一种网络故障诊断方法与流程
本发明属于通信网络领域,具体涉及一种网络故障诊断方法。
背景技术:
现代网络具有网络规模大,拓扑复杂的特点。若网络出现故障并未及时准确地检测出故障点,会对经济、民生产生重大不利影响。因此,及时有效的网络故障检测是十分重要的。
早期依赖专家知识检测网络故障的方法已经难以保证当前大规模、高复杂度网络的稳定性。因此,在大型复杂网络中,智能诊断大量应用,在这些智能诊断方法中就包括了机器学习领域内的数据分类算法。
朴素贝叶斯算法(naive Bayes,简称NB)是基于贝叶斯规则的监督学习算法,它遵循了贝叶斯假设,也叫做朴素贝叶斯条件独立假设,该假设极大的简化了该算法的贝叶斯网络结构。因此,NB无论在模型训练阶段还是在测试阶段都是高效的。这种高效基本来自于条件独立假设。而这种条件独立假设在实践中通常与真实的数据情况相违背,NB的分类精度因此受到了影响。为了提高NB的分类精度,许多研究人员通过释放严格的条件独立假设提出了一些新的分类算法。后续的,GI Webb等人提出了改进了朴素贝叶斯的AODE算法(如图1所示)。与NB相比,AODE针对测试数据考虑了普通属性值的出现对测试数据概率分布的影响,以此来提高分类精度,与此同时也增加了AODE模型的贝叶斯网络的复杂度,其训练时间复杂度和测试时间复杂度与NB相比都有相应的增加。
然而,AODE没有考虑除类标签外,普通属性之间的关系对数据分布的积极影响。这样,数据分类准确就受到影响。因此,本领域需要一种准确性更高而计算复杂度增长较小的网络故障诊断方法。
考虑到对于任意属性对Ai,Aj,如果它们之间的依赖关系越强,对P(Aj|Ai)或者P(Ai|Aj)的估计值就更有信心。因此,在AODE的基础上,期待以考虑属性之间的关系调整概率分布,来提高AODE的分类精度。
技术实现要素:
本发明的目的在于解决上述现有技术中存在的难题,提供一种网络故障诊断方法,有效提高网络诊断的准确性并保持良好的容错能力。
本发明是通过以下技术方案实现的:
一种网络故障诊断方法,包括:
(1)从网络历史数据库中获取历史数据,所述历史数据包括症状变量集和故障类变量集;
(2)构建加权平均依赖分类器预测模型;
(3)所述加权平均依赖分类器预测模型通过所述历史数据自动学习到分类器参数,形成已训练完成的加权平均依赖分类器;
(4)进行故障诊断时,将测试数据输入所述已训练完成的加权平均依赖分类器,得到对应的故障诊断结果。
所述步骤(2)中的加权平均依赖分类器预测模型如下:
其中,t为测试数据,Y为故障类变量集,y为故障类变量的值,p(y,xi)为对应的故障类变量y和症状变量xi的联合概率,i=1,2,…,m,m为症状变量个数且F(xi)≥g,F(xi)表示xi在训练数据中的频数;另外,p(xj|y,xi)为症状变量xj和症状变量xi与故障变量y的条件概率,j=1,2,…,m,wij为症状变量xi和症状变量xj的权重。该预测模型与分类器的表达式是一样的。
所述g的取值为30。
所述症状变量xi和症状变量xj的权重wij如下:
其中,p(xi,xj,y)为xi和xj及y的联合概率,p(xi|y)和p(xj|y)分别为xi和xj的条件概率,i=1,2,...,m而j=2,3,...,m且j≥i。
在步骤(3)中,所述的分类器参数包括症状变量联合概率p(xi,xj,y),p(xi,y)以及故障变量概率p(y),具体为:
其中n为在给定y值的情况下训练样例个数,ni为第i个症状变量的值和故障类值确定的情况下训练样例的个数,nij为第i,j个症状变量的值和故障类值确定的情况下训练样例的个数,并且c(·)为·的基值,F(·)为·的频数。
所述步骤(4)中的所述测试数据包括症状变量集所声明的属性值。
与现有技术相比,本发明的有益效果是:
1,本发明方法提高了网络故障诊断的准确率,且不受属性缺失值的影响,具有容错能力;
2,本发明针对现有通信网络规模大,网络拓扑复杂度高的特点,设计了一种基于加权平均一依赖分类器,通过该分类器对网络进行故障诊断,提高了分类器自身的学习能力。
附图说明
图1是AODE分类器结构图;
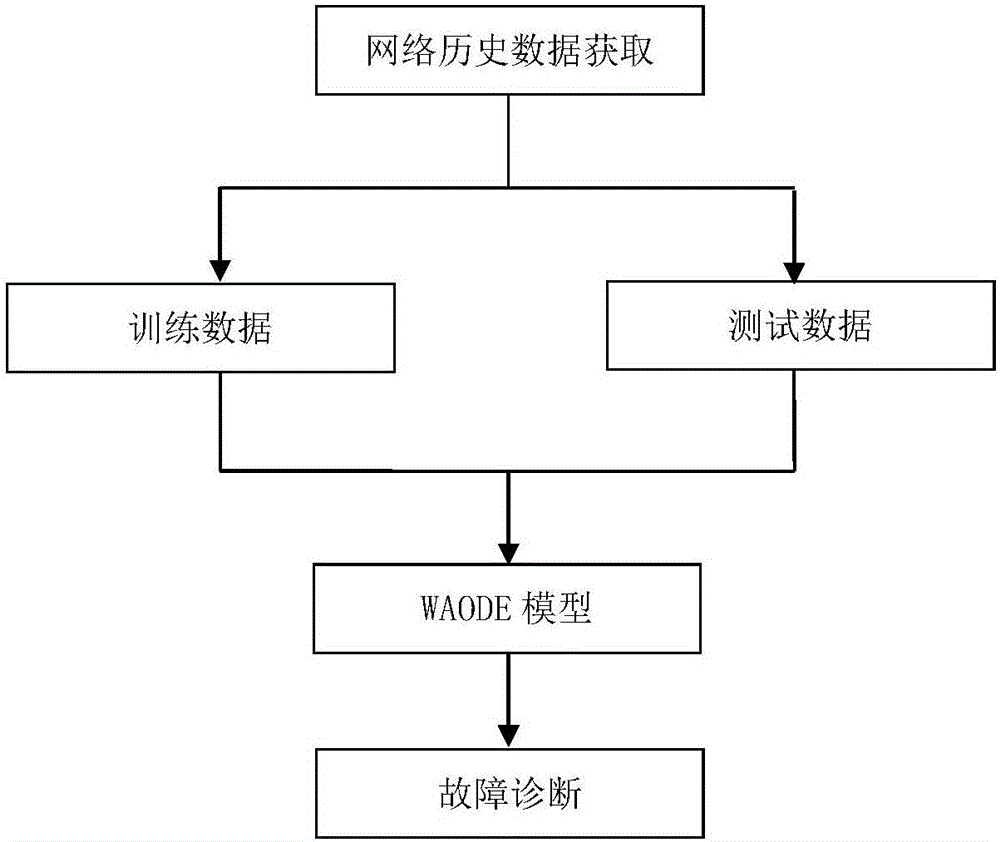
图2是故障诊断方案流程图;
图3是WAODE分类器结构图;
图4是实施例中获取的历史数据示意图;
图5是实例中故障变量与症状变量统计图;
图6是历史数据丢失时采用不同预测模型下的故障诊断准确率统计图。
具体实施方式
下面结合附图对本发明作进一步详细描述:
针对现有技术的以上缺陷,本发明提出了一种基于加权平均依赖分类器的网络故障诊断方法,有效解决大型网络的网络故障诊断准确率较低的问题。
本发明方法如图2所示,包括:
(1)从网络历史数据库中获取历史数据,所述历史数据包括症状变量集和故障类变量集;
(2)构建加权平均依赖分类器预测模型;
(3)所述加权平均依赖分类器预测模型通过所述历史数据自动学习到分类器参数,获得已训练完成的加权平均依赖分类器;
(4)进行故障诊断时,对测试数据利用上述已训练完成的加权平均依赖分类器进行估计,最终得到对应的故障诊断结果;
所述步骤(4)中的所述测试数据包括症状变量集所声明的属性值,所述加权平均一依赖分类器通过训练,给出该测试数据的分类结果,即故障类型。所谓的测试数据可以认为由n条测试样例(test instance)组成,n=1,2,3,4,…,分类器一次测试一条test instance,并对该条test instance给出分类结果。
本发明采用分类准确率来评估分类器的分类性能。
假设有100个测试样例,分类器分对70个样例,分类器分类准确率就是70%了。
一般在论文中是这样描述的:精确率是在“95%信任区间”上通过“10折交叉验证”的方式估计出来的。
分类器针对某一测试样例给出分类结果,这个“结果”就是该分类器给出的诊断结果。
WAODE分类器模型结构如图3所示,其中Y是类节点,即故障类变量集(故障变量集由图4所示,c1—c6),指向所有的属性A1,A2,…,Ai,…,Am,即症状变量集(Ai代表症状变量集中的一个属性,它本质上是一个随机变量。如图5所示,若i=2,A2是症状变量集的一个属性(又叫随机变量)。根据本发明中对症状集属性值的限定,A2的值可以为1,也可为0),Wij是属性Ai与Aj之间的权重,属性Ai指向其他所有属性但不包括类节点。
所述的症状变量集,具体为:症状变量取值均为名词性属性值(如图4中的A1-A10这10个属性,它们只能从{0,1}中取值,视为名词性属性(与数值属性相区分)),若有数值类型值,均需离散化处理(通常可使用Weka软件的无监督的属性过滤器Discretize离散掉所有的连续的属性值),且对某症状变量的缺失值只标注(通常可使用Weka软件的无监督的属性过滤器ReplaceMissingValues将缺失值替换成”*”)而不做其他特殊处理。
在步骤(2)中,所述加权平均一依赖分类器预测模型CWAODE具体为:
其中,t为测试数据,Y为故障类变量集,y为故障类变量的值,p(y,xi)为对应的故障类变量y和症状变量xi的联合概率,i=1,2,...,m,m为症状变量个数且F(xi)≥g,F(xi)表示xi在训练数据中的频数,g通常设定为30。另外,p(xj|y,xi)为症状变量xj和症状变量xi与故障变量y的条件概率,j=1,2,...,m。符号wij为症状变量xi和症状变量xj的权重。
所述症状变量xi和症状变量xj的权重wij具体为:
其中,m为症状变量集变量个数,p(xi,xj,y)为xi和xj及y的联合概率,p(xi|y)和p(xj|y)分别为xi和xj的条件概率,i=1,2,...,m而j=2,3,...,m且j≥i。
在步骤(3)中,所述的分类器参数包括症状变量联合概率p(xi,xj,y),p(xi,y)以及故障变量概率p(y),具体为:
其中n为在给定y值的情况下训练样例个数,ni为第i个症状变量的值和故障类值确定的情况下训练样例的个数,nij为第i,j个症状变量的值和故障类值确定的情况下训练样例的个数,并且c(·)为·的基值,F(·)为·的频数。
在实施例中,本发明从网络历史数据中选取了350个案例,并总结一些症状变量集为属性,一些故障类变量集为类(一条症状只对应一个故障值),详细情况如图4所示。这些症状和故障的对应关系如图5所示。图5中,A1=0和A1=1分别表示接口管理状态为正常和断开,A2=0和A2=1分别表示接口操作状态为正常和断开,A3,A4,A5,A6,A7,A8,A9,A10,这些值为0表示属性值正常,为1表示该属性值不正常。
把图5所示的350条记录网络历史数据作为测试和训练数据送入WAODE模型进行故障诊断,并与NB,AODE(如图1所示)两种分类器进行分类精度上的比较。在图6中,当丢失属性值逐渐增加时,三个分类器的分类精度逐渐下降,但在相同状态下,WAODE的分类精度始终优于NB和AODE,展示了WAODE有很好的容错能力和学习能力。
上述技术方案只是本发明的一种实施方式,对于本领域内的技术人员而言,在本发明公开了应用方法和原理的基础上,很容易做出各种类型的改进或变形,而不仅限于本发明上述具体实施方式所描述的方法,因此前面描述的方式只是优选的,而并不具有限制性的意义。
- 还没有人留言评论。精彩留言会获得点赞!