车载语音识别系统及方法与流程
本发明涉及汽车电子技术领域,特别是涉及一种车载语音识别系统及方法。
背景技术:
随着科学技术的发展,汽车电子化的程度越来越高。车载信息处理、车载导航、车载音响及娱乐、车载通信等功能都依赖车载电子系统实现。其中,车载电子系统的输入方式包括按键输入、触屏输入、语音输入等。
为实现语音输入,现有的车载电子系统一般在驾驶室设置一两个传声器,用来采集驾驶员的声音。传声器将采集到的声音转换为音频信号,由dsp(digitalsignalprocessor,数字信号处理器)对音频信号进行处理,再由soc(systemonchip,片上系统)芯片进行识别。
由于仅在驾驶室设置了传声器,现有方案无法识别后排乘客的语音指令,对于后排乘客的需求无法响应。而且,当副驾驶位置人员进行语音干扰时,现有方案无法识别驾驶员的语音指令,存在识别率低的问题。
技术实现要素:
基于此,有必要提供一种车载语音识别系统及方法,能够同时识别前排驾驶员和后排乘客的语音指令并提升语音识别准确率。
在一个实施例中,提供一种车载语音识别系统,该车载语音识别系统包括:朝向前排座椅设置的至少两个第一传声器,用于采集声音信号并将采集到的声音信号转换为第一音频信号;朝向后排座椅设置的至少两个第二传声器,用于采集声音信号并将采集到的声音信号转换为第二音频信号;音频信号处理电路,用于分别对第一音频信号和第二音频信号进行音频处理;语音识别电路,用于分别对处理后的第一音频信号和处理后的第二音频信号进行语音识别,生成语音控制指令。
上述车载语音识别系统,将至少四个传声器分组朝向车的前后排放置,可以在实现前排语音识别的基础上,实现后排乘客的语音识别。由于朝向前排放置了至少两个传声器,并通过音频信号处理电路和语音识别电路进行音频处理和识别,可以区分来自驾驶座和副驾驶座的声源,即使有来自副驾驶座的语音干扰,也能准确识别来自驾驶员的语音指令,提升识别率。
在其中一个实施例中,音频信号处理电路包括:降噪单元,用于分别对第一音频信号和第二音频信号进行降噪处理;语音增强单元,用于分别对降噪后的第一音频信号和降噪后的第二音频信号进行语音增强处理,生成第一增强语音信号和第二增强语音信号;
语音识别电路,包括:识别单元,用于对第一增强语音信号进行语音识别,生成第一识别信息;以及,对第二增强语音信号进行语音识别,生成第二识别信息;生成单元,用于根据第一识别信息和第二识别信息生成语音控制指令。
在其中一个实施例中,音频信号处理电路还包括:声源定位单元,用于根据第一增强语音信号和第二增强语音信号进行声源定位处理,获得至少一个位置信息;生成单元还用于根据第一识别信息、第二识别信息及至少一个位置信息生成语音控制指令。
在其中一个实施例中,车载语音识别系统还包括数字信号处理电路,用于接收车载电子系统输出的第三音频信号,并对第三音频信号进行处理,生成参考信号;音频信号处理电路还包括回声消除单元,用于接收参考信号,根据参考信号分别对第一增强语音信号和第二增强语音信号进行回声消除处理,生成第一音频输出信号和第二音频输出信号;识别单元,还用于对第一音频输出信号进行语音识别,生成第三识别信息;以及,对第二音频输出信号进行语音识别,生成第四识别信息;生成单元,还用于根据第三识别信息、第四识别信息及至少一个位置信息生成语音控制指令。
在其中一个实施例中,音频信号处理电路为数字信号处理芯片;语音识别电路为片上系统芯片。
在其中一个实施例中,音频信号处理电路和语音识别电路集成在片上系统芯片上。
一种车载语音识别方法,应用于任一实施例的车载语音识别系统,车载语音识别系统包括朝向前排座椅设置的至少两个第一传声器,以及朝向后排座椅设置的至少两个第二传声器;车载语音识别方法包括:将至少两个第一传声器采集的声音信号转换为第一音频信号,并将至少两个第二传声器采集的声音信号转换为第二音频信号;分别对第一音频信号和第二音频信号进行音频处理;分别对处理后的第一音频信号和处理后的第二音频信号进行语音识别,生成语音控制指令。
在其中一个实施例中,分别对第一音频信号和第二音频信号进行音频处理,包括:分别对第一音频信号和第二音频信号进行降噪处理;分别对降噪后的第一音频信号和降噪后的第二音频信号进行语音增强处理,生成第一增强语音信号和第二增强语音信号;
分别对处理后的第一音频信号和处理后的第二音频信号进行语音识别,生成语音控制指令,包括:对第一增强语音信号进行语音识别,生成第一识别信息;对第二增强语音信号进行语音识别,生成第二识别信息;以及,根据第一识别信息和第二识别信息生成语音控制指令。
在其中一个实施例中,分别对第一音频信号和第二音频信号进行音频处理,还包括:根据第一增强语音信号和第二增强语音信号进行声源定位处理,获得至少一个位置信息;
根据第一识别信息和第二识别信息生成语音控制指令,包括:根据第一识别信息、第二识别信息及至少一个位置信息生成语音控制指令。
在其中一个实施例中,述车载语音识别方法还包括:接收车载电子系统输出的第三音频信号,并对第三音频信号进行音频处理,生成参考信号;
分别对第一音频信号和第二音频信号进行音频处理,还包括:根据参考信号分别对第一增强语音信号和第二增强语音信号进行回声消除处理,生成第一音频输出信号和第二音频输出信号;
分别对处理后的第一音频信号和处理后的第二音频信号进行语音识别,生成语音控制指令,包括:对第一音频输出信号进行语音识别,生成第三识别信息;对第二音频输出信号进行语音识别,生成第四识别信息;以及,根据第三识别信息、第四识别信息及至少一个位置信息生成语音控制指令。
附图说明
图1为本发明一实施例的车载语音识别系统的结构示意图;
图2为本发明另一实施例的车载语音识别系统的结构示意图;
图3为本发明又一实施例的车载语音识别系统的结构示意图;
图4为本发明一实施例的车载语音识别方法的流程示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但是本发明能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似改进,因此本发明不受下面公开的具体实施例的限制。
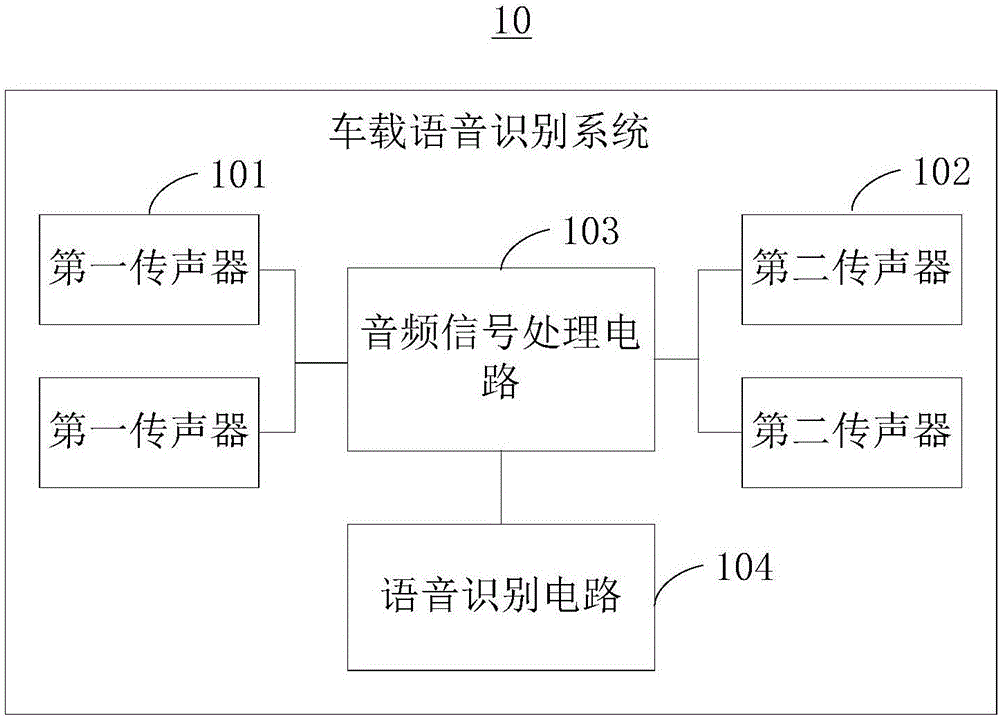
请参阅图1,为本发明一实施例的车载语音识别系统10的结构示意图。如图1所示,车载语音识别系统10包括至少两个第一传声器101、至少两个第二传声器102、音频信号处理电路103和语音识别电路104。
其中,至少两个第一传声器101朝向前排座椅设置,用于采集声音信号并将采集到的声音信号转换为第一音频信号。例如,至少一个第一传声器101朝向驾驶座设置,至少一个第一传声器101朝向副驾驶座设置。又如,至少一个第一传声器设置于仪表盘、中控盘、显示屏周围或朝向驾驶座的空调口旁。至少一个第一传声器设置于朝向副驾驶的空调口旁。
至少两个第二传声器102朝向后排座椅设置,用于采集声音信号并将采集到的声音信号转换为第二音频信号。
作为一种实施方式,至少两个第一传声器101和至少两个第二传声器102呈矩阵分布。
可选地,至少两个第一传声器101输出的第一音频信号可以为模拟信号,也可以为数字信号。至少两个第二传声器102输出的第二音频信号可以为模拟信号,也可以为数字信号。
音频信号处理电路103分别与上述至少两个第一传声器101和上述至少两个第二传声器102连接,用于分别对第一音频信号和第二音频信号进行音频处理。
其中,音频信号处理电路103包括模拟信号输入接口或数字信号输入接口。在一个实施例中,第一音频信号和第二音频信号为模拟信号,则音频信号处理电路103通过模拟信号输入接口接收第一音频信号和第二音频信号,并对第一音频信号和第二音频信号进行模数转换、降噪、语音增强等处理。
在一个实施例中,第一音频信号和第二音频信号为数字信号,则音频信号处理电路103通过数字信号输入接口接收第一音频信号和第二音频信号,并对第一音频信号和第二音频信号进行降噪、语音增强等处理。
语音识别电路104与音频信号处理电路103连接,用于分别对处理后的第一音频信号和处理后的第二音频信号进行语音识别,生成语音控制指令。
其中,语音识别电路104通过数字信号输入接口接收处理后的第一音频信号和处理后的第二音频信号,分别将处理后的第一音频信号和处理后的第二音频信号与本地或云端的语音库进行对比,识别出第一音频信号和第二音频信号对应的文字内容,并根据文字内容生成语音控制指令。
可选地,根据第一音频信号和第二音频信号对应的文字内容,可识别出一条或多条语音控制指令。
上述车载语音识别系统,将至少四个传声器分组朝向车的前后排放置,可以在实现前排语音识别的基础上,实现后排乘客的语音识别。由于朝向前排放置了至少两个传声器,并通过音频信号处理电路和语音识别电路进行音频处理和识别,可以区分来自驾驶座和副驾驶座的声源,即使有来自副驾驶座的语音干扰,也能准确识别来自驾驶员的语音指令,提升识别率。
在一个实施例中,如图2所示,音频信号处理电路103包括降噪单元1031和语音增强单元1032,语音识别电路104包括识别单元1041和生成单元1042。
其中,降噪单元1031用于分别对第一音频信号和第二音频信号进行降噪处理;语音增强单元1032用于分别对降噪后的第一音频信号和降噪后的第二音频信号进行语音增强处理,生成第一增强语音信号和第二增强语音信号;识别单元1041用于对第一增强语音信号进行语音识别,生成第一识别信息;以及,对第二增强语音信号进行语音识别,生成第二识别信息;生成单元1042用于根据第一识别信息和第二识别信息生成语音控制指令。
本实施例中,通过降噪处理和语音增强处理,能够过滤第一音频信号和第二音频信号中的噪声,增强有效的语音内容,提升对语音识别率。
在一个实施例中,如图3所示,音频信号处理电路103还包括声源定位单元1033,声源定位单元1033用于根据第一增强语音信号和第二增强语音信号进行声源定位处理,获得至少一个位置信息;生成单元1042还用于根据第一识别信息、第二识别信息及至少一个位置信息生成语音控制指令。
作为一种实施方式,声源定位单元1033分别对第一增强语音信号和第二增强语音信号进行空时采样,计算每帧语音信号的能量,并进行vad(语音活动侦测)检测,进而通过srp-phat(延时累加可控响应功率-相位变换)算法计算声源方向,获得至少一个位置信息。
本实施例中,前排或者后排多个传声器的放置可以在水平空间上具备180度范围划分,通过声源定位处理,区分来自前排、后排、驾驶座或副驾驶座的声音,可以实现人员方位的跟踪,进而能够根据识别出的语音内容和声音来源,分别根据来自前排、后排、驾驶座或副驾驶座的语音内容,生成相应的语音控制指令。还能确定一定空间范围内无效的语音,消除语音干扰源,提升语音识别效率。
在一个实施例中,如图3所示,车载语音识别系统10还包括数字信号处理电路105,数字信号处理电路105用于接收车载电子系统输出的第三音频信号,并对第三音频信号进行处理,生成参考信号;上述音频信号处理电路103还包括回声消除单元1034,回声消除单元1034用于接收参考信号,根据参考信号分别对第一增强语音信号和第二增强语音信号进行回声消除处理,生成第一音频输出信号和第二音频输出信号;识别单元1041还用于对第一音频输出信号进行语音识别,生成第三识别信息;以及,对第二音频输出信号进行语音识别,生成第四识别信息;上述生成单元1042还用于根据第三识别信息、第四识别信息及至少一个位置信息生成语音控制指令。
本实施例中,数字信号处理电路105接收来自车载电子系统的第三音频信号,其中车载电子系统包括但不限于车载音响系统、车载导航系统、车载信息娱乐系统等。数字信号处理电路105对第三音频信号进行降噪、语音增强等音频处理,将处理后的第三音频信号作为参考信号发送至音频信号处理电路103。回声消除单元1034根据参考信号,对第一增强语音信号和第二增强语音信号进行回声消除处理,即消除第一增强语音和第二增强语音中包含的来自车载电子系统的音频信号,得到第一音频输出信号和第二音频输出信号。这样,语音识别单元1041对第一音频输出信号和第二音频输出信号进行语音识别时,能避免车载电子系统自身输出的音频信号对用户语音识别的干扰,从而提升识别率。例如,本实施例采集车载导航娱乐系统的音乐输出信号作为参考,通过软件采用回音消除算法,可以实现在播放音乐的情况下,实现有效的语音识别。
在一个实施例中,音频信号处理电路103为dsp芯片;语音识别电路104为soc芯片。若至少两个第一传声器101或至少两个第二传声器102输出的第一音频信号或第二音频信号为模拟信号,则音频信号处理电路103还包括模数转换单元,用于将第一音频信号或第二音频信号转换为数字信号,以便于对第一音频信号和第二音频信号进行降噪、语音增强、声源定位、回声消除等处理。
在一个实施例中,音频信号处理电路103和语音识别电路104集成在soc芯片上。此时,若至少两个第一传声器101或至少两个第二传声器102输出的第一音频信号或第二音频信号为模拟信号,则车载语音识别系统10还包括模数转换电路,该模数转换电路的输入端与至少两个第一传声器101及至少两个第二传声器102连接,该模数转换电路的输出端与soc芯片连接。模数转换电路用于将第一音频信号或第二音频信号转换为数字信号,并将数字化的第一音频信号和数字化的第二音频信号输出至soc芯片。可选地,模数转换电路可采用模数转换器或codec芯片。
上述车载语音识别系统,将至少四个传声器分组朝向车的前后排放置,可以在实现前排语音识别的基础上,实现后排乘客的语音识别。由于朝向前排放置了至少两个传声器,并通过音频信号处理电路和语音识别电路进行音频处理和识别,可以区分来自驾驶座和副驾驶座的声源,即使有来自副驾驶座的语音干扰,也能准确识别来自驾驶员的语音指令,提升识别率。
在一个实施例中,提供一种车载语音识别方法,该车载语音识别方法应用于上述任一实施例的车载语音识别系统。车载语音识别系统包括朝向前排座椅设置的至少两个第一传声器,以及朝向后排座椅设置的至少两个第二传声器。如图4所示,车载语音识别方法包括如下步骤:
s401,将至少两个第一传声器采集的声音信号转换为第一音频信号,并将至少两个第二传声器采集的声音信号转换为第二音频信号。
s402,分别对第一音频信号和第二音频信号进行音频处理。
s403,分别对处理后的第一音频信号和处理后的第二音频信号进行语音识别,生成语音控制指令。
本实施例中,将至少四个传声器分组朝向车的前后排放置,可以在实现前排语音识别的基础上,实现后排乘客的语音识别。由于朝向前排放置了至少两个传声器,并通过音频信号处理电路和语音识别电路进行音频处理和识别,可以区分来自驾驶座和副驾驶座的声源,即使有来自副驾驶座的语音干扰,也能准确识别来自驾驶员的语音指令,提升识别率。
在一个实施例中,步骤s402包括如下步骤:分别对第一音频信号和第二音频信号进行降噪处理;分别对降噪后的第一音频信号和降噪后的第二音频信号进行语音增强处理,生成第一增强语音信号和第二增强语音信号。步骤s403包括如下步骤:对第一增强语音信号进行语音识别,生成第一识别信息;对第二增强语音信号进行语音识别,生成第二识别信息;以及,根据第一识别信息和第二识别信息生成语音控制指令。
本实施例中,通过降噪处理和语音增强处理,能够过滤第一音频信号和第二音频信号中的噪声,增强有效的语音内容,提升对语音识别率。
在一个实施例中,分别对第一音频信号和第二音频信号进行音频处理,还包括如下步骤:根据第一增强语音信号和第二增强语音信号进行声源定位处理,获得至少一个位置信息。根据第一识别信息和第二识别信息生成语音控制指令,包括如下步骤:根据第一识别信息、第二识别信息及至少一个位置信息生成语音控制指令。
本实施例中,前排或者后排多个传声器的放置可以在水平空间上具备180度范围划分,通过声源定位处理,区分来自前排、后排、驾驶座或副驾驶座的声音,可以实现人员方位的跟踪,进而能够根据识别出的语音内容和声音来源,分别根据来自前排、后排、驾驶座或副驾驶座的语音内容,生成相应的语音控制指令。还能确定一定空间范围内无效的语音,消除语音干扰源,提升语音识别效率。
在一个实施例中,车载语音识别方法还包括:接收车载电子系统输出的第三音频信号,并对第三音频信号进行音频处理,生成参考信号。步骤s402还包括:根据参考信号分别对第一增强语音信号和第二增强语音信号进行回声消除处理,生成第一音频输出信号和第二音频输出信号。步骤s403包括:对第一音频输出信号进行语音识别,生成第三识别信息;对第二音频输出信号进行语音识别,生成第四识别信息;以及,根据第三识别信息、第四识别信息及至少一个位置信息生成语音控制指令。
本实施例能避免车载电子系统自身输出的音频信号对用户语音识别的干扰,从而提升识别率。例如,本实施例采集车载导航娱乐系统的音乐输出信号作为参考,通过软件采用回音消除算法,可以实现在播放音乐的情况下,实现有效的语音识别。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
以上实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!