一种车联网环境下出行信息服务策略与仿真验证系统的制作方法
本项发明涉及出行信息服务策略与仿真技术领域,特别涉及在车联网环境下对于不同个性化驾驶员的出行路径信息选择服务策略及其仿真建模。
背景技术:
车联网环境是在信息时代下,传统交通行业与新兴的信息行业相融合的一种新型的交通发展趋势。车联网环境区别于传统的交通环境之处在于它便利的信息交流。信息流的方向从车辆驾驶员端经由路网信息管理端传向车联网的云处理端,最后产生的结果再交还给车辆驾驶员端,令其作出反应。在路网上运行的许许多多的车辆驾驶员端综合形成整个路网的交通状况,并影响车联网的云处理端对于车辆驾驶员端信息的处理。然而传统的驾驶员角色存在自己对于出行信息的判断,即驾驶员个性,在面对车联网云处理端给出的最优决策存在接受与否的博弈过程。这种车联网环境下的出行信息服务缺少一种关于个性化的考虑。
在研究车联网环境下的个性化出行信息服务策略的时候,常采用仿真平台进行模拟分析。考虑设计一种车联网环境的交通系统仿真系统,进行仿真模拟分析。
多智能体仿真模型是一种更加贴近现实的仿真。在车联网仿真的过程中,总共有三种处理端产生作用。它们是车联网的云、端、管三种系统。三种系统可以收集指令并进行计算、处理和执行,因此可以视为三种智能体,它们之间的相互作用则可以利用多智能体仿真模型进行仿真分析。
技术实现要素:
本发明是提供一种车联网环境下个性化出行者出行信息服务策略与多智能体仿真验证系统,利用出行路径选择作为考虑个性化服务的因素,在设定一种基于车辆驾驶员端与路网信息管理端的博弈协商机制后,利用多智能体仿真平台进行仿真验证,分析并判断路网运行状况,为研究车联网环境下的系统管理者提供的系统最优路径选择与车辆驾驶员依据个性选择的驾驶路径的博弈提供一种行之有效的方法。
本发明的技术方案是:制定一种车联网环境下个性化出行信息服务策略,并借助开源多智能体仿真工具netlogo构建仿真模型,进行仿真验证。
车联网环境下个性化出行信息服务策略的制定涵盖以下内容:
(1)路网管理者与车辆驾驶员的出行决策集。为构建博弈协商机制的交流基础,需要路网管理者与车辆驾驶员分别具有自己的决策集。不同角色所制定的决策集面对相同的路网状况会采用不同的权重。同时设定不同的权重拥有自己的阈值,最终可以计算获得出行决策集合。
(2)路网管理者与车辆驾驶员进行出行决策的交流。基于博弈协商机制的特点,需要充分交流路网管理者与车辆驾驶员的决策,即考虑二者的决策集合是否存在交集。此时决策集的容量会产生影响,需要依据实际条件设定合理的容量。
(3)博弈协商过程的成功判断。路网管理者与车辆驾驶员的决策集通过交流过程,产生两种结果。存在交集与不存在交集。如果存在交集,那么车辆驾驶员选择执行该路径,并视为本次博弈协商过程成功;反之,则需要进行额外的博弈协商过程,视为本次协商失败。
同时,为验证博弈协商机制的作用效果,获取相关数据进行研究分析,本发明利用多智能体模型构建基于车联网环境下的个性化出行信息服务策略仿真验证平台。仿真平台需要设定以下内容:
(1)仿真模型场景设定
给仿真系统世界设定一个坐标原点,在此坐标原点的基础上给世界一个界限,如设置世界范围为x方向坐标范围为[-16,16],y方向的范围也是[-16,16],因此仿真系统的为32×32的由1024个离散的patches组成的世界,然后按照需要将一部分patches集合的颜色设置为特定的颜色(如灰色)作为仿真路段,除此之外的patches设置为另外的易于区分的其他颜色(如绿色)作为路侧建筑、绿化等,车辆智能体可以通过判断patches的颜色识别道路,并给路段patches赋予一定标识和一定的自由流速度也就是最大速度以划分路段等级,同时对交叉口的patches进行编号,以交叉口节点patches的编号组成的有序数组用来表示仿真系统中的路径及od。同时,将设定的多条路径中合理的一条作为出行信息服务策略提供的结果。利用仿真模型所获得的路网信息以评价所设定的博弈协商机制。
(2)车辆生成及划分
将仿真场景中设定的某一坐标位置作为起点位置,设定来车率come-rate%作为车辆智能体(turtles)生成条件。同时,利用个性化connected?判断驾驶员是否需要提供个性化出行信息服务,以及不同两种驾驶员之间的比例。程序语言表述为:
if在[0,100]间生成的随机整数小于等于come-rate%;
thenif[0,100]间的随机数小于等于[设定的个性化驾驶员比例],令connected?取值1,生成车辆;
else令connected?取值0,生成车辆。
(3)仿真内容
主要是车辆行驶规则的制定。包括微观战术层规则和宏观战略层规则。
1)战术层规则
辆智能体在仿真系统中路网上的微观行驶规则,主要在于路段和交叉口的行动规则,首先是路段上的跟驰行为,车辆n生成后,根据其初始化设定的初速度行驶,在行驶过程中根据前车n+1行驶状况作出行驶决策,其算法为:
if车辆n和前车n+1距离d小于设定安全距离δx,存在跟驰行为,n按照下式进行加减速控制:
else不存在跟车行为,车辆n以路段自由流速度行驶或加速到该速度行驶。
其次是在交叉口的转弯行为,车辆智能体在生成后根据战略层规则选择出内容1)中所述的有序数组代表的路径,在到达交叉口时根据存储的路网拓扑结构作出转向决策,其算法为:
if车辆到达节点i
if车辆路径下一节点编号为a
向左(右或直行)转弯,赋值heading=heading+90°
if车辆路径下一节点编号为b
向右(直行)转弯,赋值heading=heading-90°
if车辆路径下一节点编号为c
保持直行,赋值heading=heading
else
if车辆到达节点j
……
依次遍历每个节点
2)战略层规则
战略层主要是指战略层负责车辆智能体的路径选择,包括路径计算和路径分配。路径计算规则需要根据研究需要给定,在本专利中,路径的计算需要通过路径效用函数:
其中
在公式中,f——当前效用评价因素的检测值;
f0——当前效用评价因素的最大满意值;
f1——当前效用评价因素的最小满意值;
r——第r条路径;
ur——第r条路径的路径效用值;
ωg——第g个出行行为权重目标,由具备个性化驾驶员车辆与不具备个性化驾驶员车辆的差异产生区别,二者都具有一定阈值;
dg——第g个效用评价因素的满意度函数。路径分配则是需要划分不同的车辆驾驶员考虑。在考虑connected?为0,即不需要提供给车辆驾驶员个性化出行信息服务时,只需要令其采用系统最优决策,即全局最高效用值路径;而connected?为1时,需要进行博弈协商过程,以期达成个性化出行信息服务。其算法如下:
根据即时获取的路网信息状态,利用路径效用值函数计算设定路径的效用值,此时的权重分别为不具备个性化的驾驶员权重与具备个性化的驾驶员权重(步骤一);
利用冒泡算法,分别将效用值最高的一条路径作为系统提供的最优出行信息服务与个性化驾驶员选择路径(步骤二);
根据生成车辆connected?的取值分配路径:
ifconnected?=0,选用系统最优路径,
else选用个性化驾驶员最优路径(步骤三);
进行博弈协商过程:
考虑提供给个性化驾驶员与无个性驾驶员的路径效用值最高的两条路径分别作为其最优路径集合,
if提供给个性化驾驶员的最优路径集合与系统最优路径集合存在交集,则执行该相同路径,视作第一次博弈协商过程成功,
else令路网系统管理者智能体使用自身权重阈值重新生成权重,再次计算提供给无个性驾驶员的最优路径集合,if此集合与最初个性化驾驶员接收路径集合间存在交集,则执行该相同路径,视作第二次博弈协商过程成功,
else令个性化驾驶员智能体使用自身权重阈值重新生成权重,再次计算提供给个性化驾驶员的最优路径集合,if此集合与第二次博弈协商过程计算得出的系统最优路径集合间存在交集,则执行该相同路径,视作第三次博弈协商过程成功,
else强制选择第一次博弈协商过程中系统最优路径作为选择路径,视作博弈协商过程失败(步骤四)。
(4)仿真数据信息获取
在仿真模型运行的过程中,需要采集的信息包括行程时间、路段车辆数、接受不同博弈协商过程的车辆数。
1)行程时间
仿真系统中设定有时钟ticks,车辆在进入路段a之前到达节点i,此时将时钟的值赋值给车辆智能体变量ti,同样在车辆驶出路段a后到达路段a末端节点j时,再将时钟值赋值给车辆智能体变量tj,然后计算出车辆在路段a上的行程时间ta=tj-ti,对路段a的平均行程时间的采集采用长度为5的数组tra进行存储车辆在路段a上的行程时间并求其均值作为路段a的平均行程时间,其算法为:
if车辆n使用路段a;
if数组tra长度<5;
将车辆n在路段上的行程时间加入数组tra作为第一个元素,并计算数组的均值作为路段a的平均行程时间;
else去除数组tra的最后一个元素。
2)路段车辆数
利用仿真软件中count语句,对特定路段上的海龟集(车辆模型)进行计数。
3)接受不同博弈协商过程的车辆数
在完成每次博弈协商过程时,对车辆choice属性进行定义,最后使用图表进行统计。
本发明具有以下有益效果:
(1)本发明是基于多智能体模型搭建的车联网环境下个性化出行信息服务策略仿真平台,具有多智能体模型的显著优势。模型从刻画个体行为模型出发,以体现由此产生的宏观效果,且同时考虑了个体的微观层面和宏观层面的行为。宏观层面行为的集计效果决定了交通流在路网中的分布,微观层面的行为不仅更真实的刻画了车辆在道路上的实际行驶状况,而且反映了路段运行的运行状况。实现了从底层原理的研究以探究宏观的现象,具有更好的说服力和有效性。
(2)本发明是提供一种车联网环境下个性化出行服务策略,利用出行路径选择作为考虑个性化服务的因素,提供一种基于车辆驾驶员端与路网信息管理端的博弈协商机制,分析并判断路网运行状况,为研究车联网环境下的系统管理者提供的系统最优路径选择与车辆驾驶员依据个性选择的驾驶路径的博弈提供一种行之有效的方法。
附图说明
图1车联网环境的三种组成系统以及其间的关系
图2博弈协商机制的运作过程
图3车联网环境下个性化出行信息服务策略仿真系统运行流程
图4仿真系统使用路网
图5依照od划分的路径
图6仿真系统人机交互界面
图7—110.2、0.4、0.6、0.8、1.0路网饱和度下不同个性化驾驶员占比的各路径平均行程时间
图12—1620%、40%、60%、80%、100%个性化驾驶员占比情况下接受的博弈协商过程与路网饱和度的关系
具体实施方案
下面结合附图和实施方案对本发明进行详细描述,应理解该实例仅用于说明本发明而不用于限制本发明的范围。
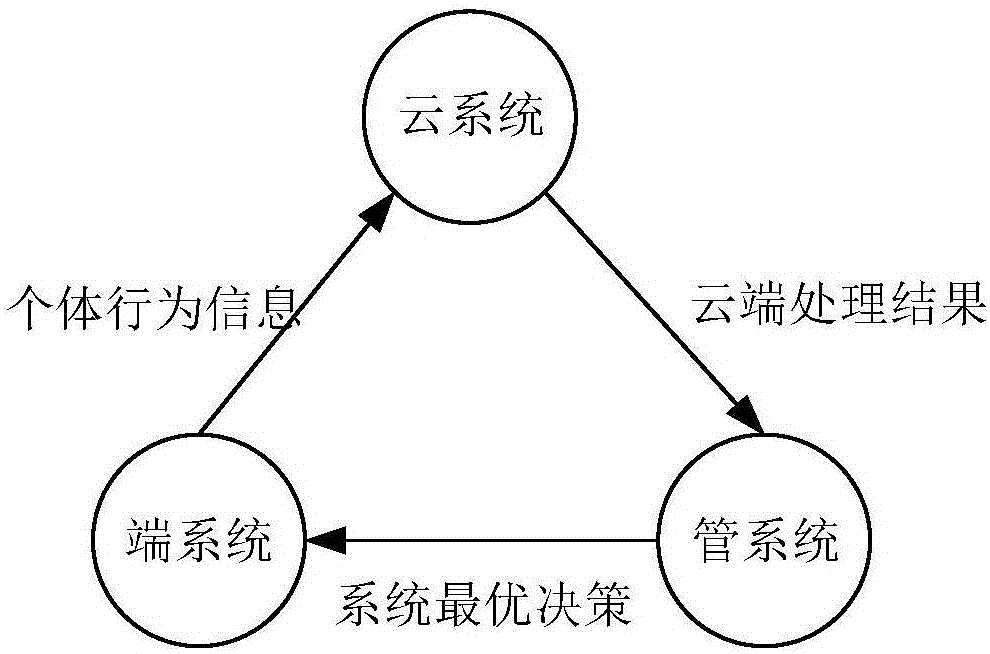
如图1所示,本发明基于车联网环境。首先将车联网的成分划分为三个系统,分别是车联网的云系统、端系统和管系统。云系统是车联网的云端平台,汇集整个车联网系统的路网信息,将经由车联网驾驶端的各种信息获取到云端,并进行计算处理,做出最优出行服务选择交给管系统;管系统是车联网的路网管理系统,由道路上各种设备构成,管系统能够获取车联网云系统所提供的最优服务策略并通过路面设备传递给端系统;端系统是车联网的终端系统,是由参与车联网的交通工具组成,端系统接受到管系统提出的出行服务策略,选择执行或否决,最后产生交通行为,形成交通状况,反馈给云系统。
如图2所示,个性化路径出行选择服务策略的博弈协商机制设定为三步。首先是通过云系统将从网联端系统获得的诸多信息通过整理、计算和分析交给管系统,由管系统提出系统最优服务策略集合交给端系统。此时,端系统进行第一次博弈协商过程:端系统对于管系统提出的系统最优决策集合进行符合自身利益的判断,最终选择接受或者拒绝。如接受,那么第一次博弈协商成功,执行选择路径;如拒绝,那么进行第二次博弈协商过程。第二次博弈协商过程是由端系统重新计算生成系统最优出行策略集合,交给端系统判断,最终进行接受或者拒绝的选择。如接受,第二次博弈协商过程成功;如拒绝,则进行第三次博弈协商过程。第三次博弈协商过程由端系统提供给管系统符合自身利益得出行策略集合,由管系统进行判断,选择接受或者拒绝。接受则第三次协商成功;拒绝则强行执行第一次系统最优出行策略,视为协商失败。
如图3所示,本发明的仿真验证平台是基于多智能体的车联网环境下出行者路径选择仿真平台环境。其运行规则表示为:首先构建路网环境并生成仿真车辆;其次依照一定的比例给定车辆驾驶员是否具有个性化的定义,因之决定其是否与系统最优路径决策进行博弈协商过程;最终完成车辆的出行决策,并由出发点驶达目的地。仿真系统运行的整个过程受到监控,便于观察者利用获取的仿真数据进行分析与验证。
如图4所示,采用“田”字型路网,令1、9点分别为路径规划的od点。同时为区分各个路段与其属性,设定各路段名称与自由流速度如图中数字所示。
如图5所示,设定od点后,规划出可供选择的六条路径:route1、route2、route3、route4、route5、route6。最终利用仿真验证系统分别计算各个路径效用值,进行仿真验证过程。
如图6所示,在本发明中,采用对照试验。在保持个性化驾驶员占比(connected?)数值一定时,令路网饱和度(come-rate)分别为0.2、0.4、0.6、0.8、1.0;相应地,在路网饱和度不变的情况下,令个性化驾驶员占比分别为0%、20%、40%、60%、80%、100%。同时,制定行驶规则时,模拟现实情况,设定车辆加速度acceleration=0.0074,减速度deceleration=0.030。在人机交互界面进行仿真场景参数设置后,通过界面上设置的setup按钮进行仿真系统初始化,然后通过点击go按钮开始进行仿真试验,在仿真试验进行过程中可以通过数据监视窗、2d视图和绘图实时观察仿真运行情况,再次点击此按钮则仿真暂停。
下面是试验流程:
(1)设定本次试验所需用的来车率与个性化驾驶员占比,点击setup按钮进行仿真系统初始化,然后点击go按钮开始仿真。将仿真系统运行一段时间,消除暂态影响并观察图像变化,观察仿真时刻大约在10000左右时点击go按钮停止仿真实验,导出仿真数据如图4、图5所示。
(2)观察数据是否出现较大误差。是则点击setup按钮重新运行该仿真;否则继续改变来车率与个性化驾驶员占比,再次重复(1)步并完成实验。
以上详细描述了本发明的实施过程,但是本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,具体的细节是可以改变替换的,如可以只需要通过改变仿真内核中出行者路径选择的规则可以研究不同的问题,在本仿真系统框架下具有较高的普适性,都属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!