一种基于多源信息融合的实时驾驶员疲劳预警系统的制作方法
本发明涉及驾驶员疲劳预警技术领域,尤其涉及一种基于多源信息融合的实时驾驶员疲劳预警系统。
背景技术:
根据交通事故年鉴:疲劳驾驶经常导致严重的交通事故,其中有17%致命的交通事故是疲劳驾驶引起的,然而在事故真正发生前司机一般不会意识到自己在疲劳驾驶。快速、准确的人眼及嘴巴定位及跟踪算法可以提高疲劳驾驶状态的检测速度,对减少交通事故的发生具有重要意义。疲劳检测系统通过实时分析驾驶员疲劳状态,根据量化的疲劳程度不同等级在必要时发出相应的预警信息。可以有效避免车祸的发生,因此具有很重要的研究意义。
传统的Kalman滤波和Mean shift相结合的算法能够跟踪目标,在目标快速运动和严重遮挡情况下常常跟踪失败,同时算法消耗的时间代价也是不能忽略的,达不到实时性的要求。
现有技术中灰度投影对人脸配戴眼镜、姿态变化敏感,以及模板匹配算法虽精度较高,但计算量过大,程序繁琐,十分不便。
传统的模板匹配是对整幅图像与目标图像相同位置的像素灰度值或颜色值进行比较,该方法存在计算的复杂度高,对目标的旋转比较敏感,干扰因素较多的问题。
技术实现要素:
为了克服现有技术的不足,本发明提供一种基于多源信息融合的实时驾驶员疲劳预警系统,以预防驾驶员疲劳驾驶为目标,系统无论在夜晚还是白天,全天候工作,实时对司机的疲劳状态作出准确的分析,具有总体运算量小、传输速率快、探测精度高、反应速度快等优点,实用性更强、应用范围更广的特点。
为了实现上述目的,本发明通过以下技术方案实现:
一种基于多源信息融合的实时驾驶员疲劳预警系统,包括以下步骤:
Step1、通过红外摄像头实时获取的驾驶员面部视频,通过视频采集模块将视频转化为图像序列传给控制器;
Step2、控制器采用图像网络分析算法实现人脸检测,首先对采集的面部图像进行中值滤波、直方图均衡化预处理;
对预处理后的图像二值化,对所得图像采用10×10的网格进行分块处理;统计每个小方块的黑色像素在图像中的比例,设定适用于大多数的人脸判别方式的合适比例P,P≤0.2,将满足面部检测要求的小方块提取出来组成新的图像,找到人脸面积最大的联通区域,检测出人脸区域;组成人脸区域的几何结构特征;
Step3、人眼初始帧的定位:
将灰度积分投影曲线与人脸区域的几何结构特征相结合,排除嘴巴和背景的干扰,对检测到的人脸图像实现较为准确的眉眼粗定位;采用模板匹配的方法在定位出的眉眼区域内逐点平移参考模板,遍历眉眼区域图像内的每个像素,找出并确定与参考模板最相似的位置,实现对眼睛在眉眼区域的定位;
所述的灰度积分投影曲线是对检测出的人脸图像分别进行水平和垂直方向的投影所得到两个方向上的像素灰度的累加值曲线,根据曲线中波峰波谷的分布及人脸面部几何特征知识定位人眼区域;
设在大小为92×112的图像上,I(x,y)为图像上(x,y)像素点的灰度值,其中区间[x1,x2]即为[0,91],区间[y1,y2]即为[0,111];水平和垂直积分投影函数分别表示为H(x)和V(y)。
人脸图像分别往水平、垂直方向投影,在进行水平方向投影时,可以看到主要出现两个极大值点,分别对应两个眼睛;而对垂直方向投影时,可以看到有大概3个明显的极大值点,分别大致对应着眉毛、眼睛和嘴巴;眼睛区域根据人脸特征分布的几何知识在人脸的上半部,所以在垂直方向灰度积分投影时应该取前半部分的最大值;通过水平和垂直方向的坐标投影结合人脸几何特征分布知识,实现人眼区域的粗定位;
采用模板匹配算法对定位出的眉眼区域搜索与人眼构建的模板最相似的匹配块,即寻找最大允许误差的位置;利用归一化互相关计算粗定位眉眼图像与人眼模板之间的相关系数来度量它们的匹配程度,相关系数r来表示两个向量的相关程度即:
式中,fn为模板图像的灰度;In为目标图像的灰度;和分别为模板图像和目标图像的灰度均方值;采用均方误差(MSE)和平均绝对误差(MAD)作为匹配算法搜索最佳匹配的价值函数;其中N为块边长像素数,Cij和Rij分别为目标图像宏块和模板宏块相应像素的灰度值;
所述的模板匹配的具体步骤如下:
步骤一:假定原眉眼图像I(x,y)和人眼模板图像F(k,j)的起始点都在左上角;
步骤二:当x和y变化时,根据归一化互相关矩阵计算F(k,j)在图像I区域中移动所有的r值;
步骤三:r取最大值时即是人眼模板图像与原眉眼图匹配的最佳位置,从该位置开始在原眉眼图像相应搜索区域中寻找最小的价值函数(MAD),即可找到匹配图像;
利用模板图像、眉眼区域图像、人脸图像之间的坐标关系变换,完成在人脸图像中的眼睛定位;
采用Jesorsky等人的眼睛定位正确性度量标准,设手工标定的左右眼睛准确位置分别为EL和ER,算法检测到的左右眼睛位置分别为EL'和ER';dl、dr和dlr分别为EL-EL',ER-ER'和EL-ER的距离,定位的相对误差定义为
eer≤0.25,eer≤0.10分别对应定位的眼睛坐标在眼镜框、眼球内;为了达到疲劳检测系统的实用要求,本文采用的人眼定位算法的评价标准为eer≤0.10,对所采用的120幅人眼定位平均相对误差eer=0.0784,小于本文采用的人眼定位准确评价标准eer≤0.10,满足驾驶员疲劳检测应用的需要;
Step4、嘴巴初始帧的定位,将检测到的人脸区域转换为数组形式,数组的第一维为高度方向(从上到下),第二维为宽度方向(从左向右),根据根据人脸器官“三庭五眼”的分布规则,截取图像中所需图像部分,感兴趣的区域(Region of Interest,即ROI区域),实现嘴巴的粗定位,对粗定位的嘴巴区域采用rgb红色分量结合最大连通域实现嘴部的精确定位;采用角点算法定位嘴角的两边,然后检测嘴唇的上下边界获取嘴巴的高度与宽度的比值H/W;
Step5、将Step3和Step4中定位好的图像,通过给定初始帧图像的眼睛和嘴巴的初始坐标及长度和宽度,采用在线选择显著特征算法(ODFS)算法实现对眼睛和嘴巴的实时跟踪;
步骤一;将定位好的眼睛和嘴巴的图像载入图像序列,采用(ODFS)算法标记检测到的初始帧图像的左右眼睛和嘴巴的初始坐标及长度和宽度,得到搜索框;
步骤二;从定位的初始帧图像中随机提取数据集{X+,X-},构建正负样本;对样本采用Haar特征提取,得到M个特征,通过利用在线学习,沿着正样本的最陡上升梯度和负样本的最陡下降梯度来迭代优化目标函数,自适应地选出分类能力强的特征,得到鲁棒强的集成分类器;
步骤三;对下一帧图像It+1在附近剪裁一系列和当前帧图像It目标等大的目标块,通过调用集成分类器计算概率p(y/x)=δ(HMK(x)),得到概率值最大的那个目标块即为目标的位置,其中δ(x)是sigmoid函数,
步骤四;通过计算跟踪目标当前帧It和下一帧It+1的中心误差值的欧几里得距离值||It+1-It||(||||表示欧几里得距离)与特定阈值δ=0.25进行比较,若||It+1-It||>δ,则转Step3,重新定位初始帧眼睛和嘴巴的位置,进行跟踪修订;若||It+1-It||≤δ,则继续跟踪;
Step6、对跟踪的眼睛及嘴巴的状态进行分析,采用OSTU算法(最大类间方差法)通过选稳定的阈值将眼部图像的灰度信息直方图分割成两部分,对定位出的眼睛进行二值化处理;统计二值化后的眼睛区域在横向和纵向上实际所占黑色像素值Contour_X、Contour_Y,通过即眼睛的纵横比的变化关系来判断眼睛的状态;
设定适用于大多数的人眼判别方式的合适阈值P=0.3;当检测人眼开度大于等于0.3时,则其为睁开的状态;反之,为闭合状态;
采用角点算法定位嘴角的两边,然后检测嘴唇的上下边界获取嘴巴的高度与宽度的比值H/W;
当(((H/W)>=0.1)&&((H/W)<=0.4))时,判定为嘴部闭着;当(((H/W)>0.4)&&((H/W)<=0.75))时,判定为嘴巴一般张开(嘴巴闭着和张开的中间状态);当((H/W)>0.75)时,判定为打哈欠;对实时跟踪得到的眼睛和嘴巴的状态数据进行归一化处理;
Step7、采用模糊神经网络算法对输入变量即眼睛和嘴巴的状态值进行模糊化处理,输出值在[0,0.4]范围内表示清醒状态;在[0.4,0.5]范围内表示临界状态;在[0.5,0.7]范围内表示中度疲劳状态;在[0.7,1]范围内表示重度疲劳状态;根据量化的疲劳程度不同等级在必要时通过无线传输设备激活报警系统。
本发明的有益效果:
本发明通过提出一种基于积分投影和模板匹配的人眼定位算法,该算法在一定程度上适应人脸图像光照和旋转角度的变化,排除眼镜的干扰,具有较好的鲁棒性;
在线选择显著特征算法(Online Discriminative Feature Selection)通过在线对特征的筛选,得到分类能力强的特征,进而得到较强的分类器,可以实时的跟踪定位出的眼睛和嘴巴,满足实时对司机驾驶的疲劳状态作出准确预测的需求。当检测到司机昏昏欲睡或者精神涣散,不集中的时候,会发出相应等级的报警声来提醒司机安全驾驶。采用这种方法设计防疲劳驾驶系统,实现了总体运算量小、传输速率快、探测精度高、反应速度快等优点,实用性更强、应用范围更广。本文中因为已粗略定位出眉眼区域,排除了嘴和背景干扰,有利于提高模板匹配算法在人眼检测方面的速度和准确率。
附图说明
图1在线学习训练集成分类器流程图。
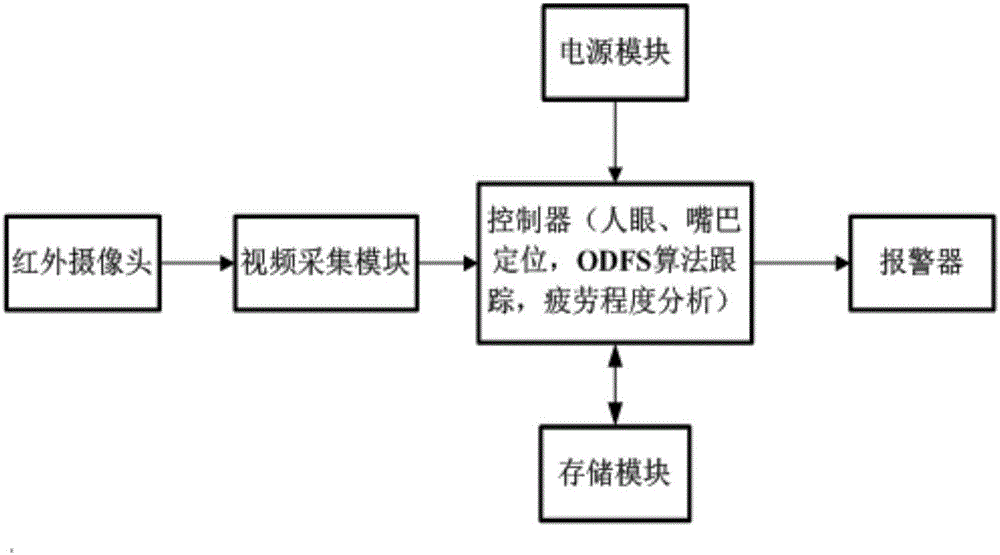
图2基于多源信息融合的实时驾驶员疲劳预警系统框图。
图3基于多源信息融合的实时驾驶员疲劳预警系统框图流程图。
图4是戴眼镜图像的眉眼粗定位示意图。
图5是头部不偏转图像的眉眼粗定位。
图6是头部偏转图像的眉眼粗定位。
图7是人眼图像模板示意图。
图8是人眼定位示意图。
图9为嘴巴定位过程图A。
图10为嘴巴定位过程图B。
图11为嘴巴定位过程图C。
图12为跟踪效果示意图。
具体实施方式
下面参照附图并结合实施例详述本发明。
如图1所示:从定位的初始帧图像中随机提取数据集{X+,X-},构建正负样本;对样本采用Haar特征提取,得到M个特征,通过利用在线学习,沿着正样本的最陡上升梯度和负样本的最陡下降梯度来迭代优化目标函数,自适应地选出分类能力强的特征,得到鲁棒强的集成分类器;
如图2图3所示:
Step1、通过红外摄像头实时获取的驾驶员面部视频,通过视频采集模块将视频转化为图像序列传给控制器;
Step2、控制器采用图像网络分析算法实现人脸检测,首先对采集的面部图像进行中值滤波、直方图均衡化预处理;
Step3、人眼初始帧的定位:
将灰度积分投影曲线与人脸区域的几何结构特征相结合,排除嘴巴和背景的干扰,对检测到的人脸图像实现较为准确的眉眼粗定位;采用模板匹配的方法在定位出的眉眼区域内逐点平移参考模板,遍历眉眼区域图像内的每个像素,找出并确定与参考模板最相似的位置,实现对眼睛在眉眼区域的定位;
Step4、嘴巴初始帧的定位,将检测到的人脸区域转换为数组形式,数组的第一维为高度方向(从上到下),第二维为宽度方向(从左向右),根据根据人脸器官“三庭五眼”的分布规则,截取图像中所需图像部分,感兴趣的区域(Region of Interest,即ROI区域),实现嘴巴的粗定位,对粗定位的嘴巴区域采用rgb红色分量结合最大连通域实现嘴部的精确定位;
Step5、将Step3和Step4中定位好的图像,通过给定初始帧图像的眼睛和嘴巴的初始坐标及长度和宽度,采用在线选择显著特征算法(ODFS)算法实现对眼睛和嘴巴的实时跟踪;
Step6、对跟踪的眼睛及嘴巴的状态进行分析,采用OSTU算法(最大类间方差法)通过选稳定的阈值将眼部图像的灰度信息直方图分割成两部分,对定位出的眼睛进行二值化处理;统计二值化后的眼睛区域在横向和纵向上实际所占黑色像素值Contour_X、Contour_Y,通过即眼睛的纵横比的变化关系来判断眼睛的状态;
Step7、采用模糊神经网络算法对输入变量即眼睛和嘴巴的状态值进行模糊化处理,输出值在[0,0.4]范围内表示清醒状态;在[0.4,0.5]范围内表示临界状态;在[0.5,0.7]范围内表示中度疲劳状态;在[0.7,1]范围内表示重度疲劳状态;根据量化的疲劳程度不同等级在必要时通过无线传输设备激活报警系统。
如图4、图5与图6所示:所述的灰度积分投影法算法对检测出的人脸图像分别进行水平和垂直方向的投影,得到两个方向上的像素灰度的累加值曲线,然后根据曲线中波峰波谷的分布及人脸面部几何特征知识定位人眼区域;
设在大小为92×112的图像上,I(x,y)为图像上(x,y)像素点的灰度值,其中区间[x1,x2]即为[0,91],区间[y1,y2]即为[0,111];水平和垂直积分投影函数分别表示为H(x)和V(y)。
人脸图像分别往水平、垂直方向投影,在进行水平方向投影时,可以看到主要出现两个极大值点,分别对应两个眼睛;而对垂直方向投影时,可以看到有大概3个明显的极大值点,分别大致对应着眉毛、眼睛和嘴巴;眼睛区域根据人脸特征分布的几何知识在人脸的上半部,所以在垂直方向灰度积分投影时应该取前半部分的最大值。通过水平和垂直方向的坐标投影结合人脸几何特征分布知识,实现人眼区域的粗定位;
如图9所示、图10、如图11和图12所示:为嘴巴定位过程图。
表1定位准确率及平均定位时间
表2分层抽样图像的人眼定位计算坐标与实际坐标之间的相对误差
- 还没有人留言评论。精彩留言会获得点赞!