一种基于倒谱分离信号的非特定人语音情感识别方法与流程
本发明涉及非特定人语音识别
技术领域:
,具体是一种基于倒谱分离信号的非特定人语音情感识别方法。
背景技术:
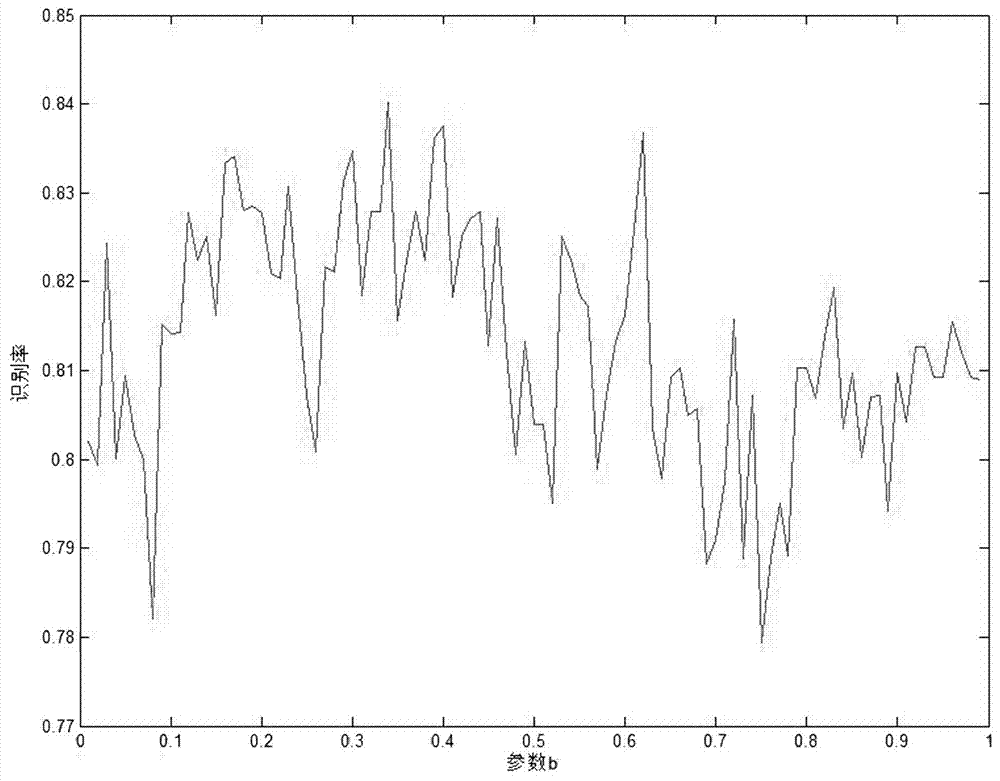
:声门与声道信号都包含了丰富的情感信息,由于个人声道的差异,通常声道信息则更多的包含了个人特征,这对于我们非特定人的情感识别工作产生了很多的干扰。在之前的谱特征提取工作之中,我们是对语音信号的整体信号进行特征提取,这类特征携带了大量的说话人的个人信息。这种特征对于特定人的情感识别往往是有效的。但是对于非特定人的情感识别效果则不如特定人。技术实现要素:本发明的目的在于克服现有技术的不足,而提供一种基于倒谱分离信号的非特定人语音情感识别方法,该方法保留声带信息并摒弃一部分的声道信息,同时寻找最佳分离点,最后对处理后的信号提取特征,可以有效提高非特定人语音情感识别率。实现本发明目的的技术方案是:一种基于倒谱分离信号的非特定人语音情感识别方法,具体包括如下步骤:S1.对情感语音库进行预处理;S2.对预处理后的情感语音库提取传统特征;S3.对处理后的情感语音库的语音信号进行倒谱域分离与重构;S4.对重构后的语音信号进行特征提取,得到重构后的情感语音库;S5.将经过步骤S4后的重构后的情感语音库分成训练集和测试集,训练集采用SVM分类器进行训练后,将测试集输入训练后的分类器中,进行语音识别后,输出判决结果;经过上述步骤,完成非特定人语音的情感识别。步骤S1中,所述的情感语音库,含有7种情感,采用16Khz采样率,8bit量化,对情感语音库进行分帧加窗处理。所述的7种情感包括中性、生气、害怕、高兴、悲伤、厌恶、无聊。所述的分帧,取10--30ms内进行分帧。所述的加窗,采用汉明窗。步骤S2中,所述的提取传统特征,是对分帧后的情感语音库的语音进行传统声学特征的提取,采用256点帧长、帧移128点,提取的声学特征包括:韵律特征参数提取、声音质量特征提取、非线性特征提取、谱特征提取;韵律特征参数提取,包括:基音频率的均值、短时能量均值和过零率变化率;声音质量特征提取,包括:频率微扰熵和振幅微扰熵;非线性特征提取,包括:Hurst指数;谱特征提取,包括:梅尔频域倒谱系数(MFCC)、线性预测系数LPC和非线性梅尔频域参数(NFD_Mel);所述的梅尔频域倒谱系数(MFCC),是提取12维MFCC特及其一阶差分共24维,然后计算其平均值。所述的线性预测系数LPC,是提取12维LPC,并计算其平均值;所述的非线性梅尔频域参数(NFD_Mel),具体的计算步骤为:S2-1.首先对S1分帧后的每帧信号做短时傅里叶变换,然后加入Teager能量算子,并取频谱幅度做2次方得到能量谱;S2-2.将S2-1中求得的能量谱输入Mel频率滤波器组中,并求出每个滤波器输出的对数能量;S2-3.将S2-2中取得的对数能量经离散余弦变换得到静态的12阶NFD_Mel参数;S2-4.将S2-3中的NFD_Mel系数进行一阶差分,得到动态的12阶NFD_Mel参数;S2-5.将S2-3与S2-4中的参数结果组合到一起,最终形成24阶的NFD_Mel参数。步骤S3中,所述的对语音信号进行倒谱域分离与重构,分帧采用256点帧长,帧移128,具体是:S3-1.取S1分帧后的每帧信号x(n)计算复倒谱,每帧语音信号x(n)是由声门脉冲激励e(n)经声道响应v(n)滤波而得到,即对x(n)进行Z变换将卷积信号变为乘积信号,然后取对数运算将乘积信号变为加性信号,最后对加性信号取Z反变换,即可得到复倒谱;S3-2.取S1分帧后的每帧信号x(n)计算倒谱信号,我们对x(n)进行Z变换后,计算取其实部做对数运算,最后做Z反变换即可得到倒谱;S3-3.人声的基音周期范围在50hz~700hz,在此范围的倒谱中寻找激励源冲激的最大值,若最大值冲激幅度超过0.08则记录下峰值点A的位置并判断为浊音,否则为清音并跳过该帧;S3-4.倒谱由于计算时失去了信号的相位信息,当判断为浊音时,在复倒谱上对信号进行分离操作,在复倒谱上以A点为分界点将信号分为声道响应与声门激励,为了保留全部声门信息的同时,逐步包含声道信息,将A点沿向原点移动,移动距离记为L,L=b*A,移动后的端点记为A1,其中b为可调节参数,0≤b≤1;S3-4.根据复倒谱的对称性,在A1点的对称点取到原点信号,并把对称的两段信号合并设为对做复倒谱逆变换,即可重构回时域信号x1(n),经过重构后的语音信号x1(n)只包含部分声道信息和全部的声门信息。步骤S4中,对重构后的语音信号进行特征提取,采用256点帧长,帧移128,具体包括如下步骤:S4-1-1.取x1(n)语音信号做短时傅里叶变换,求出频谱,并取频谱幅度做2次方得到能量谱;S4-1-2.将S4-1-1中求得的能量谱输入Mel频率滤波器组中,并求出每个滤波器输出的对数能量;S4-1-3.将S4-1-2中取得的对数能量经离散余弦变换得到静态的12阶CSS-MFCC参数;S4-1-4.将S4-1-3中的CSS-MFCC系数进行一阶差分,得到动态的12阶CSS-MFCC参数;S4-1-5.将S4-1-3与S4-1-4中的参数结果组合到一起,最终形成24阶的MFCC参数,取24阶的CSS-MFCC均值作为全局特征;S4-2-1.取x1(n)做短时傅里叶变换,通过公式对信号加入teager能量算子,并取频谱幅度做2次方得到能量谱,teager能量算子为:ψ(x(n))=x2(n)-x(n-1)x(n+1);S4-2-2.将S4-2-1中求得的能量谱输入Mel频率滤波器组中,并求出每个滤波器输出的对数能量;S4-2-3.将S4-2-2中取得的对数能量经离散余弦变换得到静态的12阶CSS-NFDMel参数;S4-2-4.将S4-2-3中的CSS-NFDMel系数进行一阶差分,得到动态的12阶CSS-NFDMel参数;S4-2-5.将S4-2-3与S4-2-4中的参数结果组合到一起,最终形成24阶的NFD_Mel参数,采用了24阶的CSS-NFDMel均值作为全局特征。步骤S5中,将经过步骤S4后的重构后的情感语音库分成65%的训练集和35%的测试集,训练集采用SVM分类器进行训练后,将测试集输入训练后的训练集中,进行语音识别后,输出判决结果,具体是:S5-1.将对情感语音库提取的特征:基音频率的均值、短时能量均值、过零率变化率、频率微扰熵、振幅微扰熵、Hurst指数、梅尔频域倒谱系数(MFCC)、线性预测系数LPC和非线性梅尔频域参数(NFD_Mel)进行特征组合;S5-2.将S5-1的特征中的65%作为训练集用SVM分类器进行训练,剩下35%作为测试集用于测试训练集的分类器性能,将测试集输入训练后的训练集中,进行语音识别后,输出判决结果。有益效果:本专利提供的一种基于倒谱分离信号的非特定人语音情感识别方法,将新特征与传统特征进行了特征组合,保留声带信息并摒弃一部分的声道信息,同时寻找最佳分离点,最后对处理后的信号提取特征,可以有效提高非特定人语音情感识别率。附图说明图1为倒谱分离信号流程图;图2为CSS-MFCC与组合特征的识别率示意图。具体实施方式下面结合附图和实施例对本发明做进一步阐述,但不是对本发明的限定。实施例:一种基于倒谱分离信号的非特定人语音情感识别方法,具体包括如下步骤:S1.对情感语音库进行预处理;S2.对预处理后的情感语音库提取传统特征;S3.对处理后的情感语音库的语音信号进行倒谱域分离与重构;S4.对重构后的语音信号进行特征提取,得到重构后的情感语音库;S5.将经过步骤S4后的重构后的情感语音库分成训练集和测试集,训练集采用SVM分类器进行训练后,将测试集输入训练后的训练集中,进行语音识别后,输出判决结果;经过上述步骤,完成非特定人语音的情感识别。步骤S1中,所述的情感语音库,含有7种情感,采用16Khz采样率,8bit量化,对情感语音库进行分帧加窗处理。所述的7种情感包括中性、生气、害怕、高兴、悲伤、厌恶、无聊。所述的分帧,取10--30ms内进行分帧。所述的加窗,采用汉明窗。步骤S2中,所述的提取传统特征,是对分帧后的情感语音库的语音进行传统声学特征的提取,采用256点帧长、帧移128点,提取的声学特征包括:韵律特征参数提取、声音质量特征提取、非线性特征提取、谱特征提取;韵律特征参数提取,包括:基音频率的均值、短时能量均值和过零率变化率;声音质量特征提取,包括:频率微扰熵和振幅微扰熵;非线性特征提取,包括:Hurst指数;谱特征提取,包括:梅尔频域倒谱系数(MFCC)、线性预测系数LPC和非线性梅尔频域参数(NFD_Mel);所述的梅尔频域倒谱系数(MFCC),是提取12维MFCC特及其一阶差分共24维,然后计算其平均值。所述的线性预测系数LPC,是提取12维LPC,并计算其平均值;所述的非线性梅尔频域参数(NFD_Mel),具体的计算步骤为:S2-1.首先对分帧后的每帧信号做短时傅里叶变换,然后加入Teager能量算子,并取频谱幅度做2次方得到能量谱;S2-2.将S2-1中求得的能量谱输入Mel频率滤波器组中,并求出每个滤波器输出的对数能量;S2-3.将S2-2中取得的对数能量经离散余弦变换得到静态的12阶NFD_Mel参数;S2-4.将S2-3中的NFD_Mel系数进行一阶差分,得到动态的12阶NFD_Mel参数;S2-5.将S2-3与S2-4中的参数结果组合到一起,最终形成24阶的NFD_Mel参数。步骤S3中,所述的对语音信号进行倒谱域分离与重构,采用256点帧长,帧移128,如图1所示,具体是:S3-1.取S1分帧后的每帧信号x(n)计算复倒谱,每帧语音信号x(n)是由声门脉冲激励e(n)经声道响应v(n)滤波而得到,即对x(n)进行Z变换将卷积信号变为乘积信号,然后取对数运算将乘积信号变为加性信号,最后对加性信号取Z反变换,即可得到复倒谱;S3-2.取S1分帧后的每帧信号x(n)计算倒谱信号,我们对x(n)进行Z变换后,计算取其实部做对数运算,最后做Z反变换即可得到倒谱;S3-3.人声的基音周期范围在50hz~700hz,在此范围的倒谱中寻找激励源冲激的最大值,若最大值冲激幅度超过0.08则记录下峰值点A的位置并判断为浊音,否则为清音并跳过该帧;S3-4.倒谱由于计算时失去了信号的相位信息,当判断为浊音时,在复倒谱上对信号进行分离操作,在复倒谱上以A点为分界点将信号分为声道响应与声门激励,为了保留全部声门信息的同时,逐步包含声道信息,将A点沿向原点移动,移动距离记为L,L=b*A,移动后的端点记为A1,其中b为可调节参数,0≤b≤1;S3-4.根据复倒谱的对称性,在A1点的对称点取到原点信号,并把对称的两段信号合并设为(n),对(n)做复倒谱逆变换,即可重构回时域信号x1(n),经过重构后的语音信号x1(n)只包含部分声道信息和全部的声门信息。步骤S4中,对重构后的语音信号进行特征提取,采用256点帧长,帧移128,具体包括如下步骤:S4-1-1.取x1(n)语音信号做短时傅里叶变换,求出频谱,并取频谱幅度做2次方得到能量谱;S4-1-2.将S4-1-1中求得的能量谱输入Mel频率滤波器组中,并求出每个滤波器输出的对数能量;S4-1-3.将S4-1-2中取得的对数能量经离散余弦变换得到静态的12阶CSS-MFCC参数;S4-1-4.将S4-1-3中的CSS-MFCC系数进行一阶差分,得到动态的12阶CSS-MFCC参数;S4-1-5.将S4-1-3与S4-1-4中的参数结果组合到一起,最终形成24阶的MFCC参数,取24阶的CSS-MFCC均值作为全局特征;S4-2-1.取x1(n)做短时傅里叶变换,通过公式对信号加入teager能量算子,并取频谱幅度做2次方得到能量谱,teager能量算子为:ψ(x(n))=x2(n)-x(n-1)x(n+1);S4-2-2.将S4-2-1中求得的能量谱输入Mel频率滤波器组中,并求出每个滤波器输出的对数能量;S4-2-3.将S4-2-2中取得的对数能量经离散余弦变换得到静态的12阶CSS-NFDMel参数;S4-2-4.将S4-2-3中的CSS-NFDMel系数进行一阶差分,得到动态的12阶CSS-NFDMel参数;S4-2-5.将S4-2-3与S4-2-4中的参数结果组合到一起,最终形成24阶的NFD_Mel参数,采用了24阶的CSS-NFDMel均值作为全局特征。步骤S5中,将经过步骤S4后的重构后的情感语音库分成65%的训练集和35%的测试集,训练集采用SVM分类器进行训练后,将测试集输入训练后的训练集中,进行语音识别后,输出判决结果,具体是:S5-1.将对情感语音库提取的特征:基音频率的均值、短时能量均值、过零率变化率、频率微扰熵、振幅微扰熵、Hurst指数、梅尔频域倒谱系数(MFCC)、线性预测系数LPC、非线性梅尔频域参数(NFD_Mel)、倒谱分离信号非线性梅尔频域CSS-NFDMel进行特征组合;S5-2.将S5-1的特征中的65%作为训练集用SVM分类器进行训练,剩下35%作为测试集用于测试训练集的分类器性能,将测试集输入训练后的训练集中,进行语音识别后,输出判决结果。选定帧移长度与参数b的取值,进行特征组合实验,其中组合特征包含有:基频均值、过零率变化率、短时能量均值、hurst参数、频率微扰熵、振幅微扰熵、MFCC均值、NFD_Mel均值、LPC均值。本文方法分类器均采用SVM。确定步骤S3中参数b的实验:采用基频均值、过零率变化率、短时能量均值、hurst参数、频率微扰熵、振幅微扰熵、MFCC均值、NFD_Mel均值、LPC均值与不同参数b下的CSS-MFCC,利用多种特征的组合并求的在不同b参数下的识别率变换,如图2所示。根据识别率的实验,我们分析得出参数b取值为0.15至0.45之间识别率相对平稳维持在较高水平。参数b取值0.34时识别率最高为84.01%。最后为了验证该方法特征的有效性我们设计了多种特征的组合实验实验一:基频、过零率、短时能量;实验二:基频、过零率、短时能量、CSS-NFDMel;实验三:基频、过零率、短时能量、CSS-MFCC;实验四:基频均值、过零率变化率、短时能量均值、hurst参数、频率微扰熵、振幅微扰熵、MFCC均值、NFD_Mel均值、LPC均值;实验五:基频均值、过零率变化率、短时能量均值、hurst参数、频率微扰熵、振幅微扰熵、MFCC均值、NFD_Mel均值、LPC均值、CSS-NFDMel;实验六:基频均值、过零率变化率、短时能量均值、hurst参数、频率微扰熵、振幅微扰熵、MFCC均值、NFD_Mel均值、LPC均值、CSS-MFCC。表2多特征组合识别率表序号高兴中性生气悲伤恐惧无聊厌恶平均实验一33.33%46.15%35.71%38.09%56.52%51.85%86.66%49.76%实验二54.16%30.76%28.57%76.19%78.26%48.14%80%56.58%实验三58.33%76.92%61.90%85.71%69.56%29.62%86.66%66.96%实验四58.7285.0188.0380.3378.6179.7286.5779.57%实验五62.50%88.46%85.71%80.95%78.26%81.48%93.33%81.52%实验六66.66%88.46%90.47%85.71%78.26%85.18%93.33%84.01%通过表2可知,实验一与实验二、实验三的对比验证了CSS-MFCC与CSS-NFDMel为有效特征,实验四、实验五、实验六,验证了本文方法可以与多特征组合,提高识别率,最高识别率为实验六,识别率84.01%。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1