附图说明
附图用于更好地理解本方案,不构成对本申请的限定。其中:
图1是根据本申请第一实施例的一种视频播放方法的流程示意图;
图2a是根据本申请第二实施例的一种视频播放方法的流程示意图;
图2b是根据本申请第二实施例的一种视频播放的显示示意图;
图3是根据本申请第三实施例的一种视频播放装置的结构示意图;
图4是用来实现本申请实施例的视频播放方法的电子设备的框图。
具体实施方式
以下结合附图对本申请的示范性实施例做出说明,其中包括本申请实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本申请的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
实施例一
图1为本申请实施例一提供的一种视频播放方法的流程示意图。本实施例适用于响应用户的触发操作,向用户播报新闻的情况,可以由本申请实施例提供的视频播放装置来执行,该装置可以采用软件和/或硬件的方式实现。如图1所示,该方法可以包括:
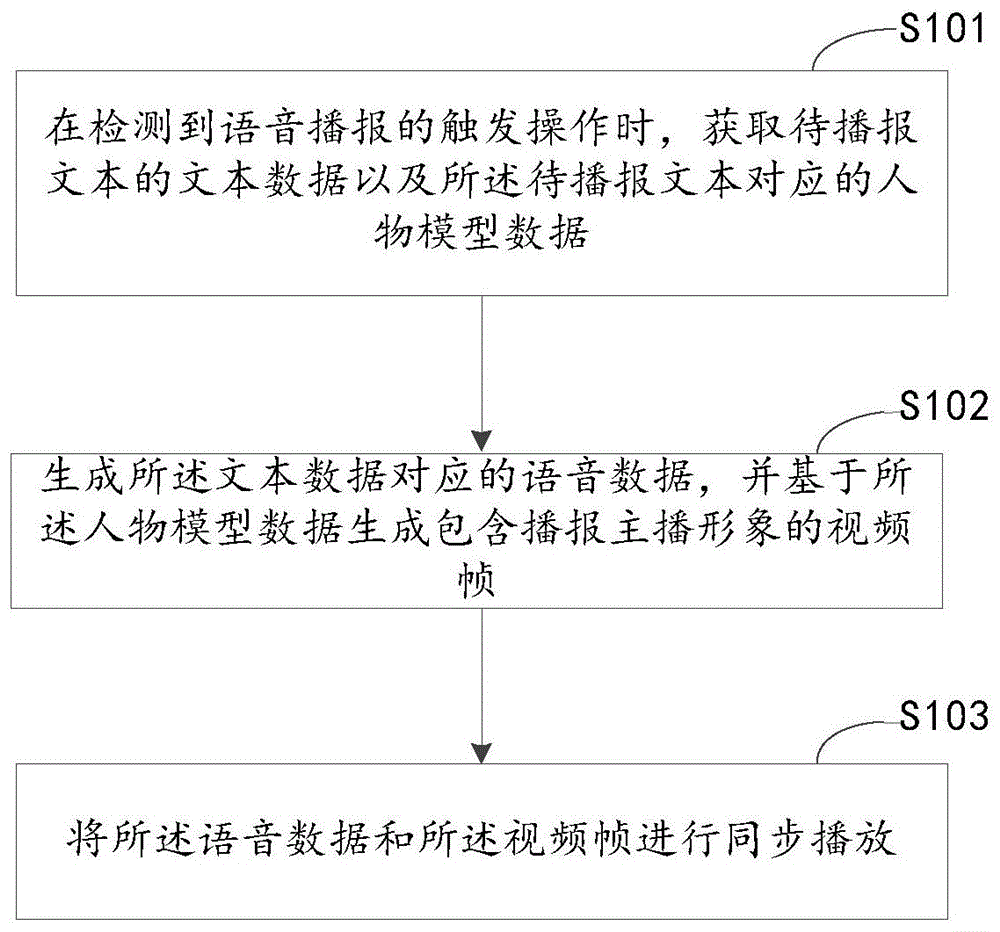
s101、在检测到语音播报的触发操作时,获取待播报文本的文本数据以及所述待播报文本对应的人物模型数据。
其中,实施触发操作的形式包括但不限于,用户通过对可触控屏幕的点击、双击或者长按指令来实施触发操作,或者,通过鼠标或者键盘等外界设备实施触发操作,或者,通过语音指令或者手势指令等来实施触发操作等。待播报文本包括但不限于新闻文本、小说文本、论文文本或者教材文本等。文本数据包括中文、英语、法语以及德语等多种语言形式。人物模型数据是用于构建视频序列中播报待播报文本对应的播报主播形象的数据。
具体的,用户对语音播报设备中的触发响应区域实施触发操作后,语音播报设备检测到所述语音播报的触发操作,并从服务器中获取与所述触发操作相关联的待播报文本的文本数据以及待播报文本对应的人物模型数据。其中,待播报文本的文本数据以及待播报文本对应的人物模型数据可以预先生成完毕,并存储于服务器中。
可选的,所述人物模型数据包括:唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种。其中,唇型数据用于构建待播报文本对应播报主播的唇部状态,面片数据即3d空间中的画布,用于构建待播报文本对应播报主播的肢体或者面部的框架,贴图数据用于构建待播报文本对应播报主播的肢体或者面部的图像,骨骼数据用于在后续根据人物模型数据渲染得到待播报文本对应视频序列时,可以控制播报主播的肢体或者面部某片区域的效果,比如眨眼、挥手、身体晃动和头部晃动等。其中的唇形数据可以实时的根据文本数据生成,也可以预先生成完毕,并存储于服务器中。
通过在检测到语音播报的触发操作时,获取待播报文本的文本数据以及待播报文本对应的人物模型数据,为后续语音数据以及包含播报主播形象的视频帧,奠定了数据基础。
s102、生成所述文本数据对应的语音数据,并基于所述人物模型数据生成包含播报主播形象的视频帧。
具体的,根据现有的文本-语音转化方法,例如tts(texttospeech,从文本到语音)等,将文本数据转化为对应的语音数据。根据现有的视频渲染方法,例如direct3d、覆盖混合渲染或者evr增强渲染模式等,将人物模型数据转化为包含播报主播形象的视频帧。其中,视频帧的数量是预先由相关技术人员确定,并根据视频帧数量在服务器中存储每一视频帧对应的人物模型数据。
通过生成文本数据对应的语音数据,以及人物模型数据对应的包含播报主播形象的视频帧,为后续将两者同步播放奠定了基础。
s103、将所述语音数据和所述视频帧进行同步播放。
具体的,通过语音播报设备的外放设备,例如喇叭或音响等,播放语音数据,与此同时,通过语音播报设备的显示屏,同步播放视频帧。
通过将语音数据和视频帧进行同步播放,为用户提供了生动化、形象化和沉浸式的播报体验。
本申请实施例提供的技术方案,通过获取待播报文本的文本数据以及待播报文本对应的人物模型数据,并相应生成语音数据以及包含播报主播形象的视频帧,最终将语音数据和视频帧进行同步播放,使得播报方式包含饱满的人物形象和人物动作,为用户提供了生动化、形象化和沉浸式的播报体验。
在上述实施例的基础上,所述方法还包括:
在每次生成所述视频帧时,获取当前时刻对应的轮播图,并基于所述人物模型数据生成包含播报主播形象和所述轮播图的视频帧,以轮播展示多个轮播图。
其中,轮播图是用来辅助说明当前待播报文本的图像,例如当前待播报文本是一款相机的介绍文本,则此时轮播图可选的为一张包含该款相机的图像。
具体的,待播报文本可能由多段文本数据组成,并且每段文本数据所包含的信息内容可能也不同,例如待播报文本由文本数据段a、文本数据段b和文本数据段c组成,其中文本数据段a是对于某个人物的介绍文本,文本数据段b是一则国际新闻的文本,文本数据段c是天气预告的文本。对于每段文本数据,都预设了对应的轮播图,当生成视频帧时,获取当前时刻对应文本数据段对应的轮播图,并基于人物模型数据生成包含播报主播形象和轮播图的视频帧。
通过获取当前时刻对应的轮播图,并基于人物模型数据生成包含播报主播形象和轮播图的视频帧,使得可通过视频帧轮播展示多个轮播图,实现了将轮播图与主播形象相结合,使得视频帧更加直观化以及形象化的效果。
在上述实施例的基础上,所述方法还包括:
获取背景音数据,在将所述语音数据和所述视频帧进行同步播放时,基于所述背景音数据播放背景音;和/或,获取背景图,相应的,s102包括:基于所述人物模型数据生成包含播报主播形象和所述背景图的视频帧。
具体的,相关技术人员预设了背景音数据和背景图,并存储在服务器中,在执行s103时,获取背景音数据并基于背景音数据播放背景音。在执行s102时,获取背景图并基于人物模型数据生成包含播报主播形象和背景图的视频帧。
通过在将语音数据和视频帧进行同步播放时,基于背景音数据播放背景音,使得更加生动化的同步播放语音数据和视频帧;通过基于人物模型数据生成包含播报主播形象和背景图的视频帧,使得视频帧更加美观,提高了用户的播报体验。
在上述实施例的基础上,s101之前,所述方法还包括:
获取串场词对应的文本数据,以及所述串场词对应的人物模型数据;生成所述串场词对应的文本数据的语音数据,并基于所述串场词对应的人物模型数据生成包含播报主播形象的视频帧;将所述串场词对应的文本数据的语音数据,与所述基于所述串场词对应的人物模型数据生成的包含播报主播形象的视频帧,进行同步播放。
其中,串场词为设置在待播报文本之前,用于引出待播报文本的文字,例如待播报文本为一则关于中东问题的新闻文本,其串场词可选的为“下面我们来看一则关于中东问题的报道”。串场词的文本数据和人物模型数据存储于服务器中,与对应的待播报文本相关联。
具体的,执行s101之前,从服务器中获取与待播报文本相关联的串场词的文本数据和人物模型数据,其中,人物模型数据包括唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种。根据串场词的文本数据与人物模型数据,分别生成语音数据与包含播报主播形象的视频帧,最终将语音数据与视频帧进行同步播放。
通过获取串场词,并将串场词对应的文本数据的语音数据,与基于串场词对应的人物模型数据生成的包含播报主播形象的视频帧,进行同步播放,使得播放待播报文本对应的语音数据和视频帧之前,会先播放串场词对应的语音数据和视频帧,增加了播报的前后连续性,为用户提供了沉浸式的播报体验。
在上述实施例的基础上,所述方法还包括:
基于所述语音数据和所述视频帧生成播报视频,以针对所述播报视频提供播放、下载和/或分享的服务。
具体的,将语音数据和视频帧进行打包,得到播报视频,播报视频包括rmvb、wmv、amv和flv等多种视频格式,可供用户对播报视频进行重复播放,以及将播报视频下载到本地端,或者分享给其它用户等。
通过基于语音数据和视频帧生成播报视频,以针对播报视频提供播放、下载和/或分享的服务,使得用户可以根据自身需求对播报视频执行不同的操作。
在上述实施例的基础上,所述方法应用于应用程序app、或智能音箱,或智能电视。
可选的,用户可通过对应用程序app实施点击操作,以执行本实施例所提供的视频播放方法,也可以通过对智能音箱或智能电视实施语音指令,以执行本实施例所提供的视频播放方法。
通过将所述方法应用于应用程序app、或智能音箱,或智能电视,使得可以随时随地的为用户提供生动化、形象化和沉浸式的播报体验,免去了时间和场地的限制。
实施例二
图2为本申请实施例二提供的一种视频播放方法的流程示意图。本实施例为上述实施例提供了一种具体实现方式,如图2所示,该方法可以包括:
s201、在检测到语音播报的触发操作时,基于用户对显示界面上播报进度条的操作或对播放时间的选择操作,确定所述当前的播报进度。
具体的,用户可对显示界面上播报进度条实施包括拖拽或者点击等操作,或者,对语音播报的播放时间进行选择,以调整语音播报的当前的播报进度。
示例性的,用户拖拽播报进度条至总播报进度条的中间位置,表示当前的播报进度为总播报进度的一半。
示例性的,用户选择播放时间“30分钟”,表示当前的播报进度为第30分钟的播报进度。
s202、获取待播报文本中所述播报进度对应的文本数据以及所述播报进度对应的唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种。
具体的,根据播报进度,以及预设的播报进度与待播报文本中文本数据的对应关系,从服务器中获取播报进度对应的文本数据。根据播报进度,以及预设的视频帧总数量,确定播报进度对应的视频帧,并从服务器中获取对应视频帧的唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种,作为播报进度对应的人物模型数据。
可选的,面片数据、贴图数据以及骨骼数据为通过人工方式预先生成并存储于服务器中。
可选的,唇形数据按照如下步骤生成:
将所述文本数据输入预先训练的神经网络模型;获取所述神经网络模型输出的所述文本数据对应的唇形数据。
其中,所述神经网络模型是预先基于多个样本数据训练得到的,所述样本数据包括:视频帧中包含人物形象的样本视频、以及所述样本视频对应播报语音的文本数据。在预先生成唇形数据后,将唇形数据存储于服务器中。
s203、生成所述文本数据对应的语音数据,并根据所述唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种数据,渲染生成包含播报主播形象的视频帧。
其中,渲染的过程如下:根据面片数据以及贴图数据,构建当前视频帧播报主播的面部以及肢体图像,根据唇型数据构建当前视频帧播报主播的唇部状态,并根据骨骼数据以及各骨骼数据的权重,控制播报主播的面部或者肢体执行目标动作。
s204、将所述语音数据和所述视频帧进行同步播放。
示例性的,图2b为一种视频播放的显示示意图,其中200表示背景图,201表示播报主播形象,202表示轮播图,203表示播报进度条。
本申请实施例提供的技术方案,通过基于多个样本数据训练得到神经网络模型,并将文本数据输入到训练好的神经网络模型,获取文本数据对应的唇形数据,实现了依据不同文本数据获取对应唇形数据的效果,进而使得根据唇型数据生成的主播形象与文本数据的语音数据的同步性更高;通过获取播报进度对应的文本数据、以及播报进度对应的人物模型数据,进而根据文本数据以及人物模型数据,生成语音数据和包含播报主播形象的视频帧,满足了用户对于不同播放进度的语音数据以及视频帧的播放需求。
实施例三
图3为本申请实施例三提供的一种视频播放装置30的结构示意图,可执行本申请任一实施例中所提供的一种视频播放方法,具备执行方法相应的功能模块和有益效果。如图3所示,该装置可以包括:
数据获取模块31,用于在检测到语音播报的触发操作时,获取待播报文本的文本数据以及所述待播报文本对应的人物模型数据;
语音及视频生成模块32,用于生成所述文本数据对应的语音数据,并基于所述人物模型数据生成包含播报主播形象的视频帧;
同步播放模块33,用于将所述语音数据和所述视频帧进行同步播放。
在上述实施例的基础上,所述人物模型数据包括:唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种;
相应的,所述语音及视频生成模块32,具体用于:
根据所述唇型数据、面片数据、贴图数据以及骨骼数据中的至少一种数据,渲染生成包含播报主播形象的视频帧。
在上述实施例的基础上,所述唇形数据按照如下步骤预先生成:
将所述文本数据输入预先训练的神经网络模型;
获取所述神经网络模型输出的所述文本数据对应的唇形数据;其中,所述神经网络模型是预先基于多个样本数据训练得到的,所述样本数据包括:视频帧中包含人物形象的样本视频、以及所述样本视频对应播报语音的文本数据。
在上述实施例的基础上,所述数据获取模块31,具体用于:
确定当前的播报进度,获取待播报文本中所述播报进度对应的文本数据、以及所述播报进度对应的人物模型数据。
在上述实施例的基础上,所述数据获取模块31,具体还用于:
基于用户对显示界面上播报进度条的操作或对播放时间的选择操作,确定所述当前的播报进度。
在上述实施例的基础上,所述装置还包括轮播图获取模块,具体用于:
在每次生成所述视频帧时,获取当前时刻对应的轮播图,并基于所述人物模型数据生成包含播报主播形象和所述轮播图的视频帧,以轮播展示多个轮播图。
在上述实施例的基础上,所述装置还包括背景音数据和背景图获取模块,具体用于:
获取背景音数据,在将所述语音数据和所述视频帧进行同步播放时,基于所述背景音数据播放背景音;和/或,
获取背景图,相应的,所述语音及视频生成模块32,具体用于:
基于所述人物模型数据生成包含播报主播形象和所述背景图的视频帧。
在上述实施例的基础上,所述装置还包括串场词获取模块,具体用于:
获取串场词对应的文本数据,以及所述串场词对应的人物模型数据;
生成所述串场词对应的文本数据的语音数据,并基于所述串场词对应的人物模型数据生成包含播报主播形象的视频帧;
将所述串场词对应的文本数据的语音数据,与所述基于所述串场词对应的人物模型数据生成的包含播报主播形象的视频帧,进行同步播放。
在上述实施例的基础上,所述装置还包括播报视频生成模块,具体用于:
基于所述语音数据和所述视频帧生成播报视频,以针对所述播报视频提供播放、下载和/或分享的服务。
在上述实施例的基础上,所述装置配置于应用程序app、或智能音箱,或智能电视。
本申请实施例所提供的一种视频播放装置30,可执行本申请任一实施例所提供的一种视频播放方法,具备执行方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本申请任一实施例所提供的一种视频播放方法。
根据本申请的实施例,本申请还提供了一种电子设备和一种可读存储介质。
如图4所示,是根据本申请实施例的视频播放方法的电子设备的框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或者要求的本申请的实现。
如图4所示,该电子设备包括:一个或多个处理器401、存储器402,以及用于连接各部件的接口,包括高速接口和低速接口。各个部件利用不同的总线互相连接,并且可以被安装在公共主板上或者根据需要以其它方式安装。处理器可以对在电子设备内执行的指令进行处理,包括存储在存储器中或者存储器上以在外部输入/输出装置(诸如,耦合至接口的显示设备)上显示gui的图形信息的指令。在其它实施方式中,若需要,可以将多个处理器和/或多条总线与多个存储器和多个存储器一起使用。同样,可以连接多个电子设备,各个设备提供部分必要的操作(例如,作为服务器阵列、一组刀片式服务器、或者多处理器系统)。图4中以一个处理器401为例。
存储器402即为本申请所提供的非瞬时计算机可读存储介质。其中,所述存储器存储有可由至少一个处理器执行的指令,以使所述至少一个处理器执行本申请所提供的视频播放方法。本申请的非瞬时计算机可读存储介质存储计算机指令,该计算机指令用于使计算机执行本申请所提供的视频播放方法。
存储器402作为一种非瞬时计算机可读存储介质,可用于存储非瞬时软件程序、非瞬时计算机可执行程序以及模块,如本申请实施例中的视频播放方法对应的程序指令/模块(例如,附图3所示的数据获取模块31、语音及视频生成模块32和同步播放模块33)。处理器401通过运行存储在存储器402中的非瞬时软件程序、指令以及模块,从而执行服务器的各种功能应用以及数据处理,即实现上述方法实施例中的视频播放方法。
存储器402可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储根据视频播放的电子设备的使用所创建的数据等。此外,存储器402可以包括高速随机存取存储器,还可以包括非瞬时存储器,例如至少一个磁盘存储器件、闪存器件、或其他非瞬时固态存储器件。在一些实施例中,存储器402可选包括相对于处理器401远程设置的存储器,这些远程存储器可以通过网络连接至视频播放的电子设备。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
视频播放方法的电子设备还可以包括:输入装置403和输出装置404。处理器401、存储器402、输入装置403和输出装置404可以通过总线或者其他方式连接,图4中以通过总线连接为例。
输入装置403可接收输入的数字或字符信息,以及产生与视频播放的电子设备的用户设置以及功能控制有关的键信号输入,例如触摸屏、小键盘、鼠标、轨迹板、触摸板、指示杆、一个或者多个鼠标按钮、轨迹球、操纵杆等输入装置。输出装置404可以包括显示设备、辅助照明装置(例如,led)和触觉反馈装置(例如,振动电机)等。该显示设备可以包括但不限于,液晶显示器(lcd)、发光二极管(led)显示器和等离子体显示器。在一些实施方式中,显示设备可以是触摸屏。
此处描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、专用asic(专用集成电路)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。
这些计算程序(也称作程序、软件、软件应用、或者代码)包括可编程处理器的机器指令,并且可以利用高级过程和/或面向对象的编程语言、和/或汇编/机器语言来实施这些计算程序。如本文使用的,术语“机器可读介质”和“计算机可读介质”指的是用于将机器指令和/或数据提供给可编程处理器的任何计算机程序产品、设备、和/或装置(例如,磁盘、光盘、存储器、可编程逻辑装置(pld)),包括,接收作为机器可读信号的机器指令的机器可读介质。术语“机器可读信号”指的是用于将机器指令和/或数据提供给可编程处理器的任何信号。
为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,crt(阴极射线管)或者lcd(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入或者、触觉输入)来接收来自用户的输入。
可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(lan)、广域网(wan)、互联网和区块链网络。
计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序来产生客户端和服务器的关系。
根据本申请实施例的技术方案,通过获取待播报文本的文本数据以及待播报文本对应的人物模型数据,并相应生成语音数据以及包含播报主播形象的视频帧,最终将语音数据和视频帧进行同步播放,使得播报方式包含饱满的人物形象和人物动作,为用户提供了生动化、形象化和沉浸式的播报体验。
应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本发申请中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本申请公开的技术方案所期望的结果,本文在此不进行限制。
上述具体实施方式,并不构成对本申请保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本申请的精神和原则之内所作的修改、等同替换和改进等,均应包含在本申请保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!