一种低产瓜氨酸的工业酿酒酵母代谢工程菌的制作方法
本发明涉及一种低产瓜氨酸的工业酿酒酵母代谢工程菌,属于发酵和生物技术领域。
背景技术:
氨基甲酸乙酯(Ethyl Carbamate,简称EC),俗称尿烷,广泛存在于发酵食品(如腐乳、酱油等)、酿造酒(如中国黄酒、日本清酒、葡萄酒、苹果酒等)和蒸馏酒(如威士忌、白兰地等)中。随着EC在多种酒精饮品中的不断检出,以及人们对健康饮食理念的重视,EC的存在不仅是消费者的健康隐患,更是阻碍了我国黄酒国际化的步伐。因此,控制黄酒中EC的含量便显得尤为重要。
在黄酒生产过程中,发酵醪液中的酿酒酵母、乳酸菌等微生物代谢所产生的尿素和瓜氨酸是黄酒中EC前体物质的主要来源。研究表明,在相同的反应条件下,黄酒中的尿素与乙醇反应形成EC的速率约为相同浓度的瓜氨酸与乙醇反应形成EC速率的3倍。因此,在尿素和瓜氨酸含量相同的情况下,尿素是黄酒中形成EC的主要前体物质。发酵醪液中含量丰富的瓜氨酸(约20~50mg/L)也是形成EC的另一重要前体物质,其对于EC形成的贡献不容忽视。在葡萄酒中,瓜氨酸与尿素一样作为主要前体物与乙醇发生反应生成EC,在酱油中瓜氨酸对EC的形成则起主导作用,而黄酒中关于瓜氨酸作为前体物形成EC的机制尚未得出统一的结论,关于酿酒酵母瓜氨酸代谢途径对黄酒发酵液中瓜氨酸含量的影响鲜有报道。
技术实现要素:
本发明的第一个目的是提供一种低产瓜氨酸的酿酒酵母工程菌,所述酿酒酵母工程菌敲除了ARG3基因,所述ARG3基因序列如SEQ ID NO.1所示。
在本发明的一种实施方式中,所述酿酒酵母工程菌的出发菌株是Saccharomyces cerevisiae N85。
本发明的第二个目的是提供所述酿酒酵母工程菌的构建方法,所述方法包括以下步骤组成:
(1)将SEQ ID NO.2,SEQ ID NO.3和SEQ ID NO.4所示基因连接,构建ARG3基因敲除组件ARG3L-URA3-ARG3R;
(2)将所述ARG3基因敲除组件ARG3L-URA3-ARG3R分别转化至单倍体酵母。
在本发明的一种实施方式中,将步骤(2)所述的单倍体酵母进行融合,获得二倍体酵母。
在本发明的一种实施方式中,所述单倍体酵母是尿嘧啶缺陷型单倍体酵母。
在本发明的一种实施方式中,所述尿嘧啶缺陷型单倍体酵母替换为色氨酸缺陷型单倍体酵母,所述SEQ ID NO.3所示序列替换为编码恢复所述色氨酸缺陷的基因。
在本发明的一种实施方式中,所述尿嘧啶缺陷型单倍体酵母替换为亮氨酸缺陷型单倍体酵母,所述SEQ ID NO.3所示序列替换为编码恢复所述亮氨酸缺陷的基因。
在本发明的一种实施方式中,所述尿嘧啶缺陷型单倍体酵母替换为组氨酸缺陷型单倍体酵母,所述SEQ ID NO.3所示序列替换为编码恢复所述组氨酸缺陷的基因。
在本发明的一种实施方式中,所述单倍体酵母为尿嘧啶缺陷型单倍体酵母。
在本发明的一种实施方式中,所述尿嘧啶缺陷型单倍体酵母包括Saccharomyces.cerevisiaeNa-u和Saccharomyces.cerevisiaeNα-u。
在本发明的一种实施方式中,所述方法具体步骤为:
(1)ARG3基因敲除组件的构建:构建由酿酒酵母ARG3基因的上游同源臂ARG3L、下游同源臂ARG3R和URA3基因组成的基因敲除组件ARG3L-URA3-ARG3R;所述上游同源臂ARG3L序列如SEQ ID NO.2所示;所述下游同源臂ARG3R序列如SEQ ID NO.4所示;所述URA3基因序列如SEQ ID NO.3所示;
(2)将所述基因敲除组件ARG3L-URA3-ARG3R分别转化至尿嘧啶缺陷型酿酒酵母Saccharomyces.cerevisiae Na-u和Saccharomyces.cerevisiae Nα-u,并筛选阳性克隆子;
(3)将阳性转化子融合,获得二倍体酿酒酵母基因工程菌。
在本发明的一种实施方式中,所述转化采用电转化法或化学转化法。
在本发明的一种实施方式中,所述电转化条件如下:电压:1.5kV,电容:25μF,电阻:186Ω。
在本发明的一种实施方式中,所述化学转化法包括聚乙二醇法、氯化锂法。
本发明的第三个目的是提供所述酿酒酵母基因工程菌的培养方法,是将所述基因工程菌接种至YPD培养基中,30℃培养12~30h。
本发明的第四个目的是提供一种降低瓜氨酸含量的发酵方法,是将所述基因工程菌接种至培养基中,15~30℃静置发酵15~70d。
在本发明的一种实施方式中,所述方法是将所述基因工程菌接种至中米汁培养基中,先30℃发酵5~10d,再15℃静置发酵10~30d。
在本发明的一种实施方式中,所述方法是先在米汁培养基中于30℃加发酵栓恒温发酵至日失重小于0.2g,再于15℃静置发酵15d。
在本发明的一种实施方式中,所述接种前将所述基因工程菌进行活化。
在本发明的一种实施方式中,所述米汁培养基的配制方法为:向糯米中加入200mL/100g的水室温浸渍3~5d,使米浆水pH为3.8~4.1;常压蒸煮20~60min;加入3倍体积的水于糖化杯中,加入2mL/kg糯米的高温α-淀粉酶,50℃~95℃保温20~60min;冷却至60℃加入2mL/kg糯米的糖化酶,搅拌均匀,保温糖化2~5h。
在本发明的一种实施方式中,所述米汁培养基糖化后降温至50℃,加入质量比17%的麦曲和2mL/kg糯米的中性蛋白酶,搅拌均匀后保温30min。
本发明还提供所述基因工程菌在黄酒生产中的应用。
有益效果:本发明以来自于二倍体工业酿酒酵母的尿嘧啶缺陷型单倍体为改造对象,以尿嘧啶缺陷型的恢复为筛选标记,构建酿酒酵母ARG3(编码合成瓜氨酸的鸟氨酸氨甲酰转移酶)敲除组件,然后转化尿嘧啶缺陷型单倍体菌株,筛选阳性转化子,获得敲除了ARG3基因的单倍体黄酒酵母。将改造后的单倍体工程菌融合为二倍体后进行米汁发酵,结果表明,该工程菌与出发菌株在米汁发酵过程中生长和发酵性能相似,而工程菌发酵液中瓜氨酸的含量降低了39.0%,为工业化生产中降低EC含量提供了新思路。
附图说明
图1 ARG3基因敲除组件的构建示意图;
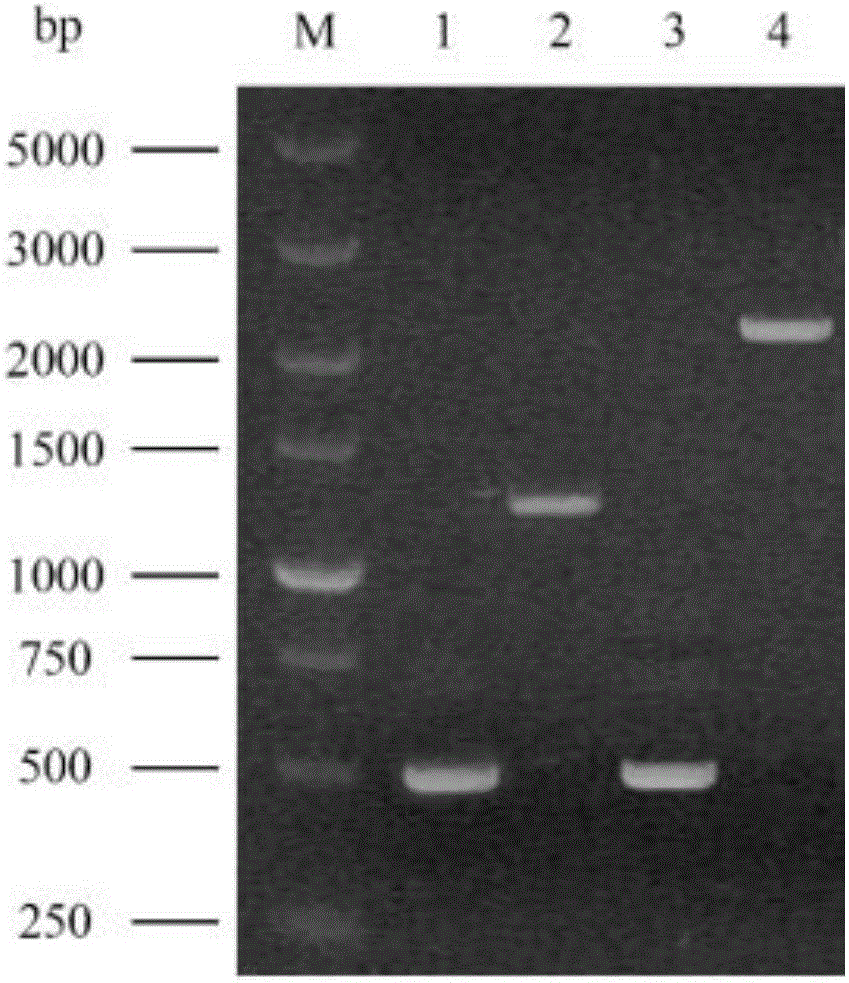
图2 ARG3基因敲除组件构建的电泳图;M,Marker DL 5000;1,ARG3L;2,URA3;泳道3,ARG3R;4,ARG3L-URA3-ARG3R;
图3酵母转化子的PCR鉴定电泳图;M,Marker DL 5000;1,a型阳性转化子(2314bp);2,α型阳性转化子(2314bp);3,阴性对照(1359bp);
图4不同酵母菌株米汁发酵过程中的CO2失重曲线。
具体实施方式
以下结合附图,并通过实施例对本发明进行具体说明。这些实施例仅用于说明本发明而不用于限制本发明的范围。
以下实施例1~实施例3所涉及实验材料如下:
菌株:实施例中所用到的二倍体酿酒酵母S.cerevisiae N85是绍兴黄酒生产常用菌株(公开于Wu DH,et al.Journal of the Institute of Brewing.2013,119(4):288-293),尿嘧啶缺陷型单倍体菌株S.cerevisiae Na-u和S.cerevisiae Nα-u(公开于Wu DH,et al.International Journal of Food Microbiology.2014,180:19-23)。
试剂与试剂盒:Prime STAR DNA Polymerase(2.5U/μL)、Ex Taq(5U/μL)、MiniBEST Universal Genomic DNA Extraction Kit、MiniBEST Agrose Gel DNA Extraction kit均购自宝生物工程(大连)有限公司。
原料:制备米汁培养基所使用的糯米、生麦曲、熟麦曲均由国家黄酒工程技术研究中心提供。
培养基:MM培养基:1.7g/LYNB(Yeast Nitrogen Base withoutAmino Acids),20g/L葡萄糖,5g/L硫酸铵,20g/L琼脂)
实施例所使用引物序列如表1所示,由生工生物工程(上海)股份有限公司合成。
表1本发明所用到的引物序列
注:下划线为用于融合PCR的重叠序列。
实施例1ARG3基因敲除组件的构建
ARG3基因敲除组件的构建如图1所示。首先,提取工业酿酒酵母N85基因组DNA(具体操作方法参见MiniBEST Universal Genomic DNA Extraction Kit试剂盒使用说明书),以该基因组DNA为模板,利用Prime STAR DNA Polymerase分别使用编号为P1/P2和P3/P4的引物对扩增ARG3基因上游同源臂(ARG3L,序列如SEQ ID NO.2所示)和下游同源臂(ARG3R,序列如SEQ ID NO.4所示),使用引物对P5/P6扩增完整的URA3基因(序列如SEQ ID NO.3所示),然后利用引物P1/P4,通过融合PCR将ARG3L、ARG3R和URA3融合获得ARG3基因敲除组件(ARG3L-URA3-ARG3R)(PCR具体操作方法及反应体系配制参见Prime STAR DNA Polymerase说明书)。
各引物对的扩增程序如下:
(1)P1/P2和P3/P4:95℃预变性4min,(98℃变性10s,52℃退火15s,72℃延伸30s)进行30个循环,72℃再延伸5min;
(2)P5/P6:95℃预变性4min,(98℃变性10s,52℃退火15s,72℃延伸80s)进行30个循环,72℃再延伸5min;
利用touchdown PCR将三个片段融合的步骤如下:
以等摩尔的ARG3L、ARG3R和URA3为模板,不加引物进行touchdown PCR将上述三个片段进行融合,PCR反应体系见表2:
表2 25μL PCR反应体系
融合PCR扩增程序如下:95℃预变性4min,然后进入PCR扩增程序,98℃变性10s,63℃退火15s,每个循环退火温度降低1℃,共15个循环,72℃延伸2min,然后55℃退火再循环一次,最后72℃再延伸5min,反应完毕,得到ARG3L、ARG3R和URA3三个扩增片段的融合片段。以得到的融合片段为模板,使用引物对P1/P4对该融合片段进行特异性扩增,PCR反应体系的配制如表3所示:
表3 25μL PCR反应体系
PCR扩增程序如下:95℃预变性4min,(94℃变性30s,50℃退火30s,72℃延伸140s)进行15个循环,72℃再延伸10min,扩增完毕,得到ARG3基因敲除组件ARG3L-URA3-ARG3R。
PCR扩增结果如图2所示。
由图2可知,利用touchdown PCR融合三个片段所得到的片段大小为2300bp左右,与预期的基因组件(ARG3L-URA3-ARG3R)大小相符,送生工生物工程(上海)股份有限公司测序结果正确,序列如SEQ ID NO.5所示,说明ARG3基因敲除组件ARG3L-URA3-ARG3R构建成功。
实施例2酿酒酵母ARG3基因的敲除
利用电转化的方法将上述获得的基因敲除组件ARG3L-URA3-ARG3R分别转化a型和α型的尿嘧啶缺陷型单倍体Na-u和Nα-u,具体步骤如下:
(1)挑取酵母单菌落接种于1mLYPD液体培养基,于30℃200r/min过夜培养,得活化种子液;
(2)按照体积比10%的接种比例,将种子液转接至50mL新鲜的YPD液体培养基,于30℃200r/min继续培养至菌液OD600在1.2~1.5之间;
(3)5000r/min离心5min收集菌体,用25mL无菌水离心洗涤菌体两次;
(4)用8mL 10mM二硫苏糖醇溶液重悬菌体,于30℃水浴振荡30min,5000r/min离心5min收集菌体;
(5)用15mL 4℃预冷的1M山梨醇溶液重悬菌体,于5000r/min 4℃离心5min收集菌体;
(6)重复步骤(5)3次;
(7)用0.5mL 1M山梨醇重悬菌体,取80μL菌液,加入10μL转化片段以及20μL 1mg/mL鲑鱼精DNA,混合后转入电击杯,冰上放置5min后,1.5kv电击;
(8)加入890μLYPD培养基将电转液洗出转移到1.5mL离心管内,于30℃150r/min复苏2h,涂布于MM固体培养基,于30℃培养至菌落长出;
(9)挑取转化子并提取基因组作为模板,使用引物对P1/P4进行PCR扩增以鉴定ARG3基因被敲除的阳性转化子。
PCR鉴定结果如图3所示。泳道1和2扩增片段大小为2300bp左右,为阳性转化子,分别为a型转化子(转化酿酒酵母Na-u中)和α型转化子(转化酿酒酵母Nα-u中);泳道3扩增片段大小为1300bp左右,为阴性对照。分别回收条带后,送生工生物工程(上海)股份有限公司测序结果正确,序列如SEQ ID NO.6所示,说明酿酒酵母的ARG3基因被成功敲除。
实施例3工业酿酒酵母工程菌发酵
将上述获得的敲除ARG3的两种配型的工程菌(a型和α型)分别接种于YPD培养基,于30℃进行活化培养,然后将两个菌液同时转接于新鲜的YPD培养基进行培养,融合后获得二倍体酿酒酵母工程菌(相当于敲除了ARG3基因的酿酒酵母N85),具体操作方法参考文献1(Wu DH,et al.International Journal of Food Microbiology.2014,180:19-23)。以未经基因工程改造的出发菌株酿酒酵母N85作为对照,与本发明构建的酿酒酵母工程菌在相同的条件下进行发酵,以考察工程菌减少瓜氨酸含量的能力,具体操作步骤如下:
(1)浸米
称取200g糯米,加400mL水室温浸渍3~5d,使米浆水pH为3.8~4.1;
(2)蒸饭
将浸好的米进行常压蒸煮,有大量蒸汽冒出后维持20min,至颗粒均匀,内无白心,熟而不粘,软而不烂;
(3)糖化
将蒸好的饭加3倍体积的水于糖化杯中,加入耐高温α-淀粉酶(2mL/kg糯米),搅拌均匀于50℃保温10min,升至92℃保温30min左右。待糖化杯冷却至60℃加糖化酶(2mL/kg糯米),搅拌均匀保温糖化4h,然后降温至50℃,加入麦曲(17%)和中性蛋白酶(2mL/kg糯米),搅拌均匀后保温30min;
(4)灭菌
用三十二折滤纸过滤后进行分装,115℃,灭菌20min;
(5)前酵
按10%的接种量将二级活化的酵母种子液接入米汁培养基,摇匀,加发酵栓于30℃进行发酵;
(6)后酵
将发酵醪置于15℃放置15d进行后酵;
(7)过滤和指标检测
使用滤纸进行过滤,参照GB/T 13662-2008中的方法进行常规理化指标的测定,发酵液中氨基酸和EC的测定分别参考文献2(Cigic I K,et al.Acta Chimica Slovenica.2008,55(3):660-664)和文献3(WuPG,et al.Food Control.2012,23(1):286-288);
酵母菌株在米汁培养基发酵过程中CO2的失重曲线见图4,发酵液理化指标的测定结果见表4,瓜氨酸、鸟氨酸和EC的含量见表5。
表4发酵液中理化指标的测定
由图4和表4可知,工程菌与出发菌株在发酵过程中CO2的失重曲线基本一致,发酵液中理化指标的含量也没有明显差异,说明工程菌的生长和发酵能力与出发菌株相似,代谢工程改造对酵母的生长和发酵性能没有影响,适用于工业化生产且不会对发酵产物风味造成不利影响。
表5发酵液中氨基酸和EC含量的比较
由表5测定结果可知,发酵结束时工程菌发酵液中瓜氨酸和EC的含量均低于出发菌株,其中瓜氨酸的含量相比于出发菌株降低了39.0%。而且,工程菌发酵液中鸟氨酸的含量(104.5mg/L)高于米汁培养基和出发菌株发酵液中鸟氨酸的含量,说明敲除了ARG3的工程菌在米汁培养基中进行纯种发酵时没有利用鸟氨酸进行瓜氨酸的合成,而瓜氨酸含量的降低也减少了工程菌发酵液中EC的形成。
虽然本发明已以较佳实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明的精神和范围内,都可做各种的改动与修饰,因此本发明的保护范围应该以权利要求书所界定的为准。
SEQUENCE LISTING
<110> 江南大学
<120> 一种低产瓜氨酸的工业酿酒酵母代谢工程菌
<160> 12
<170> PatentIn version 3.3
<210> 1
<211> 1017
<212> DNA
<213> 人工序列
<400> 1
atgtcaacca cagcatccac gccttcatct ttacgtcatt tgatttctat aaaagatctt 60
tctgatgaag aattcagaat cttagtacaa agagctcaac atttcaagaa tgtttttaaa 120
gcaaataaaa cgaatgattt ccaatccaac catctgaaac tattgggtag aactatagcc 180
ttaatattta ctaaaagatc aactagaacg agaatttcga ccgaaggtgc agccaccttc 240
tttggtgccc aaccgatgtt tttaggtaaa gaggatattc agcttggtgt caatgaatca 300
ttttacgata ccaccaaggt tgtatcatct atggtttcat gtatttttgc ccgtgtgaac 360
aaacatgaag acatacttgc tttttgcaag gattcctctg taccgatcat caactctcta 420
tgtgacaaat tccacccttt gcaagcaatt tgtgatcttt taacaataat cgaaaacttc 480
aatatatctc tagatgaagt aaataaggga atcaattcaa aattgaagat ggcatggatt 540
ggtgatgcca ataatgtcat aaatgatatg tgcatcgcat gtctgaaatt cggtataagt 600
gtcagtattt ccactccccc cggtattgaa atggattccg atattgtcga tgaagcaaag 660
aaagttgctg agagaaacgg tgcgacattt gaattaacac acgactcttt aaaggcctcc 720
accaatgcca atatattagt aaccgatact ttcgtttcca tgggtgaaga atttgcgaaa 780
caggccaagc tgaaacaatt caaaggtttt caaatcaatc aagaacttgt ctctgtggct 840
gatccaaact acaaatttat gcattgtctg ccaagacatc aagaagaagt tagtgatgat 900
gtcttttatg gagagcattc catagtcttt gaagaagcag aaaacagatt atatgcagct 960
atgtctgcca ttgatatctt tgttaataat aaaggtaatt tcaaggactt gaaataa 1017
<210> 2
<211> 555
<212> DNA
<213> 人工序列
<400> 2
tcgacttttc acctctaaag gcagtttatt ccttgtatgt cctttaagta cagttaataa 60
cgagcaattt tttttttttt ttttagccat ctacccatca acttgtacac tcgttaccat 120
gtcaaccaca gcatccacgc cttcatcttt acgtcatttg atttctataa aagatctttc 180
tgatgaagaa ttcagaatct tagtacaaag agctcaacat ttcaagaatg tttttaaagc 240
aaataaaacg aatgatttcc aatccaacca tctgaaacta ttgggtagaa ctatagcctt 300
aatatttact aaaagatcaa ctagaacgag aatttcgacc gaaggtgcag ccaccttctt 360
tggtgcccaa ccgatgtttt taggtaaaga ggatattcag cttggtgtca atgaatcatt 420
ttacgatacc accaaggttg tatcatctat ggtttcatgt atttttgccc gtgtgaacaa 480
acatgaagac atacttgctt tttgcaagga ttcctctgta ccgatcatca actctgtttc 540
agggtccata aagct 555
<210> 3
<211> 1279
<212> DNA
<213> 人工序列
<400> 3
ctctgtaccg atcatcaact ctgtttcagg gtccataaag cttttcaatt catctttttt 60
ttttttgttc ttttttttga ttccggtttc tttgaaattt ttttgattcg gtaatctccg 120
agcagaagga agaacgaagg aaggagcaca gacttagatt ggtatatata cgcatatgtg 180
gtgttgaaga aacatgaaat tgcccagtat tcttaaccca actgcacaga acaaaaacct 240
gcaggaaacg aagataaatc atgtcgaaag ctacatataa ggaacgtgct gctactcatc 300
ctagtcctgt tgctgccaag ctatttaata tcatgcacga aaagcaaaca aacttgtgtg 360
cttcattgga tgttcgtacc accaaggaat tactggagtt agttgaagca ttaggtccca 420
aaatttgttt actaaaaaca catgtggata tcttgactga tttttccatg gagggcacag 480
ttaagccgct aaaggcatta tccgccaagt acaatttttt actcttcgaa gacagaaaat 540
ttgctgacat tggtaataca gtcaaattgc agtactctgc gggtgtatac agaatagcag 600
aatgggcaga cattacgaat gcacacggtg tggtgggccc aggtattgtt agcggtttga 660
agcaggcggc ggaagaagta acaaaggaac ctagaggcct tttgatgtta gcagaattgt 720
catgcaaggg ctccctagct actggagaat atactaaggg tactgttgac attgcgaaga 780
gcgacaaaga ttttgttatc ggctttattg ctcaaagaga catgggtgga agagatgaag 840
gttacgattg gttgattatg acacccggtg tgggtttaga tgacaaggga gacgcattgg 900
gtcaacagta tagaaccgtg gatgatgtgg tctctacagg atctgacatt attattgttg 960
gaagaggact atttgcaaag ggaagggatg ctaaggtaga gggtgaacgt tacagaaaag 1020
caggctggga agcatatttg agaagatgcg gccagcaaaa ctaaaaaact gtattataag 1080
taaatgcatg tatactaaac tcacaaatta gagcttcaat ttaattatat cagttattac 1140
ccgggaatct cggtcgtaat gatttctata atgacgaaaa aaaaaaaatt ggaaagaaaa 1200
agcttcatgg cctttataaa aaggaactat ccaatacctc gccagaacca agtaacacac 1260
acgactcttt aaaggcctc 1279
<210> 4
<211> 566
<212> DNA
<213> 人工序列
<400> 4
acctcgccag aaccaagtaa cacacacgac tctttaaagg cctccaccaa tgccaatata 60
ttagtaaccg atactttcgt ttccatgggt gaagaatttg cgaaacaggc caagctgaaa 120
caattcaaag gttttcaaat caatcaagaa cttgtctctg tggctgatcc aaactacaaa 180
tttatgcatt gtctgccaag acatcaagaa gaagttagtg atgatgtctt ttatggagag 240
cattccatag tctttgaaga agcagaaaac agattatatg cagctatgtc tgccattgat 300
atctttgtta ataataaagg taatttcaag gacttgaaat aatccttctt tcgtgttctt 360
aataactaat atataaatac agatatagat gcatgaataa tgatatacat tgattatttt 420
gcaatgtcaa ttaaaaaaaa aaaatgttag taaaactatg ttacattcca agcaaataaa 480
gcacttggtt aaacgaaatt aacgttttta agacagccag accgcggtct aaaaatttaa 540
atatacactg ccaacaaatt ccttcg 566
<210> 5
<211> 2314
<212> DNA
<213> 人工序列
<400> 5
tcgacttttc acctctaaag gcagtttatt ccttgtatgt cctttaagta cagttaataa 60
cgagcaattt tttttttttt ttttagccat ctacccatca acttgtacac tcgttaccat 120
gtcaaccaca gcatccacgc cttcatcttt acgtcatttg atttctataa aagatctttc 180
tgatgaagaa ttcagaatct tagtacaaag agctcaacat ttcaagaatg tttttaaagc 240
aaataaaacg aatgatttcc aatccaacca tctgaaacta ttgggtagaa ctatagcctt 300
aatatttact aaaagatcaa ctagaacgag aatttcgacc gaaggtgcag ccaccttctt 360
tggtgcccaa ccgatgtttt taggtaaaga ggatattcag cttggtgtca atgaatcatt 420
ttacgatacc accaaggttg tatcatctat ggtttcatgt atttttgccc gtgtgaacaa 480
acatgaagac atacttgctt tttgcaagga ttcctctgta ccgatcatca actctgtttc 540
agggtccata aagcttttca attcatcttt tttttttttg ttcttttttt tgattccggt 600
ttctttgaaa tttttttgat tcggtaatct ccgagcagaa ggaagaacga aggaaggagc 660
acagacttag attggtatat atacgcatat gtggtgttga agaaacatga aattgcccag 720
tattcttaac ccaactgcac agaacaaaaa cctgcaggaa acgaagataa atcatgtcga 780
aagctacata taaggaacgt gctgctactc atcctagtcc tgttgctgcc aagctattta 840
atatcatgca cgaaaagcaa acaaacttgt gtgcttcatt ggatgttcgt accaccaagg 900
aattactgga gttagttgaa gcattaggtc ccaaaatttg tttactaaaa acacatgtgg 960
atatcttgac tgatttttcc atggagggca cagttaagcc gctaaaggca ttatccgcca 1020
agtacaattt tttactcttc gaagacagaa aatttgctga cattggtaat acagtcaaat 1080
tgcagtactc tgcgggtgta tacagaatag cagaatgggc agacattacg aatgcacacg 1140
gtgtggtggg cccaggtatt gttagcggtt tgaagcaggc ggcggaagaa gtaacaaagg 1200
aacctagagg ccttttgatg ttagcagaat tgtcatgcaa gggctcccta gctactggag 1260
aatatactaa gggtactgtt gacattgcga agagcgacaa agattttgtt atcggcttta 1320
ttgctcaaag agacatgggt ggaagagatg aaggttacga ttggttgatt atgacacccg 1380
gtgtgggttt agatgacaag ggagacgcat tgggtcaaca gtatagaacc gtggatgatg 1440
tggtctctac aggatctgac attattattg ttggaagagg actatttgca aagggaaggg 1500
atgctaaggt agagggtgaa cgttacagaa aagcaggctg ggaagcatat ttgagaagat 1560
gcggccagca aaactaaaaa actgtattat aagtaaatgc atgtatacta aactcacaaa 1620
ttagagcttc aatttaatta tatcagttat tacccgggaa tctcggtcgt aatgatttct 1680
ataatgacga aaaaaaaaaa attggaaaga aaaagcttca tggcctttat aaaaaggaac 1740
tatccaatac ctcgccagaa ccaagtaaca cacacgactc tttaaaggcc tccaccaatg 1800
ccaatatatt agtaaccgat actttcgttt ccatgggtga agaatttgcg aaacaggcca 1860
agctgaaaca attcaaaggt tttcaaatca atcaagaact tgtctctgtg gctgatccaa 1920
actacaaatt tatgcattgt ctgccaagac atcaagaaga agttagtgat gatgtctttt 1980
atggagagca ttccatagtc tttgaagaag cagaaaacag attatatgca gctatgtctg 2040
ccattgatat ctttgttaat aataaaggta atttcaagga cttgaaataa tccttctttc 2100
gtgttcttaa taactaatat ataaatacag atatagatgc atgaataatg atatacattg 2160
attattttgc aatgtcaatt aaaaaaaaaa aatgttagta aaactatgtt acattccaag 2220
caaataaagc acttggttaa acgaaattaa cgtttttaag acagccagac cgcggtctaa 2280
aaatttaaat atacactgcc aacaaattcc ttcg 2314
<210> 6
<211> 2309
<212> DNA
<213> 人工序列
<400> 6
tcgacttttc acctctaaag gcagtttatt ccttgtatgt cctttaagta cagttaataa 60
cgagcaattt tttttttttt tttagccatc tacccatcaa cttgtacact cgttaccatg 120
tcaaccacag catccacgcc ttcatcttta cgtcatttga tttctataaa agatctttct 180
gatgaagaat tcagaatctt agtacaaaga gctcaacatt tcaagaatgt ttttaaagca 240
aataaaacga atgatttcca atccaaccat ctgaaactat tgggtagaac tatagcctta 300
atatttacta aaagatcaac tagaacgaga atttcgaccg aaggtgcagc caccttcttt 360
ggtgcccaac cgatgttttt aggtaaagag gatattcagc ttggcgtcaa tgaatcattt 420
tacgatacca ccaaggttgt atcatctatg gtttcatgta tttttgcccg tgtgaacaaa 480
catgaagaca tacttgcttt ttgcaaggat tcctctgtac cgatcatcaa ctctgtttca 540
gggtccataa agcttttcaa ttcatcattt tttttttatt cttttttttg attccggttt 600
ccttgaaatt tttttgattc ggtaatctcc gagcagaagg aagaacgaag gaaggagcac 660
agacttagat tggtatatat acgcatatgt agtgttgaag aaacatgaaa ttgcccagta 720
ttcttaaccc aactgcacag aacaaaaacc tgcaggaaac gaagataaat catgtcgaaa 780
gctacatata aggaacgtgc tgctactcat cctagtcctg ttgctgccaa gctatttaat 840
atcatgcacg aaaagcaaac aaacttgtgt gcttcattgg atgttcgtac caccaaggaa 900
ttactggagt tagttgaagc attaggtccc aaaatttgtt tactaaaaac acatgtggat 960
atcttgactg atttttccat ggagggtaca gttaagccgc taaaggcatt atccgccaag 1020
tacaattttt tactcttcga agacagaaaa tttgctgaca ttggtaatac agtcaaattg 1080
cagtactctg cgggtgtata cagaatagca gaatgggcag acattacgaa tgcacacggt 1140
gtggtgggcc caggtattgt tagcggtttg aagcaggcgg cagaagaagt aacaaaggaa 1200
cctagaggcc ttttgatgtt agcagaattg tcatgcaagg gctccctagc tactggagaa 1260
tatactaagg gtactgttga cattgcgaag agcgacaaag attttgttat aggctttatt 1320
gctcaaagag acatgggtgg aagagatgaa ggttacgatt ggttgattat gacacccggt 1380
gtgggtttag atgacaaggg agacgcattg ggtcaacagt atagaaccgt ggatgatgtg 1440
gtctctacag gatctgacat tattattgtt ggaagaggac tatttgcaaa gggaagggat 1500
gctaaggtag agggtgaacg ttacagaaaa gcaggctggg aagcatattt gagaagatgc 1560
ggccagcaaa actaaaagac tgtattataa gtaaatgcat gtatactaaa ctcacaaatt 1620
agagcttcaa tttaattata tcagttatta cccgggaatc tcggtcgtaa tgatttttat 1680
aatgacgaaa aaaaaaaatt ggaaagaaaa agcttcatgg cctttataaa aaggaaccat 1740
ccaatacctc gccagaccaa gtaacacaca cgactcttta aaggcctcca ccaatgccaa 1800
tatattagta accgatactt tcgtttccat gggtgaagaa tttgcgaaac aggccaagct 1860
gaaacaattc aaaggttttc aaatcaatca agaacttgtc tctgtggctg atccaaacta 1920
caaatttatg cattgtctgc caagatatca agaagaagtt agtgatgatg tcttttatgg 1980
agagcattcc atagtctttg aagaagcaga aaacagatta tatgcagcta tgtctgccat 2040
tgatatcttt gttaataata aaggtaattt caaggacttg aaataatcct tttttcgtgt 2100
tcctaataac taatatataa atacagatat agatgcatga ataatgatat acattgatta 2160
ttttgcaatg tcaattaaaa aaaaaaatgt tagtaaaact atgttacatt ccaagcaaat 2220
aaagcacttg gttaaacgaa attaacgttt ttaagacaac cagaccgcgg tctaaaaatt 2280
caaatataca ctgccaacaa attccttcg 2309
<210> 7
<211> 20
<212> DNA
<213> 人工序列
<400> 7
tcgacttttc acctctaaag 20
<210> 8
<211> 42
<212> DNA
<213> 人工序列
<400> 8
agctttatgg accctgaaac agagttgatg atcggtacag ag 42
<210> 9
<211> 44
<212> DNA
<213> 人工序列
<400> 9
acctcgccag aaccaagtaa cacacacgac tctttaaagg cctc 44
<210> 10
<211> 21
<212> DNA
<213> 人工序列
<400> 10
cgaaggaatt tgttggcagt g 21
<210> 11
<211> 42
<212> DNA
<213> 人工序列
<400> 11
ctctgtaccg atcatcaact ctgtttcagg gtccataaag ct 42
<210> 12
<211> 44
<212> DNA
<213> 人工序列
<400> 12
gaggccttta aagagtcgtg tgtgttactt ggttctggcg aggt 44
- 还没有人留言评论。精彩留言会获得点赞!