语音对话装置、语音对话方法、语音对话程序以及机器人与流程
技术特征:
1.一种装置,是与多个用户进行语音对话的装置,具备:
传感器,其取得所述装置周边的图像数据;
麦克风,其取得所述装置周边的声音;
存储器,其存储有与所述多个用户对应的多个图像数据,所述多个用户包括大人和幼儿;
推定部,其基于所述取得的图像数据和所述存储的多个图像数据,推定所述取得的图像数据所包含的人物,输出表示所述推定出的人物的用户信息;
语音识别部,其从所述取得的声音中提取语音,提取与所述语音对应的文本数据和所述语音的特征量,将所述文本数据与所述特征量关联并记录于第1数据库;
第1判定部,其基于所述用户信息和所述第1数据库,判定所述大人与所述幼儿是否正在交谈,在所述推定出的人物是所述大人和所述幼儿、并且所述特征量包括互不相同的多个特征量的情况下,判定为所述大人与所述幼儿正在交谈;
第2判定部,其在判定为所述大人与所述幼儿正在交谈的情况下,基于所述第1数据库,判定是否需要向所述大人和所述幼儿重新提供话题,在所述文本数据包含有第1关键字的情况下,判定为需要向所述大人和所述幼儿重新提供话题;
提取部,其在判定为需要提供所述话题的情况下,基于所述第1数据库和第2数据库,提取所述话题的候选,所述第2数据库存储表示所述幼儿在第1预定期间活动了的项目的活动项目,所述话题的候选与所述活动项目对应,并且与记录于所述第1数据库的所述文本数据所包含的活动项目不对应;
选择部,其从所述话题的候选中选择向所述大人和所述幼儿提供的一个话题;
生成部,其生成包括所述一个话题的语音数据;以及
扬声器,其输出所述生成的语音数据。
2.根据权利要求1所述的装置,
所述第2数据库还存储:表示与所述活动项目对应的运动量的运动量信息;表示与所述活动项目对应的音量的音量信息;和表示与所述活动项目对应的日期的日期信息,
所述提取部基于所述第2数据库,确定最新的活动项目,提取与所述最新的活动项目和所述文本数据所包含的活动项目不同的第2活动项目来作为所述话题的候选,
所述选择部基于与所述最新的活动项目对应的第1运动量、与所述最新的活动项目对应的第1音量、与所述活动项目中的第2活动项目对应的第2运动量、和与所述第2活动项目对应的第2音量,从所述第2活动项目中选择第3活动项目作为所述一个话题。
3.根据权利要求2所述的装置,
所述选择部将所述第2运动量相对于所述第1运动量的相对运动量的平方、与所述第2音量相对于所述第1音量的相对音量的平方之和成为最大的第2活动项目选择作为所述第3活动项目。
4.根据权利要求2所述的装置,
所述提取部提取与所述最新的活动项目和所述文本数据所包含的活动项目不同、并且在第2预定期间记录的第2活动项目来作为所述话题的候选。
5.根据权利要求2所述的装置,
所述运动量信息是对所述运动量乘以第1系数而得到的值,
所述音量信息是对所述音量乘以第2系数而得到的值。
6.根据权利要求2所述的装置,
所述生成部,基于所述第2数据库,在与所述第3活动项目对应的第3运动量大于等于第1阈值的情况下,生成包括第2关键字的所述语音数据,基于所述第2数据库,在与所述第3活动项目对应的第3运动量小于第1阈值的情况下,生成包括第3关键字的所述语音数据。
7.根据权利要求6所述的装置,
所述第2关键字以及所述第3关键字包括表示投入所述第3活动项目的所述幼儿的活跃度的修饰词,
所述第2关键字所示的意思是与所述第3关键字所示的意思相反的意思。
8.根据权利要求2所述的装置,
所述生成部,基于所述第2数据库,在与所述第3活动项目对应的第3音量大于等于第1阈值的情况下,生成包括第2关键字的所述语音数据,基于所述第2数据库,在与所述第3活动项目对应的第3音量小于所述第1阈值的情况下,生成包括第3关键字的所述语音数据。
9.根据权利要求8所述的装置,
所述第2关键字以及所述第3关键字包括表示投入所述第3活动项目的所述幼儿的活跃度的修饰词,
所述第2关键字所示的意思是与所述第3关键字所示的意思相反的意思。
10.根据权利要求1所述的装置,
所述特征量包括发出所述语音的说话者的声纹。
11.根据权利要求1所述的装置,
所述第1关键字包括表示话题的单词。
12.一种机器人,具备:
权利要求1所述的装置;
壳体,其内置所述装置;以及
移动机构,其使所述壳体移动。
13.一种方法,是与多个用户进行语音对话的装置中的方法,包括:
取得所述装置周边的图像数据;
取得所述装置周边的声音;
基于所述取得的图像数据、和存储与所述多个用户对应的多个图像数据的存储器所存储的多个图像数据,推定所述取得的图像数据所包含的人物,输出表示所述推定出的人物的用户信息,所述多个用户包括大人和幼儿;
从所述取得的声音中提取语音,提取与所述语音对应的文本数据和所述语音的特征量,将所述文本数据与所述特征量关联并记录于第1数据库;
基于所述用户信息和所述第1数据库,判定所述大人与所述幼儿是否正在交谈,在所述推定出的人物是所述大人和所述幼儿、并且所述特征量包括互不相同的多个特征量的情况下,判定为所述大人与所述幼儿正在交谈;
在判定为所述大人与所述幼儿正在交谈的情况下,基于所述第1数据库,判定是否需要向所述大人和所述幼儿重新提供话题,在所述文本数据包含有第1关键字的情况下,判定为需要向所述大人和所述幼儿重新提供话题;
在判定为需要提供所述话题的情况下,基于所述第1数据库和第2数据库,提取所述话题的候选,所述第2数据库存储表示所述幼儿在第1预定期间活动了的项目的活动项目,所述话题的候选与所述活动项目对应,并且与记录于所述第1数据库的所述文本数据所包含的活动项目不对应;
从所述话题的候选中选择向所述大人和所述幼儿提供的一个话题;
生成包括所述一个话题的语音数据;以及
输出所述生成的语音数据。
14.一种程序,是用于与多个用户进行语音对话的程序,该程序使与所述多个用户进行语音对话的装置所具备的处理器作为如下各部而发挥功能:
推定部,其基于通过传感器取得的所述装置周边的图像数据、和存储有与所述多个用户对应的多个图像数据的存储器所存储的多个图像数据,推定所述取得的图像数据所包含的人物,输出表示所述推定出的人物的用户信息,所述多个用户包括大人和幼儿;
语音识别部,其从通过麦克风取得的所述装置周边的声音中提取语音,提取与所述语音对应的文本数据和所述语音的特征量,将所述文本数据与所述特征量关联并记录于第1数据库;
第1判定部,其基于所述用户信息和所述第1数据库,判定所述大人与所述幼儿是否正在交谈,在所述推定出的人物是所述大人和所述幼儿、并且所述特征量包括互不相同的多个特征量的情况下,判定为所述大人与所述幼儿正在交谈;
第2判定部,其在判定为所述大人与所述幼儿正在交谈的情况下,基于所述第1数据库,判定是否需要向所述大人和所述幼儿重新提供话题,在所述文本数据包含有第1关键字的情况下,判定为需要向所述大人和所述幼儿重新提供话题;
提取部,其在判定为需要提供所述话题的情况下,基于所述第1数据库和第2数据库,提取所述话题的候选,所述第2数据库存储表示所述幼儿在第1预定期间活动了的项目的活动项目,所述话题的候选与所述活动项目对应,并且与记录于所述第1数据库的所述文本数据所包含的活动项目不对应;
选择部,其从所述话题的候选中选择向所述大人和所述幼儿提供的一个话题;以及
生成部,其生成包括所述一个话题的语音数据,将所述生成的语音数据输出到扬声器。
15.一种装置,是与用户进行语音对话的装置,具备:
传感器,其取得所述装置周边的图像数据、和表示到位于所述装置周边的包括人物在内的物体的距离的距离数据;
麦克风,其取得所述装置周边的声音;
存储器;
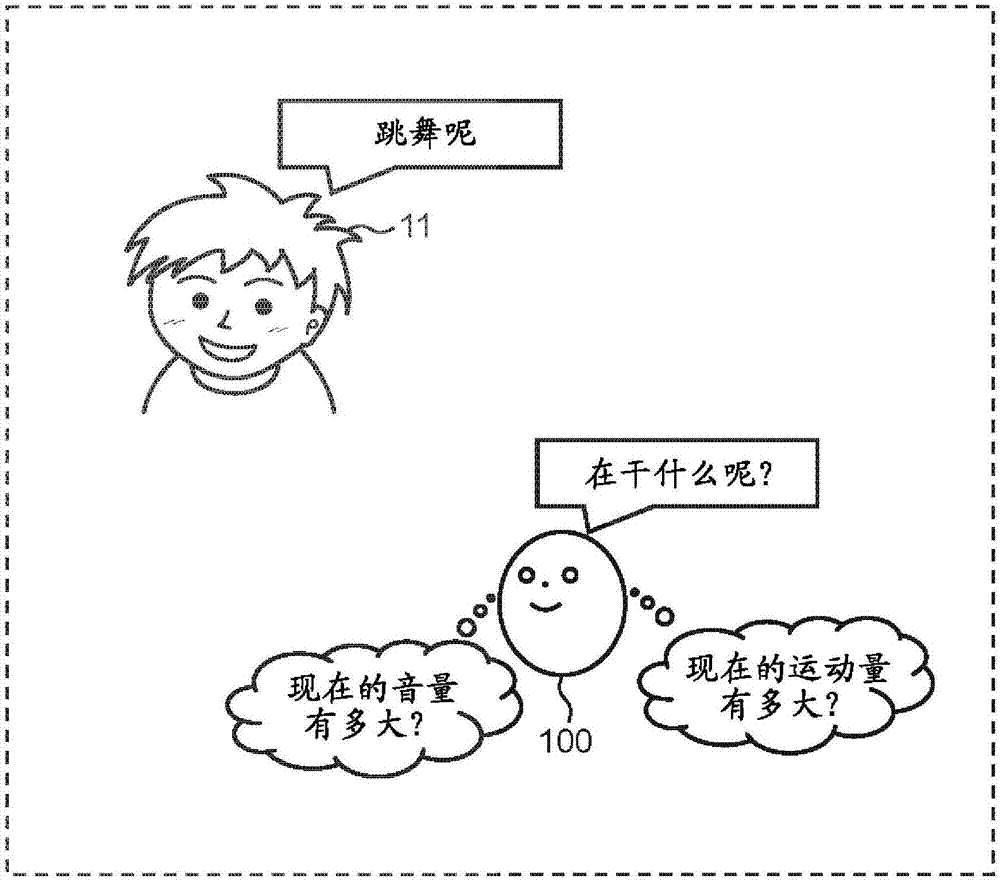
音量测定部,其从所述取得的声音中提取语音,输出表示所述提取到的语音的音量的音量信息;
人物推定部,其基于所述取得的图像数据和所述存储器所存储的与所述用户对应的图像数据,推定所述取得的图像数据所包含的人物,输出表示所述推定出的人物的用户信息,所述用户包括幼儿;
姿势推定部,其在所述用户信息所示的人物是所述幼儿的情况下,基于所述取得的图像数据、所述取得的距离数据、和所述存储器所存储的表示人体的各姿势下的三维骨骼位置的人体模型数据,推定所述幼儿的姿势,输出表示所述推定出的幼儿的姿势的姿势信息;
运动量测定部,其在所述用户信息所示的人物是所述幼儿的情况下,基于所述取得的图像数据、所述取得的距离数据、和所述存储的人体模型数据,算出所述幼儿的特定部位在第1预定期间内的位置的变化量作为运动量,输出表示所述运动量的运动量信息;
活动项目推定部,其基于所述姿势信息、所述运动量信息、和所述存储器所存储的示出了所述幼儿进行的活动项目、与该活动项目对应的运动量以及与该活动项目对应的幼儿的姿势之间的对应关系的表,或者基于所述提取到的语音所包含的名词,推定所述幼儿当前正在进行的活动项目,输出表示所述推定出的活动项目的活动信息;
生成部,其生成包括与所述活动信息所表示的活动项目对应的关键字的第1语音数据,所述第1语音数据用疑问句来表现;
扬声器,其输出所述第1语音数据;
语音识别部,其在所述第1语音数据被输出后,识别从所取得的声音中提取到的语音的内容,输出表示识别出的语音的内容的文本数据;
判定部,其判定所述文本数据是否包含有肯定句;以及
记录部,其在判定为所述文本数据包含有肯定句的情况下,将所述活动信息、所述运动量信息与所述音量信息关联并记录于数据库。
16.根据权利要求15所述的装置,
所述第1语音数据包括询问所述幼儿是否正在进行所述推定出的活动项目的文本数据。
17.根据权利要求15所述的装置,
所述判定部在判定为所述文本数据不包含所述肯定句的情况下,判定所述文本数据是否包含有否定句,
所述活动项目推定部在通过所述判定部判定为所述文本数据不包含所述否定句的情况下,判定所述文本数据是否包含有名词,在判定为所述文本数据包含有所述名词的情况下,推定为所述名词表示了所述幼儿当前正在进行的活动项目。
18.根据权利要求17所述的装置,
所述生成部在通过所述活动项目推定部判定为所述文本数据不包含所述名词的情况下,生成用于询问所述幼儿其正在干什么的第2语音数据,
所述扬声器输出所述第2语音数据。
19.根据权利要求15所述的装置,
所述运动量测定部算出在包括所述第1预定期间的第2预定期间内的所述变化量的平均值作为所述运动量,
所述音量测定部将在所述第2预定期间内提取到的语音的音量的平均值作为所述音量信息输出。
20.根据权利要求15所述的装置,
所述记录部将被乘以第1系数的所述运动量作为所述运动量信息记录于所述数据库,并且将被乘以第2系数的所述音量作为所述音量信息记录于所述数据库,
所述第1系数是预定的第1常数除以第2常数而得到的值,
所述第2系数是预定的第3常数除以所述第2常数而得到的值。
21.一种机器人,具备:
权利要求15所述的装置;
壳体,其内置所述装置;以及
移动机构,其使所述壳体移动。
22.一种方法,是与用户进行语音对话的装置中的方法,包括:
取得所述装置周边的图像数据、和表示到位于所述装置周边的包括人物在内的物体的距离的距离数据;
取得所述装置周边的声音;
从所述取得的声音中提取语音,输出表示所述提取到的语音的音量的音量信息;
基于所述取得的图像数据和存储器所存储的与所述用户对应的图像数据,推定所述取得的图像数据所包含的人物,输出表示所述推定出的人物的用户信息,所述用户包括幼儿;
在所述用户信息所示的人物是所述幼儿的情况下,基于所述取得的图像数据、所述取得的距离数据、和所述存储器所存储的表示人体的各姿势下的三维骨骼位置的人体模型数据,推定所述幼儿的姿势,输出表示所述推定出的幼儿的姿势的姿势信息;
在所述用户信息所示的人物是所述幼儿的情况下,基于所述取得的图像数据、所述取得的距离数据、和所述存储的人体模型数据,算出所述幼儿的特定部位在第1预定期间内的位置的变化量作为运动量,输出表示所述运动量的运动量信息;
基于所述姿势信息、所述运动量信息、和所述存储器所存储的示出了所述幼儿进行的活动项目、与该活动项目对应的运动量以及与该活动项目对应的幼儿的姿势之间的对应关系的表,或者基于所述提取到的语音所包含的名词,推定所述幼儿当前正在进行的活动项目,输出表示所述推定出的活动项目的活动信息;
生成包括与所述活动信息所表示的活动项目对应的关键字的第1语音数据,所述第1语音数据用疑问句来表现;
输出所述第1语音数据;
在输出所述第1语音数据后,识别从所取得的声音中提取到的语音的内容,输出表示识别出的语音的内容的文本数据;
判定所述文本数据是否包含有肯定句;以及
在判定为所述文本数据包含有肯定句的情况下,将所述活动信息、所述运动量信息与所述音量信息关联并记录于数据库。
23.一种程序,是用于与用户进行语音对话的程序,该程序使与所述用户进行语音对话的装置所具备的处理器作为如下各部而发挥功能:
音量测定部,其从通过麦克风取得的所述装置周边的声音中提取语音,输出表示所述提取到的语音的音量的音量信息;
人物推定部,其基于通过传感器取得的所述装置周边的图像数据和存储器所存储的与所述用户对应的图像数据,推定所述取得的图像数据所包含的人物,输出表示所述推定出的人物的用户信息,所述用户包括幼儿;
姿势推定部,其在所述用户信息所示的人物是所述幼儿的情况下,基于所述取得的图像数据、表示通过所述传感器取得的到位于所述装置周边的包括人物在内的物体的距离的距离数据、和所述存储器所存储的表示人体的各姿势下的三维骨骼位置的人体模型数据,推定所述幼儿的姿势,输出表示所述推定出的幼儿的姿势的姿势信息;
运动量测定部,其在所述用户信息所示的人物是所述幼儿的情况下,基于所述取得的图像数据、所述取得的距离数据、和所述存储的人体模型数据,算出所述幼儿的特定部位在第1预定期间内的位置的变化量作为运动量,输出表示所述运动量的运动量信息;
活动项目推定部,其基于所述姿势信息、所述运动量信息、和所述存储器所存储的示出了所述幼儿进行的活动项目、与该活动项目对应的运动量以及与该活动项目对应的幼儿的姿势之间的对应关系的表,或者基于所述提取到的语音所包含的名词,推定所述幼儿当前正在进行的活动项目,输出表示所述推定出的活动项目的活动信息;
生成部,其生成包括与所述活动信息所表示的活动项目对应的关键字的第1语音数据,将所述第1语音数据输出给扬声器,所述第1语音数据用疑问句来表现;
语音识别部,其在输出所述第1语音数据后,识别从所取得的声音中提取到的语音的内容,输出表示识别出的语音的内容的文本数据;
判定部,其判定所述文本数据是否包含有肯定句;以及
记录部,其在判定为所述文本数据包含有肯定句的情况下,将所述活动信息、所述运动量信息与所述音量信息关联并记录于数据库。
- 还没有人留言评论。精彩留言会获得点赞!