一种基于残基特征距离的蛋白质结构预测方法与流程
本发明涉及一种生物学信息学、人工智能优化、计算机应用领域,尤其涉及的是一种基于残基特征距离的蛋白质结构预测方法。
背景技术:
蛋白质是维持生命活动、功能最多的生物单元,而蛋白质的生物功能由蛋白质的三级结构决定,因此通过一维序列来预测蛋白质的三级结构是生物信息领域主要研究的方向之一。蛋白质结构预测方法主要有两种途径:实验法和理论预测。虽然实验法可以准确预测某些特定的蛋白质结构,但由于预测费用过于昂贵、预测时间太长的缺点极大限制了实验预测方法的广发应用,因此理论预测方法的研究显得尤为重要。理论预测方法通常可以分为同源建模、穿线法、从头预测等三类;其中同源建模、穿线法不同程度的依赖于已知结构的模板,而从头预测法是从蛋白质序列出发,不需要任何已知的结构,而是以第一性原理构建蛋白质折叠力场,再通过相应的构象搜索方法,进而预测出目标蛋白质的三维结构。
尽管从头预测法对“第二遗传密码”的探索有非凡的意义,但随着氨基酸序列的增长,构象空间变的极其复杂,局部最小能量值的也随之增加,这就要求必须选择有效的搜索算法才能找到接近天然态的结构。为了解决该问题大量的研究者提出使用遗传算法、改进的禁忌搜索算法、模拟退火算法以及,遗传算法与模拟退火算法相结合的方法等优化方法,然而,这些方法运行时间长、效率低,具有一定的局限性。
因此,现有的构象空间搜索方法在预测精度和采样效率方面存在着缺陷,需要改进。
技术实现要素:
为了克服现有的蛋白质结构预测构象空间搜索方法存在采样效率较低、预测精度较低的不足,本发明提出一种采样效率较高、预测精度较高的基于残基特征距离的蛋白质结构预测方法。
本发明解决其技术问题所采用的技术方案是:
一种基于残基特征距离的蛋白质结构预测方法,所述方法包括以下步骤:
1)给定输入序列信息;
2)根据quark获得目标蛋白的初始残基特征距离集v={vk,k+n|k∈[1,l-n]},其中vk,k+n是目标蛋白中第k个残基的cα原子和第k+n个残基的cα原子之间的距离,l是序列长度,残基的片段长度n;
3)参数初始化:设置构象集规模np,初始构象中采样次数iter,迭代计数器co,最大搜索迭代次数cmax,概率参数p;
4)初始化构象集:启动np条montecarlo轨迹,每条轨迹搜索iter次,即生成np个初始构象;
5)对每个目标构象xi,i∈{1,...,np}进行如下操作:
5.1)构建轮盘赌采样机制,过程如下:
5.1.1)依次计算出目标构象xi的第k个氨基酸的cα原子和第k+n个氨基酸的cα原子之间的欧式距离
5.1.2)构建残基距离集vi与初始特征集v对应元素间的差值构成的特征距离误差集
5.1.3)根据
5.1.4)利用轮盘赌的方式选出特征距离误差集di中三个元素
5.2)针对构象xi启动三条montecarlo搜索轨迹,在不同的搜索轨迹中设定不同的残基采样范围,过程如下:
5.2.1)利用rosettascore3函数计算得到构象xi的能量值ei;
5.2.2)在第一条轨迹中设置残基的采样范围为
5.2.3)在相应的采样范围
5.2.4)根据montecarlo机制判断是否接收构象x′i,如果接收,则
5.2.5)在第二条轨迹中设置残基的采样范围为
5.2.6)在相应的采样范围
5.2.7)在第三条轨迹中设置残基的采样范围为
5.2.8)在相应的采样范围
5.3)随机生成rand∈[0,1],若rand≤p,则执行步骤4.4),否则执行步骤4.5);
5.4)分别计算出构象xi、
5.5)根据构象
5.5.1)根据步骤4.1.1)和4.1.2)中所述分别计算出构象
5.5.2)根据公式
5.5.3)与步骤4.5.2)同理分别计算出构象xg,xh,xy对应的manhattan距离值simg,simh,simy;
5.5.4)选出manhattan距离值最小的构象为潜在构象x∈{xg,xh,xy}以及相应的manhattan距离值sim,并比较潜在构象的manhattan距离值sim和目标构象的manhattan距离值simob的大小,若sim<simob,则潜在构象x进入下一代,否则目标构象进入下一代;
6)判断是否满足终止条件co>cmax,若满足终止条件则停止迭代,否则进入下一代,返回步骤4)。
本发明的技术构思为:首先,计算出先验知识中目标蛋白的初始残基特征距离与目标构象的特征距离误差,并将这些距离误差作为采样范围的适应度;然后,根据轮盘机制选择出适应度较高的残基范围作为有效的采样区域;最后,manhattan距离与能量函数作为打分函数来指导种群的更新,进而选出潜在的构象。
本发明的有益效果表现在:一方面将特征距离与轮盘赌策略相结合选择有效的采样区域,有效地降低了空间复杂度,加快了搜索速度;另一方面通过加入残基间的空间距离信息指导构象更新,降低了由于能量函数不精确带来的误差,进而大大提高了预测精度。
附图说明
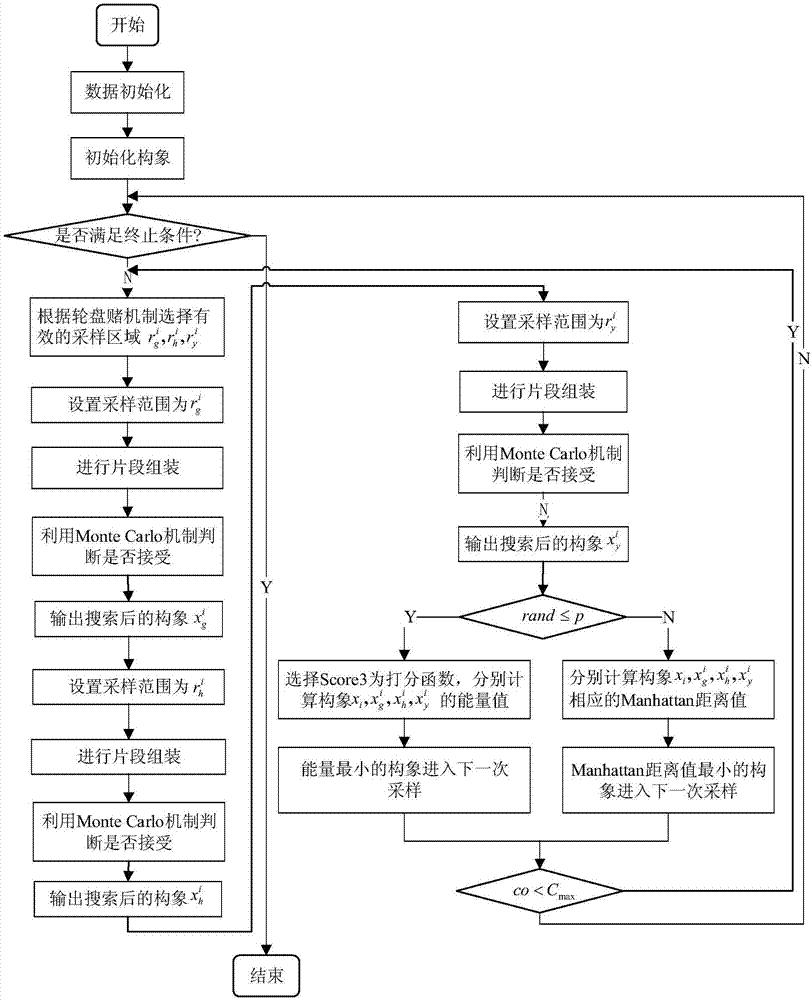
图1是基于残基特征距离的蛋白质结构预测方法的基本流程图。
图2是基于残基特征距离的蛋白质结构预测方法对蛋白质1ail进行结构预测时的构象更新示意图。
图3是基于残基特征距离的蛋白质结构预测方法对蛋白质1ail进行结构预测得到的三维结构图。
下面结合附图对本发明作进一步描述。
参照图1~图3,一种基于残基特征距离的蛋白质结构预测方法,所述方法包括以下步骤:
1)给定输入序列信息;
2)根据quark获得目标蛋白的初始残基特征距离集v={vk,k+n|k∈[1,l-n]},其中vk,k+n是目标蛋白中第k个残基的cα原子和第k+n个残基的cα原子之间的距离,l是序列长度,残基的片段长度n;
3)参数初始化:设置构象集规模np,初始构象中采样次数iter,迭代计数器co,最大搜索迭代次数cmax,概率参数p;
4)初始化构象集:启动np条montecarlo轨迹,每条轨迹搜索iter次,即生成np个初始构象;
5)对每个目标构象xi,i∈{1,...,np}进行如下操作:
5.1)构建轮盘赌采样机制,过程如下:
5.1.1)依次计算出目标构象xi的第k个氨基酸的cα原子和第k+n个氨基酸的cα原子之间的欧式距离
5.1.2)构建残基距离集vi与初始特征集v对应元素间的差值构成的特征距离误差集
5.1.3)根据
5.1.4)利用轮盘赌的方式选出特征距离误差集di中三个元素
5.2)针对构象xi启动三条montecarlo搜索轨迹,在不同的搜索轨迹中设定不同的残基采样范围,过程如下:
5.2.1)利用rosettascore3函数计算得到构象xi的能量值ei;
5.2.2)在第一条轨迹中设置残基的采样范围为
5.2.3)在相应的采样范围
5.2.4)根据montecarlo机制判断是否接收构象x′i,如果接收,则
5.2.5)在第二条轨迹中设置残基的采样范围为
5.2.6)在相应的采样范围
5.2.7)在第三条轨迹中设置残基的采样范围为
5.2.8)在相应的采样范围
5.3)随机生成rand∈[0,1],若rand≤p,则执行步骤4.4),否则执行步骤4.5);
5.4)分别计算出构象xi、
5.5)根据构象
5.5.1)根据步骤4.1.1)和4.1.2)中所述分别计算出构象
5.5.2)根据公式
5.5.3)与步骤4.5.2)同理分别计算出构象xg,xh,xy对应的manhattan距离值simg,simh,simy;
5.5.4)选出manhattan距离值最小的构象为潜在构象x∈{xg,xh,xy}以及相应的manhattan距离值sim,并比较潜在构象的manhattan距离值sim和目标构象的manhattan距离值simob的大小,若sim<simob,则潜在构象x进入下一代,否则目标构象进入下一代;
6)判断是否满足终止条件co>cmax,若满足终止条件则停止迭代,否则进入下一代,返回步骤4)。
本实施例序列长度为73的α折叠蛋白质1ail为实施例,一种基于残基特征距离的蛋白质结构预测方法,其中包含以下步骤:
1)给定输入序列信息;
2)根据quark获得目标蛋白的初始残基特征距离集v={vk,k+n|k∈[1,l-n]},其中vk,k+n是目标蛋白中第k个残基的cα原子和第k+n个残基的cα原子之间的距离,l是序列长度,残基的片段长度n;
3)参数初始化:设置构象集规模np=100,初始构象中采样次数iter=1000,迭代计数器co=0,最大搜索迭代次数cmax=5000,概率参数p=0.5;
4)初始化构象集:启动np条montecarlo轨迹,每条轨迹搜索iter次,即生成np个初始构象;
5)对每个目标构象xi,i∈{1,...,np}进行如下操作:
5.1)构建轮盘赌采样机制,过程如下:
5.1.1)依次计算出目标构象xi的第k个氨基酸的α原子和第k+n个氨基酸的cα原子之间的欧式距离
5.1.2)构建残基距离集vi与初始特征集v对应元素间的差值构成的特征距离误差集
5.1.3)根据
5.1.4)利用轮盘赌的方式选出特征距离误差集di中三个元素
5.2)针对构象xi启动三条montecarlo搜索轨迹,在不同的搜索轨迹中设定不同的残基采样范围,过程如下:
5.2.1)利用rosettascore3函数计算得到构象xi的能量值ei;
5.2.2)在第一条轨迹中设置残基的采样范围为
5.2.3)在相应的采样范围
5.2.4)根据montecarlo机制判断是否接收构象x′i,如果接收,则
5.2.5)在第二条轨迹中设置残基的采样范围为
5.2.6)在相应的采样范围
5.2.7)在第三条轨迹中设置残基的采样范围为
5.2.8)在相应的采样范围
5.3)随机生成rand∈[0,1],若rand≤p,则执行步骤4.4),否则执行步骤4.5);
5.4)分别计算出构象xi、
5.5)根据构象
5.5.1)根据步骤4.1.1)和4.1.2)中所述分别计算出构象
5.5.2)根据公式
5.5.3)与步骤4.5.2)同理分别计算出构象xg,xh,xy对应的manhattan距离值simg,simh,simy;
5.5.4)选出manhattan距离值最小的构象为潜在构象x∈{xg,xh,xy}以及相应的manhattan距离值sim,并比较潜在构象的manhattan距离值sim和目标构象的manhattan距离值simob的大小,若sim<simob,则潜在构象x进入下一代,否则目标构象进入下一代;
6)判断是否满足终止条件co>cmax,若满足终止条件则停止迭代,否则进入下一代,返回步骤4)。
以序列长度为73的α折叠蛋白质1ail为实施例,运用以上方法得到了该蛋白质的近天然态构象,最小均方根偏差为
以上说明是本发明以1ail蛋白质为实例所得出的预测效果,并非限定本发明的实施范围,在不偏离本发明基本内容所涉及范围的前提下对其做各种变形和改进,不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!