用于现场可编程门阵列的定向二维路由器和互连网络、以及所述路由器和网络的其他电路和应用的制作方法
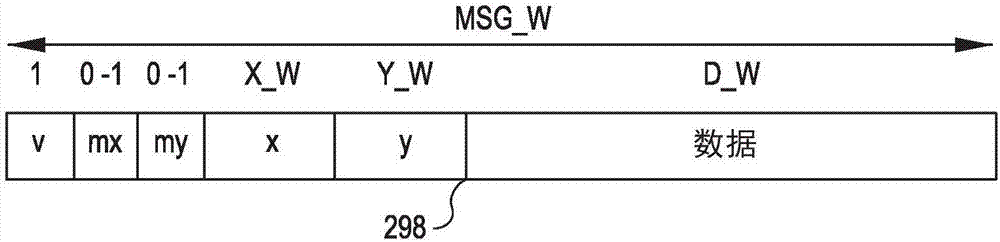
本公开总体上涉及电子电路,并且更具体地涉及例如互连网络设计、现场可编程门阵列(fpga)设计、计算机架构以及电子设计自动化工具。相关技术本公开涉及片上网络(“noc”)互连网络的设计和实施方式以用于在fpga中以可编程逻辑进行高效实施。随着fpga容量的增长并添加对许多非常高带宽接口和输入/输出(i/o)通道的支持,并且在同一集成片上系统(soc)上主控更多的客户端核,在可编程逻辑中,可行的、可扩展的、高效互连网络中实现使得高速数据可以在许多客户核与外部接口核之间和之中以全带宽(即,能够以源核(电路)可以产生的或目的地核可以消耗的最大数据速率传送数据)流动是一项困难挑战。例如,fpga可以直接附接至八个通道的双倍数据速率4(ddr4)动态随机存取存储器(dram)、八个通道的高带宽(hbm)[8]dram存储器、或十六个通道的混合存储器立方体(hmc)[9]dram存储器,每个通道能够以每秒100千兆位至每秒250千兆位(gbps)的速度读取或写入数据。另外,fpga可以直接附接至四到十六通道的25-100gbps以太网接口。大型fpga(soc)系统设计可以采用互连网络系统在fpga上的任何客户端核点与fpga上的任何dram通道接口核或网络接口核之中或之间以全带宽传输所有这些数据流。至今,对fpganoc设计的现有技术研究已经产生了复杂的fpganoc系统,这些系统在其递送的有限带宽内消耗大量fpga资源,并且因为报文穿过跨网络的路由器而相对较慢。现有技术noc规模相对较小(例如,客户端数量少于十个),链路带宽相对较低(窄链路),并且路由延迟相对较高。例如,最近由fpga研究人员广泛使用并在同行评审的fpga会议上呈现的关于在fpga中实现的最先进的noc路由器的优化状态的cmuconnect[4]研究,针对38000个6输入查找表(lut)的部件“成本”实现了具有64位链路的16客户端、16路由器、4×4经缓冲虚拟通道(vc)路由器(每个路由器间链路每个时钟周期内传输64位),其中,通过一个connect路由器的最小延迟为11纳秒(ns)。类似地,fpga设计了组成数十个客户端核来彼此互连并且与多个高带宽数据通道互连,而不论随机存取存储器(ram)、flash、10g/25g/40g/100g网络、64gbpspciexpressgen3x8、infiniband、4k/8k(超高清)视频流数据等都不具有实用的现有技术解决方案来在fpga中实现这样的全带宽在noc上观看(seeabovenoc)。对于fpga系统设计的另一项挑战是当一些报文具有较高扇出时支持客户端核互连到大规模并行系统中,例如,希望将一些报文的副本发送到许多目的地客户端核,但是发送如此多的单独报文是禁止的。已经针对其他域提出了组播报文(这些组播报文中的每一个被同时或接近同时地递送至多个客户端核),但是不存在用于可以并发地递送任意点对点报文和高扇出x组播报文、y组播报文和xy组播(广播)报文两者的任何混合的fpganoc系统的现有技术。noc和fpga特定noc设计中的相关技术关于2d环面网络设计的文献[3]假设针对asic和针对在重负荷下的高吞吐量进行优化的拓扑和路由器微架构。使用报文分段为/重组自流控制数位(flits)、输入缓冲区、虚拟通道、流控制信用以及5端口交叉开关来将北(n)/南(s)/东(e)/西(w)输入微片路由到n/s/e/w/输出链路,教科书环面路由器可处理系统设计挑战,诸如可变报文大小(64位请求对576位响应)、优先级、公平性和无死锁。这类noc实现了良好的吞吐量和延迟,代价是设计复杂度和每个路由器的延迟和面积。对于一些基于fpga的系统和工作负荷,这类设计不必要地大、复杂或慢。这种路由器核所需的数百或数千个fpgalut可以使所述路由器的客户端计算核(“客户端”)的面积变矮。noc的目的是高效地互连客户端核。如果fpgasoc太多的fpga资源或者太多的系统功率预算专用于noc,则fpgasoc可能不可行或不实用。被实施具有5端口经缓冲虚拟通道(vc)路由器的2d环面noc[3]非常大,并且消耗许多fpga资源。聚焦于路由器的数据路径,可以看出,假设w个双端口lutram用于输入缓冲区(跨vc共享)并且2w个lut用于w位5×5交叉开关,则w位的链路/微片宽度的最小fpga面积为5(w+2w)=15w个lut。而且,缓冲区lutram可以是一种资源约束:例如,在由赛灵思(xilinx)制造并销售的现代fpga中,只有25%至50%的lut实现了lutram(并且客户端核经常使用它)。现有路由器控制逻辑(用于控制路由器数据路径)同样是资源密集型的,通常对于每个vc需要缓冲区先入先出(fifo)地址计数器和信用流控制计数器。路由函数和输出分配器占用更多的lut。在connect[4]工作中,papamichael和hoe测量了具有“高质量”、“最先进状态的”noc路由器[5]的总fpga面积。尽管针对fpga实施方式调整了作为硬件定义语言的寄存器传递语言(rtl)的实施方式,并且选择设计参数以使面积最小化,但是路由器仍然巨大:约3000个lut(w=32,4个vc)至约5200个lut(w=128,4个vc)。而且,这种路由器逻辑不考虑客户端核的复杂noc接口。如果报文被分段成微片,则客户端可能需要重组来自组成传入报文的交织微片的多个传入报文。针对面积高效的fpga实现,connect工作[4]检验vc路由器微架构。其推荐浅层或不使用流水线以及较宽的链路宽度。并且其提供了“虚拟链路”选项来简化客户端接口。这些见解产生了更紧凑的路由器,需要约1500个lut(w=32,5端口,2个vc,4个微片缓冲/vc)——但是对于许多fpgasoc应用而言,这仍然是非常资源密集型的。kim[6]评估了用于asic的面积高效的2d环面路由器设计,采用维度次序路由、维度分割交叉开关、除了在维度之间的有限路由器缓冲和经修改的信用流控制。在此设计中的每个路由器处于双向x环和y环的交叉处。数据包在第一维(x)中被路由,直到所述数据包到达具有匹配x坐标的路由器。然后,所述数据包进入路由到其横穿的y环的fifo缓冲区,直到所述数据包到达目的地(x,y)路由器并退出网络。维度分割路由器数据路径使用两个3×3交叉开关而不使用5×5交叉开关。链路仲裁优先于已经在飞行中的数据包。如本文中其他地方所公开的,这些技术帮助减小路由器的一些不必要的复杂度、延迟以及资源使用,但是其中的缺点为:工作未考虑fpga实现或优化,未消除网络中的缓冲区,未尽可能地简化交换,并且不会尽可能地优化其他路由器逻辑。moscibroda和mutlu[7]评估了用于asic的快速且面积高效的无缓冲5端口2d环面路由器设计,其在输出链路争用上采用偏转路由。延迟是非常好的,但是只有当网络利用率较低(较低的注入率)时。作者指出:“对于更大的流量,移除缓冲区的根本作用是减少网络中的总可用带宽”,并且他们探索各种路由函数来减轻这个缺陷。这里再一次,关于无缓冲路由器的这项工作与经缓冲vc路由器相比实现了改进的面积和能量效率,但是其同样没有考虑fpga实现或优化,并且采用了更加资源密集的双向链路的2d环面以及包括5×5纵横式交换机的路由器交换机。参考文献[1]阿尔特拉公司,“arria10corefabricandgeneralpurposei/oshandbook(arria10核心结构和通用i/o手册)”,可从https://www.altera.com/enus/pdfs/literature/hb/arria-10/a10handbook.pdf中获得,2015年5月,[在线][2]赛灵思公司,“ultrascalearchitectureandproductoverview,ds890v2.0(ultrascale架构和产品概述,ds890v2.0)”,可从http://www.xilinx.com/support/documentation/datasheets/ds890-ultrascale-overview.pdf获得,2015年2月,[在线][3]w.dally和b.towles,principlesandpracticesofinterconnectionnetworks(互连网络的原理和实践),morgankaufmann,2004年。[4]m.k.papamichael和j.c.hoe,在纽约关于现场可编程门阵列的acm/sigda国际研讨会序列号fgpa12的论文集中的“connect:re-examiningconventionalwisdomfordesigningnocsinthecontextoffpgas(连接:重新审视fpga情境下设计noc的传统观点)”,可从http://doi.acm.org/10.1145/2145694.2145703获得,美国纽约,acm,2012年,第37-46页,[在线][5]斯坦福并发vlsi架构组,“opensourcenetwork-on-chiprouterrtl(开源片上网络路由器rtl)”,https://nocs.stanford.edu/cgibin/trac.cgi/wiki/resources/router。[6]j.kim,在2009年micro-42,第42届ieee/acm国际研讨会微架构中的“low-costroutermicroarchitectureforon-chipnetworks(用于片上网络的低成本路由器微架构)”2009年12月,第255-266页。[7]t.moscibroda和o.mutlu,在纽约关于计算机架构的第36届国际研讨会序列号isca09的论文集中的“acaseforbufferlessroutinginon-chipnetworks(片上网络中无缓冲路由的案例)”,可从http://doi.acm.org/10.1145/1555754.1555781获得,美国纽约:acm,2009年,第196-207页,[在线][8]jedec,“highbandwidthmemory(hbm)dramspecification(高带宽存储器(hbm)dram规范)”,jesd235,http://www.jedec.org/standards-documents/results/jesd235[9]混合存储器立方体联盟,“hybridmemorycubespecification1.0(混合存储器立方体规范1.0)”,http://hybridmemorycube.org/files/sitedownloads/hmc_specification%201_0.pdf技术实现要素:与现有技术noc系统相比,本文中所公开的“hoplite”路由器和hoplitenoc系统的实施例在只有1230个6-lut中实现了64位宽4×4定向环面偏转路由器,其中,每个路由器的延迟仅为2ns到3ns。虽然connect和hoplitenoc的实施例两者都提供了互连在noc中的所有客户端核的服务,并且在此示例中将64位报文从任何客户端递送至任何其他客户端,但是hoplitenoc系统的实施例针对这个应用的效率超过了一百倍(表示为面积和延迟比的乘积)——即,(38,000个lut×11ns)/(1230个lut×2.5ns)等于135,更好的面积×延时的乘积。hoplite路由器和noc的实施例在其fpga资源使用上如此节省,使得它们能够实现实用且成本效益的具有极宽的高带宽链路的附接至许多高速接口的大型noc。例如,在实施例中,用于以153gps带宽路由dram通道数据的50客户端、50路由器、10×5hoplite环面noc已经被设计用于在赛灵思xvu095设备中实现。每个链路非常宽(576位(网))(网是fpga中的可编程逻辑“导线”的名称),时钟周期是3.3ns(周期速率/频率为300mhz),每条链路的数据带宽为153gbps,并且在每个周期期间,跨fpga的50个客户端中的任何一个都可以向/从包括dram通道控制器客户端的其他客户端发送和接收576位报文。这种实现方式只使用了5%的fpga裸片面积,为客户端内核留下了丰富的资源。hoplite路由器和noc的实施例可以被配置用于实现x组播、y组播和xy组播报文递送,并且从不同客户端发送的普通报文和组播报文可以并发地横穿网络。hoplite路由器和noc的实施例以及本公开的其他实施例的许多特征包括而不限于:1)一种定向环面拓扑和偏转路由系统;2)一种定向2d无缓冲偏转路由器;3)一种五端子(3报文入、2报文出)报文路由器交换机;4)在每个链路宽度位每个路由器仅消耗一个alm或6-lut的阿尔特拉8输入可拆分lutalm(“自适应逻辑模块”)[1](由阿尔特拉制造并销售)技术和赛灵思6-lut[2]fpga技术中的路由器交换机元件的经优化拓扑映射;5)一种具有路由控制电路和报文交换电路的路由器设计,所述报文交换电路在上游路由器输出寄存器与路由器交换机元件之间引发零lut延时(fpga可编程逻辑门延时);6)一种具有路由控制电路和报文交换电路的路由器设计,所述报文交换电路在上游路由器输出寄存器与路由器输出寄存器之间引发少至一个lut延时7)一种具有可配置和灵活的路由器、链路和noc的系统;8)一种noc,在所述noc中可重新配置路由函数;9)一种noc,具有易变的报文元数据;10)一种noc,具有可配置组播报文递送支持;11)一种noc客户端接口,支持每个周期的原子报文发送和接收,具有noc和客户端流控制;12)一种可配置的noc平面规划系统;13)一种noc配置规范语言;14)一种noc生成工具,用于根据noc配置规范生成工作负荷特定noc设计,包括而不限于可合成的硬件定义语言代码、仿真测试平台、fpga平面布局约束、fpga实现约束以及文档。15)如下文中描述的noc的各种应用。在阿尔特拉fpga和赛灵思fpga的实施例中,hoplite路由器核及其组成子模块以及fpga配置如此极其高效以至于其fpga资源消耗实现了提供同一功能的电路的理论最低下限。在hoplite路由器的实施例的设计以及将hoplite路由器组合成hoplitenoc的实施例中,传统的环面路由器设计正统被拒绝,环路路由器设计被重新思考,并且新的环面路由器设计范例从“地面(thegroundup)”发展。hoplite的实施例采用了新颖的网络拓扑结构、客户端接口、原子报文发送、模块化可配置路由函数和路由器功能、微架构、fpga技术映射和节能、fpga可配置性、设计自动化工具以及其他创新,以实现每个hoplite路由器仅消耗大约10+w个lut(其中,w是链路宽度,例如,在路由器之间或客户端与路由器之间的“链路”中的导线数量,如以上所描述的)的noc路由器设计。因此,hoplitenoc的实施例通常占用小于传统noc的面积(除了由noc客户端所占用的面积之外)的十分之一的面积。与传统路由器和noc相比,hoplite路由器和noc的实施例包括以下特征中的一个或多个:单向而非双向链路、共享(重新目的化)noc链路的输出链路、被设计用于单向环面维度次序路由的交换机数据路径传递函数、无缓冲区、客户端或路由器中无虚拟通道、无信用流控制、无报文分段或重组、原子报文/周期客户端接口、可配置超宽链路、可配置路由函数、可配置组播支持、可配置的每客户端输入报文省略、可配置(0-n)链路流水线寄存器、可配置交换能量减少、fpga面积高效技术映射和平面规划的数据路径(数量级更小);更低的交换延迟以及更低的空载延迟。这些设计要素和本文中所公开的其他要素的实施例与之前的工作形成鲜明对比。例如,[4]中的torus16网络是64位微片5端口2-vc路由器的4×4环面,消耗150,720lutxc6vlx240t赛灵思设备的25%(例如约38,000个lut),并且具有11ns的路由器延迟。相比之下,包括64位报文hoplite路由器的折叠4×4定向环面的hoplitenoc的实施例消耗1230个lut并且具有小于3ns的路由器延迟。这里,对于使用不会使noc饱和的中等报文注入速率的工作负荷,hoplitenoc系统的实施例消耗小于之前工作的3%的资源,并且比之前快了超过三倍!系统的实施例包括可配置hoplite路由器和noc硬件设计、以及用于从基于文本的noc规范中生成noc电路设计的配置工具。hoplite路由器的实施例是2d无缓冲偏转路由器,具有被设计用于在基于阿尔特拉alm的fpga和基于赛灵思6-lut的fpga中实现的路由电路和交换电路。hoplitenoc的实施例是用于形成定向2d环面的多个hoplite路由器和链路的组合。片上系统设计可以采用具有不同配置参数的多个noc以便按照应用或工作负荷特性来定制所述设计。hoplite使能实现通过高带宽链路互连数百个客户端的大型noc的可行fpga,包括计算和加速器核、dram通道、pciexpress通道以及10g/25g/40g/100g网络。附图说明图1是集成计算设备100的实施例的简图,所述集成计算设备包括:以fpga102实现的soc;网络接口106;pciexpress接口114;经耦合的pciexpress主机110和外围设备112;以及dram120。fpgasoc102包括多个客户端核,所述客户端核包括接口核140、142、144和用户核170、172。fpgasoc102进一步包括hoplitenoc150、152。noc150互连在4×42d定向环面中的各种客户端核。noc150包括路由器160、162以及第一维(“x”)单向环链路164和第二维(“y”)单向环链路166。图2a是hoplitenoc报文298的实施例的简图。报文是包括第一维地址‘x’、第二维地址‘y’、数据有效载荷‘data’以及可选地其他信息(比如报文有效指示符)的多个位。图2b是hoplitenoc299的实施例的简图。noc299包括包含路由器200、201、202、203、210、212、220、222、230、232的2d路由器的4×4环面,这些路由器经由单向维度环240、242使客户端核290、291、292相互耦合,这些环包括单向链路260、252、256、256、260、262、264、266。路由器200包括报文输入、报文输出以及下文中所描述的路由器电路。路由器输入包括指定为xi和yi的两个维度报文输入。路由器输出包括指定为x和y的两个维度输出链路。路由器输入可以进一步包括指定为i的客户端核报文输入。客户端290通过与同一y环240中的下一个路由器200共享第二维y输出链路256而从路由器203中接收输出。路由器203可以具有向noc299中发送和接收报文的客户端290,或者路由器212可以具有仅从noc299中接收报文的仅输出客户端291,或者路由器222可以具有仅向noc299中输入报文的仅输入客户端292,或者路由器202可以不与任何客户端直接连接。图3是noc299的实施例的子电路的简图,其包括耦合至一个客户端核390的一个路由器300。路由器300包括报文输入、报文输出、有效性输出、路由电路350和交换电路330。报文输入包括指定为xi的第一维报文输入302和指定为yi的第二维报文输入304。报文输入还可以包括指定为i的客户端输入306。报文输出包括指定为x的第一维报文输出310和指定为y的第二维报文输出312。有效性输出包括:x有效指示符行314,被配置用于承载指示x输出报文有效的信号;y有效指示符行316,被配置用于承载指示y输出报文有效的信号;输出有效指示符行318,被指定为o_v并且被配置用于承载指示y输出报文是有效客户端输出报文的信号;以及输入准备就绪指示符行320,被指定为i_rdy并且被配置用于承载指示此周期路由器300已经接受客户端核390的输入报文的信号。图4a至图4d是图3的交换电路330的可替代实施例的简图。图5a、图5b和图5c是图3的交换电路330的附加可替代实施例的简图。图5d和图5e分别是图3的交换电路330的阿尔特拉alm和赛灵思6-lutfpga的实施例。图5f是图5e一位宽交换元件的赛灵思实施后技术映射示意图的实施例的简图。图5g示出了图3的交换电路330的时间复用可替代实施例。图6是根据实施例的图3的路由电路350的操作的流程图。通常,由流程图(比如图6的流程图)描述的算法通过以可合成硬件描述语言(hdl)(比如,verilog)表示算法而被转换成形成路由电路350的电路系统。以下提供了路由电路350的实施例的verilog表示的示例。图7a至图7d是noc路由场景的若干代表性实施例的简图,展示了使用偏转维度次序路由和组播报文递送而从源客户端到目的地客户端跨环的逐跳报文传输。图7a是报文到自身(702)、在y环(704)上、在x环706上、在x环并且然后在y环708上、以及(利用偏转)在x环和y环上的普通点对点报文递送的简图。图7b是y环组播报文递送的简图,发送到客户端的家庭y环(722)以及发送到不同的y环(724)。图7c是x环组播递送的简图,发送到客户端的家庭x环(744)、发送到另一x环(742)以及(利用偏转)发送到x环(746)。并且图7d是报文广播到每个noc762中的客户端的递送的简图。图8a至图8c是两个所实现的具有大型平面规划hoplitenoc的赛灵思fpga设计的实施例的简图。图8a是如可以在大规模并行处理器或加速器阵列中采用的w=50位报文的18×24(432个路由器)折叠2d环面noc的平面布局图。图8b和图8c是如可以在高性能计算或网络加速器应用中采用的w=576位报文的5×10(50个路由器)折叠2d环面noc的平面布局图。图8b是在赛灵思kintexultrascaleku040设备中实现的50路由器noc设计的裸片图(平面布局打印输出)的照片;图8c是与图8b中相同设计的简图。在图8b和图8c的系统中的每条链路都承载180gps的数据带宽,足以向和从fpga中的任何点处的任何客户端核那里路由4到8个通道的2400mhzddr4dram存储器流量。图9a是来自图8b的设计的一个576位hoplite路由器核的技术映射和平面规划设计的实施例的简图。值得注意的是在此实施例中完全利用了大多数逻辑单元点。许多赛灵思逻辑集群(切片)(每个集群包括八个6-lut和16个触发器)填充有被配置用于计算寄存在16个触发器中的同一切片中的下一个x输出和y输出的16个位的八个6-lut。图9b是另一个fpganoc平面布局的实施例的简图,其是不具有用于客户端核的内部空间的密集型的,具有8×8(64个路由器)折叠2d环面,每个路由器具有w=256位链路,具有适合用于主控100gb/s以太网交换结构的2.2ns时钟周期(110gb/s带宽/链路)。八个网络接口核(nic)向/从noc中注入和接收报文。图10是在图8b的noc的实施例中的关键路径的赛灵思实施后技术映射电路表示的实施例的简图。图10的简图展示了整体hoplite路由器和noc设计实现的极端电路效率。在两个上游路由器的数据和有效输出触发器x[i]、x.v、y[i]、y.v与目的路由器的相应数据输出触发器x[i]、y[i]之间只有一个lut延时(门延时)。这个示例还展示了本文中所描述的输出多路复用器交换逻辑设计使能实现零门、零延时路由函数,其中,输出多路复用器的传递函数选择信号直接从上游路由器的输出有效信号中形成。图11和图12是示例性fpga计算系统的实施例的简图,其并入了结合图1至图10所描述的路由器、noc和整体互连网络系统的多个实施例之一。所述系统实现了大规模并行以太网路由器和数据包处理器。图11是fpga计算系统的计算设备1100的实施例的高层图,其中,计算设备1100包括以fpga1102实现的soc;网络接口1106;pciexpress接口1114;所连接的pciexpress主机1110;以及dram1120。fpga计算系统还包括hbmdram存储器1130,所述hbmdram存储器包括大量hbmdram通道1132以及多个多处理器加速器集群客户端核1180。图12是图11的fpga计算系统的一个多处理器集群分块的实施例的简图,其中,所述系统包括hoplite路由器1200,此路由器耦合至其相邻hoplite路由器(未示出)并且耦合至经加速的多处理器集群客户端核1210。示例性集群1210包括八个软处理器核1220,这八个软处理器核共享对集群ram(cram)1230的访问,所述集群ram(cram)进而连接至共享的加速器核1250并且连接至所述路由器1200以通过noc来发送和接收报文。在本文中所描述的示例性fpga计算系统中,所述系统总共包括五十个这种分块或四百个处理器。noc用于在集群之间、在集群与外部接口核(例如,用于加载或存储到外部dram)之间、以及直接在外部接口核之间承载数据。为了说明用于实践以上所描述的系统的实施例的示例减少,图13a至图13d是展示了这种系统及其noc的物理实现和平面规划的不同方面的四个裸片图的简图。图13a是根据实施例的fpgasoc整体的简图。图13a覆盖了fpga逻辑细分成50个集群的视图。图13b是根据实施例的在折叠2d环面中布置路由器+集群分块的分块的高级平面布局的简图。图13c是根据实施例的所述设计的明确放置的平面规划的元件的简图。图13d是对集群1210(图12)进行互连的noc的逻辑布局的简图。图14展示了在由fpga实现工具进行处理之后如何在fpga配置比特流文件中显现所公开的路由器、noc以及应用系统设计;如何将此文件存储在配置flash存储器或类似的计算机可读介质中;此配置比特流如何经由fpga的配置端口输送至fpga,并且然后输送至fpga的配置系统,以便内部加载比特流文件来配置设备的无数可编程逻辑元件和互连结构,从而实现所公开的路由器、noc以及应用系统。具体实施方式一种hoplitenoc促进各种数据报文在soc中的各种客户端核中的高效互连和传输。现在参照图1,根据实施例,系统100包括各种接口和功能,所述接口和功能在物理上通过fpgasoc102的i/o引脚和pcb迹线108、114、122通信地耦合,并且在功能上通过noc150通信地耦合。系统100包括耦合至网络phy(物理层)104的网络接口106,所述phy通过pcb迹线108耦合至以fpgasoc102实现的网络接口核140。系统100进一步包括耦合至以fpgasoc102实现的pciexpress接口核142的pciexpress接口核114。系统100进一步包括借助于pciexpress接口114耦合至fpgasoc102的主机计算系统110。系统100进一步包括耦合至fpgasoc102的pciexpress外围设备112。系统100进一步包括通过pcb迹线122耦合至以fpgasoc102实现的dram控制器核144的dram120。fpgasoc102进一步包括用户核170、172(指定为a到f)。fpgasoc102进一步包括noc150和152。noc150使各种接口核140、142和144与用户核170和172互连。用户核170(a)包括noc152及其子模块(虽然为了清晰起见,图1中被示出为与核a分离,但是noc152实际上是核a的一部分)。noc150包括路由器核160、162、第一维(“x”)单向环链路166以及第二维(“y”)单向环链路164。虽然本文中结合一个或多个实施例进行了具体描述,但是外部接口到网络、dram、和pciexpress的数量和类型、用户核的数量和类型、noc的数量和配置、noc维度等都旨在是说明性而非限制性的。因此,应当理解,可以根据本文中所描述的原理设想具有和不具有外部接口并且具有不同系统拓扑的用例的多样性。根据实施例,系统用例的以下示例展示了noc150的实用性和操作。概括地说,主机110向pciexpress接口核142发送命令,指示所述命令启动数据块从dram120到网络接口140的传递以供在网络106上传送。详细地,主机110通过pci接口114执行到接收命令的pciexpress接口142的pciexpress事务。pciexpress接口142格式化读取存储器请求报文以请求从dram控制器144到网络接口140的数据传递,并且经由路由器(3,3)、经由路由器(1,3)并经由noc150向dram控制器144发送报文。noc150经由路由器(2,3)并且有可能经由不同的x链路166将请求报文从路由器(1,3)传输到路由器(3,3)。dram控制器144接收来自路由器(3,3)的读取请求报文,从由读取请求报文指定的dram组120的地址处执行dram读取事务,并且从指定的dram地址处接收指定的数据块。dram控制器144格式化包括从dram组120中检索到的数据块的读取响应报文,并且经由路由器(0,3)发送报文,且经由路由器(3,3)并经由noc150发送至网络接口140。noc150借助于“回绕”x环的x链路将响应报文从路由器(3,3)传输至路由器(3,0),这里直接将路由器(3,3)x链路输出连接至路由器(0,3)x链路输入。网络接口140接收来自路由器(0,3)的报文,可选地生成包含从dram组120中检索到的数据的另一报文,并且经由phy104在接口106上采用以太网数据包的格式将所述数据传送出fpga。当然,上述是示例;因此,结合上述示例所描述的报文的数量、类型和序列和noc报文路由及传输动作,或者本文中的任何其他示例都旨在是说明性而非限制性的。图2a是根据实施例的hoplitenoc报文298的简图。报文是包括以下字段的多个位:第一维地址‘x’、第二维地址‘y’以及数据有效载荷‘data’。并且所述报文可以进一步包括有效性指示‘v’,其向路由器核指示在当前周期中报文有效。在可替代实施例中,这个指示符与报文不同。地址字段(x,y)与耦合至作为报文的预期目的地的客户端核的路由器的唯一二维目的地noc地址相对应。如果不需要的话,维度地址可能会退化(0位宽),以便可以由noc地址唯一地标识所有的路由器。并且在可替代实施例中,目的地地址可以以位的可替代表示来表示,例如,唯一的序数路由器号码,可以通过应用一些数学函数从所述序数路由器号码中获得作为报文的预期目的地的路由器的逻辑x坐标和y坐标。在另一可替代实施例中,目的地地址可以包括描述穿过noc的路由器到达目的地路由器所取的期望路由路径的位。总之,报文包括在所述报文横穿路由器的二维(或更多维)安排时足以判定所述报文是否仍然在驻留目的地路由器的y环处以及是否仍然在驻留目的地路由器的x环处的目的地路由器的描述。此外,如下文中所公开的,报文可以包括可选的、可配置的促进组播报文的递送的组播路由指示符“mx”和“my”。在实施例中,报文的每个字段都具有可配置位宽。路由器构建时间参数mcast、x_w、y_w和d_w选择报文的每个字段最小位宽并且确定整体报文宽度msg_w。在实施例中,noc链路250(图2b)具有足以在一个周期内传输msg_w位报文的最小位宽w。根据实施例,图2b是noc299的简图。noc299包括包含路由器200、201、202、203、210、212、220、222、230和232的2d路由器的4×4环面,所述路由器经由单向维度环240和242互连包括客户端核290、291和292的客户端核。在noc内,由维度坐标的唯一元组来标识路由器。在2dnoc中,不失一般性,这两个维度在此被指定为x和y。因此,路由器200具有noc地址x=0,y=0,也被指定为(0,0)。类似地,路由器212具有noc地址x=1,y=2或(1,2)。noc299进一步包括一组单向互连链路250、252、256、256、260、262、264和266,其形成单向维度环240和242。所述链路可以包括逻辑上并行的导线、导电迹线、一个或多个寄存器的流水线或任何多位通信耦合信道。所述链路承载具有图2a的报文298的结构的报文。在实施例中,所述链路原子地承载报文,意味着报文以其全部(即,以其所有位以其完整宽度)被直接从路由器传播到路由器(或者经由一个或多个链路流水线寄存器),使得所述报文不需要如在一些传统noc中发生的那样经历分割并重组组成数据包或微片。例如,如果报文是64位宽,则链路的实施例包括64条导线,每条导线针对报文的每个位。因此,报文的宽度以及因此noc中的每条链路的最小逻辑宽度是针对noc的每个实例具有不同值的参数w。根据实施例,noc299的路由器200包括报文输入、报文输出以及下文中所描述的路由器电路。路由器输入包括指定为xi和yi的两个维度报文输入。路由器输出包括指定为x和y的二个维度输出链路。并且路由器输入可以进一步包括指定为i的客户端核报文输入。与传统2d路由器相比,路由器200不具有专用的客户端报文输出端口。而是,客户端接收“客户端输出有效”指示符‘o_v’,所述客户端输出有效指示符指示在路由器的第二维报文输出y上到客户端的路由器输出是有效且可用的。在可替代实施例中,客户端可以在路由器的第一维报文输出x上接收来自路由器的由客户端输出有效指示符o_v验证的输出。在另一可替代实施例中,客户端可以在路由器的第一维报文输出x或路由器的第二维输出y上接收来自路由器的输出,每个报文输出由不同的客户端输出有效指示符ox_v和oy_v分别进行验证。(在此实施例中,客户端通信地耦合至第一维报文输出和第二维路由器报文输出。)具有相同y坐标的路由器子集被指定为x行。在实施例中,一组链路260、262、264和266对在完整单向经连接循环(被指定为x环)中的x行路由器进行互连。类似地,具有相同x坐标的路由器子集被指定为y列。在实施例中,一组链路250、252、254和256对在完整单向经连接循环(被指定为y环)中的y列路由器进行互连。在noc299中,存在指定为x环[y=0]、x环[y=1]、x环[y=2]、x环[y=3]的四个x环和指定为y环[x=0]、y环[x=1]、y环[x=2]、y环[x=3]的四个y环。例如,x环242[y=0]包括链路260、262、264和266,并且y环240[x=0]包括链路250、252、254和256。在实施例中,不是每个路由器都耦合至客户端,并且不是每个客户端都既向noc299发送报文又从所述noc中接收报文。例如,在位置(0,3)处的路由器203经由客户端报文输入接受来自客户端290的输入报文,并且经由所述路由器的y输出端口向客户端290提供输出报文。接收仅输出客户端291接收来自在位置(1,2)处的路由器212的报文,但是不发送报文。相反地,发送仅输入客户端292向在位置(2,2)处的路由器222发送报文但不从所述路由器处接收任何报文。并且,在位置(0,2)处的路由器202不具有客户端。在实施例中,每个路由器可能存在多于一个客户端核。多个客户端可以经由输入多路复用器共享一个路由器客户端输入端口,并且多个客户端可以通过解码具有其他状态的路由器输出有效指示符来共享一个路由器客户端输出端口。在实施例中,当输出有效指示符被断言时,输出报文本身的一些位可以帮助判定共享路由器输出端口的多个客户端中的哪一个应当接收输出。在实施例中,可以增强路由器来在多个输入端口上接受多个报文输入。在实施例中,在每个x环中的路由器数量是相同的,并且在每个y环中的路由器的数量是相同的。然而,可替代实施例是可能的,在可替代实施例中不同的x环具有不同的直径(在环中的路由器数量),或者在可替代实施例中不同的y环具有不同的直径。例如,在这种2d拓扑中,即使有路由器(1,2)和(2,1),也不需要有路由器(2,2)。在本公开中包括了这种可替代实施例。图3是根据实施例的图2b的noc299的路由器300的简图。路由器300耦合至客户端核390,并且包括报文输入、报文输出、有效性输出、路由电路350以及交换电路330。报文输入包括指定为xi的第一维报文输入302和指定为yi的第二维报文输入304。报文输入还可以包括指定为i的客户端输入306。报文输出包括指定为x的第一维报文输出310和指定为y的第二维报文输出312。有效性输出承载:x有效指示符314,指示x输出报文是否对于在其x环上的下一个路由器有效的信号;y有效指示符316,指示y输出报文是否对于在其y环上的下一个路由器有效的信号;输出有效指示符318,被指定为o_v并且指示y输出报文对于客户端390是有效客户端输出报文的信号;以及输入准备就绪指示符320,被指定为i_rdy并且指示路由器300是否已经接受在当前周期中来自客户端核390的输入报文的信号。在实施例中,x有效指示符314和y有效指示符316包括在输出报文x和输出报文y中,但是在其他实施例中,它们是不同的指示符信号。当被启用时,并且与每个时钟周期一样频繁,路由电路350检验输入报文302、304和306(如果存在的话),以判定xi输入、yi输入和i输入中的哪一个应当路由至哪个x输出和y输出,并且以确定本文中限定的有效性输出的值。在实施例中,路由电路350还输出包括x多路复用器选择354和y多路复用器选择352的路由器交换控制信号。在可替代实施例中,交换控制信号可以包括不同的信号,包括而不限于:输入或输出寄存器时钟使得交换控制信号能够引入或修改输出报文310和312中的数据。当被启用时,并且与每个时钟周期一样频繁,交换电路330根据输入报文302、304和306(如果存在的话)并且根据从路由电路350中接收的交换控制信号352、354而在链路x和链路y上确定第一维输出报文值310和第二维输出报文值312。在被设计用于在具有可拆分8输入alm(自适应逻辑模块)逻辑单元的阿尔特拉fpga中实现的实施例中,x输出由被指定为xmux的w位宽2:1多路复用器334来计算并寄存在w位x寄存器338中,并且y输出由被指定为ymux的w位宽3:1多路复用器332来计算并寄存在w位y寄存器336中。在被设计用于在以下详述的赛灵思6-lutfpga中实现的另一实施例中,5,5-lut(具有五个共享输入和两个单独输出以及两个独立的5-lut查找表逻辑功能的赛灵思6-lut)同时计算y输出报文的一个位和x输出报文的一个位,并且这两个位被寄存在与5,5-lut相同的逻辑单元中的两个触发器中。在此实施例中,交换330包括这个5,5-lut加上两个触发器逻辑单元配置的多个实例。交换电路330的其他实施例是可能的,并且在图4和图5中详尽描述了这些实施例中的一些实施例。仍然参照图3,客户端核390经由路由器输入306和路由器输出312、318和320耦合至路由器300。路由器300的特征是共享路由器第二维报文输出行312(y),以便同样经由所述路由器的指定为ci的客户端输入端口392将noc路由器输出报文传达至客户端390。在实施例中,路由器输出有效指示符o_v318向客户端核390发信号通知y输出312是从noc接收的有效报文并去往客户端。此电路安排相对于路由器具有针对客户端的单独、专用的报文输出端口的安排的优点是在一个输出链路y上共享这两个功能(y输出和客户端输出)所提供的在交换逻辑和布线方面的大大减少。在繁忙noc中,报文将在繁忙的x链路和y链路上从路由器路由到路由器,但是只有在报文递送的最后周期中,在目的地路由器处,专用的客户端输出链路才将有用。通过共享维度输出链路作为客户端输出链路,路由器使用大幅减少的fpga资源来实现路由器交换功能。参照图2a和图3,更详细描述了报文有效位。对于来自路由器300的x输出的报文,报文有效位x.v是x输出报文的v位。也就是说,在行314(一个位)和310(可能多个行/位)上的位一起形成了x输出报文。类似地,对于来自路由器300的y输出并且去往下游路由器(图3中未示出)的报文,报文有效位y.v是y输出报文的v位。也就是说,在行316(一个位)和312(可能多个行/位)上的位一起形成了到下游路由器的y输出报文。对于来自路由器300的y输出并去往客户端390的报文,虽然报文有效位y.v是报文的一部分,但是o_v有效位验证y输出报文是有效路由器输出报文,对于在客户端390的报文输入端口392上输入到所述客户端中有效。也就是说,在行316(一个位)、318(一个位)和312(可能多个行/位)上的位一起形成了到客户端390的y输出报文,但是所述客户端有效地忽略了y.v位。可替代地,在实施例中,y.v位不被提供至客户端390。并且对于来自在行306上的客户端390的co输出并去往路由器300的报文i,报文有效位v是报文i的一部分,尽管在图3中没有单独示出。也就是说,在行306上的位(这些位包括i报文有效位的位)形成从客户端390到路由器300的i输入报文。可替代地,在实施例中,存在从客户端核390到路由器300的单独i_v(客户端输入有效)信号。图4a、图4b、图4c和图4d是交换电路330的替代实施例的电路图。虽然以fpga实现时这些交换电路可能不如本文中其他地方所描述的阿尔特拉alm交换电路和赛灵思6-lut交换电路那样有利,但是这些交换电路具有仍然使它们优于传统交换电路的其他特征。根据实施例,图4a是图3的路由器交换机电路330的简图。交换机330包括通过三个w位寄存器和三个3:1多路复用器实现的具有输入寄存器的3×3交叉开关。在此实施例中,路由器具有三个报文输出x、y和客户端输出o。与其他实施例(例如,y报文输出还用作客户端输出的实施例)相比,此实施例消耗更多的逻辑资源。根据另一实施例,图4b是图3的路由器交换机电路330的简图。交换机330包括利用维度次序路由的3×3部分交叉开关。在本文中其他地方所描述的维度次序路由中,报文从路由器(x0,y0)发送到目的地(x1,y1),横穿noc,在x维中的第一路由,沿x环直到所述报文到达具有相应的x坐标x1的路由器(例如,路由器(x1,y0)),并且然后在y维中,沿y环直到所述报文到达具有相应的y坐标y1的路由器。使用这种路由算法,没有yi输入报文需要路由至x环,因为所述yi输入报文已经具有正确的x坐标。因此,可以并且已经消除了到x输出多路复用器的yi输入。与3:1多路复用器相比,x输出多路复用器现在是占用减少的面积的较少复杂的2:1多路复用器,尤其是在fpga实现中。也就是说,图4b的交换机330与图4a的交换机330是相同的,区别在于图4b的x输出多路复用器是2:1多路复用器而图4a的x输出多路复用器是3:1多路复用器。根据另一实施例,图4c是图3的路由器交换机330的简图。交换机330包括3:1多路复用器和2:1多路复用器以及三个报文输入寄存器。交换机330的这个实施例利用了本文上述y输出共享来消除客户端报文输出端口。然而,如以fpga所实现的,所述交换机不如其他实施例高效,因为其使用三个而非两个w位寄存器,并且因为交换机包括位于交换逻辑“前面”的输入寄存器而不是包括位于交换逻辑“之后”或“后面”的输出寄存器。在某些现代fpga中,诸如赛灵思6系列和7系列6-lutfpga中,没有足够的逻辑单元互连资源来独立地利用lut的所有部分以及每个逻辑单元中的所有触发器。因此,路由器交换机330的这个实施例可以使用比以上所讨论的和以下所描述的赛灵思6-lut实施例更多的逻辑单元。根据还另一实施例,图4d是图3的路由器交换机电路330的简图。交换机330包括两个2:1多路复用器以及三个报文输入寄存器。虽然这两个2:1多路复用器的安排使能实现更紧凑(即,消耗更少的fpga资源)的交换机330,但是所述安排使得交换机引发两个lut延时,并且禁止交换机实现潜在有用的报文路由传递函数(诸如xi→x和i→y)。相比之下,以上所讨论的以及以下所描述的路由器交换机330的阿尔特拉alm实施例可以实现任何期望的传递函数,并且阿尔特拉和赛灵思6-lut两者的交换机实施例都只引发一个lut延时,尽管这些实施例消耗了更多的fpga资源。图5a、图5b和图5c是图3的交换电路330的附加实施例的简图。图5d和图5e分别是图3的交换电路330的阿尔特拉alm实施例和赛灵思6-lut实施例的简图。根据实施例,图5f是图5e的赛灵思实施后技术映射的一位宽交换元件的简图。并且图5g示出了图3的交换电路330的时间复用的可替代实施例。根据还另一个实施例,图5a是图3的路由器交换机电路330的简图。在此实施例中,交换机330包括两个输入寄存器、3:1多路复用器和2:1多路复用器。交换机330不包括i输入寄存器,并且因此比图4d的路由器交换机电路330更高效。但是因为输入寄存器仍然在交换逻辑之前,当此交换机330技术映射到赛灵思6系列或7系列fpga时,交换机可能会遭受与图4d的交换机电路330相同的互连受限的逻辑单元布置低效率。根据实施例,图5b是图3的路由器交换机电路330的简图。交换机330包括两个输入寄存器、3:1多路复用器以及2:1多路复用器,接着是用于x输出和y输出的两个w位宽输出寄存器。至少对于一些应用,与之前所描述的交换机实施例中的至少一个实施例相比,此交换机330是经改进的并且比具有经缓冲5x5交叉开关的传统fpganoc路由器交换机小五到二十倍。路由器交换机330的这个实施例包括被设计用于技术映射到赛灵思fpga和阿尔特拉fpga的路由器交换机的实施例的基本逻辑拓扑。根据实施例,图5c是图3的路由器交换机电路330的简图。此交换机330被设计用于特殊情况,比如交换机330被布置成不具有客户端核的路由器的情况,或者路由器具有不向所述路由器或通过所述路由器发送输入报文的客户端核的情况,例如对于图2b中的路由器212和路由器客户端291而言情况就是这样。交换机330包括用于选择下一个y输出报文的单个2:1多路复用器以及x和yw位输出寄存器。在一些实施例中,可以由设计者对路由器进行配置以便明确是否经由利用这种有利的简化的交换电路30来实现所述路由器。在实施例中,这个复杂度降低的交换机330可以技术映射到双输出lut(比如阿尔特拉8输入可拆分lutalm或赛灵思双输出6-lut),从而实现每个lut的2:1多路复用器x和y的两个位,并且由此相对于以下所描述的图5d和图5e的高效率实施例实现了50%的可编程逻辑资源利用减少。图5d是根据实施例的一位宽交换元件的简图,其中,交换元件是被设计用于阿尔特拉almfpga的路由器交换机的部件。5-lut和3-lut两者都封装到单个阿尔特拉alm逻辑单元中,并且提供y[i]和x[i]的这两个输出寄存器以封装到与5-lut和3-lut相同的阿尔特拉alm逻辑单元中的触发器来实现。阿尔特拉alm路由器交换机的实施例包括多个这种交换元件(每个位一个交换元件)。8输入2输出阿尔特拉alm逻辑单元的灵活性还使能实现本文中所描述的其他实施例。在一个这种实施例中,单个alm逻辑单元可以实现两个任意3-1多路复用器,从而为非维度次序路由路由函数实现灵活的路由交换。在另一实施例中,alm逻辑单元可以实现4输入2输出部分交叉开关交换,从而实现具有第一维报文输入和第二维报文输入和两个客户端输入的1alm/位宽路由器功能。图5e是根据实施例的一位宽交换元件的简图,所述一位宽交换元件是图3的路由器交换机330的针对在赛灵思6-lutfpga中的效率而设计的部件。6-lut可以明确地被配置为两个5-lut,例如5,5-lut具有包括这三个报文输入xi[i]、yi[i]和i[i]中的每一个的一个位以及两位交换选择sel[1:0]输入的输入。配置为5,5-lut模式的赛灵思6-lut可以在单个lut中实现相同的五个输入的两个逻辑功能,有时也指定为lut6_2。使用两位交换选择sel[1:0]输入,此交换机可以选择这三个输入xi[i]、yi[i]和i[i]的可能的九个传递函数中的四个。下表概括了根据实施例的传递函数和可选子集(函数1、5、7、8):表iselyx注释100i→yi→xx和/或y环入口,较简单的sel2i→yxi→xxi→x,加上y环入口3i→yyi→x不需要使用维度次序路由4xi→yi→x提供客户端入口和出口501xi→yxi→x用于组播6xi→yyi→x不需要使用维度次序路由710yi→yi→xc普通x环入口811yi→yxi→x普通x环、y环流量交叉9yi→yyi→x不需要使用维度次序路由基本原理:根据实施例,由于维度次序路由,具有yi→x的这三个传递函数3、6、9是不必要的,但是可能对于报文从y输入到y输出或从y输入到x输出横穿的非维度次序路由函数是有用的。传递函数7和8最经常用于路由x和y环流量相互传递以及用于x环报文入口。函数5使得xi→y路由以及报文扇出能够用于以下所描述的组播递送。对于高效y环报文传送,使用某个传递函数i→y来将客户端输入i路由到y环中是有帮助的。否则,从(x0,y0)到(x0,y1)的报文可能必须进入到x环并且在y环[x=x0]上向南转到(x0,y1)之前循环回到(x0,y0)。这两个传递函数1和2提供了i→y路由。函数1使能简化以下所描述的sel[1:0]路由器控制逻辑的路由函数计算。同样设想了传递函数的不同子集的可替代实施例。仍然参照图5e,如以上所描述的,所述一位宽交换元件是图3的路由器交换机330的实施例针对赛灵思6-lutfpga中的效率而设计的部件。xi[i]、yi[i]和i[i]中的由交换选择sel[1:0]选择的这两个输出传递函数输出寄存在同样封装在同一6-lut逻辑单元的这两个输出触发器x[i]和y[i]中的下一个x[i]信号和下一个y[i]信号。赛灵思6-lut高效路由器交换机包括多个这类交换元件。在实施例中,交换函数是:nextx[i]=sel[0]?xi[i]:i[i];nexty[i]=(sel==2’b00)?i[i]:(sel==2’b01)?xi[i]:yi[i];赛灵思高效交换模块的实施例本文中并入以下可合成verilog源代码中。也就是说,以下示例源代码可以用于在fpga上对赛灵思高效交换模块的实施例进行实例化。此实施例的公开不应被解释为限制性的。在此实施例中,由链路宽度w将赛灵思高效交换实现参数化。对于具有宽度w的报文的路由器,在此模块中的生成块生成包括w(2输出)6-lut和两个w位报文输出寄存器x[]和y[]的数据路径。图3的路由器交换机330的这个实施例的每个位片都与图5e的这一位交换元件的一个实例相对应,并且每个lut6_2实现如上所述的交换传递函数表i的交换传递函数1、5、7、8。针对阿尔特拉8输入可拆分lutalm和赛灵思双输出6输入lut分别结合图5d和5e所描述的实施例使用设备的双输出查找表进行配置以便紧凑地计算每个lut的两个路由器输出位x[i]和y[i]。可替代实施例可以使用时间复用来将这个已经节省的结果额外减少两倍。代替在一个时钟周期内将这三个输入xi[i]、yi[i]和i[i]交换到两个输出中,还有可能在两个时钟周期上将所述三个输入顺序地交换到两个输出中。根据这种时间复用的可替代实施例,图5g是图3的路由器交换机电路330的简图。在第一时钟周期期间,单个3:1多路复用器从这三个输入中选择第一输出;这个值是在第一“保持”寄存器处捕获的,这里显示为在第二时钟边沿clk2上计时。注意,路由器交换机330的x输出和y输出在此第一时钟周期期间不需要变化。然后,在第二时钟周期期间,多路复用器从这三个输入中选择第二输出。这两个输出在输出为交换机的x输出和y输出的第二寄存器和第三寄存器中同时被寄存和交换。此时间复用交换机的各种实施例是可能的。在实施例中,两个不同的时钟边沿clk和clk2确定用于交换机330的时间复用操作的这两个时钟周期,但是存在可以限定这两个时钟周期的许多其他方式,比如而不限于使用公共时钟加上单独的时钟来启用用于第一和(第二和第三)寄存器的输入信号;或者clk2可以是clk的否定版本,或者可以以其他方式与第一clk异相;或者第一寄存器可以是被用来将输出信号延时大约半个时钟周期从而使得组合的3:1多路复用器可以在单个时钟周期内正确地生成两个输出的组合元件。此外,可以通过重新定时图5g的电路来获得等效时间复用交换机和noc交换结构,即,将一些输出寄存器重新安排成输入寄存器。例如,代替第二寄存器和第三寄存器形成交换机330的输出寄存器,它们可以被推出第一交换机并且可以被推入到下一个x交换机和y交换机的输入路径中。在这种情况下,这些寄存器将实际上是这些下一个交换机的输入寄存器xi和输入寄存器yi。类似地,第一“保持”寄存器可以保持在第一交换机中,或者其也可以被推入到第二交换机中。在此情况下,交换机的三输入多路复用器的单个输出将被路由至下一个x交换机的xi输入和下一个y交换机的yi输入。当以某些fpga设备来实现时,时间复用路由器交换机330提供了路由器以及因此由路由器组成的noc互连系统的总lut面积的有利减少。时间复用交换机的fpga高效技术映射的各个实施例都是可能的而非限制性的。例如,一个阿尔特拉8输入可拆分lutalm可以被配置用于实现每个alm3:1多路复用器的两个位(每个位一个3:1多路复用器)。因此,一个w位宽3:1多路复用器可以使用w/2个alm来实现。设备中大量的触发器——特别是采用新型fpga架构(比如在可编程互连结构中具有hyperflex寄存器的阿尔特拉stratix10fpga),意味着每两个输出位引入第三个触发器不必是在时间复用路由器交换机实现中的限制性fpga资源。时间复用的交换机配置向noc系统设计者提供了有用的折衷选择:非时间复用路由器交换机设计,每个时钟周期内输出两个w位报文,成本为w个lut;以及时间复用路由器交换机设计,每两个时钟周期内输出两个w位报文,成本为w/2个lut。时间复用交换机330的实施例对于路由器吞吐量或带宽的两倍减少实现了两倍的面积节省。也可以将这种交换机设计与在路由器间链路中以及在路由器-客户端接口处的其他类型的时间复用相组合,以实现新颖、超紧凑的路由器交换机。这种组合的时间复用的各个实施例是可能的而非限制性的。例如,可以使用本身由上述每个节拍使用两个时钟周期的时间复用路由器交换机来实现的w/2位宽链路在w/2位宽路由器的两个节拍上承载w位报文。这里,使用阿尔特拉8输入可拆分lutalm,可以在w/4个alm中实现w位路由器交换机,其中,每4个时钟周期的吞吐量高达两个完整输出报文。此配置的其他安排和时间复用程度也是可能的。客户端接口传统经缓冲虚拟通道(vc)noc路由器设计可能在客户端上施加若干困难。如果报文宽度大于微片/链路宽度w,则客户端被迫将报文分段成微片并从所述微片重组报文。如果若干传入报文的微片交织到达,则客户端被迫提供足够的ram来缓冲并重组预期最大数量的部分接收到的报文。在具有许多客户端核的系统中,这可能变成无法忍受的负担,因为,例如,数十个源客户端可能向特定的目的地客户端发送结论/结果报文以便聚集。对于信用流控制路由器,客户端还被迫针对noc输入微片而维护每个vc输入缓冲区和信用计数器(每个vc的对应的输入缓冲区和信用计数器),并且甚至可能被迫针对noc输出微片维护每个vc输出缓冲区。因此,经缓冲虚拟通道(vc)noc路由器设计通常是巨大且复杂的。作为替代方案,在本公开中所描述的路由器的实施例提供了(例如,通过报文数据有效载荷宽度d_w和路由函数route)可配置和参数化的严格的客户端接口。所描述的路由器不需要报文分段和重组,其也不需要逻辑(例如,输入缓冲区和输出缓冲区、信用流计数器)来处理多个虚拟通道。相反,每个路由器可以在每个周期原子地接受并递送报文(除非网络繁忙,在这种情况下,在一些实施例中,网络可能在不定数量的时钟周期内不接受所提供的客户端输入报文,直到有机会来接受所述报文并且在第一维或第二维报文输出端口上立即输出所述报文,如以下所描述的)。例如,参照图3,在每个操作周期期间,可能发生以下动作:1)客户端390可以断言输入报文(i306)并且断言输入报文有效指示符信号;在与图3相对应的一些实施例中,输入报文有效信号是i报文的i.v字段;在一些实施例中,输入报文有效信号是单独的信号(未包含在i报文中),其同样从所述客户端输出;2)路由器300可以断言准备就绪输入(i_rdy320);3)如果来自客户端390的输入报文(i306)有效(i.v,未明确示出)并且路由器300准备就绪(i_rdy320)接收来自客户端390的输入报文,则路由器300接受输入报文(i306);4)路由器300还可以断言输出报文(在输出y上的o)和有效(o_v318);5)在一些实施例中,客户端390总是准备就绪接受输出报文;在其他实施例中,客户端390可以断言单独的“准备就绪输出”信号;6)如果输出报文(o392)有效并且客户端390准备就绪在客户端输入ci392上接受输出报文,则客户端接受输出报文。noc的实施例在争用noc资源的客户端390之间和当中不保证对访问noc资源的公平仲裁。在负载下,noc可能无法在无限时间内接受输入报文,或者可能无法在无限时间内递送所接受的报文。但是,给定足够的时间,noc最终递送其接受的每一条报文。至少在理论上,客户端390从不需要重发丢失或丢弃的报文。此外,noc的实施例不保证有序的报文递送。例如,如果在(x0,y0)(参见图2b)处的客户端向在(x1,y1)处的客户端发送两个报文m1和m2,则m1可能在路由中围绕noc偏转,然而m2可能直接路由并首先到达。在可替代实施例中,noc路由器可以配置有路由函数,所述路由函数确保即使发生路由偏转也将报文从一个客户端发送到另一客户端或者在客户端的不同子集之间的有序递送。此外,如果在noc上运行的客户端报文传送协议使用多个独立的(非堵塞)通道、不同的流量路由函数、不同的报文宽度(例如,读取请求对高速缓存行读取响应)或在负载下的附加带宽或吞吐量,则系统设计者可以使用这些性质来对多个(并行)noc进行实例化。但是,即使每个客户端对具有多个路由器多个noc进行实例化,也比单个传统虚拟通道(vc)路由器更快、更便宜、更少资源密集型。另外,路由器的rtl(寄存器传递语言)实现是模块化的,并预期使用应用专用路由电路来替换基本维度次序路由(dor)。通过此机制(加上对报文数据宽度d_w进行配置以承载路由元数据的能力),客户端及其定制路由器可以引入新型noc语义,可以包括例如保证有序递送、带宽保留、时分复用路由(tdmr)以及电路交换。路由器路由电路和noc操作说明现在转向路由器的路由电路的设计和将路由器组成将报文从一个客户端传输到另一客户端的noc。参照图2b和图3,回顾一下,noc299包括多个路由器200和作为路由器200的实施例的包括路由器交换机330和路由电路(或逻辑)350的路由器300。在实施例中,在每个周期期间,路由器接收0到3个有效输入报文xi、yi和i。基于这些输入(并且在一些实施例中,进一步基于其他数据,包括而不限于路由器本地状态或附加报文输入元数据),路由电路350判定哪条输入报文(如果有的话)应当在哪个路由器输出x和y上输出,并且向交换电路330发送相应的交换控制信号352、354以实现这些输出选择。并且路由电路350还断言或否定本文中所描述的各种有效性输出信号314、316、318和320。多个这类2d路由器300可以用于组成具有一个或多个有用的全系统行为的2dnoc,所述全系统行为包括但不限于报文从源路由器(x0,y0)逐步地经过另个或多个中间路由器传送到目的地路由器(x1,y1)。一般而言,环面noc报文路由是跨noc将报文从源路由器(xs,ys)传送到目的地路由器(xd,yd)的过程。总之,源路由器从其客户端中接受报文,并且所述报文包括目的地路由器坐标(xd,yd)。如果路由器(x,y)接收到具有相同坐标(x,y)的报文,则所述报文在所述路由器的y输出端口上输出,断言客户端输出有效(o_v)指示符,并且解除断言y输出有效指示符(y.v);否则,取决于目的地路由器坐标(xd,yd),路由器在输出端口y和y.v或者x和x.v上输出报文和报文有效指示符。在实施例中,有效输入报文总是在某个输出端口上输出。也就是说,有效输入报文不在路由器中缓冲,也不会由网络丢弃有效输入报文。以这种方式,报文横穿经过网络的路由器的路径,直到所述报文到达目的地路由器;随后所述报文输出至客户端(如果有的话)。在实施例中,路由器实现是模块化的,并且路由电路拓扑的选择是设计时间路由器配置参数。这种可配置性使能构造包括多个noc的系统,从而使得noc可以选择有利的应用专用和应用高效的路由策略和行为。在实施例中,路由器使用“dor”偏转维度次序路由电路。当具有dor路由电路的路由器并入到2d环面noc中时,noc总体上实现了偏转维度次序报文路由算法。偏转维度次序路由确定报文从源路由器(xs,ys)到目的地路由器(xd,yd)所需的路径(所横穿的路由器的序列)。在维度次序路由中,报文在源路由器x环(即,x环[y=ys])上从路由器传递到路由器,直到所述报文到达x坐标xd等于报文目的地x坐标xd的中间路由器(xd,ys)。路由器(xd,ys)然后在其y输出上输出所述报文。所述报文然后在y环[x=xd]上从路由器传递到路由器,直到所述报文到达目的地路由器(xd,yd)并且输出至目的地路由器的客户端。在实施例中,具有所接收报文的中间路由器(xd,ys)只可以“试图”在所述中间路由器的y输出上输出所述报文。然而,在中间路由器从所述源路由器(xs,ys)接收报文的周期期间,所述中间路由器可能必须将y输出分配给某个更高优先级的输入报文。例如,中间路由器可能具有在y上输出的有效yi报文以及在y上输出的有效xi报文。每个周期内只能在y上输出一个报文;其他报文必须“去”其他地方。在实施例中,xi报文偏转,这意味着路由器沿着x环在路由器的x输出端口上输出xi报文。报文然后“环绕”并横穿x环[y=ys]的所有路由器,直到返回到达路由器(xd,ys),其中,路由器“重新试图”在其y输出上输出报文。重复此过程直到原始xi报文在中间路由器(xd,ys)的y输出上输出。在一些实施例中,从这一点来看,无需发生进一步偏转。所述报文横穿y环[x=xd],直到所述报文到达目的地路由器并且输出至目的地路由器的客户端。可替代地,目的地路由器的客户端可以从目的地路由器中否定客户端输出准备就绪信号,这因此导致报文环绕y环直到目的地路由器的客户端准备就绪接收来自源客户端的输出报文。当且只有当所述报文的目的地x坐标xd等于路由器x坐标和y环x坐标(即,y环[x=xd])时,维度次序路由才建立并保存报文路由至y输出或在y环链路上存在的不变量。在实施例中,路由器的报文输入被优先化为如下yi>xi>i,意味着yi优先于xi和i,xi优先于i,并且i具有最低优先级。如果yi有效,则yi有效地选择其输出端口(在维度次序路由noc中总是y输出端口)。然后,如果xi有效,则xi有效地选择其输出端口(x或y),除非y已经被yi->y利用(即,yi已经“选择”y)。这种情况下,路由器偏转xi以使得其在x端口上替代地输出。只有当报文i将使用的输出端口x或y在此周期期间可用时,路由器才接受来自客户端的有效客户端输入报文i。图6是根据实施例的描述了图3的路由控制逻辑350可以被设计用于实现的dor偏转维度次序路由算法的流程图。控制逻辑350可以在可合成硬件描述语言(hdl)中指定,比如verilog。以下提供了可用于根据图6的实施例合成控制逻辑350的verilog代码。参照图3和图6,如在步骤600中所指出的,路由电路350的目的是判定在哪个输出端口上输出哪条有效输入报文。因此,路由电路350被配置用于生成分别与图3的信号354和352相对应的交换电路控制信号x_sel和y_sel(图6),并且用于确定用于输出端口x和y的有效性指示符。相应地,在步骤602处,路由电路350将信号x_sel和y_sel以及指示符i_rdy、o_v、x.v和y.v初始化到默认值。路由器电路350还采用两个内部逻辑状态x_busy和y_busy,这两个内部逻辑状态指示哪些输出报文端口(如果有的话)已经分配给输入报文。在路由器电路350中的逻辑的结构反映了输入的静态优先顺序,如以上所述的yi>xi>i。首先,yi报文,如果有效的话(yi报文是否有效是由例如图2a的报头298中的v字段来指示的),则被分配到输出端口,所述输出端口在所描述的维度次序路由中总是y。然后,xi报文,如果有效的话(xi报文是否有效是由例如图2a的报头298中的v字段来指示的),则被分配到由其目的地地址所指示的输出端口(x或y),除非y已经忙,在这种情况下,有效xi报文被分配至x输出端口而不管其目的地地址是什么。然后,i报文,如果有效的话(i报文是否有效是由例如图2a的报头298中的v字段来指示的),则被分配到由其目的地地址所指示的输出端口(x或y),除非所指示的输出已经忙,在这种情况下,将i_rdy指示符的默认设置从602中保持为假,并且客户端390被迫保持报文i直到下一个周期。路由器300首先路由第二维输入yi。具体地,在步骤604处,路由器电路350通过检验yi输入报文的报头(图2a)的v字段来测试所述yi输入报文是否有效。如果yi无效,则yi在此周期内“不存在”并且不被路由至输出端口。如果yi有效,则在步骤606处,路由器电路350使路由器交换机330路由yi→y。具体地说,路由器电路350设置y_busy来将y输出分配给yi,设置y_sel交换控制来引导ymux332选择yi输入,并且取决于输入报文的y坐标而设置o_v和y.v有效性指示符。如果yi.y等于此路由器的y坐标,则所述报文处于其目的地路由器处(通过维度次序路由不变量,yi.x已经等于路由器的x坐标是固有的)。如果yi.y等于路由器y坐标,则路由器逻辑350通过断言客户端输出有效信号o_v而使路由器交换机330将报文输出至在y输出上的客户端390。如果yi.y不等于路由器y坐标,则路由器逻辑350通过断言y输出有效信号y.v而使路由器交换机330将报文输出至在y环上的下一个路由器。路由器300其次路由第一维输入xi。在步骤608处,路由器逻辑350通过检验xi输入报文的报头(图2a)的v字段来测试所述xi输入报文是否有效。如果xi无效,则xi在此周期期间“不存在”并且不被路由至输出端口。如果xi有效,则在步骤610处,路由器逻辑350测试报文xi的目的地x坐标xi.x是否等于路由器300的x坐标,并且还检查y输出是否已经分配给yi。只有当xi.x等于路由器300的x坐标并且y输出尚未分配给yi时,路由器逻辑350才使路由器交换机330将xi报文路由至y输出。如果xi.x不等于路由器300的x坐标,则按照维度次序路由算法,路由逻辑350使路由交换机330将报文xi路由至x输出以便将xi路由至x维度中的下一个路由器。类似地,如果xi.x等于路由器300的x坐标但是y输出已经分配给更高优先级报文yi,则xi报文不能输出至y并且路由器逻辑350使路由器交换机330将xi偏转到唯一可用输出端口x。如果在步骤612处xi.x等于路由器300的x坐标并且y输出不忙(之前分配了有效输入报文yi),则路由器300路由xi→y。具体地说,路由器逻辑350设置y_busy来将y输出分配给xi,设置y_sel交换控制来引导ymux332选择xi输入,并且取决于输入报文xi的y坐标xi.y而设置o_v和y.v有效性指示符。如果xiy等于路由器y坐标,则路由器逻辑350通过断言客户端输出有效信号o_v而使路由器交换机330将xi报文输出至在y输出上的客户端390。如果xi.y不等于路由器y坐标,则路由器逻辑350通过断言y输出有效信号y.v而使路由器交换机350将xi输出至在y维度(例如在其y环上)中的下一个路由器。如果在步骤610处路由器逻辑350确定有效输入报文xi的x坐标xi.x不等于路由器300的x坐标,则在步骤614处,路由器逻辑使路由器交换机330将xi路由至在第一维输出x上的下一个路由器,例如,在环面noc中的x环上路由xi→x。同样在步骤614处,路由器逻辑350设置x_busy来将x输出分配给xi,设置x_sel交换控制来引导xmux334选择xi输入,并且断言x.v有效性指示符。路由逻辑350最后路由客户端输入i。在步骤616处,路由器逻辑350通过检验i的报头(图2a)的字段v来测试i是否是有效输入报文。如果i无效,则i在此周期期间“不存在”并且不被路由至输出端口。如果i有效,如果正确的端口(基于包括在i的报头中的目的地地址)可用,则路由器逻辑350使路由器330将i路由至输出端口。如果正确输出端口因为其已经分配给更高优先级输入报文yi或xi而不可用,则路由器逻辑350使路由器300在当前周期期间拒绝客户端输入报文i。在这种情况下,路由器逻辑350解除断言客户端输入准备就绪有效性指示符i_rdy(如在步骤602处默认完成的那样)。路由器300在任何给定周期期间从客户端390接受或不接受输入报文i是在实施例中提供的流控制机制。如果noc非常忙,例如,四面八方高度加载有多个报文路由,如果用于客户端输入报文的报文输出端口不可用,则在任何给定的周期期间都不接受到特定路由器300的客户端输入i。在此情况下,客户端必须等待随后的周期来发送其报文i。客户端可以在下一个周期期间重新尝试发送报文i、可以在下一个周期期间尝试发送某个其他输入报文i或者可以尝试根本不发送报文。如果在步骤618处i有效,则路由器逻辑650测试报文i的目的地x坐标i.x是否等于路由器300的x坐标。如果i.x不等于路由器300的x坐标,则在步骤622处,路由器逻辑350测试x输出是否已经分配给xi输入。如果是这样,则路由器300在此周期内不接受客户端输入报文i。然而,如果x输出对于有效i输入可用,则在步骤624处,路由逻辑350通过设置x_sel交换控制来引导xmux334选择i输入并且断言x.v有效性指示符而使路由电路330路由i→x。如果在步骤616和618处,路由器逻辑350确定i有效并且i.x等于路由器300的x坐标,则按照维度次序路由算法,路由器逻辑判定路由器是否可以将有效i报文路由至y输出端口。具体地说,在步骤620处,路由器逻辑350测试y是否可用或之前是否分配给xi或yi。如果可用,则在步骤626处,路由器逻辑350使路由器交换机330路由i→y。具体地说,路由器逻辑350设置y_sel交换控制来引导ymux336选择i输入,并且取决于输入报文i的y坐标i.y而设置o_v和y.v有效性指示符。如果i.y等于路由器y坐标,则路由器逻辑350通过断言客户端输出有效信号o_v而使路由器交换机330将i报文路由至在y输出上的客户端。如果客户端由于某种原因将报文路由至自己(例如,从(xs,ys)路由至(xd=xs,yd=ys)),则发生这种场景。然而,如果i.y不等于路由器y坐标,则路由器逻辑350使路由器交换机330通过断言y输出有效信号y.v而经由y输出将报文i输出至在y维度(例如,其y环)上的下一个路由器。如果在步骤616和618处路由器逻辑350确定i有效但是i.x不等于路由器300的x坐标,并且如果在步骤620处路由器逻辑确定y输出忙,则路由器300在当前周期期间不接受有效输入报文i。此时,任何有效输入报文yi、xi、i都已经被路由至输出,或者,如果i有效但是输出不可用,则否定i_rdy以使得路由器300不接受报文i。换言之,路由器300总是将有效输入报文yi路由至y,并且取决于y的可用性和xi的目的地地址而总是将有效输入报文xi路由至y或x。但是路由器300不会总是路由有效输入报文i。也就是说,在给定周期期间,路由器300保证将有效输入报文yi和xi路由到某地,但是不保证将有效输入报文i路由到任何地方。因此,在每个路由器300处,以上所描述的算法的实施例通过使已经在noc上的有效报文优先于来自客户端的新报文来实现报文访问控制的度量。由以下verilog源代码描述并表示了dor路由器功能逻辑350的实施例(其功能如以上结合图3和图6所描述的),所述源代码可以用于在fpga上合成并对路由器逻辑350进行实例化。然而,应当理解,此实施例和verilog源代码的公开并不旨在限制本文中所公开的原理和概念的范围。在由以上verilog硬件定义语言(根据所述硬件定义语言,可以合成工作路由dor路由函数电路)表示的此实施例中,与图6的流程图逻辑的对应关系是明显的。例如,verilog代码的第97、103和114行分别于步骤604、608和616相对应。将维度次序不变量与输入的静态优先顺序yi>xi>i组合实现了极小且极快的dor路由电路。与具有用于选择许多输入中的哪一个分配至哪些输出端口的巨大的逻辑树的传统fpga环面noc路由器相比,本文中所公开的dor逻辑(例如,图3的路由器逻辑350)的实施例通常合成少于十个6-lut并且具有一或两个lut延时,并且是本文中所公开的实施例实现这种节省资源使用和较低每个路由器延迟的原因之一。取决于特定实施例的交换电路330,可以从路由电路350输出不同的交换控制输出(这里为352和354)。以赛灵思6-lutfpga实现的实施例中,如例如结合图5e所描述的以及本文中较早所描述的,根据表i中详尽描述的可能传递函数(其伴随了图5e的以上讨论)的特定子集,一个两位传递函数选择信号sel[1:0]选择将各种报文输入xi、yi、i映射到这两个输出x、y的若干传递函数之一。通过从表i中选择传递函数1、5、8、9,实现了用于确定sel[1:0]的极其简单且有利的电路。这里,sel[1]就是从目前路由器的y环上的前一个路由器的输出的yi输入有效信号yi.v,并且sel[0]就是从目前路由器的x环上的前一个路由器的输出的xi输入有效信号xi.v。换言之,利用交换传递函数选择、sel编码和路由电路350的结构的这种非常有利的安排,路由电路根本不需要任何逻辑门(零门延时)来判定如何将输入报文xi、yi和i交换到输出端口x,y(然而,路由电路的确包括了逻辑门来计算输出有效性信号)。这里,将xi、yi、i输入交换到x、y输出在路由电路350中引发零门延时并且在交换电路330中引发单个门延时。以下结合图10描述了这种交换。图7是noc路由器的简图,并且用于展示若干noc路由场景,展示了从源客户端到目的地客户端跨环的逐段报文传输。如以上刚刚结合图3和图6所公开的,图7a示出了对于到自己(702)、在y环(704)上、在x环706上、在x环并且然后在y环708上、以及(利用偏转)在x环和y环上的报文使用偏转维度次序路由的普通点对点报文递送。在路由702中,在(0,0)处的客户端向在(0,0)处的客户端发送报文。路由器(0,0)在其i端口上接受报文并且然后在其y端口上输出所述报文,断言o_v。所述客户端接收回其自己的报文。在路由704中,在(0,1)处的客户端向在(0,2)处的客户端发送报文。路由器(0,1)在其i端口上接受报文,路由i→y,同时断言y.v到路由器(0,2)的yi中。在随后的周期期间,路由器(0,2)然后路由yi→y,断言o_v并否定(解除断言)y.v,以使得在(0,2)处的客户端接收来自(0,1)处的客户端的报文。在路由706中,在(1,0)处的客户端向在(3,0)处的客户端发送报文。路由器(1,0)接受来自其客户端的报文,路由i→x,同时断言x.v到路由器(2,0)的xi中。在随后的周期期间,路由器(2,0)路由xi→x,同时断言x.v到路由器(3,0)的xi中。在随后的周期期间,路由器(3,0)路由xi→y,断言o_v并否定y.v,以使得在(3,0)处的客户端接收由客户端(1,0)发送的报文。在路由708中,在(1,1)处的客户端向在(2,3)处的客户端发送报文。路由器(1,1)接受来自其客户端的报文,路由i→x,同时断言x.v到路由器(2,1)的xi中。在随后的周期期间,路由器(2,1)路由xi→y,同时断言y.v到路由器(2,2)的yi中。在随后的周期期间,路由器(2,2)路由yi→y,同时断言y.v到路由器(2,3)的yi中。在随后的周期期间,路由器(2,3)路由yi→y,断言o_v并解除断言(否定)y.v,以使得在(2,3)处的客户端接收由在(1,1)处的客户端发送的报文。在路由710中,在(1,3)处的客户端向在(2,0)处的客户端发送报文。路由器(1,3)接受来自其客户端的报文,路由i→x,同时断言x.v到路由器(2,3)的xi中。通过维度次序路由,xi报文需要路由到y,但是假设(在此示例中)此周期内y输出已经分配给yi。因此相反,xi报文偏转到x上。路由器(2,3)路由xi→x,同时断言x.v到路由器(3,3)的xi中。路由器(3,3)路由xi→x,同时断言x.v到路由器(0,3)的xi中(回绕)。路由器(0,3)路由xi→x,同时断言x.v到路由器(1,3)的xi中。路由器(1,3)路由xi→x,同时断言x.v到路由器(2,3)的xi中。这次y输出未分配给有效输入报文yi,并且报文可以“转到”y环中。路由器(2,3)路由xi→y,同时断言y.v到路由器(2,0)的yi中。路由器(2,0)路由yi→y,断言o_v并解除断言y.v,以使得在(2,0)处的客户端接收由在(1,3)处的客户端发送的报文。在实施例中,本文中所描述的偏转维度次序路由算法不会遭遇死锁或活锁。即使在给定时刻noc完全充满了飞行中的报文(即在每个x和y链路上都存在有效的报文),在多个时钟周期上,维度顺序路由也提供了在给定y环上的所有报文将在不发生偏转的情况下到达所述报文的目的地路由器(x,y)并且然后输出到此路由器的客户端。因此,随着时间推移,最初在y环链路上的所有报文都将从noc输出(递送)。这空出了y环链路来接受去往y环的x环报文,并且假设在noc上没有发送新报文,则所有最初的x环报文也将从noc输出(递送)。组播报文递送一些并行应用或工作负荷(例如,在与noc互连的并行多处理器上运行的那些)可能需要将报文或报文流高效地递送至许多客户端。对于高扇出报文的高效实现,模块化路由器可以被配置用于使用‘mcdor’(组播偏转维度次序路由器)路由电路。像dor一样,mcdor将简单的报文从一个源客户端路由至一个目的地客户端。mcdor还可以将组播报文从单个源客户端路由至如下的多个目的地客户端:x组播(到x环上的所有客户端)、y组播(到y环上的所有客户端)以及xy组播(向所有客户端“广播”)。普通报文和组播报文可以任意混合,并且可以并发地接受和递送。也就是说,在任何给定时间,noc可以承载普通(单个来源单个目的地)报文、组播报文或普通报文和组播报文的组合。再次参照图2a,报文298的mx字段和my字段控制组播递送如下:1)mx=0,my=0,x,y:仅递送至(x,y);2)mx=0,my=1,x,ys:y组播到(x,*);3)mx=1,my=0,xs,y:x组播到(*,y);4)mx=1,my=1,xs,ys:广播到(*,*)。在实施例中,对于x(或y)组播,报文x字段、y字段不被解释为目的地路由器坐标,而是源x(y)坐标(xs,ys)。一旦报文被递送到每个所选客户端,这些源坐标就作为标记值来终止组播递送,如以下更详细描述的。y组播报文递送y组播将报文递送至在指定的y环[x=xd]上的所有客户端(xd,*)。任何客户端都可以组播到任何y环,而不仅仅是其“家庭”y环。也就是说,目的地x坐标xd不需要与源(xs,ys)相同,即xd不需要等于xs。根据实施例的基本维度次序路由策略‘x,然后y’确保在路由器yi输入端口处的y环报文具有访问y输出端口的优先权,并且因此保证在最多ny周期内将所述报文递送至任何(xd,y),其中,ny是y环的直径(即,y环中的路由器数量)。类似地,保证在y环上的y组播报文在最多ny周期内横穿所述环中的每个路由器。如果(xd,*)的y组播报文到达路由器(xd,ys)的i或xi输入并成功分配其y输出端口,则所述报文既输出到客户端(xd,ys)又传播到下一个y环路由器的y输入。因为y输出报文既是有效y环报文又是有效客户端输出报文,所以mcdor路由电路350(图3)断言y.v有效输出信号和o_v有效输出信号两者。重复这个输出并传播报文过程直到下一个y环路由器将再次是(xd,ys)。在此,在(xd,ys)路由器处,通过否定y.v来结束y组播传播。图7b是根据实施例的4×4noc的简图,并且展示了两个y组播报文递送722和724。在路由722中,存在到同一y环[x=0]的y组播。具体地说,在位置(0,0)处的客户端向在(0,*)处的客户端发送y组播报文。所述报文的y坐标字段是源路由器的y坐标(这里是0)。在位置(0,0)处的路由器接受来自其客户端的报文i,路由i→y,断言耦合至在位置(0,1)处的路由器的y.v,并断言o_v(报文路由至作为组播报文的来源的客户端(0,0)并在该处接收)。路由器(0,1)路由yi→y,向路由器(0,2)断言y.v,断言o_v(报文路由至客户端(0,1)并在该处接收)。类似地,路由器(0,2)向路由器(0,3)并向其客户端(0,2)发送报文。因为下一个路由器y等于在y=0处的报文源(源路由器y),所以路由器(0,3)路由yi→y,否定y.v,因此结束组播,并断言o_v(报文路由至客户端(0,3)并在该处接收)。在路由724中,将报文y组播到不同y环[x=2]。具体地说,在位置(1,1)处的客户端向在(2,*)处的客户端发送y组播。路由器(1,1)接受来自其客户端的报文i,路由i→x,断言x.v到路由器(2,1)的xi中(即,向路由器)。路由器(2,1)路由xi→y,断言y.v到路由器(2,2)的yi中,并断言o_v(报文路由至客户端(2,1)并在该处接收)。报文传播至路由器(2,2)、(2,3)和(2,0),并且也被第送至客户端(2,2)、(2,3)和(2,0)。组播传播在路由器(2,0)处结束,所述路由器是y环中接收报文的第一个路由器,并且所述路由器解除断言y.v以结束组播。x组播x组播报文横穿x环上的每个hoplite路由器,到达每个xi输入,并且在每个x输出端口上退出。当所述报文横穿每个路由器时,其还被发送至路由器的y端口,无论是用于立即输出至相邻客户端还是用于y环来传输到在不同y坐标处的另一客户端。由于考虑到输出端口争用和维度次序路由,x组播不如y组播简单。1)输出端口争用——当x组播报文横穿每个x环路由器时,如果在那个路由器中的y输出在那个周期内分配给yi,则可能不会发生y环输出。在这种情况下,组播报文必须继续围绕所述环以便在nx周期之后重新尝试在那里进行递送,其中nx是x环的直径。在空载网络中,x组播报文需要nx周期,但是在拥塞网络中,y端口争用可能迫使x组播报文围绕x环进行多次旅行。2)维度次序路由:客户端(xs,ys)可以x组播到任何(*,yd),例如,到任何x环[y=yd]。在实施例中,将报文从(xs,ys)路由到y环[x=xs]上的(xs,yd),并且然后在x环[y=yd]上进行x组播是不正确的,因为这可能需要在x环上路由报文之前在y环上路由报文,这违反维度次序路由(即,在x环上进行路由(如果有必要)并且然后在y环上进行路由(如果有必要))。即使在实施例中利用yi→x交换增强了路由器数据路径,也可能在同一路由器处存在传入xi报文。确实,在报文都等待进入y环的情况下特定x环可能会饱和,但是在y环上x组播的(多个)报文不能进入x环。这有可能导致死锁或活锁。因此,从(xs,ys)到任意行(*,yd)的x组播将首先横穿x环,并且在每个路由器(例如,(xd,ys))处,还在y环上将报文向南朝向目的地(xd,yd)输出。再次,如果在(xd,ys)处y端口分配给yi报文,则x组播报文被迫继续围绕x环[y=ys]并且稍后重新尝试递送。对于x环中的‘恰好一次’报文递送至x环中的每个y,向每个x环报文添加附加状态来跟踪哪条y环已经接受所述报文。在实施例中,此状态可以是nx位的位向量,其中,每个位指示其相应的y环已经接受x组播。x组播报文围绕x环[y=ys]一圈又一圈的循环,直到每个位都被设置。但是,这在每条报文链路中添加了o(nx)位状态。相反,在另一实施例中,源路由器向每条x环报文链路并且向mcdor路由电路xi输入和x输出添加x坐标‘nx’(下一个x)。‘nx’是跟踪下一个未决y环的x坐标的归纳变量。当从(xs,ys)到(*,yd)的x组播报文在y上输出至y环[x=x]时,nx输出前进至(x+1)modnx。逐个路由器地重复这个过程,直到nx等于xs,指示完成x组播。当在(x,ys)处的x组播报文不能输出至y时,nx输出不会前进。nx周期之后,x组播将横穿整个x环并在(x,ys)处重试。图7c是4×4noc的简图,并且展示了三个个x组播报文路由/递送742、744和746。在路由742中,存在到同一x环[y=2]的x组播,并且不存在yi争用。首先,在(0,2)处的源客户端向在(*,2)处的客户端发送x组播报文。所述报文的x坐标字段是源路由器的x坐标(这里,x=0)。路由器(0,2)从其客户端中接受报文i,路由i→x和i→y,断言x.v到路由器(1,2)的xi中,并且断言o_v(报文路由至源客户端(0,2),并在该处接收)。路由器(1,2)路由xi→x和xi→y,断言x.v到路由器(2,2)的xi中,并断言o_v(报文路由至客户端(1,2)并在该处接收)。类似地,路由器(2,2)在x上将报文发送至路由器(3,2),并且在y上将报文输出至其客户端(2,2)。因为下一个路由器x等于报文x(即,源路由器(0,2)),所以路由器(3,2)仅路由xi→y,否定x.v,因此结束组播,并且断言o_v(报文路由至客户端(3,2)并在该处接收)。在路由744中,存在从第一x环(y=0)中的客户端(0,0)到不同x环[y=1]的x组播。首先,在(0,0)处的源客户端向在(*,1)处的客户端发送x组播报文。路由器(0,0)从其客户端中接受报文i,路由i→x和i→y,断言x.v到路由器(1,0)的xi中,并且断言y.v到路由器(0,1)的yi中。路由器(0,1)路由yi→y,断言o_v(报文被路由至客户端(0,1)并在此处被接收)。下一个x环路由器(1,0)路由xi→x,断言x.v到路由器(2,0)的xi中,并且断言y.v到路由器(1,1)的yi中。路由器(1,1)在路由器(1,1)的y输出上将报文输出至客户端(1,1)。下一个x环路由器(2,0)路由xi→x,断言x.v到路由器(3,0)的xi中,并且断言y.v到路由器(2,1)的yi中。路由器(2,1)在路由器(2,1)的y输出上将报文输出至客户端(2,1)。下一个x环路由器(3,0)仅路由xi→y,否定x.v(因为客户端(3,1)是x环x=1中接收x组播报文的最后一个客户端),并且断言y.v到路由器(3,1)的yi中。路由器(3,1)在路由器(3,1)的y输出上将报文输出至客户端(3,1)。在路由746中,存在到同一x环[y=3]的x组播,由于与有效输入yi对x环y=3中的路由器之一的争用而使用偏转。源客户端(1,3)向客户端(*,3)发送x组播。路由器(1,3)从其客户端(源客户端)接收报文,将此报文输出至在(1,3)处的客户端并且输出至路由器(2,3)的xi输入,其中,nx=2。但是在此说明性实施例中,路由器(2,3)不能在此周期期间将报文输出至客户端(2,3),因为y输出被分配至yi报文。相反,x组播偏转至路由器(3,3),而不递送至客户端(2,3),其中,nx=2。在路由器(3,3)处,nx≠3,因此路由器(3,3)路由,而不递送至客户端(0,3),其中,nx=2。在路由器(0,3)处,nx≠0,因此路由器(0,3)将报文路由至路由器(1,3),而不递送至客户端(0,3),其中,nx=2。在路由器(1,3)处,nx≠1,因此路由器(1,3)将报文路由至路由器(2,3),而不递送至客户端(1,3),其中,nx=2。这次y路由器(2,3)的y输出可用,因此路由器(2,3)路由xi→y以便输出至客户端(2,3),并且将xi→x与x.v一起路由到路由器(3,3)的xi中,其中,nx=3(路由器(2,3)将nx从2增加到3)。类似地,路由器(3,3)将报文递送至客户端(3,3)并且递送至路由器(0,3),并且将nx增量到0(如以上所描述的模增量)。路由器(0,3)将报文递送至客户端(0,3),并且此时,结束x组播,因为nx已经循环遍历所有的x值1、2、3和0。广播(xy组播)广播(xy组播)将输入报文递送至noc上的所有客户端。广播是将xy组播报文x组播到每条y环中的xy组播报文,其中,mx=1,my=1(参见图2a)。一旦xy组播被发送到y环中,则其被用作y组播,并且被第送至在那条y环上的每个客户端。与x组播一样,在noc负载下,y输出争用可能导致引发围绕x环额外的(多次)旅行的偏转,从而实现将所有xy组播注入到所有y环的所有客户端中。图7d是4×4noc的简图,并且展示了从客户端(0,0)到客户端(*,*)的广播。报文的(x,y)坐标字段是源路由器的x坐标和y坐标,在此示例中为(0,0)。xy组播报文沿着x环[y=0]横穿,访问在x环上的每个路由器(0,0)、(1,0)、(2,0)、(3,0)。在x环[y=0]中的每个路由器处,xy组播报文也在这个路由器的y端口上输出,其中,断言y.v并断言o_v,因此xy组播报文沿这个y换传播(被解释为在这个y环内的y组播报文),并且当所述报文沿y环行进时也被输出至每个客户端。在y环[x=0]上,在ny=4周期上将xy组播报文输出至在(0,0)、(0,1)、(0,2)和(0,3)处的客户端。所述报文类似地输出至所有其他y环[x=1至x=3]的客户端。在此示例中,在x和y中的报文路由和递送是流水线式的,因此,广播采用如下nx+ny-1=7个周期:在时间t=1时,xy组播报文到达路由器(0,0)和客户端(0,0)处;在时间t=2时,报文到达路由器(0,1)和(1,0)以及客户端(0,1)和(1,0)处;在时间t=3时,报文到达路由器(0,2)、(1,1)、(2,0)以及客户端(0,2)、(1,1)、(2,0)处;在时间t=4时,报文到达路由器(0,3)、(1,2)、(1,1)、(3,0)以及客户端(0,3)、(1,2)、(1,1)、(3,0)处;在时间t=5时,报文到达路由器(1,3)、(2,2)、(3,1)以及客户端(1,3)、(2,2)、(3,1)处;在时间t=6时,报文到达路由器(2,3)、(3,2)以及客户端(2,3)、(3,2)处;在时间t=7时,报文到达路由器(3,3)和客户端(3,3)处。作为广播(即,xy组播)的进一步说明性示例,如果在一个给定的周期内,图7c的noc上的每个客户端(x,y)一次全部同时向其相应的路由器输入从(x,y)到(*,*)的广播报文,则将递送总计16×16=256条报文(从4×4=16个客户端中的每一个到所有的16个客户端(包括源客户端)的对应报文)。但是在此实施例中,递送这256条报文将总计需要仅20个时钟周期!广播报文递送的一个关键用例是通过向noc上的许多或所有客户端广播报文来流传输从作为noc的一个输入客户端附接的外部接口核到达的数据。在这种特殊情况下,因为广播流输入客户端将在每个周期以全链路带宽输入广播报文,所以不会发生偏转(假设没有其他客户端正生成报文i)。因此,一旦流传输正在进行,广播报文就将在每个周期内递送至每个noc客户端(包括源客户端)。如果流传输广播报文注入速率小于每个周期的一个报文,则与其他报文生成客户端共享noc可能是实用的。虽然以上组播示例已经逐个步骤说明了一次递送一条组播报文,但是在实施例中,繁忙环面noc可能具有许多类型(普通点对点、x组播、y组播、广播)的许多报文在飞行,同时横穿网络。值得注意的是,在实施例中,传输普通点对点报文的相同路由器也可以执行各种组播报文递送,而无需对路由器交换电路330(图3)进行任何改变,并且不会增加fpga的资源使用。唯一的附加“成本”是用于生成并跟踪‘nx’寄存器状态的电路系统以及稍微更复杂的mcdor路由电路350(图3)。通过以下verilog源代码描述并表示了mcdor路由函数逻辑电路350(图3)的实施例,其并不旨在是限制性的:在实施例中,mcdor路由函数逻辑的结构遵循以上所描述的dor路由器的结构,并且针对路由器输入报文的组播路由添加了特定附加行为,所述路由器输入报文的报头mx字段和my字段指示组播x、组播y或组播xy递送。与dor不同,根据mcdor路由的组播报文输入可以被路由到x输出和y输出两者,并且mcdor可以断言x输出有效(x.v)信号、y输出有效(y.v)信号和客户端输出有效(o_v)信号中的任何一个或全部(图3)。因为每个路由器300(图3)可以容易地被配置有应用专用路由电路,所以还可能设计取代或扩大mcdor的x组播、y组播和xy组播递送模式的实施例,例如,将报文路由至目的地的位设置、noc的特定象限、noc的偶/奇行或列、或者noc的路由器的其他任意子集等。因为路由电路输入包括整个输入报文yi、xi、i,所以还可以由客户端通过将路由函数指示数据位添加至报文数有效载荷宽度dw来提供附加路由函数输入数据。平面规划的noc和工具在fpga设计和fpga电子设计自动化cad工具的领域中,大型设计的平面规划(即,在物理裸片布置的特定点处的设计的子电路布局)是允许系统设计者计划、表达和控制高级系统实现,实现有条理和确定性结果,以及实现时序收敛的重要工具。代替平面规划,fpga布局布线工具及其各种优化过程可以将高度有序和结构化的分层设计减少到散布在裸片周围的一组非结构化的无定形斑点。因此,对大型设计使用布局和布线工具可能会使设计的基本设计可布线性和时序收敛受到挑战。例如,只是在子模块设计中的小修正都可能导致设计的大部分或甚至整个设计的新的物理布局,伴有一些导线延迟增加,因此生成可能违反时序约束的新的关键路径。将2d路由器的平面规划noc安排成行和列可以为系统平面规划以及为fpgacad工具优化提供有利的工具。通过对noc、路由器或路由器的子电路及其客户端核进行平面规划,可以将其紧紧地封装到整洁的矩形区域中。这允许这些部件操作更快,因为关键的控制信号不需要横穿跨裸片的较大路径,并且确保路由器逻辑和互连不会“溢出”到客户端核的用户逻辑中。通过平面规划,路由器间链路连接可以在可编程互连中采用可预测的直接路由,并且提供可预测和可重复的设计实现并简化系统时序收敛。通过对noc进行平面规划,并通过使用连接到附近的hoplite路由器来替换到远距离模块的长通信链路,不需要长度超过裸片尺寸的几分之一的导线。更短的导线通常等于更快的信号传送和更高的操作频率。此外,高带宽noc、跨越裸片、使数据到/从各种高速接口(比如100g网络和dram通道)到fpga的任何扇区的实用性,大大简化了复杂的片上系统设计。通过使用本文中所公开的fpga高效noc,使用dram通道的客户端核不再需要在物理上与那个通道相邻。这是显著优点,因为只有这么多客户端核可以与任何高带宽资源相邻,并且如果大量客户端核都使用这类资源,则将所述客户端核全部放置和互连的高效方式就是使用这种noc。图8a至图8c是两个所实现的具有大型平面规划hoplitenoc的赛灵思fpga设计的实施例的简图。图8a是如可以在大规模并行处理器或加速器阵列中采用的w=50位报文的18×24(432个路由器)折叠2d环面noc的平面布局图。图8b和图8c是如可以在高性能计算或网络加速器应用中采用的w=576位报文的5×10(50个路由器)折叠2d环面noc的平面布局图。图8b是在赛灵思kintexultrascaleku040设备中实现的50路由器noc设计的裸片图(平面布局打印输出)的照片;图8c是与图8b中相同的设计的简图。在此示例中,每条链路承载总共180gbps的数据带宽,包括每个周期(150gbps)的512位存储器数据字。所述noc足以将8通道全速2400mhzddr4dram流量、128gbpshbmdram流量、或100gbps网络流量路由到fpga中的任何点处的任何客户端核和从所述任何客户端核中路由。所实现的路由器800、840、810、820、830、809、801、808等展示了环面是空间折叠的(其中,路由器布局是交织的),以便最小化跨环面的最差导线网长度。也就是说,路由器800(即,路由器(0,0))的yi输入来自路由器809(即,路由器(0,9))的y输出。路由器800的y输出进入路由器801(即,路由器(0,1))的yi输入。并且路由器800的xi输入来自路由器840(即,路由器(4,0))的x输出。并且路由器800的x输出进入路由器810(即,路由器(1,0))的xi输入。图9a是根据实施例的fpga高效技术映射和平面规划设计的裸片图的一个区域的照片,视口被放大用于呈现来自图8b的一个平面规划的576位hoplite路由器核。值得注意的是充分利用了在较深色调中所看到的许多逻辑单元点。这里看到,八个6-lut和16个触发器的许多赛灵思逻辑集群(切片)填充有计算寄存在16个触发器中的同一切片中的下一个x输出和y输出的16个位的八个6-lut。通过较早在图5e处描述的有利的赛灵思6-lut路由器交换技术映射优化来促进这种密集的实施方式。图9a还描绘了一些不具有逻辑单元的区域。这些区域代表了不被路由器实现消耗并且保持可供系统中的其他逻辑(例如,相邻的客户端核(如果有的话))使用的嵌入式块ram和嵌入式dsp块。图9b是根据实施例的另一个fpganoc平面布局的简图,其是不具有用于客户端核的内部空间的密集型的,是8×8(64个路由器)折叠2d环面noc,每个路由器具有w=256位链路,具有适合用于主控大型100gb/s以太网交换结构的2.2ns时钟周期(110gb/s带宽/链路)。在实施例中,如果n个以太网网络接口核(nic)被放置在n×n环面noc中的某些路由器点处(比如,在路由器位置(0,0)、(1,1)、……、(n-1,n-1)处),则从任何nic输出端口到任何nic输入端口的以太网流量数据报文可以以全带宽(通常无偏转)实现高效网络交换结构。更具体地,fpga900包含包括多个nic和8×8=64个hoplite路由器902(每一个路由器通过w=256位链路(为了清楚起见未示出)互连以形成8条x环和8条y环)的电路。包括路由器902和910的某些路由器在路由器坐标(0,0)、(1,1)、……、(7,7)处连接至nic客户端(比如906和908)。从在路由器(i,i)902处的nic[i]客户端906到在路由器(j,j)910处的另一nic[j]客户端908的任何报文进入在路由器(i,i)902处的noc,横穿在其x环上的路由器到路由器(j,i),然后在y环(x=j)上路由至路由器(j,j)910。此实施例包括将客户端核分配给路由器(在对角线上)以降低报文路由偏转的速率。在实施例中,如果多个noc客户端核被放置在环面noc中的不相交的x点和y点(比如在对角线上(0,0)、(1,1)、……、(n-1,n-1)),则报文流量可以在noc上从任何客户端输入端口到任何客户端输出端口以全带宽路由,通常无需偏转。例如,在具有以太网nic客户端核的实施例中,所述设计实现了高效且通用的以太网网络交换结构。图10是根据实施例的图8b系统的一个子电路的赛灵思实施后技术映射电路示意图的简图,其包含了至少5×10×576=28,800个这种子电路。图10展示了整体hoplite路由器和noc设计(本文中公开了其实施例)实现的极端电路效率(有人称为极端电路优化)。结合图10所描述的实施例涉及赛灵思实施方式,并且交换电路1004类似于以上结合图5e所描述的交换电路。这里,在上游路由器的报文有效载荷触发器x[i]、x.v、y[i]、y.v与此路由器的报文有效载荷输出触发器x[i]、y[i]之间只有一个lut延时(门延时)。选择路由器输入触发器如下。上游x环路由器1020和下游y环路由器1030的一些输出触发器如下:触发器1032生成y报文有效信号;触发器1034生成y报文数据有效载荷位(许多之一);触发器1022生成x报文有效信号;并且触发器1024生成相应的x报文数据有效载荷位(许多之一)。在1001处,这些信号在输入xi.v、yi.v、xi[i]、yi[i]输入至路由器1000,并且在输入i[i]上输入客户端报文数据有效载荷位。逻辑电路1002负责根据xi、yi和i报文输入来确定x和y交换多路复用器选择控制sel[1:0](类似于图3的信号352和354)。逻辑单元1004包括被分割成分别计算下一个x输出报文位和y输出报文位的两个普通5输入lut1006和1008的双输出6-lut。每个5-lut具有五个输入:sel[1]、sel[0]、xi[i]、yi[i]、i[i];以及一个输出x_nxt[i]或y_nxt[j]。寄存在触发器1010和1012中的输出形成路由器的x[i]和y[i]的两个输出位。在此实施例中,路由器的交换机多路复用器选择控制子电路1002不使用门或lut——只是重新标记导线——因为仔细选择交换多路复用器lut1006和1008传递函数和dor路由函数逻辑(以上都进行了描述)使能直接使用输入报文的xi有效信号和yi有效信号来选择输出多路复用器传递函数。路由器和noc的示例性计算系统应用本文中公开了一种示例性fpga计算系统来展示和培养对路由器、noc和整体互连网络系统的实用性的理解。在此示例中,所述系统实现了大规模并行以太网路由器和数据包处理器。图11是根据实施例的包括计算设备1100的系统的顶级视图的简图。除了计算设备1100以外,所述系统包括以fpga1102实现的soc、具有nic外部接口客户端核1140的网络接口1106、具有pciexpress外部接口客户端核1142的pciexpress接口1114、所连接的pciexpress主机1110、具有dram通道外部接口客户端核1144的dram1120、具有hbm通道外部接口客户端核1146的hbm(高带宽存储器)设备、以及多处理器/加速器集群客户端核1180(核a到核f)。图12是根据实施例的图11的系统的一个集群“分块”的简图。所述分块包括hoplite路由器1200(与图11的路由器(1,0)相对应),所述hoplite路由器耦合至其他hoplite路由器(图12中未示出)并且耦合至多处理器/加速器集群客户端1210(与图11中的客户端核“a”1180相对应)。示例性集群1210包括八个32位risc软处理器核1220,具有指令存储器(iram)块ram1222,所述指令存储器块ram共享对也连接至加速器核1250的集群数据ram(cram)1230的访问。集群1210连接至路由器1200以通过noc发送和接收报文。请求集中器1224和4×4交叉开关1226的本地互连网络将处理器连接至包括多个块ram的多端口集群ram1230,并且连接至hoplitenoc路由器接口1240。在此示例系统中,集群核分块使用用于指令ram1222的四个块ram和用于集群数据ram1230的八个块ram。此配置使能由处理器到cram1230中进行高达四路独立的读取或写入以及由加速器(如果有的话)或由网络接口到cram中进行并发八路读取或写入。在本文中所描述的示例性计算系统中,所述系统包括十行×五列=50个这类多处理器/加速器集群核或总共50×8=400个处理器。noc用于在集群之间、集群与外部接口核之间(例如,用于加载或存储到外部dram)、以及直接在外部接口核之间将数据作为报文承载。在此示例中,noc报文大约300位宽,包括288位的数据有效载荷(32位地址和256位数据字段)。集群核1210还包括hoplitenoc路由器接口1240,所述hoplitenoc路由器接口将集群的存储器组连接至集群的hoplite路由器输入,从而使得从集群存储器组读取的报文可以在noc上经由在集群的hoplite路由器上的报文输入端口发送(输出)至另一客户端,或者从另一noc客户端接收的报文可以经由noc经由集群的hoplite路由器写入到集群的存储器组中。在此示例中,多个处理器核1220相互共享并且与hoplitenoc接口共享对本地存储器组的访问。因此,从noc中接收到本地存储器中的报文可以由集群处理器中的任何一个(或多个)直接访问和处理,并且相反地,集群的处理器可以在存储器中准备报文并然后使所述报文经由集群的hoplite路由器从集群发送到noc的其他客户端。在结合图11和图12描述的核1210、集群ram1230和网络接口1240的安排中,可以实现高吞吐量且低延迟的计算。可以在一个时钟周期内从noc中接收整个32字节的请求报文;然后可以调度多达八个处理器来并行处理所述请求;然后可以在一个时钟周期内将32字节的响应发送到noc中。这甚至可以跨集群1210的五十个实例中的一些在单个fpga设备上同时发生。在此示例中,计算集群1210可以包括以各种方式耦合至集群的其他部件的零个、一个或多个加速器核1250。加速器1250可以使用集群本地互连网络来直接读取和写入所共享存储器组。加速器1250可以耦合至软处理器1220并且以各种方式与在此处理器上执行的软件(例如但不限于:访问寄存器、接收数据、提供数据、确定条件分支结果、通过中断或通过处理器状态字位)进行交互。加速器1250可以耦合至hoplite路由器接口1240以发送或接收报文。在集群1210内,处理器核1220、加速器1250、存储器1222和1230以及hoplitenoc接口1240的互连使得可能组合这些部件来形成高效加速的计算引擎。可以在处理器核1220的一个或多个上执行最佳表达为软件算法的工作负荷的各方面。可以在一个或多个加速器1250上执行可以通过在专用逻辑电路中表达来加速或使更能量高效的各方面。各种部件可以通过直接通信链路和通过集群的所共享存储器1230来共享状态、中间结果和报文。在系统设计层级的顶级处,hoplitenoc对系统的nic1140、dram通道1114以及处理集群1210进行互连。因此,跨计算集群运行的应用可以充分利用所有这些资源。通过经由noc将报文发送至dram通道控制器1114,集群1210可以请求将报文数据有效载荷存储在dram中的某个地址处,或者可以请求dram通道控制器执行dram读取事务并且然后通过noc将在另一报文中的结果数据发送回到集群。以类似的方式,另一客户端核(比如nic)可以跨noc将报文发送至其他客户端。当nic接口1140接收传入以太网数据包时,所述nic接口可以将所述以太网数据包重新格式化为一个或多个noc报文并且经由noc将这些noc报文发送至dram通道接口1144以将数据包保存在存储器中,所述nic接口可以将这些报文发送至另一nic以便在另一以太网网络端口上直接输出数据包,或者所述nic接口可以将这些报文发送至计算集群以供数据包处理。在一些应用中,将某些报文组播到包括计算集群客户端1210的多个客户端可能是有用的。可以通过noc的组成部分hoplite路由器的用于实现组播报文路由的之前配置来实现组播递送,而不是将报文反复发送至每个目的地。在数据包横穿路由器时,此示例性多处理器系统的应用是作为在nic之间路由数据包的“智能路由器”,同时还以全吞吐量执行数据包压缩和解压缩以及对恶意软件的数据包嗅探。此特定示例不应该被解释为是限制性的,而是用来说明采用hoplitenoc互连系统的集成并行计算设备可以如何输入工作请求和数据、合作并经常并行地执行工作请求,并且然后输出工作结果。在这种应用中,网络数据包到达nic。nic接收数据包并将其格式化成一个或多个32字节报文。然后,nic经由noc将所述报文发送至特定计算集群客户端1210以供数据包处理。计算集群1210接收输入数据包报文并将其组装成在集群存储器中的原始数据包的副本。如果数据包数据是经压缩的,则在集群中的一个或多个软处理器对所述数据包执行解压缩算法,从而在存储器中形成新的未压缩数据包。给定未压缩数据包,恶意软件检测软件在一个或多个软处理器1220上执行以针对呈现特定恶意软件程序或代码串的特性签名的特定字节序列来扫描报文有效载荷的字节。如果找到潜在的恶意软件,则数据包不会被传送,而是被保存到dram存储器以供随后的‘离线’分析。如果未检测到潜在的恶意软件,则通过在软处理器的一个或多个上运行的压缩算法来压缩所述数据包。接下来,在软处理器1220的一个或多个上运行的数据包路由软件查询表来确定接下来将所述数据包发送到什么地方。可以更新所述数据包的某些字段,比如,“生存时间”。最后,数据包被格式化为一个或多个noc报文并且经由noc通过集群的hoplite路由器1200发送至适当的nic客户端核。当这些报文经由noc由nic接收时,所述报文被nic格式化成nic经由所述nic的外部网络接口传送的输出数据包。在此示例中,由在一个或多个计算集群客户端1210中的一个或多个软处理器1220可能以并行或流水线的方式在软件中执行解压缩、恶意软件检测、压缩、和路由的计算。在可替代实施例中,可以由在集群中的加速器核1250在专用逻辑硬件中执行这些步骤中的任何一个或全部,这些加速器核相互互连或者互连至集群的其他部件。在实施例中,针对给定的数据包,在一个计算集群客户端1210中进行数据包处理。在可替代实施例中,多个计算集群客户端1210可以以分布式方式合作处理数据包。例如,特定集群1210可以专门用于解压缩或压缩,然而其他集群可以专门用于恶意软件检测。在这种情况下,数据包报文可能从nic发送到解压缩集群1210。解压缩之后,解压缩集群1210可以将经解压缩数据包(作为一个或多个报文)发送到恶意软件扫描集群1210上。此处,如果未检测到恶意软件,则恶意软件扫描程序可以将经解压缩、经扫描数据包发送至路由集群1210。此处,在确定数据包的下一个目的地之后,路由集群1210可以将所述数据包发送至nic客户端1140以供输出。此处,nic客户端1140可以将所述数据包传送至所述nic客户端的外部网络接口。在此分布式数据包处理系统中,在实施例中,客户端可以经由某种形式的信号的直接连接与另一客户端进行通信,或者在实施例中,客户端可以经由通过noc传送的报文与另一客户端进行通信。在实施例中,通信可以是直接信号和noc报文的混合。可以以如下的fpga实现此示例性计算系统的特定实施例。再次,以下特定示例不应被解释为限制性的,而是用于说明本文中所公开的实施例的有利应用。fpga设备是赛灵思kintexultrascaleku040,其提供了总共300行×100列切片的八个6-lut=240,000个6-lut,并且每个6-lut具有600个36kb的bram(块ram)。此fpga被配置用于利用以下具体部件和参数来实现以上所描述的示例性计算设备。被配置用于组播dor路由的具有ny=10行乘以nx=5列的hoplite路由器并且具有w=256+32+8+4=300位宽链路的hoplitenoc形成所述系统的主要noc。fpga是平面规划成50路由器+多处理器/加速器集群,安排为矩形分块并排列成10×5网格布局,其中,每个分块跨240行乘以20列=4800个6-lut,并且具有12个bram。分块的fpga资源用于实现集群客户端核1210和集群的hoplite路由器1200。集群1210具有可配置数量(零个、一个或多个)的软处理器1220。在此示例中,软处理器1220是实现risc-vrv32i指令集架构的有序流水线式标量risc核。每个软处理器1220消耗大约300个6-lut的可编程逻辑。每个集群具有八个处理器1220。每个集群还具有实现八个软处理器1220的指令存储器1222的四个双端口4kbbram。每个集群1210还具有形成集群数据ram1230的八个双端口4kbbram。在bram阵列上的一组八个端口被安排用于实现四个地址交织的存储器组以便支持由软处理器1220进行的到四个组中的多达四路并发存储器访问。对于输入端口和输出端口各自都是32位宽、总共32位×8=256位的在同一bram阵列上的其他组八个端口可由加速器核1230(如果有的话)使用并且还连接至集群的hoplite路由器输入端口1202和hoplite的路由器y输出端口1204。路由器客户端控制信号1206(与图3的i_rdy和o_v相对应)指示路由器的y输出何时对于集群1210是有效输入,并且路由器1200何时准备就绪接受来自客户端1210的新报文。一组存储器组仲裁器和多路复用器1224、1226从来自八个处理器1220的并发读取和写入来管理对bram阵列的组访问。在此示例性系统中,在集群1210中的软处理器1220上运行的软件可以启动本地存储器的一些字节的报文跨noc发送到远程客户端。在一些实施例中,可以使用特殊报文发送指令。在另一实施例中,到与集群的noc接口控制器1240相对应的特殊i/o地址的定期存储指令启动报文发送。存储指令提供了存储地址和32位存储数据值。noc接口控制器1240将此解译为报文发送请求以将在本地“存储”地址处的1-32个字节复制到在noc上(以及在客户端内的目的地地址处)的由存储的32位数据值指示的目的地客户端。根据实施例,以三个示例展示图11和图12的系统操作的方法。1)为了将报文发送至另一集群1210中的另一处理器1220,处理器1220在其集群ram1230中准备报文字节,然后将所述报文存储(发送)到接收器/目的地。32位存储数据值对目的地集群的路由器1200的(x,y)坐标和在目的地集群的本地存储器阵列内的地址两者进行编码以接收所述报文的副本。noc接口控制器读取来自集群bram阵列的多达32个字节,将所述字节格式化成报文,并经由集群的hoplite路由器跨noc将所述报文发送至特定集群,所述特定集群接收所述报文并将报文有效载荷写入到所述集群的特定地址处的本地集群存储器中。2)为了通过特定dram通道1144将1-32个字节数据的块存储到dram,可能在传统dram中,可能在hbmdram设备的分段中,处理器存储(发送)数据块并提供32位存储数据地址,所述存储数据地址指示:a)所述存储去往dram而不是某个集群的本地集群存储器,以及b)在dram阵列内的用于接收数据块的地址。noc接口控制器1240从集群本地存储器阵列中读取1-32个字节,将所述字节格式化成报文,并经由集群的hoplite路由器1200跨noc将所述报文发送至执行所述存储的特定dram通道控制器1144。3)为了执行例如从dram通道1144到集群本地存储器的1-32个字节中远程读取1-32个字节数据的块,处理器1220在指定读取地址的本地存储器中准备加载请求报文和数据的本地目的地地址,并且通过noc将此报文发送至特定dram通道控制器1144。在由dram通道控制器1144接收到后,后者执行读取请求,从dram(例如,dram1120)中读取指定数据,然后对包括读取数据字节的读取响应报文进行格式化。dram通道控制器1144经由其hoplite路由器1200通过hoplitenoc将读取响应报文发送回发布读取的集群1210,其中,报文有效载荷(读取数据)被写入到集群本地存储器1230中的指定读取地址。此示例性并行计算系统是高性能fpga片上系统。跨所有5×10=50个集群1210,50×8=400个处理器核1220,以高达每秒400×333mhz=1330亿次操作的总吞吐量进行操作。这些处理器每个时钟周期可以并发地发布50×4=200次存储器访问,或每秒总共200×333mhz=670亿次存储器访问,这是267gbps(千兆位每秒)的峰值带宽。这50个集群的存储器1230中的每一个还具有加速器/noc端口,所述加速器/noc端口可以访问用于50×32字节/周期=1.6k字节/周期或533gbps的峰值加速器/noc存储器带宽的32字节/周期/集群。机器的总本地存储器带宽是800gbps。在hoplitenoc中的每条链路每个周期以333mhz承载300位报文。每条报文可以承载用于85gbps的链路有效载荷带宽和10×85=850gbps的noc平分带宽的256位数据有效载荷。在此示例性系统中的单个hoplite路由器1200的lut面积是用于路由器数据路径的300个6-lut和用于路由器控制/路由函数的大约10个lut。因此,此hoplitenoc1200的总面积是大约50×310=15,500个lut或只是总设备lut的6%。相比而言,软处理器核的总面积是50×300×8=120,000个lut或大约设备lut的一半(50%),并且集群本地存储器互连多路复用器和仲裁器的总面积是大约50×800=40,000个lut或设备的17%。如较早所描述的,在此持续性示例系统中,当报文到达每个nic时,由一个或多个集群逐个处理报文。在另一实施例中,50个计算集群1210的阵列被视为“加特林机枪(gatlinggun)”,在所述阵列中每个传入数据包被作为noc报文发送到不同的空闲集群。在这种变体中,可以将新的数据包发送到集群以按严格的循环顺序处理,或者正当其他集群花费更多时间来处理更大或更复杂的数据包时数据包可以被发送到空闲集群。在25g(25gbps带宽)网络上,每(800位/25e9b/s)=32ns可以有100字节(800位)报文到达nic。当每个所接收数据包(作为四个32字节noc报文)从nic转发至特定集群1210时,此集群(50个之一)在多达50个数据包到达间隔内排他地处理此数据包直到必须完成此处理,并准备接收其下一个数据包。集群数据包处理时间间隔为50×32ns=1600ns或1600ns/3ns/周期=533个时钟周期,并且利用8个软处理器1220,集群可以贡献533个周期×8个处理器×多达1指令/周期,例如,每个数据包上多达4200条指令处理。相比而言,传统fpga系统不能在如此短时间内对数据包执行如此多的通用可编程计算。对于超出网络数据包压缩和恶意软件检测的应用,可以通过将专用的(多个)加速器功能核添加至软处理器1220或添加至集群1210来进一步提高吞吐量。除了基于报文传递的编程模块,系统的实施例还是主控数据并行编程模块(比如opencl)的高效并行计算机。每个并行内核调用可以被调度至或分配至系统中的集群1210中的一个或多个,其中,opencl工作组中的每个线程都被映射至集群内的一个核1220。经典的opencl编程模式为:1)从外部存储器到本地/工作组存储器中读取数据;然后2)本地、并行、跨多个核处理所述数据;然后3)将输出数据写回到外部存储器,很好地映射到结合图11和图12所描述的架构,其中,执行许多存储器加载和存储的内核执行的这些第一阶段和第三阶段通过向或从任何dram控制器的外部接口客户端核发送大型32字节数据报文(与每个周期一样频繁)来实现高性能和高吞吐量。总之,在此示例中,hoplitenoc通过提供其各种客户端(计算集群核、dram通道接口核和网络接口核)的高效互连来促进新颖并行计算机的实现。noc使通过发送报文(或组播报文)进行通信的跨计算集群的计算变得容易。通过将极端带宽数据流量高效地承载到fpga中的任何点,noc简化了系统的物理布局(平面规划)。在fpga中的任何点处的系统中的任何客户端都可以以高带宽与任何nic接口或与任何dram通道接口进行通信。这种能力对于充分利用集成hbmdram和其他裸片堆栈的高带宽dram技术的fpga来说可能特别有利。这种存储器以1gbps到2gbps提供八个或更多个dram通道,128位宽的数据(128gbps/通道到256gbps/通道)。hoplitenoc配置(比如,在此示例性计算系统中所演示的)高效地使得核能够以全存储器带宽从fpga裸片上的任何地方访问在任何dram通道上的任何dram数据。据信,任何传统系统或网络技术或架构都不能提供这种能力。为了说明用于实践以上所描述的系统的实施例的示例减少,图13a至图13d是展示了这种系统及其noc的物理实现和平面规划的不同方面的四个裸片图的简图。图13a是根据实施例的fpgasoc整体的简图。图13a覆盖了将fpga的逻辑细分成50个集群的视图,所述50个集群标记为x0y0、x1y0等直到x4y9,在系统中的所有逻辑的布置之上。深色点放置了软处理器核1220(图12)(总计400)及其块ram存储器(图12的iram1222和cram1230)。图13b是根据实施例的在折叠2d环面中布置路由器+集群分块的分块的高级平面布局的简图。路由器和路由器寻址(例如,x0y0、x4y0、x1y0、x3y0、x2y0)的物理折叠(交织)安排减少了设计中长而慢的裸片路由器网(导线)的数量或使其消除。图13c是根据实施例的所述设计的明确放置的平面规划的元件的简图。此系统包括软处理器1220(图12)的“关系放置的宏”的400个副本——在图13c中,每个四行乘以五列安排的点(表示包括八个6-lut的fpga‘切片')与一个处理器的32位risc数据路径相对应。存在总共40行乘以10列的处理器1220。这些处理器1220进而被组织成四行两列的处理器的集群。另外,在图13c中的竖直黑色条纹与600个明确放置的块ram存储器相对应,所述块ram存储器实现在50个集群(每个具有12bram((4个iram,8个集群数据ram)))中的每一个内的指令和数据存储器(图12的1222和1230)。图13d是互连集群1210(图12)的noc的逻辑布局的简图。每条粗黑线与x环和y环的路由器之间的任意方向上的大约300个网(导线)相对应。注意,按照图13a和图13b,noc是折叠的,因此,例如,网从x0y0分块跨过x4y0分块到x1y0分块。图14是根据实施例的耦合至配置固件存储器1423的fpga1410的简图。图14展示了在由fpga实现工具进行处理之后,在fpga配置比特流文件中所显现的所公开的路由器、noc或应用系统设计;此文件存储在配置flash存储器或类似的计算机可读介质中;此配置比特流经由其配置端口输送至fpga,并且然后输送至其配置系统,以便内部加载比特流文件并且以便配置设备的无数可编程逻辑元件和互连结构,从而实现fpga电路系统被配置为所公开的路由器、noc或系统。在实施例中,可以以fpga实现所公开的路由器、noc、客户端核或系统。fpga设备提供各种可编程的并且通常是可再编程(即,可重新配置)的逻辑资源,包括查找表、存储器、嵌入式功能块以及互连这些资源的可编程互连结构(即,“可编程布线”资源)。为了实现特定电路或功能(比如,所公开的路由器、noc或系统),借助于配置电路对fpga进行配置。配置电路加载被称为配置比特流的数据文件。配置比特流是用于fpga确定设备中的数百万配置单元的设置的特殊类型的固件。每个配置单元控制可编程逻辑设备的某个方面。一些配置单元形成fpga的查找表可编程逻辑门的真值表。一些配置单元控制形成可编程互连结构的传输门和多路复用器选择行,以选择性地将一个门的输出路由至特定其他门的特定输入。在配置比特流文件中存在的大量配置数据中显现了现代fpga显著的灵活性和可配置性程度。例如,赛灵思ultrascalevu440设备配置比特流文件长度超过十亿个位。不具有建立逻辑门和互连门的可编程布线以对时钟分布进行编程、设置嵌入式存储器等等的配置比特流的情况下,fpga根本不实现任何电路,是惰性的和无用的。大多数fpga设备采用cmos存储器单元用于配置单元。此存储器是易失性的;如果fpga曾经断电,则其配置存储器将丢失,并且只是与常规计算机一样,一旦加电,则配置比特流文件然后从另一个源(通常是非易失性存储器设备,比如flash存储器芯片)重新加载。其他fpga设备可以采用非易失性配置单元(例如,闪存单元),使得一旦最初使用配置对其进行编程,则将跨电源周期保留所述配置。尽管在这些设备中,配置比特流文件至少被加载或下载一次以实现特定的期望逻辑设计或系统。如图14中所展示的,系统1400包括fpga1410、在其内存储有fpga的配置比特流文件的闪存设备、以及各种外部设备和接口(诸如以太网网络、dram存储器和pciexpress主机)。在加电时,fpga是未经配置的并且还不能执行有用的功能。使用其配置端口1420,fpga1410通过配置信号总线1422将配置比特流文件从配置比特流闪存1424逐个比特、逐个字节地加载到fpga的配置端口1420中。在fpga1410上的电路加载比特流,可选地检查所述比特流有效性,可选地对所述比特流进行解密,并且将所述比特流逐个比特地加载到跨fpga的配置单元中。当整个配置比特流已经加载完成并且fpga的配置单元已经初始化时,那么fpga1410“醒来”被配置为所公开的路由器、noc或系统。使用noc来互连很多不同的客户端核梅特卡夫定律表明:电信网络的价值与系统所连接用户数量的平方成正比。类似地,noc和实现noc的fpga的价值是noc客户端核的数量和类型多样性的函数。出于这种原则考虑,本文中所公开的noc的设计理念和主要愿望是“高效地连接一切”。不受限制地,许多类型的客户端核可以连接至noc。参照图11和图12,一般而言,存在普通的(片上)客户端核1210(例如,加固的(非可编程逻辑)处理子系统)、软处理器1220、片上存储器1222和1230或者甚至多处理器集群1210;并且存在用来将fpga连接至外部接口或设备的外部接口客户端核,诸如,网络接口控制器(nic)1140、pciexpress接口1142、dram通道接口1144以及hbm通道接口1146。当这些外部接口核属于noc时,所述外部接口可以高效地使得外部设备能够与片上或外部的noc的任何其他客户端进行通信,并且反之亦然。本公开的这个部分描述了如何将各种片上和外部设备连接到noc及其其他客户端核。接口连接至fpganoc的外部设备的一个关键类别是存储器设备。一般而言,存储器设备可以是易失性的,诸如静态ram(sram)或动态ram(dram),包括双倍数据速率(ddr)dram、图形双倍数据速率(gddr)、四倍数据速率(qdr)dram、减少延迟的dram(rldram)、混合存储器立方体(hmc)、wideiodram和高带宽存储器(hbm)dram。或者,存储器设备可以是非易失性的,诸如rom、flash、相变存储器或3dxpoint存储器。通常每个设备或设备组(例如,dramdimm存储器模块)具有一个存储器通道,但是新兴的存储器接口(比如hmc和hbm)为每个设备提供了许多高带宽通道。例如,单个hbm设备(裸片堆栈)以1gbps/信号到2gbps/信号的信号传送速率提供八个通道的128个信号。fpga供应商函数库和工具提供了外部存储器通道控制器接口核。为了将这种客户端核互连至noc(即,将客户端互连至路由器的报文输入端口和报文输出端口),可以使用桥电路来接受来自其他noc客户端的存储器事务请求(例如,加载或存储字节块)并且将所述存储器事务请求呈现给dram通道控制器(并且反之亦然)以便接受来自存储器通道控制器的响应,将所述响应格式化为noc报文,并且经由路由器将所述报文发送至其他noc客户端。本文中所公开的示例性并行数据包处理系统描述了noc客户端,所述noc客户端可以将dram存储报文发送至dram控制器客户端核以将一个字节或多个字节存储到ram中的特定地址,或者可以发送dram加载请求报文以使得dram通道客户端在dram上执行读取事务,然后通过noc将所产生的数据传送回在请求报文中所标识的目标(集群、处理器)。作为另一个示例,以上结合图1所描述的示例性fpgasoc示出dram控制器客户端可以如何从pciexpress控制器客户端核接收命令报文以便读取存储器块,并且然后作为响应,通过noc将读取的数据字节,不是传送回最初的pciexpress控制器客户端,而是传送至以太网nic客户端核,从而将所述数据字节作为数据包在某个外部以太网网络上传送。本文中所公开的面积高效noc的实施例使得允许fpga中的任何点处的连接至某个路由器的任何客户端核经由任何存储器通道控制器客户端核访问任何外部存储器的系统成为可能。为了充分利用外部存储器的潜在带宽,可以实现非常宽且非常快的noc。例如,64位ddr42400接口可以以高达64位乘以2.4ghz=大约150gbps的速率传送或接收数据。以333mhz运行的通道宽度w=576位(512位数据和64位地址和控制)的hoplitenoc每条链路可以承载高达170gbps的数据。在具有流水线式互连结构(比如阿尔特拉hyperflex)的fpga中,以667mhz运行的288位路由器的288位noc同样足够。在一些实施例中,采用通过多个dram通道将多个dram设备组互连至fpga来向fpgasoc提供必要的带宽来满足工作负荷的性能需要。尽管多个外部dram通道可能被聚合成与noc上的一个路由器耦合的单个dram控制器客户端核,但是这可能不会向noc上的其他客户端核提供对多个dram通道的全带宽访问。而是,实施例为每个外部dram通道提供其自己的全带宽dram通道控制器客户端核,每个耦合至单独的noc路由器,在dram控制器客户端核与noc的其他客户端之间提供dram请求报文的高并发和全带宽的入口和出口。在一些用例中,不同的存储器请求noc报文可以使用不同的最小位宽报文。例如,在以上结合图11和图12所描述的示例性并行数据包处理fpgasoc中,在多处理器/加速器集群客户端核中的处理器发送dram存储报文以将32字节从所述处理器的集群ram传递到dram通道控制器接口客户端核。300位的报文(256位数据,32位地址、控制)足以将命令和数据承载至dram通道控制器。相比而言,为了执行存储器读取事务,处理器将dram加载请求报文发送至dram通道控制器。这里,64位报文足以承载存储器的待从dram中读取的地址,并且在其集群存储器内的目标地址接收存储器读取。当此报文在dram通道控制器客户端核上被接收和处理,并且从dram读取数据时,dram通道控制器发送dram加载响应报文,其中再次,300位的报文足够。在此场景中,对于一些300位的报文和一些64位的报文,较短的报文可以通过用0个位填充报文、通过将若干这类请求封装到一个报文中、或者通过使用其他常规技术来使用300位宽的noc。可替代地,在所述系统的其他实施例中,系统设计者可以通过在设计中对两个并行noc实例化来选择以实现soc的dram存储器系统,所述两个并行noc为300位宽的noc和64位宽的noc,一个用于承载具有32字节数据有效载荷的报文,第二个用于承载不具有这种数据有效载荷的报文。因为hoplite路由器的面积与其交换数据路径的位宽成正比,所以具有300位noc和附加64位noc的系统比单独具有300位noc的系统需要少于25%的更多的fpga资源。在此双noc示例中,发布dram加载报文的客户端核1210是两个noc的客户端。也就是说,客户端核1210耦合至第一300位报文noc路由器,并且也耦合至第二64位报文noc路由器。客户端和路由器的这种安排的优点在于,较短的dram加载请求报文可以分别横穿其自己的noc,并且不会与横穿其noc的dram存储和dram加载响应报文争用。作为结果,dram事务报文的更大总数量可能同时跨这两个noc飞行,并且因此对于给定的fpga资源面积和给定的能量消耗可以提供更高的dram流量总带宽。一般而言,在系统中使用多个noc并且将某些客户端核选择性耦合至多个noc的某些路由器可能是所公开路由器和noc的有利安排和实施例。相比而言,在更低效传统noc系统中,每个noc消耗的大量fpga资源和能量使得在系统中对多个并行的noc实例化是不切实际的。为了将fpgasoc(及其许多组成客户端核)接口连接至高带宽存储器dram设备(其以1ghz到2ghz提供了八个通道的128位数据),系统设计可以使用例如而不限于耦合至八个noc路由器核的八个hbm通道控制器接口客户端核。具有128gbps链路的noc足以到和从以1ghz操作的128位的hbm通道承载全带宽存储器流量。另一种类型的裸片堆栈高带宽dram存储器是混合存储器立方体。与采用非常宽并行接口的hbm不同,以15gbps/引脚的速度操作的hmc链路在更少的引脚上使用多个高速串行链路。根据实施例,fpga接口连接至hmc设备,因此,使用多个串行解串器(串行/解串器块)来向hmc设备传送数据并从所述hmc设备中传送数据。尽管存在这种信号传送差异,但是如何经由noc将fpgasoc中的多个客户端核最佳地耦合至hmc设备的考虑与以上所描述的hbm系统的实施例非常类似。hmc设备在逻辑上作为众多的高速通道进行访问,每个通道通常具有64位宽。每个这种通道可以采用hbm通道控制器接口客户端核来将此通道的数据耦合到noc中,以使noc上排列的许多客户端核能够访问hmc设备的显著的总存储器带宽。第二类别的外部存储器设备,非易失性存储器(nvm)(包括flash和下一代3dxpoint存储器)通常以较低带宽运行存储器通道接口。根据实施例,这可以提供使用配置有较低带宽链路的较少资源密集型的noc。包括较窄链路和相应地更小路由器的较窄noc(例如,w=64位宽)可能就足够。可替代地,系统可以包括外部nvm存储器系统,所述nvm存储器系统包括封装在dimm模块中并且被配置用于提供ddr4dram兼容的电气接口的大量nvm设备,例如,flash存储器阵列或3dxpoint存储器阵列。通过将多个nvm设备聚集在一起,可以实现到设备的高带宽传递。在此情况下,根据实施例,使用高带宽nvm通道控制器客户端核和相对更高带宽noc和noc路由器可以向noc的客户端核提供对nvm存储器系统的全带宽访问。以类似的方式,根据实施例,其他存储器设备和存储器系统(即,存储器设备的组成和安排)可以经由一个或多个外部存储器接口客户端核接口连接至fpganoc及其其他客户端核。现代fpgasoc的另一类别的重要外部接口是网络接口。现代fpga直接支持10/100/1000mbps以太网并且可以被配置用于支持10g/25g/40g/100g/400gbps以太网以及其他外部互连网络标准和系统,包括而不限于因特拉肯(interlaken)、rapidio和infiniband。使用osi参考模型层(例如,应用层/演示层/会话层/传输层/网络层/数据链路层/物理(phy)层)来描述网络系统。大多数系统在硬件中实现网络堆栈的较低两层或三层。在某些网络接口控制器、加速器和数据包处理器中,还采用硬件(包括可编程逻辑硬件)来实现网络堆栈的较高层。例如,tcp卸载引擎是用于在硬件中在网络接口控制器(nic)处卸载tcp/ip堆栈的处理的系统,而不是在软件中进行连接建立、数据包确认、检查求和等tcp内务处理(这些可能太慢以至于无法跟上非常高的速度(例如,10gbps或更快)的网络)的系统。在以太网/ieee802.3系统的数据链路层内是mac(介质访问控制电路)。mac负责以太网成帧和控制。其耦合至物理接口(phy)电路。在一些fpga系统中,对于一些网络接口,phy以fpga本身来实现。在其他系统中,fpga耦合至模块化收发器模块(比如,sfp+格式),其取决于模块的选择,根据某种电学或光学接口标准(比如base-r(光纤)或base-kr(铜背板))来传送和接收数据。网络流量是以数据包的形式传送的。传入数据从其phy到达mac,并且由mac将其成帧为数据包。mac将此成帧的数据包数据以流的形式呈现给通常与可编程逻辑裸片上的mac相邻的用户逻辑核。根据实施例,在包括所公开的noc的系统中,通过使用耦合至noc路由器的外部网络接口控制器(nic)客户端核,位于设备上的任何地方的其他noc客户端核可以将网络数据包作为发送至(从中接收)nic客户端核的一个或多个报文来传送(或接收)。以太网数据包有各种大小——大多数以太网帧的长度为64字节到1536字节。因此,为了通过noc传送数据包,将数据包分段成一系列一个或多个noc报文是有益的。例如,横穿256位宽noc的大型1536字节以太网帧可能需要待从nic客户端核输送到另一noc客户端核的48个256位报文,或者反之亦然。在接收到数据包(由报文组成)后,取决于客户端核的包处理功能,客户端可以将所述数据包缓冲在片内或外部存储器中以供后续处理,或者所述客户端可以检查或变换所述数据包,并且随后或者丢弃所述数据包,或者立即将所述数据包重新发送(作为另一个报文流)到另一个客户端核,如果所产生的数据包应该在外部传送,所述另一个客户端核可能是另一个nic客户端核。为了实现用于接口连接到将网络数据包作为一系列noc报文传送的nic客户端核的hoplite路由器noc的实施例,设计者可以配置hoplitenoc路由器以按顺序递送。本文中之前所公开的基本hoplite路由器实施方式的实施例不保证从客户端c1发送到客户端c2的报文m1、m2序列将按照报文被传送的顺序到达。例如,在将报文m1和m2从在路由器(1,1)处的客户端c11发送到在路由器(3,3)处的客户端c33后,可能出现当报文m1经由x环[y=1]到达在中间路由器(3,1)处的x报文输入,并且试图接下来路由至在y环[x=3]上的路由器(3,2)时,在此同一时刻,在路由器(3,1)的yi输入上的更高优先级输入被分配给路由器的y输出。因此,报文m1偏转至路由器(3,1)的x输出,并且横穿x环[y=1]以返回到路由器(3,1)并且重新尝试在路由器的y输出端口上外出。同时,报文m2到达路由器(3,1),并且稍后到达路由器(3,3),并且被第送至耦合至路由器(3,3)的客户端(3,3)。然后,报文m1返回到路由器(3,1),在此路由器的y输出端口上输出,并且被第送至路由器(3,3)的客户端(3,3)。因此,以m1然后m2的顺序发送报文,但是以相反顺序m2然后m1接收。对于一些用例和工作负荷,报文的无序递送是好的。但是对于递送作为一系列报文的网络数据包的当前用例,对于客户端处理无序报文可能是繁冗的,因为客户端在其开始处理数据包之前被迫首先“重组”数据包。因此,在实施例中,具有可配置路由函数的hoplite路由器可以被配置有确保在任何特定源路由器与目的地路由器之间有序递送一系列报文的路由函数。在实施例中,此配置选项还可以与组播选项向组合来同样确保有序组播递送。在实施例中,路由器是不可配置的,但是虽然如此所述路由器却被配置用于实现有序递送。存在各种方法来实现有序报文递送。实施例向无状态的基本路由器添加称为deflect的小型表或存储器,所述小型表或存储器记住最近由路由器偏离所述路由器的优选输出端口的某个报文。存在具有不同面积/性能折衷的偏转表的各种可能的实施例。最简单的一个是单个位,当其x坐标与路由器的x坐标相对应的报文由于输出端口争用而无法在路由器的y报文输出中输出时被设置,并且围绕x环偏转。这种表的另一个实施例是通过x输入上的报文的目的地y坐标索引的一位宽ram。如果设置偏转[x.y],则意味着具有目的地(x,y)的某个之前的报文已经偏转,并且因此,当前报文如果去往(x,y)的话,同样被迫偏转(否则,所述当前报文将在之前偏转的报文前面到达其目的地)。这种偏转表的另一个实施例是通过x输入上的报文的源x坐标索引的一位宽ram。(在这种情况下,noc生成器或设计者将源x坐标添加至报文有效载荷以便所述报文对当前路由器的路由函数可用。)在此实施例中,当且仅当来自在(x.src.x,x.src.y)处的路由器的某个报文已经偏转时,设置偏转[x.src.x],并且因此,如果当前报文共享相同的路由器源x坐标并且去往(x,*),当前报文同样被迫偏转以确保去往(x,y)的报文有序到达。偏转表的另一实施例是二维的,通过报文的源x坐标和目的地y坐标索引的一位宽ram。在此实施例中,当从特定源路由器到特定目的地(x,y)的某个之前报文已经偏转时,设置偏转[x.src.x][x.y],以使得从相同的源到相同的目的地的另一个随后的报文同样被迫偏转。在实施例中,还存在一种重置路由器中的偏转表的条目的机制。在实施例中,此机制是路由器本地的延时结构(比如移位寄存器),被称为undeflect,其中,延时(或深度)大约等于路由器x环的直径(即,尺寸),所述机制记录最近已经设置了哪个偏转表条目(如果有的话)。在实施例中,每个x环直径的单个状态位就足够。每次路由器路由输入报文(即,与每个时钟周期一样频繁),最老的位从undeflect中移除。这个位与路由器的到目的地(x,y)的当前x输入报文相对应,如果所述报文之前已经偏转,则其现在环绕整个x环并且将重新尝试路由到路由器的y输出报文端口上。在偏转表中的相应的条目进行重置。这提供了当前x输入报文根据需要路由到y报文输出的机会。如果再次由于y输出端口争用,x输入报文被迫偏转,则在偏转表中的相应的条目再次进行设置,新的‘1’位被添加至未偏转结构,并且再次,可能去往所述报文的目的地的其他报文也将偏转,确保最后路由至目的地路由器的y环的有序报文递送。在另一个实施例中,未偏转状态不保留在每个路由器处,而是被添加到x环报文数据,或者以其他方式与x环报文一起传播。当所述报文环绕时,伴随了其未偏转标记,并且再次环绕时,老的偏转表条目可以相应地被清除。设想了偏转机制和未偏转机制的可替代实施例。根据实施例,使用所公开的有序报文递送方法的实施例,将各种nic客户端核1140(图11)耦合至noc是简单的。报文格式被选择用于将数据包数据作为一系列报文来承载。在实施例中,报文可以包括源路由器id字段或源路由器(x,y)坐标。在实施例中,报文可以包括报文序列号字段。在实施例中,这些字段可以由目的地客户端使用来将传入报文重组成数据包的图像。在实施例中,在数据包从nic客户端1140逐个报文到达时,目的地客户端对所述数据包进行处理。在实施例中,对数据包流动以及因此报文流动进行调度,以使得目的地客户端可以假设每次所有的传入报文一次来自一个客户端,例如,不必将传入报文同时重组成两个或多个数据包。许多不同的外部网络接口核客户端可以耦合至noc。nic客户端1140可以包括简单的phy、mac或更高级网络协议实现(比如tcp卸载引擎)。在实施例中,phy可以以fpga、以外部ic来实现,或者可以以收发器模块(其可以使用电学或光学信号传送)来提供。一般而言,noc路由器和链路宽度可以被配置用于支持noc的全带宽操作以供预期的工作负荷。对于1gbps以太网,几乎任何宽度和频率的noc都将足够,然而对于100gbps以太网,大约每6ns就有64字节数据包到达nic;因此,为了在noc上实现100gbps带宽,宽的快速路由器和链路与较早所公开的用于承载高带宽dram报文的那些相当。例如,以400mhz操作的256位宽noc或以200mhz操作的512位宽noc足以在客户端核之间以全带宽承载100gbps以太网数据包。fpga片上系统的实施例包括单个外部网络接口,并且因此在noc上包括单个nic客户端核。另一实施例可以使用多种类型的多个接口。在实施例中,单个noc足以将这些外部网络接口客户端核互连至noc上的其他客户端核。在实施例中,nic客户端核1140可以连接至用于‘数据平面’数据包路由的专用高带宽noc,并且连接至用于较低频率、较低要求的‘控制平面’报文路由的次级较低带宽noc。除了本文中所描述的各种以太网网络接口、实现和数据速率之外,诸如rapidio、infiniband、光纤通道和omni-path结构等许多其他联网和网络结构技术均受益于通过noc与其他客户端核的互连,所述互连使用对应的接口专用nic客户端核1140以及将nic客户端核耦合到其noc路由器。一旦外部网络接口客户端核被添加至noc,就可以开始参与诸如从nic到nic或从nic到dram的最大带宽直接传递(反之亦然)的报文传送模式,而无需由(相对极其缓慢的)处理器核干预处理,并且不会干扰处理器的存储器层级。在实施例中,noc还可以用作一组nic客户端核的网络交换机结构。以上所描述的图9b展示了可以使用在其上的每一个nic都是客户端的noc以高带宽交换的从一个nic客户端输出到另一个nic客户端输入的任意流量。在实施例中,只有noc上的一些路由器具有nic客户端核;其他路由器可能不具有客户端输入或输出。在实施例中,这些“无输入”路由器可以使用以上结合图5c所描述和本文中其他地方所公开的有利的半成本noc路由器交换电路和技术映射效率。在实现交换数据包的组播扇出的实施例中,底层noc路由器还可以被配置用于实现组播路由,以使得当传入报文由其nic客户端核分段成报文流并且这些报文被发送到noc中时,所述报文流被组播到noc上的其他nic客户端核的全部或子集以便在多个外部网络接口上输出。用于耦合至noc的另一重要外部接口是pciexpress(pcie)接口。pcie是高速、串行、计算机扩展总线,广泛用于互连cpu、存储设备、固态硬盘、flash存储阵列、图形显示设备、加速网络接口控制器以及各种其他外围设备和功能。现代fpga包括一个或多个pcie端点块。在实施例中,可以通过配置fpga的pcie端点块和配置可编程逻辑以实现pcie控制器来以fpga实现pcie主或从端点。在实施例中,可编程逻辑还实现pciedma控制器以使得在fpga中的应用可以发布pciedma传递以将数据从fpga传递至主机,或者反之亦然。在实施例中,fpgapcie控制器或pciedma控制器可以借助于包括用于接口连接至noc路由器的pcie控制器和逻辑的pcie接口客户端核来耦合至noc。pcie接口客户端核使能实现有利的系统用例。在实施例中,noc上的任何客户端核都可以通过发送包封pciexpress读取事务和写入事务的noc报文经由noc来访问pcie接口客户端核。因此,回顾以上结合图11和图12所描述的之前的示例性网络数据包处理系统,如果如此配置的话,在聚类多处理器中的400个核或加速器中的任何一个都可能通过准备并经由noc将pciexpress事务请求报文发送到pciexpress接口客户端核来访问主机计算机中的存储器。后者核经由其pciexpress端点和pcie串行解串器phy来接收pciexpress事务请求报文并将所述事务请求报文发布到pciexpress报文结构中。类似地,在实施例中,任何片上嵌入式存储器或附接至fpga的任何外部存储器设备都可以由pcie连接的主机计算机或由另外的pcie代理进行远程访问。在此示例中,pcie接口客户端核从其pcie端点处接收本地存储器访问请求,格式化并发送由noc路由至特定多处理器集群客户端的集群存储器读取或写入请求报文,所述特定多处理器集群客户端在noc上的路由器地址是由读取或写入请求报文中的某些位来指定的。在实施例中,除了促进远程单字读取或写入事务,外部主机和裸片上客户端核可以利用pcie接口客户端核的pciedma(直接存储器访问)引擎能力来执行数据从主机存储器到pcie接口客户端中的块传递,并且然后经由noc发送到特定客户端核的本地存储器。在实施例中,同样支持相反过程——从特定客户端核的存储器,或者反之亦然,从noc上的特定客户端核的存储器将数据块传递到pcie接口客户端核,并且然后将其作为一组pcie事务报文传递到主机或其他pcie互连的设备上的存储器区域。回顾一下,如以上所描述的,noc还可以用作一组nic客户端核的网络交换机结构,以相同的方式,在实施例中,noc还可以用作一组pcie客户端核的pcie交换结构。当外部pcie事务报文到达pcie接口客户端核时,所述事务报文被包封为noc报文并且经由noc被发送到第二pcie接口客户端核,并且然后作为pcie事务报文被外部传送至第二pcie所附接设备。与网络交换结构一样,在实施例中,pcie交换结构还可以利用noc组播路由来实现pcie事务报文的组播递送。计算设备中的另一重要外部接口是sata(串行高级技术附件),其是包括硬盘、磁带、光学存储设备和固态硬盘(ssd)的大多数存储设备接口连接至计算机所利用的接口。与dram通道和100gbps以太网相比,现代sata的3/6/16gbps信号传送速率很容易在相对较窄的hoplitenoc路由器和链路上承载。在实施例中,可以通过组合可编程逻辑sata控制器核和fpga串行解串器块来以fpga实现sata接口。因此,在实施例中,sata接口hoplite客户端核包括上述sata控制器核、串行解串器和hoplite路由器接口。noc客户端核将存储传递请求报文发送至sata接口客户端核,或者在实施例中,可以将待写入的存储器块或待读取的存储器块作为noc报文流复制到/从sata接口客户端核。除了将客户端核连接至特定外部接口之外,noc可以为各种客户端核提供互连至第二互连网络并与其交换数据的高效方式。这里提供了几个非限制性示例。在实施例中,出于性能可扩展原因,非常大的系统可以包括互连的分层系统,比如所述分层系统包括的并且由noc互连到集成系统中的多个次级互连网络。在实施例中,这些分层noc路由器可以使用3d或更高维度坐标来寻址,例如,路由器(x,y,i,j)是在全局noc上的全局noc路由器(x,y)处找到的次级noc中的(i,j)路由器。在实施例中,为了网络管理或安全考虑,系统可以被分区成单独的互连网络,并且然后经由noc利用单独网络之间的报文过滤来互连。在实施例中,大型系统设计可能未在物理上拟合到特定fpga中,并且因此,需要跨两个或更多个fpga进行分区。在此示例中,每个fpga包括其自己的noc和客户端,并且需要某种方式来桥已发送的报文,以使得在一个noc上的客户端可以方便地与第二noc上的客户端进行通信。在实施例中,在两个不同设备中的这两个noc是桥的;在另一实施例中,noc分段在逻辑上和拓扑上都是一个noc,其中,使用并行、高速i/o信号传送在fpga设备之间延伸的报文环和在fpga之间循环的报文现在在现代fpga(比如赛灵思rxtxbitsliceiob)中可用。在实施例中,noc可以在客户端核之间提供高带宽“高速公路”,并且noc的客户端核本身可以具有通过其他手段互连的组成子电路。其中一个特定示例是图11中所示并且在本文中所描述的示例性数据包处理系统中所描述的多处理器/加速器计算集群客户端核。参照图12,在此示例中,本地互连网络是2:1集中器1224、4×4交叉开关1226和多端口集群共享存储器1230的组播交换网络。在这些示例中的每一个中,这些不同的互连网络的客户端可以有利地借助于将各种从属互连网络本身视为中心hoplitenoc的聚集客户端核而互连到集成整体。作为客户端核,从属互连网络包括noc接口,所述从属互连网络通过所述noc接口这一手段而连接至hoplitenoc路由器并在noc上发送和接收报文。在图12中,noc接口1240协调报文在路由器1200的客户端输入1202上从cram1230或加速器1250到所述路由器的发送以及报文在路由器的y报文输出端口1204上从所述路由器到cram1230或加速器1250或者到特定iram1222中的接收。现在转向经由noc将尽可能多的内部(片上)资源和核互连在一起的问题,内部接口客户端核的最重要的类别之一是“标准ip接口”桥客户端核。现代fpgasoc通常是许多预构建和可重复使用的“ip”(知识产权)核的组成部分。为了实现最大的可组合性和可重用性,这些核通常使用行业标准的外围互连接口,诸如axi4、axi4lite、axi4流、ambaahb、apb、coreconnect、plb、avalon和wishbone。为了将这些预先存在的ip核互相连接并且经由noc连接至其他客户端核,“标准ip接口”桥客户端核用于使ip接口的信号和协议适配于noc报文,并且反之亦然。在一些情况下,标准ip接口桥客户端核与noc报文传送语义紧密匹配。一个示例是axi4流,基本单向流控制流传输ip接口,具有在发送数据的主机与接收数据的从机之间的准备就绪/有效握手信号。axi4流桥noc客户端可以接受axi4流数据作为从机,将数据格式化为noc报文,并且通过noc将noc报文发送到目的地noc客户端,其中(如果目的地客户端也是axi4流ip桥客户端核)noc客户端核接收报文,并且用作axi4流主机将数据流提供到其从属客户端。在实施例中,noc路由器的路由函数被配置用于有序递送报文,如以上所描述的。在实施例中,利用弹性缓冲区或fifo来缓冲传入的axi4流数据然后将其作为报文在noc上接受(如果noc过重负荷,则可能发生),或者在noc报文输出端口上使用缓冲区来缓冲数据直到axi4流的消费者准备就绪接受数据可能是有益的。在实施例中,在源客户端与目的地客户端之间实现流控制(例如,当流消费者否定其准备就绪信号以在相对较长时间段内阻止流数据的递送)从而使得在目的地处的报文缓冲区不会溢出是有益的。在实施例中,流控制是基于信用的,在这种情况下,源客户端“知道”在目的地客户端的缓冲区溢出之前可以由所述目的地客户端接收多少报文。因此,源客户端发送多达那么多的报文,然后等待从目的地客户端返回信用报文,所述目的地客户端返回经缓冲报文已经进行处理并且已经释放更多缓冲空间的信用报文信号。在实施例中,此信用通过第一noc返回报文流;在另一实施例中,第二noc将信用返回报文承载回源客户端。在这种情况下,每个axi4流桥客户端核是两个noc的客户端。其他axi4接口:axi4和axi4-lite,使用五个逻辑单向通道实现事务处理,每个通道都类似于axi4流,具有准备就绪/有效的握手流控制接口。这五个通道是读取地址(主机到从机)、读取数据(从机到主机)、写入地址(主机到从机)、写入数据(主机到从机)和写入响应(从机到主机)。axi4主机通过将写入事务写入到写入地址通道和写入数据通道以及在写入响应通道上接收响应来写入到从机。从机在写入地址通道和写入数据通道上接收写入命令数据并且通过在写入响应通道上写入来响应。主机通过将读取事务数据写入到读取地址通道以及接收来自读取响应通道的响应来执行自从机的读取。从机在读取地址通道上接收读取命令数据并且通过将数据写入读取响应通道来响应。axi4主机或从机桥将axi4协议报文转换成noc报文,并且反之亦然。在实施例中,在其五个组成通道中的任何一个上接收到的每个axi4数据都作为单独的报文从主机(或从机)中从源路由器(主(或从))通过noc发送到目的地路由器(从(或主)),其中,如果存在相应的axi从/主桥,则报文在相应的axi4通道上递送。在具有更高性能的另一实施例中,每个axi4桥在给定时钟周期内从跨其所有的输入axi4输入通道中收集尽可能多的axi4通道数据,并且将此收集的数据作为单个报文在noc上发送到目的地桥,所述目的地桥将所述单个报文解包封到所述目的地桥的组成通道中。在另一实施例中,桥客户端等待直到其接收到足以与一个语义请求或响应报文(诸如“写入请求(地址、数据)”或“写入响应”或“读取请求(地址)”或“读取响应(数据)”)相对应的通道数据,并且然后将此报文发送至目的地客户端。这种方法可以简化axi4主机或从机与noc上其他地方的非axi4客户端核的互连。因此,从axi4主机到axi4从机的noc中介axi4传递实际上横穿axi4主机,到axi4从机桥客户端核,到源路由器,经过noc,到目的地路由器,到axi4主机桥客户端核,到axi4从机(并且对于响应通道报文,反之亦然)。如在以上axi4流桥接的描述中,在实施例中,在客户端核之间实现基于信用的流控制可能是有益的。以类似的方式,本文中所描述的其他ip接口,不受限制的,可以被桥用于将这些ip接口的客户端耦合至noc,并且由此耦合至其他客户端。“axi4互连ip”核是一种特殊类型的系统核,其目的是在系统中互连多个axi4ip核。在实施例中,hoplitenoc加上多个axi4桥客户端核可以配置用于实现“axi4互连ip”的角色,并且因为axi4客户端的数量或者客户端的带宽需求扩展到十多个核,所以这个极其高效的noc+桥的实施方式可以是将多个axi4ip核组合成集成系统的最高性能和最资源高效和能量高效的方式。另一种重要类型的内部noc客户端是嵌入式微处理器。如以上所描述的,具体地在数据包处理系统的描述中,嵌入式处理器可以经由报文与其他noc客户端交互以执行如下功能:读取或写入存储器或i/o数据的字节、半字、字、双字或四字;读取或写入存储器块;读取或写入高速缓存行;传送mesi高速缓存一致性报文,诸如读取、无效或读取所有权;传达中断或处理器间中断;明确地发送或接受报文作为显式软件动作;向加速器核发送或接收命令或数据报文;传达性能跟踪数据;停止、重置或调试处理器;以及适于作为报文递送的许多其他类型的信息传递。在实施例中,嵌入式处理器noc客户端核可以包括软处理器。在实施例中,嵌入式处理器noc客户端核可以包括加固的完全自定义“soc”子系统,比如赛灵思zynqps(处理子系统)中的arm处理器核。在实施例中,noc客户端核可以包括多个处理器。在实施例中,noc可以互连处理器noc客户端核和第二处理器noc客户端核。在dennardscaling的这种萧条期,在摩尔定律的这种成熟期,随着传统的微处理器性能缩减,以及随着能量减少,每个数据中心工作负荷成为业务的当务之急,数据中心工作负荷的fpga加速的兴趣也越来越大。这一趋势使得在数据中心服务器刀片中经由pciexpress连接到多处理器服务器套接字的fpga加速器卡得到了有利的支持。随着这种趋势继续发展,fpga将越来越接近耦合至处理器。fpga和服务器cpu紧密集成的下一步将是高级封装,其中,服务器cpu裸片和fpga裸片通过芯片级互连来并排封装(比如赛灵思2.5d堆叠硅集成(ssi)或英特尔嵌入式多裸片互连桥(emib))。在当今时代,fpganoc客户端通过noc经由“外部一致性接口”桥noc客户端并且经由外部一致性接口耦合到服务器cpu裸片的高速缓存一致性存储器系统。采用诸如但不限于英特尔快速路径互连或ibm/openpower一致性附接处理器接口(capi)之类的技术,外部互连可支持跨这两个裸片的高速缓存一致性传递和本地存储器高速缓存。这一进步将使fpga上的noc客户端更高效地与在服务器处理器上运行的软件线程进行通信和互操作。接下来,下一步将fpga结构嵌入到服务器cpu裸片上,或者等效地,将服务器cpu核嵌入到fpga裸片上。在当今时代,当务之急是将fpga可编程加速器核更快、更高效地互连到服务器cpu以及裸片上的其他固定功能加速器核。在当今时代,许多服务器cpu将经由诸如二维环面的非核心可扩展互连结构来彼此互连并且与互连至“非核心”结构(即,除了cpu核和fpga结构核之外的芯片的其余部分)。在此soc中的fpga结构资源可以是一个大型连续区域,或者可以被分段成位于裸片上的各个点处的较小分块。在当今时代,所公开的fpganoc的实施例将使用“fpganoc到非核心noc”桥fpganoc客户端核来接口连接至soc的其余部分。在实施例中,fpganoc路由器和非核心noc路由器可以共享路由器寻址方案,以使得来自cpu、固定逻辑或fpganoc客户端核的报文可以根据目的地路由器的路由器地址仅横穿到硬非核心noc或软fpganoc。这种紧密耦合的安排促进fpganoc客户端核、非核心noc客户端核心以及服务器cpu中的简单、高效、高性能的通信。现代fpga包括全部分布在设备周围的各个点处的数百个嵌入式块ram、嵌入式定点dsp块和嵌入式浮点dsp块。一个fpga系统设计挑战是从fpga中的其他点处的许多客户端高效地访问这些资源。fpganoc使这一点更加容易。块ram是嵌入式静态ram块。示例包括20kbit阿尔特拉m20k、36kbit赛灵思块ram和288kbit赛灵思ultraram。与以上所描述的其他存储器接口noc客户端核一样,块ramnoc客户端核接收存储器加载或存储请求报文,针对块ram执行所请求的存储器事务,并且(对于加载请求)将具有加载的数据的加载响应报文发送回请求noc客户端。在实施例中,块ram控制器noc客户端核包括单个块ram。在实施例中,块ram控制器noc客户端核包括块ram的阵列。在实施例中,访问块ram的数据带宽不大——以500mhz的高达10位的地址和72位数据。在采用块ram阵列的另一实施例中,所述访问的数据带宽可以任意大。例如,八个36kbit赛灵思块ram的阵列每个周期可以读取或写入576位的数据,即高达288gbps。因此,576位到1024位的极宽noc可以允许充分利用这种八个块ram阵列中的一个或多个的带宽。嵌入式dsp块是用于执行定点宽字数学功能(比如加法和乘法)的固定逻辑。示例包括赛灵思dsp48e2和阿尔特拉可变精度dsp块。fpga的许多dsp块还可以通过noc经由dspnoc客户端核来访问。后者接受来自其noc路由器的报文流,每个报文封装操作数或请求以执行一个或多个dsp计算;并且几个周期之后,将具有结果的响应报文发送回客户端。在实施例中,dsp功能被配置为特定的固定操作。在实施例中,dsp功能是动态的,并且连同noc报文中的功能操作数一起被传达至dsp块。在实施例中,dspnoc客户端核可以包括嵌入式dsp块。在实施例中,dspnoc客户端核可以包括多个嵌入式dsp块。嵌入式浮点dsp块是用于执行浮点数学功能(比如加法和乘法)的固定逻辑。一个示例是阿尔特拉浮点dsp块。fpga的许多浮点dsp块和浮点增强型dsp块还可以通过noc经由浮点dspnoc客户端核来访问。后者接受来自其noc路由器的报文流,每个报文封装操作数或请求以执行一个或多个浮点计算;并且几个周期之后,将具有结果的响应报文发送回客户端。在实施例中,浮点dsp功能被配置为特定的固定操作。在实施例中,浮点dsp功能是动态的,并且连同noc报文中的功能操作数一起被传达至dsp块。在实施例中,浮点dspnoc客户端核可以包括嵌入式浮点dsp块。在实施例中,dspnoc客户端核可以包括多个浮点嵌入式dsp块。简单的示例说明了将内部fpga资源(比如块ram和浮点dsp块)与noc耦合的实用性,使得它们可以容易且动态地组合成并行计算设备。在实施例中,在fpga中,数百个块ram和数百个浮点dsp块中的每一个都经由多个块ramnoc客户端核和浮点dspnoc客户端核耦合到noc。浮点操作数的两个向量a[]和b[]被加载到两个块ramnoc客户端核中。两个向量的并行点积可以借助于以下方式获得:1)这两个向量的块ram内容作为报文流传输到noc中,并且两者都被发送到将它们相乘的第一浮点dspnoc客户端核;所产生的元素式乘积流由第一浮点dspnoc客户端核经由noc发送到第二浮点dspnoc客户端核,所述第二浮点dspnoc客户端核将每个乘积添加在一起以累积这两个向量的点积。在另一实施例中,两个n×n矩阵a[,]和b[,]跨许多块ramnoc客户端核分别按行和按列分布;并且之前实施例的点积流水线的n×n个实例的安排被配置以便将a的每一行和b的每一列流传输到点积流水线实例中。这些点积计算的结果作为报文经由noc被发送到累积矩阵相乘的乘积结果c[,]的第三组块ramnoc客户端核。此实施例执行了并行、流水线、高性能浮点矩阵相乘。在此实施例中,所有的操作数和结果都在存储器与功能单元之间通过noc承载。尤其有利的是,操作数的数据流图以及操作和结果不是固定在导线中,也不是固定在特定的可编程逻辑配置中,而是通过仅仅改变经由noc发送的资源之间的报文的(x,y)目的地来动态地实现的。因此,存储器和操作者的数据流图结构可以逐个周期、逐个微秒、动态地适应于工作负荷或计算。另一重要的fpga资源是配置单元。一些示例包括赛灵思icap(内部配置访问端口)和pcap(处理器配置访问端口)。配置单元使fpga能够动态地重编程所述fpga的可编程逻辑的子集(也称为“部分重新配置”)以便动态地将新硬件功能配置到其fpga结构中。通过借助于配置单元noc客户端核将icap耦合至noc,使得icap功能可由noc的其他客户端核访问。例如,可以从任何其他noc客户端核中接收到用于对可编程逻辑结构的区域进行配置的部分重新配置比特流。在实施例中,部分重新配置比特流是经由以太网nic客户端核来发送的。在实施例中,部分重新配置比特流是经由dram通道noc客户端核来发送的。在实施例中,部分重新配置比特流是从加固嵌入式微处理器子系统中经由嵌入式处理器noc客户端核来发送的。在动态部分重新配置系统中,部分可重新配置逻辑通常平面规划到可编程逻辑结构的特定区域中。设计挑战是可以如何将此逻辑最佳通信地耦合至系统中的其他逻辑(无论是固定可编程逻辑还是更动态地重新配置的可编程逻辑),预期在稍后的时刻所述逻辑可能会被相同区域中的其他逻辑所取代。通过借助于noc将可重新配置逻辑核耦合至其他逻辑,任何可重新配置逻辑与不可配置的逻辑进行通信变得简单,并且反之亦然。部分重新配置noc客户端核包括被设计用于直接附接至在固定组fpga网(导线)上的noc路由器的部分重新配置核。一系列不同的部分重新配置的noc客户端核可以被加载到fpga中的特定点。由于每个重新配置直接耦合至noc路由器的报文输入端口和输出端口,因此每个重新配置都与系统中的其他noc客户端核完全连接。附加方面在实施例中,系统平面规划eda工具并入noc拓扑的配置和平面规划,并且可用于将客户端核块放置并互连至noc的路由器。在实施例中,fpga实现布局布线eda工具并入了与noc的互连,以促进更简单、增量或并行的布局布线算法。在其中多个路由器形成定向2d环面noc的实施例中,x输出和y输出分别连接到x环和y环上的其他路由器的xi输入和yi输入,但是在可替代实施例中,各种noc拓扑结构可以由路由器通过链路的可替代互连来组成,例如但不限于:1d移位寄存器、1d环、具有额外“快速”链路的1d环(即,将第一路由器连接到例如在环上四跳远的第二路由器,以便减少报文在大环上从源路由器路由到目的路由器所花费的平均跳数)、1d双向环、1d双倍带宽环、2d网格、1d环和1d移位寄存器的混合、2d环面(例如,具有双向链路的传统2d环面)、二叉树和更高维度的noc拓扑。具体地,路由器的路由电路的可配置性和报文数据布局的可扩展性(通过将路由数据添加到d_w数据有效载荷大小)以及能够检查和路由输入报文的任何字段中的任何数据的经配置路由电路的实用性利用各种报文路由算法在2d路由器组合成不同的noc拓扑时提供了极大的灵活性。对于“第一维输入/输出”和“第二维输入/输出”以及诸如“x输出到x环上的下一个路由器”(对应地y)的表达式,本文中术语xi/x和yi/x的使用是为了清楚地公开2d定向环面路由的目的,而不将本公开限于仅2d定向环面noc拓扑。在实施例中,更高维度noc(例如,三维noc)可以包括所公开的2d环面noc。在实施例中,多个路由器形成noc。在实施例中,系统可以包括多个noc。参照图1,如在152和150中所看到的,noc可以是由“客户端核”本身包括其他客户端的noc的路由器组成的合成或分层noc。参照图3,在实施例中,在每个时钟周期期间,路由器接受输入报文并路由所述输入报文,将路由器输出寄存在路由器输出寄存器336和338中。在可替代实施例中,路由器输出寄存器336和338之一或两者都可能不存在,即,路由器交换电路可以是组合的而不是流水线的。在另一实施例中,对于更高时钟频率操作,通过附加的流水线程度,可以在路由器内添加附加的流水线输入或输出寄存器,或者可以在路由器间链路中的路由器之间采用流水线寄存器。在实施例中,路由器流水线可能不需要实际的寄存器或触发器状态元件(例如,“波流水线”)。在实施例中,在fpga可编程互连结构可以被增强以在互连本身中提供可选流水线寄存器的情况下,系统可以在路由器内或在路由器之间(例如,流水线式路由器间链路)采用fpga的流水线式互连以用于更高频率的操作或者用于更低的资源消耗。这种实施例的示例是在阿尔特拉stratix10设备中的路由器和noc的实施方式。在此实施例中,noc链路(即,承载报文298(图2a)和相应的有效指示符的一组信号到路由器的报文输入端口或从路由器的输出端口)是流水线式的,并且链路流水线寄存器被配置用于在互连结构中采用stratix10“hyperflex”流水线寄存器。实施例的一些应用包括而不限于:1)具有包括axi4的各种接口的可重复使用的模块化“ip”noc、路由器和交换结构;2)将fpga子系统客户端核互连至接口控制器客户端核,以用于各种设备、系统和接口,包括:dram和dramdimm、封装内3d裸片堆栈或2.5d堆栈硅内插件互连的hbm/wideio2/hmcdram、sram、flash存储器、pciexpress、1g/10g/25g/40g/100g/400g网络、光纤通道、sata和其他fpga;3)作为并行处理器覆盖网络中的部件;4)作为opencl主机或存储器互连中的部件;5)作为如由soc生成器设计工具或ip核集成电子设计自动化工具进行配置的部件;4)由fpga电子设计自动化cad工具,特别是平面规划工具和可编程逻辑布局和布线工具使用,以采用noc主干来减轻子系统布局中对物理邻接的需要,或者使得能够利用单独的、可能并行的编译客户端核来实现模块化的fpga实现流程,所述客户端核通过noc客户端接口连接到系统的其余部分;6)在动态部分重新配置系统中使用平面规划的noc以在动态部分重新配置块之间提供高带宽互连性,并且经由平面规划提供保证的无逻辑和无互连的“阻止区”,以便促进将新的动态逻辑区域加载到阻止区,以及7)在计算、数据中心、数据中心应用加速器、高性能计算系统、机器学习、数据管理、数据压缩、重复数据删除、数据库、数据库加速器、联网、网络交换和路由、网络处理、网络安全、存储系统、电信、无线电信和基站、视频制作和路由、嵌入式系统、嵌入式视觉系统、消费电子、娱乐系统、汽车系统、自动驾驶汽车、航空电子、雷达、反射地震学、医疗诊断成像、机器人技术、复杂的soc、硬件仿真系统和高频交易系统中将所公开的路由器和noc系统作为部件或多个部件使用。也可将以上所描述的各种实施例组合而提供另外的实施例。鉴于以上详细描述,可以对实施例做出这些以及其他改变。一般而言,在以下权利要求书中,所使用的术语不应该被解释为将权利要求书限制为在说明书和权利要求书中所公开的具体实施例,而是应该被解释为包括所有可能的实施例连同这样的权利要求书有权获得的等效物的全部范围。因此,权利要求书不受本公开的限制。此外,“连接”和“耦合”以及其各种形式可互换使用,意味着在相互“连接的”或“耦合的”两个部件之间可能存在一个或多个部件。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1