一种基于残基接触信息辅助评价的蛋白质结构预测方法与流程
本发明涉及一种生物学信息学、智能优化、计算机应用领域,尤其涉及的是一种基于残基接触信息辅助评价的蛋白质结构预测方法。
背景技术:
蛋白质结构是指蛋白质分子的空间结构。蛋白质主要由碳、氢、氧、氮等化学元素组成,是一类重要的生物大分子,所有蛋白质都是由20种不同氨基酸连接形成的多聚体,在形成蛋白质后,这些氨基酸又被称为残基。蛋白质大小的范围可以从这样一个下限一直到数千个残基。目前估计的蛋白质的平均长度在不同的物种中有所区别,一般约为200-380个残基,而真核生物的蛋白质平均长度比原核生物长约55%。更大的蛋白质聚合体可以通过许多蛋白质亚基形成;如由数千个肌动蛋白分子聚合形成蛋白纤维。要发挥生物学功能,蛋白质需要正确折叠为一个特定构型,主要是通过大量的非共价相互作用(如氢键,离子键,范德华力和疏水作用)来实现;此外,在一些蛋白质(特别是分泌性蛋白质)折叠中,二硫键也起到关键作用。为了从分子水平上了解蛋白质的作用机制,常常需要测定蛋白质的三维结构。
由于高通量测序技术的快速发展,加之实验解析蛋白质三维结构技术(x射线晶体学、核磁共振光谱、电子显微镜以及冷冻电镜)耗时且代价昂贵,导致已知序列数目和解析出的蛋白质结构数目间的鸿沟呈指数增加。此外,生物学中心法则中的第二遗传密码和蛋白质折叠机理需要研究学者们进行探索。因此,在无全长模板的情况下(序列相似度<20%),利用计算机,结合优化算法,从氨基酸序列开始,从头预测蛋白质结构是一个研究方法。anfinsen热力学假说表明:蛋白质的空间结构由氨基酸序列唯一确定;蛋白质的空间结构是稳定的;蛋白质的天然构象处于自由能最低点。根据anfinsen原则,以计算机为工具,运用适当的算法,从氨基酸序列出发直接预测蛋白质的三维结构。
科学家提出了许多从头蛋白质结构预测方法,其预测精度在casp比赛的推动下有了巨大的提高。rosetta,quark在历届casp赛事中表现突出。两者都采用片段组装技术,并构建了基于知识的力场模型。然而,目前的力场模型的精度不足以准确搜索到近天然态区域,导致预测精度降低。
因此,现有的基于能量函数的蛋白质结构预测方法高效构象空间搜索和预测精度方面存在着缺陷,需要改进。
技术实现要素:
为了克服现有的基于能量函数的蛋白质结构预测方法高效构象空间搜索和预测精度方面的不足,本发明提供一种可以提高构象空间搜索效率的基于残基接触信息辅助评价的蛋白质结构预测方法。
本发明解决其技术问题所采用的技术方案是:
一种基于残基接触信息辅助评价的蛋白质结构预测方法,所述方法包括以下步骤:
1)给定输入序列信息,利用robetta服务器(http://robetta.bakerlab.org/)获得该序列的片段库;
2)利用raptorx-contact(http://raptorx.uchicago.edu/contactmap/)预测该序列的接触图,获得接触概率大于0.6的n个残基对,接触是指cα-cα欧氏距离小于
3)初始化:种群规模np,种群第一阶段和第二阶段最大迭代次数分别为g1,g2,根据输入序列,执行rosettaabinitio协议的第一与第二阶段np次,产生初始构象种群p={c1,c2,...,cnp},其中cnp表示第np个个体,记当前代数g=0;
4)进入种群进化第一阶段,过程如下:
4.1)对种群所有个体ci,i∈{1,...,np}进行片段组装,片段长度为9,得到候选个体ci′;
4.2)根据n个残基对的接触概率分别计算ci和ci′的评分函数影响因子μ和μ′:
其中dk和dk′分别是ci和ci′的第k对残基间的cα-cα距离,μk和μk′是对应评分函数影响因子的分项;
4.3)根据能量函数rosettascore3计算ci和ci′的能量值escore3、e′score3:
4.4)利用评分影响因子计算ci和ci′基于接触的评分s=μescore3,s′=μ′e′score3,并利用metropolis准则概率接受,若接受,则令ci=ci′;
4.5)遍历种群所有个体,得到下一代种群,令g=g+1;
5)累计学习种群残基对距离分布,过程如下:
5.1)残基对间距离离散化:根据第k个残基对的cα-cα欧氏距离dk,满足
5.2)计算种群在第k个残基对落入第b块区域的比例qk,b;
5.3)学习当前种群的残基对的距离分布:
6)判断种群进化第一阶段是否结束,若g>g1,则执行下一步;否则返回步骤4);
7)记第一阶段最终学习得到的残基对距离分布
8)进入种群进化第二阶段,过程如下:
8.1)对种群所有个体ci,i∈{1,...,np}进行片段组装,片段长度为3,得到候选个体ci′;
8.2)利用残基距离分布lk,b建立残基对距离辅助的评分函数:分别计算ci和ci′的k个残基对距离落入的区域,记为b1,b2,...,bm...,bk和b1′,b2′,...,bn′...,bk′,bm∈{1,2...,13},bn′∈{1,2...,13},m∈{1,2...,k},n∈{1,2...,k},该评分函数可以表示为:
其中w是接触信息贡献因子,0≤w≤1;
9)利用metropolis准则概率接受,若接受,则令ci=ci′;
10)遍历当前种群所有个体,得到下一代种群,令g=g+1;判断种群进化第一阶段是否结束,若g>g2,则执行下一步;否则返回步骤8);
11)利用聚类工具spicker对metropolis准则接受的所有过程点聚类,以最大类的类心构象为最终预测结果。
本发明的技术构思为:首先,利用robetta和raptorx-contact得到片段库和接触图;其次,在种群进化的两个阶段,以不同的方式利用接触图辅助评价构象;最后,通过聚类得到最终预测结果。
本发明的有益效果表现在:利用接触图信息,辅助评价构象,保留拓扑较优的构象,从而提高搜索效率,提高预测精度。
附图说明
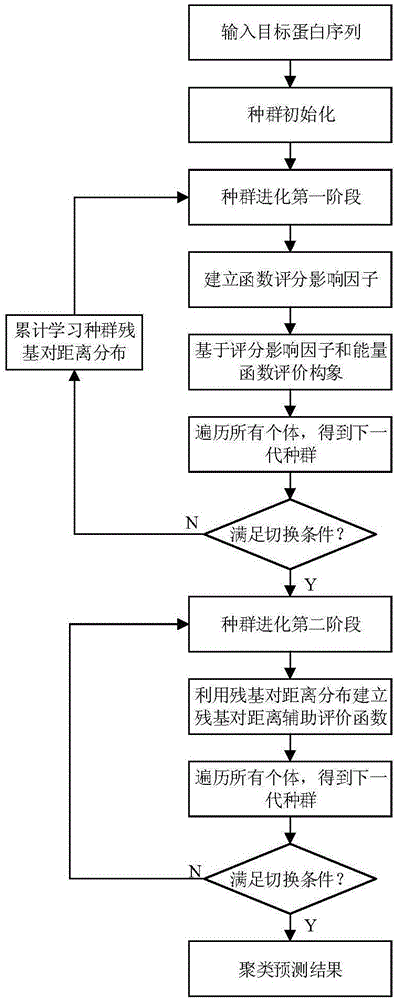
图1是基于残基接触信息辅助评价的蛋白质结构预测方法的基本流程图。
图2是基于残基接触信息辅助评价的蛋白质结构预测方法对蛋白质1m6ta进行结构预测得到的三维结构图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1和图2,一种基于残基接触信息辅助评价的蛋白质结构预测方法,包括以下步骤:
1)给定输入序列信息,利用robetta服务器(http://robetta.bakerlab.org/)获得该序列的片段库;
2)利用raptorx-contact(http://raptorx.uchicago.edu/contactmap/)预测该序列的接触图,获得接触概率大于0.6的n个残基对,接触是指cα-cα欧氏距离小于
3)初始化:种群规模np,种群第一阶段和第二阶段最大迭代次数分别为g1,g2,根据输入序列,执行rosettaabinitio协议的第一与第二阶段np次,产生初始构象种群p={c1,c2,...,cnp},其中cnp表示第np个个体,记当前代数g=0;
4)进入种群进化第一阶段,过程如下:
4.1)对种群所有个体ci,i∈{1,...,np}进行片段组装,片段长度为9,得到候选个体ci′;
4.2)根据n个残基对的接触概率分别计算ci和ci′的评分函数影响因子μ和μ′:
其中dk和dk′分别是ci和ci′的第k对残基间的cα-cα距离,μk和μk′是对应评分函数影响因子的分项;
4.3)根据能量函数rosettascore3计算ci和ci′的能量值escore3、e′score3:
4.4)利用评分影响因子计算ci和ci′基于接触的评分s=μescore3,s′=μ′e′score3,并利用metropolis准则概率接受,若接受,则令ci=ci′;
4.5)遍历种群所有个体,得到下一代种群,令g=g+1;
5)累计学习种群残基对距离分布,过程如下:
5.1)残基对间距离离散化:根据第k个残基对的cα-cα欧氏距离dk,满足
5.2)计算种群在第k个残基对落入第b块区域的比例qk,b;
5.3)学习当前种群的残基对的距离分布:
6)判断种群进化第一阶段是否结束,若g>g1,则执行下一步;否则返回步骤4);
7)记第一阶段最终学习得到的残基对距离分布
8)进入种群进化第二阶段,过程如下:
8.1)对种群所有个体ci,i∈{1,...,np}进行片段组装,片段长度为3,得到候选个体ci′;
8.2)利用残基距离分布lk,b建立残基对距离辅助的评分函数:分别计算ci和ci′的k个残基对距离落入的区域,记为b1,b2,...,bm...,bk和b1′,b2′,...,bn′...,bk′,bm∈{1,2...,13},bn′∈{1,2...,13},m∈{1,2...,k},n∈{1,2...,k},该评分函数可以表示为:
其中w是接触信息贡献因子,0≤w≤1;
9)利用metropolis准则概率接受,若接受,则令ci=ci′;
10)遍历当前种群所有个体,得到下一代种群,令g=g+1;判断种群进化第一阶段是否结束,若g>g2,则执行下一步;否则返回步骤8);
11)利用聚类工具spicker对metropolis准则接受的所有过程点聚类,以最大类的类心构象为最终预测结果。
本实施例序列长度为106的α折叠蛋白质1di2a为实施例,一种基于残基接触信息辅助评价的蛋白质结构预测方法,包括以下步骤:
1)给定输入序列信息,利用robetta服务器(http://robetta.bakerlab.org/)获得该序列的片段库;
2)利用raptorx-contact(http://raptorx.uchicago.edu/contactmap/)预测该序列的接触图,获得接触概率大于0.6的n=115个残基对,接触是指cα-cα欧氏距离小于
3)初始化:种群规模np=300,种群第一阶段和第二阶段最大迭代次数分别为g1=2000,g2=4000,根据输入序列,执行rosettaabinitio协议的第一与第二阶段np次,产生初始构象种群p={c1,c2,...,cnp},其中cnp表示第np个个体,记当前代数g=0;
4)进入种群进化第一阶段,过程如下:
4.1)对种群所有个体ci,i∈{1,...,np}进行片段组装,片段长度为9,得到候选个体ci′;
4.2)根据n个残基对的接触概率分别计算ci和ci′的评分函数影响因子μ和μ′:
其中dk和dk′分别是ci和ci′的第k对残基间的cα-cα距离,μk和μk′是对应评分函数影响因子的分项;
4.3)根据能量函数rosettascore3计算ci和ci′的能量值escore3、e′score3:
4.4)利用评分影响因子计算ci和ci′基于接触的评分s=μescore3,s′=μ′e′score3,并利用metropolis准则概率接受,若接受,则令ci=ci′;
4.5)遍历种群所有个体,得到下一代种群,令g=g+1;
5)累计学习种群残基对距离分布,过程如下:
5.1)残基对间距离离散化:根据第k个残基对的cα-cα欧氏距离dk,满足
5.2)计算种群在第k个残基对落入第b块区域的比例qk,b;
5.3)学习当前种群的残基对的距离分布:
6)判断种群进化第一阶段是否结束,若g>g1,则执行下一步;否则返回步骤4);
7)记第一阶段最终学习得到的残基对距离分布
8)进入种群进化第二阶段,过程如下:
8.1)对种群所有个体ci,i∈{1,...,np}进行片段组装,片段长度为3,得到候选个体ci′;
8.2)利用残基距离分布lk,b建立残基对距离辅助的评分函数:分别计算ci和ci′的k个残基对距离落入的区域,记为b1,b2,...,bm...,bk和b1′,b2′,...,bn′...,bk′,bm∈{1,2...,13},bn′∈{1,2...,13},m∈{1,2...,k},n∈{1,2...,k},该评分函数可以表示为:
其中w是接触信息贡献因子,0≤w≤1;
9)利用metropolis准则概率接受,若接受,则令ci=ci′;
10)遍历当前种群所有个体,得到下一代种群,令g=g+1;判断种群进化第一阶段是否结束,若g>g2,则执行下一步;否则返回步骤8);
11)利用聚类工具spicker对metropolis准则接受的所有过程点聚类,以最大类的类心构象为最终预测结果。
以序列长度为106的α折叠蛋白质1m6ta为实施例,运用以上方法得到了该蛋白质的近天然态构象,最小均方根偏差为
以上说明是本发明以1m6ta蛋白质为实例所得出的预测效果,并非限定本发明的实施范围,在不偏离本发明基本内容所涉及范围的前提下对其做各种变形和改进,不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!