一种语音识别系统及方法与流程
本发明涉及语音识别领域,尤其涉及一种语音识别系统及方法。
背景技术:
语音识别技术应用越来越广泛,但是现在的语音识别库基本都是基于普通话的语音而言,将语音转换为文字,准确率比较高。但是,现实生活中,大部分人的普通话都不标准,或多或少都携带一些地方语音。现有的语音识别系统将“方言”转换为文字的准确的较低,很多时候可能转换为令人哭笑不得的文字,甚至会给客户造成众多不便。
技术实现要素:
为解决上述技术问题,本发明提供了一种语音识别系统及方法。
第一方面,本发明提供了一种语音识别系统,该系统包括语音采集模块、口音甄别模块、语音校正模块以及语音转换模块;
语音采集模块,用于采集语音信息;
口音甄别模块,用于根据语音信息识别语音信息语音发出者的口音所属的地域,并将识别结果输入至语音校正模块;
语音校正模块,用于根据语音发出者的口音所属的地域对语音信息进行校正,并将校正后的结果输入至语音转换模块;
语音转换模块,用于将校正后的语音信息转换为文字信息并输出。
本发明的有益效果是:语音采集模块采集到语音后,首先通过口音甄别模块甄别语音信息发出者的口音所属地域,然后根据该口音所属地域,采用与该地域的口音相应的校正方式对用户的口音进行校正,将其校正为普通话。最后将转换后的普通话语音转化为文字,语音转换为文字的正确率大大提高,提升用户体验度。
进一步,该系统还包括:处理模块,用于将语音采集模块采集的语音信息,与语音转换模块将校正后的语音信息进行转换后所获取的文字信息进行匹配并存储
采用上述进一步的方案的有益技术效果在于,将采集的语音和转换后的文字信息进行匹配并存储后,如果后续采集到同样的语音后,无需经过语音甄别和校正等后续步骤,直接读取与该语音匹配的文字信息并输出。节省工作流程,提升工作效率。
进一步,口音甄别模块包括:特征提取单元和匹配单元;
特征提取单元,用于提取语音信息中的语音特征;
匹配单元,用于根据语音特征在预设地域语音库中查找与语音特征匹配的语音所属地域信息。
采用上述进一步的技术方案的有益技术效果在于,事先提取语音信息中的语音特征,然后将语音特征和预设的地域语音库中的语音特征进行匹配,可以准确的确定语音信息发出者的口音所属的地域。
进一步的,语音校正模块包括第一语音编码模块、语音解码模块以及第二语音编码模块;
第一语音编码模块,用于根据语音信息发出者的口音所属地域确定第一语音编码格式;
根据第一语音编码格式编码语音信息,生成第一数据帧;
语音解码模块,用于对第一数据帧进行解码,产生性语音采样序列;
第二语音编码模块,用于获取与普通话对应的第二语音编码格式;
根据第二语音编码格式,将线性语音采样序列转换成普通话语音。
采用上述进一步的技术方案的有益技术效果在于,事先将语音按照语音信息发出者的口音所属地域对应的语音编码格式对语音信息进行编码,生成第一数据帧,然后对第一数据帧进行解码,产生线性语音采样序列。并采样与普通话对应的语音编码格式将线性语音采样序列转换成普通话语音。
进一步的,语音特征具体包括:语调、语速、声调中一个或多个。
第二方面,本发明提供了一种语音识别方法,该方法包括:采集语音信息;
根据语音信息识别语音信息语音发出者的口音所属的地域;
根据语音发出者的口音所属的地域对语音信息进行校正;
将校正后的语音信息转换为文字信息并输出。
本发明的有益效果是采集到语音后,首先甄别语音信息发出者的口音所属地域,然后根据该口音所属地域,采用与该地域的口音相应的校正方式对用户的口音进行校正,将其校正为普通话。最后将转换后的普通话语音转化为文字,语音转换为文字的正确率大大提高,提升用户体验度。
进一步的,将校正后的语音信息转换为文字信息并输出之后,方法还包括:将采集的语音信息,与语音转换模块将校正后的语音信息进行转换后所获取的文字信息进行匹配并存储。
采用上述进一步的方案的有益技术效果在于,将采集的语音和转换后的文字信息进行匹配并存储后,如果后续采集到同样的语音后,无需经过语音甄别和校正等后续步骤,直接读取与该语音匹配的文字信息并输出。节省工作流程,提升工作效率。
进一步的,根据语音信息识别语音信息语音发出者的口音所属的地域,具体包括:
提取语音信息中的语音特征;
根据语音特征在预设地域语音库中查找与语音特征匹配的语音所属地域信息。
采用上述进一步的技术方案的有益技术效果在于,事先提取语音信息中的语音特征,然后将语音特征和预设的地域语音库中的语音特征进行匹配,可以准确的确定语音信息发出者的口音所属的地域。
进一步的,根据语音发出者的口音所属的地域对语音信息进行校正,具体包括:
根据语音信息发出者的口音所属地域确定第一语音编码格式;
根据第一语音编码格式编码语音信息,生成第一数据帧;
对第一数据帧进行解码,产生线性语音采样序列;
获取与普通话对应的第二语音编码格式;
根据第二语音编码格式,将线性语音采样序列转换成普通话语音。
采用上述进一步的技术方案的有益技术效果在于,事先将语音按照语音信息发出者的口音所属地域对应的语音编码格式对语音信息进行编码,生成第一数据帧,然后对第一数据帧进行解码,产生线性语音采样序列。并采样与普通话对应的语音编码格式将线性语音采样序列转换成普通话语音。
进一步的,语音特征具体包括:语调、语速、声调中一个或多个。
附图说明
图1为本发明实施例提供的一种语音识别系统结构示意图;
图2为口音甄别模块的一种结构示意图;
图3为语音校正模块的一种结构示意图;
图4为本发明实施例提供的一种语音识别方法流程示意图;
图5为根据语音信息识别语音信息语音发出者的口音所属的地域方法流程示意图;
图6为对语音信息进行校正的方法流程示意图。
具体实施方式
以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、接口、技术之类的具体细节,以便透切理解本发明。然而,本领域的技术人员应当清楚,在没有这些具体细节的其它实施例中也可以实现本发明。在其它情况中,省略对众所周知的系统、电路以及方法的详细说明,以免不必要的细节妨碍本发明的描述。
本发明实施例提供了一种语音识别系统结构示意图。具体如图1所示,该系统包括:语音采集模块10、口音甄别模块20、语音校正模块30以及语音转换模块40。
语音采集模块10,用于采集语音信息。语音采集模块10可以为带有录音功能的装置,将采集到的语音输出至口音甄别模块20。
口音甄别模块20,用于根据语音信息识别语音信息语音发出者的口音所属的地域,并将识别结果输入至语音校正模块30。
一般而言,不同地域的人多少都会携带一些当地的口音。即使该语音发出者说的就是普通话,也会携带口音。那么,如果直接将这样的普通话转换为文字的话,很容易出现问题,导致语音转换正确率降低。更甚的是,很多地方方言更是难以理解,语音识别系统根本无法转换为文字,或者转换的文字必定是语句不同的。因此,实现采用口音甄别模块20甄别该语音发出者的口音所属地域,然后将识别结果输入至语音校正模块30。
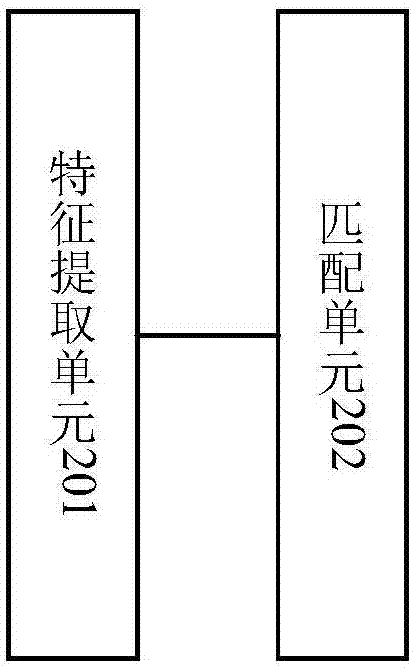
在一个可选的实施例中,为进一步详细说明口音甄别模块的具体实现功能。下面将列举一种口音甄别模块20的组成结构,具体如图2所示,口音甄别模块20可以包括特征提取单元201和匹配单元202。
其中,语音特征提取单元201用于提取语音信息中的语音特征。
匹配单元202,用于根据语音特征在预设地域语音库中查找与语音特征匹配的语音所属地域信息。
进一步可选的,语音特征可以但不限于包括:语调、语速、声调中一个或多个。
不同地方的人,说同一句话时,其说出话的语调、语速、声调等等基本都不会完全相同。多少都会有一些差别,甚至距离较远的两个地方,差别将会更加明显。那么,将不同地方语音的特征进行提取后存放在预设地域语音库中作为识别不同地方语音的特征标识。当接收到语音时,则可以将语音的特征和预设的地域语音库中的语音特征进行匹配,确定语音所属地域。
还有一些特殊情况,比如用户输入的为英文或者其他语言等,所提取的特征则还需要单词等能够识别该语言的特征信息。然后结合上文所说的特征信息进行判别所属地域。而在转换为普通话语音时,则还包括将这种非中文语音转换为中文语音的步骤。具体转换的方法为现有技术,这里不再赘述。
语音校正模块30,用于根据语音发出者的口音所属的地域对语音信息进行校正,并将校正后的结果输入至语音转换模块40。
语音校正模块30确定语音发出者的口音所属地域后,根据该地域的特点,对语音信息进行相应的调整,将其校正为普通话语音后,再输入至语音转换模块40。
进一步可选的,语音校正模块30可以包括:第一语音编码模块301、语音解码模块302以及第二语音编码模块303,具体如图3所示。
第一语音编码模块,用于根据语音信息发出者的口音所属地域确定第一语音编码格式;
根据第一语音编码格式编码语音信息,生成第一数据帧;
语音解码模块,用于对第一数据帧进行解码,产生性语音采样序列;
第二语音编码模块,用于获取与普通话对应的第二语音编码格式;
根据第二语音编码格式,将线性语音采样序列转换成普通话语音。
在一个具体的实施例中,第一语音编码模块301和第二语音编码模块303均可以采用混合编码器实现。语音解码模块可以为模数转换器和低通滤波器相结合实现。而语音信息发出者的口音所属地域和第一语音编码格式之间存在一定的映射关系,并存储在预设的位置。例如预设地域语音库,或者其他地方。然后,则可以通过这个映射关系,轻易的确定语音信息发出者的口音所属地域对应的语音编码格式。类似的,普通话语音和第二语音编码格式之前同样存在映射关系,并存储在预设位置。
混合编码器的工作原理为波形编码器和声码器的原理相结合。
其中波形编码器的原理为:波形编码器编码前利用采样定理对模拟语音信号进行量化,然后进行幅度量化,再进行二进制编码。解码器作数/模变换后再由低通滤波器恢复出现原始的模拟语音波形,这就是最简单的脉冲编码调制(pcm),也称为线性pcm。可以通过非线性量化,前后样值的差分、自适应预测等方法实现数据压缩。波形编码的目标是让解码器恢复出的模拟信号在波形上尽量与编码前原始波形相一致,也即失真要最小。波形编码的方法简单,数码率较高。
信源编码又称为声码器,是根据人的发生机理,在编码端对语音信号进行分析,分解成有声音和无声音两部分。声码器每隔一定时间分析一次语音,传送一次分析的有/无声和滤波参数。在解码端根据接收的参数再合成声音。
通过混合编码器采用与语音信息发出者的口音所属地域对应的第一语音编码格式编码语音信息,生成第一数据帧,然后利用解码器实现于对第一数据帧进行解码,产生线性语音采样序列,最终再利用一个混合编码器采用与普通话对应的第二语音编码格式将线性语音采样序列转换成普通话语音。
语音转换模块40,用于将校正后的语音信息转换为文字信息并输出。
进一步可选的,该系统还可以包括处理模块50,用于将语音采集模块采集的语音信息,与语音转换模块将校正后的语音信息进行转换后所获取的文字信息进行匹配并存储。
将采集的语音和转换后的文字信息进行匹配并存储后,如果后续采集到同样的语音后,无需经过语音甄别和校正等后续步骤,直接读取与该语音匹配的文字信息并输出。节省工作流程,提升工作效率。
本发明实施例提供的一种语音识别系统,语音采集模块采集到语音后,首先通过口音甄别模块甄别语音信息发出者的口音所属地域,然后根据该口音所属地域,采用与该地域的口音相应的校正方式对用户的口音进行校正,将其校正为普通话。最后将转换后的普通话语音转化为文字,语音转换为文字的正确率大大提高,提升用户体验度。
图4为本发明实施例提供的一种语音识别方法流程示意图。如图4所示,该方法包括:
步骤410,采集语音信息。
步骤420,根据语音信息识别语音信息语音发出者的口音所属的地域。
一般而言,不同地域的人多少都会携带一些当地的口音。即使该语音发出者说的就是普通话,也会携带口音。那么,如果直接将这样的普通话转换为文字的话,很容易出现问题,导致语音转换正确率降低。更甚的是,很多地方方言更是难以理解,语音识别系统根本无法转换为文字,或者转换的文字必定是语句不同的。因此,可以事先甄别该语音发出者的口音所属地域。
在一个可选的实施例中,步骤420可以包括步骤4201至步骤4202,具体如图5所示。
步骤4201,提取语音信息中的语音特征。其中,语音特征可以但不限于包括:语调、语速、声调中一个或多个。
步骤4202,根据语音特征在预设地域语音库中查找与语音特征匹配的语音所属地域信息。
不同地方的人,说同一句话时,其说出话的语调、语速、声调等等基本都不会完全相同。多少都会有一些差别,甚至距离较远的两个地方,差别将会更加明显。那么,将不同地方语音的特征进行提取后存放在预设地域语音库中作为识别不同地方语音的特征标识。当接收到语音时,则可以将语音的特征和预设的地域语音库中的语音特征进行匹配,确定语音所属地域。
还有一些特殊情况,比如用户输入的为英文或者其他语言等,所提取的特征则还需要单词等能够识别该语言的特征信息。然后结合上文所说的特征信息进行判别所属地域。而在转换为普通话语音时,则还包括将这种非中文语音转换为中文语音的步骤。具体转换的方法为现有技术,这里不再赘述。
步骤430,根据语音发出者的口音所属的地域对语音信息进行校正。
具体的,确定语音发出者的口音所属地域后,根据该地域的特点,对语音信息进行相应的调整,将其校正为普通话语音。以便在步骤440中将普通话语音转换为文字信息。
在一个可选的实施例中,对语音信息进行校正可以包括步骤4301至步骤4305,如图6所示。
步骤4301,根据语音信息发出者的口音所属地域确定第一语音编码格式。
步骤4302,根据第一语音编码格式编码语音信息,生成第一数据帧。
步骤4303,对第一数据帧进行解码,产生线性语音采样序列。
步骤4304,获取与普通话对应的第二语音编码格式。
步骤4305,根据第二语音编码格式将线性语音采样序列转换成普通话语音。
在一个具体的实施例中,第一语音编码模块301和第二语音编码模块303均可以采用混合编码器实现。语音解码模块可以为模数转换器和低通滤波器相结合实现。而语音信息发出者的口音所属地域和第一语音编码格式之间存在一定的映射关系,并存储在预设的位置。例如预设地域语音库,或者其他地方。然后,则可以通过这个映射关系,轻易的确定语音信息发出者的口音所属地域对应的语音编码格式。类似的,普通话语音和第二语音编码格式之前同样存在映射关系,并存储在预设位置。
混合编码器的工作原理为波形编码器和声码器的原理相结合。
其中波形编码器的原理为:波形编码器编码前利用采样定理对模拟语音信号进行量化,然后进行幅度量化,再进行二进制编码。解码器作数/模变换后再由低通滤波器恢复出现原始的模拟语音波形,这就是最简单的脉冲编码调制(pcm),也称为线性pcm。可以通过非线性量化,前后样值的差分、自适应预测等方法实现数据压缩。波形编码的目标是让解码器恢复出的模拟信号在波形上尽量与编码前原始波形相一致,也即失真要最小。波形编码的方法简单,数码率较高。
信源编码又称为声码器,是根据人的发生机理,在编码端对语音信号进行分析,分解成有声音和无声音两部分。声码器每隔一定时间分析一次语音,传送一次分析的有/无声和滤波参数。在解码端根据接收的参数再合成声音。
通过混合编码器采用与语音信息发出者的口音所属地域对应的第一语音编码格式编码语音信息,生成第一数据帧,然后利用解码器实现于对第一数据帧进行解码,产生线性语音采样序列,最终再利用一个混合编码器采用与普通话对应的第二语音编码格式将线性语音采样序列转换成普通话语音。
步骤440,将校正后的语音信息转换为文字信息并输出。
进一步可选的,该方法还可以包括步骤450,将语音采集模块采集的语音信息,与语音转换模块将校正后的语音信息进行转换后所获取的文字信息进行匹配并存储。
将采集的语音和转换后的文字信息进行匹配并存储后,如果后续采集到同样的语音后,无需经过语音甄别和校正等后续步骤,直接读取与该语音匹配的文字信息并输出。节省工作流程,提升工作效率。
本发明实施例提供的一种语音识别方法,首先甄别语音信息发出者的口音所属地域,然后根据该口音所属地域,采用与该地域的口音相应的校正方式对用户的口音进行校正,将其校正为普通话。最后将转换后的普通话语音转化为文字,语音转换为文字的正确率大大提高,提升用户体验度。
读者应理解,在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!