个人通信中降噪和回波消除时的噪声估计的制作方法
本申请涉及音频处理,尤其涉及语音增强,特别是提高嘈杂环境中目标语音信号的信号质量。本发明涉及嵌入在从存在于包括一个或多个目标声源和多个不受欢迎的噪声源的声环境中的多个传声器获得的多通道音频信号中的噪声的传声器间谱相关矩阵的估计。
本发明例如可用于获得谱信噪比估计量并形成将应用于波束形成器输出信号以获得增强信号的谱权重,其中保留目标语音内容及噪声分量得以大大减小。
谱权重例如可用于进一步减小已从回波消除系统的初始级逸出的残留回波信号。
本发明例如可用在下述应用中:耳机、助听器、有源耳朵保护系统、移动电话、远程会议系统、卡拉ok系统、广播系统、移动通信装置、免提通信装置、话音控制系统、汽车音频系统、导航系统、音频捕获、摄像机、和视频电话。
背景技术:
背景噪声、回响和回波信号为个人通信系统中及包括有声命令的自动识别的系统中所出现问题的典型原因。背景噪声和房间回响可严重降低声音质量及所需要语音信号的可懂度。在声音识别系统中,背景噪声和回响增大出错率。另外,在一些通信系统中,扬声器系统将已知的音频信号传到环境,其由传声器阵列拾取。例如,对于声控电视机,当捕获声音命令时,可能希望无视传到扬声器的电视伴音信号的回波。类似地,在电话/有声通信设置中,远端语音信号传给一个或多个本地扬声器,这产生由本地传声器拾取为不想要的回波的音频信号。该回波应在近端语音信号传给远端之前消除。类似地,声控系统受益于回波分量的消除。
解决背景噪声的常规方法包括波束形成和单通道降噪。波束形成使能通过采用空间滤波器即信号增益取决于声音相对于传声器阵列的空间方向的滤波器来区分声源。多传声器增强方法可看作波束形成器算法和单通道降噪算法的结合;因此,除由独立的单通道系统提供的时频滤波之外,多传声器方法还可执行空间滤波。
常规的回波消除方法基于自适应估计从每一扬声器信号到每一传声器信号的传递函数并从传声器信号减去回波估计量。然而,回波信号的某些分量不能通过这样的方法得以足够衰减,尤其在具有长回响时间的房间中更是如此。与延迟回响相关联的回波信号部分通常与环境噪声类似,因为两个声场实际上通常均为弥散场。这是多传声器谱降噪系统也可用于消除回波信号的残留回响部分的主要原因。
用于语音增强的多通道维纳滤波器(mwf)(例如参见参考文献[3]chapter3.2)在目标信号的均方误差意义上为最佳的线性估计器,假定传声器信号由具有附加无关联噪声的目标信号组成。mwf可分解为最小方差无失真响应(mvdr)波束形成器和单通道维纳后滤波器的结合。在这两个系统理论上一样的同时,分解后的系统在实践中对mwf滤波器的强力实施是有利的。具体地,可利用空间信号统计量(需要进行估计以实施mvdr波束形成器)在不同于信号统计量(需要进行估计以实施后滤波器)的速率下(通常更慢)随时间变化。
大多数后滤波器依赖于进入后滤波器的噪声和不想要的回响信号的功率谱密度(psd)的估计。将多传声器降噪系统考虑为波束形成器和后滤波器的结合,显然可使用众所周知的单通道噪声追踪算法(例如参见参考文献[4]sectionii,eq.(1)-(3))从波束形成器的输出信号直接估计噪声psd。然而,总的来说,当估计进入后滤波器的噪声的psd时,通过利用具有多个可用传声器信号的情形可获得更好的性能。
使用多个传声器信号用于估计进入后滤波器的噪声的psd的想法并非新想法。在参考文献[10](图1)中,zelinski使用多个传声器信号估计在传声器处观察到的噪声psd,假定噪声序列在传声器之间无关联,即传声器间噪声协方差矩阵为对角矩阵。mccowan(参考文献[11],图1)和lefkimmiatis(参考文献[12],图1)用噪声场的弥散(同质、迷向)模型代替该通常不切实际的模型。最近,wolff(参考文献[9],图1)在广义旁瓣消除器(gsc)结构中考虑波束形成器,并使用阻塞矩阵的输出,与话音活动检测(vad)算法结合,以计算进入后滤波器的噪声的psd的估计量。
技术实现要素:
在此提出一种估计时变和随频率而变的传声器间噪声协方差矩阵的方法和相应装置,与先前公开的方法和装置不同,其在最大似然意义上最佳。
在所描述的实施例中,噪声协方差矩阵可用于降噪、语音增强及残留回波信号的衰减,或用于提高话音控制系统中的识别率。本发明的优点在于噪声得以准确估计,这可导致增强后的音频信号中声音质量的提高,或可提高自动话音控制系统的识别率。
在实施例中,谱关联矩阵可用于估计波束形成器输出处的噪声级,其对多通道音频信号如从两个以上传声器的阵列获得的信号起作用。该噪声估计量可用于估计波束形成器输出处的信噪比,其可用于计算将应用于波束形成器输出的后滤波的随频率而变的增益权重。在描述的另一实施例中,对多通道音频信号起作用的波束形成器输出处的、估计的噪声级连同波束形成器输出信号一起用于自动话音命令识别。
用于噪声功率估计的最大似然方法的推导
在下面部分,导出噪声功率推算式。使对第m个传声器起作用的嘈杂信号由下式给出:
ym(n)=xm(n)+vm(n),m=1…m
其中,ym(n)、xm(n)和vm(n)分别表示嘈杂目标信号、纯净目标信号和噪声信号的信号样本,m为可用传声器信号的数量,及其中为方便起见,已忽略模数转换并简单地使用离散时间指数n。为数学上方便,假定观察数据为零平均值高斯随机过程的实现,及噪声过程统计上独立于目标过程。
每一传声器信号可通过离散傅里叶变换(dft)滤波器组,导致复dft系数
其中l和k分别表示帧和频率窗口(bin)指数,q为帧长度,d为滤波器组抽取因子,wa(n)为分析窗口函数,及
采用标准假设,即dft系数跨帧和频率指数不相关联,这使能独立地处理每一dft系数。因此,在不丧失一般性的情形下,对于给定频率指数k,可按向量
类似的等式描述目标向量
将目标信号建模为作用在阵列上的点源。使d(l,k)=[d1(l,k)…dm(l,k)]t表示(复值)传播向量,其元素dm表示相应的、在频率指数k时估计的、从该源到第m个传声器的声传递函数。则x(l,k)可写为x(l,k)=x(l,k)d(l,k),其中x(l,k)为在所涉及频率指数时具有帧指数l的纯净目标dft系数。
现在,嘈杂信号y(l,k)的关联矩阵φyy(l,k)定义为平均e[y(l,k)yh(l,k)],其中上标h表示厄米转置(共轭转置)。通过假定目标和噪声独立,φyy(l,k)可写为噪声和目标协方差矩阵φxx(l,k)及φvv(l,k)的和,即
φyy(l,k)=φxx(l,k)+φvv(l,k)
=φxx(l,k)d(l,k)dh(l,k)+e[v(l,k)vh(l,k)],
其中φxx(l,k)=e[|x(l,k)|2]为目标信号的功率。
最后,假定下面的模型用于显现跨时间的噪声协方差矩阵:
φvv(l,k)=c2(l,k)φvv(l0,k),l>l0(等式1)
其中c2(l,k)为时变实值换算因子,及φvv(l0,k)为估计为跨最近帧指数的平均值的噪声协方差矩阵,其中不存在目标并在最近的帧指数l0结束。因此,但存在语音时,上面的等式表示φvv(l,k)的演变;噪声过程不需要静态,但协方差结构必须保持固定直到标量乘法为止。
因此,该模型可看作从早期单通道降噪系统获知的方法的放宽,其中在最近仅存在噪声的区域估计的噪声功率在存在语音时假定跨时间保持恒定不变。
该部分的目标在于导出噪声协方差矩阵的估计量,φvv(l,k)=c2(l,k)φvv(l0,k),l>l0,即当存在语音时。总的想法是基于一组线性独立的目标消除波束形成器的输出进行,有时在gsc术语中称为阻塞矩阵,参见参考文献[5](图4),同样参见参考文献[6](第5.9章及其中引用的文献)。
考虑任何满秩矩阵
bh(l,k)d(l,k)=0
显然,存在许多这样的矩阵。假定d(l,k)已知并归一化到单位长度,及使h(l,k)=im-d(l,k)dh(l,k),其中im为m维单位矩阵。则可验证一个这样的矩阵b(l,k)由矩阵h的前n列给出,即
h(l,k)=[b(l,k)hn+1(l,k)…hm(l,k)](等式2)
其中hn简单地为h中的第n列。
矩阵b的每一列可看作一目标消除波束形成器,因为,当应用于嘈杂输入向量y(l,k)时,输出
z(l,k)=bh(l,k)y(l,k)=bh(l,k)v(l,k)(等式3)
从上面的等式看出,z(l,k)的协方差矩阵由下式给出:
φzz(l,k)≡e[z(l,k)zh(l,k)]=bh(l,k)φvv(l,k)b(l,k),l>l0(等式4)
将等式1插入等式4,得到
φzz(l,k)=c2(l,k)bh(l,k)φvv(l0,k)b(l,k),l>l0(等式5)
对于复滤波器组,从高斯假定得出,向量z(l,k)遵循零平均值(复、圆形对称)高斯分布,即
其中,|·|表示矩阵行列式。当φvv可逆时,矩阵φzz可逆(参见等式5),通常均是这样。
因此,似然函数
使
注意,等式6表示了估计换算因子
进一步应注意,
保持正定,只要在不存在目标的情形下在最近时间帧获得的噪声协方差估计量
最后,使
在等效方式中,波束形成器输出中噪声功率的估计量由下式给出
其中φvv0(l,k)为波束形成器输出噪声的初始估计量,其可估计为波束形成器输出功率|yw(l,k)|2跨最近帧指数的平均值,其中目标不存在并在最近帧指数l0结束。这可从波束形成器输出信号明确地进行,或经等式8中所示的估计的噪声协方差矩阵。
在实施例中,该噪声功率估计量可用于推导后滤波器增益值。通过将波束形成器输出信号的量值与噪声功率比较,可导出信噪比,其可用于计算增益值。在对波束形成器输出信号采用话音识别的其它实施例中,话音识别可受益于同时基于波束形成信号和噪声psd估计量。实施例
因此,结合从传声器阵列接收的声信号的波束形成和自适应后滤波的音频信号处理方法可包括下面的部分或所有步骤:
在子频带中接收m个通信信号,其中m至少为2;
在每一子频带中,用m行及n列线性独立列的阻塞矩阵处理相应的m个子频带通信信号,其中n>=1及n<m,以获得n个目标消除的信号(203,303,403);
在每一子频带中,用一组波束形成器系数处理相应的m个子频带通信信号和n个目标消除的信号以获得波束形成器输出信号(204,304,404);
用目标不存在检测器处理m个通信信号以获得每一子频带中的目标不存在信号(309);
使用目标不存在信号以获得每一子频带中的n阶、目标消除的协方差矩阵的逆矩阵(310,410);
以二次齐式使用目标消除的协方差矩阵的逆矩阵处理每一子频带中的n个目标消除的信号以产生每一子频带中的实值噪声校正因子(312,412);
使用目标不存在信号获得每一子频带中跨目标不存在的最近帧求平均的波束形成器输出信号中噪声功率的初始估计量(311,411);
使初始噪声估计量与噪声校正因子相乘以获得每一子频带中波束形成器输出噪声信号分量的功率的精确估计量(417);
用波束形成器输出的量值处理波束形成器输出噪声信号分量的功率的精确估计量以获得每一子频带中的后滤波器增益值;
用后滤波器增益值处理波束形成器输出信号以获得每一子频带中的后滤波器输出信号(206,306,406);
通过合成滤波器组处理后滤波器输出子频带信号以获得增强的波束形成的输出信号,其中目标信号通过衰减噪声信号分量而得以增强(207,307,407)。
其优点在于后滤波器增益值从波束形成器输出的噪声分量的功率的准确估计量导出。这得以实现,是因为噪声功率从n个目标消除的信号的结合导出,每一目标消除的信号从独立的空间滤波器获得(即阻塞矩阵),其消除了想要的目标信号因而受之影响非常小。这使能即使在存在目标信号的情形下也可估计噪声级。
通过使用具有矩阵系数的二次齐式,其中这些系数推导为n个阻塞矩阵信号的关联矩阵的逆矩阵,估计量在最大似然意义上变得最佳。先前使用空间滤波器估计波束形成器输出噪声的方法(参考文献[1](图2,模块15)、[2](图2)、[7](图2)、[10](图1)、[11](图1)、[12](图1))没有这种性质,因而不太准确。
常规的回波消除方法包括自适应估计从每一扬声器信号到每一传声器信号的传递函数,及从每一检测到的传声器信号减去预测的扬声器信号。由于回波信号的某些分量在实践中可能不能足够地衰减,尤其在长房间脉冲响应时,所公开的方法是有利的,因为与延迟回响相关联的残留回波信号被估计为环境噪声,及在实施例中,其随后通过自适应后滤波器衰减。
在其它实施例中,延迟回响信号和噪声得以准确地估计是有利的,因为这使能增加自适应波束形成的信号正通过其的话音控制系统的识别速率,及估计所述信号中噪声的psd。
在实施例中,目标增强波束形成器为借助于gsc结构(参见参考文献[3],5.2章,图5.1)实施的mvdr波束形成器(参考文献[3],2.3章,等式2.25)。所提出的方法是有利的,因为其与按gsc形式实施的mvdr波束形成器共享许多同样的计算步骤。这可通过考虑mvdr波束形成器认识到,其可通过等式
应当强调的是,在本发明中,算子e[·]以“平均”的含义使用,这意味着其或解释为统计预期值,或解释为一批样本的经验平均值,或解释为最近样本的低通滤波。常见的求平均公式是使用对应于z变换h(z)=λ/(1-(1-λ)z-1)的一阶iir低通滤波器,其中λ为满足0≤λ(l)≤1的参数,定义求平均过程的时间常数τ(l);其中时间常数τ(l)和λ(l)之间的关系可计算为
φzz(l,k)=(z(l,k)zh(l,k)-φzz(l-1,k))λ(l,k)+φzz(l-1,k)
(等式9)
在实施例中,系数λ(l,k)被使得随时间变化,以能够控制平均值应跨哪些时间帧场合进行计算或应用各个时间帧场合的什么权重进行计算。优选地,求平均跨目标不存在的帧进行,由每一子频带中的目标不存在信号t(l,k)指示。在实施例中,当目标不存在时,信号t(l,k)达到值1;否则,为接近或等于0的预定值ε,及系数λ(l,k)通过关系λ(l,k)=t(l,k)λ0(k)而被使得与目标不存在有关,其中λ0(k)反映每一子频带的预定求平均时间常数。在另一实施例中,信号t(l,k)从vad(话音活动检测器)的输出导出。
由于目标增强波束形成器系数的mvdr系数计算和噪声估计方法均受益于跨受控于干扰信号如噪声信号、传声器噪声及残留回波信号的帧的求平均,每一子频带中的n阶逆矩阵
在一些通信情形下,目标信号的声入射方向未预先确定。在实施例中,在这样的声设置中,自适应估计阻塞矩阵是有利的。在另一实施例中,这可通过分析在目标信号存在(由例如从话音活动检测器导出的目标存在信号指示)的帧期间估计的协方差矩阵而自适应估计每一子频带中的视向量d(l,k)进行。在实施例中,前述分析借助于在目标不存在的最近帧期间估计的传声器信号的m阶协方差矩阵φvv(l0,k)和在目标存在的最近帧期间估计的传声器信号的m阶协方差矩阵φyy(lp,k)的广义特征向量分析进行,其中lp可表示目标存在的最新帧指数。前述分析可通过推导对应于广义特征值问题的最大特征值的特征向量进行,φyy(lp,k)v=λφvv(l0,k)v,其中
除非明确指出,在此所用的单数形式的含义均包括复数形式(即具有“至少一”的意思)。应当进一步理解,说明书中使用的术语“具有”、“包括”和/或“包含”表明存在所述的特征、整数、步骤、操作、元件和/或部件,但不排除存在或增加一个或多个其他特征、整数、步骤、操作、元件、部件和/或其组合。应当理解,除非明确指出,当元件被称为“连接”或“耦合”到另一元件时,可以是直接连接或耦合到其他元件,也可以存在中间插入元件。如在此所用的术语“和/或”包括一个或多个列举的相关项目的任何及所有组合。除非明确指出,在此公开的任何方法的步骤不必须精确按所公开的顺序执行。
附图说明
本发明将在下面参考附图、结合优选实施方式进行更完全地说明。
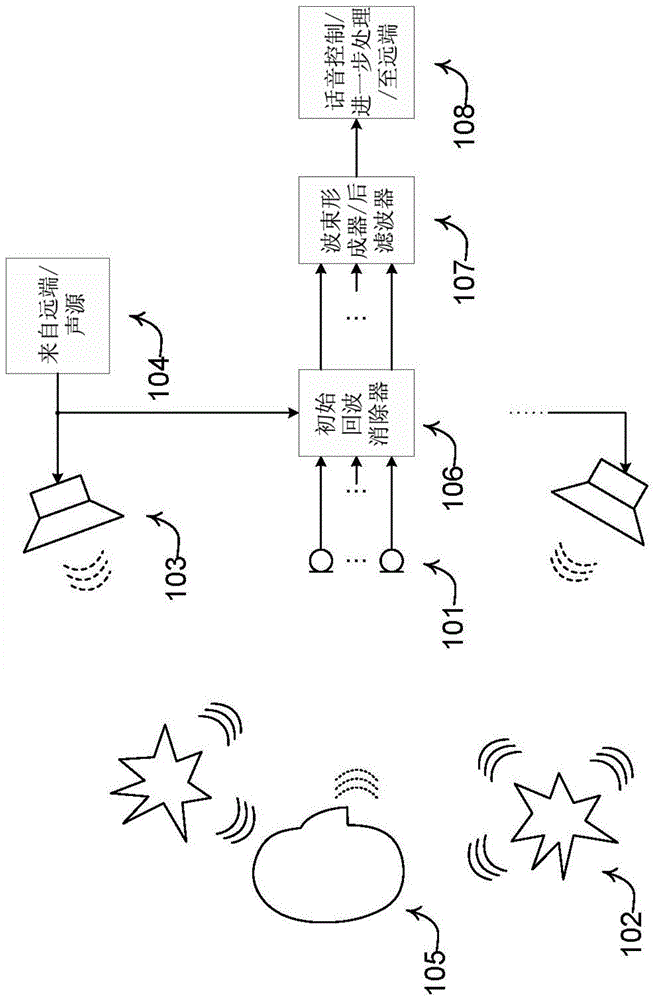
图1示出了根据本发明实施例的、个人通信或话音控制场合的用户、回波消除及降噪系统。
图2示出了根据本发明实施例的、基于噪声和残留回波功率估计的、组合的回波消除系统、波束形成器和降噪及残留回波减少系统。
图3示出了根据本发明实施例的、基于目标消除的协方差矩阵的逆矩阵的波束形成器和降噪系统,具有阻塞矩阵、目标不存在检测器及用于噪声精确估计的二次齐式。
图4示出了根据本发明实施例的、具有自适应目标方向和噪声功率估计的波束形成器和降噪系统。
图5示出了根据本发明实施例的波束形成器和降噪系统中的计算步骤。
为清晰起见,这些附图均为示意性及简化的图,它们只给出了对于理解本发明所必要的细节,而省略其他细节。在所有附图中,同样的附图标记用于同样或对应的部分。
通过下面给出的详细描述,本发明进一步的适用范围将显而易见。然而,应当理解,在详细描述和具体例子表明本发明优选实施例的同时,它们仅为说明目的给出。对于本领域的技术人员来说,从下面的详细描述可显而易见地得出其它实施方式。
具体实施方式
下面参考图示了本发明可怎样实施的附图进行描述。
图1示出了处于通信情形的用户的示意图,其可表示例如汽车中的免提电话情形、远程会议、或话音控制情形,其中装置正进行残留回波和噪声减少。用户105处于环境噪声源102中,其中一个或多个扬声器103重现例如来自远端讲话人104的声信号。扬声器还可正重现来自其它声源如无线电、音乐源、声轨、卡拉ok系统等的信号。用户可产生目标语音信号,该装置的目标是高质量地检测。m个变换器101的阵列检测声混合信号,其可能由目标语音信号、来自扬声器的回波信号、环境噪声和变换器噪声的叠加组成。传声器阵列信号和扬声器信号传到初始回波消除系统106,其自适应估计从一个或多个扬声器到一个或多个传声器的传递函数,并减去通过根据一个或多个估计的传递函数对一个或多个扬声器信号进行滤波产生的信号以获得m个初始回波消除的通信信号。这些通信信号传到波束形成器107,其实施空间滤波器以增强目标语音信号并衰减噪声和残留回波信号,及在一些实施例中还可由后滤波器107处理以借助于从信骚比的随时间-频率而变的估计量导出的随时间-频率而变的增益函数进一步减少噪声和残留回波信号,信骚比估计量从随时间-频率而变的噪声估计量导出。在话音控制情形下,增强的信号(其可以也可尚未被后滤波)传到随后的系统108进行语音识别。在远程会议系统中,增强的信号传回给远端。在其它实施例中,除增强的信号之外,随时间-频率而变的噪声功率估计量的表示也传给随后的话音识别系统。
图2示出了所公开的噪声功率估计器205可怎样嵌入在具有回波消除、波束形成和降噪的通信系统中。一个或多个音频通道中的扬声器信号可以数字形式从音频信号源211获得并通过一个或多个扬声器再现为声信号。适于匹配声回波传递函数的一组回波滤波器210对扬声器信号进行滤波以获得m个传声器中的每一个的回波信号估计量,m>1。从传声器信号减去回波信号估计量以获得m个通信信号ym(n),m=1..m,其中n为离散样本时间指数。在实施例中,分析滤波器组(未示出)处理每一扬声器信号,及在一个或多个子频带中估计声回波传递函数,及随后的在每一传声器信号处减去估计的回波信号在子频带域进行。滤波器组202产生每一通信信号的时频表示,在实施例中,其可执行为短时傅里叶变换(stft)以获得系数
图3示出了根据本发明实施例的噪声功率估计器205的进一步的细节。在该图中,框301-308对应于图2中的框201-208,及框309-312表示噪声功率估计器205的细节。目标不存在检测器309处理子频带通信信号y(l,k)以获得目标不存在指示信号t(l,k),在实施例中,其可以是从短期平均功率<|y(l,k)|2>与噪声基底功率估计量的比较导出的二元指示器,如r.martin[4](sectionii-iii),对每一子频带中的参考传声器信号起作用,使得当短期平均功率与噪声基底功率估计量的比不超出预定阈值例如8db时,假定目标不存在。在实施例中,目标消除的协方差矩阵的逆矩阵
图4示出了噪声功率估计可怎样嵌入在用于自适应波束形成和降噪的系统中,其中涉及自适应目标定向。框401、402、403、404分别对应于图2中的框201、202、203和204。噪声分析409可包含对应于309的目标不存在检测以用求平均获得目标不存在信号t(l,k),进而获得通信信号的m阶噪声协方差矩阵φvv(l,k)的估计量。在实施例中,求平均执行为递归滤波器φvv(l,k)=(y(l,k)yh(l,k)-φvv(l-1,k))λ(l,k)+φvv(l-1,k),其中λ(l,k)=t(l,k)λ0,及λ0为在实施例中可设定为对应于为0.1秒的时间常数的预定参数。目标协方差矩阵从目标分析413获得,及在实施例中可包括目标存在检测以获得目标存在信号s(l,k),其可以是vad(话音活动检测器)的形式,如果目标存在,则使得s(l,k)=1,否则为0,及在实施例中可与递归求平均过程φxx(l,k)=(y(l,k)yh(l,k)-φxx(l-1,k))s(l,k)λ0+φxx(l-1,k)一起使用以获得目标受控的帧的平均值。视向量估计量d(l,k)在414中通过分析噪声和目标协方差矩阵获得,该视向量分析在实施例中可通过使用单列矩阵差φxx(l,k)-φvv(l,k)进行。在另一实施例中,视向量通过使用对应于前述差矩阵的最大特征值的特征向量进行估计。调整后的阻塞矩阵b(l,k)在415中获得,其可基于估计的视向量根据等式2进行计算。从噪声协方差估计量和视向量,一实施例可导出一组波束形成器系数416,其可以是依据
图5示出了根据本发明实施例的降噪和波束形成方法的计算。根据本发明的实施例可通过组合多个步骤而包括在此明确或暗中描述的步骤,步骤的具体顺序并不重要。m个通道中的音频信号,其中m≥2,借助于传感器阵列501进行检测,及分析滤波器组502将信号处理为随频率而变的子频带。一组n个目标消除滤波器503,其中1≤n<m,处理音频信号以获得n个目标消除的信号。在一些实施例中,目标消除滤波器在时域进行,在其它实施例中,滤波在滤波器组提供的频域进行。目标增强波束形成器504可将m个音频信号处理为目标增强的信号。目标不存在信号检测器505提供信号供在目标不存在期间提供目标增强波束形成器输出噪声功率的初始估计量的估计器506使用。使用同样的目标不存在信号,在一个或多个子频带中获得n维目标消除的协方差,507。在一些实施例中,目标消除的协方差矩阵可通过在矩阵求逆之前在对角线上增加小值而规则化,以获得估计的、目标消除的协方差矩阵的逆矩阵,其用作目标消除的子频带信号的n阶二次齐式的系数,508。二次齐式的结果用作将与目标增强波束形成器输出噪声功率的初始估计量相乘以获得目标增强波束形成器输出噪声功率的精确噪声估计量的校正换算信号,509。精确的噪声估计量形成计算信噪比的估计量的基础,510,其在实施例中可与经典方法如ephraim&malah[13](等式48-52)一起使用以获得每一子频带中的后滤波器增益值,进而应用于目标增强波束形成器511以获得后滤波的增强目标信号。合成滤波器组512用于获得时域信号,其中目标信号得以保持,而噪声源和残留回波信号被衰减。
本发明由独立权利要求的特征限定。从属权利要求限定优选实施例。权利要求中的任何附图标记不意于限定其范围。
一些优选实施例已经在前面进行了说明,但是应当强调的是,本发明不受这些实施例的限制,而是可以权利要求限定的主题内的其它方式实现。例如,在助听器中,可能需要另外的处理步骤,例如用于听力损失补偿的步骤。
参考文献
[1]ep2026597b1,noisereductionbycombinedbeamformingandpost-filtering.
[2]uspatent8,204,263b2,methodofestimatingaweightingfunctionofaudiosignalsinahearingaid.
[3]m.brandsteinandd.ward,"microphonearrays",springer2001.
[4]r.martin,"noisepowerspectraldensityestimationbasedonoptimalsmoothingandminimumstatistics",ieeetrans.onspeechandaudioprocessing,vol.9,no.5,2001.
[5]l.j.griffithsandc.w.jim,“analternativeapproachtolinearlyconstrainedadaptivebeamforming,”ieeetrans.antennaspropagat.,vol.30,no.1,pp.27–34,january1982.
[6]s.haykin,adaptivefiltertheory,prenticehall,thirdedition,1996
[7]k.u.simmer,j.bitzer,andc.marro,“post-filteringtechniques,”inmicrophonearrays–signalprocessingtechniquesandapplications,m.brandsteinandd.ward,eds.2001,springerverlag.
[8]e.warsitz,"blindacousticbeamformingbasedongeneralizedeigenvaluedecomposition",ieeetrans.audiospeechandlanguageprocessing,vol.15,no5,2007.
[9]t.wolffandm.buck,“spatialmaximumaposterioripost-filteringforarbitrarybeamforming,”inhandsfreespeechcommunicationandmicrophonearrays(hscma),2008.
[10]r.zelinski,“amicrophonearraywithadaptivepost-filteringfornoisereductioninreverberantrooms,”inproc.ieeeinternationalconferenceonacoustics,speechandsignalprocessing,1988,vol.5,pp.2578–2581.
[11]i.a.mccowanandh.bourlard,“microphonearraypost-filterbasedonnoisefieldcoherence,”ieeetrans.speechandaudioprocessing,vol.11,no.6,pp.709–716,2003.
[12]s.lefkimmiatisandp.maragos,“optimumpost-filterestimationfornoisereductioninmultichannelspeechprocessing,”inproc.14theuropeansignalprocessingconference,2006.
[13]y.ephraimandd.malah,"speechenhancementusingaminimum-meansquareerrorshort-timespectralamplitudeestimator,"acoustics,speechandsignalprocessing,ieeetransactionson,vol.32,no.6,pp.1109-1121,dec1984.
- 还没有人留言评论。精彩留言会获得点赞!