基于神经网络的语音增强方法、设备及存储介质与流程
本发明涉及语音增强领域,尤其涉及一种基于神经网络的语音增强方法、设备及存储介质。
背景技术:
1、传统降噪算法需要能量判断以及阈值的设置来设定噪声的估计值,这样可能会导致噪声估计值不稳定,尤其是在设备移动过程中,从低噪声的环境切换到大噪声环境下。同时传统降噪算法容易引入音乐噪声,以及很难对突发的噪声(例如敲击键盘、笔掉在地上、物体碰撞等声音)进行抑制。
2、现有开源的rnnoise降噪算法,体量少复杂度低能移植到单片机上面运行,涉及的面是传统的降噪和神经网络的结合,而传统的降噪,模型涉及到vad与pitch算法,在特征提取时相对复杂。而其他主流开源的dnn、cnn、rnn等神经网络算法体量都是比较大,参数量巨大并不适合移植到单片机上面运行。
3、因此,为了解决当前神经网络的在小型单片机上运行时导致噪声过滤算法无法应对突发的噪声进行过滤抑制的技术问题。
技术实现思路
1、本发明的主要目的在于解决神经网络的在小型单片机上运行时导致噪声过滤算法无法应对突发的噪声进行过滤抑制的技术问题。
2、本发明第一方面提供了一种基于神经网络的语音增强方法,所述基于神经网络的语音增强方法包括:
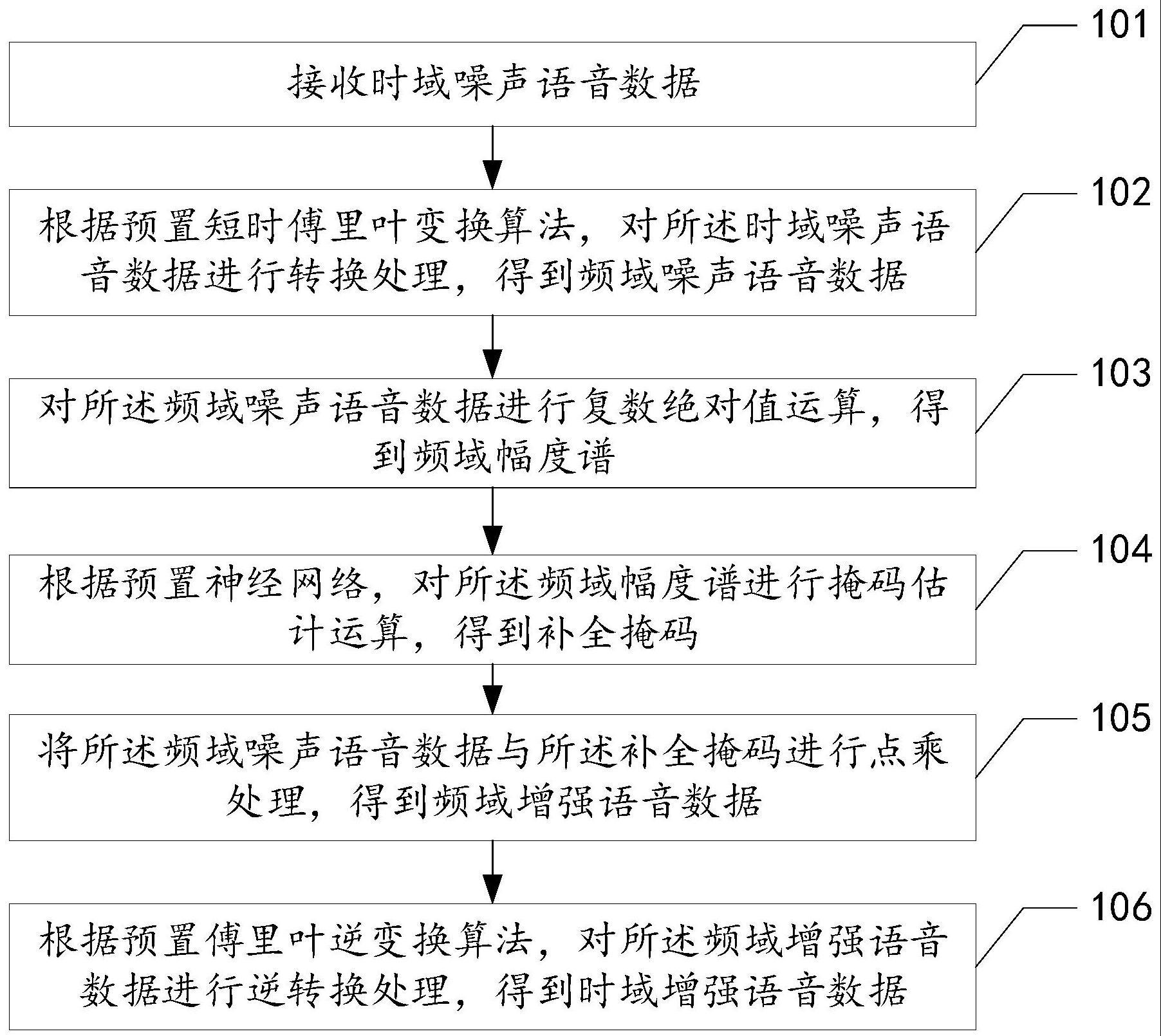
3、接收时域噪声语音数据;
4、根据预置短时傅里叶变换算法,对所述时域噪声语音数据进行转换处理,得到频域噪声语音数据;
5、对所述频域噪声语音数据进行复数绝对值运算,得到频域幅度谱;
6、根据预置神经网络,对所述频域幅度谱进行掩码估计运算,得到补全掩码;
7、将所述频域噪声语音数据与所述补全掩码进行点乘处理,得到频域增强语音数据;
8、根据预置傅里叶逆变换算法,对所述频域增强语音数据进行逆转换处理,得到时域增强语音数据。
9、可选的,在本发明第一方面的第一种实现方式中,在所述根据预置神经网络,对所述频域幅度谱进行掩码估计运算,得到补全掩码之前,还包括:
10、建立采集数据的输入层;
11、在所述输入层的信息输出端设置连接有隐藏层,在所述隐藏层的信息输出端设置连接输出层;
12、将所述输入层、所述隐藏层、所述输出层组合确定为神经网络。
13、可选的,在本发明第一方面的第二种实现方式中,所述隐藏层包括:第一全连接层、第一gru连接层、第二gru连接层、第二全连接层、第三全连接层,所述根据预置神经网络,对所述频域幅度谱进行掩码估计运算,得到补全掩码包括:
14、所述输入层对所述频域幅度谱采集幅度数据,对所述幅度数据进行输入连接处理,得到连接输入数据,将所述连接输入数据输入至所述第一全连接层;
15、所述第一全连接层接收所述连接输入数据,所述连接输入数据与第一全连接层所有数据进行线性处理,以及经过relu激活函数进非线性处理,生成第一传导数据,以及将所述第一传导数据传输至所述第一gru连接层中;
16、所述第一gru连接层接收所述第一传导数据,对所述第一传导数据进行线性处理,得到第二传导数据,以及将所述第二传导数据传输至所述第二gru连接层中;
17、所述第二gru连接层接收所述第二传导数据,对所述第二传导数据进行线性处理,以及经过relu激活函数进非线性处理,生成第三传导数据,及将所述第三传导数据传输至所述第二全连接层中;
18、所述第二全连接层接收所述第三传导数据,对所述第三传导数据进行线性处理,以及经过relu激活函数进非线性处理,生成第四传导数据,以及将所述第四传导数据传输至所述第三全连接层中;
19、所述第三全连接层接收所述第四传导数据,对所述第四传导数据进行线性处理,以及经过simoid激活函数进非线性处理,生成第五传导数据,以及将所述第五传导数据传输至所述输出层;
20、所述输出层接收所述第五传导数据,输出补全掩码。
21、可选的,在本发明第一方面的第三种实现方式中,所述输入层对所述频域幅度谱采集幅度数据包括:
22、所述输入层对所述频域幅度谱进行前257个点数据采集,得到257个数据点的幅度数据。
23、可选的,在本发明第一方面的第四种实现方式中,在所述根据预置神经网络,对所述频域幅度谱进行掩码估计运算,得到补全掩码之前,还包括:
24、接收纯净语音数据和噪声数据;
25、将所述纯净语音数据和所述噪声数据进行合并处理,得到合并声学数据;
26、根据预置短时傅里叶变换算法,对所述合并声学数据进行转换处理,得到频域声学数据;
27、对所述频域声学数据进行复数绝对值平方运算,得到预测声学数据;
28、根据预置维纳滤波器,对所述纯净语音数据和所述噪声数据进行最优掩码运算,得到最优掩码数据;
29、根据预置神经网络,对所述预测声学数据进行掩码估计运算,得到预测掩码;
30、将所述最优掩码数据与所述预测掩码进行最小均方差运算,得到方差值;
31、根据所述方差值,调整所述神经网络的参数,生成训练后的神经网络。
32、可选的,在本发明第一方面的第五种实现方式中,所述根据预置维纳滤波器,对所述纯净语音数据和所述噪声数据进行最优掩码运算,得到最优掩码数据包括:
33、根据预置短时傅里叶变换算法,对所述纯净语音数据进行转换处理,得到频域纯净语音数据;
34、根据预置短时傅里叶变换算法,对所述噪声数据进行转换处理,得到频域噪声数据;
35、将所述频域噪声数据和所述频域纯净语音数据代入预置维纳滤波器中,生成最优掩码数据。
36、可选的,在本发明第一方面的第六种实现方式中,所述维纳滤波器包括:
37、
38、其中,w为最优掩码数据,px为频域纯净语音数据的功率谱,pn为频域噪声数据的功率谱,x为纯净语音数据,n为噪声数据。
39、可选的,在本发明第一方面的第六种实现方式中,所述接收时域噪声语音数据包括:
40、接收url地址,从所述url地址中抓取时域噪声语音数据。
41、本发明第二方面提供了一种基于神经网络的语音增强设备,包括:存储器和至少一个处理器,所述存储器中存储有指令,所述存储器和所述至少一个处理器通过线路互连;所述至少一个处理器调用所述存储器中的所述指令,以使得所述基于神经网络的语音增强设备执行上述的基于神经网络的语音增强方法。
42、本发明的第三方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述的基于神经网络的语音增强方法。
43、在本发明实施例中,通过对于突发的噪声干扰,将所有声频先进行短时傅里叶变换转换为频域数据,再利用安装在单片机的神经网络进行频域的噪声和纯净声的识别,给出相关声学数据对应的补全掩码,利用补全掩码修改声学数据,消除噪声后再转换回时域的音频数据,实现了降噪的增强音频数据的生成,解决了神经网络的在小型单片机上运行时导致噪声过滤算法无法应对突发的噪声进行过滤抑制的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!