一种基于信息交互网络的犯罪个体识别方法与流程
本发明属于数据挖掘领域,具体涉及一种基于信息交互网络的犯罪个体识别方法。
背景技术:
随着信息科技、数据库的迅猛发展,数据量呈现指数趋势爆炸式的增长,但由于缺乏对分析、决策、预测等功能的支持机制,从而导致了―数据爆炸、知识贫乏”。面对这一挑战,数据挖掘技术应运而生,并越来越彰显其强大的生命力,经过多年来不断的研究和实践,数据挖掘技术已集成了人工智能、信息检索、统计学、数据库技术、数据可视化、面向对象方法、机器学习、神经网络等各不同领域的最新研究成果,进而逐步形成了一个独具特色的研究分支。与此同时,犯罪行为的智能化、高科技化、动态化,犯罪人员的组织化和职业化趋势也越来越明显,具有时代特征的新型犯罪形式和新型犯罪手段不断出现,现代违法犯罪正处在一个案件高发期和提速期。犯罪行为的变化层出不穷,对相关执法部门提出了更为严峻的挑战,亟待需要将数据库技术、数据挖掘技术等应用到警务改革中来,以提高执法效率、增强犯罪控制和防范策略等。所以,目前很多国家和城市都加大了对犯罪大数据的研究投入和自动化分析工具的开发。
现有的利用数据挖掘的方法对犯罪行为的分析主要集中在以下几个方面:(1)利用关联规则挖掘对犯罪行为进行特征分析,发现行为属性之间存在的依赖关系,获取并分析犯罪行为所在的不同区域、各个目标、不同行为意图之间的规律和联系;(2)利用分类和预测算法对大量的犯罪行为记录进行分析,发现共同的行为模式,可以得出犯罪模式、犯罪区域、犯罪行为等基本特征,挖掘犯罪行为之间的潜在联系和规律,并结合这些分析结果来对新的犯罪行为进行归类,从而进行有效的预测和防范;(3)利用聚类分析对具有相同特征的犯罪个体进行分类,发现预先未知的犯罪类型,主要用于发现具有相同作案手段的嫌疑犯或区分不同的犯罪团伙;(4)利用异常点检测,用特定的度量方法研究和发现与一般的行为模式不一样的数据对象;(5)利用社会网络分析,通过数据对象之间的某种特殊联系构建犯罪网络,主要用来挖掘犯罪团伙的核心成员,以达到迅速捣毁犯罪窝点的目的。
与本发明最接近的研究是利用社会网络分析的方法研究犯罪数据,也称之为犯罪网络分析,作为社会网络分析(Social Network Analysis,SNA)一个分支,犯罪网络分析的研究和应用在国外已有较好的开展,在国内则处于起步阶段[1]。文献[2]指出社会网络分析是指通过分析行动者之间的关联和交互的模式来发现潜在的社会结构的一种社会学研究方法,作者将社会网络分析的关系分析和位置分析方法引入到犯罪网络的分析中,设计出了一个犯罪网络知识发现体系CrimeNetExplorer,该体系采用一种概念间隔方法来建立犯罪网络,应用层次聚类方法来进行子网分析,根据强度、度、中介数等度量参数和Dijkstra最短路径算法来进行犯罪网络结构分析,利用MDS和SVD算法来进行网络结构的可视化。根据上述基本思路,亚利桑那大学的人工智能实验室的COLINK科研项目,不但研制出了专门的犯罪网络分析产品COLINK,还出产了大量的论文,如文献[3]论述了应对国家和运输安全的跨区域犯罪活动网络分析方法,文献[4]论述了数据挖掘技术在犯罪网络分析中的应用,而文献[5,6]则是通过几个应用架构来说明犯罪网络分析在反恐斗争中的运用。文献[7]对双曲线树和层次列表两种犯罪网络可视化方法进行了比较。上述文献所提出的犯罪网络分析技术与方法所依托的数据是综合性的,包括犯罪信息、电话记录、监视日志、资金流动记录等,这对分析犯罪网络结构很有帮助,如果在仅有通信数据的条件下进行犯罪网络分析。文献[8]设计了一个队恐怖组织网络的结构进行估计的工具NETEST,该工具综合应用了层次贝叶斯的推论模型、偏好网络理论[9]和多代理系统等技术,为犯罪网络分析提供了有一种参考文献。而文献[11]介绍了数据融合和数据挖掘技术在犯罪分子抓捕辅助系统ReCAP中的应用。ReCAP是较早应用计算机程序进行数据分析辅助司法部门抓捕犯罪嫌疑人的智能警用系统。对于网络核心成员的挖掘问题,文献[10]提出了一种新的思想。该文献首先定义了特殊的网络核心人员挖掘问题(KPP-Neg,KPP-Pos),然后提出了对应的挖掘方法。该挖掘方法为:如果删除某个节点后能使网络分成两个或多个大小相似的子网络的话,那么删除的节点是网络核心成员之一,如此下去找到K个核心成员,并采用贪心算法来实现。上述两个紧密继承于社会网络分析技术的犯罪网络分析方法,尤其对如何在通信数据上进行犯罪网络分析有很强的指导意义。四川大学计算机学院对犯罪网络分析进行了一些研究,提出了基于六度分割理论的最短路径算法SPLINE[12],在此基础上提出了犯罪网络核心挖掘算法(KEY Member Ming KMM)[12]。在犯罪网络建立和子网络分析方面他们分别提出了BSN(Building Social Network)算法[12]和SGM(Sub-Group Mining)算法[12]。他们还提出了一种基于GEP(Gene Expression Programming)[3]的恐怖分子分类算法和基于属性筛选支持向量机的挖掘社团结构(可用于犯罪网络结构)的方法ASRA(Attribute Selected and Rule Abstracted)[14]。现有的技术只基于从数据中抽象出来的人员通信的拓扑结构进行简单的网络分析,或者只基于获取的通信内容进行一般的数据挖掘分析,很少有将二者结合起来进行研究。但是一般而言,一个人是否具备犯罪的嫌疑,既和这个人的谈论话题相关,也和这个人和谁有过交流有关,即一个个体的犯罪嫌疑度既取决于其通信内容,也取决于其所在的信息交互网络中的位置。
人们每天都在通信,犯罪分子也不例外,随着社交媒体的普及,这些通信记录都在被无时无刻的记录着,如何从这些海量的通信记录中准确的发现并识别出其中最有可能参与犯罪的嫌疑分子,从而帮助相关部门迅速定点出击,将犯罪团伙一网打尽,在如今的大数据时代,无疑具有重大的现实意义。
技术实现要素:
针对上述技术问题,本发明旨在解决如何从人员通信网络中识别出犯罪个体的问题,具体技术方案如下:
一种基于信息交互网络的犯罪个体识别方法,主要包括以下步骤:
(1)获取包含犯罪活动内容的数据集,对数据集进行预处理:
若数据集为英文,则按照提取正文、去除停用词、将所有单词变成小写、提取词干的顺序进行处理,最后提取名词,并将属于人名的名词删除;
若数据集为中文,则先提取正文,然后分词、去除停用词、命名实体识别,最后提取名词,并将属于人名的名词删除;
在实施过程中,若数据集为非英文、非中文,可以翻译成英文或者英文再进行对应处理。
(2)提取犯罪话题的关键词描述
人工确定若干个与犯罪话题相关的关键词(一般而言分析数据之前,对于犯罪活动的内容一般有个大概的了解,因此此处为人工选取关键词提供了可能,这也体现了该专利是一种人机交互模型,既借鉴了人的经验,又发挥了数学模型的精确性特点),计算各关键词的TFIDF值(Term Frequency Inverse Document Frequency,简称TFIDF),取前10个值最高的关键词作为犯罪话题的描述。
(3)基于困惑度确定主题模型LDA(Latent Dirichlet Analysis,简称LDA)的交互主题个数K:定义困惑度表示为perplexity,困惑度是用于评价衡量训练出的语言模型的好坏的指标,其中定义为各篇文档合理性的几何平均值:
其中M表示数据集进行预处理后的文档数,K表示交互主题数,dm表示第m篇文档,zk表示第k个交互主题,wt表示第t个字符,表示第m篇文档中字符wt出现的次数,N表示文档中字符的总数,即步骤(2)中处理后的数据集中的字符总数;使得困惑度值取最小的K值便是交互主题个数;
(4)基于主题模型LDA对步骤(1)预处理后的数据集提取个体间交互内容的交互主题:分别为交互主题与关键词的关联概率矩阵φk(交互主题k对应的单词分布)、交互边与交互主题的关联概率矩阵θij(交互边(vi,vj)对应的交互主题分布);
(5)根据交互边与交互主题的关联概率矩阵和交互主题与关键词的关联概率矩阵,计算交互边的权重;
设个体vi和个体vj之间的交互边为eij,假设得到的K个交互主题z1,z2,...,zK在交互边(vi,vj)上的分布为p(z1),p(z2),...,p(zK),犯罪话题描述为:crime_content={c1,c2,...,cH},H表示犯罪话题的个数,Ch表示第h个犯罪话题,交互主题与关键词的关联矩阵φk=p(ch|zk),k取值为1,2,3,…,K;h取值为1,2,3,…,H,则交互边(vi,vj)对应的内容和犯罪话题crime_content的语义相似度,即作为交互边eij的权重ψij:
(6)基于加权信息交互网络的结构计算个体的局部犯罪嫌疑度
信息交互网络G(V,E,W),其中V是个体节点集合,E是个体之间的交互关系集合,W是个体之间的交互边的权重;从犯罪行为的逻辑分析角度,提出的四点假设的基础:1)一个人的犯罪嫌疑度由其所参与的交互主题和交流的对象是否是犯罪嫌疑人决定;2)如果一个人谈论的内容完全与犯罪话题无关,并且和他交流的对象也都是已知无辜的人,那么该人就肯定不是犯罪分子(至少从现有的数据无法判断其有犯罪嫌疑);3)如果一个人讨论越多的犯罪话题,并且和越多的犯罪分子有过交流,那么该人的犯罪嫌疑度越大;4)在计算一个人的犯罪嫌疑度时,其所谈论主题的犯罪嫌疑度对结果的影响要大于其所交谈对象的犯罪嫌疑度的影响。
在上述四点假设的基础上,构造基于网络结构的个体局部犯罪嫌疑度的迭代计算公式:
其中ki是节点vi的度数,i,j均表示节点vi,vj,Q表示网络中的节点个数,Si(q)表示第q步迭代计算中节点vi的局部犯罪嫌疑度值;并基于该式计算所有个体的局部犯罪嫌疑度;个体的局部犯罪嫌疑度在迭代过程中会收敛。(此处节点即代表信息交互网络中的个体,个体的初始局部犯罪嫌疑度Si(0)随机赋值)。
(7)基于模糊K均值聚类和距离-密度聚类相结合的方法计算个体的全局犯罪嫌疑度,并根据全局犯罪嫌疑度对犯罪个体进行识别。
以步骤(6)中得到的个体局部犯罪嫌疑度值作为特征值,将所有个体角色划分为两类:犯罪类和无辜类,从而将该问题转化为一个聚类问题;利用模糊K均值聚类方法(k-means)计算所有个体到犯罪类的隶属度,作为该个体的全局犯罪嫌疑度;利用距离-密度(Distance-Density,简称DD)聚类方法将所有个体分别明确的聚为犯罪类、无辜类和无法辨别的噪音类中的一种。
采用本发明获得的有益效果:本发明提出的基于聚类算法的个体全局犯罪嫌疑度计算方法可以很好的利用全局的信息,并且模糊K均值聚类和距离-密度聚类相结合的方法可以给出更为明确细致的结果,得到的结果具有很好的可解释性。
本发明综合了网络分析和语义分析;本发明的计算结果不依赖先验信息,即不需要事先知道有哪些犯罪分子,只要获取他们的通信内容,便可准确的分析出其中最有可能的嫌疑分子;原理简单、流程清晰、易于实现,可以为相关部门的侦查提供辅助决策,提高办案效率。
说明书附图
图1为本发明的流程图;
图2为犯罪话题的词云图;
图3为实施例中犯罪话题关键词TFIDF的雷达图;
图4为实施例中各交互主题的犯罪嫌疑度;
图5为实施例中83名员工的局部嫌疑度;
图6为基于FCM(fuzzy C-means)聚类算法的83名员工的全局嫌疑度;
图7为DD算法的决策图及类中心点选择图;
图8为基于DD算法的83名员工的犯罪角色判别;
图9为基于FCM聚类的结果和基于DD聚类的结果比较图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明。
本发明的流程如图1所示,实施例选用的ICM-C82数据集是一家公司内容员工的邮件数据集,因为保护隐私的原因,并未公开邮件的全部内容,公开的是经人工提炼后的交互主题内容。该数据集是在公司发生一起内部员工通过网络诈骗手段合伙欺骗公司股东资金的犯罪案件后,有关部门为了找到其中的犯罪分子,调出公司内部员工在案发一段时间内的邮件通信数据,并经过一些前期的分析处理,放在网上供相关学者进行研究。
数据集包含83个公司员工之间超过400多次的交互,交互的内容超过21000个有效单词(去除停用词),经过对原始内容的分析,提炼出15个交互主题,并描述了每个交互主题的具体内容,以及每条交互涉及的最相关的主题信息。
根据事后的调查,发现已知的犯罪嫌疑人有Jean,Alex,Elsie,Paul,Ulf,Yao和Harvey等7人,已知的无辜的人有Darlene,Jia,Tran,Ellin,Gard,Chris,Paige和Este等8人。
调查局发现实际参与犯罪的还有其他员工,而且就隐藏在其中,下面基于本发明给出所有潜在罪犯的一个预测。
因为实验所用数据已经经过了人工分析处理,提取了15个人员的交互主题,并详细描述了交互主题的内容,则下面仅需计算交互主题与犯罪话题的语义关联度,计算个体的局部嫌疑度,计算个体的全局嫌疑度并进行犯罪角色的分析。
分析实验所提供的交互主题的描述信息,大致了解原始数据中公司内的83名员工都在交流什么内容,有在谈论公司股票的,有抱怨公司的数据库加密太严格导致权限受阻的,有讨论谁会被提升的,有讨论公司组织足球活动的,当然也有讨论,或者可以说是密谋对公司利益有害的犯罪活动的。因为获取的不是原始数据集,可能在词汇层面不能―原汁原味”的还原出原来的特色,但对于分析要解决的问题而言没有什么影响,我们关心的是交互主题与犯罪话题的语义关联度。
(1)提取犯罪话题(因为网上公开的该数据集已经提取了各人之间的交互主题,因此在实施例中没有进行发明内容部分步骤(3)、(4),该步骤同时包含了本发明的步骤(1)至步骤(4))。
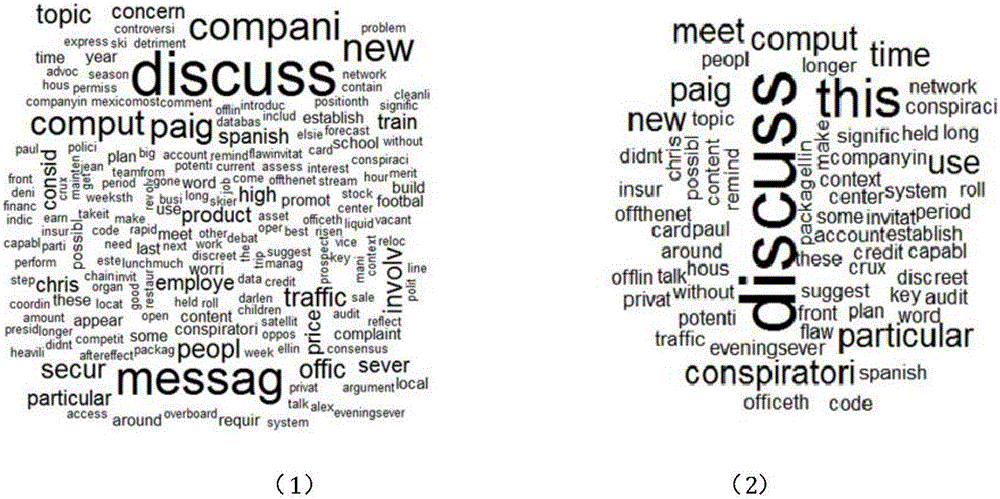
首先看一下提供的犯罪话题描述数据中的词汇分布(去掉如“is,am,are,I,you,the of”等对语义分析无关的停用词:stop word),是根据各单词出现的频率绘制的词云图,单词出现频率越大,相应的词云形状越大,如图2(1)所示,分析发现,对这15个交互主题的描述所用的单词中,出现频率较多的有discuss,message,company等词,这也符合描述公司谈论的主题的一般的用语表达。
根据已知的信息,交互主题7,11,13很有可能是犯罪话题,交互主题7在交流什么时候去某个人家里召开隐秘的会议,交互主题11在讨论公司的财务、审计及可能的系统漏洞的,交互主题13在讨论高管何时会下线、公司内网何时会出现监管盲区,可见这三个交互主题内容确实很令人起疑心。这3个交互主题的内容描述数据的单词分布见图2(2)。可见,频率较高的单词有discuss,conspiratory,particular等词。为了找到最适合描述犯罪话题的关键词,下面计算这三个交互主题中每个单词的TF-IDF值,图3以雷达图的形式呈现结果。
可以发现,TFIDF值较高的词有―account,audit,capabl,card,code,credit,discreet,flaw,network,privat,system,plan,spanish”,因此可以选作为该犯罪话题的描述。
(2)计算交互边的权重(因为特定实验数据集已经确定了交互主题,不需要再按照步骤(4)方法在主题模型的前提下进行计算)
计算其他交互主题和犯罪话题的关联度可转化为计算其他交互主题中这些关键词的TFIDF值的和。计算出各交互主题的嫌疑度如图4所示:
如图4所示,发现除了交互主题7,11,13三个已知的犯罪话题嫌疑度很高之外,交互主题2,8,12也都有一定的嫌疑度,而回到原始数据,分析交互主题2,8,12的内容,可以看到,这几个交互主题要么用Spanish语交流,要么交流公司网络安全的内容,而实际的犯罪活动中,犯罪成员用Spanish语作暗语,利用公司内网的漏洞进行信用诈骗,确实有一定可疑。
(3)基于加权信息交互网络的结构计算个体局部嫌疑度
原始数据提供了各交互边包含的交互主题信息,(1)计算了各交互主题的嫌疑度,则通过求和的方式计算交互边的犯罪嫌疑度,即边的权重。设边eij包含交互主题z1,z2,...,zK,每个犯罪话题的犯罪嫌疑度为p(z1),p(z2),...,p(zK),则交互边eij的权重:
应用本发明构造的个体局部犯罪嫌疑度计算公式计算每个员工的局部嫌疑度。如图5所示,为83名员工的局部嫌疑度值。分析发现,根据局部嫌疑度值已经可以对员工的角色进行初步判断,例如对于已知是罪犯的22号员工Alex,55号员工Ulf,68号员工Yao等,他们的局部嫌疑度值已经很高。然而仅用个体的局部嫌疑度值进行犯罪分子识别存在两个问题,一是因为局部嫌疑度值相对较集中,难以有比较明确的数值界限;二是也没有充分利用全局的信息,必定会因为遗漏信息而导致漏判或者误判。
(4)基于模糊K均值聚类和距离-密度聚类的方法计算个体全局嫌疑度。
将83名员工当做83个数据点,以各员工的局部嫌疑度值作为各数据点的属性值,计算各员工的全局嫌疑度值。
首先利用模糊K均值聚类计算83名员工的全局嫌疑度,计算结果如图6所示,并与图5进行比较,可以看到,和图5相比,基于FCM算法的个体全局嫌疑度值的区分结果更加明确(FCM的计算结果两极化更明显)。
其次基于DD算法计算员工的全局嫌疑度值(结果非1即0),首先得到决策图,并基于决策图选择类中心点,见图7;
可以发现,决策图中的右上角有很明显的两个点,基于DD算法的原理,知道这两个数据点是两个类的中心,同时得到这堆数据可以聚为两个类,一个是犯罪类,一个是无辜类。这两个点对应到数据集中是55号节点和72号节点,其中55号对应已知的罪犯Ulf,因此55号是犯罪类中心,72号是无辜类中心,聚类结果如图8所示,类别1是犯罪类,类别2是无辜类,类别0是噪音类(即DD算法也不能判别的类)
结果分析,根据全局犯罪嫌疑度对犯罪个体进行识别;表1是15位已知角色的人员的FCM嫌疑度及DD判别结果(1是罪犯,2是无辜人员,0是不能判断的角色),可以看到,对于已经确定是犯罪分子的Elsie等人,计算得到FCM嫌疑度值都很高,排名也都很靠前,因此基于FCM的模型,即使不知道他们是犯罪分子,也可以将其识别出来,而且在这种情况下,其他还没发现的犯罪分子可以通过定位那些嫌疑度值高的人来进行侦查分析识别;基于DD的模型同样也将这些人归为犯罪类,识别效果较好。对于事先知道是无辜的人,同样可以看到不仅是基于FCM的算法还是基于DD的算法也同样可以区分的很好。当然也可以看出,标号为66的员工,无论是FCM算法还是DD算法,都容易误将其归为犯罪类,而回到原数据集中,发现66号员工Jia参与讨论了交互主题2,7,11,而这些交互主题都具有一定的嫌疑度,而且他还与Paul等已知罪犯有过交流,因此至少从所提供的数据来看,Jia具有较高的嫌疑度,因此算法的结果是符合实际的。
表1已知角色的员工的模型结果
基于模型结果的犯罪分子预测,上述结果表明本文的模型可以有效的识别组织中的犯罪分子,那么,按照―理解-量化-预测-控制”的科学研究步骤,下一步就是预测组织中其他的犯罪分子,这也是本发明的最终价值所在。在给出预测结果之前,首先对比一下FCM聚类的结果和DD聚类的结果,如表2所示。
表2基于FCM聚类的结果和基于DD聚类的结果的比较
图9按照全局嫌疑度值从高至低进行排序,且根据不同数据点在DD算法中的类判别结果赋予不同的形状,“○”表示判别为犯罪类,“*”表示判别为噪音类(即不能判断是犯罪还是无辜),“◆”表示判别为无辜类。
表2可以得到,基于两种不同的聚类算法得到的结果在犯罪角色的识别上是一致的,即在FCM聚类的结果中计算出较高嫌疑度值的员工在DD聚类中也会被归为犯罪类,在FCM聚类结果中计算出较低嫌疑度值的员工在DD聚类中也会被归为无辜类,在FCM聚类结果中计算的嫌疑度值处于中间值的员工在DD聚类中也会被归为噪音点。这正好互为印证两种方法结果的合理性,其次还可以互为弥补两种方法的不足:FCM聚类方法的不足在于很难有一个明确的方法确定犯罪类的边界,到底嫌疑度值高于多少才能认为是罪犯,这给侦查机构在最终下定决心该逮捕谁带来了问题;DD聚类方法的不足在于对类内员工的嫌疑程度可解释性不强,它认为归为犯罪类的员工的嫌疑度都一样,其实不尽然,即便一个犯罪团伙里还分犯罪主犯和从犯呢,这给侦查机构的侦查精力分配带来了困扰。如果结合两种方法,认为在DD聚类中被归为犯罪类且在FCM聚类中犯罪嫌疑度值较大的员工是侦查机构最应该去调查的嫌疑分子,则既解决了边界的问题也解决了嫌疑度量化的问题。
从表2中都可以看到,犯罪角色划分的边界点在11号员工(最后一个划为犯罪类的66号员工已经知道是无辜的),嫌疑度值为0.7954。据此,可以对该公司涉及到这次犯罪活动的罪犯进行预测(将表2中66号以上的员工都列为犯罪嫌疑人,并按照嫌疑程度高低进行有重点的排查),结果如表3所示。
表3该公司可能参与这次犯罪活动的犯罪分子
参考文献:
[1]唐常杰、刘威、温粉莲等,社会网络分析和社团信息挖掘的三项探索——挖掘虚拟社团的结构,核心和通信行为[J],计算机应用,2006,9(2)123~125.
[2]Jennifer J.XU and Hsinchun Chen.CrimeNet Explorer:A Framework for Criminal Network Knowledge Discovery.ACM Transactions on Information Systems,Vol.23 No.2,April 2005,Pages 201-226.
[3]Marshall,B.,et al.Cross-Jurisdictional Criminal Activity Networks to Support Border and Transportation Security.in 7th International IEEE Conference on Intelligent Transportation Systems.2004.Washington D.C.
[4]Hsinchun Chen,et al.Crime Data Mining:A General Framework and Some Examples.Computer,April 2004
[5]Xu,J.,Chen,H.,Untangling Criminal Networks:A Case Study.Proceedings of the 1st NSF/NIJ Symposium on Intelligence and Security Informatics(ISI'03),Tucson,AZ(2003).
[6]Jialun Qin,et al.Analyzing Terrorist Networks:A Case Study of the Global Salafi Jihad Network.P.Kantor et al.(Eds.):ISI 2005,LNCS 3495,pp.287-304,2005.
[7]Y.Xianga,*,M.Chaub,H.Atabakhsha,H.Chen,Visualizing criminal relationships:comparison of a hyperbolic tree and a hierarchical list.Decision Support Systems 41(2005),Pages 69–83
[8]Matthew J.Dombroski,Kathleen M.Carley.NETEST:Estimating a Terrorist Network’s Structure.Graduate Student Best Paper Award,CASOS2002 Conference.
[9]刘军,社会网络模型研究论析,社会学研究,2004年第1期
[10]Borgatti,S.P.2006.Identifying sets of key players in a network.Computational,Mathematical and Organizational Theory.12(1):21-34.
[11]Brown,D.E.,The Regional Crime Analysis Program(ReCAP):a framework for mining.Data to catch criminals,Proc.of IEEE International Conference on Systems,Man,and.Cybernetics,2848–2853,1998
[12]温粉莲、唐常杰、乔少杰等,挖掘被监控社团核心的最短路径方法.中国科技论文在线(教育部)http://www.paper.edu.cn No,200607-42.
[13]Shaojie Qiao,et al.VCCM Mining:Mining Virtual Community Core Members Based on Gene Expression Programming[C].H.Chen et al.(Eds.):WISI 2006,LNCS 3917,pp.133-138,2006.
[14]乔少杰、唐常杰,基于属性筛选支持向量机挖掘虚拟社团结构,计算机科学(增刊A),第23卷第7期,2005.8.
- 还没有人留言评论。精彩留言会获得点赞!