一种卵巢癌分子分型预测系统的制作方法
本发明涉及数据处理技术领域,具体为一种卵巢癌分子分型预测系统。
背景技术:
卵巢癌作为当今妇科癌症中死亡率最高的疾病,其早期诊断、预后和个体差异较大。根据现有的临床诊断及治疗手段难以继续提高卵巢癌的生存率,因而,基于癌症的异质性,有必要通过对卵巢癌的基因表达谱的挖掘和研究来深入认识卵巢癌复杂的致病机制。通过挖掘基因组学数据中卵巢癌的基因表达差异,可以将卵巢癌分成分化型、增殖型、免疫反应型、间质型4个亚型,以期于正确认识各亚型间的致病机制,并推断其起源,从根源上制定诊疗计划。
随着大数据的完善和发展,让基因在疾病中的作用机制不断为人所知,通过对亚型的研究,发现在不同的亚型中基因表达谱有所不同,这类特定的基因也在不同通路中发挥作用,这也提示,对卵巢癌的进一步分类及挖掘有助于认识到各亚型的起源、发病机制,为治疗、预后等可提供新的研究方向。
技术实现要素:
本发明的目的在于提供一种卵巢癌分子分型预测系统,以解决上述背景技术中提出的问题,本发明探索并建立了跨平台亚型分类模型,筛选与各亚型相关的特异性基因进行基因富集分析后,得出与各亚型相关的通路,从而可推测出各亚型的致病机制与起源,为临床早期筛查方法、癌症精准治疗及靶向治疗位点提供新的思路与方法,改善卵巢癌患者预后及中位生存期等。
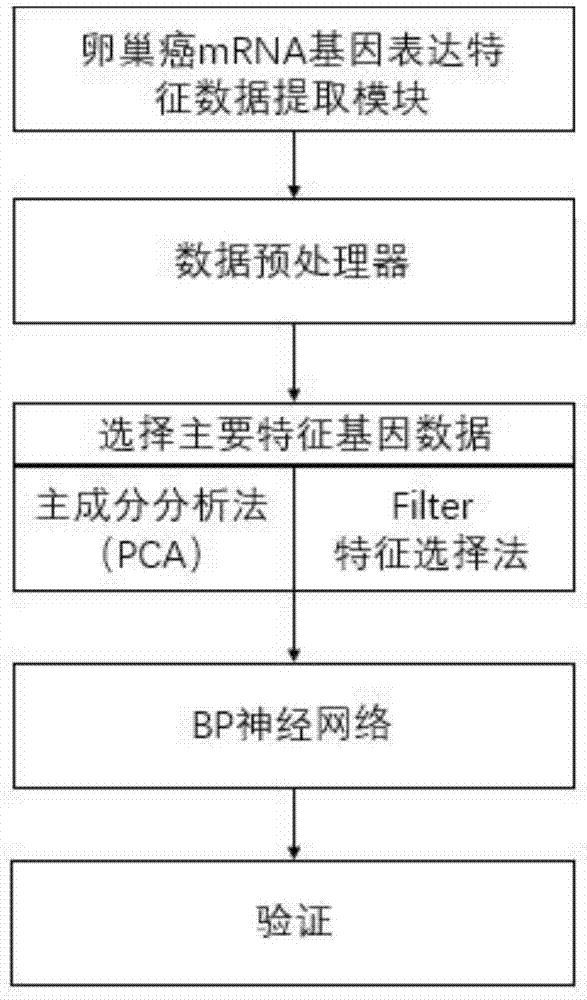
为实现上述目的,本发明提供如下技术方案:一种卵巢癌分子分型预测系统,主要包括以下步骤:
步骤1,卵巢癌mrna基因表达特征数据提取模块:获取卵巢癌基因表达数据;
步骤2,数据预处理器:对所有基因表达数据使用skleam中preprocessing.scale方法进行标准化处理,根据公式z-scroce=(x-μ)/s2,将每张mrna表达谱数据处理成均值为0,方差为1的服从正态分布的数据;
步骤3,选择主要特征基因数据:运用主成分分析法(pca)进行特征筛选,filter特征选择法选取出特征表达最明显的n个特征;
步骤4,使用bp神经网络对n个特征的基因数据训练模型;
步骤5,验证:使用一定量样本进行回带程序验证。
进一步的,所述主成分分析法(pca)为:
设原始变量x1,x2等数据矩阵为x,将数据矩阵按列进行中心标准化,然后求相关系数矩阵r;
r=(rij)p×p
其中,rij=rji,rii=1;
求r的特征方程:
det(r-λe)=0
其中,λ1>=λ2>=λp>0;
确定主成分个数:
其中,α为累计贡献率,一般取α>=80%;
计算m个相应的单位特征向量:
计算主成分:
zi=β1ix1+β2ix2+......+βpixp,i=1,2,......,m。
进一步的,所述filter特征选择法是一种启发式方法,其基本思想就是制定一个准则,用来衡量每个特征或者属性,对目标特征或属性的重要性程度,以此来对所有特征或者属性进行排序,或者进行择优选择,选取出特征表达最明显的n个特征。
进一步的,所述准则采用但不限于信息增益准则。
进一步的,所述bp神经网络包含输入层,隐含层和输出层:
假设有d个输入神经元,有1个输出神经元,q个隐含层神经元;
设输出层第j个神经元的阈值为θj;
设隐含层第h个神经元的阈值为γh;
输入层第i个神经元与隐含层第h个神经元之间的连接权为vih;
隐含层第h个神经元与输出层第j个神经元之间的连接权为whj;
记隐含层第h个神经元接收到来自于输入层的输入为αh;
记输出层第j个神经元接收到来自于隐含层的输入为βj;
其中bh为隐含层第h个神经元的输出;
理论推导:在神经网络中,神经元接收到来自其他神经元的输入信号,这些信号乘以权重累加到神经元接收的总输入值上,随后与当前神经元的阈值进行比较,然后通过激活函数处理,产生神经元的输出;
激活函数:采用sigmoid函数作为激活函数;
训练数据的时候,输入数据后得到的结果放入激活函数,与预期的结果进行比较,如果与预期结果有误差,则进行误差传递和调整参数;
sigmoid函数的公式如下:
对于一个训练例(xk,yk),假设神经网络的输出层为yk,则神经网络输出层第j个神经元的输出值可表示为:
f(***)表示激活函数,可以计算网络上,(xk,yk)的均方差误差为:
从隐含层的第h个神经元看,输入层总共有d个权重传递参数,共有l个权重传递参数传给输出层,自身还有1个阈值,一个隐含层神经元有(d+l+1)个参数待确定,输出层每个神经元还有一个阈值,所以总共有l个阈值,最后,总共有(d+l+1)*q+l个待定参数,随机给出这些待定的参数,后面通过bp算法的迭代,这些参数的值会逐渐收敛于合适的值;
任意权重参数的更新公式为:
w←w+δw
以隐含层到输出层的权重参数whj为例,求出均方差误差ek,期望值为0,或者为最小值,以目标的负梯度方向对参数进行调整,通过多次迭代,新的权重参数会逐渐趋近于最优解;
对于误差ek,给定学习率(learningrate)即步长η,有:
首先whj影响到了输出层神经元的输入值βj,然后影响到输出值yjk,然后再影响到误差ek,所以
根据输出层神经元的输入值βj的定义得到:
对于激活函数很容易通过求导证得下面的性质:
f′(x)=f(x)[1-f(x)]
使用这个性质进行如下推导:
令
又因为
所以得到
即
把其带入式子中,
得到
所以
通过不停地更新即梯度下降法就可实现权重更新了,w←w+δw,
η为学习率,即梯度下降的补偿;
其中
通过不断的误差传递,权重调整得到最后的模型,把测试的数据带入模型中,即输入层位置进行计算,模型训练的时候会把正确分类结果放进输出层,模型进行权重的调整,会使得最后得到的结果十分接近1或2或3或4,若测试数据的结果接近1判定为分化型,若接近2判定为增繁殖型,若接近3判定为免疫反应型,若接近4判定为间质型。
与现有技术相比,本发明的有益效果是:
本发明克服了以往的针对卵巢癌分子分型技术方法速度慢、泛化性能差、分类准确率低的缺陷,并且能够凭借卵巢癌病理切片实现机器自动识别及报错,实现了快速且准确率高的卵巢癌分子分型预测;利用本发明系统进行卵巢癌分子分型预测,能更好的帮助临床治疗方案的完善;本发明使卵巢癌患者治疗更有针对性,帮助提高患者预后及存活时间。
附图说明
图1为本发明的流程图;
图2为本发明简易bp神经网络示意图;
图3为本发明gse9891roc曲线图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。此处所描述的具体实施例仅用于解释本发明技术方案,并不限于本发明。
在对癌症亚型分类模型的研究中,现常用的建模方法为k-means,其分组的可预测性是其优点,但后期需要人工对各亚型进行定义,因此对于较为相似的两种亚型,可能存在分型的定义偏差。因此,我们采用了神经网络中的bp模型,可直接预测出每一个样本的准确亚型,这不失为癌症亚型分类的一种新方法。另外,通过对比与tcga团队的研究结果,及tothill等人的结论,我们证实了卵巢癌四型亚型分类法的可行性。并且,通过对卵巢癌亚型基因的通路分析,我们认为不同亚型间的病因机制也有所不同。
本发明提供一种技术方案:一种卵巢癌分子分型预测系统,如图1所示,主要包括以下步骤:
步骤1,卵巢癌mrna基因表达特征数据提取模块:获取卵巢癌基因表达数据;
步骤2,数据预处理器:对所有基因表达数据使用sklearn中preprocessing.scale方法进行标准化处理,根据公式z-scroce=(x-μ)/s2,将每张mrna表达谱数据处理成均值为0,方差为1的服从正态分布的数据;
步骤3,选择主要特征基因数据:运用主成分分析法(pca)进行特征筛选,filter特征选择法选取出特征表达最明显的n个特征;
步骤4,使用bp神经网络对n个特征的基因数据训练模型;
步骤5,验证:使用一定量样本进行回带程序验证。
进一步的,主成分分析法(pca)为:
设原始变量x1,x2等数据矩阵为x,将数据矩阵按列进行中心标准化,然后求相关系数矩阵r;
r=(rij)p×p
其中,rij=rji,rii=1;
求r的特征方程:
det(r-λe)=0
其中,λ1>=λ2>=λp>0;
确定主成分个数:
其中,α为累计贡献率,一般取α>=80%;
计算m个相应的单位特征向量:
计算主成分:
zi=β1ix1+β2ix2+......+βpixp,i=1,2,......,m。
进一步的,filter特征选择法为是一种启发式方法,其基本思想就是制定一个准则,用来衡量每个特征或者属性,对目标特征或属性的重要性程度,以此来对所有特征或者属性进行排序,或者进行择优选择,常用的衡量准则有假设检验的p值、相关系数、信息增益、信息熵等,选取出特征表达最明显的n个特征。
进一步的,衡量准则采用但不限于信息增益准则。
进一步的,如图2所示,这是一个简单的bp神经网络示意图,bp神经网络包含输入层,隐含层和输出层:
假设有d个输入神经元,有1个输出神经元,q个隐含层神经元;
设输出层第j个神经元的阈值为θj;
设隐含层第h个神经元的阈值为γh;
输入层第i个神经元与隐含层第h个神经元之间的连接权为vih;
隐含层第h个神经元与输出层第j个神经元之间的连接权为whj;
记隐含层第h个神经元接收到来自于输入层的输入为αh;
记输出层第j个神经元接收到来自于隐含层的输入为βj;
其中bh为隐含层第h个神经元的输出;
理论推导:在神经网络中,神经元接收到来自其他神经元的输入信号,这些信号乘以权重累加到神经元接收的总输入值上,随后与当前神经元的阈值进行比较,然后通过激活函数处理,产生神经元的输出;
激活函数:理想的激活函数是阶跃函数,“0”对应神经元抑制,“1”对应神经元兴奋,然而阶跃函数的缺点是不连续,不可导,且不光滑,所以常用sigmoid函数作为激活函数代替阶跃函数;
训练数据的时候,输入数据后得到的结果放入激活函数,与预期的结果进行比较,如果与预期结果有误差,则进行误差传递和调整参数;
阶跃函数和sigmoid函数的公式如下:
对于一个训练例(xk,yk),假设神经网络的输出层为yk,则神经网络输出层第j个神经元的输出值可表示为:
f(***)表示激活函数,可以计算网络上,(xk,yk)的均方差误差为:
从隐含层的第h个神经元看,输入层总共有d个权重传递参数,共有l个权重传递参数传给输出层,自身还有1个阈值,一个隐含层神经元有(d+l+1)个参数待确定,输出层每个神经元还有一个阈值,所以总共有l个阈值,最后,总共有(d+l+1)*q+l个待定参数,随机给出这些待定的参数,后面通过bp算法的迭代,这些参数的值会逐渐收敛于合适的值;
任意权重参数的更新公式为:
w←w+δw
以隐含层到输出层的权重参数whj为例,求出均方差误差ek,期望值为0,或者为最小值,以目标的负梯度方向对参数进行调整,通过多次迭代,新的权重参数会逐渐趋近于最优解;
对于误差ek,给定学习率(learningrate)即步长η,有:
首先whj影响到了输出层神经元的输入值βj,然后影响到输出值yjk,然后再影响到误差ek,所以
根据输出层神经元的输入值βj的定义得到:
对于激活函数很容易通过求导证得下面的性质:
f′(x)=f(x)[1-f(x)]
使用这个性质进行如下推导:
令
又因为
所以得到
即
把其带入式子中,
得到
所以
通过不停地更新即梯度下降法就可实现权重更新了,w←w+δw,
η为学习率,即梯度下降的补偿;
其中
通过不断的误差传递,权重调整得到最后的模型,把测试的数据带入模型中,即输入层位置进行计算,模型训练的时候会把正确分类结果放进输出层,模型进行权重的调整,会使得最后得到的结果十分接近1或2或3或4,若测试数据的结果接近1判定为分化型,若接近2判定为增繁殖型,若接近3判定为免疫反应型,若接近4判定为间质型。
在本发明中,根据基因表达量的大小对其进行排列,选出表达量最大的前50个基因,以这50个基因作为特征,将299例已分好亚型的tcga卵巢癌基因表达谱数据随机分为249例和50例,以249例为训练集,对tcga数据采用bp神经网络进行建模,将其分为4个卵巢癌的亚型,用剩余50例作验证集,通过同样的方法将其分为4个亚型,并反向验证模型的准确率,用已建立的模型对gse9891的数据进行分类,对模型进行优化并计算模型准确率,如图3所示。
以上所述仅表达了本发明的优选实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形、改进及替代,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!