一种表情反馈方法及智能机器人与流程
本发明涉及智能设备技术领域,尤其涉及一种表情反馈方法及智能机器人。
背景技术:
随着智能设备的制造和研发技术的飞速发展,有一种比较特殊的智能设备——智能机器人开始走进人们的生活。所谓智能机器人,其实是一种功能多样化的智能设备,相当于在一个智能设备中集成了不同种类的智能设备的不同功能。例如在一个智能机器人中可能集成有音频播放设备的音频播放功能,视频播放设备的视频播放功能,智能语音设备的语音对话功能以及其他各类功能。
现有技术中,智能机器人可以根据使用者输入的信息做出反馈,即智能机器人可以跟使用者之间进行比较简单的信息交互。但是智能机器人针对使用者做出的反馈信息通常是“冷冰冰”的,即并不会依照使用者输入信息时的不同情绪做出不同的反馈,因此造成使用者与智能机器人之间的信息交互的内容比较死板,从而降低使用者的使用体验。
技术实现要素:
根据现有技术中存在的上述问题,现提供一种表情反馈方法及智能机器人的技术方案,旨在丰富智能机器人和使用者之间的信息交互内容,从而提升使用者的使用体验。
上述技术方案具体包括:
一种表情反馈方法,适用于智能机器人,所述智能机器人上设置有图像采集装置;其中,包括:
步骤s1,所述智能机器人采用所述图像采集装置采集图像信息;
步骤s2,所述智能机器人检测所述图像信息中是否存在表示人脸的人脸信息:
若是,则获取关联于所述人脸信息的位置信息和大小信息,随后转向步骤s3;
若否,则返回所述步骤s1;
步骤s3,根据所述位置信息和所述大小信息,预测得到所述人脸信息中的多个特征点信息并输出;
多个所述特征点信息分别关联于所述人脸信息表示的所述人脸的各部位;
步骤s4,采用一预先训练形成的第一识别模型,根据所述特征点信息判断所述人脸信息是否表示笑脸,随后退出:
若是,则所述智能机器人输出预设的表情反馈信息;
若否,则退出。
优选的,该表情反馈方法,其中,于所述智能机器人内预先训练形成一用于检测所述人脸信息的第二识别模型;
则所述步骤s2具体为:
所述智能机器人采用所述第二识别模型检测所述图像信息中是否存在所述人脸信息:
若是,则获取关联于所述人脸信息的位置信息和大小信息,随后转向步骤s3;
若否,则返回所述步骤s1。
优选的,该表情反馈方法,其中,于所述智能机器人内预先训练形成一用于预测所述特征点信息的第三识别模型;
则所述步骤s3具体为:
采用所述第三识别模型,根据所述位置信息和所述大小信息预测得到所述人脸信息中的多个所述特征点信息并输出。
优选的,该表情反馈方法,其中,所述步骤s3中,采用所述第三识别模型预测得到关联于所述人脸信息的68个所述特征点信息。
优选的,该表情反馈方法,其中,所述步骤s4具体包括:
步骤s41,将所述步骤s3中预测得到的所有所述特征点信息输入至所述第一识别模型中;
步骤s42,采用所述第一识别模型判断所述人脸信息是否表示笑脸:
若是,则所述智能机器人输出预设的表情反馈信息;
若否,则退出。
优选的,该表情反馈方法,其中,所述步骤s4中,所述表情反馈信息包括:
通过所述智能机器人的显示装置显示的用于表示高兴的情绪的预设的表情符号;和/或
通过所述智能机器人的语音播放装置播放的用于表示高兴的情绪的预设的声音。
一种智能机器人,其中,采用上述的表情反馈方法。
上述技术方案的有益效果是:提供一种表情反馈方法,能够丰富智能机器人和使用者之间的信息交互内容,从而提升使用者的使用体验。
附图说明
图1是本发明的较佳的实施例中,一种表情反馈方法的总体流程示意图;
图2是本发明的较佳的实施例中,于图1的基础上,识别笑脸的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
本发明的较佳的实施例中,基于现有技术中存在的上述问题,现提供一种表情反馈方法,其适用于智能机器人。该方法的具体步骤如图1所示,包括:
步骤s1,智能机器人采用图像采集装置采集图像信息;
步骤s2,智能机器人检测图像信息中是否存在表示人脸的人脸信息:
若是,则获取关联于人脸信息的位置信息和大小信息,随后转向步骤s3;
若否,则返回步骤s1;
步骤s3,根据所述位置信息和所述大小信息,预测得到所述人脸信息中的多个特征点信息并输出;
步骤s4,采用一预先训练形成的第一识别模型,根据特征点信息判断人脸信息是否表示笑脸:
若是,则智能机器人输出预设的表情反馈信息,随后退出;
若否,则退出。
在一个具体实施例中,智能机器人采用面部识别的方式确认其应该反馈何种表情信息。具体地,使用者需要站在智能机器人的图像采集装置(即摄像头)的采集区域内,例如站在图像采集装置的正前方。
则该实施例中,智能机器人首先采用图像采集装置采集其采集区域内的图像信息,随后判断该图像信息中是否存在人脸信息:若存在,则接收该人脸信息,并同时提取该人脸信息的位置信息和大小信息。具体地,所谓位置信息,是指该人脸信息位于图像采集装置的取景框内的具体位置;所谓大小信息,是指该人脸信息所表示的人脸的大小。
该实施例中,获取到人脸信息及其位置信息和大小信息后,可以根据其位置和大小预测得到该人脸信息的多个特征点信息。具体地,多个特征点信息分别关联于人脸信息表示的人脸的各部位;例如不同的特征点信息分别关联于上述人脸信息所表示的人脸上的眉毛部位、眼睛部位、鼻子部位、嘴巴部位以及整个人脸轮廓等各部位。
该实施例中,预测得到上述多个特征点信息后,采用预先训练形成的第一识别模型,根据所有这些特征点信息,识别上述人脸信息所表示的人脸是否为笑脸:若是,则智能机器人根据该笑脸输出预设的表情反馈信息;若否,则直接退出。进一步地,若上述人脸信息不表示笑脸,则智能机器人根据预设的策略输出其他的反馈信息,该过程并不包括在本发明技术方案内,因此不对其进行描述。
本发明的较佳的实施例中,于上述智能机器人内预先训练形成一用于检测人脸信息的第二识别模型;
则上述步骤s2具体为:
智能机器人采用第二识别模型检测图像信息中是否存在人脸信息:
若是,则获取关联于人脸信息的位置信息和大小信息,随后转向步骤s3;
若否,则返回步骤s1。
具体地,本发明的较佳的实施例中,通过输入多个不同的训练样本,在上述智能机器人内预先训练形成第二识别模型,该第二识别模型为一个人脸检测器,可以用来判断图像采集装置采集得到的图像信息中是否存在人脸信息。在现有技术中存在较多实现训练形成人脸检测器的技术方案,因此在此不再赘述。
本发明的较佳的实施例中,于智能机器人内预先训练形成一用于预测特征点信息的第三识别模型;
则上述步骤s3具体为:
采用第三识别模型,根据位置信息和大小信息预测得到人脸信息中的多个特征点信息并输出。
具体地,本发明的较佳的实施例中,同样通过输入多个不同的训练样本,在上述智能机器人中预先训练形成用于对人脸信息中的多个特征点信息进行预测的第三识别模型。换言之,上述第三识别模型为特征点预测模型。利用该第三识别模型,能够根据人脸信息及其位置和大小等信息预测得到人脸信息上的多个特征点信息。本发明的一个较佳的实施例中,利用上述第三识别模型,从人脸信息上预测得到68个特征点信息,这些特征点信息所涉及的人脸的部位包括但不限于:眉毛、眼睛、鼻子、嘴巴以及脸的整体轮廓等。换言之,依照上述第三识别模型从人脸信息上预测得到的68个特征点信息,分别可以用来表示该人脸信息上的各部位的信息。则根据上述第三识别模型的识别处理,输出预测得到的该68个特征点信息。
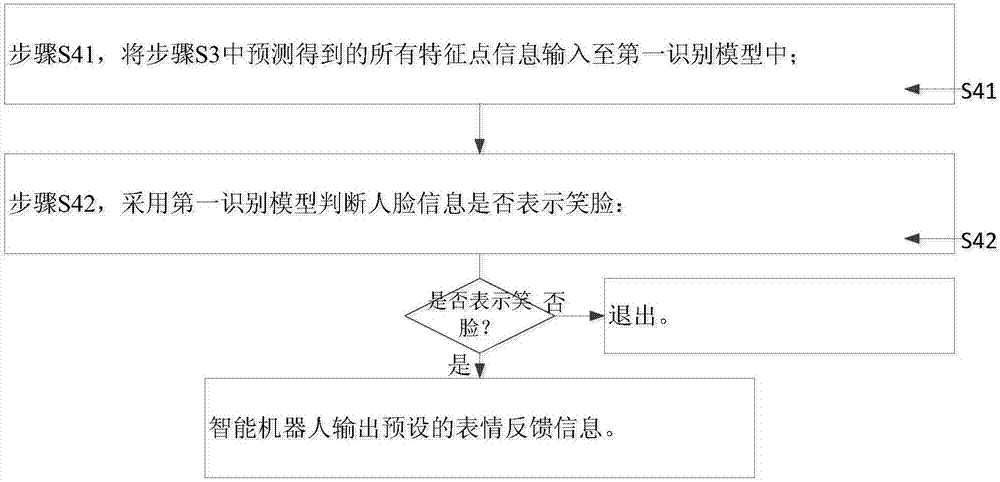
本发明的较佳的实施例中,如图2所示,上述步骤s4具体包括:
步骤s41,将步骤s3中预测得到的所有特征点信息输入至第一识别模型中;
步骤s42,采用第一识别模型判断人脸信息是否表示笑脸:
若是,则智能机器人输出预设的表情反馈信息;
若否,则退出。
具体地,本发明的较佳的实施例中,上述第一识别模型同样是通过输入大量的训练样本形成的,该第一识别模型为用于识别人脸是否为笑脸的笑脸识别模型。该笑脸识别模型可以根据抓取到的人脸上的各种特征点信息判断该特征点信息是否为笑脸的特征,并进而判断该人脸是否为笑脸。
本发明的较佳的实施例中,上述步骤s41中,根据上述第三识别模型预测得到的所有特征点信息被输入到上述第一识别模型中,例如上文中根据预测得到的68个特征点信息,被全部输入到第一识别模型中,以作为该第一识别模型的输入数据。随后第一识别模型根据这些特征点信息进行判断,判断依据可以例如下文中所述的一种或几种:
1)特征点信息是否表示该人脸上的嘴巴部分呈现对应笑脸的形状(例如嘴角上翘的形状,或者张嘴的形状);
2)特征点信息是否表示人脸上的脸部笑肌区域呈现对应笑脸的形状(例如肌肉聚拢并隆起的形状);
3)特征点信息是否表示人脸上的眼睛区域呈现对应笑脸的形状(例如眯眼的形状)。
上述判断依据还可以包括其他通常可以观测到或者通过实验数据得到的笑脸特征,在此不再赘述。
本发明的较佳的实施例中,若根据上述68个特征点信息的输入可以判断当前的人脸符合笑脸特征,则可以判断该人脸为笑脸,并进而根据判断结果输出对应笑脸的表情反馈信息。
本发明的较佳的实施例中,所谓表情反馈信息,其中可以下文中所述的一种或几种包括:
通过智能机器人的显示装置显示的用于表示高兴的情绪的预设的表情符号;以及
通过智能机器人的语音播放装置播放的用于表示高兴的情绪的预设的声音。
具体地,本发明的较佳的实施例中,上文中所述的表情符号,可以为显示在智能机器人的显示装置(例如显示屏)上的表情符号,例如表示简笔画的笑脸的表情符号,或者直接在显示屏上显示笑脸,或者其他预设的用于表示高兴情绪的表情。
上文中所述的声音,可以为从智能机器人的语音播放装置(例如扬声器)播放的例如预设的笑声或者语气较为高兴的预设语音,或者其他预设的声音等。
本发明的较佳的实施例中,上述表情反馈信息还可以包括其他能够输出并被使用者所感知的反馈信息,在此不再赘述。
综上所述,本发明技术方案中,利用不同的识别模型,首先根据一人脸检测器识别出图像采集装置采集到的图像信息中的人脸信息,随后根据一特征点预测模型预测得到人脸信息中的多个特征点信息,再把所有特征点信息输入到一笑脸识别模型中,并根据该笑脸识别模型识别当前的人脸信息是否表示笑脸:若表示笑脸,则智能机器人输出能够被使用者感知的用于表示高兴的情绪的表情反馈信息;若否,则直接退出。上述技术方案能够丰富智能机器人与使用者之间的信息交互,并提升使用者的适用体验。
本发明的较佳的实施例中,还提供一种智能机器人,其中采用上文中所述的表情反馈方法。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所作出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!