一种促进胶质纤维酸性蛋白在大肠杆菌中大量表达的方法与流程
本发明属于生物技术领域,具体涉及一种促进胶质纤维酸性蛋白在大肠杆菌中大量表达的方法。
背景技术:
胶质纤维酸性蛋白(gfap)是中枢神经系统所独有的特异性细胞骨架蛋白,是星形胶质细胞唯一表达的一种标志性蛋白,广泛分布于中枢神经系统各个部位,约占正常成年人脑细胞总数的40%。gfap则是星形胶质细胞和星形胶质细胞源性肿瘤的标志蛋白,对神经元起支撑和营养作用,参与星形胶质细胞的许多生物学功能,包括细胞的增殖与分裂、维护血脑屏障的正常生理功能、自噬、维持神经递质的平衡等。gfap是星形胶质细胞特有的中间丝蛋白,是胶质瘤的标志蛋白。在正常情况下,细胞胞质内的gfap循环降解,血液中gfap水平较稳定;而病理条件下,如病人的中枢神经系统受到损伤,其星形胶质细胞遭受破伤或坏死时,gfap从胶质细胞中流出,穿过血脑屏障进入血液中,使gfap浓度上调,因此gfap在恶性胶质瘤中表现出异常过度表达。gfap表达水平异常与多种遗传病和精神病相关,如亚历山大病、唐氏综合征、精神分裂症、情感型双极性疾患和抑郁症。目前,gfap表达水平已经作为中风、脑外损伤、星型细胞源性胶质瘤等多种疾病的诊断标志之一。另外gfap主要用于星型胶质瘤,包括星型细胞瘤,星型母细胞瘤,混合胶质瘤,多形性胶质母细胞瘤和非星型细胞瘤,包括部分少数胶质细胞瘤,多数室管膜瘤等中枢神经系统肿瘤的诊断和鉴别诊断。
在胶质纤维酸性蛋白抗原的制备过程中,采取pgex-4t-2载体对其全长基因进行表达,发现其原序列在大肠杆菌中不好表达,为此我们提供了一种经过密码子优化的序列用于表达。此外表达的蛋白都以包涵体形式存在。一方面增加纯化成本,另一方面纯化过程可能造成蛋白失活。
技术实现要素:
针对现有技术普遍存在的缺陷,本发明提供了一种促进胶质纤维酸性蛋白在大肠杆菌中大量表达的方法。通过本发明提供的方法,使胶质纤维酸性蛋白在大肠杆菌中的分泌增加,改善胶质纤维酸性蛋白包涵体形式的表达,为后续的纯化带来很大的便利。
为了达到上述目的,本发明采用的技术方案为:
一种促进胶质纤维酸性蛋白在大肠杆菌中大量表达的方法,包括如下步骤:
s1、用软件optimumgenetm分析编码gfap蛋白的基因序列,进行密码子优化,获得优化后的gfap基因序列;
s2、将步骤s1所得优化后的gfap基因序列导入pgex-4t-2质粒中,经测序验证序列信息,即可获得构建成功的重组质粒pgex-4t-2-gfap-opt;
s3、向步骤s2获得的构建成功的重组质粒pgex-4t-2-gfap-opt上添加ompa信号肽,进一步酶切测序验证,得到pgex-4t-2-ompa-gfap-opt重组质粒;
s4、将步骤s3得到的pgex-4t-2-ompa-gfap-opt重组质粒转化至宿主菌bl21感受态细胞中,进行蛋白表达,验证,即可。
优选地,步骤s1所述的优化后的gfap基因序列如seqidno.2所示。
优选地,步骤s3所述的ompa信号肽序列信息如seqidno.3所示,编码信号肽的核苷酸序列如seqidno.4所示,用引物ompa进行扩增。
优选地,所述引物ompa的上游引物序列如seqidno.5所示,所述引物ompa的下游引物序列如seqidno.6所示。
优选地,步骤s3的具体过程如下:
(1)将pgex-4t-2-gfap-opt用限制性内切酶bamhi和ecorⅰ进行双酶切,获得线性化的pgex-4t-2-gfap-opt作为插入载体,然后将酶切产物进行纯化,获得纯化的线性化pgex-4t-2-gfap-opt载体;
(2)用t4dna连接酶将ompadna片段与步骤(1)所得纯化的线性化pgex-4t-2-gfap-opt载体连接,并进一步酶切验证、测序,即可得到pgex-4t-2-ompa-gfap-opt重组表达质粒。
优选地,步骤(1)中的双酶切过程为,配制20μl的酶切体系:10×酶切buffer2μl,pgex-4t-2-gfap-opt质粒1μg,ecori1μl,bamhⅰ1μl,补水至20μl;将上述酶切体系置于37℃下酶切1h即可。
优选地,步骤(1)所述的酶切产物纯化过程为:用tae缓冲液制作1%琼脂糖凝胶,将酶切产物进行电泳,120v,1h;称重空1.5mlep管,于紫外灯下切下含目的dna酶切片段的凝胶置入ep管中;切碎胶块,分析天平称胶块的质量,按100mg=100μl进行计算胶块的体积;加入至少1倍等体积的bindingbuffer;把混合物置于60℃水浴中温浴7min至凝胶完全融化,其间每隔2-3分钟混匀一次;转移700μl冷却的dna-琼脂糖溶液到一个spincolumnscb2dna柱子,25℃下,12,000×g离心1min,弃去液体;将柱子重新套回收集管中,加入600μl漂洗液pw至spincolumnscb2dna柱子中,25℃下,12,000×g离心1分钟,弃去滤出液;重复洗涤一次,将空柱子重新套回收集管中,12,000×g离心1min以甩干柱基质残余的液体;把柱子装在一个干净的1.5ml离心管上,加入30~50μl洗脱液或灭菌水上柱子膜上,12,000×g离心1分钟,离心管中的溶液就是纯化的dna产物,测定dna浓度并保存于-20℃备用,即可。
优选地,步骤(2)所述的连接具体过程如下:按下述配方配制连接体系:10×t4dnaligasebuffer1μl,线性化的pgex-4t-2-gfap-opt1μl,ompadna片段7μl,t4dnaligase1μl,混匀,16℃放置16h,然后将连接物转化至dh5α感受态细胞,提取质粒。
优选地,步骤(2)中的酶切测序验证过程为:用限制性内切酶bamhi和xhoi酶切pgex-4t-2-ompa-gfap-opt质粒,验证用酶切体系为:质粒1μl,bamhi0.3μl,xhoi0.3μl,10×hbuffer1μl,加入双蒸水至10μl;回收用酶切体系为:质粒dna16μl,bamhi1μl,xhoi1μl,10×hbuffer2μl,进行1%琼脂糖凝胶电泳检测酶切产物,进一步测序即可。
优选地,步骤s4所述的蛋白表达过程具体包括如下步骤:
(1)取1μl溶解的质量浓度为0.2μg/μl的重组质粒加入到制备好的30μl的bl21细菌感受态细胞中,冰上放置30min,获得混合液i;
(2)将步骤(1)所得混合液i置于42℃下水浴中热击45s,再放在冰上2min,得混合液ii;
(3)向步骤(2)所得混合液ii中加入700μl不含抗生素的lb液体培养基,置于37℃、200rpm恒温培养振荡器中培养1h,得培养好的混合液;
(4)取步骤(3)所得培养好的混合液200μl涂布于含50μg/ml氨苄霉素抗性lb固体平板培养基上,于37℃恒温培养箱内正置培养30min后,倒置平板培养12-16h;
(5)挑取阳性单克隆菌落,接种于5ml含50mg/l氨苄抗性的试管lb液体培养基中,37℃培养过夜后将此培养液接种于200ml含有50mg/l氨苄抗性的三角瓶lb液体培养基中扩培,37℃,200rpm/min培养至菌液od值达到0.6-0.8,加入终浓度为0.5mm的iptg,37℃继续培6h,离心收集菌体并进行超声破碎,对破碎后的菌体成分分析即可。
本发明是基于大肠杆菌来源优化密码子的胶质纤维酸性蛋白基因在大肠杆菌中表达的平台,通过改造信号肽实现胶质纤维酸性蛋白在大肠杆菌中高效表达,以期能够提高胶质纤维酸性蛋白在大肠杆菌中的分泌能力。
与现有技术相比,本发明具有如下优势:
(1)本发明提供的方法针对大肠杆菌,对gfap碱基序列进行密码子优化,具有很强的表达活性,能实现外源基因在大肠杆菌中的高表达;
(2)本发明通过融合信号肽,可以使gfap的分泌量增加,改善gfap抗原制备过程中包涵体的问题,为后续的纯化带来很大的便利。
附图说明
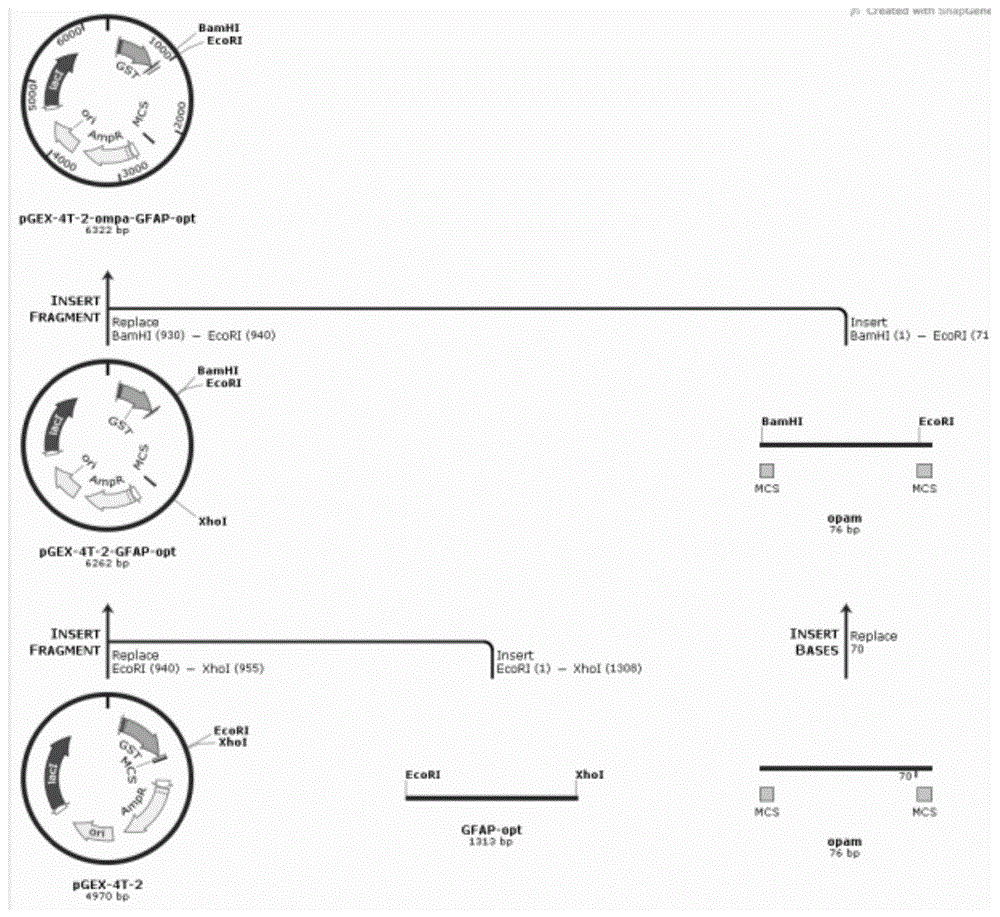
图1为pgex-4t-2-ompa-gfap-opt质粒构建流程图;
图2为pgex-4t-2-ompa-gfap-opt质粒双酶切验证结果图;
图3为质粒蛋白表达结果图。
具体实施方式
下面结合具体实施例对本发明作进一步解释,但是应当注意的是,以下实施例仅用以解释本发明,而不能用来限制本发明,所有与本发明相同或相近的技术方案均在本发明的保护范围之内。本实施例中未注明具体技术或条件者,按照本领域常规技术方法和仪器说明书内容进行操作;所用试剂或仪器未注明生产厂商者,均为可以通过市面购买获得的常规产品。
本发明中,涉及到的基因序列、引物序列及测序过程均由上海生工生物工程有限公司完成;本发明所述的酶切位点bamhi、ecor1及xhoi均来源于newenglandbiolabs(北京);本发明所述的dh5α感受态细胞、宿主菌bl21来源于天根生化科技有限公司;pgex-4t-2质粒来源于优宝生物科技有限公司本发明所述lb液体培养基及lb固体培养基均可购自赛默飞世尔科技(中国)有限公司。
实施例一种促进胶质纤维酸性蛋白在大肠杆菌中大量表达的方法
所述促进胶质纤维酸性蛋白在大肠杆菌中大量表达的方法,包括如下步骤:
s1、用软件optimumgenetm分析编码gfap蛋白的基因序列,进行密码子优化,获得优化后的gfap基因序列;
s2、将步骤s1所得优化后的gfap基因序列导入pgex-4t-2质粒中,经测序验证序列信息,即可获得构建成功的重组质粒pgex-4t-2-gfap-opt;
用软件optimumgenetm分析编码gfap蛋白的基因序列seqidno.1,找出其密码子使用偏好以及大肠杆菌使用偏好不同的位点。对于使用偏好不同的密码子位点,用大肠杆菌偏好的密码子替代,设计出密码子优化的gfap蛋白基因序列seqidno.2上述密码子优化的基因序列所编码的蛋白氨基酸序列与原有的氨基酸序列一致。上述密码子优化的基因序列由上海生工生物工程有限公司合成,装入载体pgex-4t-2,构建成重组质粒pgex-4t-2-gfap-opt。经测序证实合成的序列正确。
为了明确显示进行密码子优化的位点,现将密码子优化后的核酸序列gfap-opt与密码子优化前的核酸序列gfap进行对比。比较结果如下(*为终止密码子)
优化前:atggagaggagacgcatcacctccgctgctcgccgctcctacgtctcctcaggggagatgatggtggggggcctggctcctggccgccgtctgggtcctggcacccgcctctccctggctcgaatgccccctccactcccgacccgggtggatttctccctggctggggcactcaatgctggcttcaaggagacccgggccagtgagcgggcagagatgatggagctcaatgaccgctttgccagctacatcgagaaggttcgcttcctggaacagcaaaacaaggcgctggctgctgagctgaaccagctgcgggccaaggagcccaccaagctggcagacgtctaccaggctgagctgcgagagctgcggctgcggctcgatcaactcaccgccaacagcgcccggctggaggttgagagggacaatctggcacaggacctggccactgtgaggcagaagctccaggatgaaaccaacctgaggctggaagccgagaacaacctggctgcctatagacaggaagcagatgaagccaccctggcccgtctggatctggagaggaagattgagtcgctggaggaggagatccggttcttgaggaagatccacgaggaggaggttcgggaactccaggagcagctggcccgacagcaggtccatgtggagcttgacgtggccaagccagacctcaccgcagccctgaaagagatccgcacgcagtatgaggcaatggcgtccagcaacatgcatgaagccgaagagtggtaccgctccaagtttgcagacctgacagacgctgctgcccgcaacgcggagctgctccgccaggccaagcacgaagccaacgactaccggcgccagttgcagtccttgacctgcgacctggagtctctgcgcggcacgaacgagtccctggagaggcagatgcgcgagcaggaggagcggcacgtgcgggaggcggccagttatcaggaggcgctggcgcggctggaggaagaggggcagagcctcaaggacgagatggcccgccacttgcaggagtaccaggacctgctcaatgtcaagctggccctggacatcgagatcgccacctacaggaagctgctagagggcgaggagaaccggatcaccattcccgtgcagaccttctccaacctgcagattcgagaaaccagcctggacaccaagtctgtgtcagaaggccacctcaagaggaacatcgtggtgaagaccgtggagatgcgggatggagaggtcattaaggagtccaagcaggagcacaaggatgtgatgtga(seqidno.1);
优化后:atggaacgtcgtcgtatcacctccgctgcgcgtcgtagctacgtttccagcggtgaaatgatggttggtggcctggcgccgggtcgtcgtctgggtccgggcacccgtctgagcctggcgcgtatgccgccgccgctgccgacccgcgttgatttctctctggccggcgcgctgaacgctggcttcaaagaaacccgtgcttctgaacgtgcggaaatgatggaactgaacgatcgtttcgcaagctatatcgaaaaagttcgtttcctggaacagcagaacaaagccctggcggccgaactgaaccagctgcgtgcaaaagaaccgaccaaactggcagacgtt
taccaggcggaactgcgcgaactgcgtctgcgtctggaccagctgaccgcaaacagtgcgcgcctggaagttgaacgtgataacctggcgcaagatctggcgactgttcgtcagaaactgcaggacgaaactaacctgcgtctggaagcggaaaacaacctggcggcgtaccgccaggaagctgacgaagccactctggcgcgcctggatctggaacgtaaaatcgaaagcctggaagaagaaatccgtttcctgcgtaaaatccacgaagaagaagtgcgtgaactgcaggaacagctggcccgtcagcaggttcacgttgaactggatgtagctaaaccggatctgaccgcggctctgaaagaaatccgtacccagtatgaagcgatggcatccagcaacatgcacgaagcggaagaatggtatcgctctaaattcgcggacctgactgatgcggctgcgcgtaacgcggaactgctgcgccaggcgaaacacgaagcgaacgattaccgtcgtcagctgcagtctctgacctgcgatctggaatctctgcgtggtaccaacgaatccctggaacgtcagatgcgtgaacaagaagaacgtcacgttcgtgaagcagcgtcctaccaggaagcgctggcgcgtctggaagaagaaggtcagagcctgaaagatgaaatggcgcgtcacctgcaggaataccaggatctgctgaacgttaaactggcgctggatattgaaatcgcgacctaccgtaaactgctggaaggtgaagaaaaccgtatcaccatcccggttcagaccttcagcaacctgcagatccgcgaaacctccctggataccaaaagcgtttctgaaggccacctgaaacgtaacatcgtagttaaaaccgttgaaatgcgtgacggtgaagttatcaaagaatctaaacaggaacacaaagatgtgatgtaa(seqidno.2);
氨基酸:merrritsaarrsyvssgemmvgglapgrrlgpgtrlslarmppplptrvdfslagalnagfketraseraemmelndrfasyiekvrfleqqnkalaaelnqlrakeptkladvyqaelrelrlrldqltansarleverdnlaqdlatvrqklqdetnlrleaennlaayrqeadeatlarldlerkiesleeeirflrkiheeevrelqeqlarqqvhveldvakpdltaalkeirtqyeamassnmheaeewyrskfadltdaaarnaellrqakheandyrrqlqsltcdleslrgtneslerqmreqeerhvreaasyqealarleeegqslkdemarhlqeyqdllnvklaldieiatyrkllegeenritipvqtfsnlqiretsldtksvseghlkrnivvktvemrdgevikeskqehkdvm*(seqidno.3);
本发明在对gfap的序列优化后,直接由合成优化序列的公司(生工)连接至载体;后续的测序是针对gfap序列前后200个bp左右的碱基进行测序,是直接测质粒。
注意:优化前及优化后的基因序列中,最后三位为终止密码子,上述密码子优化的gfap蛋白基因序列与野生型序列比较密码子偏好性发生了改变。与野生型基因序列相比,密码子优化的基因中大肠杆菌偏好的密码子出现频率增加,但是它们所编码的氨基酸序列不变,从而使gfap蛋白更适于在大肠杆菌中的蛋白表达。
s3、向步骤s2获得的合成的重组质粒pgex-4t-2-gfap-opt上添加ompa信号肽,进一步酶切、测序验证,得到pgex-4t-2-ompa-gfap-opt重组质粒;
本发明提供的ompa信号肽序列:mkktaiaiavalagfvtvaqa(seqdino.4),对应的核苷酸序列如seqidno.5所示;
atgaaaaagacagctatcgcgattgcagtggcactggcaggtttcgtcaccgtcgctcaggct(seqidno.5);
用引物ompa经过退火合成dna片段,引物中,加下划线的碱基为相应的酶切位点,加粗的碱基为保护的碱基,上游引物为ompa-f,序列信息如seqidno.6所示,下游引物为ompa-r,具体序列信息如seqidno.7所示;
gatccatgaaaaagacagctatcgcgattgcagtggcactggcaggtttcgtcaccgtcgctcaggctgg(seqidno.6);
aattccagcctgagcgacggtgacgaaacctgccagtgccactgcaatcgcgatagctgtctttttcatg(seqidno.7)。
酶切过程:将pgex-4t-2-gfap-opt用限制性内切酶bamhi和ecor1进行双酶切,获得线性化的pgex-4t-2-gfap-opt线性片段作为插入载体。酶切反应体系为:10×酶切buffer2μl,pgex-4t-2-gfap-opt质粒1μg,ecori1μl,bamhⅰ1μl,补水至20μl,37℃,1h。
酶切产物的纯化:tae缓冲液制作1%琼脂糖凝胶,酶切产物进行电泳,120v,1h;称重空1.5mlep管,紫外灯下切下含目的dna的凝胶置入ep管;切碎胶块,分析天平称胶块的质量,按100mg=100μl进行计算胶块的体积;加入至少1倍等体积的bindingbuffer;把混合物置于60℃水浴中温浴7min至凝胶完全融化,其间每隔2-3分钟混匀一次;转移700μl冷却的dna-琼脂糖溶液到一个spincolumnscb2dna柱子,室温下,12,000×g离心1min,弃去液体;将柱子重新套回收集管中,加入600μl漂洗液pw至spincolumnscb2dna柱子中,室温下,12,000×g离心1分钟,弃滤出液;重复洗涤一次,将空柱子重新套回收集管中,12,000×g离心1min以甩干柱基质残余的液体;把柱子装在一个干净的1.5ml离心管上,加入30~50μl洗脱液或灭菌水上柱子膜上,12,000×g离心1分钟,离心管中的溶液就是纯化的dna产物,测定dna浓度并保存于-20℃。
连接反应:用t4dna连接酶将ompadna片段与pgex-4t-2-gfap-opt酶切片段连接,得到pgex-4t-2-ompa-gfap-opt重组表达质粒。连接反应体系为:10×t4dnaligasebuffer1μl,线性化的pgex-4t-2-gfap-opt1μl,退火相关目的片段7μl,t4dnaligase1μl,混匀,4℃放置16h。将连接物转化至dh5α感受态细胞,提取质粒。
酶切验证,用限制性内切酶bamhi和xhoi酶切pgex-4t-2-ompa-gfap-opt质粒,验证用酶切体系为:质粒1μl,bamhi0.3μl,xhoi0.3μl,10×hbuffer1μl,加入双蒸水至10μl;进行1%琼脂糖凝胶电泳检测酶切产物。酶切验证结果如图2所示,酶切成功的序列由上海生工生物工程有限公司进行测序,测序结果正确,从而得到pgex-4t-2-ompa-gfap-opt重组质粒。具体连接过程如图1所示。pgex-4t-2-ompa-gfap-opt质粒双酶切验证结果如图2所示。
s3、将步骤s2得到的pgex-4t-2-ompa-gfap-opt重组质粒转化至宿主菌bl21感受态细胞中,进行蛋白表达,验证,即可。
s4、将步骤s3得到的pgex-4t-2-ompa-gfap-opt重组质粒转化至宿主菌bl21感受态细胞中,进行蛋白表达,验证,即可。
分别取测序正确的重组质粒转化至宿主菌bl21感受态细胞中转化制备pgex-4t-2-gfap、pgex-4t-2-gfap-opt、pgex-4t-2-ompa-gfap-opt表达菌并保种。
具体步骤如下:1.将1μl溶解的0.2μg/μl的重组质粒加入制备好30μl的bl21细菌感受态细胞中,冰上放置30min;2.将此混合液于42℃水浴中热击45s;3.再放在冰上2min;4.往此混合液中加入700μl不含抗生素的lb培养基;5.将混合液置于37℃、200rpm恒温培养振荡器中培养1h;6.取培养好的混合液200μl涂布于50μg/ml氨苄霉素抗性lb固体平板培养基上,37℃恒温培养箱正置培养30min后,倒置平板培养12-16h。)挑取阳性单克隆菌落,接种于5ml含50mg/l氨苄抗性的试管lb培养基中,37℃培养过夜后将此培养液接种于200ml含有50mg/l氨苄抗性的三角瓶lb培养基中扩培,37℃,200rpm/min培养至菌液od值达到0.6-0.8,加入终浓度为0.5mm的iptg,16℃,120rpm/min继续培养16h,离心收集菌体并进行超声破碎。
图3为gfap蛋白表达鉴定的聚丙烯酰胺凝胶电泳图:图3中,pgex-4t-2-gfap为gfap原始序列;pgex-4t-2-gfap-opt为gfap优化后的序列;pgex-4t-2-ompa-gfap-opt在优化了gfap序列之后加入ompa信号肽。由图3可知,gfap基因序列经过密码子优化后为gpap-opt,构建的pgex-4t-2-gpap-opt蛋白可以成功被诱导出来,菌体破碎后主要在包涵体中,于是在添加gfap-opt序列后,加入ompa信号肽构建pgex-4t-2-ompa-gpap-opt表达载体,gfap蛋白成功诱导表达,并且存在菌体破碎后的上清中,有利于后续的纯化。
最后应当说明的是,上述的对实施例的描述是为便于该技术领域的普通技术人员能理解和使用发明。熟悉本领域技术的人员显然可以容易地对这些实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,不脱离本发明范畴所做出的改进和修改都应该在本发明的保护范围之内。
序列表
<110>厦门宝太生物科技有限公司
<120>一种促进胶质纤维酸性蛋白在大肠杆菌中大量表达的方法
<130>2021.3.5
<160>7
<170>siposequencelisting1.0
<210>1
<211>1299
<212>dna
<213>gfap优化前序列(gfapoptimizedpre-sequence)
<400>1
atggagaggagacgcatcacctccgctgctcgccgctcctacgtctcctcaggggagatg60
atggtggggggcctggctcctggccgccgtctgggtcctggcacccgcctctccctggct120
cgaatgccccctccactcccgacccgggtggatttctccctggctggggcactcaatgct180
ggcttcaaggagacccgggccagtgagcgggcagagatgatggagctcaatgaccgcttt240
gccagctacatcgagaaggttcgcttcctggaacagcaaaacaaggcgctggctgctgag300
ctgaaccagctgcgggccaaggagcccaccaagctggcagacgtctaccaggctgagctg360
cgagagctgcggctgcggctcgatcaactcaccgccaacagcgcccggctggaggttgag420
agggacaatctggcacaggacctggccactgtgaggcagaagctccaggatgaaaccaac480
ctgaggctggaagccgagaacaacctggctgcctatagacaggaagcagatgaagccacc540
ctggcccgtctggatctggagaggaagattgagtcgctggaggaggagatccggttcttg600
aggaagatccacgaggaggaggttcgggaactccaggagcagctggcccgacagcaggtc660
catgtggagcttgacgtggccaagccagacctcaccgcagccctgaaagagatccgcacg720
cagtatgaggcaatggcgtccagcaacatgcatgaagccgaagagtggtaccgctccaag780
tttgcagacctgacagacgctgctgcccgcaacgcggagctgctccgccaggccaagcac840
gaagccaacgactaccggcgccagttgcagtccttgacctgcgacctggagtctctgcgc900
ggcacgaacgagtccctggagaggcagatgcgcgagcaggaggagcggcacgtgcgggag960
gcggccagttatcaggaggcgctggcgcggctggaggaagaggggcagagcctcaaggac1020
gagatggcccgccacttgcaggagtaccaggacctgctcaatgtcaagctggccctggac1080
atcgagatcgccacctacaggaagctgctagagggcgaggagaaccggatcaccattccc1140
gtgcagaccttctccaacctgcagattcgagaaaccagcctggacaccaagtctgtgtca1200
gaaggccacctcaagaggaacatcgtggtgaagaccgtggagatgcgggatggagaggtc1260
attaaggagtccaagcaggagcacaaggatgtgatgtga1299
<210>2
<211>1299
<212>dna
<213>gfap优化后序列(gfapoptimizedsequence)
<400>2
atggaacgtcgtcgtatcacctccgctgcgcgtcgtagctacgtttccagcggtgaaatg60
atggttggtggcctggcgccgggtcgtcgtctgggtccgggcacccgtctgagcctggcg120
cgtatgccgccgccgctgccgacccgcgttgatttctctctggccggcgcgctgaacgct180
ggcttcaaagaaacccgtgcttctgaacgtgcggaaatgatggaactgaacgatcgtttc240
gcaagctatatcgaaaaagttcgtttcctggaacagcagaacaaagccctggcggccgaa300
ctgaaccagctgcgtgcaaaagaaccgaccaaactggcagacgtttaccaggcggaactg360
cgcgaactgcgtctgcgtctggaccagctgaccgcaaacagtgcgcgcctggaagttgaa420
cgtgataacctggcgcaagatctggcgactgttcgtcagaaactgcaggacgaaactaac480
ctgcgtctggaagcggaaaacaacctggcggcgtaccgccaggaagctgacgaagccact540
ctggcgcgcctggatctggaacgtaaaatcgaaagcctggaagaagaaatccgtttcctg600
cgtaaaatccacgaagaagaagtgcgtgaactgcaggaacagctggcccgtcagcaggtt660
cacgttgaactggatgtagctaaaccggatctgaccgcggctctgaaagaaatccgtacc720
cagtatgaagcgatggcatccagcaacatgcacgaagcggaagaatggtatcgctctaaa780
ttcgcggacctgactgatgcggctgcgcgtaacgcggaactgctgcgccaggcgaaacac840
gaagcgaacgattaccgtcgtcagctgcagtctctgacctgcgatctggaatctctgcgt900
ggtaccaacgaatccctggaacgtcagatgcgtgaacaagaagaacgtcacgttcgtgaa960
gcagcgtcctaccaggaagcgctggcgcgtctggaagaagaaggtcagagcctgaaagat1020
gaaatggcgcgtcacctgcaggaataccaggatctgctgaacgttaaactggcgctggat1080
attgaaatcgcgacctaccgtaaactgctggaaggtgaagaaaaccgtatcaccatcccg1140
gttcagaccttcagcaacctgcagatccgcgaaacctccctggataccaaaagcgtttct1200
gaaggccacctgaaacgtaacatcgtagttaaaaccgttgaaatgcgtgacggtgaagtt1260
atcaaagaatctaaacaggaacacaaagatgtgatgtaa1299
<210>3
<211>432
<212>prt
<213>gfap对应的氨基酸序列(aminoacidsequencecorrespondingtogfap)
<400>3
metgluargargargilethrseralaalaargargsertyrvalser
151015
serglyglumetmetvalglyglyleualaproglyargargleugly
202530
proglythrargleuserleualaargmetproproproleuprothr
354045
argvalasppheserleualaglyalaleuasnalaglyphelysglu
505560
thrargalasergluargalaglumetmetgluleuasnaspargphe
65707580
alasertyrileglulysvalargpheleugluglnglnasnlysala
859095
leualaalagluleuasnglnleuargalalysgluprothrlysleu
100105110
alaaspvaltyrglnalagluleuarggluleuargleuargleuasp
115120125
glnleuthralaasnseralaargleugluvalgluargaspasnleu
130135140
alaglnaspleualathrvalargglnlysleuglnaspgluthrasn
145150155160
leuargleuglualagluasnasnleualaalatyrargglngluala
165170175
aspglualathrleualaargleuaspleugluarglysilegluser
180185190
leugluglugluileargpheleuarglysilehisgluglugluval
195200205
arggluleuglngluglnleualaargglnglnvalhisvalgluleu
210215220
aspvalalalysproaspleuthralaalaleulysgluileargthr
225230235240
glntyrglualametalaserserasnmethisglualagluglutrp
245250255
tyrargserlysphealaaspleuthraspalaalaalaargasnala
260265270
gluleuleuargglnalalyshisglualaasnasptyrargarggln
275280285
leuglnserleuthrcysaspleugluserleuargglythrasnglu
290295300
serleugluargglnmetarggluglnglugluarghisvalargglu
305310315320
alaalasertyrglnglualaleualaargleugluglugluglygln
325330335
serleulysaspglumetalaarghisleuglnglutyrglnaspleu
340345350
leuasnvallysleualaleuaspilegluilealathrtyrarglys
355360365
leuleugluglyglugluasnargilethrileprovalglnthrphe
370375380
serasnleuglnilearggluthrserleuaspthrlysservalser
385390395400
gluglyhisleulysargasnilevalvallysthrvalglumetarg
405410415
aspglygluvalilelysgluserlysglngluhislysaspvalmet
420425430
<210>4
<211>21
<212>prt
<213>ompa信号肽序列(ompasignalpeptidesequence)
<400>4
metlyslysthralailealailealavalalaleualaglypheval
151015
thrvalalaglnala
20
<210>5
<211>63
<212>dna
<213>ompa对应的核苷酸序列(nucleotidesequencecorrespondingtoompa)
<400>5
atgaaaaagacagctatcgcgattgcagtggcactggcaggtttcgtcaccgtcgctcag60
gct63
<210>6
<211>70
<212>dna
<213>ompa-f
<400>6
gatccatgaaaaagacagctatcgcgattgcagtggcactggcaggtttcgtcaccgtcg60
ctcaggctgg70
<210>7
<211>70
<212>dna
<213>ompa-r
<400>7
aattccagcctgagcgacggtgacgaaacctgccagtgccactgcaatcgcgatagctgt60
ctttttcatg70
- 还没有人留言评论。精彩留言会获得点赞!