采用模式识别技术识别耐碳青霉烯类大肠杆菌的方法与流程
本发明涉及医药工程技术领域,特别是涉及采用模式识别技术识别耐碳青霉烯类大肠杆菌的方法。
背景技术:
肠杆菌科细菌是临床上常见的致病菌,主要包括大肠杆菌、肺炎克雷伯菌等。目前,临床上使用的亚胺培南等碳青霉烯类抗生素被认为是治疗该耐药菌最有效的抗菌药物,也被认为是治疗的最终方法。但是随着此类抗生素的使用,碳青霉烯类抗生素耐药肠杆菌科细菌不断出现,极大的限制了此类抗生素的使用。其中,耐碳青霉烯类抗生素的大肠杆菌耐药率也已经由早年的零上升到1%,致使临床治疗面临巨大困难。
耐碳青霉烯类药物的大肠杆菌鉴定的方法主要包括革兰氏染色、生化和血清学方法,这些方法对于细菌耐药性的鉴定仍然必不可少,但是都存在分析周期较长、难以自动化,提供的信息较少及难以满足鉴定的要求等缺点。近些年,质谱技术是目前发展较快的一种化学分析技术,已经发展为高灵敏度、高通量和高准确性的技术,样品处理简单、快速,并且能提供复杂样品中各组分的分子量信息,正在成为系统细菌学研究人员的新工具。电喷雾-静电场轨道阱质谱(esi-orbitrap-ms)因其具有足够高的分辨率(1500da时分辨率在10万以上),可以促进复杂体系中有机质的更加精确和全面的分析。同时,电喷雾离子源(esi)更适用于分析中高等极性的化合物,主要产生单电荷离子,分析的化合物分子量一般小于1500da。相对于普通质谱仪器,高分辨质谱能获得大量的分析数据。但是,如何从大量的orbitrap-ms数据中高效、深入地获取复杂体系组成和分子结构信息面临巨大的挑战。
模式识别方法结合质谱技术,使快速发展的计算机技术为解决数据的信息学问题带来了契机。通过模式识别方法,科研工作者可以快速、准确、最大限度地获取分析样品的各种信息。模式识别是通过计算机运用统计学方法对各类渠道所获得的海量数据进行处理,从看似杂乱无章的数据中提炼出有用的信息部分,建立识别模型。模式识别主要是对数据进行分类加工,包括特征选择、特征提取和数据维数压缩来决定事物的类别,进而制定识别标准。模式识别在化学相关学科中的应用主要在病历数据分析、医疗诊断、生物分类、药物和生物活性物质的构效关系及药物设计、质量控制和生产管理等。模式识别常用的方法主要是多变量统计算法,包括非监督型多变量统计、主要是主成分分析(pca)和聚类分析(hca)等。监督型多变量统计、主要是偏最小二乘法判别分析(pls-da)和人工神经网络(ann)等方法被广泛应用于鉴别各个类型的样本。单变量统计如t检验和倍率变化能对单个变量进行检验,判断其在统计学上是否有显著性差异。
技术实现要素:
为了克服上述现有技术的不足,本发明提供了采用模式识别技术识别耐碳青霉烯类大肠杆菌的方法。
本发明所采用的技术方案是:采用模式识别技术识别耐碳青霉烯类大肠杆菌的方法,包括以下步骤:
a、采集大肠杆菌:按照要求,规范采集患者的细菌样本,采集后立即于-80℃冷冻保存;
b、提取大肠杆菌中代谢物和多肽:取-80℃保存的菌株,用枪头进行划线,并放入生化培养箱中,孵育过夜,将培养皿中的菌体完全移入到ep管中,并向ep管中加入pbs洗涤液,用涡旋混合仪使其混合均匀,放入冷冻离心机中离心,弃上清液,重复上述实验2次;将洗涤好的菌体放入-20℃保存,并加入尿素,混合后破碎菌体,离心,取上清;向上清液中加入丙酮,置于-20℃,沉淀过夜;取沉淀完全的样品,离心,ep管中的上清液,即为大肠杆菌代谢物样品,沉淀即为大肠杆菌蛋白质样品;
加碳酸氢铵和尿素于蛋白质样品中,溶解蛋白,离心,取上清,用bca法测蛋白浓度。取蛋白,加入(三(2-羧乙基)膦盐酸盐)tcep,ep管用封口膜封紧,95℃金属浴放置5min,取出后降温至室温;用碳酸氢铵稀释10倍,加入胰蛋白酶,37℃生化培养箱中孵育过夜;向已经酶解的蛋白样品中加入甲酸,使其ph为3左右,终止酶解,-20℃保存,待orbitrap-ms检测;每株大肠杆菌均设置3个生物学重复;
c、orbitrap-ms分析检测:检测前要先用仪器校正液对仪器进行校正,取代谢物用acn:h2o=1:1的0.1%的甲酸混合溶剂稀释,用进样针进样检测,其余的代谢物均用相同的方法进行处理;多肽样品检测时,仪器校正同代谢物样品一样,然后取多肽样品用acn:h2o=9:1的0.1%的甲酸混合溶剂稀释,用进样针进样检测,其余的多肽样品均用相同的方法进行处理;
d、orbitrap-ms数据处理分析:在分析前将24个多肽和24个代谢物经过筛选后得到的数据汇总在一个合并表内,并使用excel对数据进行预处理,合并和筛选;
e、使用r语言软件和自己编写的程序对数据进行模式识别分析。
进一步地,上述步骤a中采集的细菌的编号分别为:耐碳青霉烯类大肠杆菌编号为r1,r2,r3,r4,敏感大肠杆菌编号为s1,s2,s3,s4。
进一步地,上述步骤d中采用“80%规则”对数据进行筛选,删除缺失值过多的变量,删除在所有组别中(如耐药组和敏感组)中出现频率都小于80%的离子。
进一步地,上述步骤c中24个代谢物和24个多肽均在96h内检测完毕。
与现有技术相比,本发明的有益效果是:
(1)运用orbitrap-ms的高分辨率和高灵敏度的特点,从分子层面更精确地研究碳青霉烯类大肠杆菌耐药菌株与敏感菌株之间的差异。
(2)通过评估比较建立的不同的模式识别模型,opls-da能实现对碳青霉烯类大肠杆菌耐药菌株和敏感菌株的快速准确鉴定。
(3)根据单变量统计筛选出的在统计学上有显著差异化合物,为阐明大肠杆菌耐药机制提供了理论基础。
附图说明
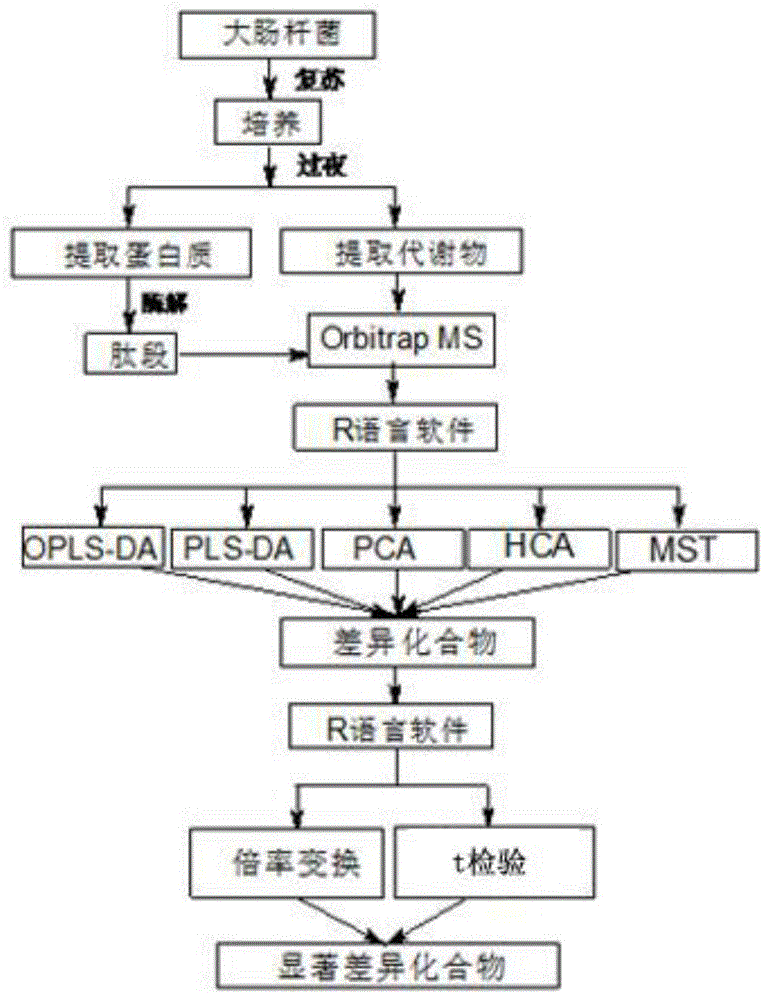
图1为本发明采用模式识别技术识别耐碳青霉烯类大肠杆菌的方法的流程图。
具体实施方式
为了加深对本发明的理解,下面结合附图和实施例对本发明进一步说明,该实施例仅用于解释本发明,并不对本发明的保护范围构成限定。
如图1所示,采用模式识别技术识别耐碳青霉烯类大肠杆菌的方法,包括以下步骤:
1)大肠杆菌的来源:
所有细菌样本均按照要求,依据规范、合理的操作流程采集提供,采集后立即于-80℃冷冻保存。细菌的编号分别为:耐碳青霉烯类大肠杆菌编号为r1,r2,r3,r4,敏感大肠杆菌编号为s1,s2,s3,s4。
2)试剂与仪器
主要试剂与药品
主要仪器与设备
3)大肠杆菌中代谢物和多肽的提取步骤(experimentalpr℃edure)
碳青霉烯类大肠杆菌的耐药菌株和敏感菌株均取自徐州医科大学附属医院检验科。取-80℃保存的菌株,用枪头进行划线。首先,将枪头用酒精灯烧成圆球状,蘸取菌落,将其接种于血琼脂平板培养皿上,划线,放入37℃生化培养箱中,孵育过夜。取出已经复苏的细菌,将枪头烧成圆球状,轻轻刮取培养皿中的菌体,置于加有少量pbs洗涤液的ep管中,重复上述操作,直至培养皿中的菌体尽可能完全移入到ep管中。向放有菌体的ep管中加入pbs洗涤液,用涡旋混合仪使其混合均匀,放入冷冻离心机中,6000rmp,10min,4℃,离心,弃上清液。重复上述实验2次。将洗涤好的菌体放入-20℃保存。取-20℃保存的菌体,加入100μl8m尿素,用涡旋混合仪混合均匀。然后,放入超声波细胞粉碎机(80w,10s,10s,10次)破碎菌体。破碎完全的菌体放入冷冻离心机,离心,15000rmp,20min,4℃,取上清。然后,向上清液中按1:4体积比加入400μl丙酮,轻轻震荡,-20℃,沉淀过夜。取沉淀完全的样品,离心,6000rmp,5min,4℃,取上清于心的ep管中,即为大肠杆菌代谢物样品,沉淀即为大肠杆菌蛋白质样品。代谢物置于-20℃保存,待orbitrap-ms检测。
加400μl50mmol碳酸氢铵和100ml8m尿素于蛋白质样品中,溶解蛋白,5min,10000rmp,4℃离心,取上清。用bca法测蛋白浓度。取100μg蛋白,加20μl0.1mol/l(三(2-羧乙基)膦盐酸盐)tcep,40μl0.1mol/l2-chloroacetamide,ep管用封口膜封紧,95℃金属浴放置5min,取出后降温至室温。用50mmol碳酸氢铵稀释10倍,加入5μl1μg/μl胰蛋白酶,对蛋白质进行酶解,37℃生化培养箱中孵育过夜。向已经酶解的蛋白样品中加入甲酸,使其ph为3左右,终止酶解,-20℃保存,待orbitrap-ms检测。每株大肠杆菌均设置3个生物学重复。
4)orbitrap-ms分析检测(instrumentalanalysis)
代谢物和多肽检测采用美国thermofisher公司生产的q-exactiveorbitrap-ms进行分析。24个代谢物和24个多肽均在96h内检测完毕。检测前要先用仪器校正液对仪器进行校正,以保证质量轴的精确度。然后,取5μl代谢物用acn:h2o=1:1的0.1%的甲酸混合溶剂稀释至500μl,用进样针进样检测,其余的代谢物均用相同的方法进行处理。多肽样品检测时,仪器校正同代谢物样品一样,然后取5μl多肽样品用acn:h2o=9:1的0.1%的甲酸混合溶剂稀释至500μl,用进样针进样检测,其余的多肽样品均用相同的方法进行处理。
5)orbitrap-ms数据处理分析
对orbitrap-ms分析得到的数据,使用thermoxcaliburroadmapsoftwaredataanalysis3.0软件进行解析。24个多肽和24个代谢物经过筛选后得到的数据在分析前需要汇总在一个合并表内,数据预处理过程可以通过使用excelvisualbasicforapplications(vba)功能快速实现。数据合并后再次使用excelvisualbasicforapplications(vba)功能对数据进行筛选。此次筛选是利用在组学分析中比较常用的方法,“80%规则”进行删除缺失值过多的变量。“80%规则”是指删除在所有组别中(如耐药组和敏感组)中出现频率都小于80%的离子。
6)使用r语言软件和自己编写的程序对数据进行模式识别分析。
本发明的实施例公布的是较佳的实施例,但并不局限于此,本领域的普通技术人员,极易根据上述实施例,领会本发明的精神,并做出不同的引申和变化,但只要不脱离本发明的精神,都在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!