用于耳蜗植入物的声音增强的制作方法
本发明属于用于声音处理的系统和方法领域。
本发明的主要目的是允许在噪声环境中进行声音增强的用于耳蜗植入物的两耳声音处理方法。
背景技术:
当前,对于整体或部分听力损失的情况可用不同类型的可植入助听设备。所述设备基于电磁的、机械的、压电的或电动的致动原理。
耳蜗植入物是一种能够恢复其听觉神经仍起作用的耳聋人或听力减退人的听力的助听设备。更具体地,耳蜗植入物基于用刺激听觉神经的电信号变换麦克风所拾取的声信号的换能器。
耳蜗植入物的基本元件是“声音处理器”,其确定了将通过植入物的电极输送的电刺激模式。所述刺激模式根据每种情形的声音条件而变化。此外,电极被引入“蜗壳”的鳞状定音鼓或内耳的耳蜗中以最终将所述刺激传输到听觉神经,并且从此处到大脑。
当前市场现有的声音处理器旨在复制健康耳朵所执行的信息处理。不幸的是,所述处理器忽略了在噪声环境中通信很重要的该处理的基本方面:对于通过相对的耳朵接收到的声音所运用的耳朵运行的自主控制(下文称为对侧控制)。可能由于该原因,耳蜗植入物的用户在噪声环境中沟通显现出极大的难度,噪声环境例如为道路和街道,有大量人的房屋,如自助餐厅、酒吧和餐厅等。
近年来,Blake S.Wilson(杜克大学,美国)已经领导了首次由国家健康机构(National Institutes ofHealth)且现在由MED-EL GmbH公司资助的多个研究项目,设计用于忠实地复制健康耳朵(即,生物启发系统)的运行的耳蜗植入物的声音处理器,目的是提高植入物在噪声环境中的效能。其解决方案包括,基于Enrique A.Lopez-Poveda(西班牙萨拉曼卡大学)所设计的听觉神经响应的“计算模型”来设计声音处理器的原型,EnriqueA.Lopez-Poveda在2002年作为顾问加入Blake S.Wilson的项目。Reinhold Schatzer也作为工程师加入该团队,当前在MED-EL总部(澳大利亚)。
生物启发处理器的运行及其结果已经公布于多个文献(Wilson等人,“Two new directions in Speech Processor design for cochlear implants(用于耳蜗植入物的语言处理器设计的两个新方向)”,2005年;2006年,“Possibilities for a closer mimicking of normal auditory functions with cochlear implants(利用耳蜗植入物进行正常听觉功能的更接近模仿的可能性)”,“Use of auditory models in developing coding strategies for cochlear implants(开发用于耳蜗植入物的编码策略中使用听觉模型)”,2010年),以及公布于Reinhold Schatzer的博士论文(“Novel concepts for stimulation strategies in cochlear implants(用于耳蜗植入物中的刺激策略的新颖概念)”)因斯布鲁克大学,2010年),但是研究继续。
另一方面,已知的是,在“自然听力”中,每一个耳朵的运行取决于相对的耳朵的运行,从而大脑将从两个耳朵到达它的信息结合(“两耳”听力)。在这点上,应当提及所谓“双边耳蜗植入物”的存在。在该情况下,用户具有安装的两个耳蜗植入物,每只耳朵一个。这种类型的植入物的缺陷在于,植入物的运行的控制和模式完全彼此独立。换言之,这种类型的植入物缺少在健康耳朵中存在的对侧控制,该对侧控制在噪声环境下为正常听力的人提供听力,因此这种类型的植入物在这些噪声环境中的效能和性能明显亟待改善。
在该意义上,文献US2012/0093329使用了基于耳间强度差的检测算法并且根据检测到的耳间强度差来精确地处理声音。这意味着,声音处理技术需要对强度差的在先检测。类似的方法由WO2010/022456A1披露,其中所描述的声音处理系统也基于检测算法;该检测算法使用SNR信噪比从而相对于检测到的噪声来增强信号。另一方方法来自US2009/0304188A1,其中有向麦克风用于确定那些被视为相关的信号并且相对于其余的信号执行所述信号的延迟。所引用的全部文献都基于在先检测或确定并且因此需要在先检测或确定并且以使得声学相关信号劣化的方式变换信号,在先检测或确定需要更多的处理资源。
本领域已知的其他发展不基于在先检测,但是基于所检测到的声信号的基于时间的对齐,在该意义上,公开为US2004/0172101A1的文献描述了一种用于多通道耳蜗植入物的峰值取得时序模拟策略,其中通过两个麦克风中的每一个拾取的信号被处理成在时间上对齐并且保留了用于声源定位的内耳时间差。
一些当前的听力辅助装置(例如,)特征在于匹配听力辅助装置的降噪和方向性特征的双边无线同步。这些听力辅助装置特征还在于协调两个设备之间的音量和节目变化的两耳协调(即,通过调节仅一个设备对两个设备做出调整)。声称它们的两耳听力辅助装置保留了耳间差并且帮助用户组织声音场景,降低收听努力。由于产权问题,这些声称背后的声音处理不为本作者所知。然而,独立的科学家已经确认了听力辅助装置制造商所声称的一些益处(Wiggins IM,and Seeber BU,“Linking dynamic-range compression across the ears can improve speech intelligibility in spatially separated noise”,J.Acoust.Soc,Am.133:1004-1016)。通过听力辅助装置进行的声音处理尤其是频率相关的动态范围压缩,不能显著区别于耳蜗植入物的声音处理。
因此,在本文提出的技术问题在于,当前的两耳耳蜗植入物和所开发的声音处理技术未提供在诸如城市街道、自助餐厅等噪声环境中(其中同时有许多不同的声音)耳聋用户的听力和沟通的有效的解决方案。这意味着,用户不能清楚地理解语言,也不能精确地定位和检测声源。
发明概述
本发明的一个方面是用于声信号的声音处理方法,本发明的另一实施方案是用于声信号的声音处理的声音处理设备或系统,其适于根据本文所描述的方法来处理声音,本发明的又一方面是配备有所述声音处理器的耳蜗植入物,本发明的又一方面是包括上述声音处理设备的听力辅助设备植入物。
本文所描述的本发明的用于耳蜗植入物声音处理器的声音增强处理方法不需要任何参数、信号或输入的任何先验检测;本发明的方法基于通过与处理器相关联的麦克风捕获声信号以及随后在没有任何在先检测的情况下处理该信号。
不同于上述用于双边耳蜗植入物的声音处理方法,本发明的声音处理方法不涉及到特征(或信号)检测,因为不对感兴趣特征(或信号)做出假设。在一个设备(声音处理器)中的频道的增益与来自对侧设备(声音处理器)中的适合的频道的时间加权输出幅值成比例地受抑制。如上述的一些现有的声音处理器,本发明的声音增强方法也增强了SNR或内耳声音定位线索,但是该增强自然地出现于其生理启发运作,而不是来自使用特征检测和增强算法。
因为本文所描述的声音处理方法基于两耳方案,所以该方法需要两个处理器或一个处理器进而仿真第二处理器。其中任一者或两者可以如所述那样工作,因为每个处理器所捕获的信号的声音过程取决于另一个的一些参数,反之亦然。
因此,一个处理器将从麦克风接收到的进入的信号分解成频带。每个频带进一步被处理从而获得每个带的相应的包络,以此方式,每一个包络可通过压缩技术来放大。
通过每个处理器应用于每个包络的放大处理的增益取决于来自另一处理器的输出信号的幅值能量,因此来自一个处理器的输出能量越高,通过另一处理器执行的放大越低,反之亦然。
然后,放大的包络用于调制当处理器通过任何适合的连接相关联时可用于刺激听觉神经的电脉冲的幅值。以此方式,本文所描述的声音处理技术可用于噪声环境中的声音增强的耳蜗植入物。
本发明的声音增强处理方法可能包含如下步骤中的每一个:
通过两个互连的声音处理器中的一个的麦克风来捕获至少声信号,
通过声音处理器将捕获的声信号分解成频带,
通过声音处理器分别提取每个频带的包络,
通过声音处理器借助压缩技术来放大包络,所述放大进而包括根据来自另一声音处理器的输出信号的幅值来修正放大的增益值,其中增益与幅值的关系是,输出信号的幅值的能量越高,放大的增益越低,反之亦然。
本发明的另一方面涉及声音增强设备,或者用于执行产生耳蜗植入物中的声音增强所需的步骤的耳蜗植入物声音处理器的具体模块。本发明的该方面包含了所述声音增强设备,声音增强设备包括两个互连的声音处理器,更确切地是持续交错采样(CIS)处理器、或者称为m中n(n-of-m)类型的处理器(例如,先进组合编码器(ACE)、谱峰(SPEAK)),带有各自的麦克风;两个声音处理器中的一个适于根据来自另一处理器的输出信号来处理由相应的麦克风捕获的输入声信号。所述声音处理器适于借助所述输入声信号的增益处理相对于处理器的输出信号的幅值来执行输入声信号的放大;这意味着,处理器之一根据从另一个处理器接收到的信号来工作,反之亦然。
声音增强设备可以呈现至少两种构造;第一构造包括两个互连的声音处理器,带有各自的麦克风,声音增强设备的特征在于两个声音处理器中的至少一个适于根据来自另一处理器的输出信号来处理由其相应的麦克风所捕获的输入声信号;第二构造包括至少一个声音处理器,带有至少一个麦克风,仿真多处理器,该声音增强设备的特征在于,每个仿真的声音处理器适于根据来自另一仿真的声音处理器的输出信号来处理由麦克风捕获的输入声信号。
声音处理器可以包括来自如下的至少一个滤波器:Butterworth,Bessel,Chebicheb,DRNL和Gammachirp。
本发明的又一方面涉及独立的耳蜗植入物,包括用于听神经的电刺激的至少一个模块,以及适于实施之前所描述的本发明的声音增强方法的声音增强设备。
在本发明的进一步的方面中,听力辅助设备包括之前所描述的声音增强设备。
附图说明
为了补充所做的说明以及为了帮助更好的理解本发明的特征,依照本发明的实际的实施方案的优选实施例,附上一组图作为所述说明的一体的部分,其中利用示例而非限制性的字符做如下表示:
图1示出了描绘将MOCR传出控制并入搏动的CIS声音处理器的实施方案的示意图。
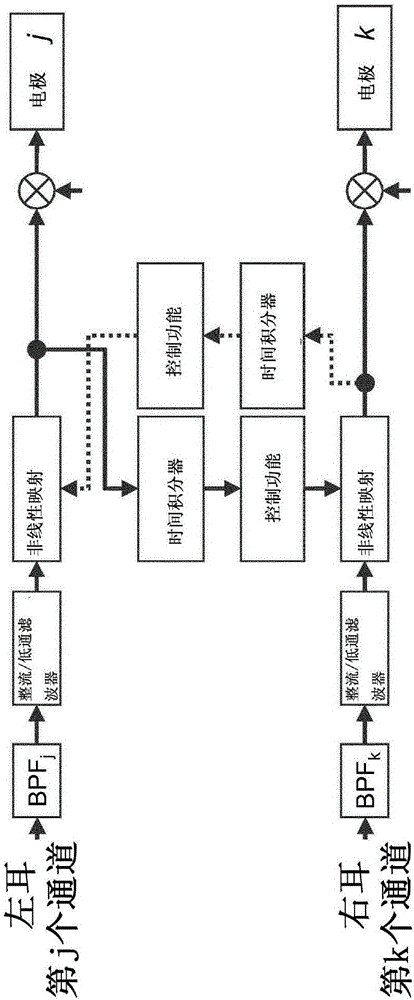
图2示出了描绘利用动态对侧控制的双边CIS处理器的实施方案的示意图。上下处理线仅表示左耳和右耳CIS处理器的一个一般的频道。来自左耳处理器中的通道j的非线性映射的输出信号是时间加权的且进行时间积分,并且结果用于设定右耳处理器中的通道k的非线性映射。
图3a,3b示出了如插图所指示的参数c的不同值的称为IBK的压缩函数的曲线图。两个面板描绘了相同的数据,不同之处在于,输入和输出幅值分别在左右面板中成线性和对数标度。注意,压缩函数对于c=0.01近似为线性(虚线)并且典型地c=500。
图4a-4c示出了描绘压缩参数c、对侧输出能量E以及反曲控制函数的输入和输出幅值之间的关系的曲线图,cb=525,ca=0.01,α=15和β=0.2。
图5示出了描绘时间窗h(t)的曲线图,τa=4ms,τb=29ms,和w=0.86。
图6a-6f示出了描绘在安静情况下-6dB、1-kHz纯音信号而言两个独立的标准CIS处理器(上)以及本发明的两两个MOC-CIS处理器(下)的频道输出的比较的曲线图,对于相对于收听者的音调信号的三个不同的位置:左(SL)(左面板)、前(SF)(中间面板)和右(SR)(右面板)。音调信号具有10ms的余弦方形开端和偏移斜坡,在10ms处开始,持续了50ms。每个面板图示出右耳(红线)和左耳(蓝线)处理器的通道输出幅值。在每个面板中,每对蓝线和红线用于不同的频道(共12个)。
图7a,7b示出了对于位于右侧的1kHz纯音信号而言在时间~37ms处两个独立的CIS处理器(图7a)和本发明的两个处理器(图7b)的左耳(下线)和右耳(上线)输出峰值激励模式的比较的相应的曲线图。
图8a,8b示出了对于本发明的双边CIS处理器的通道#5以及对于信号处于安静中且在右侧的条件下对侧效应的时间过程的相应的曲线图。图8a是本发明的左耳(下线)和右耳(上线)处理器的通道输出幅值。水平粗线示出了刺激物存在的周期。图8b是本发明的左耳(蓝色)和右耳(红色)处理器的压缩参数c的瞬时值。
图9a-9f示出了对于在0dB SNR白噪声中的-6dB、1-kHz纯音信号而言两个独立的标准CIS处理器(上)以及本发明的两个处理器(下)的通道输出的比较的相应的曲线图,针对音调和噪声的不同的相对位置:信号和噪声在收听者前方(SFNF)(左);信号到左耳,噪声在收听者前方(SLNF)(中间);以及信号到左耳且噪声到右耳(SLNR)(右)。
图10a-10f示出了对于在0dB SNR白噪声中的-6dB、1-kHz纯音信号而言,两个独立的标准IS处理器(每个耳朵各一个)(上面板)以及本发明的两个处理器(下面板)的左耳和右耳峰值激励模式(在时间~37ms处)的比较的相应的曲线图,针对不同的信号-噪声位置:信号和噪声在收听者前方(SFNF)(左);信号到左耳,噪声在收听者前方(SLNF)(中间);以及信号到左耳且噪声到右耳(SLNR)(右)。
图11a-11d示出了对于信号电平-36(下)和-18dB(上)、对于固定SNR 0dB,以及对于当信号到收听者左侧且噪声到收听者右侧时的条件,两个标准独立CIS处理器(左面板)和本发明的两个处理器(右面板)的峰值激励模式(在时间~37ms处)的比较的相应的曲线图。水平虚线描绘了作为基准的标准CIS处理器的通道#5的输出幅值。竖直箭头指示通道#5的耳间(处理器间)输出幅值。
图12a-12f示出了对于-12dB的固定信号电平以及对于三个不同的SNR:-6dB(上)、0dB(中间)、+6dB(下),两个独立的标准CIS处理器(左面板)和本发明的两个处理器(右面板)的峰值激励模式(在时间~37ms处)的比较的相应的曲线图。全部是信号到收听者左侧而噪声到收听者右侧的情况。
图13a,13b示出了两个连续短音分开20ms的时间间隔且嵌入冻结噪声,对于两个标准的独立CIS处理器(图13a)和本发明的两个处理器(图13b)的通道输出的比较的相应的曲线图。第一和第二短音分别呈现给左耳和右耳。音频是1.9kHz,音调电平是-4.6dB,SNR是+3dB。蓝色曲线和红色曲线分别示出了左耳处理器和右耳处理器的通道输出。
图14a-14f示出了对于0dB SNR语言整形噪声中的卡斯蒂利亚-西班牙语句子,两个标准的独立CIS处理器(上)以及本发明的两个处理器(下)的通道输出的比较的相应的曲线图,对于音调和噪声的不同的相对位置:信号和噪声在收听者前方(SFNF,左);信号到收听者左侧且噪声在收听者前方(SLNF,中间);以及信号到收听者左侧且噪声到收听者右侧(SLNR,右)。信号电平=噪声电平=-6dB。在所有情况下使用相同的噪声记号(即,‘冻结’噪声)。每个面板示出了右耳(红线)和左耳(蓝线)处理器的通道输出幅值。
图15示出了通道#8的MOC-CIS(上线)和STD-CIS(下线)的比较的曲线图。此处所示的片段是从图13A和图13D的箭头所指示的数据再绘制的。
图16a-16d示出了对于两个同时呈现的卡斯蒂利亚-西班牙语词语而言,两个标准的独立CIS处理器(左)和本发明的两个处理器(右)的通道输出的比较的相应的曲线图:词语‘diga’呈现在左耳,而词语‘sastre’呈现在右耳。两个词语具有相同的RMS电平-15dB。图16a是在左耳的词语‘diga’的HRTF滤波的波形。图16b是在右耳的词语‘sastre’的HRTF滤波的波形。图16c是两个标准CIS处理器的输出幅值。图16d是本发明的处理器的输出幅值。每个面板示出了右耳(上线)和左耳(下线)处理器的通道输出。注意,两个处理器的通道输出有时相同并且因此重叠。
发明详述
在本发明的优选的实施方案中,用户佩戴两个耳蜗植入物,每只耳朵各一个,具有对应的声音处理器,其能够时间上自适应地交换时变控制信号并且更新它们的频率特定压缩映射。控制信号的交换可以是直接的(即,从处理器到处理器)或者间接的(从每个处理器到远程控制单元,到对侧处理器);在任何情况下,耳蜗植入物的部件之间的通信可以是有线的或无线的。控制信号的更新率可以如处理器的工作采样率一样快或者如通道包络的最高频率两倍一样慢(即,在每个通道中的包络检测所采用的滤波器的截止频率的两倍)。
在本发明的一些实施方案中,可以使用一个耳蜗植入物,是负责捕获和处理任何声信号且模拟否则将分配给另一耳蜗植入物的全部任务的耳蜗植入物。同样可以构思在一只耳朵上佩戴了整个系统(植入物+声音处理器)且在另一耳朵上仅处理器(无植入物)的单侧耳蜗植入物用户。可替代地,单侧耳蜗植入物用户,他们的单个声音处理器就好像其是具有两个不同的声学输入的双边一样工作,每只耳朵一个(即,这将在一个耳朵需要整个耳蜗植入物,加上非植入物耳朵中的麦克风)。在这些情况下,仍有可能实现双边CIS处理器,并且经由仅可用的植入物所提供的电刺激模式将保留双边处理的一些所讨论的益处。
图1部分地示出了普通的现有技术的多通道搏动CI声音处理器。在该普通处理器中,声音通过麦克风拾取,经过预强调滤波器处理来增强某些频率成分,典型地是高频,并且通过自动增益控制(AGC)进行整体水平调节。AGC和预强调滤波器可以交换或联合地实现。得到的信号随后经过一组N线性带通滤波器(BPF)滤波。然后,提取出来自每个带的输出信号的包络。在图1所示的实施例中,包络是通过半波整流(Rect.)随后是低通滤波(LPF)来提取的,但是不同的声音处理器可以使用不同的包络提取算法。最后,每个通道的包络被压缩(非线性映射)以将宽范围的声压电平映射成较窄动态范围的可容忍电流,典型地从绝对阈值到最舒适的水平。最后,映射的包络用于调制经由相应的电极输送的一连串的持续交错电脉冲。
当前的临床声音处理策略,包括流行的持续交错采样(CIS)策略或先进组合编码器(ACE)是该普通的多通道搏动处理器的变型例。其它具体的声音处理策略可以在通道数量、滤波器数量与激活的电极的数量之间的关系、每个通道的包络如何提取的细节以及保留多少时间信息方面不同于该普通的实现方式。
利用类似图1的搏动CI声音处理器,通过非线性映射上的后台幅值压缩器,对于每个电极独立地确定听觉灵敏度和动态范围。一旦定制,这些非线性映射在声学刺激物和收听条件中保持固定且相同。对比而言,在自然声学听力中,内侧橄榄耳蜗(MOC)传出物的激活将耳蜗增益并且因此耳蜗灵敏度抑制到低水平以及适中水平的声音,但是不能到高水平声音。换言之,MOC传出物的激活‘线性化’耳蜗响应,因此缩小了耳蜗动态范围,并且伴随地缩小了耳蜗调谐。这些在耳蜗响应上的MOC效应可能降低听觉灵敏度、听觉动态范围和听觉频率选择性。主要MOC可以通过同侧和对侧声音以反射性方式激活,就有可能的是,在自然听力中,耳蜗增益(以及调谐)可以不固定,但是相反根据同侧声音和对侧声音的特性而动态地变化。我们提出的是,可利用自适应(即,时变的)而不是固定幅值压缩器或非线性映射在CI中模仿MOC激活的基本效果。换言之,通过允许非线性映射取决于适合的控制信号而在时间上动态地变化(即,或多或少压缩)。
一个重要的问题是应使用何种类型的控制信号以及应如何施加该控制。据我们所知,对于该论题先前没有研究,因此,原则上,任何合理形式的控制可能是可用的,并且应当探索任何合理形式的控制。然而,可以从自然MOC获得一些启示。
让我们首先考虑如何利用两耳CIS处理器来模仿对侧MOC反射(MOCR)控制。在自然听力中,耳蜗增益减少的量随着对侧MOCR诱导者声音的水平增加而增加。事实上,可以做出合理的假设:耳蜗增益减少与直接由MOCR诱导者声音所刺激的听觉神经的响应成比例,而不是与诱导者本身的整体水平成比例。此外,当对侧MOCR诱导者的频率在受抑制耳蜗区域的特征频率以下的半八度音阶至一个八度音阶之间时,MOC抑制较大。与当对侧诱导者是窄带时相比,当对侧诱导者是宽带时,MOC抑制也较大。最后,在对侧MOC诱导者被接通和关断后,MOC抑制分别需要花费一些时间来积聚或衰减。本发明提出通过利用双边CIS处理器来模仿对侧MOCR传出控制,其中在一个处理器的给定频道上的压缩量根据来自对侧处理器中的适合的频道(或通道)的时间加权输出能量而动态地变化,如图2所示,其中控制在两个频道之间是相互的,但是无需是这种情况。也即,在大多数一般情况下,对于两个处理器而言,通道数量可以不同;或者甚至,左耳处理器中的通道j可以控制右耳处理器中的通道k,并且右耳处理器中的通道k可以控制左侧处理器中的通道i。
例如,在右侧处理器的第k个通道上的压缩可以取决于来自左侧处理器中的第j个频道的时间加权输出能量(或者取决于来自左侧处理器中的多个通道的组合能量)。受自然MOC启示,对侧输出能量越大,压缩器越线性,并且低水平声音增益应越低。此外,只要输出能量能够随着声学刺激而在时间上变化,控制应当是动态的(即,时变的)。两个处理器中的受控制的通道和控制通道j和k可以具有相同或不同的频率(例如,为了更接近地模仿对侧MOC控制,对侧控制通道应当在频率上低于受控制通道)。最重要的是,对侧控制应当是相互的。也即,左侧处理器应当控制右侧处理器,反之亦然,但是这不意味着受控制的通道和控制通道应当在频率上配对。这种类型的控制的特定的实施例实现被开发和测试如下。
到目前为止,我们已经考虑了CIS后台压缩器的MOCR启发对侧控制。恰如传出MOC耳蜗抑制可以通过同侧声音和对侧声音激活一样,可同侧地施加替选或另外形式的控制。在自然听力中,同侧MOCR传出效果共享了对侧MOCR控制的多个特性,除了可能当MOC诱导者与测试音调同频率时同侧MOC抑制最大之外。因此,后台CIS压缩器的同侧控制可以利用上述用于对侧控制的方法(图2)来实现,除了受控制通道和控制通道应当相同(即,给定处理器中的每个通道将受其自身控制)或者在多数一般情况下将来自同一耳朵之外。自然同侧和对侧MOCR传出效果表现为加性的。因此,理论上讲,CIS处理器中的后台压缩器的同侧控制和对侧控制应当同时发生。
可能的范围是巨大的,并且对侧和/或同侧MOCR控制的实际的实现可能是困难的,并且潜在益处是不确定的。在下一部分,我们描述在双边CIS处理器中对侧MOCR控制的特定的实施例实现及其潜在的益处。
CIS处理器通常所使用的压缩函数,称为IBK映射函数(或映射定律),是通过下式给出的:
其中x和y分别是到处理器/自处理器的输入幅值和输出幅值,两者假设在间隔[0,1]内;并且c是确定压缩量的参数。图3示出了c的值越小,函数越线性。典型值是c=500。对于单耳CI用户,c可以在频道之间相同或不同,但是是固定的(即,非时变和独立于刺激物)。对于双边CI用户,c的不同值可以用于左耳处理器和右耳处理器并且这些值是在每个设备拟合过程中独立地确定的。让我们将任一处理器的给定通道的对应值称为cstd。
现在考虑双边CI用户。受对侧MOCR控制的特性的启发,我们提出双边CIS声音处理器,其中c根据来自对应的对侧通道的时间加权输出能量而在时间上自适应地变化。为方便,在该实施例实现中,我们不考虑在其它地方描述的对侧MOCR传出物的半八度音阶频移,因此,在提出的双边处理器中,对侧控制用于匹配频道。
左耳处理器中的任何给定频道cL(t)的瞬时值c(t)与来自右耳(对侧)处理器的对应的通道的输出能量ER(t)逆相关,反之亦然。由于下文所述的原因,在该实施例实现中,我们假设如下形式的反曲关系:
其中假设ER(t)和EL(t)在0与1之间(见下文),并且ca和cb确定了压缩范围,在该压缩范围上,映射定律可以变化,cb和ca分别对应于最大压缩值和最小压缩值。原则上,cb应当等于或接近于单耳CIS系统的标准值(即,cb=cstd)以确保在没有任何对侧控制的情况下,同侧处理器表现为标准的处理器[即,对于ER(t)=0,cL=cstd]。在极端情况下,ca可以对应于线性系统,使得利用最大对侧输出并且映射定律变成全线性[即,对于ER(t)=1,cL=ca]。换言之,映射定律被约束在线性度和标准CIS内。在Eq.2.a和中Eq.2.b,α是确定c随E(t)的变化率的参数,β是E(t)的值,其中c=(ca+cb)/2。注意,在Eq.2.a和中Eq.2.b中,假设α,β,ca和cb对于两个处理器即右耳处理器和左耳处理器来说是相同的,但是无需是这种情况。
图4示出了对于反曲关系而言压缩参数c、对侧能量E、输入幅值和输出幅值之间的关系,其中cb=525且ca=0.01,α=15,且β=0.2。图4A示出了实际的控制函数(Eq.2.a或Eq.2.b)。注意的是,对于E=0,c~500,缺省标准值,并且其随E增加而减小,直至对于E=1其等于0.01(线性映射定律)。图4B示出了对于线性地分布在0与1之间的对侧能量的十个不同值的压缩函数。注意,随着对侧能量增加,该函数变得逐渐更线性(即,输出到低电平输入逐渐更衰减)。图4C示出了作为输入幅值的函数的抑制量(dB re最大输出)。注意,最大的抑制是大约35dB并且对于对侧能量1以及输入幅值0.001而发生。最后,图4D示出了对于三个固定输入幅值0.01、0.1和0.5,作为对侧能量的函数的抑制量。该图示出了对于E~0.5,随着E的变化的变化抑制率(即,函数的斜率)最大,而无论输入幅值如何。这不是巧合。事实上,假设CI声音处理器的AGC特别地设计为用于适应大约0.5的刺激物幅值,记住该标准来手动优化α和β。当然,如标准不同,则可以采用不同的参数和/或不同的控制函数。
来自对侧处理器的瞬时输出能量E(t)被计算作为前一时间段T内的时间加权均方根(RMS)幅值如下:
其中,y(t)是压缩器的输出处的波形,T是积分周期,h(τ)是如下形式的成指数衰减的时间窗:
在Eq.(4)中,τa和τb分别是快速和慢速衰减常数,并且w是在范围[0,1]内取值的参数,当慢速时间常数接管快速时间常数时,该参数确定幅值。注意,在时间零(τ=0)处,时间窗的最大幅值等于1。还注意的是,E(t)在0与1之间取值,因为y(t)和h(t)都总是在0与1之间取值,并且积分(Eq.3)被标准化成积分周期T。
值得注意的是,对于每个时间常数t,E(t)是前一时间段t-T中通道输出波形y(t)的时间加权RMS能量,并且时间窗对于近期的比远期过去的能量给予更多的加权,取决于时间常数τa和τb。图5示出了实施例的时间窗的形状。
本发明的另一方面是用于实现本发明的方法的处理器。该处理器是利用对侧受控自适应压缩的MOCR启发双边处理器(MOC-CIS),然后将其与使用固定压缩的标准双边CIS处理器(STD-CIS)进行比较。STD-CIS处理器由两个相同的且功能上独立的CIS处理器构成,每只耳朵各一个。MOC-CIS处理器由两个CIS处理器构成,这两个CIS处理器与STD-CIS的相同,除了在任一处理器的每个通道中的它们的压缩函数受对侧处理器自适应控制之外,如上文在本发明的方法中所描述的。比较基于压缩后的通道输出(即,来自图1的非线性映射的输出)的分析。
在该比较中,本发明的处理器不包含前端增益或AGC,预强调滤波器是Butterworth 1阶高通滤波器,具有1200Hz的截止频率。线性滤波器组由12个6阶Butterworth带通滤波器构成。该滤波器的截止频率在从300Hz至8.5kHz的频率范围内近似对数地间隔(实际的截止频率是利用的未公开的函数性质来获得的)。相邻的滤波器在它们的截止频率处重叠。来自每个滤波器的输出信号的包络通过具有200Hz的截止频率的4阶Butterworth滤波器进行全波整流(FWR)和低通滤波来提取。包络幅值跨范围[0,1]并且利用IBK映射(Eq.1)来压缩。对于STD-CIS两耳处理器,右耳处理器和左耳处理器相同并且被设定有压缩值c=cstd=500,在临床设备中使用的典型值。
利用上文所述的反曲对侧控制函数(Eq.2)来实现自适应MOC-CIS处理器,参数用于产生图4(ca=0.01,cb=525,α=15,β=0.2)。来自对侧通道的时间加权输出能量E(t)(Eq.3)是利用时间窗(Eq.4)来计算的,使用以下参数:w=0.86,τa=4,τb=29ms。这些参数任意选择。积分时间周期(T,Eq.3)被设定为等于窗幅值从其最大值1衰减到任意值0.01所需的周期。对于选定的参数,T变得等于76ms。较长的T将增加计算时间,而不会使结果有显著变化。除非指出,否则压缩参数c在逐个样本的基础上重新计算,取决于E(t)。
需要强调的是,双边STD-CIS和MOC-CIS差别仅在于它们的压缩函数。对于STD-CIS,压缩是固定的且等同于典型的临床值(c=500)。对于MOC-CIS,压缩自适应地变化,如上文所说明的,STD-CIS是MOC-CIS压缩的上限。
全部处理器在时域内数字地实现在MatlabTM中并且利用44.1kHz的采样频率进行评估。
对于不同类型的噪声和不同量的噪声下的不同信号比较STD-CIS处理器和MOC-CIS处理器的性能。信号可供用作数字记录或者在时域内数字地生成。刺激水平表达为RMS幅值,以dB re RMS幅值,1kHz的正弦,峰值幅值是1(即,dB re√2)。为避免暂态开端滤波效应,信号有时前置静默段和/或后随静默段,和/或利上升方形开端/偏移斜坡选通。静默段和斜坡包含在RMS电平计算中。
期望MOC-CIS处理器中的对侧控制效果根据每只耳朵处的相对刺激水平和频谱而不同。出于此原因,并且为了评估两耳、空间上现实方案中的性能,全部的刺激物在它们经过MOC-CIS或STD-CIS之前经KEMAR头相关传递函数(HRTF)滤波。HRTF被应用作为512点有限脉冲响应(FIR)滤波器。比较STD-CIS和MOC-CIS性能,假设在眼睛水平(0°高程)处的声源以及对于信号和噪声(或干扰器)三个不同的水平位置:信号和噪声在收听者前方(SFNF);信号在左侧而噪声在收听者前方(SLNF);以及信号在收听者左侧而噪声在收听者右侧(SLNR)。
通过分析响应于有10ms余弦方形开端和偏移斜坡的50ms的持续时间的两耳、1kHz的纯音信号的其通道输出信号,在下面的部分图示说明了MOC-CIS的基本性质。在所有情况下,纯音信号前置了10ms的静默且后跟随了10ms的静默。除非指出,否则信号电平是-6dB。
图6示出了对于静音情况下的1kHz纯音信号以及对于三个不同的信号位置:左(SL)、前(SF)和右(SR),STD-CIS通道输出和MOC-CIS通道输出的比较。蓝线和红线分别描绘了左耳处理器和右耳处理器的通道输出信号。注意,红线与蓝线之间的重叠在某条件下出现。对于通道#5(通道从每个面板最下方开始编号),输出幅值最大,因为信号频率(1kHz)落入该滤波器的通带内。给定刺激物是两耳且经过适当的HRTF滤波,存在声学耳间水平差(ILD)。出于该原因,当信号在右侧时(图6C),与左耳处理器相比,通道#5的幅值对于右耳处理器而言更大,并且当信号在左侧时(图6A),情况相反。当信号在前方时,输出幅值对于左耳处理器和右耳处理器相同,因此,图6B中的蓝色曲线与红色曲线之间重叠。该行为是合理并且对于STD-CIS处理器以及对于MOC-CIS处理器而言是定形可比较的(比较图6中的上面板和下面板)。
然而,惊人的是,与STD-CIS处理器相比,对于MOC-CIS处理器,通道#5的耳间输出幅值差(IOD)较大。该结果更清楚地显示在图7中,该图描绘了作为右耳和左耳处理器的通道数量的函数的在时间~37ms处的峰值输出幅值。注意,这些结果是针对仅位于右侧(SR)的刺激物。显然,与STD-CIS处理器的IOD相比(图7A中的IODSTD-CIS),MOC-CIS处理器的IOD(图7B中的IODMOC-CIS)较大。这是因为,在MOC-CIS处理器中,两个MOC-CIS处理器中的通道#5的增益与来自对侧处理器的对应通道的输出幅值成正比地受到抑制。给定声学刺激物是两耳并且在图7所示的特定的实施例中,与左侧处理器相比,其水平在右耳上较大,并且输出幅值对于右侧也较大。因此,右耳处理器比相反情况更多抑制左耳处理器。
当然,右耳处理器在一定程度上也受左耳处理器抑制。这通过如下事实显示在图7中:与对于STD-CIS处理器相比,对于MOC-CIS处理器而言,右耳处理器中的通道#5的峰值幅值略低。在没有对侧抑制的情况下,MOC-CIS等同于STD-CIS。因此,与STD-CIS处理器(图7B中的红色箭头)相比的右耳MOC-CIS处理器的略小的输出表明了某种抑制。然而,该抑制的量由于如下两个原因对于左侧处理器(图7B中的蓝色箭头)而言小得多:(1)因为刺激物水平在左耳上较低;以及(2)因为左侧处理器中的增益进一步受较强的右耳处理器输出抑制。换言之,对侧抑制的量是不对称的,因为其取决于处理器的输出幅值,而不是取决于其输入幅值。
因为刺激物在时间上持续且压缩量在逐个样本基础上重新计算,所以通道#5的IOD在刺激物开端相对较小并且在时间上逐渐地增加直至其达到高原效应。该效应的时间过程图示在图8中。注意,在时间=0,对于右耳和左耳处理器,压缩相同(c~500)。然后,随着来自右耳处理器的输出幅值增加,在左耳处理器上的压缩减小(即,映射定律变得更线性)。这更进一步减少了来自左耳处理器的输出幅值,这进而减少了其对右耳处理器的抑制效应。
不同于MOC-CIS,其输出幅值取决于对侧控制而变化,在两个STD-CIS处理器中的压缩是固定的。因此,较小的IODSTD-CIS(相对于IODMOC-CIS)(图7A)仅反映声学的HRTF相关的ILD。总之,MOC-CIS大概传达了相比于STD-CIS更佳的单侧性信号。
图9示出了对于在0dB SNR白噪声中-6dB的、1kHz的纯音信号,STD-CIS处理器和MOC-CIS处理器的通道输出。图10示出了对于时间~37ms的对应的峰值激励模式。等同的噪声记号(即,冻结噪声)用于产生全部这些图来利于处理器和条件之间的比较。让我们首先考虑SFNF条件(图9和图10中的左面板)。在该条件下,对于左耳和右耳处理器而言,通道输出相同。然而,与MOC-CIS相比,对于STD-CIS而言,峰值输出幅值较大(即,比较图10A和图10D)。这是因为,在两个耳朵处刺激物是相同的,因此,两个MOC-CIS处理器以相同的量相互抑制,将映射定律线性化并且相比于STD-CIS减少了输出幅值。虽然该线性化可能减少可听性,但是其可以具有其它潜在的益处。例如,其增强了幅值调制。事实上,通道#8至#10中的调制对于MOC-CIS(图9D)而言比对于STD-CIS(图9D)而言更深。该问题论述如下。
现在我们考虑SLNF条件(图9和图10中的中间面板)。在该条件下,相同的噪声电平到达两个耳朵,但是信号电平在左侧比在右耳上高。对于STD-CIS处理器,这引起了具有大约信号频率的频率的通道(通道#4至#6,图10B)中的相对小的IOD,以及对噪声最敏感的通道(通道#8至#12)引起了相对高的输出。结果对于MOC-CIS处理器(图10E)有惊人的不同。因为噪声电平对于两个耳朵是相同的,所以噪声电平对侧地自我抑制,因此减少了那些对噪声最具有响应性的通道(通道#8至#12)的响应,如之前对于SFNF条件所描述的。然而,纯音信号的水平在左耳比在右耳上高。因此,在左耳处理器中的较大的信号输出比相反情况下更多地抑制右耳处理器。如图10E所示,对于伴随着对噪声(通道#8至#12)的减弱激励的信号通道(通道#4至#6)净效应是极大的IOD。从感觉上讲,按推测,MOC-CIS将传达噪声较低的且更佳的单侧化信号。
最后,让我们考虑SLNR。在该情况下,噪声电平在右耳上比在左耳上高,并且信号电平在左耳上比在右耳上高。换言之,有效SNR在左耳上比在右耳上更大。这解释了图10C所示的STD-CIS激励模式:来自信号最敏感通道(#5)的输出对于左耳比对于右耳更大,而来自噪声最敏感的通道(#8至#12)的输出对于右耳比对于左耳更大。MOC-CIS处理器的激励模式(图10F)有惊人的不同。由于对侧抑制,左耳处理器回应(即,传达)信号,而右耳处理器主要回应噪声。此外,与STD-CIS的相比,信号(通道#5)的IOD大得多。从感觉上讲,按推测,效果将是更小的噪声以及更佳的单侧化信号和噪声。
至此所描述的效果是针对的-6dB的信号电平,但是它们对于宽范围的信号电平仍成立。作为实施例,图11示出了对于SLNR条件以及对于-36dB(下)和-18dB(上)的信号电平,对于STD-CIS(左面板)和MOC-CIS(右面板)的峰值激励模式。所有结果是0dB SNR。水平虚线仅为了参考并且描绘了左耳和右耳STD-CIS处理器,对于通道#5的峰值输出幅值。注意的是,对于两个电平,尤其是对于i-18,与STD-CIS相比,对于MOC-CIS而言,对信号最敏感的通道#5(竖直箭头描绘)的IOD较高。还要注意,已经显示出对于-6dB的信号电平发生(图10F)的左耳MOC-CIS处理器的通道#8至#12上的降噪甚至对于-18dB的信号电平继续发生(比较图11A和图11B)以及对于-36dB也继续在较小的程度上发生(比较图11C和图11D)。
上述的MOC-CIS的益处对于宽范围的SNR也成立,甚至是对于负的SNR。作为实施例,图12示出了对于SLNR条件以及对于-6dB的SNR(上)、0dB(中间)和+6dB(下)而言,对于STD-CIS(左面板)和MOC-CIS(右面板)的峰值激励模式(在时间~0.37ms)。全部结果是针对-12dB的固定信号电平。注意,对于对信号最敏感的通道#5,对于全部三个SNR,IODMOC-CIS高于IOCSTD-CIS。还注意的是,在左耳MOC-CIS处理器的通道#8至#12上的降噪甚至对于-6dB SNR继续发生(比较图12B和图12A)。
虽然对于特定的空间条件(SFNR)示出了在信号电平和SNR上MOC-CIS的益处的稳健性,但是至此所描述的效果对于其他位置同样稳健。
本发明的MOC-CIS处理器涉及到对侧反馈,并且可能会认为这会使得MOC-CIS不稳定。图13通过将STD-CIS(A)和MOC-CIS(B)的通道输出与谨慎选定的刺激物的比较而允许评估稳定性。刺激物由20ms的静默,随后是20ms的短音呈现给左耳、随后是20ms的静默,随后是20ms的短音呈现给右耳,随后是20ms的静默构成。两个短音具有相同的频率(1.9kHz)并且以相同(冻结)噪声呈现给两耳。噪声持续整个刺激持续期间(100ms)。分别利用5ms和10ms的余弦方形开端和偏移斜坡对短音和噪声进行选通。
图13A示出了来自STD-CIS处理器的输出作为参考。主要通过通道#7来传送两个短音。到第一短音的输出对于左耳比对于右耳更大,因为第一短音呈现给左耳,而HRTF引入了ILD;到第二短音的输出对于右耳比对于左耳处理器更大,因为第二短音呈现给右耳。输出在静默间隔上或者在远离短音频率的频道上相同,因为对于两个耳朵而言噪声相同
图13B示出了对于MOC-CIS处理器的对应的输出幅值。注意,在该情况下,左耳输出和右耳输出不总是在不存在短音信号的情况下重叠。例如,对于通道#8,在第一短音开端后,左耳输出变得高于右耳输出,但是甚至在第一短音的开端后继续高。在通道#7中,在两个短音之间的时间间隔上(图13B中的箭头)发生同样的情况。这表明了,在到两个压缩器的输入或者来自两个压缩器的输出之间的小的耳间差可能足以使得耳间输出差逐渐增加且在甚至在刺激物导致高差别停止后仍在时间上传播的意义上,MOC-CIS系统可以是‘不稳定的’。
这种类型的不稳定是安全的并且可能是生理似然的。这种类型的不稳定是安全的,因为在MOC-CIS中的压缩总是小于或等于STD-CIS压缩。因此,STD-CIS处理器的输出幅值在任何条件下对于任何通道是MOC-CIS输出幅值的上限。为证实这点,图13B中的绿线(通道#8)是STD-CIS右耳输出的再绘制。注意的是,尽管不稳定,但是MOC-CIS处理器的幅值永不会超过STD-CIS的幅值。
所讨论中的不稳定性也可能是生理似然的。在回响环境中的声学听力中,声音被感觉到源自第一波前所指示的位置,称为优先效应的现象。图13B表明,对于第二短音(至少对于通道#6和#8),左耳支配两耳MOC-CIS响应,并且因此,两个音调序列可能被有效地感觉到向左,即使第二音调呈现给右耳。
不确定的是该‘横向支配’现象在何种程度上影响MOC-CIS用户的听觉性能。所描述的不稳定性仅对于稳定背景声音发生。此外,横向支配仅在声学场景中的足够大的变化发生之前保留。在图13的实施例中,仅在其电平在右耳上较高的第二短音发生之前左耳支配了通道#7中的两耳输出。在现实的声学方案中,到两个处理器的输入远不能稳定,因此横向支配不可能且不会成为问题。
图14示出了卡斯蒂利亚-西班牙语噪声中听力测试(HINT)的句子的通道输出。句子是“Yo tengo un coche verde”并且在语言整形噪声中呈现。该语言电平是-6dB并且SNR是0dB。让我们首先分析SFNF条件(即,图14中的左面板)。在该情况下,如所期望的,输出幅值对于STD-CIS处理器和MOC-CIS处理器而言对于右耳和左耳是相同的。然而,与STD-CIS(图13A)相比,对于MOC-CIS(图13D)而言,绝对幅值较低,并且最突出的语言特征的幅值调制对于MOC-CIS而言比对于STD-CIS而言更深。这更好地从图15中看出,图15示出了对于图14A和图14D中的箭头所指示的特征的两个处理器的右耳输出的直接比较(通道#8)。对于MOC-CIS,基准幅值较低,因为相同的刺激物到达两个耳朵并且它们以相同的量相互抑制。结果,两个MOC-CIS处理器在该条件下比两个STD-CIS更线性地工作。然而,MOC-CIS处理器的更线性的功能增强了幅值调制,这可能利于检测感觉上突出的语言特征。
现在我们比较对于SLNF条件两个处理器的通道输出。合理地,对于STD-CIS处理器(图14B),一些语言特征在本底噪声之上,并且在左耳处理器比在右耳处理器上更突出,因为语言在左侧。尽管如此,在左耳处理器和右耳处理器的输出之间存在显著的重叠。对于MOC-CIS的结果的模式(图14E)惊人地不同。对于通道#1至#6以及#11-#12,在右耳的输出受最突出的语言特征抑制,由于HRTF滤波,该最突出的语言特征的水平在左耳比在右耳高。因此,对于这些通道,对于最突出的语言特征,对侧抑制增加了IOD。HRTF滤波增强了中频并且增强对于左耳比对于右耳相对较大,因为语言在左侧。结果,对于中频通道(#7至#10),左耳抑制抑制右耳比相反情况下更大,倒置左耳输出支配整体的两耳响应。尽管这种支配存在,最突出的语言特征仍存在于右耳输出,如图14E中的箭头所示。换言之,在部分3.1.4中所描述的横向支配效应对于这些中频通道发生。然而,重要的是,如上文所示,在左侧MOC-CIS处理器中的输出幅值永不超过STD-CIS的那些输出幅值。共同地,当前的结果模式表明,MOC-CIS按推测应当增强最突出语言特征的横向化并且同时减少整体(两耳)噪声电平,尤其是在与语言信号对侧的耳朵上。这可以增强智能性并且可能减少收听努力。
最后,让我们分析对于SLNR条件的结果模式。上述对于SLNF条件的现象也适用于该条件,甚至更明显。在MOC-CIS(图14F)中,由于相互对侧抑制,语言特征明显地呈现于左耳处理器的输出(设备面向语言信号),而噪声基本上编码到右耳处理器的输出中(设备面向噪声)。惊人地,在左耳输出中存在极小的噪声。此外,右耳中到噪声的输出受左耳的最突出语言特征抑制。组合地,当前结果表明,MOC-CIS应当推测地增强语言和噪声的横向化,同时提高IOD(即,减少对侧噪声电平)到最突出语言特征。这可能增强了空间分离并且减少了收听努力。
空间位置是听觉流的有利线索。更精确地,空间对于在时间上交错的声音序列的分离是重要的,但是对于时间上重叠(即,同时发生的)声音的分开不太重要。上文已表明,MOC-CIS处理器可能增强空间远距声音的横向化,至少对于宽带噪声中的信号(音调或语言)。该部分致力于表明,MOC-CIS也可以在多讲话者(例如,鸡尾酒聚会)情况下增强横向化,因此增强语言分离。
图16示出了位于收摊子任一侧的讲话者在自由场地同时所讲的两个不同的卡斯蒂利亚-西班牙语词语,双边STD-CIS和MOC-CIS处理器的通道输出:在收听者的左侧讲了词语(‘diga’),并且在收听者的右侧讲了词语‘sastre’。两个词语是二音节的并且取自发音平衡的语言测听集合。在当前的实施例中,两个人词语实际上是同一女性讲话者所讲且以相同的电平(-15dB)呈现。注意,对于该水平,一些剪切仍发生在HRTF滤波波形中(即,图16A和图16B中的瞬时幅值,有时超过±1),但是很少有这种情况。
图16示出了与STD-CIS(图16C)相比,对于MOC-CIS(图16D),词语的最显著的波形特征之间的左右重叠更少。事实上,相比于STD-CIS,能够几乎‘看到’在收听者左侧所讲的词语diga主要编码在左处理器输出中,而而收听者右侧所讲的词语sastre主要编码在右处理器输出中。这表明,在具有多个空间远距讲话者的情形下,MOC-CIS增强了横向化以及可能的空间分离。这可以在‘鸡尾酒聚会’情形下增强智能性并且减少收听努力。
至此所显示的结果针对双边MOC-CIS处理器,其中压缩参数c在逐个样本的基础上更新;即,更新率等于采样频率(44100Hz)。对于高采样频率,这可以使得MOC-CIS过慢且对于双边CI中的实际使用不切实际。另一方面,假设通道包络是通过利用200Hz的截止频率进行低通滤波来获得的,无需以高于该频率两倍的速率更新c。事实上,如果压缩后的输出再经过低通滤波以最小化暂态效应,则对于400Hz(低通滤波器的截止频率的两倍)的更新速率,MOC-CIS性能实际上保持不变。相对于当前结果的唯一显著差别是通过该新的后台低通滤波器所引入的通道输出波形的附加延迟。
所提出的双边MOC-CIS处理器的典型的实现方式将要求收听者佩戴两个带有对应的声音处理器的CI,其能够交换时变控制信号以及在时间上自适应地更新它们的频率特定压缩映射。控制信号的交换可以是直接的(即,从处理器到处理器)或者间接的(从每个处理器到远程控制单元,到对侧处理器)。部件之间的通信可以是有线的或无线的。如上文所看到的,控制信号的更新率可以如处理器的采样率一样快,或者如通道包络中的最高频率的两倍一样慢(即,包络检测低通滤波器的频率的两倍)。
虽然双边耳蜗植入正变得越来越更常见,尤其是在儿童中,当前大部分植入物用户仍佩戴单CI。本文所描述的潜在MOC-CIS益处(例如,降噪、提高的调制以及改进的横向化)是双边声音处理的结果,而不适双边电刺激的结果。实际上,双边声音处理可能仍对于单耳CI用户有用,并且使用带单植入物的两耳MOC-CIS也不难。想象比如在一只耳朵上佩戴整个系统(植入物+声音处理器)而在另一耳朵上仅有处理器(无植入物)的单边CI用户。可替代地,想象单边CI用户,其单个声音处理器就好像其是具有两个不同的声学输入的双边一样工作,每只耳朵各一个(即,这将需要一只耳朵上是完整的CI,加上非植入物耳朵中的麦克风)。在这些情况下,仍有可能实现双边MOC-CIS处理并且经由唯一可用的植入物所提供的电刺激将保留双边处理的一些所讨论的益处。
在声学听力中,同侧和对侧MOCR同时起作用。此处,我们集中于如双边MOC-CIS所模仿的对侧MOCR效果。然而,顺便提及,MOC-CIS还可以起到模仿同侧MOCR效果的作用。为此,使用双边MOC-CIS且假设两耳声学输入诸如用于本文描述的SFNF条件将是足够的。本模拟暗示了,同侧MOCR与STD-CIS相比(例如,比较图10A和图10D)减少了总模拟并且将通过线性化来增强幅值调制(图15)。
- 还没有人留言评论。精彩留言会获得点赞!