一种低复杂度的极化码递进式比特翻转SC译码方法与流程
本发明涉及一种极化码的译码方法,尤其涉及一种低复杂度的极化码递进式比特翻转sc译码方法,属于信道编解码
技术领域:
。
背景技术:
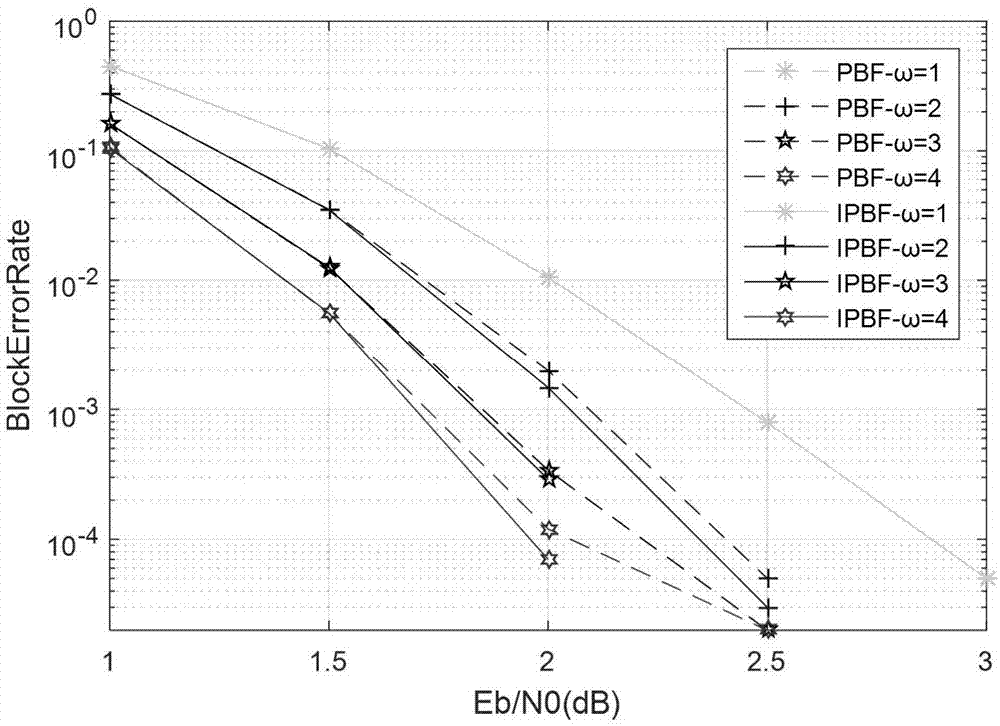
:极化码于2008年由arikan在国际信息论isit会议上首次提出,是唯一一种被严格证明可以达到信道容量的编码方式。目前极化码所能达到的纠错性能超过了广泛使用的turbo码、ldpc码。2016年11月18日,在美国内华达州里诺举办的3gppran1#87次会议上,经过与会公司代表多轮技术讨论,国际移动通信标准化组织3gpp最终确定了5gembb(增强移动宽带)场景的信道编码技术方案,其中,极化码被选为控制信道的编码方案。串行抵消sc算法和置信度传播bp算法是极化码译码的两大经典算法。sc译码算法计算复杂度低,但对于中短码长的极化码来说,sc算法的译码效果并不理想。bp算法较sc算法来说,在译码效果方面具有一定的优越性,但是其译码过程需要大量的迭代处理,具有很高的计算复杂度。串行抵消列表sclist系列的算法作为sc算法的改进,使得极化码的译码效果得到大幅提升,其列表list规模越大译码效果越好,但是需要付出更高的计算复杂度和存储器消耗作为代价,因此,在实际应用中得到限制。加入提前终止迭代策略的bp算法,虽然能够在一定程度上减少迭代次数、降低计算复杂度,但是在译码效果方面与sclist类算法相比,仍具有一定的差距。最近提出的递进式比特翻转sc算法,是利用sc算法进行多次重复译码尝试,以纠正首次sc译码结果中的出现的译码错误。递进式比特翻转sc算法的译码效果可与sclist系列中译码效果最好的算法相媲美,并且其硬件复杂度仅相当于sc算法的硬件复杂度,但是它由于在译码过程中需要多次调用sc算法进行重复译码,因此在计算复杂度和译码延迟方面具有短板。技术实现要素:基于以上技术所存在的弊端,本发明提供了一种低复杂度的极化码递进式比特翻转sc译码方法,通过在编码时加入crc校验,译码时,使用错误定位策略构建错误比特位置集合,翻转错误比特集合,使用sc译码算法进行递进式比特翻转译码尝试,并使用错误比特组合删减策略,减少sc重复译码的次数,降低其计算复杂度,具体步骤如下:(1)加入crc校验的极化码编程过程:(1a)给定码长为n=2n极化码,其中n≥1,选取k≤n个信息位比特,其余n-k个为固定位比特;选取码长为r的crc校验比特,则信息比特序列的有效信息长度为k-r;(1b)输入k-r个信息比特,并进行crc校验加入r位校验比特,组成码长为k的信息比特序列;(1c)将码长为k的信息比特序列与n-k个固定比特混合,构成码长为n的原始发送信息序列(1d)编码器对加入crc校验的原始发送信息序列进行极化码编码得到编码序列并经信道传输,在接收端接收到待译码信息序列(2)采用低复杂度的递进式比特翻转sc方法译码的过程:(2a)计算接收到的待译码信息序列的对数似然比并初始化sc译码器;(2b)执行首次sc译码过程,并对首次译码结果序列进行crc校验,若通过校验,则判定译码成功,并输出译码结果;如果校验失败,则执行步骤(2c);(2c)根据首次sc译码结果序列信息比特的对数似然比l(ui),利用错误比特位置定位策略,构建第一个错误比特集合;(2d)查看第一个错误比特集合内所有元素是否都被翻转并进行过sc译码尝试,如果没有,则执行步骤(2e),否则执行步骤(2f);(2e)依次翻转集合内元素进行sc译码尝试,来纠正第一个错误比特,并对每次译码尝试的译码结果进行crc校验,若通过了校验,则判定译码成功,并输出译码结果,否则,转至步骤(2d);(2f)根据错误比特定位策略,构建第flip_time个错误比特集合,构建包含flip_time个错误比特的翻转组合,并使用错误比特组合删减策略减少错误比特翻转组合的数量;(2g)查看所有由flip_time个元素组成的错误比特翻转组合是否都被翻转并进行过sc译码尝试,如果没有,则执行步骤(2h),否则执行步骤(2i);(2h)依次翻转包含flip_time个错误比特的翻转组合进行sc译码尝试,来纠正flip_time个错误比特,并对每次译码尝试的译码结果进行crc校验,若校验失败,则转至步骤(2g),否则,判定译码成功,并输出译码结果;(2i)查看flip_time是否小于max_flip_times,如果满足条件就令flip_time值增加1,接着执行步骤(2f),否则,判定译码失败,结束整个译码过程。进一步地,所述步骤(2c)中错误比特位置定位策略如下:根据首次sc译码结果序列信息比特的对数似然比l(ui)和设定的阈值l_threshold,将所有对数似然比绝对值|l(ui)|小于阈值l_threshold的译码结果序列的信息比特位置作为可供选择的出现译码错误的信息比特,并构建错误比特位置集合。进一步地,所述步骤(2f)中错误比特翻转组合如下:设定最多能够纠正首次sc译码结果中的max_flip_times个错误比特,flip_time表示在当前译码尝试过程要纠正flip_time个错误比特;当要纠正2≤flip_time≤max_flip_times个错误比特时,所对应的错误比特翻转组合由flip_time个比特翻转位置组成,所述flip_time个翻转位置分别是flip_time个错误比特集合中的元素。进一步地,所述步骤(2f)中错误比特组合删减策略如下:当flip_time个元素的所有组合翻转译码尝试均失败时,根据当前译码尝试的结果,使用删减策略,删除部分错误比特组合,以减少flip_time递增之后错误比特组合的数量,进而减少翻转译码尝试的次数。进一步地,所述阈值l_threshold是通过不同信噪比下由噪声引起的译码错误的信息比特的对数似然比l(ui)分布规律而确定的。进一步地,所述步骤(2f)根据当前flip_time个元素的所有错误比特组合翻转译码尝试的结果,求得每次译码尝试的信息序列所有信息比特的对数似然比绝对值|l(ui)|之和sum_l,并求出其最大值max_sum_l,以及首次sc译码尝试的sum_l为pri_sum_l;设定阈值sum_l_threshold、缩放因子α和β;sum_l_threshold=max{α*max_sum_l,β*pri_sum_l},并将满足sum_l<sum_l_threshold的翻转译码尝试所对应的flip_time个元素的组合删除。进一步地,所述缩放因子α根据不同信噪比数据仿真统计结果取值,对于码长1024的极化码,取值范围为{α|0.78≤α≤0.94}。进一步地,所述缩放因子β根据不同信噪比数据仿真统计结果取值,对于码长1024的极化码,取值范围为{β|0.97≤β≤1.03}本发明提供的改进的递进式比特翻转sc译码算法与原始递进式比特翻转sc译码算法相比,没有任何译码性能损失,利用有效的错误比特定位策略和错误比特组合删减策略,可有效减少译码过程重复调用sc进行译码尝试的次数,显著的降低了译码的计算复杂度和译码延迟。附图说明图1是码长为16的sc译码树结构图;图2是sc译码树的基本单元;图3是本发明递进式比特翻转sc译码方法的流程示意图;图4是本发明方法与传统递进式比特翻转译码方法的译码性能比较;图5是本发明方法与传统递进式比特翻转译码方法的译码复杂度比较。具体实施方式下面结合附图对本发明的技术方案进行详细说明:极化码的sc译码算法的译码树结构如图1(以码长为16的极化码为例)所示,译码树最底层叶子节点对应极化码位置信息,图1中标号从0到15的叶子节点表示码长为16的极化码,其中白色圆圈表示固定位节点,黑色节点表示信息位节点。开始译码时,将经过信道传输接收的待译码序列的对数似然比序列传递给译码树的根节点。图2为sc译码树的基本译码单元,其中节点vp表示节点v的父节点,节点vl和vr分别表示节点v的左右孩子节点。当节点v被激活时,它利用父节点vp向其传递的一个对数似然比序列αv,使用迭代公式(1)计算出一个对数似然比序列αl,并将αl传递给她的左孩子节点vl。如果节点vl不是叶子节点,则激活节点vl,继续根据迭代公式(1)做运算,直到左孩子节点为叶子节点为止。如果节点vl是叶子节点,则对对数似然比序列αl做硬判决,计算出分量码βl,并将βl向上传递给它的父节点v,然后根据迭代公式(2),计算出对数似然比序列αr,并将αr传递给节点v的右孩子节点vr。如果节点vr是叶子节点,则对对数似然比序列αr做硬判决,计算出分量码βr,并将βr向上传递给它的父节点v。进一步,根据迭代公式(3),计算出分量码序列βv,并将βv向上传递给节点vp。如果节点vr不是叶子节点,则激活节点vr,如同节点v那样继续做迭代运算,直到最后一个叶子节点的分量码被计算出来。最后将所有叶子节点的分量码组合起来,就是最终的极化码译码结果。以上就是传统sc译码算法译码过程。本发明使用错误比特定位策略构建错误比特集合,然后翻转集合内的错误比特进行sc译码尝试,以纠正首次sc译码结果中的错误比特;并在不造成译码效果损失的情况下,采用错误比特组合删减策略减小译码过程中sc重复译码的次数;与传统递进式比特翻转sc算法相比,本发明可有效降低译码的计算复杂度和译码延迟。本发明使用的错误比特位置定位策略如下:根据首次sc译码结果序列信息比特的对数似然比l(ui)和设定的阈值l_threshold,将所有对数似然比绝对值|l(ui)|小于阈值l_threshold的译码结果序列的信息比特位置作为可供选择的出现译码错误的信息比特,并构建错误比特位置集合。进一步地,所述阈值lthreshold是通过不同信噪比下由噪声引起的译码错误的信息比特的对数似然比l(ui)分布规律而确定的。本发明的错误比特位置集合构建过程如下:①获取编码数据,选取某一信噪比下若干帧编码数据,包括原始发送信息序列和待译码信息序列的对数似然比序列②使用sc译码,将对数似然比序列输入sc译码器进行译码,得到译码结果序列③找出第一个错误比特,将译码结果序列与原始发送序列进行逐字对比,找出第一个错误比特err_ui,并得到其对应的对数似然比l(err_ui);④确定阈值,取所有数据中的第一个错误比特的对数似然比绝对值组成的序列的最大值作为阈值l_threshold,即l_threshold=max{|l1(ui)|,|l2(ui)|,|l3(ui)|,......,|ln(ui)|}⑤构建错误比特集合s,将满足|l(ui)|<l_threshold的信息比特加入到集合s中,即s={i||l(ui)|<l_threshold}对于第二、第三个等错误比特的位置集合构建,也类似于上述第一个错误比特位置集合的构建过程。设定最多能够纠正首次sc译码结果中的max_flip_times个错误比特,flip_time表示在当前译码尝试过程要纠正flip_time个错误比特。当要纠正2≤flip_time≤max_flip_times个错误比特时,所对应的错误比特翻转组合由flip_time个比特翻转位置组成,这flip_time个翻转位置分别是flip_time个错误比特集合中的元素。进一步,当flip_time个元素的所有组合翻转译码尝试均失败时,根据当前译码尝试的结果,使用错误比特组合删减策略,删除不太可能的错误比特组合,以减少flip_time递增之后错误比特组合的数量,进而减少翻转译码尝试的次数,错误比特组合删减过程如下:①根据当前flip_time个元素的所有错误比特组合翻转译码尝试的结果,求得每次译码尝试的信息序列所有信息比特的对数似然比绝对值|l(ui)|之和sum_l,即②求出所有译码尝试结果所对应的sum_l的最大值max_sum_l,即③设定阈值sum_l_threshold、缩放因子α和β。其中,sum_l_threshold=max{α*max_sum_l,β*pri_sum_l}。缩放因子α根据不同信噪比数据仿真统计结果优化,对于码长1024的极化码,其取值范围为{α|0.88≤α≤0.95},缩放因子β根据不同信噪比数据仿真统计结果优化,对于码长1024的极化码,其取值范围为{β|0.97≤β≤1.03}。④将满足sum_l<sum_l_threshold的翻转译码尝试所对应的flip_time个元素的组合删除,在flip_time值增加1之后,基于这些删除的错误比特组合扩展的错误比特组合的译码尝试就会被避免。下面以码长n=1024,信息位k=512为例,说明本发明的译码流程。选定用于校验信息比特序列的crc校验码长度r=24,则信息比特序列的有效信息长度为488,信息比特序列经过crc校验之后添加24位校验比特,构成码长为512的信息比特序列。然后与n-k=512个固定位比特混合得到原始发送序列再经过极化码编码得到编码信息序列最后经过信道传输,在接收端收到待译码信息序列计算待译码信息序列的对数似然比得到序列按照位置信息构建码长为1024的sc译码树,设定最多纠正首次sc译码结果中错误比特数量max_flip_times=4,将对数似然比序列传递给译码树的根节点,作为根节点的对数似然比序列启动sc译码程序。当译码树最后一个叶子节点的分量码β值被计算出来之后,将所有叶子节点的分量码β值按节点标号组合成译码结果序列。对译码结果序列进行crc校验,如果校验成功,则直接将其作为译码结果输出,结束整个译码过程。如果校验失败,则启动错误比特定位策略,构建第一个错误比特位置集合。令flip_time=1,翻转错误比特位置集合中的第一个元素,再次使用sc进行译码,得到另一个译码结果序列,再次使用crc校验此译码结果序列,若校验成功,则将其作为译码结果输出,结束译码工作。若校验失败,则类似的,依次翻转错误比特位置集合的第二、第三等其他元素进行译码尝试,并使用crc校验其译码结果,一旦某次译码尝试的结果通过了crc校验,就将其作为译码结果输出,结束译码工作。如果翻转集合的最后一个元素的译码尝试仍然失败的话,令flip_time值增加1,即flip_time=2,构建第二个错误比特位置集合,并根据第一、第二个错误比特位置集合构建由两个元素组成的错误比特翻转组合,然后使用错误比特组合删减策略,根据flip_time=1时的所有译码尝试结果,删除不太可能的错误比特组合,对剩余的由两个元素构成的错误比特组合依次进行翻转,并使用sc进行译码尝试。译码尝试期间,一旦某次译码尝试的结果通过了crc校验,就将其作为译码结果输出,结束译码工作。如果所有由两个元素构成的错误比特组合的翻转译码尝试都失败,则令flip_time值增加1,即flip_time=3,如同flip_time=2那样,继续构建第三个错误比特位置集合,然后组建有三个元素的错误比特组合并进行翻转译码尝试。直至flip_time=max_flip_times时的所有错误比特组合的翻转译码尝试失败,判定译码失败,结束译码程序。本发明方法的基本流程如图3所示。图4显示了本发明方法与传统递进式比特翻转译码方法在高斯加性白噪声信道中的测试结果。极化码码长为1024,信息位为512位,使用24位的crc校验。图中横坐标eb/no为信噪比,纵坐标blockerrorrate为误块率。图例中ipbf表示本发明提出的递进式比特翻转sc译码方法,pbf表示传统递进式比特翻转译码方法,ω表示纠正的错误比特位数。根据图4可看出,相对于传统递进式比特翻转译码方法,本发明的译码性能不仅没有任何损失,而且还有一定程度的提升。图5显示了本发明方法与传统递进式比特翻转译码方法在不同信噪比信道中的平均译码复杂度,其中极化码码长为1024,信息位数为512,crc校验位数为24。图中eb/no为信噪比,averagedecodingcomplexity表示平均译码复杂度。可以看出,本发明方法的平均译码复杂度明显低于传统递进式比特翻转译码方法的译码复杂度。对于码长为1024,信息位为512的极化码,本发明提出的错误比特定位策略与传统递进式比特翻转算法提出的第一个错误比特集合大小对比下表所示:信噪比(db)1.01.52.02.53.0传统递进式比特翻转算法110112117124129本发明提出的策略171.5116.760.930.15.9由表中数据可见,在中高信噪比下,本发明中提出的错误比特定位策略确定的集合大小显著小于原始递进式比特翻转算法所确定的集合。以上对发明所提供的方法,进行了详细的介绍,并应用具体实施例对本发明的原理及实施进行了阐述,用于帮助理解本发明的方法及其核心思想,但并非用于限定本发明,本
技术领域:
的技术人员依据本发明的思想,做出的均等变换与改变等,均包括在本发明的专利保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1