一种微博突发话题检测方法及装置与流程
本发明涉及网络信息挖掘领域,特别是涉及一种微博突发话题检测方法及装置。
背景技术:
微博是近年来兴起的web2.0新媒体,用户可以通过手机、即时通信工具、Email、Web等媒介在个人微博上发布140字以内的文本信息及图片、影音等多媒体内容,展现个人最新动态,分享身边实时信息。微博平台上每天产生数量庞大的信息,截至2013年年底,我国微博用户总用户量已经突破13亿,日均用户发帖量超过2亿。而且,由于微博与多种媒体关联,信息发表、转发非常便捷,微博成为信息传播速度最快的媒体。社会上许多突发性话题,往往在微博平台上首发,借助其好友转发机制迅速传播,引起广泛的社会共鸣,进而波及传统媒体如新闻、论坛、博客等,产生巨大的社会影响。因此,微博平台上的社会突发话题检测技术对于最新社会热点发现、网络民意的及时感知、舆情检测、应急处置等方面都具有积极的现实意义。
但不同于传统的新闻文档,微博数据具有内容短小、数量巨大、信息零碎、用语不规范等显著特性,这些新特点为面向微博的突发话题检测技术带来了以下挑战:
微博信息用词不规范,须及时识别微博新词,每个用户随时都可以发表微博,信息具有原创性和时效性的同时,也表现出草根性和随意性,用词口语化、不规范现象严重,简称、缩略语大量存在。随着网络事件的事态发展,微博空间不断涌现出表达话题核心语义的新词,只有及时动态地发现这些重要新词,才能准确地表达话题内容,因此,新词的不断涌现,对突发话题发现技术提出 了新的挑战。
微博信息数量庞大,突发话题容易被信息噪音淹没,微博用户根据个人兴趣每天发表大量身边发生的事件,信息琐碎零散,基于好友转发的传播机制,导致海量的信息冗余,因此,对于突发话题,虽然其在话题相关的微博数量上增长迅猛,但总量有限,很容易被各种噪声信息、热点话题等所淹没,难以识别。
然而,传统的突发话题发现方法是以词典中的词语作为特征,从话题随时间的动态特性出发,提取突发词语来实现的,这些方法在微博环境下不适用,表现在以下两方面:一方面词典中词语不能准确反映突发事件的关键特征,微博信息实时性很强,突发事件往往是新发生的事件,需要用新词来描述;另一方面微博信息短小,用静态的词语特征来表示微博信息,将带来严重的特征稀疏问题,同时微博数量巨大后续计算复杂度高,所以,需要针对微博信息的特点,发明微博突发话题检测方法。
技术实现要素:
本发明提供一种微博突发话题检测方法及装置,用以解决目前微博突发话题难以识别的问题。
根据本发明的一个方面,提供了一种微博突发话题检测方法,包括:提取指定的微博数据集合中的特征项,特征项为包含具体语义的语言单元;确定特征项在微博数据集合的文本中的流通度以及特征项当前的热度;以流通度为质量参数项,以热度为位置参数项对特征项进行动力学建模,得到特征项的当前能量和加速度;在得到的能量以及加速度分别大于第一预设值以及第二预设值时,检测突发特征项;根据检测到的突发特征项在同一条微博中同时出现的情况计算突发特征项之间的互信息;当互信息大于第三阈值时,对突发特征项进行合并,得到突发话题。
其中,提取指定的微博数据集合中的特征项包括:提取指定的微博集合中 的重复字符串;提取重复字符串所在的文本中位于重复字符串前面的词语,得到第一邻接集合,提取重复字符串所在的文本中位于重复字符串后面的词语,得到第二邻接集合;确定第一邻接集合以及第二邻接集合中元素的个数;在第一邻接集合以及第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为特征项。
其中,以流通度为质量参数项,以热度为位置参数项对特征项进行动力学建模,得到特征项当前的能量和加速度,包括:根据统计特征项i在选定的历史微博数据集合中的词频tf以及逆向文件频率idf按照公式1计算得到质量参数项m:公式1:m(i)=tf(i)×idf(i);根据特征项在时刻t出现的频次tf(t,i)、在时刻t出现的文档频次df(t,i)、以及在时刻t微博内容包含特征项的博主数af(t,i)按照公式2计算得到位置参数项x;公式2:x(t,i)=a×tf(t,i)+b×df(t,i)+c×af(t,i);其中a、b以及c是调节参数;根据质量参数项、位置参数项以及动力学模型,使用速度计算公式、加速度计算公式以及动量计算公式计算得到特征项的当前能量和加速度。
其中,当互信息大于第三阈值时,对突发特征项进行合并,得到突发话题,包括:在每两个突发特征之间的互信息大于第三阈值时,将该两个突发特征合并为一个特征项组;待第一次合并完成后,将与特征项组内的突发特征之间的互信息大于第三阈值的突发特征合并到该特征项组内,直至不存在任何突发特征与特征项组内的突发特征之间的互信息大于指定阈值。
其中,根据检测到的突发特征项在微博中同时出现的情况计算突发特征项之间的互信息,包括:采用如下公式计算突发特征项之间的互信息:其中,P(i)代表特征i在时间窗口的文档中出现的概率,P(i,j)代表特征i和j在时间窗口内共现的概率。
根据本发明的另一个方面,提供了一种微博突发话题检测装置,包括:
提取模块,用于提取指定的微博数据集合中的特征项,特征项为包含具体语义的语言单元;确定模块,用于确定特征项在微博数据集合的文本中的流通 度以及特征项当前的热度;建模模块,用于以流通度为质量参数项,以热度为位置参数项对特征项进行动力学建模,得到特征项的当前能量和加速度;检测模块,用于在得到的能量以及加速度分别大于第一预设值以及第二预设值时,检测突发特征项;计算模块,用于根据检测到的突发特征项在同一条微博中同时出现的情况计算突发特征项之间的互信息;合并模块,用于当互信息大于第三阈值时,对突发特征项进行合并,得到突发话题。
其中,提取模块包括:第一提取单元,用于提取指定的微博集合中的重复字符串;第二提取单元,用于提取重复字符串所在的文本中位于重复字符串前面的词语,得到第一邻接集合,提取重复字符串所在的文本中位于重复字符串后面的词语,得到第二邻接集合;第一确定单元,用于确定第一邻接集合以及第二邻接集合中元素的个数;第二确定单元,用于在第一邻接集合以及第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为特征项。
其中,建模模块,包括:
第一计算单元,用于根据统计特征项i在选定的历史微博数据集合中的词频tf以及逆向文件频率idf按照公式1计算得到质量参数项m;公式1:m(i)=tf(i)×idf(i);第二计算单元,用于根据特征项在时刻t出现的频次tf(t,i)、在时刻t刻出现的文档频次df(t,i)、以及在时刻t微博内容包含特征项的博主数af(t,i)按照公式2计算得到位置参数项x;公式2:x(t,i)=a×tf(t,i)+b×df(t,i)+c×af(t,i);其中a、b以及c是调节参数;第三计算单元,用于根据质量参数项、位置参数项以及动力学模型,使用速度计算公式、加速度计算公式以及动量计算公式计算得到特征项的当前能量和加速度。
其中,合并模块包括:第一合并单元,用于在每两个突发特征之间的互信息大于第三阈值时,将该两个突发特征合并为一个特征项组;第二合并单元,用于待第一次合并完成后,将与特征项组内的突发特征之间的互信息大于第三阈值的突发特征合并到该特征项组内,直至不存在任何突发特征与特征项组内的突发特征之间的互信息大于指定阈值。
其中,计算模块具体用于:采用如下公式计算突发特征项之间的互信息:其中,P(i)代表特征i在时间窗口的文档中出现的概率,P(i,j)代表特征i和j在时间窗口内共现的概率。
本发明实施例的方案,基于动量模型提取微博的突发特征,并通过对突发特征的合并来得到微博的突发话题,该方案能够提高微博突发话题检测的准确率。
附图说明
图1是本发明实施例1提供的微博突发话题检测方法的流程图;
图2是本发明实施例2提供的微博突发话题检测方法的流程图;
图3是本发明实施例3提供的微博突发话题检测装置的结构框图。
具体实施方式
为了解决现有技术微博突发话题难以识别的问题,本发明提供了一种微博突发话题获取方法及装置,以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
实施例1
本实施例提供了一种微博突发话题检测方法,该方法用于实现微博突发话题的识别以及获取,如图1所示,该方法包括如下步骤:
步骤101:提取指定的微博数据集合中的特征项,特征项为包含具体语义的语言单元;
在该步骤中,提取指定的微博数据集合中的特征项包括:提取指定的微博集合中的重复字符串;提取重复字符串所在的文本中位于重复字符串前面的词语,得到第一邻接集合,提取重复字符串所在的文本中位于重复字符串后面的词语,得到第二邻接集合;确定第一邻接集合以及第二邻接集合中元素的个数; 在第一邻接集合以及第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为特征项。
步骤102:确定特征项在微博数据集合的文本中的流通度以及特征项当前的热度;
步骤103:以流通度为质量参数项,以热度为位置参数项对特征项进行动力学建模,得到特征项的当前能量和加速度;
在该步骤中:以流通度为质量参数项,以热度为位置参数项对特征项进行动力学建模,得到特征项当前的能量和加速度具体包括:
根据统计特征项i在选定的历史微博数据集合中的词频tf以及逆向文件频率idf按照公式1计算得到质量参数项m:
公式1:m(i)=tf(i)×idf(i);
根据特征项在时刻t出现的频次tf(t,i)、在时刻t出现的文档频次df(t,i)、以及在时刻t微博内容包含特征项的博主数af(t,i)按照公式2计算得到位置参数项x;
公式2:x(t,i)=a×tf(t,i)+b×df(t,i)+c×af(t,i);
其中a、b以及c是调节参数;
根据质量参数项、位置参数项以及动力学模型,使用速度计算公式、加速度计算公式以及动量计算公式计算得到特征项的当前能量和加速度。
步骤104:在得到的能量以及加速度分别大于第一预设值以及第二预设值时,检测突发特征项;
步骤105:根据检测到的突发特征项在同一条微博中同时出现的情况计算突发特征项之间的互信息;
在该步骤105中,根据检测到的突发特征项在微博中同时出现的情况计算突发特征项之间的互信息,包括:
采用如下公式计算突发特征项之间的互信息:
其中,P(i)代表特征i在时间窗口的文档中出现的概率,P(i,j)代表特征i和j在时间窗口内共现的概率。
步骤106:当互信息大于第三阈值时,对突发特征项进行合并,得到突发话题。
在该步骤106中:当互信息大于第三阈值时,对突发特征项进行合并,得到突发话题,包括:在每两个突发特征之间的互信息大于第三阈值时,将该两个突发特征合并为一个特征项组;待第一次合并完成后,将与特征项组内的突发特征之间的互信息大于第三阈值的突发特征合并到该特征项组内,直至不存在任何突发特征与特征项组内的突发特征之间的互信息大于指定阈值。
实施例2
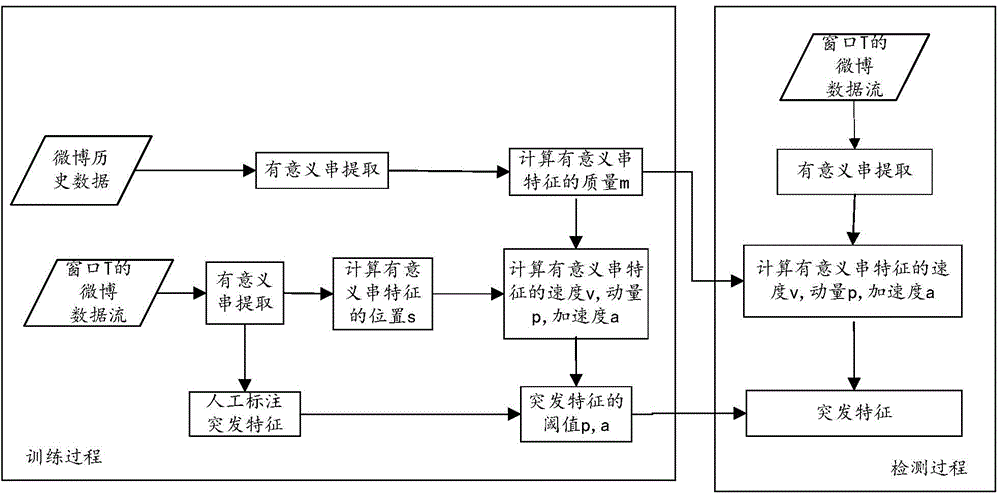
为解决上述技术问题,本实施例通过公开更多的技术细节结合附图2,对上述实施例中的微博突发话题发现方法进行进一步说明。
步骤1:动态提取指定的时间窗口内微博信息流的有意义串特征,即有意义字符串,作为局部微博信息的动态特征,利用微博信息的重复特性,结合字符串的上下文邻接分析,提取微博信息中的有意义串。
将微博信息看作时间序列上的文本流,设置观察时间窗口T,将时间窗口T内的微博信息作为文档集合D={D1,D2,D3,…},提取D中的有意义字符串,形成窗口T内微博信息的特征空间S,随着时间窗口的推移,特征空间S将动态变化。
提取的有意义串是指包含具体语义,灵活独立的语言单元,能在多种不同语境中使用的字符串,包括了未登录的新词和命名实体,以及有意义的词组和短语,具有语义完整性,突破了词典中词语的界限。
步骤1中的邻接分析是指分析有意义字符串的上下文语言环境,能够应用于多种不同的上下文环境,具有语用灵活性的字符串是有意义字符串。
上下文邻接分析指提取重复串的邻接集合,计算邻接类别,邻接集合和邻接种类定义如下:
邻接集合:分为左邻接集合NBL和右邻接集合NBR,分别指真实文本中,与字符串S左边或者右边相邻的词语的集合。当字符串做为一个句子的开始,其左邻接元素记为BOS,做为句子的结束时,其右邻接元素记为EOS。
邻接种类:分为左邻接种类VL和右邻接种类VR,分别指左邻接集合中和右邻接集合种元素的数目,它们反映了字符串上文和下文语境种类的多少。
选取左邻接类别和右邻接类别中的较小值记为minVN。当重复串的minVN大于阈值TVN时,该字符串就是有意义字符串。阈值TVN的选取与微博信息的规模相关,取值应大于2,本实施例优选的取值为3,时间窗口T优选的取值为1天。
步骤2:对微博特征借鉴动力学原理建模,类似物体的运动过程,建模特征随事件动态变化的动力学指标,根据特征的当前能量大小和加速度检测突发特征。
步骤2中,由于微博突发话题的产生、发展、高潮、衰落、消失的过程,与动力学中的物体从静止开始运动,速度加快,再到速度变缓,最终停止的过程类似,在物理学中,动量是与物体的质量和速度相关的物理量,描述这个物体在它运动方向上保持运动的趋势,因此微博特征的动力学模型可以借鉴动力学中的动量定义对微博特征建模,将特征在大规模统计文本中的流通度作为特征的“质量”m,将特征当前时刻的热度作为特征的“位置”x,来计算特征在当前时刻的速度、动量和加速度,直接反映了特征在事件发展中的能量大小和变化趋势。
微博的突发特征是与时间相关的,指在某一时刻突然爆发,大量涌现的特征,突发特征具有两方面的特性,一个是当前时刻的瞬时能量比较大,另一个是与历史情况比较,加速度比较大,有迅速增长的趋势,这两方面正好与动量以及加速度相对应.所以,基于特征的动量模型能够检测出突发特征。
特征的“质量”m指特征的重要性,它不随时间变化,是特征的基本属性,在一段较长时间内基本恒定,该值采用传统的TF-IDF来衡量,通过统计特征 在大量信息中的频次tf和文档频次idf值计算得到,特征i的质量m(i)=tf(i)×idf(i);
特征的“位置”x与时间相关,指特征在某一时刻的流通度或关注度,随时间动态变化该值与特征在时刻t出现的频次、文档频次以及参与博主数等相关,计算公式如下:
x(t,i)=a×tf(t,i)+b×df(t,i)+c×af(t,i),
其中,x(t,i)表示特征i在时刻t的“位置”,tf(t,i)表示特征i在时刻t出现的频次,df(t,i)表示特征i在时刻t出现的文档频次,af(t,i)表示在时刻t的微博内容包含特征i的博主数,a、b、c是调节参数。
上述定义中,特征的“质量”m是在大量信息中统计得到的,反映了特征在普通文本流中的重要性,特征的“位置”x是与时间相关的值,反映了特征在时刻t的热度,由这两个基本的定义,可以计算特征i在时刻t的一系列物理值:
速度
加速度
动量p=m×v;
经过动量模型建模后,特征的动量p反映了特征在时刻t的能量大小及变化趋势,加速度a反映了特征在时刻t与时刻t-1的二阶变化趋势,即时刻t的增长率与时刻t-1的增长率相比是加快还是放缓。
突发特征检测过程分为训练阶段和检测阶段,训练阶段有两方面,一方面是从大量的微博历史数据中计算得到特征的质量m,另一方面是在标注的微博突发特征集合上,训练得到突发特征提取的动量p和加速度a的阈值参数,检测阶段利用训练好的质量m来计算特征的速度v,加速度a和动量p,根据动量p和加速度a的阈值参数来检测突发特征。
步骤3:根据突发特征在微博信息中的共现的情况计算两两突发特征之间的互信息,根据互信息对突发特征合并,发现突发话题。
在该步骤中,对步骤2检测出的突发特征进行合并,每个突发特征对应一个广义的话题,这些广义话题之间可能存在交叉重复现象,所以,还需要对这些突发特征进行合并,多个突发特征共同来描述一个话题,形成具体明确的突发话题。
特征之间的互信息指特征在相同微博信息中的共现情况,体现了两个特征的依赖程度,互信息越高,特征的相关度越高,描述同一话题的可能性越大,考虑到话题的特征之间可能有交叉,一个突发特征有可能描述多个不同的话题,特征合并时需要计算突发特征两两之间的互信息,互信息大于一定阈值时,将特征合并,经过多轮层次合并后,最后得到突发话题。
两个特征的互信息反映了特征在同一条微博信息中的共现情况,将互信息作为突发特征距离的度量,计算公式如下:
P(i)代表特征i在观察时间窗口的文档中出现的概率,P(i,j)代表特征i和j在时间窗口内共现的概率。
特征合并的阈值D在标注的突发特征集合中训练得到。首轮合并时,只要两个特征之间的互信息大于D,就将特征合并为一个组。下一轮合并时,只要特征与一组特征中的一个特征之间的互信息大于D,就将特征合并入这个组。一个特征可以并入多个组。直到没有互信息大于D的特征可合并,合并完毕。合并后的每个组中有两个或多个突发特征,构成一个突发话题。
实施例3
本实施例提供了一种微博突发话题检测装置,该装置用于实现上述实施例1以及实施例2提供的微博突发话题检测方法,如图3所示,该装置20包括如下组成部分:
提取模块21,用于提取指定的微博数据集合中的特征项,特征项为包含具体语义的语言单元;
确定模块22用于确定特征项在微博数据集合的文本中的流通度以及特征 项当前的热度;
建模模块23,用于以流通度为质量参数项,以热度为位置参数项对特征项进行动力学建模,得到特征项的当前能量和加速度;
检测模块24,用于在得到的能量以及加速度分别大于第一预设值以及第二预设值时,检测突发特征项;
计算模块25,用于根据检测到的突发特征项在同一条微博中同时出现的情况计算突发特征项之间的互信息;
合并模块26,用于当互信息大于第三阈值时,对突发特征项进行合并,得到突发话题。
其中,提取模块21具体可以包括:第一提取单元,用于提取指定的微博集合中的重复字符串;第二提取单元,用于提取重复字符串所在的文本中位于重复字符串前面的词语,得到第一邻接集合,提取重复字符串所在的文本中位于重复字符串后面的词语,得到第二邻接集合;第一确定单元,用于确定第一邻接集合以及第二邻接集合中元素的个数;第二确定单元,用于在第一邻接集合以及第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为特征项。
其中,建模模块23具体可以包括:第一计算单元,用于根据统计特征项i在选定的历史微博数据集合中的词频tf以及逆向文件频率idf按照公式1计算得到质量参数项m;公式1:m(i)=tf(i)×idf(i);第二计算单元,用于根据特征项在时刻t出现的频次tf(t,i)、在时刻t刻出现的文档频次df(t,i)、以及在时刻t微博内容包含特征项的博主数af(t,i)按照公式2计算得到位置参数项x;公式2:x(t,i)=a×tf(t,i)+b×df(t,i)+c×af(t,i);其中a、b以及c是调节参数;第三计算单元,用于根据质量参数项、位置参数项以及动力学模型,使用速度计算公式、加速度计算公式以及动量计算公式计算得到特征项的当前能量和加速度。
其中,上述计算模块25具体用于:采用如下公式计算突发特征项之间的 互信息:其中,P(i)代表特征i在时间窗口的文档中出现的概率,P(i,j)代表特征i和j在时间窗口内共现的概率。
其中,上述合并模块26包括:第一合并单元,用于在每两个突发特征之间的互信息大于第三阈值时,将该两个突发特征合并为一个特征项组;第二合并单元,用于待第一次合并完成后,将与特征项组内的突发特征之间的互信息大于第三阈值的突发特征合并到该特征项组内,直至不存在任何突发特征与特征项组内的突发特征之间的互信息大于指定阈值。
尽管为示例目的,已经公开了本发明的优选实施例,本领域的技术人员将意识到各种改进、增加和取代也是可能的,因此,本发明的范围应当不限于上述实施例。
- 还没有人留言评论。精彩留言会获得点赞!