一种语音隐私保护方法及装置与流程
本发明涉及语音,尤其涉及一种语音隐私保护方法及装置。
背景技术:
1、语音是人类最自然、最便捷的交流方式,通过语音传递信息占据了人们日常交流的主要部分。语音数据中包含的丰富个人信息,如年龄、性别、情绪、地理区域等,越来越受到关注。
2、随着科技的发展,由于语音助手、语音操控设备、电话咨询、网络语音业务等语音交互应用的广泛应用,用户语音信息更多地暴露在公开环境中,给个人信息安全带来了潜在威胁。在语音交互过程中,用户的个人信息可能被不法分子获取并用于非法的目的,如诈骗、身份盗用等;而且,在一些情境下,如社交平台、短视频平台等,用户也注重个人语音信息的匿名化处理,保护用户个人信息的安全性和隐私性。
3、相关技术中,为了保护用户语音隐私,主要采取声纹替换的技术措施,将用户语音替换为他人的声纹;或将用户的声音转换成特定类型的声音,如儿童、老人、男性或女性的声音;或者将用户语音中的敏感内容替换为语义相似的非敏感内容。
4、但是简单的声纹替换手段对用户个人信息保护力度较弱,溯源难度较低,同时现有的语音处理手段最终生成了不可控的音色,不能满足用户个性化需求;而且将内容替换的技术手段针对复杂语义容易出现语音内容信息识别误差。
技术实现思路
1、为克服上述语音隐私保护方法和装置所存在的缺陷,本发明要解决的技术问题是提供一种适应用户个性化需求、语音内容信息真实度高、语音信息安全性更高的语音隐私保护方法和装置。
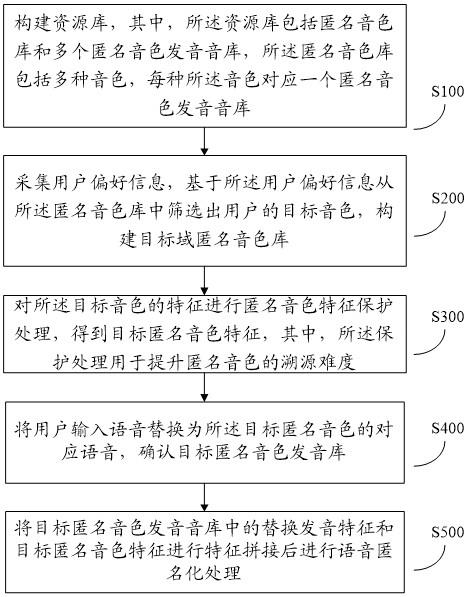
2、一方面,就语音隐私保护方法而言,本发明为解决所述技术问题的语音隐私保护方法包括如下步骤:
3、构建资源库,其中,所述资源库包括匿名音色库和多个匿名音色发音音库,所述匿名音色库包括多种音色,每种所述音色对应一个匿名音色发音音库;
4、采集用户偏好信息,基于所述用户偏好信息从所述匿名音色库中筛选出用户的目标音色,构建目标域匿名音色库;
5、将用户输入语音替换为所述目标音色的对应语音,形成替换发音特征并构建目标匿名音色发音库;
6、基于所述替换发音特征进行语音匿名化处理。
7、相比现有技术,本发明在匿名音色定义单元,通过支持用户上传偏好信息,提高匿名音色的用户喜爱度,解决了先关技术中语音隐私保护方法及装置不能生成可控的匿名音色的问题,完全适应用户的个性化需求。
8、作为上述语音隐私保护方法的改进,所述构建目标域匿名音色库包括:
9、对所述目标音色的特征进行匿名音色特征保护处理,得到目标匿名音色特征,其中,所述保护处理用于提升匿名音色的溯源难度。
10、与现有技术相比,本发明在匿名音色确认单元,通过生成随机权重对若干音色组合应用,提高了匿名音色的溯源难度,进一步用户信息的安全性。
11、作为上述语音隐私保护方法的改进,所述匿名音色特征保护处理包括如下步骤:
12、对多个目标匿名音色的特征取均值,得到平均目标音色特征;
13、从dirichlet分布中获得多个随机数作为多个所述目标音色的权重向量k,对多个所述目标音色的特征进行加权求和得到加权目标音色特征;
14、取所述平均目标音色特征与加权目标音色特征的均值作为当前用户的目标匿名音色特征。
15、作为上述语音隐私保护方法的改进,所述构建目标匿名音色发音库包括如下步骤:
16、从匿名音色发音音库中索引出所述目标音色对应的发音音库;
17、对所述发音音库的每一个语音发音对应的不同音色的语音片段进行加权求和。
18、作为上述语音隐私保护方法的改进,所述对所述发音音库的每一个语音发音对应的不同音色的语音片段进行加权求和包括如下步骤:
19、调整用户实时语音采样率与目标匿名音色的采样率一致;
20、对所述用户实时语音进行归一化、分帧处理;
21、提取每帧语音信号的声学发音特征;
22、对每帧语音信号,将提取到的声学发音特征 与所述目标匿名音色发音音库中的声学发音特征进行相似度计算,取最为相似的5组特征 和与5组所述特征对应的相似度分数 ,其中,所述分数范围为0-1;
23、根据公式
24、
25、计算得到所述5组特征的权重;
26、将5组所述特征与所述权重加权求和,得到当前帧语音信号的替换发音特征。
27、作为上述语音隐私保护方法的改进,所述匿名音色库包括多种音色的表征特征,所述表征特征通过基于ecapa-tdnn的声纹信息提取模型获得的256维语音信号;
28、所述匿名音色发音音库包括多种所述音色对应的声学发音特征构成,所述声学发音特征为通过预训练特征提取器wav2vec2.0获得的768维语音信号。
29、作为上述语音隐私保护方法的改进,在进行语音匿名化处理之前,进行如下步骤:
30、将所述替换发音特征和目标匿名音色特征进行特征拼接。
31、相比现有技术,本发明实施例提供的语音隐私保护方法及装置在语音匿名化过程中采用发音替换和音色替换两种手段,在发音替换模块后,用户语音中的身份信息不再后传,增强了用户原始音色的保护力度,提升用户身份信息的安全性。
32、作为上述语音隐私保护方法的改进,所述语音匿名化处理步骤具体包括如下步骤:
33、将256维的目标匿名音色特征和768维的替换发音特征拼接为1024维的特征;
34、将所述1024维的特征输入给训练好的合成器,输出合成的频谱特征;
35、将合成的频谱特征作为hifi-gan声码器的输入,生成匿名化的语音输出。
36、作为上述语音隐私保护方法的改进,
37、所述合成器的训练过程包括以下步骤:
38、准备训练语音数据;
39、对所述语音数据进行采样率统一、归一化、分帧处理;
40、基于ecapa-tdnn的声纹信息提取模型提取所述语音数据的256维音色特征;
41、基于预训练特征提取器wav2vec2.0提取所述语音数据的768维发音特征;
42、将所述语音数据的音色特征和发音特征拼接为1024维的特征;
43、计算所述语音数据的频谱特征;
44、将所述1024维的特征作为所述合成器网络的输入,输出所述语音数据的频谱特征,以所述频谱重建损失函数,训练所述合成器模型,直到频谱重建损失满足用户要求。
45、第二方面,就语音隐私保护装置而言,本发明为解决所述技术问题的语音隐私保护装置包括:
46、资源库建设模块:用于存储包括多种音色的匿名音色库及每种音色对应的发音音库;
47、匿名音色定义模块:用于基于用户偏好信息构建出当前用户的目标域匿名音色库;
48、匿名音色处理模块:用于通过随机权重和目标域匿名音色库得到当前用户的目标匿名音色特征;
49、目标匿名音色发音库确认模块:用于基于随机权重和目标域匿名音色的发音音库得到目标匿名音色发音音库;
50、语音匿名化处理模块:用于基于目标匿名音色特征和目标匿名音色发音音库得到匿名化的语音输出。
51、上述语音隐私保护装置的有益效果与上述语音隐私保护方法的有益效果一致,在此不做赘述。
52、第三方面,就语音隐私保护系统而言,本发明为解决所述技术问题的语音隐私保护系统包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述的语音隐私保护方法的步骤。
53、上述语音隐私保护系统的有益效果与上述语音隐私保护方法的有益效果一致,在此不做赘述。
54、第四方面,就语音隐私保护计算机存储介质而言,本发明为解决所述技术问题的语音隐私保护计算机存储介质包括:所述计算机存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述的语音隐私保护方法的步骤。
55、上述语音隐私保护计算机存储介质的有益效果与上述语音隐私保护方法的有益效果一致,在此不做赘述。
- 还没有人留言评论。精彩留言会获得点赞!