对象处理方法及装置与流程
本发明涉及通信领域,更为具体而言,涉及对象处理方法及装置。
背景技术:
对象(例如,菜品)的标签是人工定义的有限集合,例如,【川菜】、【祛寒】等。利用标签标注对象的技术是基于对象与标签之间的相似性来确定是否采用该标签来标注所述对象。其中的关键技术是向量的相似度计算,即基于对象的向量与标签的向量之间的相似度来确定对象与标签之间的相似性。
然而,在现有技术当中,标签的向量通常需要人为构造,具体而言,需要人为地给标签确定若干个关键词,并给每个关键词人为地赋予权重weight_i,利用这些权重构造出标签tag_i的向量vector_i=[weight_1,weight_2,weight_3,……weight_n],然而,这种人为构造标签向量的方法受人为主观因素的影响,导致其结果不稳定。
技术实现要素:
为解决上述技术问题,本发明提供了对象处理方法及装置。
一方面,本发明的实施方式提供了一种对象处理方法,所述方法包括:
获取待标注对象的向量;
根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签;
若判定为采用所述标签,则通过所述标签标注所述待标注对象。
在本发明的实施方式中,利用标签下的种子对象(具有代表性的典型对象)的向量(即种子对象向量)来取代标签自身的向量,与待标注对象的向量进行相似度计算,省去了对标签进行向量构造的过程,从而有效避免了上述人为构造标签向量所带来的问题。
在本发明的一些实施方式中,所述根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签包括:
根据所述相似度计算所述标签的相似性得分;
确定所述相似性得分的排序位次;
识别所述排序位次是否落入设定范围;
若所述排序位次落入设定范围,则判定为采用所述标签。
在本发明的实施方式中,只有当标签的相似性得分的排序位次落入了预先设定的范围时,才判定为采用该标签对待标注对象进行标注,例如,按照相似性得分从高到低的顺序对相似性得分进行排序,只有当标签的相似性得分在第1位到第5位之间时,才判定为采用该标签;或者,按照相似性得分从低到高的顺序对相似性得分进行排序,只有当标签的相似性得分在最后1位到倒数第5位之间时,才判定为采用该标签,由此可以提高利用标签标注对象的准确度。
在本发明的一些实施方式中,所述方法还包括:
构建训练语料,所述训练语料用于获取所述待标注对象的向量。
为了进一步提高标签标注的准确度,在本发明的一些实施方式中,所述方法还包括:
对所述训练语料执行降噪处理。
其中,在本发明的一些实施方式中,所述对所述训练语料执行降噪处理包括:
对所述训练语料中的对象表征文本执行清洗处理;
识别清洗后的对象表征文本是否为噪声数据;
若所述清洗后的对象表征文本为噪声数据,则将所述清洗后的对象表征文本从所述训练语料中去除。
另一方面,本发明的实施方式提供了一种对象处理装置,所述装置包括:
获取模块,用于获取待标注对象的向量;
判断模块,用于根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签;
标注模块,用于在判定为采用所述标签的情形下,通过所述标签标注所述待标注对象。
在本发明的实施方式中,利用标签下的种子对象(具有代表性的典型对象)的向量(即种子对象向量)来取代标签自身的向量,与待标注对象的向量进行相似度计算,省去了对标签进行向量构造的过程,从而有效避免了上述人为构造标签向量所带来的问题。
在本发明的一些实施方式中,所述判断模块包括:
计算单元,用于根据所述相似度计算所述标签的相似性得分;
确定单元,用于确定所述相似性得分的排序位次;
第一识别单元,用于识别所述排序位次是否落入设定范围;
判定单元,用于在所述排序位次落入设定范围的情形下,判定为采用所述标签。
在本发明的实施方式中,只有当标签的相似性得分的排序位次落入了预先设定的范围时,才判定为采用该标签对待标注对象进行标注,例如,按照相似性得分从高到低的顺序对相似性得分进行排序,只有当标签的相似性得分在第1位到第5位之间时,才判定为采用该标签;或者,按照相似性得分从低到高的顺序对相似性得分进行排序,只有当标签的相似性得分在最后1位到倒数第5位之间时,才判定为采用该标签,由此可以提高利用标签标注对象的准确度。
在本发明的一些实施方式中,所述装置还包括:
构建模块,用于构建训练语料,所述训练语料用于获取所述待标注对象的向量。
为了进一步提高标签标注的准确度,在本发明的一些实施方式中,所述装置还包括:
降噪模块,用于对所述训练语料执行降噪处理。
其中,在本发明的一些实施方式中,所述降噪模块包括:
清洗单元,用于对所述训练语料中的对象表征文本执行清洗处理;
第二识别单元,用于识别清洗后的对象表征文本是否为噪声数据;
去除单元,用于在所述清洗后的对象表征文本为噪声数据的情形下,将所述清洗后的对象表征文本从所述训练语料中去除。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明方法实施方式1的对象处理方法的流程图;
图2示出了图1所示的处理s12的一种实施方式;
图3是根据本发明方法实施方式7的对象处理方法的流程图;
图4是根据本发明方法实施方式9的对象处理方法的流程图;
图5示出了图4所示的处理s32的一种实施方式;
图6是根据本发明装置实施方式1的对象处理装置的结构示意图;
图7示出了图6所示的判断模块12的一种实施方式。
具体实施方式
以下结合附图和具体实施方式对本发明的各个方面进行详细阐述。其中,在本发明的各个具体实施方式中,众所周知的模块、单元及其相互之间的连接、链接、通信或操作没有示出或未作详细说明。
并且,所描述的特征、架构或功能可在一个或一个以上实施例中以任何方式组合。
此外,本领域技术人员应当理解,下述的各种实施方式只用于举例说明,而非用于限制本发明的保护范围。本领域的技术人员还可以容易理解,本文所述和附图所示的各实施方式中的模块或单元或步骤可以按多种不同配置进行组合和设计。
对于未在本说明书中进行具体说明的技术术语,除非另有特定说明,都应以本领域最宽泛的意思进行解释。
【方法实施方式1】
图1是根据本发明方法实施方式1的对象处理方法的流程图。参见图1,在本实施方式中,所述方法包括:
s11:获取待标注对象的向量。
s12:根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签。若是,则执行s13,若否,则执行s14。
s13:通过所述标签标注所述待标注对象。
s14:结束当前流程。
在本发明的实施方式中,利用标签下的种子对象(具有代表性的典型对象)的向量(即种子对象向量)来取代标签自身的向量,与待标注对象的向量进行相似度计算,省去了对标签进行向量构造的过程,从而有效避免了上述人为构造标签向量所带来的问题。
【方法实施方式2】
本实施方式所提供的方法包括了方法实施方式1中的全部内容,在此不再赘述。其中,在本实施方式中,处理s11可以通过下述方式实现:利用神经网络模型训练出待标注对象的向量。
【方法实施方式3】
本实施方式所提供的方法包括了方法实施方式1中的全部内容,在此不再赘述。其中,在本实施方式中,所述种子对象包括:所述标签下置信度大于或等于设定阈值的已标注对象。
在本发明的实施方式中,以置信度大于或者等于设定阈值的已标注对象作为相应标签下的种子对象,来代表该标签与待标注对象进行相似度计算,可以提高该相似度计算的准确度。
【方法实施方式4】
本实施方式所提供的方法包括了方法实施方式1中的全部内容,在此不再赘述。其中,在本实施方式中,所述相似度基于所述待标注对象的向量与所述种子对象向量的夹角的余弦值计算得出。
【方法实施方式5】
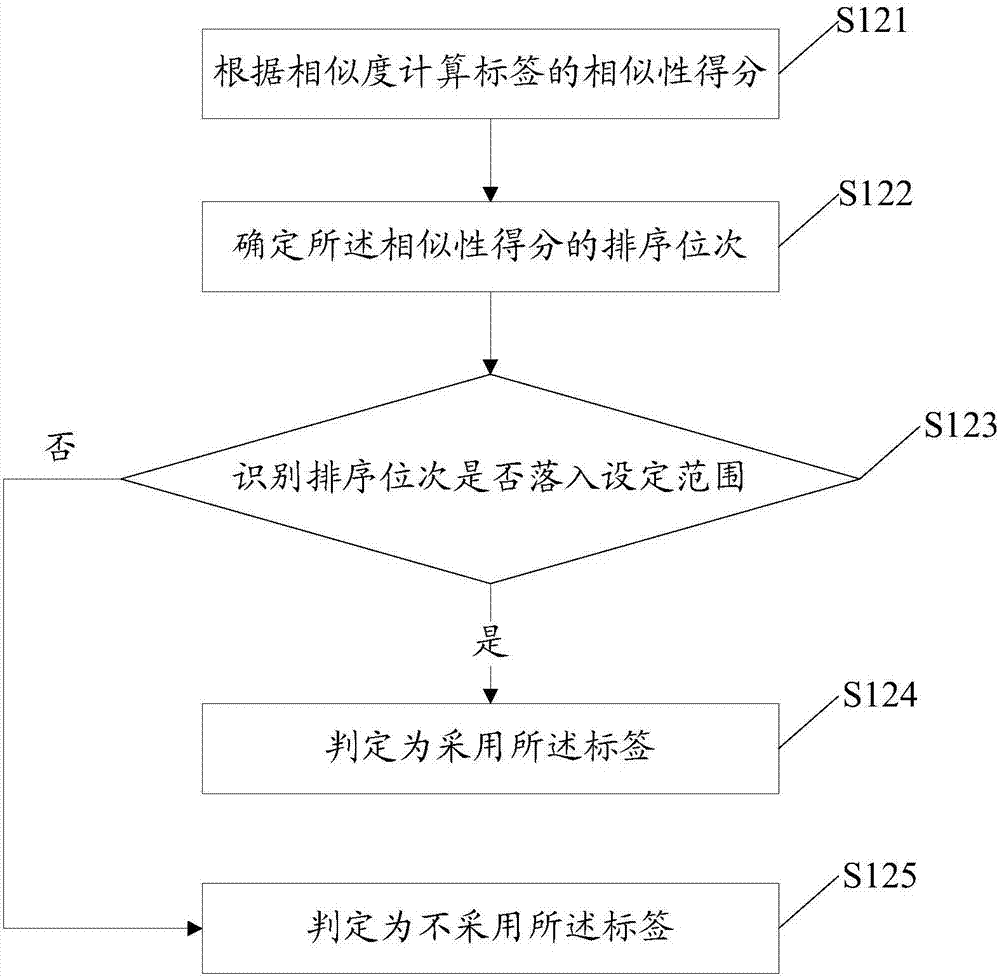
本实施方式所提供的方法包括了方法实施方式1中的全部内容,在此不再赘述。其中,如图2所示,在本实施方式中,处理s12通过下述处理实现:
s121:根据所述相似度计算所述标签的相似性得分。
其中,基于下述公式计算所述相似性得分:
score_i表示:标签i的相似性得分。
cos(待标注对象,标签i下的每一个种子对象)表示:待标注对象的向量与标签i下的每一个种子对象的向量的夹角的余弦值,即待标注对象的向量与标签i下每一个种子对象的向量之间的相似度。
s122:确定所述相似性得分的排序位次。
s123:识别所述排序位次是否落入设定范围,若是,则执行s124,若否,则执行s125。
s124:判定为采用所述标签。
s125:判定为不采用所述标签。
在本发明的实施方式中,只有当标签的相似性得分的排序位次落入了预先设定的范围时,才判定为采用该标签对待标注对象进行标注,例如,按照相似性得分从高到低的顺序对相似性得分进行排序,只有当标签的相似性得分在第1位到第5位之间时,才判定为采用该标签;或者,按照相似性得分从低到高的顺序对相似性得分进行排序,只有当标签的相似性得分在最后1位到倒数第5位之间时,才判定为采用该标签,由此可以提高利用标签标注对象的准确度。
【方法实施方式6】
本实施方式所提供的方法包括了方法实施方式2中的全部内容,在此不再赘述。其中,在本实施方式中,所述神经网络模型包括:word2vec(词向量训练模型)。
自然语言处理(nlp)相关任务中,要将自然语言交给机器学习中的算法来处理,通常需要首先将语言数学化,因为机器不是人,机器只认数学符号。向量是人把自然界的东西抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式。
传统的中文文本的向量表示采用下述方式实现:
设定该中文文本为doc_i,该中文文本doc_i中的所有词汇集合是个有限的集合s,其中,term_x表示集合中第x个元素,集合s的大小为m。对doc_i进行中文分词并去除停词(例如,【的】【地】【得】这样的词)之后,剩余的n个词汇组成的集合为s的子集,且n小于等于m。
设定每个剩余词汇的出现次数为:n_1,n_2,n_3,…,n_n。则可以用一个m维的向量来表示这个中文文本doc_i。即在子集中出现的词汇term_j,在m维向量的对应位置上为n_j,在子集中未出现的词汇,在m维向量的对应位置上为0。对k位置的出现次数用dweight_k进行表示。
这样,中文文本doc_i可以被表示成一个固定维度的向量:vector_i=[dweight_1,dweight_2,…dweight_k,…dweight_m]
然而,以菜品对象为例,一般菜品对象的对象表征文本(即用于对对象进行表征的文本,例如,菜品名称)在10个字以内,然而,针对这样的短文本,通过上述方式得到的向量会非常稀疏,最终导致利用标签标注对象的准确度极低。
在本实施方式中,通过word2vec模型来训练待标注的对象的向量。
word2vec是google在2013年年中开源的一款将词表征为实数值向量的高效工具,其利用深度学习的思想,可以通过训练,把对文本内容的处理简化为k维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。word2vec输出的词向量可以被用来做很多nlp相关的工作,比如聚类、找同义词、词性分析等等。如果换个思路,把词当作特征,那么word2vec就可以把特征映射到k维向量空间,可以为文本数据寻求更加深层次的特征表示。
word2vec使用的是distributedrepresentation(分布式表示)的词向量表示方式。distributedrepresentation最早由hinton在1986年提出。其基本思想是通过训练将每个词映射成k维实数向量(k一般为模型中的超参数),通过词之间的距离(比如cosine相似度、欧氏距离等)来判断它们之间的语义相似度。其采用一个三层的神经网络,输入层-隐藏层-输出层。这个三层神经网络本身是对语言模型进行建模,但也同时获得一种单词在向量空间上的表示,而这个副作用才是word2vec的真正目标。
采用word2vec模型来训练待标注的对象的向量,无需对文本进行分词,因此,针对短文本而言可以更加合理、有效、准确地生成向量,提高标签标注的准确度。
其中,在本发明的一些实施方式中,所述word2vec模型包括下述之一:cbow(continuousbag-of-words,连续词袋)模型以及skip-gram(跳元)模型。
【方法实施方式7】
图3是根据本发明方法实施方式7的对象处理方法的流程图。参见图3,所述方法包括:
s21:构建训练语料。
其中,所述训练语料包括:包含待标注对象在内的多个对象的对象表征文本。
s22:利用word2vec模型通过所述训练语料训练出待标注对象的向量。
s23:根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签。若是,则执行s24,若否,则执行s25。
s24:通过所述标签标注所述待标注对象。
s25:结束当前流程。
【方法实施方式8】
本实施方式所提供的方法包括了方法实施方式7中的全部内容,在此不再赘述。其中,在本实施方式中,处理s21通过下述方式实现:基于对象的分类信息构建所述训练语料。
由于在本发明的实施方式中,所述训练语料基于对象的分类信息构建而成,因此,可以提高所述训练语料中各对象表征文本所表征的对象之间的相关性,进而可以更加准确地训练出对象的向量。
【方法实施方式9】
图4是根据本发明方法实施方式9的对象处理方法的流程图。参见图4,所述方法包括:
s31:构建训练语料。
其中,所述训练语料包括:包含待标注对象在内的多个对象的对象表征文本。
s32:对所述训练语料执行降噪处理。
s33:利用word2vec模型通过经所述降噪处理后的训练语料训练出待标注对象的向量。
s34:根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签。若是,则执行s35,若否,则执行s36。
s35:通过所述标签标注所述待标注对象。
s36:结束当前流程。
【方法实施方式10】
本实施方式所提供的方法包括了方法实施方式9中的全部内容,在此不再赘述。其中,如图5所示,在本实施方式中,处理s32通过下述处理实现:
s321:从所述训练语料中选取一个未被选取过的对象表征文本。
s322:对选取出的对象表征文本执行清洗处理。
s323:识别清洗后的对象表征文本是否为噪声数据,若是,则执行s324,若否,则执行s325。
s324:将该清洗后的对象表征文本从所述训练语料中去除。
s325:识别所述训练语料中是否存在未被选取过的对象表征文本,若是,则返回执行s321,若否,则执行s326。
s326:结束当前流程。
其中,在本发明的一些实施方式中,所述清洗处理包括:清洗标点符号和/或清洗描述性信息。
其中,所述描述性信息例如包括:单位、括号内容、描述前缀等。
【方法实施方式11】
本实施方式以待标注对象为菜品对象为例,对本实施方式所提供的对象处理方法的进行描述。所述方法包括下述处理:
step1:数据预处理。
为了提升最终结果的准确率,首先对全量的菜品库中的菜品名称做清洗处理。
清洗的规则为:去除中文标点符号;去除括号及括号内容;去除单位;去除描述前缀。
例如,【德州扒鸡】与【德州扒鸡半只】是相同的菜品,把第二个菜品名称去除【半只】。
step2:构建训练语料。
在神经网络的训练过程中,需要输入若干个由词组成的序列作为训练语料。在这一处理中,本发明创新地利用菜品的分类信息,作为训练语料构建的依据。具体而言,本实施方式中将全量的菜品库中同一类别下清洗过的菜品名称作为一个序列。这样以来,每个序列中各词之间的关系比较密切。不同类别组成不同的序列作为神经网络的输入。
节选示例如下:
...
布丁岩盐芝士红豆oreoq果珍珠小芋圆
珍珠茶拿铁布丁茶拿铁红豆茶拿铁红茶拿铁珍珠茶拿铁红豆茶拿铁布丁茶拿铁红茶拿铁
布丁可可双柚q果风味绿茶芒橙q果风味红茶菠萝q果风味红茶芒橙q果风味绿茶
原味奶茶原味奶茶珍珠奶茶珍珠奶茶大满贯布丁奶茶大满贯布丁奶茶oreo曲奇奶茶
...
step3:去掉训练语料中的噪声数据。
step4:训练菜品名称的向量。
选择浅层神经网络中的cbow模型进行训练,其中,共现窗口的大小设置为8,输出向量维度设置为20。当然,本发明的实施方式不限于此,本领域的技术人员可以根据实际需要对共现窗口的大小以及向量维度进行其他合理设置。最终通过所述cbow模型为训练语料中的每一个菜品名称训练出一个20维的向量。节选示例如下:
...
雪碧-->[2.990189,2.454690,...1.845449]
鱼香肉丝-->[-1.587564,-2.352610,...-1.935643]
酸辣土豆丝-->[-0.376799,0.052792,...-3.941500]
...
step5:菜品自动标签。
在这一处理中,本发明采取了种子词扩展的方法。相当于在每个标签下找几个典型的菜品作为种子菜品,利用种子菜品自动扩展出同标签下其他的菜品。种子菜品的构建比较简单,只要在每个标签下选取若干个置信度大于或者等于设定阈值的菜品即可。节选示例如下:
对于需要标注的菜品,计算其与标签i下的每一个种子菜品的相似度,以这些相似度的平均值作为标签i的相似性得分,然后,确定标签i的相似性得分score_i的排序位次,若score_i的排序位次落入设定范围内,则将该标签i作为所述需要标注的菜品的标签。
【装置实施方式1】
图6是根据本发明装置实施方式1的对象处理装置的结构示意图。参见图6,装置1包括:获取模块11、判断模块12、以及标注模块13,具体地:
获取模块11用于获取待标注对象的向量。
判断模块12用于根据获取模块11获取的向量与标签下种子对象向量的相似度判断是否采用所述标签。
标注模块13用于在判断模块12判定为采用所述标签的情形下,通过所述标签标注所述待标注对象。
在本发明的实施方式中,利用标签下的种子对象(具有代表性的典型对象)的向量(即种子对象向量)来取代标签自身的向量,与待标注对象的向量进行相似度计算,省去了对标签进行向量构造的过程,从而有效避免了上述人为构造标签向量所带来的问题。
【装置实施方式2】
本实施方式所提供的装置包括了装置实施方式1中的全部内容,在此不再赘述。其中,在本实施方式中,获取模块11包括:训练单元,该训练单元用于利用神经网络模型训练出待标注对象的向量。
【装置实施方式3】
本实施方式所提供的装置包括了装置实施方式1中的全部内容,在此不再赘述。其中,在本实施方式中,所述种子对象包括:所述标签下置信度大于或等于设定阈值的已标注对象。
在本发明的实施方式中,以置信度大于或者等于设定阈值的已标注对象作为相应标签下的种子对象,来代表该标签与待标注对象进行相似度计算,可以提高该相似度计算的准确度。
【装置实施方式4】
本实施方式所提供的装置包括了装置实施方式1中的全部内容,在此不再赘述。其中,在本实施方式中,所述相似度基于所述待标注对象的向量与所述种子对象向量的夹角的余弦值计算得出。
【装置实施方式5】
本实施方式所提供的装置包括了装置实施方式1中的全部内容,在此不再赘述。其中,如图7所示,在本实施方式中,判断模块12包括:计算单元121、确定单元122、第一识别单元123、以及判定单元124,具体地:
计算单元121用于根据所述相似度计算所述标签的相似性得分。
确定单元122用于确定计算单元121计算的相似性得分的排序位次。
第一识别单元123用于识别确定单元122确定的排序位次是否落入设定范围。
判定单元124用于在第一识别单元123识别出排序位次落入设定范围的情形下,判定为采用所述标签。
在本发明的实施方式中,只有当标签的相似性得分的排序位次落入了预先设定的范围时,才判定为采用该标签对待标注对象进行标注,例如,按照相似性得分从高到低的顺序对相似性得分进行排序,只有当标签的相似性得分在第1位到第5位之间时,才判定为采用该标签;或者,按照相似性得分从低到高的顺序对相似性得分进行排序,只有当标签的相似性得分在最后1位到倒数第5位之间时,才判定为采用该标签,由此可以提高利用标签标注对象的准确度。
【装置实施方式6】
本实施方式所提供的装置包括了装置实施方式2中的全部内容,在此不再赘述。其中,在本实施方式中,所述神经网络模型包括:word2vec模型。
自然语言处理(nlp)相关任务中,要将自然语言交给机器学习中的算法来处理,通常需要首先将语言数学化,因为机器不是人,机器只认数学符号。向量是人把自然界的东西抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式。
传统的中文文本的向量表示采用下述方式实现:
设定该中文文本为doc_i,该中文文本doc_i中的所有词汇集合是个有限的集合s,其中,term_x表示集合中第x个元素,集合s的大小为m。对doc_i进行中文分词并去除停词(例如,【的】【地】【得】这样的词)之后,剩余的n个词汇组成的集合为s的子集,且n小于等于m。
设定每个剩余词汇的出现次数为:n_1,n_2,n_3,…,n_n。则可以用一个m维的向量来表示这个中文文本doc_i。即在子集中出现的词汇term_j,在m维向量的对应位置上为n_j,在子集中未出现的词汇,在m维向量的对应位置上为0。对k位置的出现次数用dweight_k进行表示。
这样,中文文本doc_i可以被表示成一个固定维度的向量:vector_i=[dweight_1,dweight_2,…dweight_k,…dweight_m]
然而,以菜品对象为例,一般菜品对象的对象表征文本(即用于对对象进行表征的文本,例如,菜品名称)在10个字以内,然而,针对这样的短文本,通过上述方式得到的向量会非常稀疏,最终导致利用标签标注对象的准确度极低。
在本实施方式中,通过word2vec模型来训练待标注的对象的向量。
word2vec是google在2013年年中开源的一款将词表征为实数值向量的高效工具,其利用深度学习的思想,可以通过训练,把对文本内容的处理简化为k维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度。word2vec输出的词向量可以被用来做很多nlp相关的工作,比如聚类、找同义词、词性分析等等。如果换个思路,把词当作特征,那么word2vec就可以把特征映射到k维向量空间,可以为文本数据寻求更加深层次的特征表示。
word2vec使用的是distributedrepresentation(分布式表示)的词向量表示方式。distributedrepresentation最早由hinton在1986年提出。其基本思想是通过训练将每个词映射成k维实数向量(k一般为模型中的超参数),通过词之间的距离(比如cosine相似度、欧氏距离等)来判断它们之间的语义相似度。其采用一个三层的神经网络,输入层-隐藏层-输出层。这个三层神经网络本身是对语言模型进行建模,但也同时获得一种单词在向量空间上的表示,而这个副作用才是word2vec的真正目标。
采用word2vec模型来训练待标注的对象的向量,无需对文本进行分词,因此,针对短文本而言可以更加合理、有效、准确地生成向量,提高标签标注的准确度。
其中,在本发明的一些实施方式中,所述word2vec模型包括下述之一:cbow模型以及skip-gram模型。
【装置实施方式7】
本实施方式所提供的装置包括了装置实施方式1中的全部内容,在此不再赘述。其中,本实施方式所提供的装置还包括构建模块,具体地:
所述构建模块用于构建训练语料,所述训练语料用于获取所述待标注对象的向量。
【装置实施方式8】
本实施方式所提供的装置包括了装置实施方式7中的全部内容,在此不再赘述。其中,在本实施方式中,所述构建模块包括构建单元,具体地,所述构建单元用于基于对象的分类信息构建所述训练语料。
由于在本发明的实施方式中,所述训练语料基于对象的分类信息构建而成,因此,可以提高所述训练语料中各对象表征文本所表征的对象之间的相关性,进而可以更加准确地训练出对象的向量。
【装置实施方式9】
本实施方式所提供的装置包括了装置实施方式7中的全部内容,在此不再赘述。其中,本实施方式所提供的装置还包括:降噪模块,具体地:
所述降噪模块用于对所述训练语料执行降噪处理。
由此,可以进一步提高标签标注的准确度。
【装置实施方式10】
本实施方式所提供的装置包括了装置实施方式9中的全部内容,在此不再赘述。其中,在本实施方式中,所述降噪模块包括:清洗单元、第二识别单元、以及去除单元,具体地:
所述清洗单元用于对所述训练语料中的对象表征文本执行清洗处理。
所述第二识别单元用于识别清洗单元清洗后的对象表征文本是否为噪声数据。
去除单元用于在第二识别单元识别出所述清洗后的对象表征文本为噪声数据的情形下,将所述清洗后的对象表征文本从所述训练语料中去除。
其中,在本发明的一些实施方式中,所述清洗处理包括:清洗标点符号和/或清洗描述性信息。
其中,所述描述性信息例如包括:单位、括号内容、描述前缀等。
本发明的实施方式提供了一种移动终端,包括存储器和处理器;其中,
所述存储器用于存储一条或多条计算机指令,其中,所述一条或多条计算机指令供所述处理器调用执行;
所述处理器用于进行如方法实施方式1至方法实施方式11中任意一项所述的操作。
此外,本发明的实施方式还提供一种计算机存储介质,所述计算机存储介质存储有一条或多条计算机指令,当所述一条或多条计算机指令被一个或多个设备执行时,使得所述设备执行方法实施方式1至方法实施方式11中任意一项所述的操作。
本领域的技术人员可以清楚地了解到本发明可全部通过软件实现,也可借助软件结合硬件平台的方式来实现。基于这样的理解,本发明的技术方案对背景技术做出贡献的全部或者部分可以以软件产品的形式体现出来,所述计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,智能手机或者网络设备等)执行本发明各个实施方式或者实施方式的某些部分所述的方法。
本文中所使用的“软件”等词均指一般意义上的任意类型的计算机编码或者计算机可执行指令集,可以运行所述编码或者指令集来使计算机或其他处理器程序化以执行如上所述的本发明的技术方案的各个方面。此外,需要说明的是,根据实施方式的一个方面,在执行时实施本发明的技术方案的方法的一个或多个计算机程序不必须要在一台计算机或处理器上,而是可以分布于多个计算机或者处理器中的模块中,以执行本发明的技术方案的各个方面。
计算机可执行指令可以有许多形式,如程序模块,可以由一台或多台计算机或是其他设备执行。一般地,程序模块包括例程、程序、对象、组件以及数据结构等等,执行特定的任务或是实施特定的抽象数据类型。特别地,在各种实施方式中,程序模块的功能可以根据各个不同实施方式的需要进行结合或者拆分。
并且,本发明的技术方案可以体现为一种方法,并且已经提供了所述方法的至少一个示例。可以通过任何一种合适的顺序执行动作,所述动作表现为所述方法中的一部分。因此,实施方式可以构造成可以按照与所示出的执行顺序不同的顺序执行动作,其中,可以包括同时地执行一些动作(尽管在示出的实施方式中,这些动作是连续的)。
本文所给出的和使用的定义,应当对照字典、通过引用而并入的文档中的定义、和/或其通常意思进行理解。
在权利要求书中以及上述的说明书中,所有的过度短语,例如“包括”、“具有”、“包含”、“承载”、“具有”、“涉及”、“主要由…组成”以及类似词语是应理解为是开放式的,即,包含但不限于。只有“由……组成”应该是封闭或半封闭的过度短语。
本发明说明书中使用的术语和措辞仅仅为了举例说明,并不意味构成限定。本领域技术人员应当理解,在不脱离所公开的实施方式的基本原理的前提下,对上述实施方式中的各细节可进行各种变化。因此,本发明的范围只由权利要求确定,在权利要求中,除非另有说明,所有的术语应按最宽泛合理的意思进行理解。
本发明公开a1、一种对象处理方法,包括:
获取待标注对象的向量;
根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签;
若判定为采用所述标签,则通过所述标签标注所述待标注对象。
a2、如a1所述的方法中,所述根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签包括:
根据所述相似度计算所述标签的相似性得分;
确定所述相似性得分的排序位次;
识别所述排序位次是否落入设定范围;
若所述排序位次落入设定范围,则判定为采用所述标签。
a3、如a1或a2所述的方法,还包括:
构建训练语料,所述训练语料用于获取所述待标注对象的向量。
a4、如a3所述的方法中,所述构建训练语料包括:
基于对象的分类信息构建所述训练语料。
a5、如a3所述的方法,还包括:
对所述训练语料执行降噪处理。
a6、如a5所述的方法中,所述对所述训练语料执行降噪处理包括:
对所述训练语料中的对象表征文本执行清洗处理;
识别清洗后的对象表征文本是否为噪声数据;
若所述清洗后的对象表征文本为噪声数据,则将所述清洗后的对象表征文本从所述训练语料中去除。
本发明还公开了b7、一种对象处理装置,包括:
获取模块,用于获取待标注对象的向量;
判断模块,用于根据所述向量与标签下种子对象向量的相似度判断是否采用所述标签;
标注模块,用于在判定为采用所述标签的情形下,通过所述标签标注所述待标注对象。
b8、如b7所述的装置中,所述判断模块包括:
计算单元,用于根据所述相似度计算所述标签的相似性得分;
确定单元,用于确定所述相似性得分的排序位次;
第一识别单元,用于识别所述排序位次是否落入设定范围;
判定单元,用于在所述排序位次落入设定范围的情形下,判定为采用所述标签。
b9、如b7或b8所述的装置,还包括:
构建模块,用于构建训练语料,所述训练语料用于获取所述待标注对象的向量。
b10、如b9所述的装置中,所述构建模块包括:
构建单元,用于基于对象的分类信息构建所述训练语料。
b11、如b9所述的装置,还包括:
降噪模块,用于对所述训练语料执行降噪处理。
b12、如b11所述的装置中,所述降噪模块包括:
清洗单元,用于对所述训练语料中的对象表征文本执行清洗处理;
第二识别单元,用于识别清洗后的对象表征文本是否为噪声数据;
去除单元,用于在所述清洗后的对象表征文本为噪声数据的情形下,将所述清洗后的对象表征文本从所述训练语料中去除。
本发明还公开了c13、一种移动终端,包括存储器和处理器;其中,
所述存储器用于存储一条或多条计算机指令,其中,所述一条或多条计算机指令供所述处理器调用执行;
所述处理器用于进行如a1至a6中任意一项所述的操作。
- 还没有人留言评论。精彩留言会获得点赞!