一种基于数据模型对工业废水处理过程的故障检测与诊断的方法与流程
本发明属于工业化工与过程控制交叉领域,涉及工业废水处理过程中,通过测量数据量及时反映系统运行状态的方法。
背景技术:
工业废水处理工程的建设主要是解决排水系统污水随意排放的问题,改善和治理污水对当地生态的严重污染问题。工业系统的排水质量对于人们的生活环境,社会的可持续发展,都有着至关重要的影响。
针对进水水质为食品工业废水,其可生化性较高。污水浓度较高,其生化需氧量(biochemicaloxygendemand,bod)、化学需氧量(chemicaloxygendemand,cod)、氮总含量(totalnitrogen,tn)、磷总含量(totalphosphorous,tp)等浓度是普通城市污水的3-4倍。对于大规模污水,处理厂采用最多的工艺就是传统活性污泥法的生物曝气工艺。这种工艺是对物理处理过程之后利用在同一人工环境中培养的好氧生物(包括细菌和原生物)对污水中的有机污染质进行降解。该工艺较为简单,对cod,bod和ss的去除效率可以达到预期要求。但是,这种方法只有单一的生物环境,不能发挥和强化不同微生物的生物特性和优势,既不能提高对高浓度污水的有效处理,也不能对氮、磷营养元素的有效去除,因此必须采用生化二级处理来满足预期的处理目标。生物处理技术所遵循的途径主要有两条:一是提高参与作用的微生物量,增加有机物与微生物接触的机率,其实现的手段是提高混合液浓度。二是发挥不同微生物优势的代谢特性,筛选菌种,提供与优势微生物生理特性相适合的生物环境。使各类微生物尽其所能“分工负责”,发挥最大优势来实现所预期的处理目标。生物除磷脱氮工艺即采取这一途径。其脱氮是通过延长曝气时间,利用世代时间较长的消化菌,将氨氮转化为硝酸盐,再利用缺氧条件下的兼性厌氧反消化菌将硝态氮转化为气态氮逸出,从而达到去除水中nh3-n的目的。除磷则是先利用厌氧条件下兼性和好氧聚磷菌进行磷的有效释放,再利用经厌氧放磷的菌群在好氧条件下大家增殖吸磷的特性,使原污水中的磷转化为生物细胞(活性污泥),最终通过沉淀分离,将富磷剩余污泥排除来实现的。由于这一完整的除磷、脱氮过程是分别在厌氧、兼氧和好氧条件下进行的,所以通常被称之为a2/o工艺(即厌氧anaerobic+缺氧anoxic+好氧oxic工艺)。在此工艺改良基础上,设计出整体污水处理系统,其工艺流程框图见图1。
污水系统中a2/o部分的详细工艺,该池体由四个部分组成,并联工作。每池从前至后依次是进水区,厌氧区,缺氧区,好氧区。好氧区内安装爆氧头,其余各区均安装水下搅拌器,防止混合液形成沉淀。a2/o反应池的运行过程对于废水处理过程有着至关重要的作用。如当进水速度过快,使反应池中反应不充分,或是反应池中氧含量不在正常范围,使得氮磷去除不充分,严重时导致处理后的水质不达标,影响生态环境。因此,如何确定目前生产状态、维护设备安全、稳定与优化运行,是工业废水处理工程迫切需要解决的重要问题之一。
近年来基于数据模型的过程建模在工业中获得了大量成功的应用,解决了许多运行系统状态监控问题。基于数据驱动的过程监控是利用收集系统过程中过程数据建模,构造过程观测的监控统计量,从而监测系统运行的状态,及时发现系统运行故障并进行诊断。a2/o反应池中的生物化学反应也产生了大量数据,这些数据蕴含污水处理过程的特征信息,因此可以基于工业废水处理过程产生与分析数据,建立过程关联模型。本发明采用了基于载荷选取主元的主元分析支持向量数据域描述(loading-basedprincipalcomponentselectionforprincipalcomponentanaylsisintegratedwithsupportvectordatadescription,ppca-svdd)建模方法,利用工业废水处理过程中收集到的过程数据建立数学模型。针对每个变量选取特定敏感主元构成变量子空间,对每个变量的变化更敏感,从而具备更好的过程故障信息提取能力。通过svdd统计量构造,使得过程监控统计量具有反应过程状态的能力,从而达到过程故障检测的目的。当检测到故障后,根据过程数据,做出相应的变量贡献图,使得过程故障原因得以诊断,从而可以进一步修正故障,使得过程恢复正常运行。
技术实现要素:
本发明目的是利用工业废水处理工厂的过程数据,提供一个状态监控的统计量来监测运行过程,及时发现系统故障并进行诊断。选取的观测变量有:进水区溶氧量do(x1,mg/l)、好氧区悬浮体含量ss(x2,mg/l)、进水口流量qin(x3,m3/s)、出水口流量qef(x4,m3/s)、化学需氧量codin(x5,mg/l)、以及出水口悬浮体含量ssef(x6,mg/l)。将这6个变量作为该工业废水处理系统的原始监测变量,利用相关的测量仪表,直接测量或间接计算获得x1~x6。采集工业装置样本数据,构建数据模型,通过计算获得的过程监测统计量对废水处理过程实现故障监测和诊断,以保障系统过程的正常运行。
1.原始监测变量的选取
工业废水处理的工艺流程中,a2/o反应池是整个系统中的核心单元。影响反应池氧化反应正常运行的关键因素有:反应池中的氧含量、实际需氧量、进水的流量、出水的流量、反应物浓度。
本发明的特点是:
通过利用过程收集的样本数据,建立基于载荷选取主元的主元分析支持向量数据域描述(ppca-svdd)模型,构造过程监控统计量,实现对整个运行过程进行实时监控,从而及时地监测到过程故障并诊断。
为此,基于以上分析说明,该工业废水处理工程的监测变量选取如下:
(1)进水区溶氧量do(x1,mg/l)
(2)好氧区悬浮体含量ss(x2,mg/l)
(3)进水口流量qin(x3,m3/s)
(4)出水口流量qef(x4,m3/s)
(5)化学需氧量codin(x5,mg/l)
(6)以及出水口悬浮体含量ssef(x6,mg/l)
以上六个变量均可由测量仪器直接获得。
2.建模样本的预处理
为了消除量纲的影响,对采集的样本数据进行归一化预处理。输入变量利用式(1)进行归一化处理:
(1)式中,xi是第i个观测变量的实际测量值,μi表示观测量xi所对应的均值,σi表示观测量xi所对应的方差,
采集到n组代表性的工业装置数据,其中每组数据包含输入变量[x1,x2,x3,x4,x5,x6],经公式(1)归一化处理后得到
对于在t时刻实时收集的数据xt,对其利用式(1)中获得的均值方差进行归一化处理,如下,
其中,μ=[μ1,μ2,…,μ6],且σ=[σ1,σ2,…,σ6]。
3.基于ppca-svdd的工业废水处理过程监控模型
假设建模样本的样本容量为n,首先对建模数据按照(1)式归一化,采用ppca-svdd建模方法,建立初始模型;然后,通过分析pca建模产生的载荷矩阵p以及每个载荷向量pi对应的特征值λi,根据(2)式计算的转换加权值,为每个变量选取敏感主元。
其中,pi,j为载荷矩阵中第(i,j)个元素。对于某一变量
由于每个变量所对应的子空间对于该变量的变化更为敏感,因此当变量发生故障变化时,所对应的空间可以更快更准确的检测到。正常的训练样本得到对应于6个变量的统计量
其中,r和τ分别表示超球体的半径和中心,参数c表示球体体积大小与正常样本分错分数之间的权衡,ξi表示松弛系数,即允许训练样本被误判的概率。上述优化问题的对偶形式可以表示成,
其中βi为对应的拉格朗日乘子,svdd选取0≤βi≤c所对应的各个样本作为支持向量。这样,超球体的球心和半径就可以根据下式求得,
其中,
对于t时刻收集的一个有包含六个变量的归一化目标测试样本
当测试样本在特征空间中到圆心的距离大于训练样本所得半径时,我们认为该样本为异常样本,反之,该样本被认为处于正常状态。过程监控统计量设计如下,
当dr统计量小于1时,认为系统正常;当大于1时,即认为过程监控统计量检测到故障,发出警告。接着,就应进行相应的故障诊断来发现过程发生故障的根本原因,从而修复系统。这里,利用能监测到故障的子空间中的主元信息,计算贡献率,如下
其中
由于变量对应的敏感主元含有更多关于过程的故障信息量,因此基于敏感主元选取所作的贡献图可以给出一个更加准确的故障诊断结果。
4.工业废水处理系统中过程监控统计量的在线计算
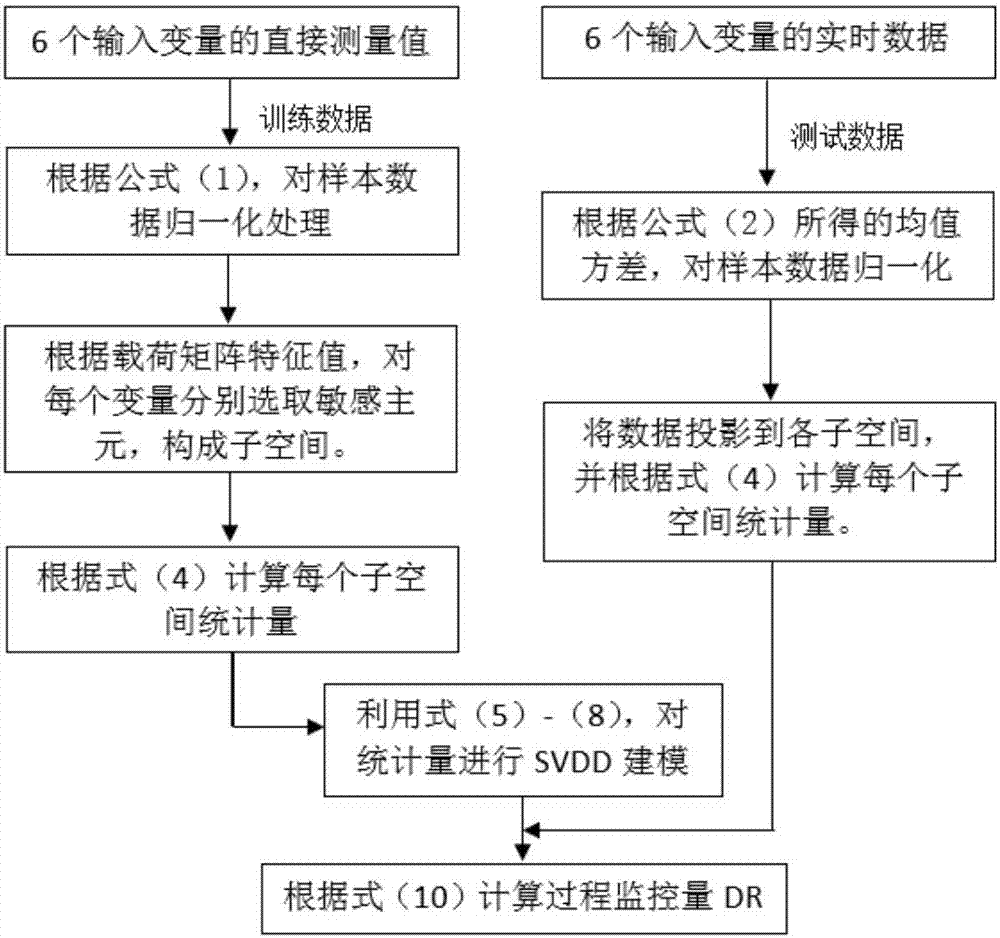
工业废水处理系统过程监控统计量在线计算流程如图2所示。进水区溶氧量、好氧区悬浮体含量ss、进水口流量、出水口流量、化学需氧量、以及出水口悬浮体含量,基于上述6个输入变量的直接测量数据,通过(1)式对数据进行归一化处理;利用pca对训练数据进行整体建模,根据产生的载荷向量为每个变量分别选取主元,形成子空间;分别计算每个子空间的t2统计量,并构造svdd模型;对于监控的实时数据,利用(2)式产生的均值方差,进行归一化处理;将归一化的实时监控数据投影到各子空间,计算得到相应的t2统计量;计算统计量在svdd构造的高维空间中距离圆心的距离,从而判断该时刻的监控数据是否正常。另外,当发现系统中有故障时,用式(11)(12)计算变量的贡献率,实现故障诊断。
附图说明
图1工业废水处理工艺流程框图。
图2工业废水处理过程监控统计量在线计算流程。
具体实施方式
以下通过实施例对本发明作进一步说明:
对于六个变量,进水区溶氧量do(x1,mg/l)、好氧区悬浮体含量ss(x2,mg/l)、进水口流量qin(x3,m3/s)、出水口流量qef(x4,m3/s)、化学需氧量codin(x5,mg/l)、以及出水口悬浮体含量ssef(x6,mg/l),采集一组100个样本的系统的历史正常数据作为训练数据,以及一组由100个样本组成的实时过程观测数据。
1.预处理样本
对上述采集的第一组由200个样本构成的数据进行归一化处理,利用(1)式:x1的均值为3.78,方差为1.37;x2的均值为4.00,方差为1.27;x3的均值为3417.48,方差为1290.31;x4的均值为4090.31,方差为1274.90;x5的均值为24.82,方差为3.58;x6的均值为19.58,方差为33.53。进行归一化计算:
对t时刻实时收集的数据xt利用(8)式进行归一化处理
其中,均值μ=[3.78,4.00,3417.48,4090.31,24.82,19.58],方差σ=[1.37,1.27,1290.31,1274.90,3.58,33.53]。这里有小数的形式,一律保留小数点后两位,四舍五入计算。
2.基于ppca-svdd的过程监控模型中统计量的构造
采用ppca-svdd建模方法,对样本数为100的训练数据进行建模,样本数为100的数据进行测试。其具体的模型参数如下:
(1)首先对训练数据进行pca建模,产生六个主元,按式(3)计算加权矩阵具体如下:
根据加权值大于该变量所对所有加权值的均值,即选中该加权值所对应的向量构造子空间这一原理,每个变量选取的主元结果如下:
变量x1:p2,p3,p5
变量x2:p2,p3
变量x3:p1,p6
变量x4:p1,p6
变量x5:p1,p2,p3,p5
变量x6:p1,p4
由此,对应6个变量生成6个子空间,对每个变量实现分散监控。每个子空间的转换矩阵为:
空间1:
空间2:
空间3:
空间4:
空间5:
空间6:
(2)核函数k(·)中,s2=100;
(3)svdd模型中,参数c=1.2;
(4)由各子空间统计量构成的svdd模型,产生的参数值如下:
β值为0.3006,0.4931,0.6545,0.8119,0.9374,0;超球体半径r=0.216。
上述通过实例描述了,基于工业废水处理系统,通过测量得到的进水区溶氧量、好氧区悬浮体含量、进水口流量、出水口流量、化学需氧量、以及出水口悬浮体含量,实时、在线监测系统运行状态。
由上述例子得到的模型,下面是一组实时收集到的测试数据样本:
经归一化计算得到:
通过(10)式,计算得到该实时样本的统计量为0.3322。该值小于1,认为是该时刻系统处于正常状态。对应于100个测试样本的dr统计量计算结果如下:
计算结果中加粗数据表示该点超过控制限1,为不正常数据。第81点处的统计量为15.5309,明显超过控制限。该时刻的过程数据被用来做故障诊断,计算出6个变量的贡献率分别为:
0.315,2.031,0.929,2.743,46.401,0.972
由以上诊断结果可见,变量x5对此故障的贡献率最大,故为废水处理过程中的化学需氧量发生了变量。
- 还没有人留言评论。精彩留言会获得点赞!