机器人模型的学习装置、机器人模型的机器学习方法、机器人模型的机器学习程序、机器人控制装置、机器人控制方法、以及机器人控制程序与流程
公开的技术涉及机器人模型的学习装置、机器人模型的机器学习方法、机器人模型的机器学习程序、机器人控制装置、机器人控制方法、以及机器人控制程序。
背景技术:
1、为了自动获得机器人为了完成作业所需的控制规则,通过机器学习来进行学习机器人模型。
2、例如,在日本特开2020-055095号公报中,公开一种控制具备检测施加在机械手的力和力矩的功能的工业用机器人的控制装置,具备:控制部,基于控制指令控制所述工业用机器人、数据获取部,获取施加在所述工业用机器人的机械手的力以及力矩的至少一个作为获取数据、以及预处理部,所述预处理部基于所述获取数据,生成表示包括施加在所述机械手的力涉及的信息的力状态数据、以及所述机械手涉及的控制指令的调整行动的控制指令调整数据作为状态数据,基于所述状态数据,执行与所述机械手涉及的控制指令的调整行动相关的机器学习的处理的技术。
技术实现思路
1、发明所要解决的技术问题
2、但是,通过机器学习学习机器人模型时的参数的设定以及奖励函数的设计很难,因此有效学习是困难的。
3、公开的技术是鉴于上述的点而成的,以在通过机器学习学习机器人模型时,提供可以有效学习的机器人模型的学习装置、机器人模型的机器学习方法、机器人模型的机器学习程序、机器人控制装置、机器人控制方法、以及机器人控制程序为目的。
4、用于解决技术问题的方案
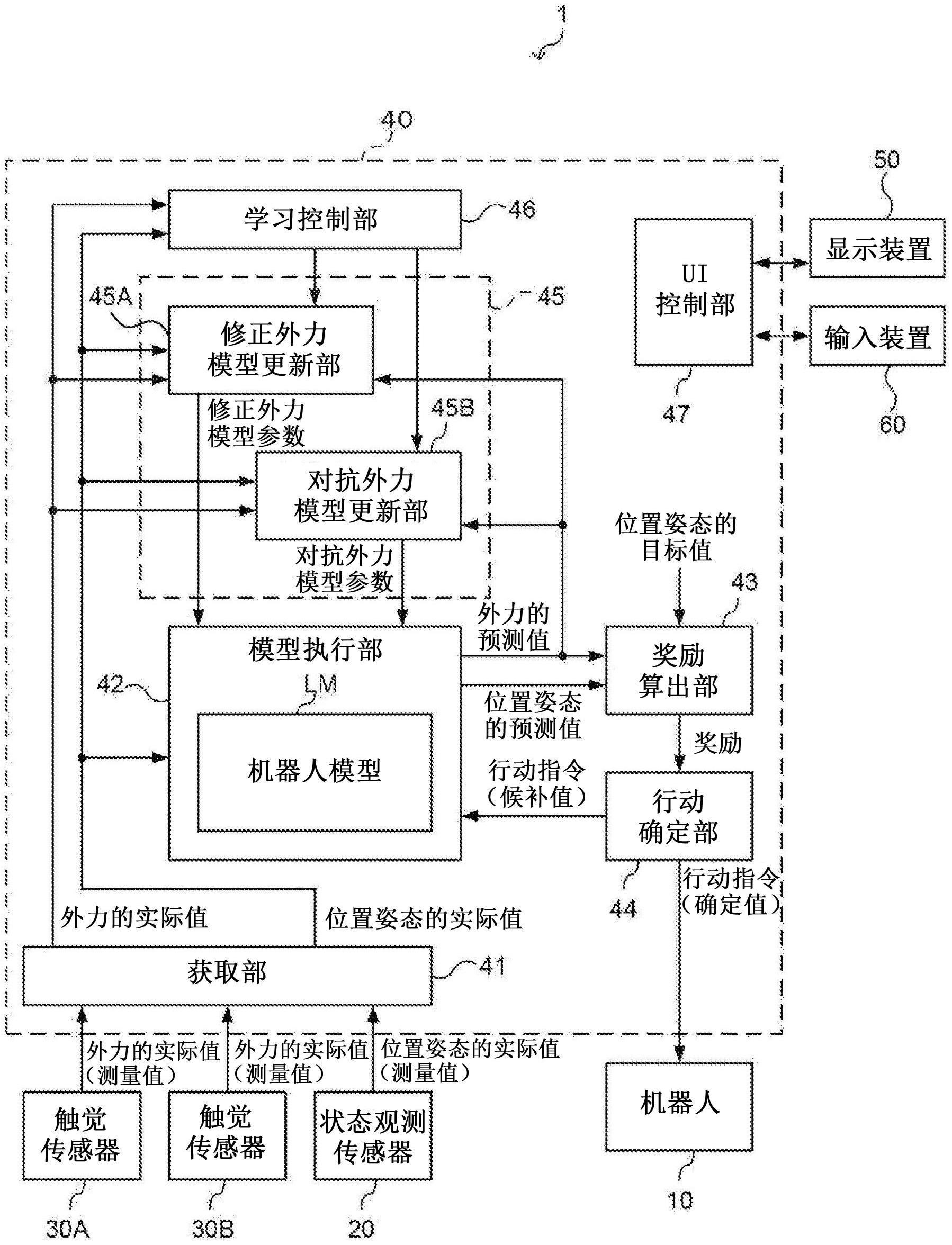
5、公开的第一方式是机器人模型的学习装置,具备:获取部,获取机器人的位置姿态的实际值以及对所述机器人施加的外力的实际值、机器人模型,所述机器人模型包括基于某一时段的所述位置姿态的实际值以及能够提供给所述机器人的行动指令,算出下一时段的所述机器人的位置姿态的预测值的状态迁移模型以及算出对所述机器人施加的外力的预测值的外力模型;模型执行部,执行所述机器人模型;奖励算出部,基于所述位置姿态的预测值与应达到的位置姿态的目标值之间的误差以及所述外力的预测值算出奖励;行动确定部,对于每个控制周期,生成所述行动指令的多个候补并提供给所述机器人模型,基于所述奖励算出部对应于所述行动指令的多个候补分别算出的奖励确定使奖励最大化的行动指令;以及外力模型更新部,更新所述外力模型,以使得所述外力模型基于确定的所述行动指令算出的所述外力的预测值和与该外力的预测值对应的所述外力的实际值之间的差异变小。
6、根据上述第一方式,也可以构成为具备状态迁移模型更新部,所述状态迁移模型更新部更新所述状态迁移模型,以使得所述状态迁移模型基于确定的所述行动指令算出的所述位置姿态的预测值和与该位置姿态的预测值对应的所述位置姿态的实际值之间的误差变小。
7、根据上述第一方式,也可以为在所述外力为抑制所述误差的扩大的外力即修正外力的情况下,所述奖励算出部通过将所述修正外力的预测值作为所述奖励的减少因素的计算来算出所述奖励。
8、根据上述第一方式,也可以为在所述外力为抑制所述误差的缩小的外力即对抗外力的情况下,所述奖励算出部通过将所述对抗外力的预测值作为所述奖励的增加因素的计算来算出所述奖励。
9、根据上述第一方式,也可以为所述奖励算出部,在所述外力为抑制所述误差的扩大的修正外力的情况下,通过将所述修正外力的预测值作为所述奖励的减少因素的计算来算出所述奖励,在所述外力为抑制所述误差的缩小的外力即对抗外力的情况下,通过将所述对抗外力的预测值作为所述奖励的增加因素的计算来算出所述奖励。
10、根据上述第一方式,也可以为所述奖励算出部通过基于任务执行中的所述修正外力的预测值的所述奖励的减少量的变化幅度比基于所述误差的所述奖励的变化幅度小,且基于任务执行中的所述对抗外力的预测值的所述奖励的增加量的变化幅度比基于所述误差的所述奖励的变化幅度小的计算来算出所述奖励。
11、根据上述第一方式,也可以构成为所述外力模型包括:在所述外力为所述修正外力的情况下输出所述修正外力的预测值的修正外力模型、以及在所述外力为所述对抗外力的情况下输出所述对抗外力的预测值的对抗外力模型,所述外力模型更新部包括:修正外力模型更新部,更新所述修正外力模型,以使得在所述外力为所述修正外力的情况下,所述修正外力模型基于所述确定的行动指令算出的所述修正外力的预测值与所述外力的实际值的差异变小;以及对抗外力模型更新部,更新所述对抗外力模型,以使得在所述外力为所述对抗外力的情况下,所述对抗外力模型基于所述确定的行动指令算出的所述对抗外力的预测值与所述外力的实际值的差异变小。
12、根据上述第一方式,也可以为所述机器人模型包括具备所述修正外力模型以及所述对抗外力模型的整合外力模型,所述修正外力模型以及所述对抗外力模型为神经网络,所述对抗外力模型的一个或者多个中间层以及输出层中的至少一层通过渐进式神经网络的方法整合所述修正外力模型的对应的层的前段的层的输出,所述对抗外力模型输出外力的预测值以及该外力为修正外力还是对抗外力的识别信息,所述整合外力模型将所述对抗外力模型的输出作为自身的输出,所述奖励算出部,在所述识别信息表示为修正外力的情况下,通过将所述外力的预测值作为所述奖励的减少因素的计算来算出所述奖励,在所述识别信息表示为对抗外力的情况下,通过将所述外力的预测值作为所述奖励的增加因素的计算来算出所述奖励。
13、根据上述第一方式,也可以是还具备受理所述外力为所述修正外力还是所述对抗外力的指定的受理部,还具备学习控制部,所述学习控制部在所述指定为所述修正外力的情况下,使所述修正外力模型更新部的动作有效化,所述学习控制部在所述指定为所述对抗外力的情况下,使所述对抗外力模型更新部的动作有效化的构成。
14、根据上述第一方式,也可以构成为还具备学习控制部,所述学习控制部基于所述位置姿态的实际值以及所述外力的实际值判别所述外力为所述修正外力还是所述对抗外力,在所述判别的结果为所述修正外力的情况下,使所述修正外力模型更新部的动作有效化,在所述判别的结果为所述对抗外力的情况下,使所述对抗外力模型更新部的动作有效化。
15、公开的第二方式是机器人模型的机器学习方法,准备机器人模型,所述机器人模型包括基于某一时段的机器人的位置姿态的实际值以及能够提供给所述机器人的行动指令,算出下一时段的所述机器人的位置姿态的预测值的状态迁移模型以及算出对所述机器人施加的外力的预测值的外力模型,对于每个控制周期,获取所述位置姿态的实际值以及对所述机器人施加的外力的实际值,对于每个控制周期,生成所述行动指令的多个候补并提供给所述机器人模型,基于与所述行动指令的多个候补对应由所述状态迁移模型算出的多个所述位置姿态的预测值与应达到的位置姿态的目标值之间的多个误差以及与所述行动指令的多个候补对应由所述外力模型算出的多个所述外力的预测值,基于与所述行动指令的多个候补对应算出的多个奖励,确定使奖励最大化的行动指令,更新所述外力模型,以使得所述外力模型基于确定的所述行动指令算出的所述外力的预测值和与该外力的预测值对应的所述外力的实际值之间的差异变小。
16、根据上述第二方式,也可以为还更新所述状态迁移模型,以使得所述状态迁移模型基于确定的所述行动指令算出的所述位置姿态的预测值和与该位置姿态的预测值对应的所述位置姿态的实际值之间的误差变小。
17、根据上述第二方式,也可以为在所述外力为抑制所述误差的扩大的外力即修正外力的情况下,通过将所述修正外力的预测值作为所述奖励的减少因素的计算来算出所述奖励。
18、根据上述第二方式,也可以为在所述外力为抑制所述误差的缩小的外力即对抗外力的情况下,通过将所述对抗外力的预测值作为所述奖励的增加因素的计算来算出所述奖励。
19、根据上述第二方式,也可以为在所述外力为抑制所述误差的扩大的修正外力的情况下,通过将所述修正外力的预测值作为所述奖励的减少因素的计算来算出所述奖励,在所述外力为抑制所述误差的缩小的外力即对抗外力的情况下,通过将所述对抗外力的预测值作为所述奖励的增加因素的计算来算出所述奖励。
20、根据上述第二方式,也可以为所述外力模型包括:在所述外力为所述修正外力的情况下输出所述修正外力的预测值的修正外力模型、以及在所述外力为所述对抗外力的情况下输出所述对抗外力的预测值的对抗外力模型,更新所述修正外力模型,以使得在所述外力为所述修正外力的情况下,所述修正外力模型基于所述确定的行动指令算出的所述修正外力的预测值与所述外力的实际值的差异变小,更新所述对抗外力模型,以使得在所述外力为所述对抗外力的情况下,所述对抗外力模型基于所述确定的行动指令算出的所述对抗外力的预测值与所述外力的实际值的差异变小。
21、根据上述第二方式,也可以为在所述误差正在扩大的情况下,对所述机器人施加所述修正外力,在所述误差正在缩小的情况下,对所述机器人施加所述对抗外力。
22、公开的第三方式是机器人模型的机器学习程序,是用于进行机器学习包括基于某一时段的机器人的位置姿态的实际值以及能够提供给所述机器人的行动指令,算出下一时段的所述机器人的位置姿态的预测值的状态迁移模型以及算出对所述机器人施加的外力的预测值的外力模型的机器人模型的机器学习程序,使计算机进行以下各处理:对于每个控制周期,获取所述位置姿态的实际值以及对所述机器人施加的外力的实际值,对于每个控制周期,生成所述行动指令的多个候补并提供给所述机器人模型,基于与所述行动指令的多个候补对应由所述状态迁移模型算出的多个所述位置姿态的预测值与应达到的位置姿态的目标值之间的多个误差以及与所述行动指令的多个候补对应由所述外力模型算出的多个所述外力的预测值,基于与所述行动指令的多个候补对应算出的多个奖励,确定使奖励最大化的行动指令,更新所述外力模型,以使得所述外力模型基于确定的所述行动指令算出的所述外力的预测值和与该外力的预测值对应的所述外力的实际值之间的差异变小。
23、公开的第四方式是机器人控制装置,具备:模型执行部,所述模型执行部执行包括某一时段的机器人的位置姿态的实际值以及能够提供给所述机器人的行动指令,算出下一时段的所述机器人的位置姿态的预测值的状态迁移模型以及算出对所述机器人施加的外力的预测值的外力模型的机器人模型;获取部,获取所述机器人的位置姿态的实际值以及对所述机器人施加的外力的实际值;奖励算出部,基于由所述机器人模型算出的位置姿态的预测值与应达到的位置姿态的目标值之间的误差以及由所述机器人模型算出的外力的预测值算出奖励;以及行动确定部,对于每个控制周期,生成所述行动指令的多个候补并提供给所述机器人模型,基于所述奖励算出部对应于所述行动指令的多个候补分别算出的奖励确定使奖励最大化的行动指令。
24、公开的第五方式是机器人控制方法,准备机器人模型,所述机器人模型包括基于某一时段的机器人的位置姿态的实际值以及能够提供给所述机器人的行动指令,算出下一时段的所述机器人的位置姿态的预测值的状态迁移模型以及算出对所述机器人施加的外力的预测值的外力模型,对于每个控制周期,获取所述位置姿态的实际值以及对所述机器人施加的外力的实际值,对于每个控制周期,生成所述行动指令的多个候补并提供给所述机器人模型,基于与所述行动指令的多个候补对应由所述状态迁移模型算出的多个所述位置姿态的预测值与应达到的位置姿态的目标值之间的多个误差以及与所述行动指令的多个候补对应由所述外力模型算出的多个所述外力的预测值,基于与所述行动指令的多个候补对应算出的多个奖励,确定使奖励最大化的行动指令,基于确定的所述行动指令控制所述机器人。
25、公开的第六方式是机器人控制程序,是用于控制使用包括基于某一时段的机器人的位置姿态的实际值以及能够提供给所述机器人的行动指令,算出下一时段的所述机器人的位置姿态的预测值的状态迁移模型以及算出对所述机器人施加的外力的预测值的外力模型的机器人模型的所述机器人的程序,使计算机进行以下各处理;对于每个控制周期,获取所述位置姿态的实际值以及对所述机器人施加的外力的实际值,对于每个控制周期,生成所述行动指令的多个候补并提供给所述机器人模型,基于与所述行动指令的多个候补对应由所述状态迁移模型算出的多个所述位置姿态的预测值与应达到的位置姿态的目标值之间的多个误差以及与所述行动指令的多个候补对应由所述外力模型算出的多个所述外力的预测值,基于与所述行动指令的多个候补对应算出的多个奖励,确定使奖励最大化的行动指令,基于确定的所述行动指令控制所述机器人。
26、发明效果
27、根据公开的技术,在通过机器学习学习机器人模型时,可以有效学习。
- 还没有人留言评论。精彩留言会获得点赞!