一种声场的音频数据的处理方法及装置与流程
本发明实施例涉及虚拟现实(virtualreality,vr)技术领域,尤其涉及一种声场的音频数据的处理方法及装置。
背景技术:
随着科学技术的不断发展,虚拟现实技术也逐步被应用到用户的生活中。其中,虚拟现实是利用电脑模拟,产生一个三维(threedimensional,3d)空间的虚拟世界,给用户提供视觉、听觉和触觉等感官上的模拟,使得用户可以及时且没有限制地观察三维空间内的事物。
现有的虚拟技术,对声音的虚拟现实(让声音产生环绕立体效果)一般都需借助多声道立体音响或多声道立体声耳机来实现。然而,大部分环绕立体效果实质上是一种二维(twodimensional,2d)层面的效果,即这种效果只能大致模拟出声源物体在用户的左侧或者右侧,离用户远还是近。所以,在场景模拟的过程中,声音只能起到简单的辅助效果,并不能满足当前场景下用户的“沉浸感”体验。
因此,目前对于声音的虚拟现实技术可靠性较差,用户体验有待提高。
技术实现要素:
为解决相关技术问题,本发明提供一种声场的音频数据的处理方法及装置,使得用户在运动时所能接收到的音频数据也随之发生相应的变化。在听觉方面,可以将场景中的音效准确地还原给用户,提升用户体验。
为实现上述目的,本发明实施例采用如下技术方案:
第一方面,本发明实施例提供了一种声场音频数据的处理方法,所述方法包括:
获取所述声场的音频数据;
根据所述音频数据,基于预设还原算法,得到所述声场的音频数据信息;
获取目标的运动信息;
根据所述音频数据信息和所述目标的运动信息,基于预设处理算法,得到基于目标的声场音频数据。
第二方面,本发明实施例提供了一种声场音频数据的处理装置,所述装置包括:
原始声场获取模块,用于获取所述声场的音频数据;
原始声场还原模块,用于根据所述音频数据,基于预设还原算法,得到所述声场的音频数据信息;
运动信息获取模块,用于获取目标的运动信息;
目标音频数据处理模块,用于根据所述音频数据信息和所述目标的运动信息,基于预设处理算法,得到基于目标的声场音频数据。
本发明实施例的技术方案中,在获取原始声场的音频数据后,根据音频数据,基于预设还原算法,可对声场进行还原,得到原始声场的音频数据信息;通过获取目标的运动信息,并根据音频数据信息和目标的运动信息,基于预设处理算法,可以得到基于目标的声场音频数据,进而可以根据目标的实时运动情况对声场进行重建,使得声场中的音频数据可以跟随目标的运动发生相应的变化。在场景模拟的过程中,可增强声音的辅助效果,提升当前场景下用户的“沉浸感”体验。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对本发明实施例描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据本发明实施例的内容和这些附图获得其他的附图。
图1为本发明实施例一提供的一种声场的音频数据的处理方法的流程图;
图2为本发明实施例二提供的一种声场的音频数据的处理方法的流程图;
图3为本发明实施例二提供的一种单声源坐标位置变化的示意图;
图4为本发明实施例三提供的一种声场的音频数据的处理装置的结构框图。
具体实施方式
为使本发明解决的技术问题、采用的技术方案和达到的技术效果更加清楚,下面将结合附图对本发明实施例的技术方案作进一步的详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
图1为本发明实施例一提供的一种声场的音频数据处理方法的流程图。本实施例的方法可以由如虚拟现实头盔、眼镜或头戴显示器等虚拟现实装置或系统来执行,具体可以由部署在虚拟现实装置或系统中的软件和/或硬件来实施。
如图1所述,该方法可以包括如下步骤:
s110:获取声场的音频数据。
其中,获取声场的音频数据的设备可以为集成有专业的音频数据制作和/或处理软件或引擎的硬件和/或软件。声场的音频数据可以是前期已制作好与电影、游戏等视频内容配套的原始音频数据。具体的,上述音频数据中包含有音频所对应的场景中的声源的位置或方向等信息。通过对上述音频数据进行解析,可获取到声源的相关信息。
示例性的,在实验室或研发环境中,可利用全景声制作软件为工具,还原基础音频数据。在使用全景声软件之前,需要对全景声引擎进行创建并初始化(例如设置声源与用户的初始距离)。
示例性的,下面以vr游戏配套的声场音频数据处理为例进行具体说明:
在处理游戏的声场音频数据时,可利用unity3d作为全景声软件工具。其中,unity3d是由unitytechnologies开发创建诸如三维视频游戏、建筑可视化以及实时三维动画等类型互动内容的多平台的综合型游戏开发工具,是一个全面整合的专业游戏引擎。在具体实验过程中,可将游戏全景声引擎包导入到unity3d工程中,然后,在unity3d中选择edit\projectsettings\audio\spatializerplugin\里选择导入的全景声引擎包,接着在需要添加全景声的物体上添加音频源(audiosource)组件,同时添加全景声脚本,最后,在unityedit里直接配置全景声。通过选择空间化(enablespatialization)即可打开全景声处理模式。
在上述准备工作完成后,对于与全景声引擎包对应的多媒体文件,可自动获取到多媒体文件中声场的音频数据。
示例性的,对于未携带声源位置信息的音频数据,或者通过常规音频数据处理软件无法识音频数据中携带的声源位置信息的,也可以通过手动输入声源位置参数信息的形式获取声源的初始位置信息。
其中,声场中的声源可以为一个也可以为多个。若声源为多个,则在获取声源的位置信息时,可根据声源所播放音频数据的特点对其进行选择。例如,若当前游戏的场景为战争场景,则可将枪声或炮声的音调高于一定阈值的声音作为表征当前场景的目标音频,并获取播放目标音频的声源的位置信息。这样设置的好处在于,可以抓取对当前场景的音频渲染具有代表性意义的音频信息,以提升对当前场景的渲染效果,增强用户的游戏体验效果。
s120:根据音频数据,基于预设还原算法,得到声场的音频数据信息。
优选的,声场的音频数据信息可包括:声场中声源的位置信息、方向信息、距离信息、和/或运动轨迹信息。
其中,通过预设还原算法,也可以是通过unity3d、wavepurity等音频数据编辑与反编辑等专业工具来实现原始音频数据信息的提取。示例性的,可以通过unity3d软件,将多媒体文件中的声场音频数据还原出各音频的如采样率、采样精度、通道数、比特率和编码算法等音频数据参数,作为后续进一步加工和处理该音频数据的基础。
具体的,在基于预设还原算法,确定声场的音频数据信息时,可将声源拆分为直线位置信息和垂直位置信息。其中,虚拟现实设备可以通过位置解析方法解析出声源的初始位置信息。由于声源可能是一个运动的物体,其位置具有不确定性,因此可获取不同时刻声源的位置信息,然后结合声源的初始位置信息,获取到声源的运动方向信息、运动轨迹信息,不同时刻同一声源的距离信息或者同一时刻不同声源之间的距离信息等。
示例性的,在对声场的音频数据进行还原时,也可以根据音频数据的功能属性对其进行还原。其中,功能属性可包括与当前场景相对应的音量的音调、响度或音色信息等。通过对音频数据功能属性的选择,可将与当前场景相匹配的音频数据进行还原,同时也可以排除场景中的一些杂音,提升当前场景下用户的“沉浸感”体验。
s130:获取目标的运动信息。
示例性的,与传统在电影院固定位置观赏前期已按影院模式制作好的电影场景不同的是,在虚拟现实游戏等虚拟现实体验环境中,用户控制着游戏角色在虚拟现实空间中运动时,用户的具体体验位置不是像影院中静止不动的,而是在虚拟空间中随着场景运动。为了让用户在虚拟运动环境中体验到实时3d音效,实时获取用户的运动信息,从而间接获得用户在虚拟现实环境中的位置、方向等参数,并在传统预先制作好的音频数据的进一步处理中,实时加入用户的运动信息参数就显得尤为重要。
其中,本步骤中提到的目标优选为用户的头部。
优选的,用户头部的运动信息包含用户头部可以进行活动的任何方向和位置,例如可包括:朝向变化信息、位置变化信息、和/或角度变化信息等。上述运动信息可通过集成在如虚拟现实头盔等虚拟现实设备中的三轴陀螺仪进行获取。通过上述运动信息的确定可为处于不同位置的目标所对应的声场音频数据的处理提供数据基础,而不是仅仅将目标确定在上、下、左和右四个简单的方位。因此,通过实时获取目标的运动信息,全景声引擎可相应地实时调整声场,进而提升用户体验。
s140:根据音频数据信息和目标的运动信息,基于预设处理算法,得到基于目标的声场音频数据。
其中,基于目标的声场音频数据是指随着目标如用户的运动,用户通过耳机等播放设备实时接收到的声场音频数据。对于播放设备中的全景声引擎而言,目标的位置、角度或朝向等信息以及经过预设还原算法获取到的音频数据信息都可以作为其输入参数,通过预设处理算法对上述参数进行处理后,可在虚拟场景中相应地调整声源的位置、方向或运动轨迹等,以跟随目标的运动。所以,可将经过预设还原算法处理后的音频数据作为原始声场中的原始音频数据,而将经过预设处理算法获取到的基于目标的声场音频数据作为输出给用户的目标音频数据。
示例性的,若存在多个声源分别以不同的方向朝向用户时,通过对用户的运动进行追踪,同时配合预设处理算法,用户可区分出是哪个声源播放的声音。例如,对于处于当前实时游戏角色所处位置的一前一后的两处呈现的爆炸声,若采用传统的声场模拟方式,游戏玩家只能获取到一大一小且从同方向传来爆炸声。而若采用本实施例提供的音频数据的处理方式,游戏玩家可清楚地感受到一声爆炸声在其前方,另一声爆炸声在其后方。如果此时,另外一个玩家,控制的游戏角色刚好处在上述两处爆炸点的后方,那么基于本实施例提供的声场音频数据处理方法,该玩家则可以听到两个分别从前方传过来的爆炸声。因此,本实施例提供的音频数据的处理方式可为声场的模拟提供具体的方向信息,提升了用户对于场景的“沉浸感”。
优选的,预设处理算法为头相关变换函数(headrelatedtransferfunction,hrtf)算法。本领域技术人员可以理解的是,hrtf算法是一种声音定位的处理技术,是将声音转到ambisonic域,然后再通过使用旋转矩阵对声音信号做变换处理,其具体过程是:将音频转为b格式信号,并将该b格式信号再转换为虚拟扬声器阵列信号,然后将虚拟扬声器阵列信号通过hrtf滤波器进行滤波,从而可得到虚拟环绕声。综上所述,通过该算法不仅可以得到基于目标的音频数据,同时也可有效地模拟原始音频,使得最后播放给用户的音频更为逼真。例如,若vr游戏中存在多个声源时,则可通过hrtf算法对多个声源分别进行处理,使得游戏玩家可以更好地浸入虚拟游戏中。
本实施例提供了一种声场音频数据的处理方法,在获取原始声场音频数据和音频数据声源的位置信息后,根据音频数据和声源的位置信息,基于预设还原算法,对原始声场进行还原,得到原始声场的音频数据的基础参数信息;另外,通过实时获取如用户等活动目标的如朝向、位置、角度等运动信息,并根据音频数据信息和活动目标的运动信息,基于预设的音频处理算法,可以得到基于活动目标的声场音频数据,进而可以结合目标的实时运动情况,基于从原始声场的音频数据中还原出来的如声源个数、音调、响度、采样率、通道数等音频数据基础信息,对目标的声场音频数据进行重建,得到基于运动目标的实时声场音频数据。使得重建声场中的音频数据可以跟随目标的实时运动而发生相应的实时变化。达到了在场景模拟的过程中,可增强声音的辅助效果,提升当前场景下用户的“沉浸感”体验的技术效果。
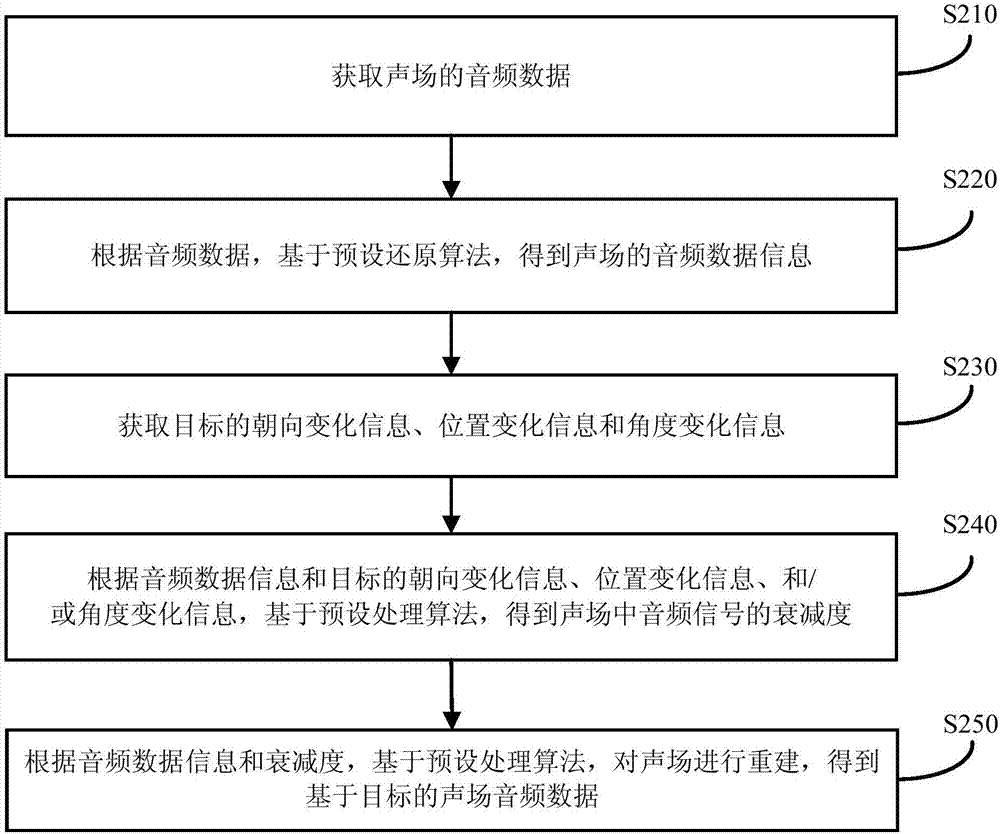
实施例二
图2为本发明实施例二提供的一种声场的音频数据的处理方法的流程图。本实施例二在实施例一的基础上,对上述实施例进行了优化,参照图2,本发明实施例二具体包括如下步骤:
s210:获取声场的音频数据。
s220:根据音频数据,基于预设还原算法,得到声场的音频数据信息。
在原始声场中,可获取到原始声场的音频数据,同时也可通过预设还原算法解析出音频数据中初始时刻声源的初始位置信息和初始角度信息作为原始声场中声源的初始信息。由于不同时刻声源的初始信息不同,因此通过确定声源的初始信息可为下一步对音频数据的处理提供数据基础。
s230:获取目标的朝向变化信息、位置变化信息和角度变化信息。
通过三轴陀螺仪传感器可建立基于x轴、y轴和z轴三维立体坐标系,在现有技术的基础上,由于增加了z轴,因此可以获取到用户的不同方向、不同角度以及不同朝向的信息。
s240:根据音频数据信息和目标的朝向变化信息、位置变化信息、和/或角度变化信息,基于预设处理算法,得到声场中音频信号的衰减度。
示例性的,随着用户位置的变化,用户的头部和双耳与原始声场中的声源的距离也相应地发生变化。因此,可通过分别获取用户头部和双耳在运动前的初始位置信息和初始角度信息以及声场中声源的初始位置信息和初始角度信息,并可分别计算出在运动之前用户头部和双耳与声源的初始相对距离。示例性的,用户头部信息(包括位置信息和角度信息)的获取可以间隔10秒的时间为基准,即每隔10秒获取一次用户的头部位置、双耳的位置和头部旋转的角度,前一个10秒所获取的位置信息和角度信息可作为下一个10秒信息处理的基础,以此类推。
示例性的,根据音频数据信息和目标的朝向变化信息、位置变化信息、和/或角度变化信息,基于预设处理算法,得到声场音频信号的衰减度的步骤可以包括:
确定所述目标与所述声场中声源的初始距离;根据所述目标的朝向变化信息、位置变化信息、和/或角度变化信息确定运动后的所述目标与所述声源的相对位置信息;根据所述初始距离和所述相对位置信息确定所述音频信号的衰减度。
其中,对于不同的声场,声源的数目不同,且声源的位置也不是固定不变的。下面分别以单声源和多声源为例进行具体说明:
1、针对声场中只存在一个固定声源的情况:
当用户的头部运动之前,可通过头盔中的如陀螺仪等传感器或结合其他测距仪器获取用户的头部(或眼部)相对于固定声源的初始距离。以用户的头部未发生运动前的位置设置为坐标原点(0,0,0),则基于该初始距离可以确定出声源的初始坐标信息(x0,y0,z0)。
当传感器检测到用户抬头或低头时,在z轴方向上用户的头部位置相对于z0将产生大小为z1的变化:当z1>0时,表示用户抬头,此时则减弱声源左声道和右声道的音频信号的输出;当z1<0时,表示用户低头,此时,则增强声源左声道和右声道音频信号的输出。需要注意的是,预设最低音频信号对应的用户头部的仰角为45度,若仰角超过45度时,则输出的音频信号保持在与45度仰角相同的状态。相应的,预设最高音频信号对应的用户头部的俯角为30度,若俯角低于30度时,则输出的音频信号保持在与30度俯角相同的状态。
图3为本发明实施例二提供的一种单声源坐标位置变化的示意图,x轴、y轴和z轴的方向如图3所示。当传感器检测到用户头部左右扭转时,在x轴方向上用户头部的位置相对于x0产生大小为x1的变化:如图3所示,当x1>0时,z轴向x轴的正方向发生旋转,表示用户向右扭头,此时则减弱声源左声道音频信号的输出,同时增强右声道音频信号的输出。当用户向右扭头的角度达到90时,右声道音频信号的输出达到最大,左声道音频信号的输出降到最低;当x1<0时,表示用户向左扭头,此时增强左声道音频信号的输出,同时减弱右声道的音频信号的输出,当用户向左扭头的角度达到90时,左声道音频信号的输出达到最大,右声道音频信号的输出降到最低。需要注意的是,当用户扭头旋转的角度达到180度时,左声道和右声道音频信号的输出状态与用户头部未发生扭动时输出的状态相反。当用户扭头旋转的角度为360度时,则左声道和右声道音频信号的输出状态与头部未发生扭转时相同。
当传感器检测到用户向前靠近声源或向后远离声源(声源位置仍保持固定)时,在y轴方向上用户的头部相对于声源的位置y0产生大小为y1的变化。当y1<0时,表示用户远离声源,此时则减弱左声道和右声道音频信号的输出;当y1>0时,表示用户靠近声源,此时则增强左声道和右声道音频信号的输出。
2、针对声场中存在多个声源的情况:
对于声场中存在多个声源这种情况,可将每个声源单独处理,若多个声源的位置固定不变,则对于每个声源而言,其音频信号衰减度的确定方式与上述情况1中只存在一个固定声源的情况相同,具体可参照上述情况1所提供的方式。
若每个声源的位置为非固定,则每个声源与用户头部的距离都不是固定不变的,以用户的头部未发生运动前的位置为坐标原点(0,0,0),则在不同时刻,每个声源都可确定出对应的坐标信息(xn,yn,zn),并且每一时刻的坐标信息都可作为下一时刻坐标信息确定的基础。其中,将各个声源的初始坐标信息设置为(x0,y0,z0),对于某一设定的时刻,当用户上下抬头(z轴数值的变化)、用户左右扭头(x轴数值的变化)以及用户向前或向后运动(y轴数值的变化)时,音频信号的衰减度与固定声源的情况(上述情况1)下音频信号衰减度的确定方式相同,具体可参照上述情况1所提供的方式。在计算出各个声源音频信号的衰减度后,可对不同声源输出的音频信号进行调整并将调整后的所有音频信号做叠加处理,以使用户听到的声音可以跟随用户的运动而相应地发生改变。
进一步的,在声源位置固定的情况下,音频信号的衰减度与目标和声源之间的初始距离存在线性关系,因此,目标与声源的初始距离越远,音频信号的衰减度越大。
综上所述,通过确定目标(例如用户头部或用户眼部)与各个声源的初始距离,并获取目标的运动信息后,可确定各个声源所要输出的音频信号的衰减度;根据确定的衰减度,通过调整各个声源输出的音频信号,可以使得声场中的音频信号跟随用户的运动实时得到更新,在听觉方面提升用户体验。
可选的,用户头盔或眼镜中的传感器可以实时跟踪用户面部位置并计算出用户视觉焦点的坐标信息。当视觉焦点与声源物体发生重合时,可增加音频信号的输出,以强化音频信号的输出效果。其中,完成音频信号的调整的时间可控制到20ms以内,帧率最低设置为60hz,这样设置可以使得用户基本感受不到声音回馈的延时及卡顿,提升了用户体验。
s250:根据音频数据信息和衰减度,基于预设处理算法,对声场进行重建,得到基于目标的声场音频数据。
示例性的,步骤s250可包括:根据所述衰减度调整所述音频信号的幅值,并将调整后的音频信号作为目标音频信号;基于所述预设处理算法,并根据所述目标音频信号对所述声场进行重建,得到所述基于目标的声场音频数据。
示例性的,当用户在看电影的场景下,若相对于初始位置(正向面对声源),用户头部转过180度(此时耳朵背向声源)时,用户所能接收到的声音的强度也会有所衰减(左声道和右声道输出的音频信号降低)。此时,可通过减小音频信号的幅值来降低耳机或音响输出的音量,然后基于hrtf算法且根据幅值减小后的音频信号对声场进行重建,使得用户可以感觉声音是从耳后传来的。这样设置的好处在于:用户能体验到由自身位置的改变而带来的声场的改变,增强了用户的听觉体验。
本实施例二通过在上述实施例的基础上,通过对声场中声源的位置信息进行具体化,根据音频数据信息和目标的朝向变化信息、位置变化信息、和/或角度变化信息,基于预设处理算法,得到声源声音的衰减度。通过将音频数据信息与声音的衰减度相结合,并基于预设处理算法,可对声场进行重建,可以使用户体验到虚拟环境中的声场随其位置的改变而发生了相应的变化,进而提升用户对于场景的体验感。
实施例三
图4为本发明实施例三提供的一种声场的音频数据的处理装置的结构框图。该装置可由软件和/或硬件实现,一般可集成音响或耳机等播放设备中。如图4所示,该装置包括:原始声场获取模块310、原始声场还原模块320、运动信息获取模块330和目标音频数据处理模块340。其中,
原始声场获取模块310,用于获取所述声场的音频数据;
原始声场还原模块320,用于根据所述音频数据,基于预设还原算法,得到所述声场的音频数据信息;
运动信息获取模块330,用于获取目标的运动信息;
目标音频数据处理模块340,用于根据所述音频数据信息和所述目标的运动信息,基于预设处理算法,得到基于目标的声场音频数据。
本实施例三提供了一种声场的音频数据的处理装置,在获取原始声场音频数据后,根据音频数据,基于预设还原算法,可对声场进行还原,得到原始声场的音频数据信息;通过获取目标的运动信息,并根据音频数据信息和目标的运动信息,基于预设处理算法,可以得到基于目标的声场音频数据,进而可以根据目标的实时运动情况对声场进行重建,使得声场中的音频数据可以跟随目标的运动发生相应的变化。在场景模拟的过程中,可增强声音的辅助效果,提升当前场景下用户的“沉浸感”体验。
在上述实施例的基础上,所述声场的音频数据信息包括:所述声场中声源的位置信息、方向信息、距离信息、和/或运动轨迹信息。
在上述实施例的基础上,所述运动信息包括:朝向变化信息、位置变化信息、和/或角度变化信息。
在上述实施例的基础上,所述目标音频数据处理模块340包括:衰减度确定单元:用于根据所述音频数据信息和所述目标的朝向变化信息、位置变化信息、和/或角度变化信息,基于所述预设处理算法,得到所述声场中音频信号的衰减度;声场重建单元:用于根据所述音频数据信息和所述衰减度,基于所述预设处理算法,对所述声场进行重建,得到所述基于目标的声场音频数据。
在上述实施例的基础上,所述衰减度确定单元具体用于:确定所述目标与声源的初始距离;根据所述目标的朝向变化信息、位置变化信息、和/或角度变化信息确定运动后的所述目标与声源的相对位置信息;根据所述初始距离和所述相对位置信息确定音频信号的衰减度。
在上述实施例的基础上,所述声场重建单元具体用于:根据所述衰减度调整所述音频信号的幅值,并将调整后的音频信号作为目标音频信号;基于所述预设处理算法,并根据所述目标音频信号对所述声场进行重建,得到所述基于目标的声场音频数据。
本发明实施例提供的声场的音频数据的处理装置可执行本发明任意实施例所提供的声场的音频数据的处理方法,具备执行方法相应的功能模块和有益效果。未在上述实施例中详尽描述的技术细节,可参见本发明任意实施例所提供的声场的音频数据的处理方法。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!