主动降噪方法、设备及耳机与流程
本发明涉及降噪技术领域,特别是涉及一种主动降噪装置和耳机,以及一种主动降噪方法。
背景技术:
现实生活中,用户在佩戴耳机时,耳机的壳体与人体耦合形成腔体。一方面,外界噪音可通过壳体传播进腔体内,壳体对外界噪音有一定的过滤作用,随着壳体的形状以及材料的不同,对外界噪音的过滤作用也不相同。另一方面,外界噪音还可通过壳体与人耳之间的缝隙泄露进腔体内,随着壳体与人体耦合程度的不同,外界噪音泄露进腔体内的程度也不相同,壳体与人体耦合的程度越紧密,泄露进腔体内的噪音越少。因此,人耳听到的噪音不等于外界噪音,实际上听到的是外界噪音通过壳体传播或通过缝隙泄露进腔体内的部分噪音。因此可通过外界噪音、壳体的材料、壳体的形状、壳体与人体的耦合程度等条件,推导出主动降噪技术中滤噪参数的数值。传统技术中,获取普遍适用的滤噪参数的过程计算繁杂且滤噪效果不佳。
技术实现要素:
基于此,有必要针对滤噪参数滤噪效果不佳的问题,提供一种基于反馈调整的主动降噪方法。
此外,还提供一种主动降噪设备及耳机。
一种主动降噪方法,用于降低壳体与人体耦合形成的腔体内的噪音,包括:
获取腔体内的第一噪音信息。
根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息。
根据互不重叠的频率段的噪音信息,分别调整对应于互不重叠的频率段的噪音信息的至少两个滤噪参数。
获取腔体外的第二噪音信息。
接收并根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。
在其中一个实施例中,根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息的步骤,包括:
通过至少两个分频滤波器将第一噪音信息分为至少两个互不重叠频率段的噪音信息。
在其中一个实施例中,根据互不重叠的频率段的噪音信息,分别调整对应于互不重叠的频率段的噪音信息的至少两个滤噪参数的步骤,包括:
通过连接至少两个分频滤波器的控制模块来根据互不重叠的频率段的噪音信息调整至少两个滤噪参数。
在其中一个实施例中,接收并根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据的步骤,包括:
通过连接控制模块的至少两个处理滤波器接收并根据至少两个滤噪参数对应处理第二噪音信息,以输出具有降噪效果的音频数据。
在其中一个实施例中,根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息的步骤,包括:
根据预设频率段将第一噪音信息按照时间先后依次分出至少两个互不重叠的频率段的噪音信息。
在其中一个实施例中,根据至少两个互不重叠的频率段的噪音信息,分别调整对应于至少两个互不重叠的频率段的噪音信息的至少两个滤噪参数的步骤,包括:
根据至少两个互不重叠的频率段的噪音信息,按照时间先后分别依次调整对应于至少两个互不重叠的频率段的噪音信息的至少两个滤噪参数。
在其中一个实施例中,接收并根据调整后的至少两个滤噪参数,处理第二噪音信息的步骤,包括:
接收并按照时间先后依次根据调整后的至少两个滤噪参数,处理第二噪音信息。
在其中一个实施例中,获取腔体内的第一噪音信息的步骤之前,还包括:
接收外部设备间歇性产生的数字音频信号。
检测是否接收到数字音频信号,未接收到数字音频信号时,执行获取腔体内的第一噪音信息的步骤。接收到数字音频信号时,暂停执行获取腔体内的第一噪音信息的步骤。
在其中一个实施例中,检测是否接收到数字音频信号,未接收到数字音频信号时,执行获取腔体内的第一噪音信息的步骤。接收到数字音频信号时,暂停执行获取腔体内的第一噪音信息的步骤,包括:
检测是否接收到数字音频信号的数码流以判断是否接收到数字音频信号。
一种主动降噪设备,包括:
壳体,用于与人体耦合形成腔体。
第一传感器,用于获取腔体内的第一噪音信息。
分频模块,与第一传感器电连接,用于根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息。
控制模块,与分频模块连接,用于根据至少两个互不重叠的频率段的噪音信息,分别调整对应于至少两个互不重叠的频率段的噪音信息的至少两个滤噪参数。
第二传感器,用于获取腔体外的第二噪音信息。
音频处理模块,分别与控制模块、第二传感器连接,用于接收并根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。
在其中一个实施例中,分频模块包括对应于至少两个互不重叠的频率段的至少两个分频滤波器。
在其中一个实施例中,音频处理模块包括连接控制模块的至少两个处理滤波器。处理滤波器用于处理第二噪音信息。
在其中一个实施例中,分频模块用于根据预设频率段将第一噪音信息按照时间先后依次分出至少两个互不重叠的频率段的噪音信息。
在其中一个实施例中,控制模块用于根据至少两个互不重叠的频率段的噪音信息,按照时间先后分别依次调整对应于至少两个互不重叠的频率段的噪音信息的至少两个滤噪参数。
在其中一个实施例中,音频处理模块用于接收并按照时间先后依次根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。
在其中一个实施例中,进一步包括,与控制模块连接的音频信号输入模块。音频信号输入模块用于接收外部设备间歇性产生的数字音频信号。其中,
控制模块检测到音频信号输入模块未接收到数字音频信号时,控制模块控制分频模块进行工作。控制模块检测到音频信号输入模块接收到数字音频信号时,控制模块控制分频模块暂停工作。
在其中一个实施例中,控制模块还包括数码流检测单元,数码流检测单元用于检测音频信号输入模块是否接受到数字音频信号的数码流,以判断是否接收到数字音频信号。
一种主动降噪耳机,包括:
壳体,用于与人体耦合形成腔体。
第一传感器,用于获取腔体内的第一噪音信息。
分频模块,与第一传感器电连接,用于根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息。
控制模块,与分频模块连接,用于根据互不重叠的频率段的噪音信息,分别调整对应于互不重叠的频率段的噪音信息的至少两个滤噪参数。
第二传感器,用于获取腔体外的第二噪音信息。
音频处理模块,分别与控制模块、第二传感器连接,用于接收并根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。
在其中一个实施例中,耳机包括头戴式耳机或入耳式耳机。
该主动降噪方法通过先设置一个大致的滤噪参数,然后在使用时对该滤噪参数进行反馈修正,从而省去前期为获得普遍适用的滤噪参数的大量计算,还可针对不同使用环境进行适应性修正,提高滤噪参数对不同环境的适应性。
附图说明
图1为一实施例中主动降噪方法的流程图;
图2为一实施例中主动降噪方法的流程图;
图3为一实施例中主动降噪方法的流程图;
图4为一实施例中主动降噪方法的流程图;
图5为一实施例中主动降噪设备的原理框图;
图6为一实施例中主动降噪设备的结构示意图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施方式。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施方式。相反地,提供这些实施方式的目的是使对本发明的公开内容理解的更加透彻全面。
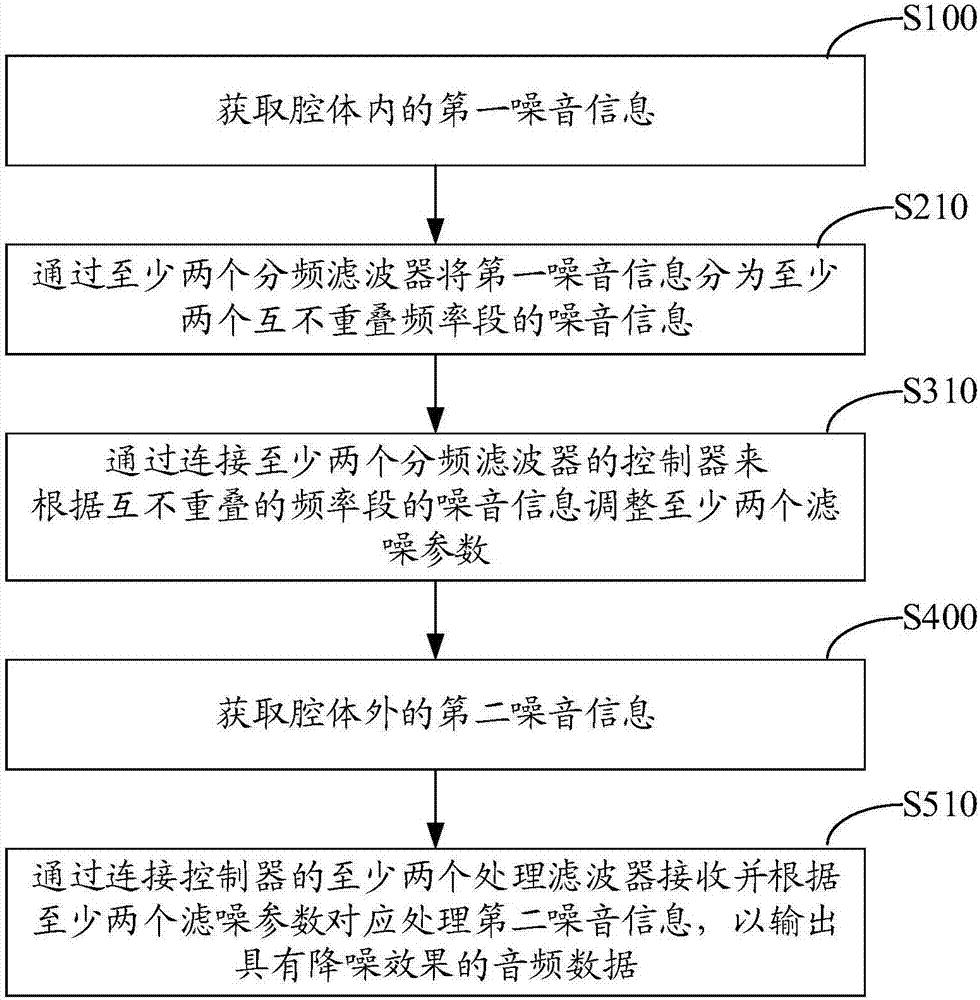
如图1所示,一种主动降噪方法,具体可以包括以下步骤:
步骤S100:获取腔体内的第一噪音信息。
步骤S200:根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息。
步骤S300:根据互不重叠的频率段的噪音信息,分别调整对应于互不重叠的频率段的噪音信息的至少两个滤噪参数。
步骤S400:获取腔体外的第二噪音信息。
步骤S500:接收并根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。
该主动降噪方法通过先设置一个大致的滤噪参数,然后在使用时对该滤噪参数进行反馈修正,从而省去前期为获得普遍适用的滤噪参数的大量计算,还可针对不同使用环境进行适应性修正,提高滤噪参数对不同环境的适应性。
步骤S100:获取腔体内的第一噪音信息。
腔体内的第一噪音信息包括噪音的频率、相位、幅度等。可以通过设置在腔体内的反馈麦克风获取腔体内的第一噪音信息。优选地,可将反馈麦克风设置在与产生反相噪音的驱动器距离较近的地方,最大程度上接收驱动器周围的腔体内的噪音,从而更好的还原驱动器周围噪声信息,使得驱动器产生的反相噪音能够更精确地抵消腔体内的噪音。
步骤S200:根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息。
通过分频点将全频率段或某一频率段划分为预设的多个频率段,该频率段互不重叠。分频点的设置不限,可根据第二噪音信息的频率段分布选择性设置分频点。
在一个实施例中,可选择在噪音集中分布的频率段集中布置分频点,在其余频率段少布置分频点甚至不布置分频点,从而既节省了元器件,又不影响主动降噪效果。例如,将4KHz、2KHz、1KHz、500Hz作为预设的分频点,可分为4KHz-2KHz、2KHz-1KHz、1KHz-500Hz的预设频率段。若噪音集中分布在4KHz-1KHz的频率段上,则可省略500Hz这一分频点,新设置的分频点为4KHz、2KHz、1KHz,对应的新的预设频率段为4KHz-2KHz、2KHz-1KHz。如此,可省略与1KHz-500Hz频率段对应的分频滤波器,达到节省元器件的目的。
在一个实施例中,预设的频率段选择低频频率段,因为外壳采用隔音材料能够很大程度上隔绝环境的中高频噪音,传播到人耳与耳机耦合形成的腔体内的第一噪音主要为隔音材料难以滤除的低频噪音,所以主动降噪设备可选择性地对低频噪音进行降噪处理,从而可节省分频滤波器,也可减少调整滤噪参数时的计算量,提高检测设备的检测速度。
优选地,预设的分频点可以选择8KHz、4KHz、2KHz、1KHz、750Hz、500Hz、250Hz和125Hz。从而将第一噪音信息分为8个互不重叠的频率段的噪音信息。
在一个实施例中,如图2所示,步骤S200包括步骤S210:通过至少两个分频滤波器将第一噪音信息分为至少两个互不重叠频率段的噪音信息。
在一个实施例中,若预设的分频点选择8KHz、4KHz、2KHz、1KHz、750Hz、500Hz、250Hz和125Hz,则通过对应的8个分频滤波器将第一噪音信息分为8个互不重叠的频率段的噪音信息。
在一个实施例中,如图3所示,步骤S200包括步骤S220:根据预设频率段将第一噪音信息按照时间先后依次分出至少两个互不重叠的频率段的噪音信息。
按照时间先后依次分出不同频率段的噪音信息的过程,可以是按照预设的顺序依次分出各个预设的频率段的噪音信息。预设的顺序可以是从低频率段到高频率段,也可以是从高频率段到低频率段,还可以按随机的顺序进行分频。例如,首先,分出第一噪音信息中4KHz-2KHz频率段的噪音信息,将分频结果推送给相应装置。然后,分出第一噪音信息中2KHz-1KHz频率段的噪音信息,再将分频结果推送给相应装置,接着,分出第一噪音信息中1KHz-500Hz频率段的噪音信息,将检测结果推送给相应装置。通过依次分出各频率段的噪音信息可以减少同一时间段内的计算量,有助于主动降噪过程的快速响应。随着计算量的减少也有助于减少元器件的数量,降低了成本。
步骤S300:根据互不重叠的频率段的噪音信息,分别调整对应于互不重叠的频率段的噪音信息的至少两个滤噪参数。
在一个实施例中,滤噪参数与分离出的互不重叠的频率段的噪音信息之间的对应关系可以是一一对应,也可以是多个频率段的噪音信息对应一个滤噪参数,还可以是一个频率段的噪音信息对应多个滤噪参数。
在一个实施例中,如图2所示,步骤S300包括步骤S310:通过连接至少两个分频滤波器的控制模块来根据互不重叠的频率段的噪音信息调整至少两个滤噪参数。
滤噪参数包括处理滤波器的滤波系数。在一个实施例中,可以根据5个分频滤波器分出的5个互不重叠频率段的噪音信息,对应调整5个处理滤波器的滤波系数。还可以根据8个分频滤波器分出的8个互不重叠的频率段的噪音信息,对应调整3个或5个处理滤波器的滤波系数。
在一个实施例中,如图3所示,步骤S300包括步骤S320:根据至少两个互不重叠的频率段的噪音信息,按照时间先后分别依次调整对应于至少两个互不重叠的频率段的噪音信息的至少两个滤噪参数。
除了可以在相同的时间段同时调整滤噪参数,还可以按照时间先后调整滤噪参数。
在一个实施例中,可以对先分离出的噪音信息进行优先处理,以提高调整滤噪参数的响应速度。例如,先分离出第一噪音信息中4KHz-2KHz频率段的噪音信息后,立即优先根据该噪音信息修正4KHz-2KHz频率段相对应的滤噪参数。接着再根据分离出第一噪音信息中2KHz-1KHz频率段的噪音信息调整2KHz-1KHz频率段相对应的滤噪参数。通过对先检测到的噪音信息进行优先处理,提高了调整滤噪参数过程的响应速度。
步骤S400:获取腔体外的第二噪音信息。
第二噪音信息包括噪音的频率、相位、幅度等。可以通过前馈麦克风获取第二噪音信息,前馈麦克风设置在腔体外。优选地,可将前馈麦克风设置在与产生反相噪音的驱动器距离较远的地方,以避免获取第二噪音信息时受到驱动器发出的反相噪音的干扰。
步骤S500:接收并根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。
根据滤噪参数处理第二噪音信息产生具有降噪效果的音频数据,通过该音频数据驱动位于腔体内的驱动器产生与腔体内第一噪音声波相位相差180°的反相噪音声波将腔体内的第一噪音中和,从而达到主动降噪的目的。驱动器可以是扬声器,具体可以是动圈式扬声器、气动式扬声器、电磁式扬声器等。
在一个实施例中,如图2所示,步骤S500包括步骤S510:通过连接控制模块的至少两个处理滤波器接收并根据至少两个滤噪参数对应处理第二噪音信息,以输出具有降噪效果的音频数据。
滤噪参数具体与各频率段的处理滤波器对应,通过调整处理滤波器的滤波系数以调整滤噪参数。可设置与不同滤噪参数对应的多个处理滤波器,多个处理滤波器分别处理第二噪音信息中不同频率段的噪音信息。例如,滤噪参数可包括中频滤噪参数和低频滤噪参数。中频滤噪参数对应第一处理滤波器的滤波系数,低频滤噪参数对应第二处理滤波器的滤波系数,通过调整第一处理滤波器的滤波系数来调整中频滤噪参数,通过调整第二处理滤波器的滤波系数来调整低频滤噪参数。此时,根据低频滤噪参数处理第二噪音信息中的低频噪音信息,以产生反相低频噪音;根据中频滤噪参数处理第二噪音信息中的中频噪音信息,以产生反相中频噪音。需要说明的是,滤噪参数还可以包括高频滤噪参数。
在一个实施例中,如图3所示,步骤S500包括步骤S520:接收并按照时间先后依次根据调整后的至少两个滤噪参数,处理第二噪音信息。
在一个实施例中,按照时间先后依次调整可以是按照预设的顺序依次调整与不同频率段对应的滤噪参数,预设的顺序可以是从低频率段到高频率段,也可以是从高频率段到低频率段,还可以按随机的顺序进行调整。
在一个实施例中,如图4所示,步骤S100之前还包括:
步骤S610:接收外部设备间歇性产生的数字音频信号。
步骤S620:检测是否接收到数字音频信号。未接收到所述数字音频信号时,执行所述获取腔体内的第一噪音信息的步骤;接收到所述数字音频信号时,暂停执行所述获取腔体内的第一噪音信息的步骤。如图4所示,进一步地,步骤S620在暂停执行步骤S100的同时,跳转至接受外部设备间隙性产生的数字音频信号的步骤,继续实时检测数字音频信号。
用户通过耳机听音乐时,扬声器等外部设备会间歇性在腔体内播放音乐。若在播放音乐的时间段获取腔体内的第一噪音信息,将不可避免夹杂音乐信息,此时就需要增加额外的复杂设备将获取到的音乐信息滤除。而通过在未接收到数字音频信号时(未播放音乐时)获取第一噪音信息,可避免增加额外的复杂设备将检测到的腔体内音频信息滤除,节约成本。
在一个实施例中,检测方式可以是检测是否接收到数字音频信号的数码流以判断是否接收到数字音频信号。数码流是数字音频信号的数码形成的数据流,通过检测数码流可以更加精准快速地判断音频间隙,且检测所需的元器件较为简单。
基于相同发明构思,以下提供一种主动降噪设备。如图5所示,主动降噪设备包括:
壳体(图中未示出),用于与人体耦合形成腔体。
第一传感器610,用于获取腔体内的第一噪音信息。
分频模块620,与第一传感器610电连接,用于根据预设频率段将第一噪音信息分为至少两个互不重叠的频率段的噪音信息。
控制模块630,与分频模块620连接,用于根据至少两个互不重叠的频率段的噪音信息,分别调整对应于至少两个互不重叠的频率段的噪音信息的至少两个滤噪参数。
第二传感器640,用于获取腔体外的第二噪音信息。
音频处理模块650,分别与控制模块630、第二传感器640连接,用于接收并根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。
壳体是耳机等音频装置的一部分,第一传感器610可以是反馈麦克风,第二传感器640可以是前馈麦克风。分频模块620的处理步骤可以参考上述实施例的步骤S200。控制模块630的处理步骤可以参考上述实施例的步骤S300、步骤S310。音频处理模块650的处理步骤可以参考上述实施例的步骤S500。在此不再赘述。
在一个实施例中,分频模块620包括对应于至少两个互不重叠的频率段的至少两个分频滤波器。分频滤波器的处理步骤可以参考上述实施例的步骤S210。
在一个实施例中,分频模块620用于根据预设频率段将第一噪音信息按照时间先后依次分出至少两个互不重叠的频率段的噪音信息。分频滤波器的处理步骤可以参考上述实施例的步骤S220。
在一个实施例中,控制模块630用于根据至少两个互不重叠的频率段的噪音信息,按照时间先后分别依次调整对应于至少两个互不重叠的频率段的噪音信息的至少两个滤噪参数。控制模块630的处理步骤可以参考上述实施例的步骤S320。
在一个实施例中,音频处理模块650包括连接控制模块630的至少两个处理滤波器。处理滤波器用于处理第二噪音信息。处理滤波器的处理步骤可以参考上述实施例的步骤S510。
在一个实施例中,音频处理模块650用于接收并按照时间先后依次根据调整后的至少两个滤噪参数,处理第二噪音信息,以输出具有降噪效果的音频数据。音频处理模块650的处理步骤可以参考上述实施例的步骤S520。
在一个实施例中,如图6所示,主动降噪设备包括用于与人体耦合形成腔体的壳体710,壳体710是头戴式耳机或入耳式耳机等音频装置的一部分。壳体710外的噪音有一部分会泄露进壳体710内,壳体710内的噪音称为第一噪音,壳体710外的噪音称为第二噪音。第一传感器720为反馈麦克风,第一传感器720获取腔体内的第一噪音信息,第一噪音信息通过音频流1的形式传输至分频模块730,分频模块730根据预设频率段将第一噪音信息分为多个互不重叠频率段的噪音信息后形成控制流4传输至控制模块740,控制模块740接收并处理控制流4以调整至少两个不同频率段的滤噪参数,该滤噪参数包括滤波系数。接着控制模块740通过控制流2将调整后的滤噪参数传递至音频处理模块750,音频处理模块750根据调整后的滤噪参数调整自身处理滤波器的滤波系数,该处理滤波器处理第二传感器760获取的第二噪音信息,以输出具有降噪效果的音频数据至驱动器770。驱动器770播放音频数据产生降噪声音。
进一步地,控制模块740连接音频输入模块780。音频输入模块780间歇性输入数字音频信号(如输入多首音乐音频信号,每首音乐间存在时间间隙)分频模块730具有开关功能,在每首音乐间隙执行进行分频工作。具体为,控制模块740连接音频输入模块780,通过检测数字音频信号的数码流(即控制流1)判定当前是否处于音乐间隙。控制模块740根据控制流1产生控制流3,以控制在音乐间隙打开分频模块730。
该主动降噪设备实现在原降噪处理的基础上,获取腔体内依然残留的第一噪音信息,根据第一噪音信息分频率段反馈调整滤噪参数,调整后的滤噪参数可用于消除残留的噪音信息,提高主动降噪处理的准确性。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!