一种基于SAE的脱丁烷塔底部产品丁烷浓度实时监测方法与流程
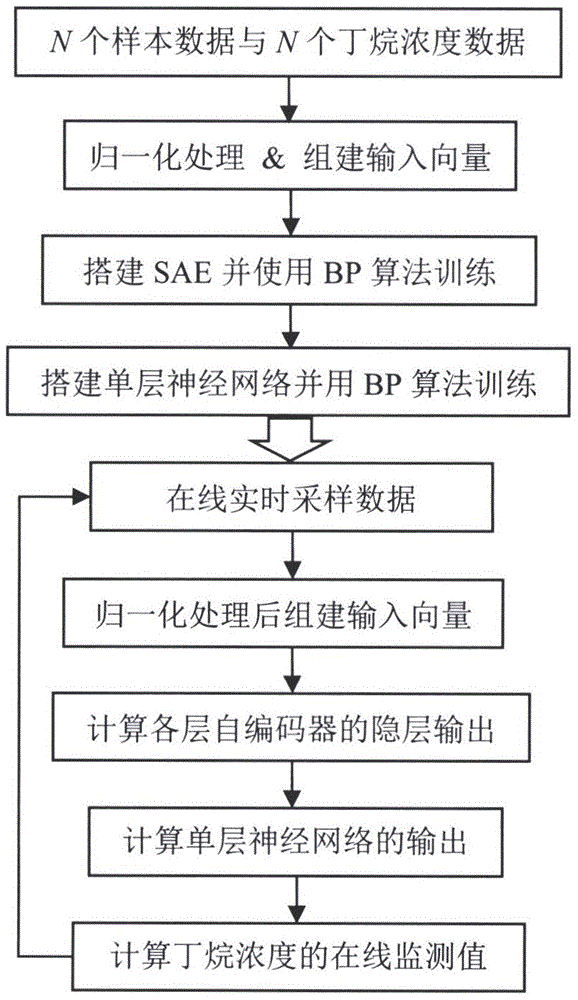
本发明涉及一种软测量技术,特别涉及一种基于sae的脱丁烷塔底部产品丁烷浓度实时监测方法。
背景技术:
脱丁烷塔是炼油工业过程中非常重要的设备,其在炼油过程中起到的作用是分离石脑油和脱硫处理。脱丁烷塔的的工艺流程一般包含6个化工设备:塔顶部冷凝器,热交换器,塔顶部回流泵,塔底部再沸器,回流储液器,和进料泵。在石脑油的流经通道内,需要去除石脑油中的丙烷和丁烷。因此,对于丁烷塔质量控制要求而言,最小化塔底部产品的丁烷含量是非常重要的。为保证质量控制的实时性,在线实时测量丁烷的浓度是最直接,也是最有效的技术手段。
然而,丁烷含量的测量跟化工过程测量温度、压力、流量是不同的,需要使用成分分析仪。此外,在线成分分析仪价格高昂,且后期维护成本较高,测量丁烷浓度一般采用离线分析仪器。但是,离线分析仪器无法保证对丁烷浓度的实时测量,不能满足丁烷浓度测量的实时性要求。因此,需要一种软测量技术来实时在线监测丁烷的浓度。
近年来,栈式自编码器(stackedauto-encoder,缩写:sae)在深度学习领域得到了广泛的关注,其优势在于逐层提取输入数据中的特征,已被广泛用于模式识别领域。由于脱丁烷塔运行过程中动态变化性强,运行环境中还存在随机干扰,因此对脱丁烷塔过程测量变量进行深度特征提取是非常有必要的。值得强调的是,sae虽然可以分层递进的提取输入数据中的特征,但是在逐层提取特征的过程中会出现信息丢失问题。从这个角度上讲,无法做到对特征的充分有效挖掘。此外,sae是一种无监督型的建模技术,而软测量模型归属于有监督模型。因此,如何有效的利用这些提取的特征用于实时软测量脱丁烷塔底部产品的丁烷浓度还是一个需要商榷的技术难题。
技术实现要素:
本发明所要解决的主要技术问题是:如何避免信息丢失的情况下利用sae逐层提取丁烷塔过程测量数据的非线性特征,并充分有效利用这些非线性特征对塔底部产品的丁烷浓度进行在线软测量。具体来讲,本发明方法通过将脱丁烷塔的过程测量数据皆做为各层自编码器的输入,在逐层提取非线性特征时,可以避免信息的丢失问题。此外,利用各层自编码器提取的非线性特征,与丁烷浓度的输出数据之间建立单层神经网络,从而实现对丁烷浓度的实时在线监测。
本发明方法解决上述问题所采用的技术方案为:一种基于sae的脱丁烷塔底部产品丁烷浓度实时监测方法,包括以下步骤:
步骤(1):利用丁烷塔设备中安装的7个测量仪表实时测量过程变量数据,直至采集得到n个样本数据,分别记录成7个列向量x1,x2,…,x7,并利用离线分析仪获取相同测量时刻塔底部产品丁烷含量的n个数据,对应记录成列向量y,其中xi由第i个过程变量的n个样本数据组成,i∈{1,2,…,7}分别对应于塔顶部温度,塔顶部压力,回流流量,底部产品出口流量,第6层塔板温度,塔底部温度a和塔底部温度b。
由于涉及商业机密,塔底部温度测量点有两个,具体测量位置使用a和b来表示。
步骤(2):根据如下所示公式对x1,x2,…,x7和y分别实施归一化处理,对应得到7个数据向量
其中,rn×5表示n×5维的实数矩阵,
步骤(3):根据如下所示公式组建输入矩阵z中的第k列输入向量zk∈r28×1:
zk=[x(k+3),x(k+2),x(k+1),x(k)]t②
上式中,x(k+3),x(k+2),x(k+1),x(k)分别表示数据矩阵x中的第k+3行,第k+2行,第k+1行和第k行的行向量,k∈{1,2,…,n},r28×1表示28×1维的实数向量,n=n-3,上标号t表示矩阵或向量的转置。
步骤(4):搭建一个由m层自编码器串联组成的sae,并确定隐层神经元激活函数f(u),输出层神经元激活函数ζ(u),和各层自编码器的隐层神经元个数h1,h2,…,hm;其中u表示函数自变量。
步骤(5):利用反向传播(back-propagation,缩写为bp)算法依次训练sae中第1层自编码器,第2层自编码器,直至第m层自编码器的隐层和输出层的权重系数w1,w2,…,wm和
步骤(5.1):第1层自编码器的输入层有28个神经元,隐层有h1个神经元,输出层有28个神经元,分别初始化隐层和输出层的权重系数和阈值。
步骤(5.2):以z1,z2,…,zn做为第1层自编码器的输入,同时以z1,z2,…,zn做为第1层自编码器的输出,利用bp算法训练得到第1层自编码器的隐层和输出层的权重系数
步骤(5.3):第m+1层自编码器的输入层有hm+28个神经元,隐层有hm+1个神经元,输出层有28个神经元,并分别初始化隐层和输出层的权重系数和阈值。
步骤(5.4):将第m层自编码器隐层的输出向量g1(m),g2(m),…,gn(m)组建成矩阵gm=[g1(m),g2(m),…,gn(m)]t,并将矩阵gm与输入矩阵z合并成一个矩阵hm=[gm,zt]t,其中,g1(m),g2(m),…,gn(m)的计算方式如下所示。
步骤(5.5):以矩阵hm的n个列向量做为第m+1层自编码器的输入,同时以z1,z2,…,zn做为第m+1层自编码器的输出,再次利用bp算法训练得到第m+1层自编码器的隐层和输出层的权重系数
步骤(5.6):判断是否满足m+1<m;若是,则设置m=m+1后返回步骤(5.3);若否,则训练结束,保留栈式自编码器所有的权重系数w1,w2,…,wm和
步骤(6):搭建一个只有输入层与输出层的单层神经网络,其中输入层包含h=h1+h2+…+hm个神经元,输出层包含1个神经元,输出层的激活函数为φ(u)。
步骤(7):将矩阵g1,g2,…,gm合并成一个矩阵g=[g1,g2,…,gm]t后,将矩阵g∈rh×n中的n个列向量做为单层神经网络的输入,将
上述实施步骤完成了对丁烷塔底部产品丁烷浓度的软测量建模,接下来就是利用在线实时测量的数据,实现对脱丁烷塔底部产品丁烷浓度的在线监测,具体实施步骤如下所示。
步骤(8):在最新采样时刻t,对7个采样数据v1(t),v2(t),…,v7(t)进行归一化处理,得到归一化后的数据
上式中,i∈{1,2,…,7}。
步骤(9):根据at=[v(t),v(t-1),v(t-2),v(t-3)]t组建最新采样时刻的输入向量at,其中,行向量
步骤(10):以输入向量at做为栈式自编码器的输入,依次计算得到第1层自编码器,第2层自编码器,直至第m层自编码器的隐层输出向量ct(1),ct(2),…,ct(m),具体的实施过程如下所示:
步骤(10.1):根据公式ct(1)=f(w1tat+b1)计算第1层自编码器的隐层输出向量ct(1),并初始化m=1。
步骤(10.2):将第m层自编码器的隐层输出向量ct(m)与输入向量at合并成一个列向量
步骤(10.3):判断是否满足m+1<m;若是,则设置m=m+1后,返回步骤(10.2);若否,则得到m个隐层输出向量ct(1),ct(2),…,ct(m)。
步骤(11):将隐层输出向量ct(1),ct(2),…,ct(m)合并成一个列向量ct∈rh×1后,将ct做为单层神经网络的输入,并根据公式
步骤(12):根据
步骤(13):返回步骤(8),继续实施对下一个最新采样时刻的脱丁烷塔底部产品丁烷浓度的实时监测。
通过以上所述实施步骤,本发明方法的优势介绍如下。
首先,本发明方法在训练模型时,各层自编码器的输入都使用了输入向量,因此在特征提取的过程中避免了输入数据信息丢失问题。其次,本发明方法将各层神经网络的隐层输出向量做为单层神经网络的输入,从而较全面的利用到了sae提取的非线性特征。最后,在接下来的具体实施案例中,通过实验结果的对比验证了本发明方法的优越性。
附图说明
图1为本发明方法的实施流程示意图。
图2为脱丁烷塔的组成结构示意图
图3为本发明方法中sae的结构示意图。
图4为本发明方法与其他方法在监测脱丁烷塔底部产品丁烷浓度的结果对比。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
如图1所示,本发明公开了一种基于sae的脱丁烷塔底部产品丁烷浓度实时监测方法,下面结合一个具体应用实例来说明本发明方法的具体实施方式。
如图2所示,脱丁烷塔过程系统组成包括:塔顶部冷凝器,热交换器,塔顶部回流泵,塔底部再沸器,回流储液器,和进料泵。
首先,利用1000个样本数据离线训练软测量模型,具体包括如下所示步骤(1)至步骤(7)。
步骤(1):利用丁烷塔设备中安装的7个测量仪表实时测量过程变量数据,直至采集得到n=1000个样本数据,分别记录成7个列向量x1,x2,…,x7,并利用离线分析仪获取相同测量时刻塔底部产品丁烷含量的n个数据,对应记录成列向量y,其中xi由第i个过程变量的1000个样本数据组成,i∈{1,2,…,7}分别对应于塔顶部温度,塔顶部压力,回流流量,底部产品出口流量,第6层塔板温度,塔底部温度a和塔底部温度b。
步骤(2):根据前述公式①对x1,x2,…,x7和y分别实施归一化处理,对应得到7个数据向量
步骤(3):根据前述公式②组建输入矩阵z中的第k列输入向量zk∈r28×1。
步骤(4):搭建一个由m=3层自编码器串联组成的sae,其结构如图3所示,并确定各层自编码器的隐层神经元个数为h1,h2,h3、隐层神经元激活函数f(u)为sigmoid函数,和输出层神经元激活函数ζ(u)为双曲正切函数。
步骤(5):根据上述步骤(5.1)至步骤(5.6),利用bp算法依次训练栈式自编码器中第1层自编码器,第2层自编码器,直至第m层自编码器的隐层和输出层的权重系数w1,w2,…,wm和
值得指出的是,利用bp算法训练自编码器的权重系数和阈值时,需要确定相应的目标函数;以第m层的自编码器为例,其目标函数为:
其中,gj(m)的计算方式如前述公式③所示,
步骤(6):搭建一个只有输入层与输出层的单层神经网络,其中输入层包含h=h1+h2+…+hm个神经元,输出层包含1个神经元,输出层的激活函数为φ(u);
步骤(7):将矩阵g1,g2,…,gm合并成一个矩阵g=[g1,g2,…,gm]t后,将矩阵g∈rh×n中的n个列向量做为单层神经网络的输入,将
至此,离线的软测量建模阶段完成,接下来就是利用在线实时测量的7个流量数据软测量得到塔底部丁烷浓度的在线监测值,具体包括如下所示步骤(8)至步骤(13)。
步骤(8):在最新采样时刻t,对7个采样数据v1(t),v2(t),…,v7(t)进行归一化处理,得到归一化后的数据
步骤(9):根据at=[v(t),v(t-1),v(t-2),v(t-3)]t组建最新采样时刻的输入向量at,其中,行向量
步骤(10):按照前述步骤(10.1)至步骤(10.3),以输入向量at做为栈式自编码器的输入,依次计算得到第1层自编码器,第2层自编码器,直至第m层自编码器的隐层输出向量ct(1),ct(2),…,ct(m)。
步骤(11):将隐层输出向量ct(1),ct(2),…,ct(m)合并成一个列向量ct∈rh×1后,将ct做为单层神经网络的输入,并根据公式
步骤(12):根据
步骤(13):返回步骤(8),继续实施对下一个最新采样时刻的脱丁烷塔底部产品丁烷浓度的实时监测。
用1380个在线采样时刻的数据进行测试,在这1380个在线采样数据的采样时刻同时实际测量丁烷塔底部产品丁烷浓度数据,从而可以通过在线监测值与实际测量值之间的差异来判断不同方法的优劣。在图4中,对比分析了三类方法对丁烷塔底部产品丁烷浓度的在线监测。从图4中可以发现,本发明方法得到的在线监测值与实际测量值之间的差异最小,这充分说明了本发明方法的优势。
上述实施案例只用来解释说明本发明的具体实施,而不是对本发明进行限制。在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!