一种头部姿态检测方法与流程
本发明涉及一种头部姿态检测方法,涉及一种利用计算机视觉技术中深度学习训练模型对精神疾病儿童的头部姿态进行检测的方法。
背景技术:
头部姿态能够帮助人们定位以传递一些丰富的信息,比如人们用他们的头部指向来表明其对话对象和意图。在一些对话中,头部方向是一个非语言的公示,提醒倾听者什么时候去转换角色和开始说话;在这些对话中,头部姿态方向和手势的形式有着相同重要的作用。
对于一些自闭症、多动症或抽动症儿童来说,头部指向更能够反映出这些孩子对于当前环境中所指的意图是什么,可以方便治疗师或者医生了解这些孩子的想法。当今的头部姿态检测方法有多种:如早期使用探测器阵列方法(训练很多的头部探测器,每个检测器适应一个特殊姿势,然后指定一个离散姿势到这些探测器上,相应的预测一些头部姿态);中期使用机器学习中的非线性回归方法或者随机森林算法;近期的一些算法是提取人脸的关键点,以深度学习训练进行头部姿态的预测。
但是上述方法存在一定的缺陷:都比较依赖于环境的影响。如果环境背景有很大的变换,或者检测者的年龄有很大的差距(如具有自闭症、多动症或抽动症等精神疾病的人群普遍是儿童,而儿童的头部姿态检测和成人略有不同),就容易造成检测结构不准确。
技术实现要素:
本发明目的是为了克服现有技术的不足而提供一种头部姿态检测方法,适用于具有自闭症、多动症或抽动症等精神疾病的儿童。
为达到上述目的,本发明所采用的技术方案为:一种头部姿态检测方法,它包括以下步骤:
(a)选择数据集;
(b)对所述数据集中的人脸图片进行预处理,使用多任务级联卷积神经网络对所述人脸图片进行人脸检测和切割,随后进行大小转换得到设定大小的图片;
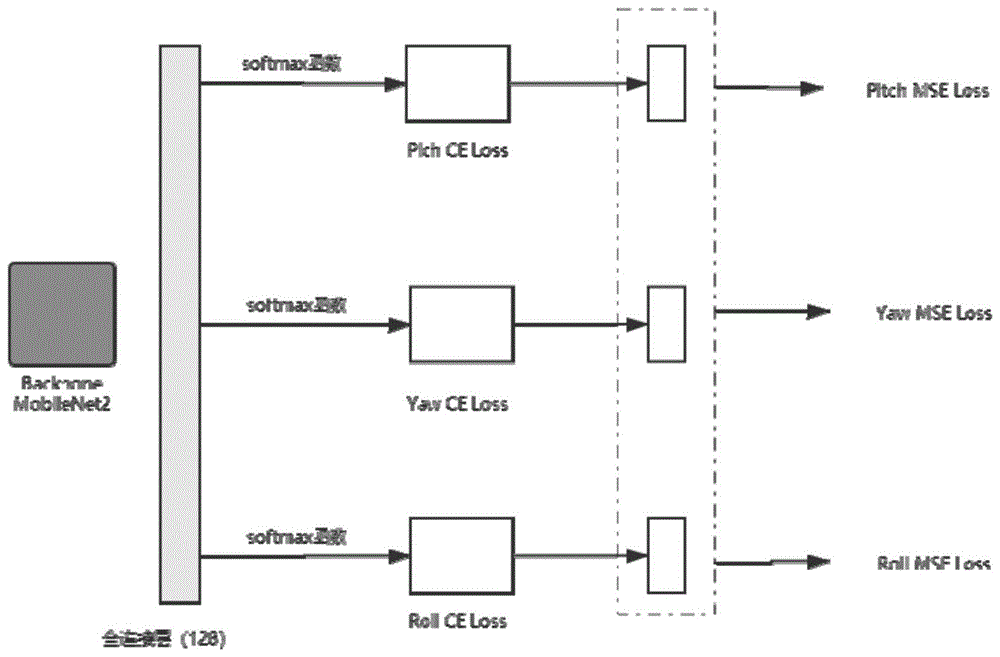
(c)对深度学习的模型构建以mobilenetv2作为骨干且分别连接三个全连接层的神经网络;
(d)将所述设定大小的图片放入所述神经网络进行分类;
(e)对所述全连接层的结果做softmax以将所述全连接层的值映射成概率值;
(f)对所述概率值进行映射得回归,用mse损失函数的方法计算回归的损失概率;
(g)对所述损失概率进行权重加权求和,并对最终的损失概率梯度方向,以完成深度学习模型的训练;
(h)以鼻子为基础点,水平的方向设置成x轴,垂直的方向设置成y轴,z轴则垂直于x轴与y轴形成的平面,环绕x轴、y轴、z轴顺时针旋转的角度定义为头部姿态在pitch、yaw、roll方向的偏移角度,将所述深度学习模型对儿童头部进行测试得到儿童头部的姿势位置。
优化地,步骤(a)中,所述数据集是biwi、300w-lp和aflw2000数据集。
优化地,步骤(b)中,所述预处理是将所述人脸图片中不需要的背景或其它物体排除。
进一步地,步骤(b)中,所述多任务级联卷积神经网络由pnet、rnet和onet三个级联的轻量级cnn完成。
优化地,步骤(d)中,将所述分类结果map到一个范围里面。
由于上述技术方案运用,本发明与现有技术相比具有下列优点:本发明头部姿态检测方法,利用深度学习模型使用复合型损失函数对三个角度分别进行损失计算,具有程序检测速度快、能达到实时性;有统一的评判标准,准确率高;可以节省治疗师或者医生观察孩子的时间,让治疗师或者医生在其它方面更多的去治疗孩子;而且数据可以视频的形式被存储和显示。
附图说明
图1为本发明头部姿态检测方法中mse损失函数的流程图;
图2为本发明头部姿态检测方法的第一使用效果图;
图3为本发明头部姿态检测方法的第二使用效果图。
具体实施方式
下面将结合附图对本发明优选实施方案进行详细说明。
本发明头部姿态检测方法,它包括以下步骤:
(a)选择数据集;在本实施例中,数据集主要是biwi、300w-lp和aflw2000数据集(即主要是在biwi、300w-lp和aflw2000数据集上训练和测试的)。biwi数据集发布于2010年,包含1000个高质量的3d扫描仪和专业麦克风采集的3d数据,采集以每秒25帧的速度获取密集的动态面部扫描。300w-lp是基于300w数据集和3dmm模型仿真得到的3d数据集,这是3d领域里使用最大,使用最广泛的仿真数据集,包含了68个关键点,相机参数以及3dmm模型的系数的标注。aflw是一个包括多姿态、多视角的大规模人脸数据库,一般用于评估面部关键点检测效果,图片来自于flickr的爬取,总共有21997张图、25993张面孔、每张人脸标注21个关键点(共380000个关键点)。
(b)对数据集中的人脸图片进行预处理,使用多任务级联卷积神经网络(mtcnn,mtcnn是比较经典快速的人脸检测技术,它是由三个级联的轻量级cnn完成:pnet,rnet和onet)对人脸图片进行人脸检测和切割,把一些不需要的背景或者是其它物体进行排除,以保证训练时不出现过拟合数据。随后将预处理的图片进行大小转换得到设定大小的图片,因为深度学习在训练时候需要大小一致的图片,在本实施例中,设定每一张图片的大小是128像素×128像素;
(c)对深度学习的模型构建以mobilenetv2作为骨干且分别连接三个全连接层的神经网络(即深度网络是以mobilenetv2作为基础的骨干,分别全连接三个全连接层,每个层单独预测);
(d)将设定大小的图片放入神经网络进行分类,然后将分类的结果map到一个范围里面,这样它的精度会有很大的提升(这个步骤是分类的损失概率);
(e)对全连接层的结果做softmax以将全连接层的值映射成概率值;
(f)对概率值进行映射得回归(即根据这个概率值进行映射就是需要的回归),用mse损失函数的方法计算回归的损失概率(如图1所示;mse本来主要介绍机器学习中常见的损失函数mse的定义以及它的求导特性,而数理统计中均方误差是指参数估计值与参数值之差平方的期望值;mse是衡量“平均误差”的一种较方便的方法,可以评价数据的变化程度,mse的值越小,说明预测模型描述实验数据具有更好的精确度);
(g)对损失概率进行权重加权求和,并对最终的损失概率梯度方向,以完成深度学习模型的训练;
(h)以鼻子为基础点,水平的方向设置成x轴,垂直的方向设置成y轴,z轴则垂直于x轴与y轴形成的平面,环绕x轴、y轴、z轴顺时针旋转的角度定义为头部姿态在pitch、yaw、roll方向的偏移角度,将深度学习模型对儿童头部进行测试得到儿童头部的姿势位置(具体应用参见图2和图3)。
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
技术特征:
1.一种头部姿态检测方法,其特征在于,它包括以下步骤:
(a)选择数据集;
(b)对所述数据集中的人脸图片进行预处理,使用多任务级联卷积神经网络对所述人脸图片进行人脸检测和切割,随后进行大小转换得到设定大小的图片;
(c)对深度学习的模型构建以mobilenetv2作为骨干且分别连接三个全连接层的神经网络;
(d)将所述设定大小的图片放入所述神经网络进行分类;
(e)对所述全连接层的结果做softmax以将所述全连接层的值映射成概率值;
(f)对所述概率值进行映射得回归,用mse损失函数的方法计算回归的损失概率;
(g)对所述损失概率进行权重加权求和,并对最终的损失概率梯度方向,以完成深度学习模型的训练;
(h)以鼻子为基础点,水平的方向设置成x轴,垂直的方向设置成y轴,z轴则垂直于x轴与y轴形成的平面,环绕x轴、y轴、z轴顺时针旋转的角度定义为头部姿态在pitch、yaw、roll方向的偏移角度,将所述深度学习模型对儿童头部进行测试得到儿童头部的姿势位置。
2.根据权利要求1所述的头部姿态检测方法,其特征在于:步骤(a)中,所述数据集是biwi、300w-lp和aflw2000数据集。
3.根据权利要求1所述的头部姿态检测方法,其特征在于:步骤(b)中,所述预处理是将所述人脸图片中不需要的背景或其它物体排除。
4.根据权利要求1或3所述的头部姿态检测方法,其特征在于:步骤(b)中,所述多任务级联卷积神经网络由pnet、rnet和onet三个级联的轻量级cnn完成。
5.根据权利要求1所述的头部姿态检测方法,其特征在于:步骤(d)中,将所述分类结果map到一个范围里面。
技术总结
本发明涉及一种头部姿态检测方法,它包括以下步骤:(a)选择数据集;(b)对所述数据集中的人脸图片进行预处理,随后进行大小转换得到设定大小的图片;(c)对深度学习的模型构建以MobileNetv2作为骨干;(d)将所述设定大小的图片放入所述神经网络进行分类;(e)对所述全连接层的结果做softmax以将所述全连接层的值映射成概率值;(f)对所述概率值进行映射得回归,用MSE损失函数的方法计算回归的损失概率;(g)对所述损失概率进行权重加权求和,并对最终的损失概率梯度方向,以完成深度学习模型的训练;(h)将所述深度学习模型对儿童头部进行测试。具有程序检测速度快、能达到实时性。
技术研发人员:林士然;蒋磊
受保护的技术使用者:苏州瓴图智能科技有限公司
技术研发日:2020.02.26
技术公布日:2020.06.26
- 还没有人留言评论。精彩留言会获得点赞!