一种数据存储方法及数据存储装置与流程
本发明涉及信息处理
技术领域:
,特别涉及一种数据存储方法及数据存储装置。
背景技术:
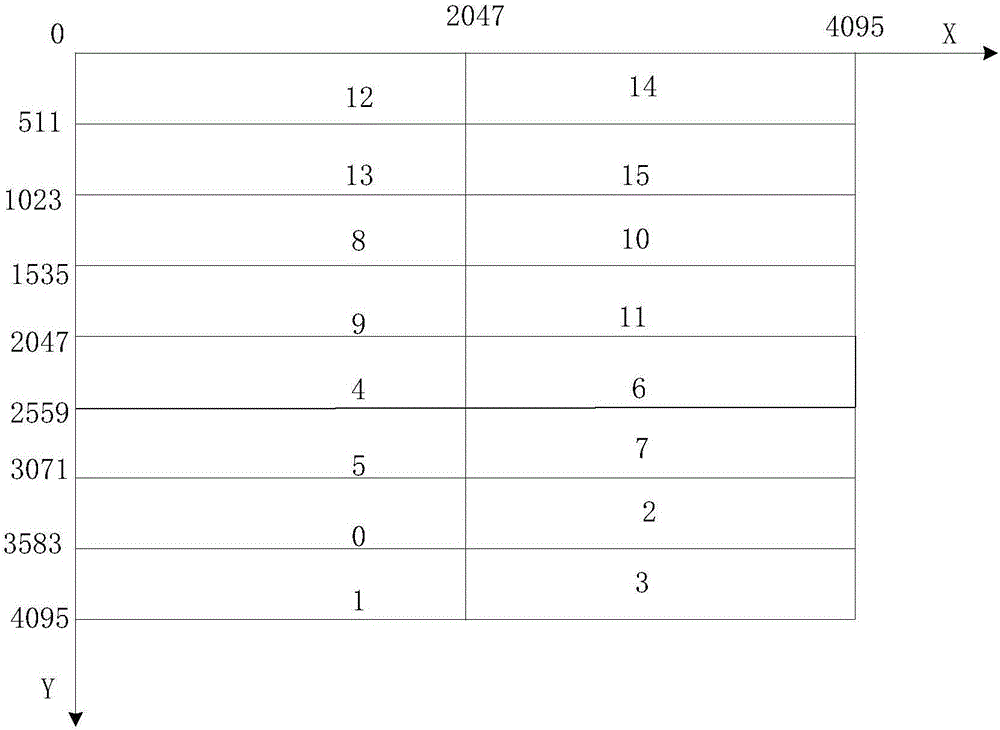
:为了测试芯片的性能,需要用测序仪采集芯片中各反应单元(即芯片中进行相关反应的反应腔)的输出数据进行研究。现有技术中,为了方便数据的采集,常会设计简单的数据采样原则或采集方法。但本发明的发明人发现,这些数据采样原则或采集方法通常会每次采集的数据的个数有要求,芯片中实际的反应单元的个数要远远小于该要求的个数,而为了满足该要求的个数,采集数据时往往会引入大量的冗余数据(即无效数据),也就是说原始数据文件中既包括有效数据(芯片中各反应单元的输出数据),也包括冗余数据。由于冗余数据是虚假、无效、不参与数据计算的,尤其是对于高通量测序仪而言,冗余数据个数的量级是十万、百万级别的,它们的存在不仅占用大量的内存空间。更重要的是,在查找相关反应单元的输出数据时,为了避开冗余数据,常常需要设置很多判断条件来参与数值计算,这必将造成计算时间的大量浪费。技术实现要素:本发明实施方式的目的在于提供一种数据存储方法及数据存储装置,使得可以剔除原始数据文件中采集的冗余数据,只存储芯片中各反应单元的输出数据,从而减小内存空间,并提高查找相关反应单元的输出数据的速度。为解决上述技术问题,本发明的实施方式提供了一种数据存储方法,包括:从原始数据文件中读取2*M个数据;按照原始数据文件中数据的存储规律,将读取的数据分别存入预设的C个长度为DX的一维变量中;计算每一个一维变量的第一个数据在预设的二维变量中的开始位置,其中,该二维变量的行数为N,列数为P;从开始位置按照存储规律将所述一维变量中的有效数据填充到二维变量;其中,(M/2)<P≤N≤M,N、P为自然数,M=2m,m为自然数。本发明的实施方式还提供了一种数据存储装置,包括:读取模块、缓存模块、计算模块及存储模块;读取模块用于从原始数据文件中读取2*M个数据;缓存模块用于按照原始数据文件中数据的存储规律,将读取的数据分别存入预设的C个长度为DX的一维变量中;计算模块用于计算每一个一维变量的第一个数据在预设的二维变量中的开始位置,其中,该二维变量的行数为N,列数为P;存储模块用于从开始位置按照存储规律将一维变量中的有效数据填充到二维变量;其中,(M/2)<P≤N≤M,N、P为自然数,M=2m,m为自然数。本发明实施方式相对于现有技术而言,先从原始数据文件中提取出部分原始采集的数据,并将该原始采集的数据按照原始数据文件中数据的存储规律,存储至预设的一维变量中;再从该预设的一维变量中,将该原始采集的数据中的有效数据(芯片中各反应单元输出的数据)从计算出的开始位置起按照相应的规律(这些数据在原始数据文件中的存储规律)存储至预设的二维变量中,这样二维变量中的数据就全是有效数据。这种存储方式不仅会减少内存空间,还会减小查找相关反应单元的输出数据的时间,从而提高工作效率。进一步地,在从开始位置按照该存储规律将一维变量中的有效数据填充到二维变量之后,还包括:判断从原始数据文件中读取数据的次数是否达到P/2次;在没有达到P/2次时,则接着前一次读取数据从原始数据文件中读取当前的2*M个数据。进一步地,在按照原始数据文件中数据的存储规律,将读取的数据分别存入预设的C个长度为DX的一维变量中,将读取的每一个数据在原始数据文件中的位置索引整除C,并按照余数将读取的数据分别存入对应的一维变量中。进一步地,在计算每一个一维变量的第一个数据在预设的二维变量中的开始位置时,根据前一次计算出的开始位置计算当前的开始位置。附图说明图1是根据本发明第一实施方式的数据存储方法的流程图;图2是根据本发明第一实施方式的各通道采集的数据在原始数据文件中的分布示意图;图3是根据本发明第一实施方式的第0通道中数据的存储顺序示意图;图4是根据本发明第一实施方式的第3通道中数据的存储顺序示意图;图5是根据本发明第一实施方式的各通道采集的数据在二维变量中的存储示意图;图6是根据本发明第一实施方式的原始数据文件中各通道中的有效数据与冗余数据的分布示意图;图7是根据本发明第三实施方式的数据存储装置的结构框图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明的各实施方式进行详细的阐述。然而,本领域的普通技术人员可以理解,在本发明各实施方式中,为了使读者更好地理解本申请而提出了许多技术细节。但是,即使没有这些技术细节和基于以下各实施方式的种种变化和修改,也可以实现本申请所要求保护的技术方案。本发明的第一实施方式涉及一种数据存储方法。具体流程如图1所示:步骤101:从原始数据文件中读取2*M(M为4096)个数据。原始数据文件是按照现有技术中设计的采样原则或采样方法采集芯片中各反应单元的输出数据后存储这些采集数据的文件。该原始数据文件中既包括有效数据,也包括冗余数据。这些数据在原始数据文件中的存储规律与采集这些数据的规律相对应。假设本实施方式中,有效数据的个数为N*P(即芯片中反应单元的个数为)N*P,而总共需要采集M*M个数据,共有C个采集数据的通道,其中,(M/2)<P≤N≤M,N、P、C为自然数,M=2m,m为自然数。本实施方式将以M=4096、N=3648、P=3600、C=16为例进行说明。假设原始数据文件中数据的存储规律如下:将采集的第一个数据存储至第0通道的第一位置,将采集的第二个数据存储至第1通道的第一位置,将采集的第三个数据存储至第2通道的第一位置,以此类推,直至将采集的第16个数据存储至第15通道的第一位置。紧接着,进行下一循环,即将采集的第17个数据存储至第0通道的第二位置,将采集的第18个数据存储至第1通道的第二位置……直至将采集的4096*4096个数据全部存储完为止。图2示出了各通道采集的数据在原始数据文件中的分布示意图,每个通道对应的区域中可以存储2048*512个数据,即每一纵列可存储512个数据,共有2048个纵列。在对应第0通道的存储区域中,第一位置(即上文所说的第0通道的第一位置)的坐标为(2047,3583),第二位置的坐标为(2047,3582)……,第512位置的坐标为(2047,3072),第513位置的坐标为(2046,3583)……,由此可见,第0通道的存储区域中,存储数据的顺序是:先存储该存储区域中横坐标及纵坐标都最大的位置,再以该位置为基准,按照“横坐标不变、纵坐标递减”的顺序依次存储,当一纵列存储完后,再将当前的横坐标减1,继续按照“横坐标不变、纵坐标递减”的顺序依次存储(如图3所示,图中的箭头方向表示存储的顺序)。本实施方式中对应第1、4、5、8、9、12、13通道的存储区域,其存储顺序均与此相同。而对应第2、3、6、7、10、11、14、15通道的存储区域,其存储顺序为:先存储该存储区域中横坐标及纵坐标都最小的位置,再以该位置为基准,按照“横坐标不变、纵坐标递减”的顺序依次存储,当一纵列存储完后,再将当前的横坐标加1,继续按照“横坐标不变、纵坐标递减”的顺序依次存储(如图4所示,图4示出了第3通道中数据的存储顺序)。值得一提的是,当原始文件中的数据以矩阵的形式进行保存时,上文所说的“横坐标不变、纵坐标递减”可以看成是列编号不变、行编号递减。另外,值得注意的是,在采集数据时,会先采集有效数据,当有效数据采集完之后,才会引入冗余数据。需要强调的是,本实施方式是所述的原始数据文件中数据的存储规律仅是举例说明,然并不应以此为限,在实际应用中,原始数据文件中数据的存储规律应该与具体选择的采样原则相对应。根据上文假设的存储规律可知,本步骤中从原始数据文件中读取2*M(此处M为4096)个数据的顺序是:第0通道的第一位置、第1通道的第一位置、第2通道的第一位置……,第15通道的第一位置,待所述通道的第一位置的数据都被读取完后,进入下一循环,即第0通道的第二位置、第1通道的第二位置……,以此类推,直至读取2*M个数据,可以发现,读取数据顺序与原始文件中数据的存储顺序相同。步骤102:按照原始数据文件中数据的存储规律,将读取的数据分别存入预设的C个长度为DX的一维变量中。本步骤中,可为该C个长度为DX(512,即有512列)的一维变量依次编号为0、1、2……,15。在将读取的数据存入该C个一维变量中时,可按读取的数据顺序(即原始文件中数据的存储顺序),将读取的数据分别放入该C个一维变量中。具体地,将读取的第一个数据存储至编号为0的一维变量的第一列,将读取的第二个数据存储至编号为1的一维变量的第一列,……,以此类推,将读取的第16个数据存储至编号为15的一维变量的第一列,接着进入下一循环,即将读取的第17个数据存储至编号为0的一维变量的第二列,将读取的第18个数据存储至编号为1的一维变量的第二列……,直至将读取的2*M个数据完全存入该C个一维变量中。由此可以看出,原始数据文件中每个通道的第一纵列的512个数据存储在对应编号的一维变量中。例如,编号为0的一维变量中存储的是原始数据文件中第0通道的第一纵列的512个数据(该第一纵列即为第一位置至第512位置所在的纵列),编号为1的一维变量中存储的是原始数据文件中第1通道的第一纵列的512个数据,……,以此类推,编号为15的一维变量中存储的是原始数据文件中第15通道的第一纵列的512个数据。步骤103:计算每一个一维变量的第一个数据在预设的二维变量中的开始位置。该预设的二维变量的行数为N(即3648),列数为P(即3600)。图5示出了各通道采集的数据在该二维变量中的存储示意图。由于编号为0的一维变量中存储的是原始数据文件中第0通道的第一纵列的512个数据,将其存储在二维变量中时,也需要将其存储在二维变量中第0通道的第一纵列。根据上文假设的存储规律可知,原始数据文件中第0通道的第一纵列的512个数据中只有448个有效数据,且这448个数据占据第一纵列的前448个位置。因此,只需要将编号为0的一维变量中的前448个数据存储至二维变量中第0通道的第一纵列。从图5可以计算出,编号为0的一维变量中的第一个数据在二维变量中的开始位置的坐标为(1799,3199)。其他编号的一维变量中第一个数据在二维变量中的开始位置的计算方法,与上文提供的编号为0的一维变量中的第一个数据在二维变量中的开始位置的计算方法相同,本实施方式不再赘述。步骤104:从该开始位置按照存储规律将一维变量中的有效数据填充到二维变量中。仍以编号为0的一维变量为例。在将编号为0的一维变量中的有效数据存储至二维变量中时,以该计算出的开始位置的坐标为基准,可将编号为0的一维变量中的前448个数据按照“横坐标不变、纵坐标递减”的原则依次存储在坐标(1799,3199)、(1799,3198)……、(1799,2752)对应的位置处。值得一提的是,二维变量实际上是个矩阵,上文所说的“横坐标不变、纵坐标递减”可以看成是列编号不变、行编号递减。另外,需要说明的是,根据上文假设的存储规律可知,原始数据文件中除了第12、14通道的第一纵列中有512个有效数据外,其它通道的第一纵列中都只有前448个数据为有效数据。也就是说,除了编号为12、14的一维变量中有512个有效数据外,其它编号的一维变量中只有前448个数据为有效数据。步骤105:判断从原始数据文件中读取数据的次数是否达到P/2次。若是,则结束流程;若否,则进入步骤106。根据上文假设的存储规律可知,原始数据文件中各通道中,都只有前1800纵列中存在有效数据,且第12、14通道的每个纵列中有512个有效数据,其他通道的每个纵列中只有448个有效数据(如图6所示,图中阴影部分表示各通道中冗余数据的位置,空白部分表示各通道中有效数据的位置)。因此,每次读取2*M(M为4096)个数据,只需要读取P/2次(P=3600)就可以将所有的有效数据全部读取完毕。步骤106:接着前一次读取数据从原始数据文件中读取当前的2*M个数据。即从前一次读取的最后一个数据的下一位开始读取。如前一次读取的最后一个数据是第15通道的第512位置,即第15通道第一纵列的最后一个数,在图2中的坐标为(2048,512),则当前读取的第一个数据应是第0通道的第513位置,即第0通道第二纵列的第一位置,在图2中的坐标为(2046,3583)。在读取完当前的2*M个数据后,则重新进入步骤102。再次进入步骤103时,可以根据前一次计算出的开始位置计算当前的开始位置。以编号为0的一维变量为例,若前一次计算出的第一个数据的开始位置的坐标为(1799,3199),而前一次读取的数据已将二维变量中该坐标所在的纵列(即(1799,3199)、(1799,3198)……、(1799,2752))全部占据,因此,本次第一个数据的开始位置应是下一纵列的第一位置,坐标为(1798,3199),即将前一次计算出的第一个数据的开始位置的横坐标减1(即列编号减1)。当然,若是编号为2、3、6、7、10、11、14、15的一维变量,则需要将前一次计算出的第一个数据的开始位置的横坐标加1(即列编号加1)。本实施方式,先从原始数据文件中提取出部分原始采集的数据,并将该原始采集的数据按照原始数据文件中数据的存储规律,存储至预设的一维变量中;再从该预设的一维变量中,将该原始采集的数据中的有效数据(芯片中各反应单元输出的数据)从计算出的开始位置起按照相应的规律(这些数据在原始数据文件中的存储规律)存储至预设的二维变量中,这样二维变量中的数据就全是有效数据。这种存储方式不仅会减少内存空间,还会减小查找相关反应单元的输出数据的时间,从而提高工作效率。上面各种方法的步骤划分,只是为了描述清楚,实现时可以合并为一个步骤或者对某些步骤进行拆分,分解为多个步骤,只要包含相同的逻辑关系,都在本专利的保护范围内;对算法中或者流程中添加无关紧要的修改或者引入无关紧要的设计,但不改变其算法和流程的核心设计都在该专利的保护范围内。本发明的第二实施方式涉及一种数据存储方法。第二实施方式与第一实施方式大致相同,主要区别之处在于:第一实施方式是按照读取数据的顺序,将读取的数据分别放入该C个一维变量中的。而本发明第二实施方式,则是将读取的每一个数据在原始数据文件中的位置索引整除C,并按照余数将读取的数据分别存入对应的一维变量中的。具体地,以读取的第一个数据、第二个数据及第三个数据为例,读取的第一个数据是第0通道的第一位置上的数据。它在原始数据文件中的位置索引为0,用0整除C(16)余数为0,因此,可将读取的第一个数据存储至编号为0的一维变量中;读取的第二个数据是第1通道的第一位置上的数据。它在原始数据文件中的位置索引为1,用1整除C(16)余数为1,因此,可将读取的第一个数据存储至编号为1的一维变量中;读取的第三个数据是第2通道的第一位置上的数据。它在原始数据文件中的位置索引为2,用2整除C(16)余数为2,因此,可将读取的第一个数据存储至编号为2的一维变量。也就是说,用读取的数据的位置索引除以16,余数是多少,就将该读取的数据存储至编号为多少的一维变量中。表一示出了原始文件中各数据的位置索引。该位置索引是按照数据的存储顺序产生的。“0”是第0通道的第一位置上的数据(即第一个数据)的位置索引,“1”是第一通道的第一个数据的位置索引,“2”是第二通道的第一个数据的位置索引,以此类推,“16”是第一通道的第二个数据的位置索引,“17”是第二通道的第二个数据的位置索引。表一:位置索引012……1617……本发明第三实施方式涉及一种数据存储装置。如图7所示,该数据存储装置包括读取模块71、缓存模块72、计算模块73及存储模块74。具体地,读取模块71用于从原始数据文件中读取2*M个数据。缓存模块72用于按照原始数据文件中数据的存储规律,将读取的数据分别存入预设的C个长度为DX的一维变量中。其中,C*DX=2*M。计算模块73用于计算每一个一维变量的第一个数据在预设的二维变量中的开始位置。其中,该二维变量的行数为N,列数为P。存储模块74用于从该开始位置按照存储规律将一维变量中的有效数据填充到该二维变量中。其中,(M/2)<P≤N≤M,N、P为自然数,M=2m,m为自然数。本实施方式中,该数据存储装置还包括判断模块75。在存储模块74从该开始位置按照存储规律将一维变量中的有效数据填充到二维变量之后,判断模块75用于判断从原始数据文件中读取数据的次数是否达到P/2次,并在判定没有达到P/2次时,触发读取模块71接着前一次读取数据从原始数据文件中读取当前的2*M个数据。另外,值得一提的是,计算模块73在计算每一个一维变量的第一个数据在预设的二维变量中的开始位置时,可根据前一次计算出的开始位置计算当前的开始位置。具体地,若是编号为2、3、6、7、10、11、14、15的一维变量,则需要将前一次计算出的第一个数据的开始位置的横坐标加1(即列编号加1)并保持纵坐标不变(即行编号不变),以得到当前的第一个数据的开始位置的坐标;若是编号为1、4、5、8、9、12、13的一维变量,则需要将前一次计算出的第一个数据的开始位置的横坐标减1(即列编号减1)并保持纵坐标不变(即行编号不变),来得到当前的第一个数据的开始位置的坐标。不难发现,本实施方式为与第一实施方式相对应的装置实施例,本实施方式可与第一实施方式互相配合实施。第一实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在第一实施方式中。值得一提的是,本实施方式中所涉及到的各模块均为逻辑模块,在实际应用中,一个逻辑单元可以是一个物理单元,也可以是一个物理单元的一部分,还可以以多个物理单元的组合实现。此外,为了突出本发明的创新部分,本实施方式中并没有将与解决本发明所提出的技术问题关系不太密切的单元引入,但这并不表明本实施方式中不存在其它的单元。本发明第四实施方式涉及一种数据存储装置。第四实施方式与第三实施方式大致相同,主要区别之处在于:第三实施方式是按照读取数据的顺序,将读取的数据分别放入该C个一维变量中的。而在本发明第四实施方式则是将读取的每一个数据在原始数据文件中的位置索引整除C,并按照余数将读取的数据分别存入对应的一维变量中的。具体地说,本实施方式中,缓存模块通过将读取的每一个数据在原始数据文件中的位置索引整除C,并按照余数将读取的数据分别存入对应的一维变量中。也就是说,用读取的数据的位置索引除以16,余数是多少,就将该读取的数据存储至编号为多少的一维变量中。由于第二实施方式与本实施方式相互对应,因此本实施方式可与第二实施方式互相配合实施。第二实施方式中提到的相关技术细节在本实施方式中依然有效,在第二实施方式中所能达到的技术效果在本实施方式中也同样可以实现,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在第二实施方式中。本领域技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-OnlyMemory)、随机存取存储器(RAM,RandomAccessMemory)、磁碟或者光盘等各种可以存储程序代码的介质。本领域的普通技术人员可以理解,上述各实施方式是实现本发明的具体实施例,而在实际应用中,可以在形式上和细节上对其作各种改变,而不偏离本发明的精神和范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1