工单处理方法及装置与流程
本申请涉及数据处理技术领域,尤其涉及一种工单处理方法及装置。
背景技术:
随着数据处理技术的飞速发展,在企业内部和企业外部会产生工单也越来越多,例如,通过在线机器人、热线电话、网站等等都会产生很多工单。目前,这些工单都是通过简单的工单流程程序和数据库来进行处理的。
按照相关的工单处理方法,都是直接将工单保存在数据库中,当用户需要处理工单时,需要从数据库中获取该工单,再进行处理,当数据库中的数据量非常大或者数据库的访问压力非常大,工单查询耗时非常长,这就会严重影响工单处理效率,进而严重影响用户体验。
技术实现要素:
本申请实施例提供一种工单处理方法及装置,用以解决相关的工单处理方法中存在的工单查询耗时非常长,严重影响工单处理效率和用户体验的问题。
根据本申请实施例,提供一种工单处理方法,包括:
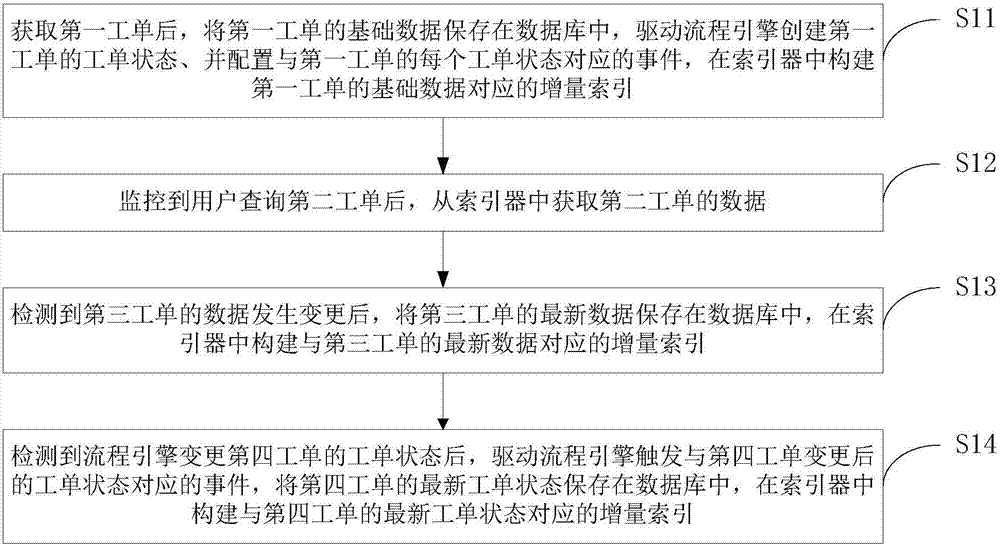
获取第一工单后,将所述第一工单的基础数据保存在数据库中,驱动流程引擎创建所述第一工单的工单状态、并配置与所述第一工单的每个工单状态对应的事件,在索引器中构建所述第一工单的基础数据对应的增量索引;
监控到用户查询第二工单后,从所述索引器中获取所述第二工单的数据;
检测到第三工单的数据发生变更后,将所述第三工单的最新数据保存在所述数据库中,在所述索引器中构建与所述第三工单的最新数据对应的增量索引;以及,
检测到所述流程引擎变更第四工单的工单状态后,驱动所述流程引擎触发与所述第四工单变更后的工单状态对应的事件,将所述第四工单的最新工单状态保存在所述数据库中,在所述索引器中构建与所述第四工单的最新工单状态对应的增量索引。
可选的,还包括:
以设定周期在所述索引器中构建所述数据库的全部数据对应的全量索引。
具体的,在索引器中构建所述第一工单的基础数据对应的增量索引,具体包括:
向所述索引器发送第一通知消息,所述第一通知消息中携带所述第一工单的基础数据,以使所述索引器构建所述第一工单的基础数据对应的增量索引。
具体的,从所述索引器中获取所述第二工单的数据,具体包括:
向所述索引器发送携带所述第二工单的标识信息的查询请求,以使所述索引器根据所述第二工单的标识信息查询所述第二工单的数据并发送;
接收所述索引器发送的所述第二工单的数据。
具体的,在所述索引器中构建与所述第三工单的最新数据对应的增量索引,具体包括:
向所述索引器发送第二通知消息,所述第二通知消息中携带所述第三工单的最新数据,以使所述索引器构建所述第三工单的最新数据对应的增量索引。
具体的,在所述索引器中构建与所述第四工单的最新工单状态对应的增量索引,具体包括:
向所述索引器发送第三通知消息,所述第三通知消息中携带所述第四工单的最新工单状态,以使所述索引器构建所述第四工单的最新工单状态对应的增量索引。
根据本申请实施例,还提供一种工单处理装置,包括:
第一处理模块,用于获取第一工单后,将所述第一工单的基础数据保存在数据库中,驱动流程引擎创建所述第一工单的工单状态、并配置与所述第一工单的每个工单状态对应的事件,在索引器中构建所述第一工单的基础数据对应的增量索引;
获取模块,用于监控到用户查询第二工单后,从所述索引器中获取所述第二工单的数据;
第二处理模块,用于检测到第三工单的数据发生变更后,将所述第三工单的最新数据保存在所述数据库中,在所述索引器中构建与所述第三工单的最新数据对应的增量索引;以及,
第三处理模块,用于检测到所述流程引擎变更第四工单的工单状态后,驱动所述流程引擎触发与所述第四工单变更后的工单状态对应的事件,将所述第四工单的最新工单状态保存在所述数据库中,在所述索引器中构建与所述第四工单的最新工单状态对应的增量索引。
可选的,还包括:
构建模块,用于以设定周期在所述索引器中构建所述数据库的全部数据对应的全量索 引。
具体的,所述第一处理模块,用于在索引器中构建所述第一工单的基础数据对应的增量索引,具体用于:
向所述索引器发送第一通知消息,所述第一通知消息中携带所述第一工单的基础数据,以使所述索引器构建所述第一工单的基础数据对应的增量索引。
具体的,所述获取模块,用于从所述索引器中获取所述第二工单的数据,具体用于:
向所述索引器发送携带所述第二工单的标识信息的查询请求,以使所述索引器根据所述第二工单的标识信息查询所述第二工单的数据并发送;
接收所述索引器发送的所述第二工单的数据。
具体的,所述第二处理模块,用于在所述索引器中构建与所述第三工单的最新数据对应的增量索引,具体用于:
向所述索引器发送第二通知消息,所述第二通知消息中携带所述第三工单的最新数据,以使所述索引器构建所述第三工单的最新数据对应的增量索引。
具体的,所述第三处理模块,用于在所述索引器中构建与所述第四工单的最新工单状态对应的增量索引,具体用于:
向所述索引器发送第三通知消息,所述第三通知消息中携带所述第四工单的最新工单状态,以使所述索引器构建所述第四工单的最新工单状态对应的增量索引。
本申请实施例提供一种工单处理方法及装置,获取第一工单后,将所述第一工单的基础数据保存在数据库中,驱动流程引擎创建所述第一工单的工单状态、并配置与所述第一工单的每个工单状态对应的事件,在索引器中构建所述第一工单的基础数据对应的增量索引;监控到用户查询第二工单后,从所述索引器中获取所述第二工单的数据;检测到所述第三工单的数据发生变更后,将所述第三工单的最新数据保存在所述数据库中,在所述索引器中构建与所述第三工单的最新数据对应的增量索引;以及,检测到所述流程引擎变更第四工单的工单状态后,驱动所述流程引擎触发与所述第四工单变更后的工单状态对应的事件,将所述第四工单的最新工单状态保存在所述数据库中,在所述索引器中构建与所述第四工单的最新工单状态对应的增量索引。该方案中,将工单的数据存储在数据库中,驱动流程引擎创建并监控工单的工单流程,并在索引器中构建工单的数据对应的增量索引,当用户需要查询工单时,不是在数据库中查询,而是在索引器中进行查询,这就可以有效缓解数据库的访问压力,尤其是在处理海量工单时,可以有效减少工单查询耗时,提升工单处理效率和用户体验。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请实施例中一种工单处理方法的流程图;
图2为本申请实施例中s12的流程图;
图3为本申请实施例中一种工单处理装置的结构示意图。
具体实施方式
为了使本申请所要解决的技术问题、技术方案及有益效果更加清楚、明白,以下结合附图和实施例,对本申请进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
为了解决相关的工单处理方法中存在的工单查询耗时非常长,严重影响工单处理效率和用户体验的问题,本申请实施例提供一种工单处理方法,该方法可以但不限于应用在服务器中,该方法的流程如图1所示,包括如下步骤:
s11:获取第一工单后,将第一工单的基础数据保存在数据库中,驱动流程引擎创建第一工单的工单状态、并配置与第一工单的每个工单状态对应的事件,在索引器中构建第一工单的基础数据对应的增量索引。
通过热线电话、在线机器人、客服、各种平台等都可以创建工单,这些工单可以定义为第一工单。
在获取第一工单后,将第一工单的基础数据保存在数据库中,数据库可以但不限于是结构化查询语言(structuredquerylanguage,sql)分库分表数据库,sql分库分表数据库能够高效地存储海量工单的基础数据。第一工单的基础数据可以包括客户问题、提问时间、问题的来源、工单标识、处理客服标识等信息。
还可以驱动流程引擎创建第一工单的工单状态、并配置与第一工单的每个工单状态对应的事件,第一工单的所有工单状态也就是第一工单的生命周期,工单状态对应的事件可以为,当工单处于创建状态时给负责的客服发送旺旺、邮件等提醒消息,当工单处于完结状态时给客户发送旺旺、邮件等通知消息。流程引擎可以但不限于为工作流中间件(xbpm)。
同时,还可以在索引器张创建第一工单的基础数据对应的增量索引,以便于用户在索引器中查询第一工单的基础数据,索引器可以但不限于是tsearch索引器,tsearch索引器能够将多库多表的数据进行了整合来构建工单的数据对应的索引,提升了多维度索引的灵 活性,进一步降低了数据库查询的压力。
s12:监控到用户查询第二工单后,从索引器中获取第二工单的数据。
由于索引器中已经构建了工单的数据对应的索引,可以直接从索引器中查询第二工单的数据,尤其在查询海量工单时,可以有效降低数据库的访问压力,并且提高工单的查询效率。
s13:检测到第三工单的数据发生变更后,将第三工单的最新数据保存在数据库中,在索引器中构建与第三工单的最新数据对应的增量索引。
在工单的处理过程中,客服有可能介入处理工单,客服在与客户沟通的过程中,会产生很多数据,每次产生的数据都将会保存下来,并同步到数据库和索引器。由于工单状态没有变更,不会驱动流程引擎。一个工单可能不止被客服介入一次,每一次客服介入都会产生一条服务记录;如果一个客服不能完成,就将这个工单转接到同一个服务团队的其他客服,这里工单状态没有发生变更,不会驱动流程引擎。如果这个工单的服务内容超过了这个服务团队的责任范围,需要将这个工单转接的别的服务团队,生成一种新的工单,重新执行s11,并且会驱动流程引擎变更工单状态,执行s14。
s14:检测到流程引擎变更第四工单的工单状态后,驱动流程引擎触发与第四工单变更后的工单状态对应的事件,将第四工单的最新工单状态保存在数据库中,在索引器中构建与第四工单的最新工单状态对应的增量索引。
工单状态可以有多个,例如新建、修改、完结等等,在“新建”结束之后,可以驱动流程引擎将工单状态变更为“修改”,并触发“修改”相应的事件,在“修改”结束之后,可以驱动驱动流程引擎将工单状态变更为“完结”,并触发“完结”对应的事件。同时还会将工单的最新工作状态同步到数据库和索引器中。
上述s11、s12、s13、s14并没有严格的先后执行顺序,可以灵活根据监控到的触发条件来执行。
该方案中,将工单的数据存储在数据库中,驱动流程引擎创建并监控工单的工单流程,并在索引器中构建工单的数据对应的增量索引,当用户需要查询工单时,不是在数据库中查询,而是在索引器中进行查询,这就可以有效缓解数据库的访问压力,尤其是在处理海量工单时,可以有效减少工单查询耗时,提升工单处理效率和用户体验。该方案可以实现海量工单的生命周期管理、存储、快速多维度检索,提供了一套工单处理方案。
可选的,上述工单处理方法还包括:
以设定周期在索引器中构建数据库的全部数据对应的全量索引。
为了保证索引器中所有工单的数据的完整性和准确性,可以定期将数据库中的全部数 据同步到索引器中,在索引器中构建数据库的全部数据对应的全量索引,全量索引构建可以依托于云梯,即分布式计算集群(基于hive)。
具体的,上述s11中在索引器中构建第一工单的基础数据对应的增量索引的实现过程,具体包括:向索引器发送第一通知消息,第一通知消息中携带第一工单的基础数据,以使索引器构建第一工单的基础数据对应的增量索引。
第一通知消息可以但不限于采用notify消息,在索引器中构建第一工单的基础数据对应的增量索引可以有效提升工单的检索速度。
具体的,上述s12中从索引器中获取第二工单的数据的实现过程,如图2所示,具体包括:
s121:向索引器发送携带第二工单的标识信息的查询请求,以使索引器根据第二工单的标识信息查询第二工单的数据并发送。
当用户需要查询第二工单时,可以直接向索引器发送携带第二工单的标识信息的查询请求,索引器查询第二工单的的标识信息对应的数据然后发送给服务器。其中,第二工单的标识信息可以根据实际需要进行设定。
s122:接收索引器发送的第二工单的数据。
服务器接收索引器发送的第二工单的数据,从而实现查询第二工单的数据,由于通过索引器查询第二工单的数据,不是通过数据库查询,从而可以有效降低数据库的访问压力,提升工单查询效率。
具体的,上述s13中在索引器中构建与第三工单的最新数据对应的增量索引的实现过程,具体包括:向索引器发送第二通知消息,第二通知消息中携带第三工单的最新数据,以使索引器构建第三工单的最新数据对应的增量索引。
第二通知消息可以但不限于采用notify消息,在索引器中构建第三工单的最新数据对应的增量索引可以有效提升工单的检索速度。
具体的,上述s14中的在索引器中构建与第四工单的最新工单状态对应的增量索引的实现过程,具体包括:向索引器发送第三通知消息,第三通知消息中携带第四工单的最新工单状态,以使索引器构建第四工单的最新工单状态对应的增量索引。
第三通知消息可以但不限于采用notify消息,在索引器中构建第四工单的最新工单状态对应的增量索引可以有效提升工单的检索速度。
基于同一发明构思,本申请实施例还提供一种工单处理装置,该装置与如图1所示的工单处理方法相对应,该装置可以但不限于应用在服务器中,该装置的结构如3图所示, 包括第一处理模块31、获取模块32、第二处理模块33和第三处理模块34,其中:
上述第一处理模块31,用于获取第一工单后,将第一工单的基础数据保存在数据库中,驱动流程引擎创建第一工单的工单状态、并配置与第一工单的每个工单状态对应的事件,在索引器中构建第一工单的基础数据对应的增量索引;
上述获取模块32,用于监控到用户查询第二工单后,从索引器中获取第二工单的数据;
上述第二处理模块33,用于检测到第三工单的数据发生变更后,将第三工单的最新数据保存在数据库中,在索引器中构建与第三工单的最新数据对应的增量索引;以及,
上述第三处理模块34,用于检测到流程引擎变更第四工单的工单状态后,驱动流程引擎触发与第四工单变更后的工单状态对应的事件,将第四工单的最新工单状态保存在数据库中,在索引器中构建与第四工单的最新工单状态对应的增量索引。
该方案中,将工单的数据存储在数据库中,驱动流程引擎创建并监控工单的工单流程,并在索引器中构建工单的数据对应的增量索引,当用户需要查询工单时,不是在数据库中查询,而是在索引器中进行查询,这就可以有效缓解数据库的访问压力,尤其是在处理海量工单时,可以有效减少工单查询耗时,提升工单处理效率和用户体验。该方案可以实现海量工单的生命周期管理、存储、快速多维度检索,提供了一套工单处理方案。
可选的,上述工单处理装置还包括构建模块,用于以设定周期在索引器中构建数据库的全部数据对应的全量索引。
具体的,上述第一处理模块31,用于在索引器中构建第一工单的基础数据对应的增量索引,具体用于:
向索引器发送第一通知消息,第一通知消息中携带第一工单的基础数据,以使索引器构建第一工单的基础数据对应的增量索引。
具体的,上述获取模块32,用于从索引器中获取第二工单的数据,具体用于:
向索引器发送携带第二工单的标识信息的查询请求,以使索引器根据第二工单的标识信息查询第二工单的数据并发送;
接收索引器发送的第二工单的数据。
具体的,上述第二处理模块33,用于在索引器中构建与第三工单的最新数据对应的增量索引,具体用于:
向索引器发送第二通知消息,第二通知消息中携带第三工单的最新数据,以使索引器构建第三工单的最新数据对应的增量索引。
具体的,上述第三处理模块34,用于在索引器中构建与第四工单的最新工单状态对应 的增量索引,具体用于:
向索引器发送第三通知消息,第三通知消息中携带第四工单的最新工单状态,以使索引器构建第四工单的最新工单状态对应的增量索引。
上述说明示出并描述了本申请的优选实施例,但如前所述,应当理解本申请并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本申请的精神和范围,则都应在本申请所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!