立体惯性导盲方法及装置和系统与流程
本发明涉及视力残疾人助行导航方法,更具体地说是指立体惯性导盲方法及装置和系统。
背景技术:
目前,市场上已出现多种导盲设备,比如导盲仗以及其他导盲设备,导盲仗又包括普通导盲仗以及超声导盲仗两种,其他导盲设备包括加装摄像头的导盲设备,由于我国视力残疾人数高达千万人,因此,导盲设备的需求量很大。
但是,上述的普通导盲仗是最传统的视力残疾人用导盲产品,只能帮助视力残疾人探测前方有限距离的障碍物,也没法做障碍物体识别,从而提醒视力残疾人避开障碍物;超声导盲仗是在普通导盲仗的基础上加上超声波传感器,但是超声波传感器探测距离有限,而且也无法做到全方位障碍物检测,检测方向只能在超声传感器的正前方,也无法做到物体识别,为视力残疾人的导盲能力也是有限的;加装摄像头的导盲设备虽然可以做简单的物体识别,识别红绿灯等,但是只通过摄像头无法检测物体远近,不能做基于距离的避障,也不能做导航。
中国专利201610057616.1公开了一种基于计算机双目视觉与惯性测量的视力残疾人行走定位方法,一方面利用佩戴在视力残疾人头部的双目相机2采集场景图像,通过图像特征匹配方法查找场景中已知经纬度的标志物,采用计算机双目立体视觉方法计算标志物在相机坐标系下的三维坐标,另一方面利用固定在相机上的组合惯性器件测量相机的姿态角,计算出相机坐标系关于视力残疾人所在位置的地理坐标系的转换矩阵;利用转换矩阵将标志物的相机系坐标变换为视力残疾人所在位置的地理系坐标,进而由标志物经纬度推算出视力残疾人所在位置的经纬度。综合计算机双目视觉算法与惯性测量技术,实现视力残疾人行走位置的定位,不仅简单易行,而且准确性较高,特别适用于视力残疾人出行导盲的定位。
上述的专利中并没有同时具备对行走轨迹的正确度判断以及在行走轨迹上遇到的障碍物的判断,对于导盲而言,不够全面。因此,有必要设计一种立体惯性导盲方法,实现既能做到全方位、远距离的障碍物检测,还提高三维空间定位的更新频率,获得更小的定位误差,以便于提示视力残疾人正确的避开障碍物。
技术实现要素:
本发明的目的在于克服现有技术的缺陷,提供立体惯性导盲方法及装置和系统。
为实现上述目的,本发明采用以下技术方案:立体惯性导盲方法,所述方法包括:
轨迹获取步骤,采用视觉惯性定位方式,确定首次行走的轨迹,同时记录两个相机所拍摄到的所有图像中的特征点;
轨迹判断步骤,判断实际行走的轨迹是否与所述首次行走的轨迹一致;若一致,则进行点云获取步骤,若不一致,则发送提醒信息,并进入点云获取步骤;
点云获取步骤,获取实际行走的轨迹中的点云信息;
点云判断步骤,判断所述点云信息中是否有超过设定数量的点集合在某一规定的区域内;若有,则发送提醒信息,若无,则返回所述点云获取步骤。
其进一步技术方案为:所述点云获取步骤包括以下具体步骤:
获取两个相机的相对位置和角度;
获取两个所述相机同一时刻曝光的图像,作为第一图像以及第二图像;
利用所述第一图像以及所述第二图像、两个所述相机的相对位置和角度,获取点云信息。
其进一步技术方案为:利用所述第一图像以及所述第二图像、两个所述相机的相对位置和角度,获取点云信息的步骤,包括以下具体步骤:
提取第一图像中的所有像素,并提取每个像素周围的图像特征,在第二图像中寻找与第一图像中提取的像素对应的特征最相似的像素;
获取所述第二图像的像素相对于所述第一图像对应的像素的位置,作为点的图像位置;
利用三角定位的方式,确定所述点的真实三维位置;
集合所述第一图像以及所述第二图像所有像素点所对应的点,获取点云;
将所述点云中所有点对应的真实三维位置与所述点云对应,获取点云信息。
其进一步技术方案为:所述轨迹获取步骤中,采用视觉惯性定位的方式包括以下具体步骤:
获取两个所述相机在某一时刻曝光的两张图像;
提取其中一张所述图像的角点以及所述角点的周围的图像特征,作为特征点;
计算所述特征点在另一张图像中的极线,并在所述极线上寻找与所述特征点最接近的点,作为辅助特征点;
结合特征点以及辅助特征点,通过三角法计算所述特征点所对应的真实位置,以特征点、辅助特征点以及所述真实位置作为标记点;
给定某一角点的周围的图像特征,将其和所有已有标记点所对应的图像特征对比;如果匹配,则把所述角点列入所述标记点的特征中;
获取所有标记点串联而成的路线,将惯性传感器中的陀螺仪信息加入角度测算,将惯性传感器中的加速度信息加入行走速度测算,获取行走的轨迹。
其进一步技术方案为:所述轨迹获取步骤之前,还包括:
判断是否属于第一次使用;
若是,则进行所述轨迹获取步骤;
若不是,则进行图像匹配,确定初始位置;
结合所述初始位置以及相对于所述导航路径所处的位置,进行导航,并进入所述轨迹判断步骤。
本发明还提供了立体惯性导盲装置,包括装置本体、两个相机、惯性传感器、服务器以及播放结构;两个所述相机、所述惯性传感器以及所述播放结构连接在所述装置本体上。
其进一步技术方案为:所述装置本体为导盲眼镜、导盲仗以及导盲机器人中至少一种。
本发明还提供了立体惯性导盲系统,包括轨迹获取单元、轨迹判断单元、点云获取单元以及点云判断单元;
所述轨迹获取单元,用于采用视觉惯性定位方式,确定首次行走的轨迹,同时记录两个相机所拍摄到的所有图像中的特征点;
所述轨迹判断单元,用于判断实际行走的轨迹是否与所述首次行走的轨迹一致;若一致,则进行点云获取,若不一致,则发送提醒信息,并进入点云获取;
所述点云获取单元,用于获取实际行走的轨迹中的点云信息;
所述点云判断单元,用于判断所述点云信息中是否有超过设定数量的点集合在某一规定的区域内;若有,则发送提醒信息,若无,则进行点云获取。
其进一步技术方案为:所述点云获取单元包括基础信息获取模块、图像获取模块以及点云信息获取模块;
所述基础信息获取模块,用于获取两个相机的相对位置和角度;
所述图像获取模块,用于获取两个所述相机同一时刻曝光的图像,作为第一图像以及第二图像;
所述点云信息获取模块,用于利用所述第一图像以及所述第二图像、两个所述相机的相对位置和角度,获取点云信息。
其进一步技术方案为:所述点云信息获取模块包括像素提取子模块、图像位置获取子模块、真实位置确定子模块、点云获取子模块以及对应子模块;
所述像素提取子模块,用于提取第一图像中的所有像素,并提取每个像素周围的图像特征,在第二图像中寻找与第一图像中提取的像素对应的特征最相似的像素;
所述图像位置获取子模块,用于获取所述第二图像的像素相对于所述第一图像对应的像素的位置,作为点的图像位置;
所述真实位置确定子模块,用于利用三角定位的方式,确定所述点的真实三维位置;
所述点云获取子模块,用于集合所述第一图像以及所述第二图像所有像素点所对应的点,获取点云;
所述对应子模块,用于将所述点云中所有点对应的真实三维位置与所述点云对应,获取点云信息。
本发明与现有技术相比的有益效果是:本发明的立体惯性导盲方法,通过两个相机拍摄的图像以及惯性传感器的数据,测算出当前视力残疾人所在的位置,以及测算周围物体相对于视力残疾人的三维坐标,若有障碍物,则识别物体,并将盲人本身的三维坐标以及物体相对于视力残疾人而言的位置,通过语音播报等形式实时反馈给视力残疾人,将实际行走轨迹正确的判断与行走轨迹上的障碍物判断结合在一起,利用相机拍摄以及惯性传感器的配合,既能做到全方位、远距离的障碍物检测,还提高三维空间定位的更新频率,获得更小的定位误差,以便于提示视力残疾人正确的避开障碍物。
下面结合附图和具体实施例对本发明作进一步描述。
附图说明
图1为本发明具体实施例提供的立体惯性导盲方法的流程图;
图2为本发明具体实施例提供的点云获取的具体流程图;
图3为本发明具体实施例提供的获取点云信息的具体流程图;
图4为本发明具体实施例提供的视觉惯性定位的具体流程图;
图5为本发明具体实施例一提供的立体惯性导盲装置的立体结构示意图;
图6为本发明具体实施例二提供的立体惯性导盲装置的立体结构示意图;
图7为本发明具体实施例三提供的立体惯性导盲装置的立体结构示意图;
图8为本发明具体实施例提供的立体惯性导盲系统的结构示意图;
图9为本发明具体实施例提供的点云获取单元的结构示意图;
图10为本发明具体实施例提供的点云信息获取模块的结构示意图;
图11为本发明具体实施例提供的轨迹获取单元的结构示意图。
具体实施方式
为了更充分理解本发明的技术内容,下面结合具体实施例对本发明的技术方案进一步介绍和说明,但不局限于此。
如图1~11所示的具体实施例,本实施例提供的立体惯性导盲方法,可以运用在导盲的过程中,帮助视力残疾人进行行走引导、躲避障碍物以及物体识别,实现既能做到全方位、远距离的障碍物检测,还提高三维空间定位的更新频率,获得更小的定位误差,并且可以对障碍物进行识别,以便于提示视力残疾人正确的避开障碍物;当然,也可以运用在其他导航的过程中。
如图1所示,立体惯性导盲方法包括:
s1、判断是否属于第一次使用;
s2、若是,则进入轨迹获取步骤,采用视觉惯性定位方式,确定首次行走的轨迹,同时记录两个相机所拍摄到的所有图像中的特征点,并进入s5步骤;
s3、若不是,则进行图像匹配,确定初始位置;
s4、结合所述初始位置以及相对于所述导航路径所处的位置,进行导航,并进入s5步骤。
s5、轨迹判断步骤,判断实际行走的轨迹是否与所述首次行走的轨迹一致;若一致,则进行s6、点云获取步骤,若不一致,则s8、发送提醒信息,并进入s6、点云获取步骤;
s6、点云获取步骤,获取实际行走的轨迹中的点云信息;
s7、点云判断步骤,判断所述点云信息中是否有超过设定数量的点集合在某一规定的区域内;若有,则s8、发送提醒信息,若无,则返回所述s6、点云获取步骤。
上述的s1步骤,判断是否属于第一次使用,指的是是否是第一次使用该立体惯性导盲装置,若是,则需要帮助视力残疾人佩戴立体惯性导盲装置沿某路径行走,以作为路径的记录,若不是第一次使用,则图像匹配,寻找与之行走的路线对应的记录的路径,直接调取,效率高。
如图4所示,在上述的s2步骤中,轨迹获取步骤中,采用视觉惯性定位方式包括以下具体步骤:
s21、获取两个所述相机2在某一时刻曝光的两张图像;
s22、提取其中一张所述图像的角点以及所述角点的周围的图像特征,作为特征点;
s23、计算所述特征点在另一张图像中的极线,并在所述极线上寻找与所述特征点最接近的点,作为辅助特征点;
s24、结合特征点以及辅助特征点,通过三角法计算所述特征点所对应的真实位置,以特征点、辅助特征点以及所述真实位置作为标记点;
s25、给定某一角点的周围的图像特征,将其和所有已有标记点所对应的图像特征对比,如果匹配,则把所述角点列入所述标记点的特征中;
s26、获取所有标记点串联而成的路线,将惯性传感器中的陀螺仪信息加入角度测算,将惯性传感器中的加速度信息加入行走速度测算,获取行走的轨迹。
例如:两个相机2在t时刻曝光,获取两张图像i(t,1)和图像ii(t,2),在图像i(t,1)中提取一定的角点(例如70个)。对于每个角点,提取其周围图像特征,对于第i个在i(t,1)中的的特征点p(t,1,i),计算其在图像ii中的极线,在极线上寻找与特征点p1(t,1,i)的图像特征最接近的点,记为p2(t,2,i),给定p1(t,1,i)和p2(t,2,i)通过三角法计算对应三维点的位置p(i,t),一组p1(t,1,i)、p2(t,2,i)、p(i,t)记为一个“标记点”l(i,t);给定特征点p1(t,1,i)的特征,将其和所有已有标记点l(i,t)(t<t)的图像特征对比,如果匹配,则把p1(t,1,i)加入l(i,t)的特征中;获取所有标记点l(i,t)串联而成的路线,作为行走的轨迹。
对于上述的s24中的标志点,对任何一个标记点,都有一个三维点p(i,t)和一组在不同图像中对应的特征位置。
给定拍摄图像时的两个相机2以及惯性传感器1imu的位置和角度(x,y,z,quaternion),都可以计算三维点p(i,t)在所拍摄的图像中的几何投影位置,几何投影位置和图像特征位置的不同是参数误差,所有参数误差的l2求和记做e(i,t)。
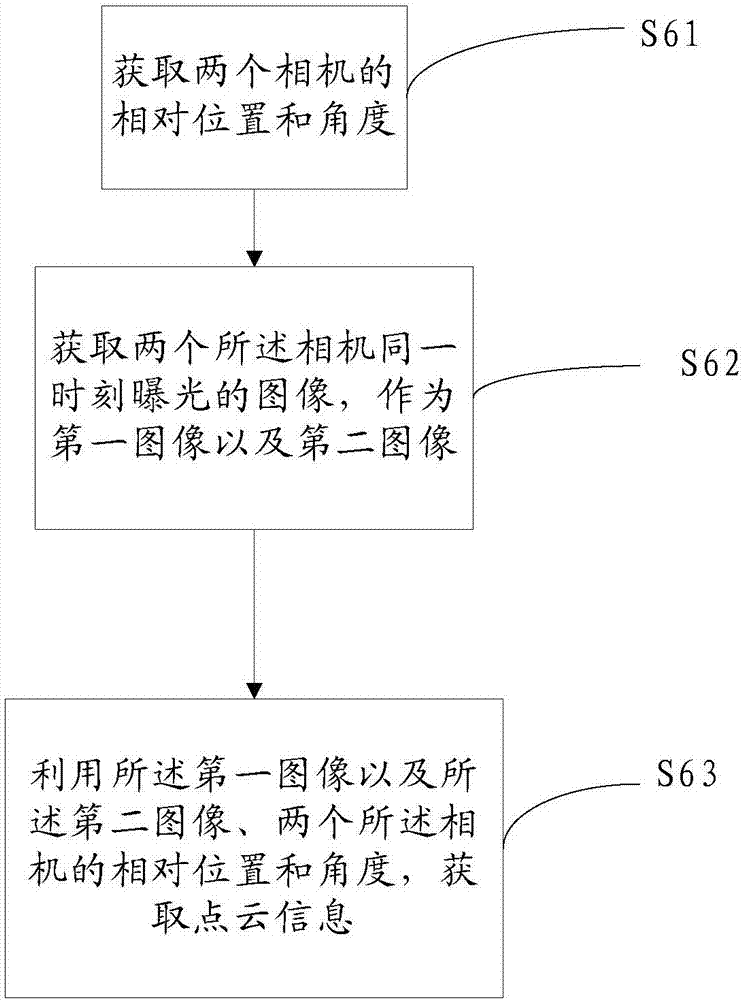
如图2所示,对于s6步骤,点云获取步骤包括以下具体步骤:
s61、获取两个相机的相对位置和角度;
s62、获取两个所述相机同一时刻曝光的图像,作为第一图像以及第二图像;
s63、利用所述第一图像以及所述第二图像、两个所述相机的相对位置和角度,获取点云信息。
对于s61步骤,在获取两个相机2的位置和角度时,给定所有标记点l(i,t)和imu数据,求一组惯性传感器1的位置(x,y,z)和角度(quaternion)使得所有标记点l(i,t)的投影误差e(i,t)之和、imu数据和位置、角度的参数的不同程度最小,只要给定惯性传感器1在初始时刻的位置,就可以求出两个相机2在任何时刻的位置和角度。
如图3所示,s63的步骤,利用所述第一图像以及所述第二图像、两个所述相机2的相对位置和角度,获取点云信息的步骤,包括以下具体步骤:
s631、提取第一图像中的所有像素,并提取每个像素周围的图像特征,在第二图像中寻找与第一图像中提取的像素对应的特征最相似的像素;
s632、获取所述第二图像的像素相对于所述第一图像对应的像素的位置,作为点的图像位置;
s633、利用三角定位的方式,确定所述点的真实三维位置;
s634、集合所述第一图像以及所述第二图像所有像素点所对应的点,获取点云;
s635、将所述点云中所有点对应的真实三维位置与所述点云对应,获取点云信息。
比如,两个相机2在同一时刻曝光,获取两张图像:图像1和图像2;对于图像1的每一个像素(x,y),提取其周围图像的特征,在图像2中寻找与像素(x,y)特征最相似的像素(u,v),(x,y)-(u,v)对应真实空间的一个点,利用三角定位方式,确定(x,y)-(u,v)对应的真实的点的三维坐标p,将所有的像素对应的点收集在一起,获得点云,此过程中像素的坐标,是利用惯性传感器1获得重力方向,在点云中去除垂直于重力方向的平面(地面)。
上述的s7步骤,判断时,主要是将两个相机2所拍摄的前方区域切分成扇形区域,统计每个扇形区域的点的数量,若某一规定的区域(也就是某一扇形区域)超过设定数量,则认为即将遇到障碍物。
对于s7中,若所述点云信息中是否有超过设定数量的点集合在某一规定的区域内,则发送提醒信息之前还会进行s9、识别区域内的物体;识别区域内的物体时,主要是将两个相机2拍摄到的图像输入到物体识别cnn网络系统中,由物体识别cnn网络系统识别后,输出物体对应的大致模型和名字以及其在图像中出现的位置。
上述的发送提醒信息,在本实施例中,采用的是语音播报方式,以一定的频率(例如3秒钟1次)向视力残疾人播报两个相机2所拍摄的每个扇形区域点的数量,播报的方式可以利用环绕立体声,利用省掉高低表示每个方向的点的数量,让视力残疾人听到潜在障碍物和整体环境的几何信息。接收到的物体识别结果,通过语音播报当前的图像中实现规定的物体的出现情况以及在当前的图像中的位置。上述的立体惯性导盲方法,通过两个相机2拍摄的图像以及惯性传感器1的数据,测算出当前视力残疾人所在的位置,以及测算周围物体相对于视力残疾人的三维坐标,若有障碍物,则识别物体,并将盲人本身的三维坐标以及物体相对于视力残疾人而言的位置,通过语音播报等形式实时反馈给视力残疾人,将实际行走轨迹正确的判断与行走轨迹上的障碍物判断结合在一起,利用相机2拍摄以及惯性传感器1的配合,既能做到全方位、远距离的障碍物检测,还提高三维空间定位的更新频率,获得更小的定位误差,并且可以对障碍物进行识别,以便于提示视力残疾人正确的避开障碍物。
如图5所示为本实施例提供的立体惯性导盲装置,包括装置本体、两个相机2、惯性传感器1、服务器以及播放结构;两个所述相机2、所述惯性传感器1以及所述播放结构连接在所述装置本体上。
在本实施例中,上述的装置本体为导盲眼镜,于其他实施例,上述的装置本体为导盲仗或者导盲机器人,即上述的装置本体为导盲眼镜、导盲仗以及导盲机器人中至少一种。
当装置本体为导盲眼镜时,两个相机2装在眼镜的镜框5上,该眼镜的镜脚7上设有耳机3,播放结构为嵌入在耳机3内的喇叭,惯性传感器1也安装在镜框5上。
另外,立体惯性导盲装置还包括电池,电池与惯性传感器1、播放结构以及相机2分别连接。
如图6所示,当装置本体为导盲仗时,两个相机2以及惯性传感器1安装在仗杆上,服务器以及电池安装在仗柄4上,另外,仗柄4上设有耳机3,播放结构为嵌入在耳机3内的喇叭。
如图7所示,当装置本体为导盲机器人时,两个相机2以及惯性传感器1安装在机器人本体6的前端,服务器以及电池安装在机器人本体6内,播放结构为嵌入在耳机3内的喇叭,该耳机3与服务器为无线连接。
上述的立体惯性导盲装置,检测水平角度120度内、最远到10米的障碍物,可以识别签发物体类别,例如红绿灯颜色,纸币面额,人脸的姓名等,三维空间定位可以将定位的更新频率大幅提高(例如从30hz提高到300hz),由于惯性传感器1的imu数据可以一同被用作位置测算,定位误差减小可以达到50%或者更多,可以获得更小的定位误差,并且可以进行静止状态的三维障碍物检测。
如图8所示为本实施例提供的立体惯性导盲系统,包括轨迹获取单元8、轨迹判断单元9、点云获取单元10以及点云判断单元11;
轨迹获取单元8,用于采用视觉惯性定位方式,确定首次行走的轨迹,同时记录两个相机所拍摄到的所有图像中的特征点;
轨迹判断单元9,用于判断实际行走的轨迹是否与所述首次行走的轨迹一致;若一致,则进行点云获取,若不一致,则发送提醒信息,并进入点云获取;
点云获取单元10,用于获取实际行走的轨迹中的点云信息;
点云判断单元11,用于判断所述点云信息中是否有超过设定数量的点集合在某一规定的区域内;若有,则发送提醒信息,若无,则进行点云获取。
如图9所示,上述的点云获取单元10包括基础信息获取模块30、图像获取模块31以及点云信息获取模块32;
基础信息获取模块30,用于获取两个相机2的相对位置和角度;
图像获取模块31,用于获取两个所述相机2同一时刻曝光的图像,作为第一图像以及第二图像;
点云信息获取模块32,用于利用所述第一图像以及所述第二图像、两个所述相机2的相对位置和角度,获取点云信息。
基础信息获取模块30在获取两个相机2的位置和角度时,给定所有标记点l(i,t)和imu数据,求一组惯性传感器1的位置(x,y,z)和角度(quaternion)使得所有标记点l(i,t)的投影误差e(i,t)之和、imu数据和位置、角度的参数的不同程度最小,只要给定惯性传感器1在初始时刻的位置,就可以求出两个相机2在任何时刻的位置和角度。
如图10所示,上述的点云信息获取模块32包括像素提取子模块321、图像位置获取子模块322、真实位置确定子模块323、点云获取子模块324以及对应子模块325;
像素提取子模块321,用于提取第一图像中的所有像素,并提取每个像素周围的图像特征,在第二图像中寻找与第一图像中提取的像素对应的特征最相似的像素;
图像位置获取子模块322,用于获取所述第二图像的像素相对于所述第一图像对应的像素的位置,作为点的图像位置;
真实位置确定子模块323,用于利用三角定位的方式,确定所述点的真实三维位置;
点云获取子模块324,用于集合所述第一图像以及所述第二图像所有像素点所对应的点,获取点云;
对应子模块325,用于将所述点云中所有点对应的真实三维位置与所述点云对应,获取点云信息。
对于上述的点云信息获取模块32,两个相机2在同一时刻曝光,获取两张图像:图像1和图像2;对于图像1的每一个像素(x,y),提取其周围图像的特征,在图像2中寻找与像素(x,y)特征最相似的像素(u,v),(x,y)-(u,v)对应真实空间的一个点,利用三角定位方式,确定(x,y)-(u,v)对应的真实的点的三维坐标p,将所有的像素对应的点收集在一起,获得点云,此过程中像素的坐标,是利用惯性传感器1获得重力方向,在点云中去除垂直于重力方向的平面(地面)。
上述的立体惯性导盲系统还包括首次使用判断单元12、以及匹配单元20;
首次使用判断单元12,用于判断是否属于第一次使用,若是,则进行轨迹获取;
若不是,则进行图像匹配,确定初始位置;
匹配单元20,用于结合所述初始位置以及相对于所述导航路径所处的位置,进行导航,并进入轨迹判断。
首次使用判断单元12判断是否属于第一次使用,指的是是否是第一次使用该立体惯性导盲装置,若是,则需要帮助视力残疾人佩戴立体惯性导盲装置沿某路径行走,以作为路径的记录,若不是第一次使用,则图像匹配,寻找与之行走的路线对应的记录的路径,直接调取,效率高。
如图11所示,上述的轨迹获取单元8还包括曝光图像获取模块81、特征点提取模块82、辅助特征点提取模块83、标志点获取模块84、角点列入模块85以及获取轨迹模块86;
曝光图像获取模块81,用于获取两个所述相机2在某一时刻曝光的两张图像;
特征点提取模块82,用于提取其中一张所述图像的角点以及所述角点的周围的图像特征,作为特征点;
辅助特征点提取模块83,用于计算所述特征点在另一张图像中的极线,并在所述极线上寻找与所述特征点最接近的点,作为辅助特征点;
标志点获取模块84,用于结合特征点以及辅助特征点,通过三角法计算所述特征点所对应的真实位置,以特征点、辅助特征点以及所述真实位置作为标记点;
角点列入模块85,用于给定某一角点的周围的图像特征,将其和所有已有标记点所对应的图像特征对比,如果匹配,则把所述角点列入所述标记点的特征中;
获取轨迹模块86,用于获取所有标记点串联而成的路线,将惯性传感器中的陀螺仪信息加入角度测算,将惯性传感器中的加速度信息加入行走速度测算,获取行走的轨迹。
上述轨迹确认单元在使用过程中,若两个相机2在t时刻曝光,获取两张图像i(t,1)和图像ii(t,2),在图像i(t,1)中提取一定的角点(例如70个)。对于每个角点,提取其周围图像特征,对于第i个在i(t,1)中的的特征点p(t,1,i),计算其在图像ii中的极线,在极线上寻找与特征点p1(t,1,i)的图像特征最接近的点,记为p2(t,2,i),给定p1(t,1,i)和p2(t,2,i)通过三角法计算对应三维点的位置p(i,t),一组p1(t,1,i)、p2(t,2,i)、p(i,t)记为一个“标记点”l(i,t);给定特征点p1(t,1,i)的特征,将其和所有已有标记点l(i,t)(t<t)的图像特征对比,如果匹配,则把p1(t,1,i)加入l(i,t)的特征中;获取所有标记点l(i,t)串联而成的路线,作为行走的轨迹。
对于标志点获取模块84获取的标志点,对任何一个标记点,都有一个三维点p(i,t)和一组在不同图像中对应的特征位置。
给定拍摄图像时的两个相机2以及惯性传感器1imu的位置和角度(x,y,z,quaternion),都可以计算三维点p(i,t)在所拍摄的图像中的几何投影位置,几何投影位置和图像特征位置的不同是参数误差,所有参数误差的l2求和记做e(i,t)。基础信息获取单元40在获取两个相机2的位置和角度时,给定所有标记点l(i,t)和imu数据,求一组惯性传感器1的位置(x,y,z)和角度(quaternion)使得所有标记点l(i,t)的投影误差e(i,t)之和、imu数据和位置、角度的参数的不同程度最小,只要给定惯性传感器1在初始时刻的位置,就可以求出两个相机2在任何时刻的位置和角度。
上述的点云判断单元11在判断时,主要是将两个相机2所拍摄的前方区域切分成扇形区域,统计每个扇形区域的点的数量,若某一规定的区域(也就是某一扇形区域)超过设定数量,则认为即将遇到障碍物。
另外,在识别区域内的物体时,主要是将两个相机2拍摄到的图像输入到物体识别cnn网络系统中,由物体识别cnn网络系统识别后,输出物体对应的大致模型和名字以及其在图像中出现的位置。
播放单元播报所述物体的位置时,在本实施例中,采用的是语音播报方式,以一定的频率(例如3秒钟1次)向视力残疾人播报两个相机2所拍摄的每个扇形区域点的数量,播报的方式可以利用环绕立体声,利用省掉高低表示每个方向的点的数量,让视力残疾人听到潜在障碍物和整体环境的几何信息。接收到的物体识别结果,通过语音播报当前的图像中实现规定的物体的出现情况以及在当前的图像中的位置。
上述的立体惯性导盲系统,通过两个相机2拍摄的图像以及惯性传感器1的数据,测算出当前视力残疾人所在的位置,以及测算周围物体相对于视力残疾人的三维坐标,若有障碍物,则识别物体,并将盲人本身的三维坐标以及物体相对于视力残疾人而言的位置,通过语音播报等形式实时反馈给视力残疾人,将实际行走轨迹正确的判断与行走轨迹上的障碍物判断结合在一起,利用相机2拍摄以及惯性传感器1的配合,既能做到全方位、远距离的障碍物检测,还提高三维空间定位的更新频率,获得更小的定位误差,并且可以对障碍物进行识别,以便于提示视力残疾人正确的避开障碍物。
上述仅以实施例来进一步说明本发明的技术内容,以便于读者更容易理解,但不代表本发明的实施方式仅限于此,任何依本发明所做的技术延伸或再创造,均受本发明的保护。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!