一种语意识别的多模态全双工对话方法及系统与流程
本发明涉及语意识别,特别涉及一种语意识别的多模态全双工对话方法及系统。
背景技术:
1、多模态全双工对话是指在对话过程中同时涉及多种模态(如:文本、语音、图像和视频等)的输入和输出。语意识别指的是识别一段内容(比如:文字、音频和图像等)代表的意思。语意识别的多模态全双工对话方法是指在对话系统中同时处理多种模态输入和输出的方法,该方法能够实现全双工的对话交互,它将语意理解和生成扩展到多种模态,并使得对话系统能够更全面地理解用户输入信息并生成多模态回复信息。
2、申请号为:cn201811010816.7的发明专利公开了一种基于网页实现全双工语音对话和页面控制的方法,其中,方法包括:用户进行网页页面访问;用户在网页页面内发起语音会话请求;以及响应语音会话请求的服务端;服务端与用户建立全双工语音对话并输出用户意图;命令控制模块接收用户意图实现页面控制。上述发明解决了现有网页管理者与网站访客对话交互体验较差、沟通效率不高的问题。
3、但是,上述现有技术只是进行语音模态的对话,但是简单的语音模态的表达的表达方式较为单一,存在需要表达的内容无法通过语音直观的表现的情形,另外,人机交互过程体验也较差。
4、有鉴于此,亟需一种语意识别的多模态全双工对话方法及系统,以至少解决上述不足。
技术实现思路
1、本发明目的之一在于提供了一种语意识别的多模态全双工对话方法及系统,根据获取的发起对话和对话用户选择的对话模态,确定对话语意,根据对话语意和对话模态,进行多模态全双工对话,更丰富地表达和理解用户意图,提供了更多样化的回应,交互性也更强。
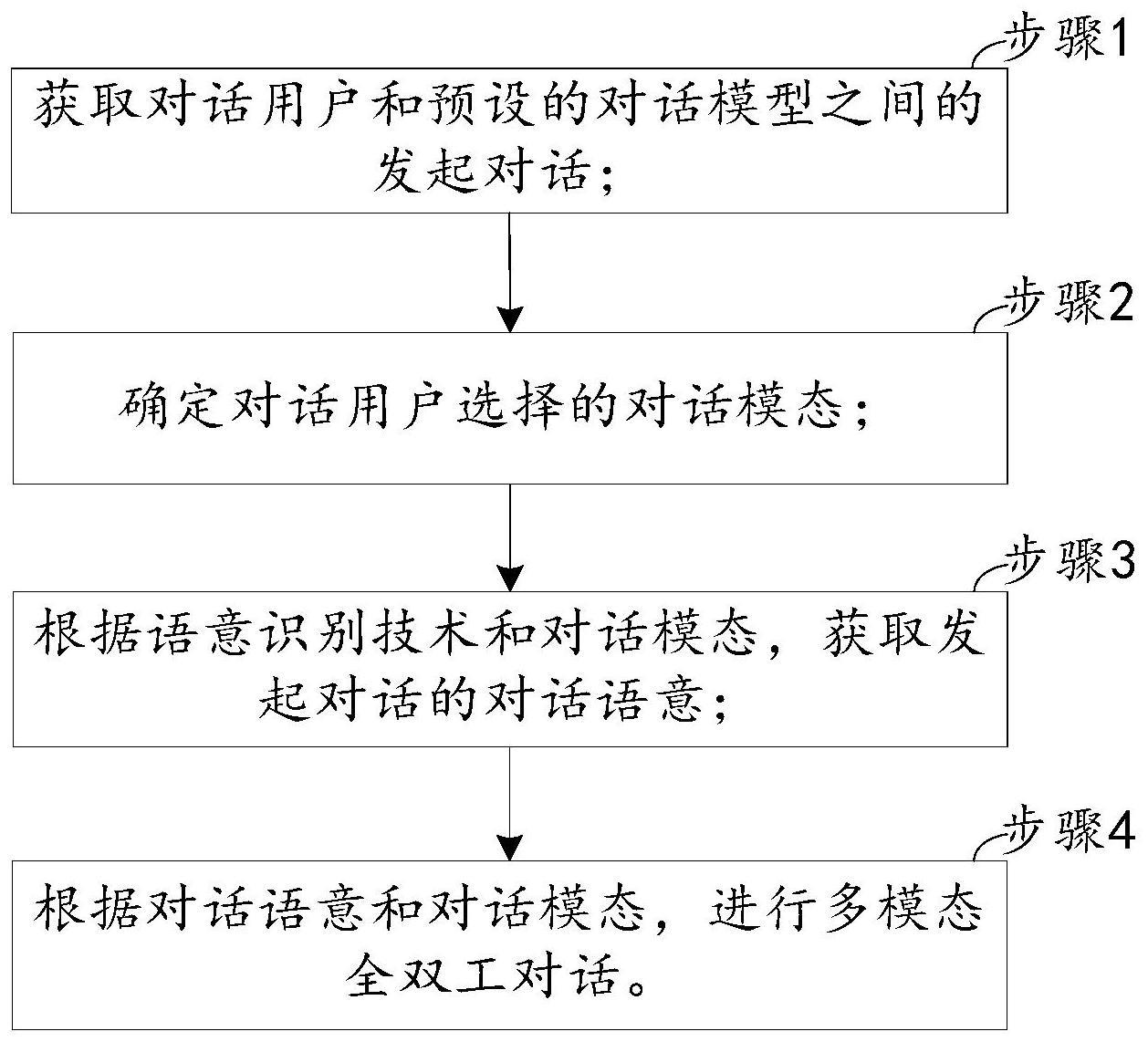
2、本发明实施例提供的一种语意识别的多模态全双工对话方法,包括:
3、步骤1:获取对话用户和预设的对话模型之间的发起对话;
4、步骤2:确定对话用户选择的对话模态;
5、步骤3:根据语意识别技术和对话模态,获取发起对话的对话语意;
6、步骤4:根据对话语意和对话模态,进行多模态全双工对话。
7、优选的,步骤1:获取对话用户和预设的对话模型之间的发起对话,包括:
8、确定用于发起对话的输入端口;
9、获取对话用户的输入信息;
10、根据输入信息的信息类型,确定输入信息的目标端口;
11、基于目标端口对应的解析规则,根据输入信息,确定端口信息;
12、基于实时web技术,根据端口信息,确定发起对话。
13、优选的,步骤2:确定对话用户选择的对话模态,包括:
14、获取对话用户输入的模态选择指令,根据模态选择指令,确定对话模态;
15、和/或,
16、获取对话用户输入的上文信息,根据上文信息,确定用户的模态切换意图,根据模态切换意图,确定对话模态。
17、优选的,步骤3:根据语意识别技术和对话模态,获取发起对话的对话语意,包括:
18、根据对话模态,收集训练数据;
19、基于预设的抽取规则,根据训练数据,确定多个抽取样本;
20、基于随机森林算法,根据抽取样本,训练语意识别决策树;
21、根据发起对话和语意识别决策树,确定多个决策结果;
22、获取决策结果表达热图;
23、根据决策结果表达热图,进行每一决策结果的层次聚类,获得聚类树;
24、确定聚类树中体量最大的树节点;
25、获取树节点对应的决策结果的中心热图值;
26、根据中心热图值,确定对话语意;
27、其中,根据决策结果表达热图,进行每一决策结果的层次聚类,获得聚类树,包括:
28、计算决策结果两两之间的相似性,其中,相似性的计算公式为:
29、
30、
31、其中,dm为第m个决策结果,dn为第n个决策结果,correlation(dm,dn)为第m个决策结果和第n个决策结果的相似性计算结果,dis(dm,dn)为第m个决策结果和第n个决策结果在决策结果表达热图上的距离,xm和xn分别为决策结果表达热图上第m个决策结果和第n个决策结果的x维度的标定值,ym和yn分别为决策结果表达热图上第m个决策结果和第n个决策结果的y维度的标定值,σ为预设的相似性归一化系数;
32、将相似性最高的决策结果进行迭代合并,获得聚类树。
33、优选的,根据对话模态,收集训练数据,包括:
34、获取对话模态的模态类型;
35、根据模态类型,确定收集规则;
36、确定收集规则对应预设的收集模板;
37、获取发起对话的对话场景;
38、基于预设的对话场景特征提取规则,提取对话场景的对话场景特征;
39、根据对话场景特征,确定收集模板的特征设置参数;
40、设置收集模板相应特征设置参数,获得目标模板;
41、根据目标模板,收集训练数据。
42、优选的,步骤4:根据对话语意和对话模态,进行多模态全双工对话,包括:
43、根据对话语意,获取对话需求;
44、确定对话模态的输出通道;
45、根据对话需求和输出通道,确定输出内容;
46、根据输出内容进行多模态全双工对话。
47、优选的,根据对话需求和输出通道,确定输出内容,包括:
48、基于预设的对话向量模型,确定对话需求的第一对话向量;
49、获取输出通道对应语料组;
50、基于预设的断句规则,根据语料组,确定多个第一断句语料;
51、基于对话向量模型,确定第一断句语料的第二对话向量;
52、将第一对话向量与第二对话向量的向量起点对齐,当向量起点对齐后,获取第一对话向量和第二对话向量之间的第一向量夹角;
53、若第一向量夹角小于预设的向量夹角阈值,将对应第二对话向量作为第三对话向量;
54、确定第一对话向量和第三对话向量之间的第一向量夹角,并作为第二向量夹角;
55、将第三对话向量旋转第二向量夹角,获得第四对话向量;
56、计算第四对话向量和第一对话向量的向量模值差值;
57、根据第二向量夹角和向量模值差值,确定输出内容;
58、其中,计算第四对话向量和第一对话向量的向量模值差值,包括:
59、计算第四对话向量和第一对话向量的同一向量维度的维度差值;
60、根据向量维度和预设的维度权重库,获取向量维度的维度权重;
61、基于预设的计算规则,根据维度差值和维度权重,确定向量模值差值。
62、优选的,根据第二向量夹角和向量模值差值,确定输出内容,包括:
63、获取向量夹角对应预设的第一转换规则,同时,获取向量模值差值对应预设的第二转换规则;
64、根据第一转换规则,确定第二向量夹角对应的第一转换值,并与对应第三对话向量进行关联;
65、根据第二转换规则,确定向量模值差值对应的第二转换值,并与对应第三对话向量进行关联;
66、对第三对话向量关联的第一转换值和第二转换值进行求和,获得统计值;
67、将统计值最小的第三对话向量对应的第一断句语料作为第二断句语料;
68、根据第二断句语料和语料组中的第一断句语料,确定第三断句语料,将第三断句语料作为输出内容。
69、优选的,根据输出内容进行多模态全双工对话,包括:
70、获取输出内容的呈现要求;
71、根据呈现要求,确定第一支持参数;
72、获取本地服务器的第二支持参数;
73、根据第一支持参数和第二支持参数,判断输出内容能否在用户界面呈现;
74、若输出内容能够在用户界面呈现,则通过用户界面呈现输出内容;
75、若输出内容不能在用户界面呈现,通过本地服务器建立与符合呈现要求的目标平台的通信链路,并将呈现要求发送给目标平台;
76、获取目标平台接收呈现要求之后的呈现信息,并将呈现信息进行实时回传。
77、本发明实施例提供的一种语意识别的多模态全双工对话系统,包括:
78、发起对话获取子系统,用于获取对话用户和预设的对话模型之间的发起对话;
79、对话模态确定子系统,用于确定对话用户选择的对话模态;
80、对话语意获取子系统,用于根据语意识别技术和对话模态,获取发起对话的对话语意;
81、对话子系统,用于根据对话语意和对话模态,进行多模态全双工对话。
82、本发明的有益效果为:
83、本发明根据获取的发起对话和对话用户选择的对话模态,确定对话语意,根据对话语意和对话模态,进行多模态全双工对话,更丰富地表达和理解用户意图,提供了更多样化的回应,交互性也更强。
84、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
85、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!