ETL依赖自动识别方法与系统与流程
本发明涉及计算机技术领域,特别涉及一种etl(extract-transform-load,抽取、转换、加载)依赖自动识别方法与系统。
背景技术:
当前在作业平台上开发任务时,配置任务依赖的步骤通常包括:人为地识别出所有的输入表,再人为地辨别每个输入表是否需要依赖,并在需要依赖的情况下辨别是否需要改变输入表的当前依赖。如此,大量的人为操作增加了etl任务开发的复杂度,同时大量的人为操作也容易发生依赖错误(诸如缺失依赖或者多余依赖)的情况,进而导致最终产出的结果发生错误。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中人为配置任务依赖的缺陷,提供一种etl依赖自动识别方法与系统。
本发明是通过下述技术方案来解决上述技术问题:
一种etl依赖自动识别方法,其特点在于,包括:
s1、获取所有etl任务中的标记语言,并将所述标记语言保存至标记语言库,其中所述标记语言包括数据对象id和标记任务号;
s2、根据etl任务获取数据对象,所述数据对象包括当前数据对象id;
s3、判断所述数据对象是否为当前创建的临时表;
若否,则转至步骤s4;
s4、判断所述标记语言库是否包括所述当前数据对象id;
若是,则转至步骤s5;
s5、根据所述标记任务号生成依赖任务号。
优选地,步骤s1具体包括:
s11、询问etl任务;
s12、判断所述etl任务是否包括标记语言;
若是,则转至步骤s13;
s13、判断所述标记语言是否包括数据对象id和标记任务号;
若是,则转至步骤s14;
s14、将所述标记语言保存至标记语言库;和/或
步骤s2具体包括:
s21、解析etl任务获取语法树;
s22、解析所述语法树获取数据对象。
优选地,所述数据对象还包括当前任务号,所述etl依赖自动识别方法还包括:
s6、判断所述标记任务号是否与所述当前任务号相同;
若否,则转至步骤s7;
s7、将所述当前任务号保存至错误依赖表。
优选地,步骤s7具体包括:
s71、根据所述标记任务号和所述当前任务号判断发生的是多余依赖还是缺失依赖;
若是多余依赖,则转至步骤s72;若是缺失依赖,则转至步骤s73;
s72、将所述当前任务号保存至多余依赖表;
s73、将所述当前任务号保存至缺失依赖表。
优选地,所述etl依赖自动识别方法还包括:
s8、发送错误通知。
一种etl依赖自动识别系统,其特点在于,包括:
第一获取模块,用于获取所有etl任务中的标记语言,并将所述标记语言保存至标记语言库,其中所述标记语言包括数据对象id和标记任务号;
第二获取模块,用于根据etl任务获取数据对象,所述数据对象包括当前数据对象id;
第一判断模块,用于判断所述数据对象是否为当前创建的临时表,并在判断为否时调用第二判断模块;
所述第二判断模块,用于判断所述标记语言库是否包括所述当前数据对象id,并在判断为是时调用生成模块;
所述生成模块,用于根据所述标记任务号生成依赖任务号。
优选地,所述第一获取模块包括:
询问模块,用于询问etl任务;
第三判断模块,用于判断所述etl任务是否包括标记语言,并在判断为是时调用第四判断模块;
所述第四判断模块,用于判断所述标记语言是否包括数据对象id和标记任务号,并在判断为是时调用第一保存模块;
所述第一保存模块,用于将所述标记语言保存至标记语言库;和/或
所述第二获取模块包括:
第一解析模块,用于解析etl任务获取语法树;
第二解析模块,用于解析所述语法树获取数据对象。
优选地,所述数据对象还包括当前任务号,所述etl依赖自动识别系统还包括:
第五判断模块,用于判断所述标记任务号是否与所述当前任务号相同,并在判断为否时调用第二保存模块;
所述第二保存模块,用于将所述当前任务号保存至错误依赖表。
优选地,所述第二保存模块包括:
第六判断模块,用于根据所述标记任务号和所述当前任务号判断发生的是多余依赖还是缺失依赖,并在判断发生多余依赖时调用第三保存模块,发生缺失依赖时调用第四保存模块;
所述第三保存模块,用于将所述当前任务号保存至多余依赖表;
所述第四保存模块,用于将所述当前任务号保存至缺失依赖表。
优选地,所述etl依赖自动识别系统还包括:
通知模块,用于发送错误通知。
本发明的积极进步效果在于:本发明etl依赖自动识别方法与系统首先获取etl任务中事先标记的标记语言,再判断etl任务中的数据对象是否被标记,并在是的情况下根据标记语言生成真正的依赖任务号。减少了作业平台开发中的人为参与,提高了任务配置的效率以及准确率。
附图说明
图1为本发明实施例1的etl依赖自动识别方法的流程图。
图2为本发明实施例2的etl依赖自动识别方法的流程图。
图3为本发明实施例3的etl依赖自动识别方法的流程图。
图4为本发明实施例4的etl依赖自动识别系统的结构示意图。
图5为本发明实施例5的etl依赖自动识别系统的结构示意图。
图6为本发明实施例6的etl依赖自动识别系统的结构示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1
本实施例提供了一种etl依赖自动识别方法,图1示出了本实施例的流程图。如图1所示,本实施例的etl依赖自动识别方法包括以下步骤:
s101、获取所有etl任务中的标记语言,并将标记语言保存至标记语言库,其中标记语言包括数据对象id和标记任务号;
s102、根据etl任务获取数据对象,数据对象包括当前数据对象id;
s103、判断数据对象是否为当前创建的临时表;
若否,则转至步骤s104;
s104、判断标记语言库是否包括当前数据对象id;
若是,则转至步骤s105;
s105、根据标记任务号生成依赖任务号。
具体地,编程人员在编写程序时,通常会在语句、程序段等之后添加标记语言,以对所编写的程序代码进行解释和说明,etl任务中也包括标记语言,该标记语言包括数据对象id和标记任务号,用以解释和说明数据对象的真正的任务号。本实施例首先获取所有etl任务中的标记语言并保存至标记语言库,即获取数据对象id与标记任务号之间的对应关系并保存,以供后续步骤调用。其次,获取etl任务的数据对象,该数据对象包括当前数据对象id,并排除当前创建的临时表,以提高本实施例etl依赖自动识别方法的准确性。最后,再判断标记语言库中是否包括当前数据对象id,即判断针对当前数据对象id是否设有标记任务号,也即判断针对当前数据对象id是否对其真正的任务号进行解释和说明,若是,则根据标记语言库中当前数据对象id对应的标记任务号生成依赖任务号,以为当前数据对象配置其真正的任务号;若否,则按照常规方式配置依赖任务号,例如通过人为手动的方式为当前数据对象配置其真正的任务号,又或者某些维表(诸如国家维表)并不需要设置依赖任务号。
本实施例的etl依赖自动识别方法首先获取etl任务中预设的对数据对象真正的任务号进行解释和说明的标记语言,再判断etl任务中的数据对象是否被标记语言所标记,并在是的情况下根据该标记语言生成该数据对象真正的依赖任务号。因此,本实施例的etl依赖自动识别方法在程序编写完成之后,可以自动识别etl任务中的依赖任务号并对数据对象的依赖任务号进行自动配置,减少了作业平台开发中的人为参与,进而提高了任务配置的效率以及准确性。
实施例2
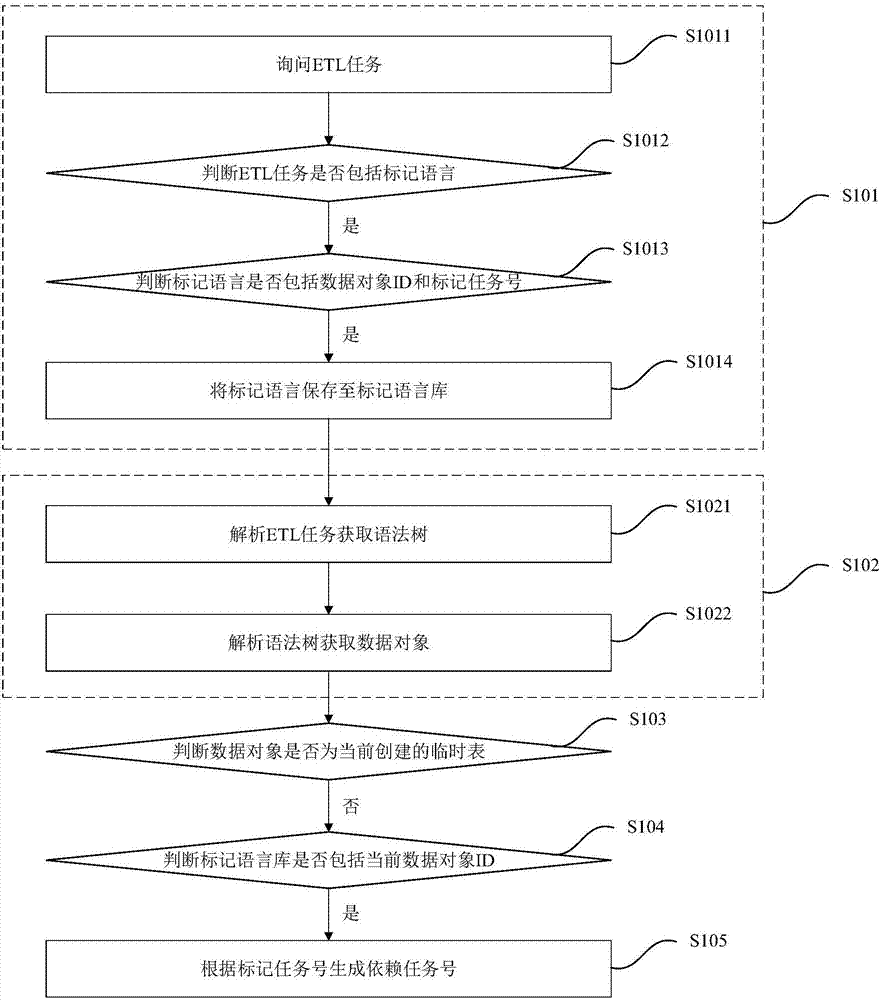
本实施例提供的etl依赖自动识别方法是对实施例1的进一步改进,图2示出了本实施例的流程图。如图2所示,本实施例的etl依赖自动识别方法较之实施例1,其改进在于:
步骤s101具体包括:
s1011、询问etl任务;
s1012、判断etl任务是否包括标记语言;
若是,则转至步骤s1013;
s1013、判断标记语言是否包括数据对象id和标记任务号;
若是,则转至步骤s1014;
s1014、将标记语言保存至标记语言库。
本实施例进一步细化了获取所有etl任务中标记语言并保存至标记语言库的步骤s101。在程序编写过程中,标记语言不仅仅只用来解释和说明数据对象及其真正的任务号,因此获取etl任务中的数据对象id以及其对应的标记任务号的过程则包括两个判断步骤:其一,判断etl任务中是否包括标记语言;其二,判断标记语言的内容是否用来解释和说明数据对象及其真正的任务号,即标记语言是否包括数据对象id和标记任务号,其中,在两个判断皆为是时才能获得etl任务中包括数据对象id和标记任务号的标记语言。
此外,本实施例的etl依赖自动识别方法较之实施例1,其改进还在于:
步骤s102具体包括:
s1021、解析etl任务获取语法树;
s1022、解析所述语法树获取数据对象。
本实施例进一步细化了根据etl任务获取数据对象的步骤s102,即通过解析etl任务以识别数据对象,数据对象的类型包括表和视图。
本实施例的etl依赖自动识别方法是对实施例1的进一步改进,具体细化了实施例1中的步骤s101和步骤s102,提供了一种更加优选的实施方式。
实施例3
本实施例提供的etl依赖自动识别方法是对实施例1的进一步改进,图3示出了本实施例的流程图。如图3所示,较之实施例1,本实施例步骤s102中的数据对象还包括当前任务号,本实施例的etl依赖自动识别方法的还包括:
s106、判断标记任务号是否与当前任务号相同;
若否,则转至步骤s107;
s107、将当前任务号保存至错误依赖表;
s108、发送错误通知。
其中,步骤s107具体包括:
s1071、根据标记任务号和当前任务号判断发生的是多余依赖还是缺失依赖;
若是多余依赖,则转至步骤s1072;若是缺失依赖,则转至步骤s1073;
s1072、将当前任务号保存至多余依赖表;
s1073、将当前任务号保存至缺失依赖表。
具体地,与实施例1提供的etl依赖自动识别方法相比,本实施例在步骤s105根据标记任务号生成依赖任务号之后,还判断生成的依赖任务号所依据的标记任务号是否与数据对象的当前任务号相同。若相同,则表明事先针对该数据对象配置的当前任务号为该数据对象真正的任务号,未发生错误依赖;若不相同,则表明事先针对该数据对象配置的当前任务号并非该数据对象真正的任务号,发生了错误依赖,在此情况下,进一步根据该数据对象的对应的标记任务号以及当前任务号判断发生的是多余依赖的情形还是缺失依赖的情形,并分别将多余依赖以及缺失依赖对应的当前任务号保存至多余依赖表以及缺失依赖表。最后,发送错误通知以告知相关人员之前存在的错误依赖的情形,例如但不限于通过邮件方式发送错误通知。
本实施例的etl依赖自动识别方法是对实施例1的进一步改进,改进在于本实施例还包括识别etl任务中发生的错误依赖(多余依赖以及缺失依赖)的情形,并且本实施例还包括发送错误通知的步骤,提高了本实施例etl依赖自动识别方法与相关人员的交互性。
实施例4
本实施例提供了一种etl依赖自动识别系统,图4示出了本实施例的结构示意图。如图4所示,本实施例的etl依赖自动识别系统1包括:
第一获取模块11,用于获取所有etl任务中的标记语言,并将标记语言保存至标记语言库,其中标记语言包括数据对象id和标记任务号;
第二获取模块12,用于根据etl任务获取数据对象,数据对象包括当前数据对象id;
第一判断模块13,用于判断数据对象是否为当前创建的临时表,并在判断为否时调用第二判断模块14;
第二判断模块14,用于判断标记语言库是否包括当前数据对象id,并在判断为是时调用生成模块15;
生成模块15,用于根据标记任务号生成依赖任务号。
具体地,编程人员在编写程序时,通常会在语句、程序段等之后添加标记语言,以对所编写的程序代码进行解释和说明,etl任务中也包括标记语言,该标记语言包括数据对象id和标记任务号,用以解释和说明数据对象的真正的任务号。本实施例首先通过第一获取模块11获取所有etl任务中的标记语言并保存至标记语言库,即获取数据对象id与标记任务号之间的对应关系并保存,以供后续步骤调用。其次,通过第二获取模块12获取etl任务的数据对象,该数据对象包括当前数据对象id,并通过第一判断模块13排除当前创建的临时表,以提高本实施例etl依赖自动识别系统1的准确性。最后,再通过第二判断模块14判断标记语言库中是否包括当前数据对象id,即判断针对当前数据对象id是否设有标记任务号,也即判断针对当前数据对象id是否对其真正的任务号进行解释和说明,若是,则生成模块15根据标记语言库中当前数据对象id对应的标记任务号生成依赖任务号,以为当前数据对象配置其真正的任务号;若否,则按照常规方式配置依赖任务号,例如通过人为手动的方式为当前数据对象配置其真正的任务号,又或者某些维表(诸如国家维表)并不需要设置依赖任务号。
本实施例的etl依赖自动识别系统首先获取etl任务中预设的对数据对象真正的任务号进行解释和说明的标记语言,再判断etl任务中的数据对象是否被标记语言所标记,并在是的情况下根据该标记语言生成该数据对象真正的依赖任务号。因此,本实施例的etl依赖自动识别系统在程序编写完成之后,可以自动识别etl任务中的依赖任务号并对数据对象的依赖任务号进行自动配置,减少了作业平台开发中的人为参与,进而提高了任务配置的效率以及准确性。
实施例5
本实施例提供的etl依赖自动识别系统是对实施例4的进一步改进,图5示出了本实施例的结构示意图。如图5所示,本实施例的etl依赖自动识别系统1较之实施例4,其改进在于:
第一获取模块11具体包括:
询问模块111,用于询问etl任务;
第三判断模块112,用于判断etl任务是否包括标记语言,并在判断为是时调用第四判断模块113;
第四判断模块113,用于判断标记语言是否包括数据对象id和标记任务号,并在判断为是时调用第一保存模块114;
第一保存模块114,用于将标记语言保存至标记语言库。
本实施例进一步细化了第一获取模块11的组成结构。在程序编写过程中,标记语言不仅仅只用来解释和说明数据对象及其真正的任务号,因此获取etl任务中的数据对象id以及其对应的标记任务号的过程则包括两个判断步骤:其一,判断etl任务中是否包括标记语言;其二,判断标记语言的内容是否用来解释和说明数据对象及其真正的任务号,即标记语言是否包括数据对象id和标记任务号,其中,在两个判断皆为是时才能获得etl任务中包括数据对象id和标记任务号的标记语言。
此外,本实施例的etl依赖自动识别系统1较之实施例4,其改进还在于:
第二获取模块12具体包括:
第一解析模块121,用于解析etl任务获取语法树;
第二解析模块122,用于解析所述语法树获取数据对象。
本实施例进一步细化了第二获取模块12的组成结构,即通过第一解析模块121和第二解析模块122解析etl任务以识别数据对象,数据对象的类型包括表和视图。
本实施例的etl依赖自动识别系统是对实施例4的进一步改进,具体细化了实施例4中的第一获取模块11和第二获取模块12的组成结构,提供了一种更加优选的实施方式。
实施例6
本实施例提供的etl依赖自动识别系统是对实施例4的进一步改进,图6示出了本实施例的结构示意图。其中,本实施例第二获取模块12所获取的数据对象还包括当前任务号,如图6所示,较之实施例4,本实施例的etl依赖自动识别系统1还包括:
第五判断模块16,用于判断标记任务号是否与当前任务号相同,并在判断为否时调用第二保存模块17;
第二保存模块17,用于将当前任务号保存至错误依赖表;
通知模块18,用于发送错误通知。
其中,第二保存模块17具体包括:
第六判断模块171,用于根据标记任务号和当前任务号判断发生的是多余依赖还是缺失依赖,并在判断发生多余依赖时调用第三保存模块172,发生缺失依赖时调用第四保存模块173;
第三保存模块172,用于将当前任务号保存至多余依赖表;
第四保存模块173,用于将当前任务号保存至缺失依赖表。
具体地,与实施例4提供的etl依赖自动识别系统相比,本实施例在生成模块15根据标记任务号生成依赖任务号之后,还通过第五判断模块16判断生成的依赖任务号所依据的标记任务号是否与数据对象的当前任务号相同。若相同,则表明事先针对该数据对象配置的当前任务号为该数据对象真正的任务号,未发生错误依赖;若不相同,则表明事先针对该数据对象配置的当前任务号并非该数据对象真正的任务号,发生了错误依赖,在此情况下,进一步第六判断模块17根据该数据对象的对应的标记任务号以及当前任务号判断发生的是多余依赖的情形还是缺失依赖的情形,并分别通过第三保存模块172和第四保存模块173将多余依赖以及缺失依赖对应的当前任务号保存至多余依赖表以及缺失依赖表。最后,通知模块18发送错误通知以告知相关人员之前存在的错误依赖的情形,例如但不限于通过邮件方式发送错误通知。
本实施例的etl依赖自动识别系统是对实施例4的进一步改进,改进在于本实施例还包括识别etl任务中发生的错误依赖(多余依赖以及缺失依赖)的情形,并且本实施例还包括发送错误通知的通知模块,提高了本实施例etl依赖自动识别系统与相关人员的交互性。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!