用于智能语音识别和处理的系统、方法和装置与流程
相关申请
本申请为在2014年10月20日提交的美国专利申请序号62/066,154的延续,其公开内容通过引用整体并入。
本申请大体涉及电子通信,并且更具体地,涉及具有智能语音识别和处理的通信系统、方法和装置。
背景技术:
现代通信系统(例如,蜂窝电话)中的背景噪声、房间混响和信号失真破坏许多重要的语音提示(cue),从而产生贫乏的语音信号。然而,语音包含许多冗余的提示,正常听力的人可以使用这些冗余来补偿在日常生活中遇到的大多数嘈杂、混响或其他形式的失真语音的语音提示丢失。这不是偶然的事故。法规、公众压力和相关因素致使工作场所、公共场所、学校等的背景噪声减少,所以对于正常听力的人来说,大多数时间的语音交流是相对有效的。然而,听力损失的人必须处理两种形式的贫乏语音,由于受损的听觉系统中的信号的神经处理减少所导致的语音提示丢失以及在失真的语音中的语音提示的额外损失。尽管有听力损失的许多人能够使用冗余的语音提示来理解安静无失真的语音,以补偿由受损的听觉系统中的神经处理不足导致的语音提示的丢失,但是失真的语音信号实质上更难以理解。放大对于提高安静无失真语音的清晰度(intelligibility)是有用的,因为它增加了贫乏语音信号中许多有用的冗余提示的可听性。然而,如果放大的语音信号失真(例如,背景噪声随着语音信号被放大),则存在更少的剩余冗余语音提示用于补偿受损听觉系统中的神经处理不足和失真语音信号中的语音提示损失所导致的组合语音提示损失。具有听力损失的老年人在神经和认知过程中也具有年龄相关的缺陷,特别是在处理快速时间(temporal)变化方面。因此,这些老年人在理解日常生活中经常遇到的各种失真的语音时比年轻的正常听力成人有更大的困难。常规的放大在提高失真语音的清晰度方面几乎没有什么益处,特别是具有快速时间失真的语音。
自动语音识别领域近年来取得了长足的进步。机器语音识别现在是实际的现实,尽管还不如人类语音识别那样有效。然而,已经开发了使用自动语音识别技术的算法来提高贫乏语音的清晰度和质量。然而,在助听器中实现的信号处理算法仅处理声学信号。相比之下,自动语音识别算法使用语音信号中的所有信息,其可包括视光学、发音、语言和/或统计信息。能够理解贫乏语音的语音信号中的许多冗余由语音的声学和光学分量在面对面通信中传达,特别是在具有挑战性的聆听条件下。
技术实现要素:
公开了具有智能语音识别和处理的系统、方法和装置。在一个实施例中,系统、方法和装置可实现如本文所述的语音识别辅助(sra)。sra可以以提高听力损失的人,包括特别是具有听力损失的几乎总是也具有年龄相关的神经和认知处理缺陷的老年人的语音的清晰度和声音质量的方式来实施。
例如,常规助听器处理声学信号,而不考虑语音信号的发音、语言、语义或统计内容。然后,经过处理的声学信号仅使用听力传送给聆听者。因此,本发明的目的是提供可通过听觉、视觉以及在特殊情况下,诸如听力障碍的盲人通过触觉辅助使用sra触摸来利用到达聆听者的所有语音信息的系统、方法和装置。根据通信模式(例如,面对面对话、看电视、收听音频记录),sra以合适的格式将经处理的语音信号传送给聆听者。
本发明的另一目的是提供可支持改进的或智能的用于为声音放大候选者的大部分人(例如,老年人)进行语音识别的系统、方法和装置。除听力损失外,这些候选者可能遇到与神经方面的年龄相关的听觉处理缺陷和降低的认知处理。因此,sra被设计成以可提高听力损失的人,包括具有在神经和认知处理中与年龄相关的缺陷的老年人的语音的清晰度和声音质量的方式进行操作。
根据听力损失的性质和严重程度以及其他复杂变量,具有语音感知听力损失的人之间存在较大的个体差异。因此,在本发明的另一目的中,可实现sra,使得可对其进行训练,以识别对于每个个体用户未适当处理的语音信号的那些方面。然后,sra可为每个用户修改语音信号,以便提高其清晰度和/或声音质量。使用该训练范式,sra也可用于提高听力损失的人以及对于他们的年龄具有正常听力而聆听贫乏语音的人的语音清晰度和/或声音质量。贫乏的语音可为受到传输信号方法独有的失真所造成的背景噪声、房间混响或经由差的电话或因特网连接接收到的语音的结果。例如,现代语音通信系统中的新形式失真为蜂窝电话链路中的短期信号丢失。这些新的失真形式与日常语音通信(背景噪声、房间混响)中遇到的失真有很大不同,并因此可能需要非常不同的算法来提高语音清晰度和/或声音质量。sra有能力识别失真的性质,并且语音信号的哪些方面容易受到失真的影响。通过此方式,sra可针对每种类型的失真自动选择适当的信号处理算法。例如,在一个实施例中,由于sra在一段时间内被用户佩戴的结果,sra可识别常见的失真。sra识别由于失真而可能被用户丢失的语音提示,并且通过增强这些提示和/或不太可能受失真影响的其他冗余语音提示来选择补偿这些提示丢失的算法。这种形式的语音处理利用语音信号的物理、发音、语言和统计特性以及听力受损用户的听觉能力。sra非常适合以此方式处理语音,以提高每个用户通常遇到的失真的语音清晰度和/或声音质量。sra还具有识别和补偿未来可能引入的新形式失真的能力,并且该新形式失真随着时间的推移可能变得普遍,如通过蜂窝电话引入的类型的失真的情况。应注意,sra可被训练成依据哪些语音提示被丢失、哪些提示被减少或改变和可以被调整以及哪些剩余的冗余语音提示可以被加强来识别和分类每个失真以补偿被丢失、减少或改变的提示。一旦在这些术语中识别出失真,则确定失真的物理特性。以此方式,sra可被训练成以语音特征级别识别和分类未来可能引入的任何失真。
具体地,实现sra的系统、方法和装置与常规的助听器或具有信号增强特征的蜂窝电话在许多方面不同。sra可使用用于分析到达聆听者的物理信号的发音、语言和统计信息来操作。在另一方面,sra可操作来分析由人类面对面通信或使用基于因特网的音频-视频链路(诸如,skypetm)使用的由声学和光学信号组成的物理信号。最后,sra可操作以向聆听者传送语音,该语音不限于听觉,而且可以包括视觉和触觉。尽管未广泛使用,但触觉用于向深度耳聋和聋哑人传送语音提示已经有超过一个世纪了。
在特定实施例中,sra可以以非语音识别模式操作。在非语音识别模式中,sra可操作提供常规的助听器功能(例如,听音乐、警报信号和其他非语音声音)。此外,该操作模式可处理音频信号,并进一步分析声学信号。
在另一实施例中,sra可在语音识别模式下操作。在语音识别模式中,sra可操作以利用物理语音信号中的所有可用的语音信息以及关于如何产生语音以及口语的发音、语言和统计特性的信息,以便识别、处理语音并向聆听者传送该语音以提高语音清晰度和/或声音质量。
根据一个实施例,用于提高语音信号的清晰度的方法可包括:(1)至少一个处理器接收包括多个声音元素的输入语音信号;(2)至少一个处理器识别输入语音信号中的声音元素以提高其清晰度;(3)至少一个处理器通过修改和替换声音元素中的至少一者来处理该声音元素;以及(4)至少一个处理器输出包括经处理的声音元素的经处理的语音信号。
在一个实施例中,声音元素包括连续声音元素和非连续声音元素中的至少一者。
在一个实施例中,该处理增加了声音元素的持续时间。
在一个实施例中,该处理减少了声音元素的持续时间。
在一个实施例中,该方法可进一步包括:至少一个处理器识别输入语音信号中的第二声音元素以提高其清晰度;以及至少一个处理器通过修改和替换该声音元素中的至少一者来处理第二声音元素。第二声音元素可被修改或替换以补偿第一声音元素的处理。
在一个实施例中,声音元素可为语音声音。
在一个实施例中,第一声音元素可为短持续的,以及第二元素可为长持续的,并且所输出的经处理的语音信号包括经修改或替换的第一声音元素和第二声音元素。
在一个实施例中,该方法可进一步包括至少一个处理器通过修改输入语音信号中的停顿的持续时间来进一步处理输入语音信号,并且其中,所输出的经处理语音信号包括经修改的停顿。
在一个实施例中,该方法可进一步包括再现经处理的语音信号,并且降低所输出的经处理的语音被再现的速率。
根据另一实施例,用于提高语音信号的清晰度的方法可包括:(1)至少一个处理器接收输入语音信号;(2)至少一个处理器识别该输入语音信号的语音基频;(3)至少一个处理器通过分析语音信号来处理输入语音信号,以在有声语音中提取激励声道的共振的周期性音调脉冲,这些周期性音调脉冲的频率为有声基频;(4)至少一个处理器用激励具有更大强度的声道共振的较宽频率范围的周期性音调脉冲替换所提取的输入语音信号的周期性音调脉冲;以及(5)所述至少一个处理器输出经处理的语音信号。
在一个实施例中,替换周期性脉冲可为近似狄拉克脉冲。
在一个实施例中,该方法可进一步包括:至少一个处理器通过产生包括语音基频的补充信号来进一步处理输入语音信号;并且至少一个处理器通过听觉、触觉和视觉中的一者输出补充信号。
在一个实施例中,声音元素可为语音声音。
根据另一实施例,用于提高语音信号的清晰度的方法可包括:(1)至少一个处理器接收包括输入语音信号的音频信号;(2)至少一个处理器识别音频信号的声学环境;(3)至少一个处理器识别接收到的语音信号中的声音元素以提高其清晰度;(4)至少一个处理器基于声学环境确定用于处理该声音元素的信号处理策略;(5)至少一个处理器将所确定的信号处理策略应用于所识别的声音元素;和(6)至少一个处理器输出包括经处理的声音元素的经处理的语音信号。
在一个实施例中,该方法可进一步包括至少一个处理器确定声学环境降低语音信号的清晰度。
在一个实施例中,基于降低的语音清晰度聆听条件来确定用于处理语音信号的信号处理策略可包括至少一个计算机处理器基于来自用户的反馈改变信号处理策略。反馈可为来自用户的听得见的反馈。
在一个实施例中,所确定的信号处理策略降低音段间掩蔽(inter-segmentmasking)。
在一个实施例中,所确定的信号处理策略降低混响掩蔽。
在一个实施例中,所确定的信号处理策略降低背景噪声。
在一个实施例中,所确定的信号处理策略降低声学反馈。
在一个实施例中,声音元素可为语音声音。
在一个实施例中,输出经处理的语音信号可包括将经处理的语音信号的第一部分输出到输出端的第一通道,并将经处理的语音信号的第二部分输出到该输出端的第二通道。
根据另一实施例,通信装置可包括输入端,其接收包括多个声音元素的输入语音信号;至少一个处理器,其识别输入语音信号中的声音元素以提高其清晰度,并且通过修改和替换声音元素中的至少一者来处理该声音元素;以及输出端,其输出包括经处理的声音元素的经处理的语音信号。
在一个实施例中,输入端可包括麦克风。
在一个实施例中,输出端可包括扬声器。
在一个实施例中,输出端可包括触觉换能器。
在一个实施例中,输入端、至少一个处理器和输出端共同位于相同的装置内。
在一个实施例中,输出端和至少一个处理器是分开的。
在一个实施例中,声音元素可为语音声音。
根据另一实施例,通信装置可包括输入端,其接收音频信号,该音频信号包括输入语音信号;至少一个处理器,其执行以下操作:识别音频信号的声学环境;识别接收到的语音信号中的声音元素以提高其清晰度;基于声学环境确定用于处理声音元素的信号处理策略;并将所确定的信号处理策略应用于所识别的声音元素;以及输出端,其输出包括经处理的声音元素的经处理的语音信号。
在一个实施例中,至少一个处理器进一步确定声学环境降低语音信号的清晰度。
在一个实施例中,输入端可为麦克风。
在一个实施例中,输出端可为扬声器。
在一个实施例中,输出端可包括触觉换能器。
在一个实施例中,输入端、至少一个处理器和输出端共同位于相同的装置内。
在一个实施例中,输出端和至少一个处理器是分开的。
在一个实施例中,声音元素可为语音声音。
根据另一实施例,用于提高语音信号的清晰度的装置可包括接收输入音频信号的输入端;与第一用户耳朵相关联的第一输出端;与第二用户耳朵相关联的第二输出端;以及至少一个处理器,其在第一输出端和第二输出端之间切换输出该输入音频信号。
在一个实施例中,切换可为准周期性的。
根据另一实施例,用于提高语音信号的清晰度的装置可包括接收输入音频信号的输入端;与第一用户耳朵相关联的第一输出端;与第二用户耳朵相关联的第二输出端;至少一个处理器,其执行以下操作:将输入音频信号中的第一声音元素识别为强声音元素;将第一声音元素输出到第一输出端;接收输入音频信号中的第二声音元素;将第二声音元素输出到第二输出端;将输入音频信号中的第三声音元素识别为强声音元素;将第三声音元素输出到第二输出端;接收输入音频信号中的第四声音元素;并将第四声音元素输出到第一输出端。
附图说明
为了更全面地理解本发明、其目的和优点,现在结合附图参考以下描述,其中:
图1a描绘了根据一个实施例的用于智能语音识别和处理的系统;
图1b描绘了根据另一实施例的用于智能语音识别和处理的系统;
图1c描绘了根据另一实施例的用于智能语音识别和处理的系统;
图1d描绘了根据另一实施例的用于智能语音识别和处理的系统;
图1e描绘了根据另一实施例的用于智能语音识别和处理的系统;
图2描绘了根据一个实施例的用于智能语音识别和处理的装置的框图;
图3描绘了根据一个实施例的用于以音类级别(sound-classlevel)处理语音的方法;
图4描绘了根据另一实施例的用于以音类级别处理语音的方法;以及
图5描绘了根据一个实施例的用于以音段级别(segmentallevel)处理语音的方法;以及
图6描绘了根据一个实施例的用于以音段级别处理语音的方法。
具体实施方式
通过参考图1-图6可理解本发明的几个实施例及其优点。
这里使用的短语“接收到的语音信号”是指到达聆听者的物理信号。在面对面通信中,所接收到的语音信号具有声学和光学分量。在电话通信中,所接收到的语音信号通常仅由声学信号组成。对于具有听力损失的盲人的特殊情况,接收到的语音信号可包括来自振动装置的声音和触觉语音提示。
如本文所使用的,术语语音识别辅助或sra是指起到如本文所述作用的任何装置。sra可以以硬件、软件或其组合来实现。它也可为如在常规助听器中佩戴在耳朵上的独立装置,或者它可分成两个或更多个单元。例如,它可包括两个单元,一个小的低功率耳戴式单元,其尺寸与常规助听器相当,以及具有较大尺寸的袖珍式穿戴单元,其能够以相当高的功耗进行计算密集处理。耳戴式单元可具有一个或更多个具有前置放大器的麦克风,音频输出换能器和至可穿戴视频显示器的链路。触摸换能器也可用于向用户传送信号。两个单元通过硬连线电气链路或电磁链路相互通信,诸如拾音线圈链路、蓝牙链路或其他无线电链路。双耳版的sra具有两个耳戴式单元,每个耳朵上一个。在另一实施方案中,较大的单元可连接到提供链路至电话网络和/或因特网的另一装置(例如,智能电话,平板计算机等)或者是其一部分。这些链路允许经由普通老式电话(pots)、手机,具有附加信号处理能力的智能手机、基于互联网的通信装置(硬件和/或软件)、skypetm或其他通信装置以及由电子装置执行的其他软件应用等通信。sra的其他实施方案在本公开的范围内。
如本文所用,术语“听力损失”可包括对听觉系统的损伤以及神经和认知处理中与年龄有关的缺陷的影响。使用这种更广泛的听力损失定义,因为大多数听力损失的人是在神经和认知过程中具有年龄相关的缺陷的老年人。
如本文所公开,提高语音信号的清晰度可包括提高语音信号的清晰度和/或提高语音信号的声音质量。
语音由向更改所发送的声音的声音传输路径(声道)传送声能的能量源(肺)产生。声道通常具有取决于声道形状的共振频率。使用频谱分析测量的这些共振称为“共振峰”。
语音中有三种能量产生形式:i)周期性激励,其中,由声带振动引起的周期性空气突发激励声道的共振;ii)随机激励,其中,在声道中的空气流的随机扰动产生由声道的共振过滤的类似噪声的声音;以及iii)脉冲激励,其包括单次能量突发,诸如当声道的阻塞突然释放时所产生的脉冲激励。
语音的声音可根据声源分为几类。元音和双元音通过声带的周期性振动产生。这些声音与辅音相比较长。在元音的稳态部分,声道的共振(共振峰)不会显着改变。存在指示相邻辅音的共振峰过渡进入和离开元音。双元音起始于典型的元音的共振峰模式,然后该元音的共振峰模式合并到第二元音的共振峰模式中。元音和双元音可以根据它们的产生方式进行子分类,诸如分别由嘴的前部、中心和后部的声道收缩产生的前元音、央元音和后元音。
通过声道的随机激励产生的声音被称为清擦音(voicelessfricative),诸如sip中的/s/和ship中的/sh/。浊擦音(voicedfricative),诸如zip中的/z/,结合随机激励与声道的周期性激励。
鼻辅音(nasalconsonant),诸如nip中的/n/,通过声道的周期性激励产生,如同元音一样,但是声道的形状有很大不同。声道被阻塞,无论是在嘴唇处还是在嘴的后部,使得声学信号经由鼻腔离开声道。鼻辅音中声道的形状很复杂,从而产生共振和反共振的复杂混合。鼻辅音在低频中也有大部分的能量。
滑辅音(glideconsonant)以与元音相同的方式产生,但是具有短暂的快速共振峰过渡。滑音的发音以适合一个元音的形状的声道开始,并且以适合另一元音的形状之后不久结束。
闭塞辅音(stopconsonant),诸如pin中的/p/和bin中的/b/由声道中的收缩的突然释放产生。闭塞辅音可为浊音或清音;例如,/p/为通过唇部收缩产生的清塞音(voicelessstop),而其同源/b/为通过唇部的相同收缩产生的浊塞音(voicedstop)。清塞音的发音与浊塞音的发音的不同之处在于收缩释放之后的开始发声被延迟。闭塞辅音也包括称为停止突发的随机激励的突发。停止突发中的能量量变化很大。在某些情况下,诸如在单词结尾的停止,可完全省略停止突发。
上述声音类别可被分为两大类:持续音和非持续音。持续音(元音、双元音、摩擦音、鼻音和几个特殊的声音,诸如lip中的/l/以及rip中的/r/)为持续的声音,其持续时间可以被修改而不改变所说的含义。非持续音、滑音、闭塞音和塞擦音(闭塞音和摩擦音的组合)具有固定的持续时间,并且在没有改变含义的情况下不能在持续时间内更改,除了停止突发的轻微修改之外。
每个音类中的语音声音可被细分成音段或元素,这些音段或元素传达含义,有时被称为音素。不同的语言在每个音类中都有不同的音段/元素集合,但是有许多音段/元素是多种语言通用的。语音也有传达含义的超音段的分量,诸如词重音和信号问题、陈述、重点的语调。
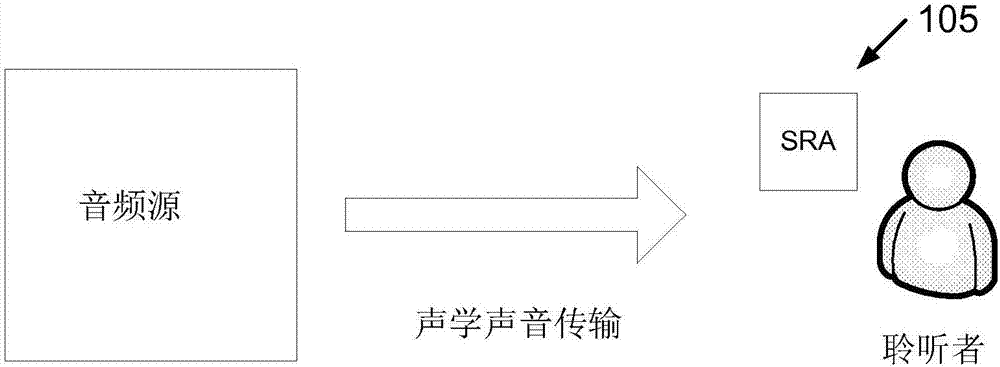
现在参考图1a,该图示出了可用于例如面对面通信中的sra的实施例。在此实施例中,由讲话者产生的语音可通过由sra105接收的声学和光学信号发送给sra的用户。到达sra105的声学信号可由用作至sra的声学输入的一个或更多个麦克风接收。到达sra105的光信号可由用作至sra105的光学输入端的一个或更多个可穿戴式相机接收。所接收到的声学和光学信号可由sra105处理以提高语音的清晰度和/或声音质量。
sra105的输出可包括声学和/或光学信号,并且在一些情况下可包括触觉信号。声学信号可通过助听器输出换能器、耳内扬声器、耳机或用于将声音传送到耳朵的其他声学换能器传送给用户。光信号可通过视频显示器、头戴式光学显示器、google眼镜或其他光学/视频显示器传送给用户。传送给用户的光信号补充了正常面对面通信中可用的讲话者脸部和身体动作的视觉提示。振动装置和其他触觉换能器也可用于向用户传送语音提示。sra也可在无需使用通常在面对面通信中可用的对视觉提示的光学或触觉补充的情况下使用。
图1b描绘了sra105的音频源可发送由sra105接收的声学语音信号的实施例。音频源可为收音机、唱片机、录音带播放器、cd播放器、辅助聆听装置、ip语音装置、音频会议系统、公共广播系统、流式无线电装置、双向无线电或平板电脑、台式机和笔记本计算机、工作站、电子读取装置等的音频输出。到达sra的声学信号可由用作至sra105的声学输入端的一个或更多个麦克风接收。所接收的声学信号可由sra处理以提高语音的清晰度和/或声音质量。
图1b中的sra105的输出由声学信号组成,其可通过助听器输出换能器、耳内扬声器、耳机或用于将声音传送到耳朵的其他声学换能器传送给用户。由sra105从声学信号中提取的语音提示也可通过视频显示器、头戴式光学显示器、google眼镜或其他光学/视频显示器传送的视觉激励来传送。类似地,由sra105从声学信号中提取的语音提示也可通过借助于振动装置和其它触觉换能器传送的触觉激励来传送。通过此装置传送的语音提示补充了通常在面对面通信中可用的视觉语音提示。
尽管可能认识到通过视觉或触觉装置传送的补充语音提示可有助于听力损失的人,但是未广泛认识到的是,通过此装置传送的补充视觉提示也可有助于正常听力的人在困难的聆听条件下,如在背景噪声中或在高度混响的环境中聆听,或者通过质量差的通信信道聆听失真的语音。
图1c描绘了sra105的音频-视频源可发送由sra105接收到的声学和光学信号的实施例。音频-视频源可为电视机、dvd播放器、录像带播放器、剧院中的电影、家庭影院、视频会议系统或平板计算机、台式机和笔记本电脑或工作站等的音频-视频输出。到达sra105的声学信号可由用作sra105的声输入端的一个或更多个麦克风来接收。到达sra105的光信号可由用作至sra105的光学输入端的一个或更多个相机接收。所接收到的声学和光学信号可由sra105处理以提高语音的清晰度和/或声音质量。
图1c中的sra105的输出可由声学、电学和/或光学信号组成。声学信号可通过助听器输出换能器、耳内扬声器、耳机或用于将声音传送到耳朵的其他声学换能器传送给用户。光信号可通过视频显示器、头戴式光学显示器、google眼镜或其他光学/视频显示器传送给用户。振动装置和其他触觉换能器也可用于向用户传送信号。sra也可在无需使用通常在观看音频-视频显示时可用的对视觉提示的光学或触觉补充的情况下使用。
图1d描绘了sra105的实施方案,其中,sra105从诸如普通老式电话(pots)、移动电话,具有附加信号处理能力的智能电话之类的通信装置、基于因特网的通信装置(硬件和/或软件)、skypetm或其他通信装置接收信号。该图示出了使用通信装置彼此进行通信的两个人。讲话者可对着第一通信装置110a讲话。语音信号可通过通信网络115发送到网络的接收端的第二通信装置110b。通信网络的示例包括普通老式电话系统(pots)、蜂窝网络、wifi网络、因特网、个人区域网络、卫星网络、近场通信网络、蓝牙网络及其任何组合。可根据需要和/或期望使用任何合适的通信网络。
到达图1d中的通信装置110b的信号可通过声学和光学信号和/或借助于硬连线的电气链路或电磁链路,诸如拾音线圈链路、蓝牙链路或其它无线电链路传送至sra105。由sra105接收到的信号可被处理以提高语音的清晰度和/或声音质量。
尽管sra105被描绘为单独的元件,但是sra105的硬件、软件和/或功能可被并入到第一通信装置110a和/或第二通信装置110b中。
图1d中的sra105的输出可由声学、电学和/或光学信号组成。声学信号可通过助听器输出换能器、耳内扬声器、耳机或用于将声音传送到耳朵的其他声换能器传送给用户。光信号可通过视频显示器、头戴式光学显示器、google眼镜和其他光学/视频显示器传送给用户。振动装置和其他触觉换能器也可用于向用户传送信号。sra105也可在无需使用通常在观看音频-视频显示时可用的对视觉提示的光学或触觉补充的情况下使用。
图1e描绘了除了或代替第二通信装置之外,第一通信装置110a可包括sra105的实施例。再者,尽管sra105被描绘为单独的元件,但是sra105的硬件、软件和/或功能可被并入到第一通信装置110a中。
在一个实施例中,sra105可被并入或提供给第一通信装置110a和第二通信装置110b两者。
图2描绘了sra的实施例的框图。接收器205可拾取到达sra的声学和光学信号。这些信号可临时存储在存储器210中。附加i/o装置215可被访问以用于可选的处理,诸如针对盲人用户的触觉输出。声学信号处理器220可与光学信号处理器225同步地处理声学信号。sra205、210、215、220、225、230的某些或全部部件可经由接口235通信地耦合。本地接口235可为,例如但不限于,一个或更多个总线或如本领域已知的其他有线或无线连接。经处理的声学和光学信号可经由输出装置230传送给用户。
在一个实施例中,sra200可以以软件、固件、硬件或其组合来实现。在一个实施例中,装置的一部分以软件实现为可执行程序,并且由特殊或通用计算机,诸如sra的主体内的微型计算机,或者借助于至外部计算机,诸如个人计算机、个人数据助理、智能电话、工作站、小型计算机、大型计算机等的硬连线线或无线电链路执行。
在另一实施例中,sra205的一个或更多个输入/输出(i/o)部件(205、215、230)可包括能够以声学、光学或触觉方式接收/传送语音信号的外围装置,诸如麦克风、照相机、触觉加速度计或其他输入传感器、助听器输出换能器、耳内扬声器、耳机或用于将声音传送到耳朵的其他声学换能器、视频显示器、头戴式光学显示器、google眼镜、计算机显示器或其他光学/视频显示器、用于盲人用户的振动装置或其他触觉换能器等。应认识到,输入/输出装置可包括可为sra200内部或与其分开的附加硬件(未示出)。附加硬件可使用标准有线(例如,通用串行总线)或标准无线连接,诸如拾音线圈链路、蓝牙链路或其他无线电链路连接至/自sra200,以便提供通信。可根据需要或期望使用用于将附加硬件通信地连接至sra200的任何合适的装置。
sra可被用作非语音识别模式以及语音识别模式中的常规助听器。在非语音识别模式下,助听器的操作允许在使用自动语音识别处理之前获得用户理解通过常规手段放大的语音的能力的基线数据。因此,sra可使用行之有效的拟合程序,诸如由dillon,h.在悉尼:boomerang出版社,纽约,斯图加特:thieme,(2010)第二版第9.2.2节第239至242页的《助听器》(“hearingaids”)中描述的由澳大利亚国家声学实验室(australiannationalacousticlaboratories)开发的nal程序,以与常规助听器相同的方式安装,该公开通过引用整体并入。然后可获得用户如何能够使用常规放大来更好理解语音的基线数据。标准化语音测试可用于此目的,诸如由nilsson,m.,soli,s.d.和sullivan,j.a.在《声学学会杂志》(jacoustsocam.),95,1085-99(1994)在“用于在安静和噪声中测量语音接收阈值的噪声测试的听力开发”(“developmentofthehearinginnoisetestforthemeasurementofspeechreceptionthresholdsinquietandinnoise”)中描述的噪声测试中的听力(hearinginnoisetest,hint),其公开内容通过引用整体并入。助听器有益效果的主观评估也可使用标准化的自我评估调查问卷,诸如由cox,r.m.和alexander,g.c.在《耳朵听力》(“earhear.”)16,176-86,(1995)在“助听器有益效果简要概况”(“theabbreviatedprofileofhearingaidbenefit”)中所述的助听器有益效果简要概况,其公开内容通过引用整体并入。此外,面向客户的改进量表(clientorientedscaleofimprovement,cosi)可被管理以确定用户最希望从sra获得的有益效果,由dillon,h.,james,a.和ginis,j.,在美国听觉学会杂志(“jamacadaudiol.”)8,27-4,(1997)在“面向客户的改进量表(cosi)及其与助听器提供的其他几项益处量度和满意度的关系”(“clientorientedscaleofimprovement(cosi)anditsrelationshiptoseveralothermeasuresofbenefitandsatisfactionprovidedbyhearingaids.”)中所述,该公开通过引用整体并入。其他测试和评估程序可用于确定具有和不具有语音识别处理的助听器的有益效果。语音识别处理和上述的基线数据的几个级别不仅在提供评估sra的基础上有用,而且在识别适用于每个sra用户的语音识别算法及其实施方案方面也有用。cosi被设计成识别每个人的最重要需求。与基于常规放大的每个人的能力的基线数据相结合的信息提供了用于确定语音识别处理水平和实现可能产生最大有益效果的适当算法的手段。可在sra中实现的各种语音识别处理级别在下面讨论。
音类的语音识别处理
根据实施例,sra可以以若干不同的级别操作。以音类级别处理语音通常需要最少量的处理来获得语音清晰度和/或声音质量的提高。图3描绘了根据一个实施例的用于以音类级别处理语音的方法。老年人难以理解快速语音,特别是儿童的快速语音。听觉敏感性的正常年龄相关损失是部分负责的,但更重要的因素是时间(temporal)处理中与正常年龄相关的缺陷与认知处理中年龄相关的缺陷相结合。在具有挑战性的听力条件(背景噪声、混响、失真的电话语音)下,正常听力的年轻人也将表现出减少的时间处理和与语音基频频率fo相关的较差的神经同步。在根据方法300的实施例中,sra减慢语音信号和/或包括停顿的语音信号的元素,以便补偿降低的时间处理速率和下降的神经同步。为了改善处理速度信号与原始语音信号的时间同步,sra可加速包括停顿的语音信号的某些元素,以便更接近地近似经处理的语音信号中的原始语音信号(其可包括非听觉分量)的整体节奏和步伐。
在步骤305中,sra可接收语音信号。在一个实施例中,由于语音信号的快速语音速率,该语音信号可能会经历降低的清晰度。
在步骤310中,sra可处理所接收到的语音信号,以便识别语音信号内的持续和非持续音类。诸如持续音的音类(元音、双元音、鼻音、摩擦音)可在持续时间内进行调整,而不影响含义,而非持续(滑音、闭塞音)对持续时间内的变化特别敏感。根据实施例,停顿可通过语音信号的中止(cessation)来识别。在步骤310中,持续音可通过相对较慢的共振峰过渡以及随时间推移的音调周期的持续时间内的小变化来识别。零交叉周期性的分析可用于跟踪fo的变化,并且可以以数字方式或使用模拟电子器件来实现。
根据另一实施例,在步骤315中,sra可操作以识别语音信号中的持续音以及停顿,然后增加它们的持续时间。因此,可表现出共振峰值和音调周期的缓慢变化的语音信号的部分可在持续时间内增加以提高清晰度。
在一个实施例中,语音速率的降低可以使用相对简单的信号处理方法来实现。识别和分析语音波形中的零交叉,以确定波形中零交叉为周期性的那些区域。两个周期性零交叉之间的时间差被定义为音调周期。执行分析以识别音调周期相对稳定的波形的区域。音调周期的连续对中的波形为相互关联的。如果互相关函数的峰值大于0.95,则该波形的该音段的音调周期被定义为稳定的。互相关也用作零交叉实际上是周期性的检查。如果语音波形包含一些噪声,则它也可提供更准确地音调周期估计。具有稳定音调周期的波形的区域允许音调周期从语音波形重复或切除,而不引入可听见的失真。重复音调周期会减慢语音速度。切除音调周期会加速语音。对语音信号的持续时长调整简单易于实现,并且可几乎没有困难地自动化。该方法也允许有效执行音调同步频谱分析。此外,可以使用该方法的变化来获得频谱的降低。如果语音声音的音调周期切除x%,并以更快的速率播放波形,以便不改变语音声音的持续时间,则该语音声音的频谱将降低x%。通过重复或切除音调周期来调整语速的示例性方法由osberger,m.和h.levitt,h.在mj.acoust.soc.am.(声学学会杂志),1316-1324,66(1979)在“时间错误对聋童语音可理解性的影响”(”theeffectsoftimingerrorsontheintelligibilityofdeafchildren’sspeech”)中公开。该方法被用来提高聋哑儿童讲话的清晰度。该文献的公开内容通过引用整体并入。
该方法也被用于提高会话语音的清晰度。
对话语音比明确阐述的语音更为快速。具有年龄相关的听觉处理缺陷的老年人难以理解快速发音,特别是由具有高基频频率的幼儿发出的快速语音。这些老年人中的许多人也具有年龄相关的高频听力损失,这增加了他们理解孙辈语音的难度,他们孙辈语音不仅语速很快,而且由于基频频率高所以高频内容也相当多。如果孩子在发音之后停顿,以允许较慢处理的语音能够赶上,则减慢语音将提高其清晰度。语音的频谱也可以降低,以便在聆听者有更好听力的频率区域置放更多的语音提示。然而,在语音声音不自然之前,关于语速可以降低多少或频率可能降低多少存在限制。
减慢语速是提高单向语音传播,即当听录音时的语音清晰度的简单实用的方法。如果语速的降低在音频和视频信道之间同步,它也可以用于观看视频录制。对于双向通信,如在对话中,谈话者有必要在短语和句子的末尾停顿,以便减慢所处理的语音以赶上讲话者的语音。这种讲话礼仪可以与彼此了解对方的人或在与听力丧失的人特别是听力丧失的老年人以及与年龄相关的听觉处理缺陷的人对话时,为理解停顿和慢速语音需求的人有效地工作。
在步骤315中,sra的替代实施例可采用增加持续时间的其他方法。例如,替代实施例可使用持续时间增加机制,诸如用音调周期异步地添加到波形,或者简单地减慢语音的再现速率。在这些实施例中,减慢语音可能引入可听见的失真。在步骤315中,对于音频-视频语音传输,可通过重复在重复帧期间与音调周期的重复同步的视频信号的帧来减慢语音信号。音频和视频信号的同步应在+/-10毫秒内,以避免声学和光学语音信号之间的异步感知。在清晰度和/或声音质量降低之前,人与人之间可以容忍多少可感知的异步存在很大的个体差异。
在一些实施例中,减慢语音信号可能引入延迟。根据通信模式,聆听者可以容忍多少延迟具有限制。例如,面对面对话可能对接收到语音信号的延迟更敏感,而远程会话(通过电话)不那么敏感。
可选地,如果在语音处理中经历延迟,则可由sra执行步骤320以减少延迟。在一个实施例中,可将处理延迟降低到面对面通信中的可接受水平的实施方案可包括缩短相对长的持续音、同时延长短持续音,使得声学信号与视觉感知的光信号同步。
在用于不存在光学语音信号的情况下处理声学语音信号的实施例中,为了提高清晰度,聆听者可容忍对通过增加语音信号的持续时间引入的相对长的延迟和/或语音信号的元素。因此,可根据需要和/或期望使用或调整任何合适的延迟减少实施方案。需要注意不要使用持续时间的极端变化,这可能会改变对未强调的语音模式的强调。可通过增加语音音调来补偿感知强调的减少。
不需要降低语音速率的实施例专注于在对话语音中略微改变持续时间的语音声音。在没有停止突发的情况下往往在单词最终位置产生闭塞辅音,并且许多辅音以强度低于明确发音的语音的方式产生。这种闭塞辅音的示例由pincheny,m.,durlach,n.和braida,l.在“jspeechhearres.”96-103,1985中在“说清楚很难听得懂的话i:清晰和对话性语音之间的清晰度差异”(“speakingclearlyforthehardofhearingⅰ:intelligibilitydifferencesbetweenclearandconversationalspeech”)以及由pincheny,m.a,durlach,n.i和braida,l.d.在“jspeechhearres.”29,434-46,1986中在“说清楚很难听得懂的话ii:清晰和对话性语音之间的声学特性”(“speakingclearlyforthehardofhearing.ⅱ:acousticcharacteristicsofclearandconversationalspeech”)中公开。这些文献的公开内容通过引用整体并入本文。
这些声音可使用专注于包含容易受到对话语音中的失真影响的声音的音类的突出声学特性和易受影响的声音频繁发生的声音的声学特性的两者的算法来识别并且然后被修改以增加它们的清晰度。这种类型的算法与用于自动语音识别的常规方法中的算法不同之处在于,搜索特定声音类型的子集而不是识别发音中的所有声音。另外,错误率(例如,不会发现会话语音中已被缩短的易受影响的声音)可以比用于实际系统要求极低的错误率的自动语音识别的常规方法的错误率高得多。
根据另一实施例,步骤320中使用的实施方案可以用于间歇或时变背景噪声。在步骤320中,sra可根据噪声强度不同地调整持续时间。研究表明,在噪声级别随着时间变化明显的情况下,聆听者专注于当语音-噪声比相对较好时的时间间隔内的语音以及不或不太能够专注于当语音-噪声比相对较差时的语音。在本实施例中,语音可在语音可听到的时间间隔期间被减慢,从而提高其清晰度,并且使用当语音被掩蔽为停顿时的时间间隔,从而允许减慢语音以能跟得上。
在用于不是面对面的电话或因特网通信的sra的另一实施例中,方法300的语音处理对于由于减慢语音所产生的延迟可能不那么敏感。在步骤320中,可能希望说话者停顿以允许延迟的语音跟得上。这些停顿可在短语或句子的末尾引入,以免歪曲语音的韵律。
在步骤325中,语音信号可在完成处理以提高清晰度之后被发送给用户。
在通过因特网的面对面通信(例如,使用skypetm、苹果的facetimetm、视频电话、视频会议设备等)的实施例中,sra可使用声学和光学输入和输出信号。因此,用于显示视频图像的googleglasstm、移动装置或类似装置可用于显示减速视频语音信号。此外,在用于减慢语音的步骤315中,sra所使用的算法也可被包含在用于远程面对面通信的计算机或可视电话中。
在另一实施例中,用于语音处理的额外的清晰度考虑由sra解决。例如,难以理解的部分记录可在sra以减慢语音模式操作的外部回放系统上重放。
sra也可用于提高混响公共广播系统的清晰度,诸如交通终端的公告的清晰度。在一个实施例中,sra可在非语音识别操作模式中最初放大公共广播系统的公告。公告也可由sra记录。如果公告不可理解,则可根据需要由sra回放,应用方法300的一些或全部元素以提高回放信号的清晰度。可根据需要记录、存储和回放几个公告。因此,改善的重要公共广播消息的清晰度可以通过sra实现。
对抗神经处理异步的实施例
图4描绘了根据一个实施例的用于处理以音类级别解决的语音的方法。针对下面所列各项在亚皮质级别对神经处理不足进行研究:i)噪声中的语音(正常听力和听力受损的人,但后者更多),ii)听力丧失的人的安静语音,iii)具有与年龄相称的正常听力的老年人和与年龄相称的年龄相关的听觉处理缺陷。在亚皮质级别减少处理的示例在由dgeffner和dswain编辑的圣地亚哥:plural出版社2012出版由levitt,h.,oden,c.,simon,h.,noack,c.和lotze,a.在“用于年龄相关的apd的基于计算机的训练方法:过去、现在和将来,听觉处理障碍”(“computer-basedtrainingmethodsforage-relatedapd:past,present,andfuture”)第二版第773-801页的第30章:“评估、管理和治疗(assessment,managementandtreatment):”中公开。该文献的公开内容通过引用整体并入。
这些研究表明,语音中的声道的周期性激励与传递声音信息的相关神经脉冲之间的同步性减弱。例如,一些声音比其他声音更易理解,更可理解的声音对声道有更强的周期性激励。
参考图4,sra可处理语音信号以模拟具有声道的强周期性激励的语音,该声道被设计成改善传送话音信息的神经冲动的同步。
在步骤405中,sra接收语音信号。对于在噪声、混响或其他干扰中聆听的听力丧失的人、具有与其年龄相称的正常听力的老年人或任何人(年轻人、老年人、正常听力的人、听力受损的人),可能会降低声道的周期性的激励和传送声音信息的相关联的神经脉冲之间的同步。
在步骤410中,sra可处理音频信号以模拟所接收到的语音信号和/或具有较强音调脉冲的语音信号的元素,该较强音调脉冲提供处理语音中的声道的强周期性激励。包含在语音信号中的任何合适的元素或元素的组合可用于必要和/或期望的处理。
在步骤410中,可加强、重新生成或模拟语音信号,以减少聆听者在神经处理中的缺陷。一种方法可放大包含语音基频(fo)的频率区域。这对于安静的语音可能很容易做到。然而,许多常见的环境噪声在fo的频率区域相对较强,并且有效地掩蔽了fo。对于这些常见的噪声,fo的谐波可在噪声不怎么强的较高频率检测到。在噪声水平较低的频率区域中,fo的谐波之间的间隔可提供用于确定fo的手段。
在另一实施例中,包含fo的补充信号可通过听觉、触觉或视觉或这些模态的一些组合来传送给聆听者,以便提高清晰度。这种补充信号的示例由hanin,l.,boothroyd,a.,hnath-chisolm,t.在《耳朵听力期刊》(“j.earhear.”)335-341(1988)中“作为句子发音的辅助的语音基频的触觉表示”(“tactilepresentationofvoicefundamentalfrequencyasanaidtothespeechreadingofsentences”)中公开。该文献的公开内容通过引用整体并入。在一个实施例中,听觉补充被简单地添加到噪声语音信号中。在另一实施例中,可使用陷波滤波器消除噪声fo,并且由从无噪声频率区域中的谐波fo估计的fo的无噪声值代替。在另一实施例中,可使用振动装置传送触觉补充。在助听器中传送触觉信号的方便方法是嵌入安装在sra的耳模中的小压电触觉换能器。另一实施例可使用通过googleglasstm传送的光学补充。在一个这种实施例中,闪烁图标可被叠加在讲话者的喉部区域的图像上。该图标可以以与fo成比例的速率闪烁,并且也可与fo的值同步地上下移动。有大量实验证据表明,在fo上以触觉或视觉方式传送的补充信息可提高听力损失的人或正常听力的人在噪声中聆听的语音清晰度。
在步骤410中,根据另一实施例,sra再生或模拟在步骤405中接收到的输入语音信号和/或语音信号元素,以便改善声道的周期性激励与传送声音信息的关联神经冲动之间的同步。一个实施例为用合成的音调脉冲来代替输入语音信号的音调脉冲,该合成音调脉冲近似狄拉克脉冲,从而再生语音信号,和/或用激励声道中更广泛范围的谐振频率的该新能量源代替语音信号的元素。
在本实施例中,可使用狄拉克脉冲的实际近似,其包括具有快速开始和偏移的非常短持续时间的脉冲。这种类型的脉冲可在宽的频率范围内具有平坦的频谱。理想化的狄拉克脉冲具有零持续时间以及在无限频率范围内具有平坦频谱的无限幅度。通过用具有近似狄拉克脉冲的脉冲的周期性激励所产生的基频fo在更宽的频率范围内具有比输入语音信号的更宽、更少离散脉冲所产生的fo更强的谐波。更重要的是,在听觉系统中的语音信号的神经处理中,由周期性类似狄拉克脉冲产生的高度离散的音调周期利用更大程度的同步来跟踪。
在另一实施例中,可使用线性预测编码来预测在激励脉冲之间的间隔中的语音信号的衰减。当声道被新的脉冲激励时,所观察到的语音信号将与不考虑新的激励的预测信号不同。所观察到的信号和预测信号之间的差异可用于识别激励声道的脉冲的形状。该技术可用于将声道的声音传播特性与脉动声源分开,并且用激励声道的不同声源来再生语音和/或语音信号的元素。
在步骤410中产生的模拟语音或其元素被设计成改善传送语音信息的神经冲动的同步。该技术也可提高贫乏语音信号的清晰度。
在步骤415中,语音信号可在提高清晰度的处理完成之后被发送给用户。经处理的语音信号可通过助听器输出换能器、耳内扬声器、耳机或用于将声音传送至耳朵的其他声换能器以声学方式传送。此外,补充的fo信息可通过振动器或其他触觉换能器以触觉传送。在一个实施方案中,触觉换能器可为安装在sra的耳模中的小型压电换能器,其比佩戴大的可见的触觉换能器在美观上更可接受。可使用作为周期性能量源的实际近似的狄拉克脉冲来传送触觉fo补充,以便改善与fo中的音调脉冲的神经同步。
音段级别的spa语音处理
图5描绘了根据一个实施例的用于以音段级别处理语音的方法。
在实施例中,语音声音的掩蔽可能降低由sra最初接收的清晰度和声音质量。因此,方法500中的sra可处理语音信号以解决掩蔽问题。
在方法500的一个实施例中,sra可被训练成识别接收到的语音信号中的对于助听器用户不可理解或不能充分理解的音段/元素。此后,sra可处理语音信号,以使这些音段/元素的清晰度最大化,从而提高语音的清晰度和/或声音质量。
在另一实施例中,在方法500期间,sra可处理语音信号,以便使整个语音信号的清晰度和/或声音质量最大化,而不仅仅是不可理解的音段/元素。根据该实施例,处理可不限于在音段级别的处理,而是可进一步包括超音段的处理。应注意,由sra接收到的语音信号可具有声学和光学分量,并且在高级别的背景噪声和/或混响的情况下,光学分量可能是特别重要的。
在步骤505中,sra可监测音频信号,以便识别可能对于语音清晰度具有挑战性的聆听条件。
在涉及sra的训练的实施例中,可记录到达用户耳朵的声学信号。用户可设置有方便的手持式或身体佩戴式单元,其允许用户在语音不可理解时向sra发信号。sra可将接收到的语音信号(声学和光学)临时存储在连续刷新的短期存储器中,使得当sra接收到指示语音不可理解的信号时,存储在该短期存储器中的过去x秒的语音信号被记录以供将来分析。x的值可为可调整的参数,其允许在用户发出语音不可理解的信号的时间间隔之前和期间,立即对接收到的语音信号(包括任何干扰)进行记录和后续分析。
在具有挑战性的聆听条件下,大部分接收到的声学语音信号可能不可理解。在步骤505中,在日常使用助听器的条件下记录的这些无法理解或无法充分理解的语音信号可最初存储在sra中,然后被传送到具有用于详细分析的信号处理能力的较大单元。
在步骤510中,sra可识别出每个单独的助听器用户在挑战性的日常聆听条件下无法理解或无法充分理解的音段/元素。
在步骤515中,sra可确定用于处理对于每个sra用户的日常聆听条件具有挑战性的语音信号的适当信号处理策略。在该实施例中,可为每个用户确定用于处理在挑战性日常聆听条件中接收或受挑战性的日常收听条件影响的音频信号的最有效的信号处理策略。在一个实施例中,sra可改变其放大特性(增益、频率响应、振幅压缩、频移)以提高对贫乏语音的识别。可使用诸如发音指数、语音传播指数的人类语音识别模型和其他模型来确定接收被频率滤波、背景噪声、混响和日常使用助听器常常遇到的其他失真歪曲的语音信号的具有听力损失的人的放大特性。由humes,l.e.,dirks,d.d.,bell,t.s.,ahlstbom,c.和kincaid,g.e.在“j.speech,lang.hear.res.”29,447-462(1986)中在“发音指数和语音传播指数对正常听力和听力障碍聆听者语音识别的应用”(“applicationofthearticulationindexandthespeechtransmissionindextotherecognitionofspeechbynormal-hearingandhearing-impairedlisteners”)中公开,该公开内容通过引用整体并入本文。
在另一实施例中,贫乏的语音可被可理解的、未失真的和无噪声的再生或合成语音替代。再生或合成的语音可用于替代严重失真的贫乏语音信号的音段,或者包括单词和短语的贫乏语音的较大音段。将再生/重新合成的语音音段与未处理的语音合并可能需要一些额外的处理,以使过渡声音尽可能自然。
在被设计成用于与sra的用户频繁通信的人(例如,配偶)一起使用的实施例中,在sra的存储器中存储可以再现该人的语音的语音合成器。语音合成器的参数可被精细调整,以便考虑用户听力损失的性质和严重性来最大化合成语音的清晰度和声音质量。如果包括接收到的来自该人的声音语音信号的单词和短语的音段或更大音段严重失真或缺失,但是光学语音信号在没有失真的情况下接收到,则sra可主要使用光学语音提示来准确地识别语音,从而允许在没有失真的情况下清晰地合成严重失真或缺失的语音音段。如果在没有失真的情况下接收到声学语音信号并且光学语音信号丢失或严重失真,则该实施例的变型可使用光学语音合成。光学语音合成的方法的示例在“促进康复技术协会的国际会议”(proc.int.conf.assoc.)232-233(1988)在“通过级联处理的视频语音合成”(“visualspeechsynthesisbyconcatenation”)中公开,其公开内容通过引用整体并入本文。
在步骤520中,sra可被训练成在挑战性的日常聆听条件下自动识别助听器用户无法理解或无法充分理解的音段/元素或其序列。在一个实施例中,频繁与sra的用户通信的人(例如,配偶)可在日常使用助听器中通常遇到的挑战性聆听条件下产生一组发音。发音的音标被提供给sra,然后sra将发音识别与正确的音标进行比较和优化。这可使用重复的发音进行若干次。在另一实施例中,sra可在噪声语音的正弦波模型上进行训练,以便提高噪声中语音识别的精度。改善语音噪声比和具有正常和听力受损聆听者获得的结果的正弦波建模示例在由j.beilin和g.r.jensen编辑的哥本哈根:stougardjensen(1993)第十五届danavox研讨会第333-358页由levitt,h.,bakke,m.,kates,j.,neuman,a.c.和m.在先进的信号处理助听器(recentdevelopmentsinhearinginstrumenttechnology)中公开的“听力仪器技术的最新进展”(“advancedsignalprocessinghearingaids”),其公开内容通过引用整体并入本文。由于人耳的频谱和时间分辨率有限,尽管使用正弦波模型改善人类聆听者的语音识别已经产生了很小的改进,但sra的信号处理能力不受这些限制。训练sra的其他方法可根据需要或期望来实现。
然后,sra可应用先前在步骤515中确定的用于提高识别的语音音段的清晰度和/或声音质量的信号处理策略。
在一个实施例中,sra可具有自我训练实施方案。根据自我训练能力,sra可起到识别在语音处理操作期间遇到的无法理解的音段的作用。随后,sra可用来自用户的反馈来动态地更新语音处理策略。在一个实施例中,sra的用户可设置有便利的手持式或身体穿戴式信号单元。在另一实施例中,用户可通过可听见的提示向装置提供指示,以提供此反馈。可根据需要和/或期望使用可由sra识别的任何声学信号。每当sra更新语音处理策略时,用户向sra发送指示该更新是否致使经处理的语音信号改善或递减的信号。除了这些简单的二进制决策之外,不需要来自用户的其他通信。对于来自用户的每个响应,sra使用自适应策略来修改其语音处理策略,以在给定的聆听条件下有效地收敛于用户的最佳语音处理策略。用于调整助听器的这种适应性策略的示例由neuman,a.c.,levitt,h.,mills,r.和schwander.t.在“j.acoust.soc.am.”82,1967-1976(1987)在“三种适应性助听器选择策略的评估”(“anevaluationofthreeadaptivehearingaidselectionstrategies”)中描述,其公开内容通过引用整体并入本文。
sra也可识别无法理解的音段/元素,并且同时执行其他语音识别和处理功能。在本实施例中,在主动处理输入语音信号的情况下,例如,在语音识别模式下操作时,sra可同时监测挑战性的聆听条件。这可以通过监测和识别用户对指示难以理解的单词/短语的发音来确定,诸如“可以重复一遍”或“你刚刚说什么”。
此外,sra可在语音处理期间识别在这些具有挑战性的收听条件中接收到的无法理解的音段/元素,并且自适应地调整用于处理这些音段/元素的策略。因此,在进行实施例的语音识别和处理之前,sra可能不一定执行单独的监测和/或训练,只是执行处理(例如,非语音识别模式)。根据实施例,sra可通过与任何语音处理步骤525-530并行地或有效地同时地执行步骤505-520来完成自训练。
在一个实施例中,sra可采用在步骤515中确定的用于不同类型掩蔽的不同处理策略。在日常语音通信中常常遇到的三种类型的掩蔽为音段间掩蔽、混响掩蔽和背景噪声掩蔽。下面描述针对这些类型的掩蔽中的每一种的实施例。
降低音段间掩蔽的实施例
在一个实施例中,sra可采用方法500来降低音段间掩蔽。
音段间掩蔽为安静语音的清晰度降低的主要原因。例如,由于掩蔽的时间扩展,强(例如,高强度)音段可掩蔽相邻的弱(例如,低强度)音段。助听器的语音信号的放大增加掩蔽的扩展。在时间和认知处理中,音段间掩蔽可能是具有年龄有关缺陷的老年人的重要问题。
当弱音段在强音段之后(正向掩蔽)时,掩蔽的时间扩展可能是相当大的。当弱音段先于强音段(反向掩蔽)时,存在较少的时间掩蔽。当弱音段相对于相邻的强音段增加强度时,可提高语音清晰度和/或声音质量。然而,进一步的考虑可以是强度增加太大可能会降低清晰度和/或声音质量。因此,对于弱音段的级别增加多少是有益的,在有听力损失的人之间可能会有大的个人差异。
如由kennedy,e.,levitt,h.,neuman,a.c.和weiss,m.在“j.acoust.soc.am.”103,1098-1114(1998)中在“使听力障碍聆听者的辅音识别最大化的辅音-元音强度比”(“consonant-vowelintensityratiosformaximizingconsonantrecognitionbyhearing-impairedlisteners”)所证明的,语音识别可以通过对每个聆听者的语音信号中的每个声音的强度进行个性化调整来改善。该文献的公开内容通过引用整体并入。高强度声音之后的低强度声音可能需要对于聆听者a可理解来说比聆听者b更多的放大。sra需要被训练成识别需要被处理为助听器的用户可理解的发音环境中的语音声音。训练过程的第一阶段是在日常语音通信的条件下,识别进行额外处理的候选者的语音声音。
在一个实施例中,在步骤510中,可识别弱音段被相邻强音段掩蔽的强弱音段对。在本实施例中,可在常规使用sra期间获得所接收的声学语音信号的场记录。在该实施例中,用户可设置有方便的手持式或身体穿戴式单元,其允许用户在语音不可理解时向sra发信号。在另一实施例中,sra可基于来自用户的评论(例如,“请重复”或“你说什么”)来识别语音什么时候可能不可理解。当sra接收到指示语音为无法理解的信号时,记录所接收到的信号(语音加在输入麦克风和照相机声学接收到的干扰)。这些记录可进行分析以识别用户在日常语音通信中常常遇到的语音声音需要被处理以提高清晰度和/或声音质量。
因此,sra可以用于为每个用户有效地识别主要负责降低安静语音的清晰度和/或声音质量的强弱音段对。
一旦sra已佩戴一段时间以识别需要处理以提高清晰度和/或声音质量的语音声音,则使用前一阶段获得的记录来对sra进行训练,以识别需要额外处理的语音声音。接下来的阶段是开发处理这些声音的方法,以提高被识别为需要额外处理的语音声音的清晰度。
在一个实施方案中,可实施由kennedy等人(1998)开发的方法,其中,低强度语音声音以系统级别被调整以最大化其用于每个用户的清晰度。增益量有可能取决于需要考虑到的声音的语音语境。可执行助听器用户的语音测试以获得该信息。如果需要进行实质测试,则可以分阶段完成,从最需要处理的声音开始,以提高清晰度。测试方法和实验结果的示例由kennedy,e.,levitt,h.,neuman,a.c.和weiss,m.在“j.acoust.soc.am.”103,1098-1114(1998)中在“使听力障碍聆听者辅音识别最大化的辅音-元音强度比”(“consonant-vowelintensityratiosformaximizingconsonantrecognitionbyhearing-impairedlisteners”)中描述,该文献的公开内容通过引用整体并入。
然后可编程sra,以便每当sra在日常通信中识别该声音时,实现针对给定声音的处理方法。
在另一实施例中,可不执行训练。
根据实施例,在步骤515期间,sra可为用户确定最合适的信号处理策略。sra可操作以采用行为测量来考虑信号处理策略的实施方案中的个体差异。因此,可分别为sra装置的每个用户确定用于最大化清晰度和/或声音质量的适当的信号处理策略。已经开发了高效的自适应搜索程序,并且可用于优化每个用户的信号处理策略的确定。示例由neuman,a.c.,levitt,h.,mills,r.和schwander.t.在“j.acoust.soc.am.”82,1967-1976(1987)在“三种适应性助听器选择策略的评估”(“anevaluationofthreeadaptivehearingaidselectionstrategies”)中公开。该文献的公开内容通过引用整体并入。
在步骤520中,sra可被训练成自动识别对于用户来说是无法理解的或无法充分理解的音段对,如先前在该方法的步骤510中所识别的音段对。进一步,sra可被训练成应用先前确定的个性化信号处理策略。
在步骤525中,根据其他实施例,sra可处理所接收到的语音信号。该处理可包括将接收到的语音信号在一组连续的频率滤波器中滤波,其带宽等于作为频率的函数而变化的临界听力频带。在该处理期间,sra也可考虑到临界频带内和临界频带之间的掩蔽效应来执行信号分析,以提高语音信号的清晰度。
在另一实施例中,为了提高清晰度和/或声音质量,在步骤525中可增加一对中不太强音段的持续时间。持续时间的变化可以代替强度的增加,也可以除了强度的增加之外,有持续时间的变化。可能需要和/或期望将更强音段的持续时间缩短相等的量,以便不改变语音的整体持续时间。可以根据需要和/或期望使用任何其他合适的实施方案或对音段持续时间的调整。
在步骤530中,在完成了改善的清晰度的处理之后,该信号可被输出给用户或另一装置。
在另一实施例中,sra可执行信号切换,诸如可以使用双耳助听器来实现。在本实施例中,输出语音信号可在两个耳朵之间快速切换。因此,紧跟在强音段之后,随后的不太强的音段可被切换到用户的另一耳朵。sra可操作以通过使用该技术消除强音段的时间的掩蔽扩展。此外,不太强的音段的强度和/或持续时间也可增加,以便使清晰度和/或声音质量最大化。根据实施例,通过在耳朵之间快速切换语音信号,sra输出可产生位于用户头部中心附近的单个声音图像的感知。另外,通过适当选择每个耳朵的上升和下降时间,切换瞬变可降低到较低的水平。hoffman,i.和levitt,h.在《通信失真杂志》(“j.communicationdisorders”)11,207-213(1978)中的“关于同时和交错掩蔽的注释”(“anoteonsimultaneousandinterleavedmasking”)中公开了两耳间的切换方法的示例。本文献的公开通过引用整体并入。
降低混响掩蔽的实施例
在另一实施例中,sra可降低混响掩蔽。
一般来讲,混响掩蔽包括同时和时间的掩蔽扩展。当前面音段的混响部分与随后的音段重叠时,发生同时掩蔽。当混响信号掩蔽一个或更多个跟随的音段时,发生时间向前掩蔽。
并不是所有的混响都会影响到清晰度或声音质量。低水平混响,如设计精美的礼堂,加强了所接收到的语音信号并提高了清晰度和声音质量。例如,在消声室内的语音听起来很弱和不自然。中等水平混响可能会降低小量清晰度,但也可能会大大降低声音质量。高水平混响大大降低了清晰度和声音质量。对于混响的感知以及可接受和不可接受的混响水平之间的界限,在助听器使用者之间存在很大的个体差异。
根据实施例,在步骤520中,sra可执行语音信号的耳间分析。例如,可分析到达两耳的语音信号,以便确定接收到的信号中的混响量作为频率的函数。allen等人(1977)公开了示例。为了执行该分析,将每个耳朵接收到的声学语音信号细分成一组连续的频带。对应于听力的临界频带的带宽用于此分析。然后对两个耳朵的相应频带中的信号执行运行的互相关。低的耳朵间相关性指示高度的混响。高的耳朵间相关性指示相对于混响的强信号。
在该实施例中,具有可忽略的耳朵间相关性的频带由明显高于语音信号的混响组成并被衰减。具有高的耳朵间相关性的频带包含强的语音信号并被放大。互相关函数中的峰值的时间偏移识别所接收到的语音信号的耳间时间延迟。该信息可用于确定所接收到的语音信号的方向。
在步骤525中,对于来自不同方向的语音和噪声的情况,信号处理的行之有效方法可用于放大来自语音方向的信号并且衰减来自噪声方向的信号,从而增加语音噪声比并伴随语音清晰度和声音质量的提高。peterson等人(1987)公开了包括定向麦克风的使用和使用griffiths-jim算法进行双信道信号处理的示例。
在步骤530中,在完成了用于提高清晰度的处理之后,该信号可被输出给用户。可选地,在步骤530中,可在处理期间将语音信号输出给聆听者。
减少背景噪声掩蔽的实施例
在另一实施例中,sra采用方法500来减少可能由背景噪声引起的掩蔽。
在实施例中,背景噪声的掩蔽可能特别地损害语音清晰度和声音质量。在诸如助听器的常规放大装置中,语音和背景噪声均被放大。因此,常规的放大装置在噪声中几乎没有提供益处,除非实现某种形式的信号处理以降低噪声水平。
在另一实施例中,sra可同时与环境噪声或其他形式的干扰一起接收语音信号。环境噪声通常具有与语音不同的频谱。环境噪声也可能具有不同于语音的时间结构。
因此,sra的实施例可使用自动语音识别的元素来提高被背景噪声掩蔽的语音的清晰度和/或声音质量。
在实施例中,sra可能经历强背景噪声的掩蔽。除了相同频率掩蔽之外,掩蔽可产生跨频率的掩蔽扩展。
因此,在步骤525中,sra可采用用于减少频率掩蔽扩展的信号处理策略。信号处理策略可包括将接收到的语音信号过滤成一组连续的频带。此外,处理策略可包括衰减具有完全掩蔽频带内的语音信号的强噪声的那些频带。这种信号处理方法广泛应用于现代助听器。
因此,在步骤525期间,除了上述降噪处理方法之外,sra还可采用自动语音识别。可以根据需要和/或期望使用用于处理语音信号和/或语音信号元素的任何合适的实施方式。该实施方式可包括在本文所述的实施例中或在实施例的任何组合中使用的语音信号处理。
可使用行之有效的自动语音识别算法来识别所接收到的语音信号中的音段/元素。例如,可分析低噪声频谱和时间区域中的可用声学语音提示。此外,可使用诸如可穿戴照相机的外围装置所提供的光学提示来补充由噪声声学语音信号传送的语音提示,从而获得更准确的语音自动识别。
在另一实施例中,声学语音信号的分析可包括超出正常听力范围的频率区域中的语音提示的识别。
在另一实施例中,sra可对所接收到的噪声语音信号执行频谱-时间分析,以识别背景噪声的强度小于语音的强度的那些时间和频谱区域。
在另一实施例中,sra可分析两个耳朵之间的振幅和时间差。具体地,在本实施例中,在每个耳朵接收到的在噪声强度刚好低于语音强度的那些频谱和时间区域,包括超出正常听力范围的频谱区域中的接收到的声学信号之间的差异可允许识别所接收到的声学信号的方向。行之有效的双耳信号处理技术可用于放大来自语音信号方向的信号并衰减来自其他方向的信号,从而增加语音噪声比。因此,sra可提高语音的清晰度和/或声音质量。
在实施例中,所接收到的语音信号的声学和光学分量均可由sra使用。例如,音段/元素可被编码以通过视觉和/或触觉传递给sra。视觉语音提示可经由显示语音源(例如,讲话者)的视觉显示器传送,该语音源具有可表示例如叠加在相关联的显示区域,诸如说话人的脸部上的音段/元素或类型的图标或文本字符。sra的外围装置可以能够接收/传送诸如google眼镜的视觉语音信号,并因此可在本实施例中使用。在另一实施例中,可以是sra的外围装置的显示系统可将虚拟图像投影在特定显示区域中(例如,叠加在讲话者的脸部上)。
此外,根据sra的实施例,可存在若干种方式对音段/元素进行编码。例如,视觉显示器可采用显示一个或更多个音段/元素类型的多个图标或文本字符(例如,一个图标可指示音段/元素为浊音还是清音,第二图标可指示音段是否是闭塞辅音,而第三图标可指示音段是否为摩擦音)。在该示例中继续,剩余的语音声音(元音、双元音、鼻音、滑音、边音)可通过视觉图像的颜色进行编码。浊塞音和清塞音在发音中是不可区分的。显示浊音-清音区别的简单图标可有助于发音。停止突发是闭塞辅音的重要元素,以及表示停止突发的强度的图标为是闭塞辅音中有关浊音-清音区分的有用提示。语音音段或语音音段的元素的视觉显示与声学语音信号同步也是重要的。
在通过触觉传送语音提示的实施例中,可使用一个或更多个振动装置。在一个这种实施例中,视觉显示器中使用的各种图标和/或文本字符中的每者可使用开关振动器,并且可使用具有可变振动速率的一个或更多个附加振动器来编码元音和类元音声音。可根据用户的发音能力使用其他视觉和触觉显示器。
在另一实施例中,可使用可为外围装置的显示器来补充正常语音提示。例如,可使用单个视觉图标或文本字符或单个振动器来传送语音音调。显示器可指示音段/元素为浊音还是清音。此外,显示器可传送语调和韵律提示。
在实施例中,sra可在语音信号的处理期间采用各种降噪方法。例如,可使用具有数字降噪的行之有效的声学放大方法来处理噪声声学语音信号。可使用行之有效的自动语音识别算法来识别所接收的语音信号中的音段/元素,以使得能够处理信号以在存在噪声的情况下增加音段/元素的清晰度。
在步骤530中,sra可通过单耳或双耳的听觉来输出具有降低噪声的经处理的语音。因此,sra可通过采用各种降噪机制来提高语音的清晰度和/或声音质量。在一个实施例中,sra可输出具有降低的相同频率掩蔽的语音以及减少的时间掩蔽和频率掩蔽扩展。
减少不稳定声学反馈的实施例
在另一实施例中,sra可采用方法500来降低声学反馈。
根据实施例,在sra音段/元素级别的处理可允许比现有方法更有效地消除不稳定的声学反馈。sra可解决当前的声学反馈减少方法的各种问题。当前技术中遇到的问题的示例可包括依赖于探测信号来识别反馈路径的特性,以及需要通过被放大的音频信号来掩蔽这种探测信号。为了实现探测信号掩蔽,可使用低振幅的探测信号;然而,低振幅探测信号可能产生所估计的反馈路径的差的分辨率,这进而可能限制可以实现的反馈减少的量。因此,反馈可在低于最佳放大水平的水平开始被用户感知。sra可使用与特定音段/元素匹配并替代特定音段/元素的探测信号;从而避免需要探测信号掩蔽,并因此允许探测信号相对较强,从而以更高的分辨率估计反馈路径,这继而可在用户感知到反馈开始之前允许更高的最佳放大水平。因此,sra可改善反馈减少。
在此实施例中,sra反馈减少可基于用户听力的确定。根据一个实施例,反馈减少可基于用户耳朵对随机波形的强度-频率谱的灵敏度的确定。此外,可确定用户的耳朵对随机波形的频谱敏感,但对波形本身不敏感。例如,具有相同强度-频率谱的两个随机噪声波形可能听起来相同。发音工作模式中的sra可依据发音声音类型来分析输入的语音信号。浊音持续音,诸如元音具有周期性的结构,其可通过声带的周期性振动来确定。清擦音辅音可通过声道中的湍流气流产生,从而产生具有由声道形状确定的强度-频率谱的随机波形。
在实施例中,sra可操作以识别清擦音,并用与随机波形感知无区别的已知波形替换摩擦音的随机波形。这可通过将若干正弦波与和随机波形的频谱匹配的频率和振幅相加来实现。模拟随机波形的频率和振幅可能是sra所知的。具有已知波形的类随机信号可用作用于估计反馈路径的探测。这种探测可使用行之有效的反馈减少方法。由于探测是被放大的语音信号的部分,所以它可提供具有比可能处于低电平并被放大的语音信号掩蔽的常规探测大得多的分辨率的反馈路径的估计。
在超音段级别的语音sra处理
根据实施例,sra可对所接收到的语音信号执行音段分析和/或在所接收到的语音的音段级别执行分析。
已经开发了用于在超音段级别识别语音的非常强大的自动语音识别方法。现代自动语音识别装置常常用于将语音转换为文本。在这些装置中所使用的方法也可用于产生语音的发音表示。
在实施例中,sra可操作以采用自动语音识别算法来识别所接收到的声学语音信号并产生语音的发音表示。此后,可使用行之有效的语音合成或语音再现方法来产生新版本的语音。与未处理的语音相比,合成或再现的语音可能会减慢,以便具有听力损失的人,包括在时间和认知处理中具有与年龄有关的缺陷的老年人更容易理解。
sra可采用用于减慢语音和/或语音元素以及用于处理语音使其更易于理解的各种信号处理方法。这些方法可包括在前述实施例中使用的信号处理方法的任何变化,诸如提高弱音段/元素的清晰度。
在实施例中,sra可被设计成用于聆听诸如讲座的语音记录,其中,减慢语音和/或语音元素的过程不会对例如聆听者造成任何不便或降低的清晰度。
在其他实施例中,sra可采用自动语音识别算法来识别所接收到的语音信号。所接收到的语音信号的声学和光学分量均可被包含在自动语音识别过程中。sra的输出可包括声学和光学语音信号。光学语音信号可由sra装置输出,以增加清晰度。另外,光学语音信号可由通信地耦合至sra的外围装置,诸如录像机/再现器、dvd播放器或类似装置输出。如果减慢语音,视频再现器的帧速率可能需要调整以便保持与声学语音信号的同步。在sra的前述实施例中描述的方法可用于保持同步的目的。
在其他实施例中,sra可使用自动语音识别算法来识别所接收到的声学语音信号并产生语音的发音表示。因此,可使用行之有效的语音合成或语音再现的方法来产生新版本的语音和/或语音元素。合成或再现的语音可包括在前述实施例中使用的用于提高清晰度的方法的任何变体或组合。例如,该实施例可进一步包括语音产生速率平均而言相同与未处理语音速率相同的约束。这种约束可使得sra能够在与其他人的实时、面对面的对话中方便地使用。
在又一实施例中,sra可操作以使用自动语音识别算法来识别所接收到的声学语音信号并产生语音的发音表示。此后,可修改所接收到的声学语音信号以提高其清晰度。在实施例中,sra可使用在前述实施例中采用的任何方法的变化,诸如提高弱音段/元素的清晰度。可使用所接收到的语音信号和/或语音信号的元素的修改而不是合成或再现该语音的新版本,以便说话者的声音是可识别的并且声音更自然。
根据其他实施例,sra可在噪声和混响环境中操作。在这些实施例中,sra可采用自动语音识别算法来识别所接收到的语音信号。所接收到的语音信号的声学和光学分量均可被包含在自动语音识别过程中。本申请中sra的输出可包括:1)合成或再现的安静声学语音信号,2)与所接收到的光学语音信号的视频记录同步回放的合成或再现的安静声学语音信号,3)所接收的声学语音信号的修改版本,其已经针对可与所接收到的光学语音信号的视频记录同步回放的降噪被处理,4)包括前述实施例中用以提高清晰度的信号处理方法的合成或再现的安静声音语音信号。这些信号处理方法可包括各种实施方案,诸如提高弱音段/元素的清晰度以及修改所接收的到光学语音信号,以提高视觉语音提示的清晰度,诸如增加元音期间的张口并增强牙齿和舌头的可见度。
根据另一实施例,sra可操作以提供单词和/或短语定位(spotting)。在频繁使用常用词或短语的情况下,该实施例可被证明是有效的。例如,可在与配偶、同事或可能是sra用户的语音的频率源的任何人和/或装置的对话(例如,定位)期间识别通用单词和/或短语。在实施例中,sra可被训练以识别频繁使用的单词和短语。训练可由sra执行,或者训练可由与sra分开的装置或多个装置(例如,智能电话、单独的电子装置、计算机(例如,平板计算机、笔记本电脑、台式计算机等),远离sra(例如,集中式服务区域))提供。训练可由用户执行,或者该装置可为自训练的。sra的这种训练可增加识别所接收到的语音信号的速度和准确度。此外,对于给定的说话者为共有的语音模式的知识可在识别该人的语音时提高sra装置的效率和准确性。此外,配偶、同事或亲密朋友可以一致地学习生成频繁使用的短语。例如,“现在是晚餐时间”可在sra中存储为或以其他方式指定为频繁使用的短语。在另一实施例中,sra可采用预定的单词和/或短语(例如,预设等)。使用预定的单词和/或短语可致使可选地执行上述特定的训练任务。根据实施例,一个或更多个单词和/或短语可存储在诸如sra的存储器的存储装置中。可根据需要和/或期望使用任何合适的存储器(即,远程或本地的)。这些短语的相对大的集合可被sra快速和准确地识别,并且可以以增加语音的识别和清晰度的方式来再现。
语音识别处理的重要方面在于可以在识别过程中使用范围广泛的提示。除了在自动语音识别系统中由常规的声学和光学提示所传达的实质信息之外,还存在正常听力范围之外的声学语音提示,或通过外围听觉系统的频率和时间分辨率限制对人类听觉进行掩蔽的声学提示。语音识别处理器可以检测和分析的语音提示数越多,对贫乏语音的语音识别过程的鲁棒性就越大。识别对话语音特别重要的是由发音、语言、语义提示和许多语音分量的统计特性所传达的信息。除了在声学和光学语音信号中的物理提示之外,现代自动语音识别装置还利用这些提示,尽管其不完美。除了非身体发音、语言、所使用的语言的语义和统计学和统计学属性之外,将包括以下所有的语音提示考虑在内的实施例使用语音识别的隐马尔可夫模型(hiddenmarkovmodel)来处理所有这些提示:在正常听力范围之外的声学提示,由于外围听觉系统的限制而没有被审核处理的声音提示,超出正常视觉范围的光学提示(诸如,在闭塞辅音期间肉眼看不到的嘴唇和脸颊的振动),鼻辅音中的振动提示以及聋哑人的泰多码(tadoma)通信方法中使用的其他触觉提示。然后将该语音识别装置的输出馈送到再现语音的语音合成器中。对于诸如可由背景噪声、混响和由电子和无线电通信系统引入的失真导致的贫乏的声学、光学和触觉语音输入的情况,语音识别处理器使用冗余提示来补偿输入语音信号中丢失或失真的语音提示。然后,再生的语音信号通过声学、光学和触觉手段传送给人或另一机器。
图6描绘了根据一个实施例的用于以音段级别处理语音的方法。图6的实施例与图5的不同之处在于,图6没有描绘可选步骤525,训练步骤505、510、515、525和530基本上类似于上述实施例中描述的那些步骤。
以下美国专利申请通过引用整体并入:在2014年12月10日提交的美国临时专利申请序列号61/938,072;在2014年4月17日提交的美国临时专利申请序列号61/981,010;在2015年2月9日提交的美国专利申请序列号14/617,527;以及在2015年4月17日提交的美国专利申请序列号14/689,396。
在下文中,将描述本发明的系统、装置和方法的实施方案的一般方面。
例如,本发明的系统或本发明的系统的部分可采用“处理部件”的形式,诸如通用计算机。如本文所使用的,术语“处理部件”应被理解为包括使用至少一个存储器的至少一个处理器。至少一个存储器存储一组指令。指令可永久地或暂时地存储在处理机的存储器或多个存储器中。处理器执行存储在存储器或多个存储器中的指令以便处理数据。该组指令可包括执行一个特定任务或多个任务,诸如上述那些任务的各种指令。用于执行特定任务的这样一组指令可被表征为程序、软件程序或简单地为软件。
如上所述,处理机执行存储在存储器或多个存储器中的指令用于处理数据。例如,数据的这种处理可响应于处理机的一个用户或多个用户的命令、响应于先前处理、响应于另一处理机和/或任何其他输入的请求。
如上所述,用于实现本发明的处理机可为通用计算机。然而,上述处理机也可利用各种各样的其他技术中的任何技术,包括专用计算机,包括例如微型计算机、迷你计算机或大型机的计算机系统,编程的微处理器,微控制器,外围集成电路元件,csic(客户专用集成电路)或asic(专用集成电路),精简指令集计算机(risc)或其他集成电路,逻辑电路,数字信号处理器,诸如fpga、pld、pla或pal的可编程逻辑器件,或能够实现本发明的方法的步骤的任何其他器件或器件的布置。这些处理机中的任何一个或全部可在各种装置,诸如移动电话/装置、陆线电话、助听器、个人放大装置、辅助聆听装置、视频和音频会议系统、ip语音装置、流式无线电装置、双向收音机、平板电脑、台式机和笔记本电脑、工作站、电子阅读装置等中实现。
用于实现本发明的处理机可利用合适的操作系统。因此,本发明的实施例可包括运行ios操作系统、osx操作系统、android操作系统、microsoftwindowstm10操作系统、microsoftwindowstm8操作系统、microsoftwindowstm7操作系统、microsoftwindowstmvistatm操作系统、microsoftwindowstmxptm操作系统、microsoftwindowstmnttm操作系统、windowstm2000操作系统、unix操作系统、linux操作系统、xenix操作系统、ibmaixtm操作系统、hewlett-packarduxtm操作系统、novellnetwaretm操作系统、sunmicrosystemssolaristm操作系统、os/2tm操作系统、beostm操作系统、macintosh操作系统、apache操作系统、opensteptm操作系统或其他操作系统或平台的处理机。
应理解,为了实施如上所述的本发明的方法,处理机的处理器和/或存储器不必在物理上位于相同的物理或地理位置。也就是说,处理机所使用的每个处理器和存储器可位于地理上不同的位置并且被连接以便以任何合适的方式进行通信。此外,应理解,处理器和/或存储器中的每者可由设备的不同物理件组成。因此,处理器不必是在一个位置的一个单件设备,并且该存储器不必是在另一位置的另一单件设备。也就是说,预期处理器可为在两个不同物理位置的两件设备。两件不同的设备可以任何合适的方式连接。另外,存储器可包括在两个或更多个物理位置中的两个或更多个存储器部分。
为了进一步说明,如上所述的处理由各种部件和各种存储器执行。然而,应理解,根据本发明进一步的实施例,由上述两个不同部件执行的处理可由单个部件执行。此外,如上所述由一个不同部件执行的处理可由两个不同的部件执行。以类似的方式,根据本发明的进一步的实施例,由两个不同的存储器部分执行的存储器存储可由单个存储器部分来执行。此外,如上所述由一个不同的存储器部分执行的存储器存储可由两个存储器部分执行。
此外,可使用各种技术来提供各种处理器和/或存储器之间的通信,并且允许本发明的处理器和/或存储器与任何其他实体通信;即,以便例如获得进一步的指令或访问和使用远程存储器存储。例如,用于提供这种通信的这种技术可包括网络、因特网、内联网、外联网、lan、以太网、经由蜂窝塔或卫星的无线通信或提供通信的任何客户端服务器系统。例如,这种通信技术可使用任何合适的协议,诸如tcp/ip、udp或osi。
如上所述,在本发明的处理中可使用一组指令。该组指令可以是程序或软件的形式。例如,该软件可采用系统软件或应用软件的形式。该软件也可以是单独程序的集合、更大程序中的程序模块或程序模块的一部分的形式。所使用的软件也可包括面向对象编程形式的模块化编程。该软件告诉处理机如何处理正在处理的数据。
此外,应理解,在本发明的实施方案和操作中使用的指令或指令集可采用适当的形式,使得处理机可读取指令。例如,形成程序的指令可以是合适的编程语言的形式,其被转换为机器语音或目标代码,以允许处理器或多个处理器读取指令。也就是说,使用编译器、汇编器或解译器将特定编程语言中的编程代码或源代码的书写行转换为机器语言。机器语言为专用于特定类型的处理机,即例如专用于特定类型的计算机的二进制编码的机器指令。计算机理解机器语言。
可根据本发明的各种实施例使用任何合适的编程语言。作为说明性地,例如所使用的编程语言可包括汇编语言、ada、apl、basic、c、c++、cobol、dbase、forth、fortran、java、modula-2、pascal、prolog、rexx、visualbasic和/或javascript。此外,结合本发明的系统和方法的操作,不需要使用单一类型的指令或单一编程语音。相反,可按需要和/或期望使用任何数量的不同的编程语言。
此外,在本发明的实施中使用的指令和/或数据可根据期望利用任何压缩或加密技术或算法。加密模块可用于加密数据。此外,文件或其他数据可使用例如适当的解密模块来解密。
如上所述,本发明可说明性地以例如具有至少一个存储器的包括计算机或计算机系统的处理机的形式实施。应理解,根据需要,可将多个指令集,即例如使计算机操作系统执行上述操作的软件包含在各种媒体或介质中的任何媒体或介质上。此外,由该组指令处理的数据也可包含在各种媒体或介质中的任何媒体或介质上。也就是说,例如,用于保存本发明中使用的指令集和/或数据的特定介质,即处理机中的存储器可采用各种物理形式或传输中的任何物理形式或传输。作为说明性地,介质可采用纸(paper)、透明纸(papertransparency)、光盘、dvd、集成电路、硬盘、软盘、光盘、磁带、ram、rom、prom、eprom、电线、电缆、光纤、通信信道、卫星传输、存储卡、sim卡或其他远程传输的形式,以及可被本发明的处理器读取的任何其他介质或数据源。
此外,实现本发明的处理机中使用的存储器或多个存储器可采用各种形式中的任何形式,以允许存储器按需要保存指令、数据或其他信息。因此,存储器可采用数据库的形式来保存数据。例如,数据库可使用诸如平面文件布置或关系数据库布置的任何所需的文件布置。
在本发明的系统和方法中,可使用各种“用户界面”来允许用户与用于实现本发明的处理机或机器交接。如本文所使用的,用户界面包括由允许用户与处理机交互的处理机使用的任何硬件、软件或硬件和软件的组合。例如,用户界面可采用对话屏幕的形式。用户界面也可包括鼠标、触摸屏、键盘、小键盘、语音读取器、语音识别器、对话屏幕、菜单框、列表、复选框、切换开关、按钮或允许用户接收关于处理机在处理一组指令和/或向处理机提供信息时的操作的信息的任何其他装置。因此,用户界面为提供用户与处理机之间的通信的任何装置。用户通过用户界面向处理机提供的信息可以是例如命令、数据选择或一些其他输入的形式。
如上所述,处理机使用用户界面来执行一组指令,使得处理机处理用户的数据。用户界面通常由处理机用于与用户交互以传达信息或从用户接收信息。然而,应理解,根据本发明的系统和方法的一些实施例,人类用户实际上不需要与本发明的处理机所使用的用户界面交互。相反,还应想到,本发明的用户界面可与另一处理机而不是人类用户交互,即传送和接收信息。因此,其他处理机可被表征为用户。此外,还应想到,在本发明的系统和方法中使用的用户界面可与另一处理机或多个处理机部分地相互作用,同时还与人类用户部分地相互作用。
本领域的技术人员应容易理解,本发明易于广泛使用和应用。在不脱离本发明的实质或范围的情况下,除本文所述以外的本发明的许多实施例和改型以及许多变化、修改和等同布置应在本发明及其前述描述的合理建议下是明显的。
因此,尽管在此相对于其实施例详细描述了本发明,但是应理解,本发明仅是本发明的说明和示例描述的,并且是为了提供本发明的发明可实施性。因此,前述发明并不旨在解释或限制本发明或以其他方式排除任何其他类实施例、改型、变化、修改或等同布置。
- 还没有人留言评论。精彩留言会获得点赞!