一种检测DNA序列的方法与流程
本发明涉及一种DNA检测方法,尤其涉及一种简单、高效、定量的DNA检测方法。
背景技术:
自1977年Sanger发明了DNA双脱氧链终止法DNA测序技术以来(Sanger F.,Nichlen S.et al.Proc.Natl.Acad.Sci.U.S.A.,1977,74(2):5463-5467),DNA测序已经取得了跨越式发展。Sanger法的原理是在反应体系中加入一定比例的2’,3’-双脱氧核苷酸(ddNTP),然后随着ddNTP的掺入,链反应会终止延伸。Sanger法操作简单,而且随着荧光标记的发明,逐渐实现了自动化。其中,最著名的测序仪器便是美国ABI公司开发的ABI377和ABI3730等,其中基于毛细管电泳技术的3730到目前仍在广泛使用。虽然Maxam和Gilbert也于1977年发明了化学法测定DNA序列的技术,但是由于操作繁琐,该技术并未获得广泛推广(Maxam A.M.,Gilbert W.,Proc.Natl.Acad.Sci.U.S.A.,1977,74(2):560-564)。
这些年随着下一代测序技术(Next Generation Sequencing,NGS)的飞速发展,DNA测序开始往高通量、低成本的方向在发展。目前NGS市场主要是使用Illumina公司提供的测序平台,剩余的市场使用由Life Technologies(Thermo Fisher Scientific)、454Roche和Pacific Biosciences等公司提供的平台。各个公司的平台各有特点,但是都是在朝着降低成本、提高通量和速度的方向在努力。
自诞生以来,NGS已经在多个领域获得了广泛应用,例如,生物研发、医疗诊断和人类基因组计划等。通常的做法是将双链DNA模板随机打断,然后连上接头进行测序。如果出发的样本是RNA,则需要先将RNA反转录为DNA样本,然后再进行测序。
对于较短的单链DNA(ssDNA)样品,目前也有为数不多一些的技术方案 来利用NGS平台进行测定。例如,Gansauge等人曾经使用生物素标记的接头(adaptor)来与ssDNA连接,然后再连入第二个接头,之后用PCR的方法进行扩增,并利用现有的NGS平台进行序列测定(M.-T.Gansauge,M.Meyer,Nat.Protoc.,2013,8(4):737-748)。该方案需要两次连接接头;而且第二个接头是经过特别设计的,含有2’,3’双脱氧结构以保证只连接一条链。同时,该方案比较适合于较少量的ssDNA的序列测定,但特别不适合对ssDNA中序列的定量分析,因此该方法主要用于古生物DNA的测定,重点针对损坏的微量DNA。另外,该方案只能与Illumina平台配套,一定程度上限制了该方案的使用范围。由于该方案还需要进行PCR扩增,且PCR有一定的偏好性,该方案会影响数据的绝对定量结果。
技术实现要素:
针对目前DNA检测方法存在的成本高、适用性差、定量性差等问题,本发明提供了一种新的检测DNA序列的方法,可以实现高效、简便和准确的定性和定量检测。
本发明第一个方面是提供一种检测DNA序列的方法,步骤包括:
从单链DNA(ssDNA)待测样品出发,在DNA序列一个末端连接DNA接头(adaptor)序列;其中,所述DNA接头序列的5’端含有磷酸化基团(Pi基团);使所述DNA接头序列形成双链;
将ssDNA合成双链DNA;
利用NGS平台进行测序。
本发明上述内中,所述DNA待测样品中,DNA可以是寡核苷酸(oligonucleotide)、或比寡核苷酸更长或更短的DNA;如:可以是5-500碱基的序列,更优选为7-500碱基的序列,更优选为10-450碱基的序列,更优选为20-450碱基的序列,更优选为25-400碱基的序列,更优选为30-350碱基序列,更优选为35-300碱基序列,更优选为40-250碱基序列,如45碱基、50碱基、60碱基、65碱基、70碱基、75碱基、100碱基、150碱基等。
本发明上述内容中,所述DNA接头序列优选为寡核苷酸序列,所述DNA接头序列的长度优选为5-250碱基,更优选为7-240碱基,更优选为10-230碱 基,更优选为12-200碱基,更优选为15-180碱基,更优选为20-150碱基,如25碱基、30碱基、50碱基、80碱基、100碱基、110碱基、120碱基。
本发明上述内容中,使所述DNA接头序列形成双链的方法可以是选自:加入引物,其中所述引物与所述DNA接头序列之间至少部分特异互补,以与DNA接头序列形成互补双链;或者所述接头本身设计为部分双链结构。
因此,本发明上述内容中,所述DNA接头序列可以是单链序列,也可以是双链序列,所述双链序列可以是仅为部分双链结构,如5’端为单链结构而3’端为双链结构。
当所述DNA接头序列为单链结构时,所述接头序列3’端优选为含有羟基。
当所述DNA接头序列为双链结构时,5’端含Pi基团的为正链,另一条链为反链。
当所述DNA接头序列为双链结构时,可以优选为3’端为平端、正链的3’端突出、正链的3’端缩进、3’端封闭、3’端带有可化学切割部分、在3’端双链之间通过茎环结构连接。
当所述DNA接头序列为单链、3’端为平端、正链的3’端突出或正链的3’端缩进时,所述正链3’端带有羟基基团、或对含有羟基的3’端进行了可逆修饰。
当所述DNA接头序列含有茎环时,在正链和/或反链上还可以存在能够酶切的碱基修饰或酶切位点,所述碱基修饰可以选自脱氨、烷基化修饰中的任意一种或几种,如甲基化修饰,也可以是尿嘧啶,应当理解的是,所述碱基修饰可以是一个碱基或多个碱基修饰;所述酶切位点如位点非常稀少的酶切位点,如归位内切酶、限制性内切酶的酶切位点。所述归位内切酶如I-Dmol、I-Scel、I-Ceul等,并优选为I-Scel,其识别和酶切DNA核心序列包含如下序列或其反向互补序列:
5’-ATTACCCTGTTATCCCTA-3’
当所述DNA接头序列3’端封闭(如3’端羟基被封闭)时,所述封闭可以是、但不限于:碱基修饰、3’端双脱氧处理中的任意一种,并且所述修饰可以是可逆修饰,如对含有羟基的3’端进行可逆修饰。
当所述DNA接头序列3’端封闭时,在正链或反链上还可以存在能够酶切的碱基修饰或酶切位点,所述碱基修饰可以选自脱氨、烷基化修饰,如甲基化修饰,也可以是尿嘧啶;所述酶切位点如位点非常稀少的酶切位点,如归位内切酶,如 I-Dmol、I-Scel、I-Ceul等。
在本发明的一种优选实施例中,所述检测DNA序列的方法,步骤包括:
从单链DNA(ssDNA)待测样品出发,在DNA序列一个末端连接DNA接头序列;其中,所述DNA接头序列为单链序列,5’端含Pi基团,3’端含羟基;
加入引物,在DNA聚合酶作用下,将ssDNA合成双链DNA;其中,所述引物与所述DNA接头序列之间至少部分特异互补;
利用NGS平台进行测序。
在本发明的一种优选实施例中,所述检测DNA序列的方法,步骤包括:
从单链DNA(ssDNA)待测样品出发,在DNA序列一个末端连接DNA接头序列;其中,所述DNA接头序列含双链结构,其中正链的5’端含Pi基团,正链的3’端含羟基;
在DNA聚合酶作用下,将ssDNA合成双链DNA;
利用NGS平台进行测序。
在本发明的一种优选实施例中,所述检测DNA序列的方法,步骤包括:
从单链DNA(ssDNA)待测样品出发,在DNA序列一个末端连接DNA接头序列;其中,所述DNA接头序列含双链结构,其中正链的5’端含Pi基团,正链和反链之间在3’端形成茎环连接,DNA接头序列中含有甲基化修饰碱基;
在DNA聚合酶作用下,将ssDNA合成双链DNA;
在特异性切割甲基化修饰DNA的酶作用下,去除DNA接头序列中的茎环;
利用NGS平台进行测序。
在本发明的一种优选实施例中,所述检测DNA序列的方法,步骤包括:
从单链DNA(ssDNA)待测样品出发,在DNA序列一个末端连接DNA接头序列;其中,所述DNA接头序列含双链结构,其中正链的5’端含Pi基团,正链和反链之间在3’端形成茎环连接,DNA接头序列中含有甲基化修饰碱基;
在特异性切割甲基化修饰DNA的酶作用下,去除DNA接头序列中的茎环;
在DNA聚合酶作用下,将ssDNA合成双链DNA;
利用NGS平台进行测序。
在本发明的一种优选实施例中,所述检测DNA序列的方法,步骤包括:
从单链DNA(ssDNA)待测样品出发,在DNA序列一个末端连接DNA接头序 列;其中,所述DNA接头序列含双链结构,其中正链的5’端含Pi基团,正链和反链之间在3’端形成茎环连接,DNA接头序列中含有尿嘧啶;
在特异性切割尿嘧啶的酶(如NEB公司的USERTM Enzyme)作用下,去除DNA接头中的茎环;
在DNA聚合酶作用下,将ssDNA合成双链DNA;
利用NGS平台进行测序。
本发明上述内容中,所述待测样品在5’端含有磷酸化基团的,还包括在连接DNA接头序列之前进行脱磷的步骤。
本发明第二个方面是提供一种上述检测DNA序列的方法的应用。所述应用可以是定量、定性检测DNA序列中的任意一种或几种,更优选为进行定量检测DNA。
在一种优选实施例中,所述应用包括在合成核苷酸药物质检中的应用:步骤包括:
将合成的核苷酸药物粗产物进行纯化,分离出纯化产物和杂质产物;
采用本发明第一个方面所述的方法,对纯化产物和/或杂质产物进行检测。
在另一种优选实施例中,所述应用包括在合成核苷酸药物质检中的应用:步骤包括:
将合成的核苷酸药物粗产物进行纯化,分离出纯化产物和杂质产物;
采用本发明第一个方面所述的方法,对纯化产物和/或杂质产物进行检测。
将检测结果与已检测合格的产品中的检测结果相对比,如果检测结果与合格产品一致的检测结果一致,则该纯化后的产物为合格产品;否则为不合格产品。
在另一种优选实施例中,所述应用包括在合成核苷酸药物质检中的应用:步骤包括:
将合成的核苷酸药物粗产物进行纯化,分离出纯化产物和杂质产物;
采用本发明第一个方面所述的方法,对纯化产物和/或杂质产物进行检测。
将检测结果与已检测合格的产品中的检测结果相对比,如果检测结果与合格产品一致的检测结果一致,则该纯化后的产物为合格产品;如果检测结果不一致,则需要对纯化产物进行安全性测试。
在另一种优选实施例中,所述应用包括在合成核苷酸药物质检中的应用:步 骤包括:
将合成的核苷酸药物粗产物进行纯化,分离出纯化产物和杂质产物;
采用本发明第一个方面所述的方法,对纯化产物和/或杂质产物进行检测。
将检测结果与已检测合格的产品中的检测结果相对比,如果检测结果与合格产品一致的检测结果一致,则该纯化后的产物为合格产品;如果检测结果不一致,则需要对超出预定含量的杂质进行安全性测试。
本发明上述内容中,所述核苷酸药物可以是预防疾病、治疗疾病的药物中的任意一种或几种。并优选为寡核苷酸类药物,如反义寡核苷酸。
其中,所述药物可以是包括抗病毒药物、抗肿瘤药物、激素类药物中的任意一种或几种,如促红细胞生成素、生长激素、表皮生长因子、胰岛素、白介素、集落刺激因子。
其中,所述反义寡核苷酸也可以是包括化学修饰反义寡核苷酸、Decoy寡核苷酸中的任意一种或几种,如硫代修饰反义寡核苷酸、嵌合寡核苷酸、杂合寡核苷酸、肽核酸、锁核酸、吗啉化寡核苷酸、磷酰胺酯化寡核苷酸、2’-O-烷基化寡核苷酸中的任意一种或几种。
应当理解的是,本发明上述内容中,所述“茎环”指的是一段核苷酸序列,其在3’端将DNA接头的两条链进行连接。
发明人通过广泛而深入的研究,建立了一套用于ssDNA测序的技术方案。首先用给ssDNA连上接头序列,需要加入特异的引物,与接头形成互补的双链,然后在DNA聚合酶的作用下,生成dsDNA,以利用现有的NGS测序平台进行测序分析。实验结果表明,采用上述技术方案成功地进行了多组ssDNA序列的测定。
附图说明
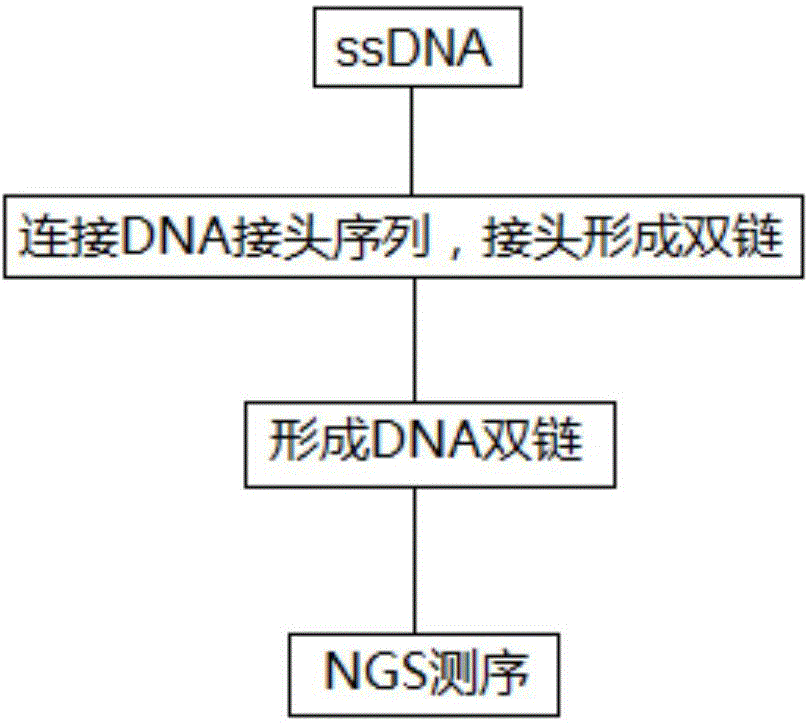
图1为本发明检测DNA序列的方法流程框图;
图2为本发明实施例中几种接头序列结构示意图;
图3为本发明中使用单链接头的检测DNA序列的方法流程示意图;
图4-6为本发明使用双链接头的检测DNA序列的方法流程示意图;
图7-8为本发明使用含茎环结构接头的检测DNA序列的方法流程示意图.
具体实施方式
下面参照附图,并结合具体实施例对本发明检测DNA序列的方法及其应用进行详细介绍。
图1给出了本发明检测DNA序列的方法流程框图,本发明先将ssDNA的一端连接一端DNA接头序列,然后生成双链DNA,最后进行NGS检测。
其中,NGS(Next Generation Sequencing)为高通量测序(High-Throughput sequencing),是相对于传统的桑格测序(Sanger Sequencing)而言的。目前高通量测序的主要平台代表为Illumina、Life Technologies(Thermo Fisher Scientific)、罗氏公司(Roche)和Pacific Biosciences的测序平台。
图2给出了几种不同的DNA接头序列,其中:
第(1)种为单链接头序列,其5’端为磷酸化基团,3’端为羟基(-OH);
第(2)种为部分双链接头序列,正链(图中较长的链)5’端为磷酸化基团,3’端为羟基,并且反链(短链)在3’端与正链之间形成双链;该接头序列分为3’端为平端、突出和缩进三种,具体详见下述实施例;
第(3)种为部分双链接头序列,与第(2)种接头序列不同之处在于,两条链在3’端形成茎环结构,彼此通过该茎环结构连接;图中,正链和反链中均含有尿嘧啶U,但本发明也可以仅在正链或仅在反链上含有该尿嘧啶U;
第(4)为部分双链接头序列,与第(3)中接头不同之处在于,反链上含有某种碱基修饰X,该碱基修饰可以是能够进行酶切的甲基化修饰,或者本身为酶切位点,如位点非常稀少的酶切位点,如归位内切酶如I-Dmol、I-Scel、I-Ceul等;如果X为限制性内切酶的酶切位点,可以生成双链后进行酶切,以去除3’端的部分;
第(5)种为部分双链接头序列,与第(2)种接头序列不同之处在于,正链3’端被封闭,例如碱基修饰或者3’端双脱氧处理,因此不能与5’端形成磷酸二酯键,并且3’端带有类似于第(4)中序列的某种碱基修饰X;另外,3’端也可以是可逆修饰,在此情况下,3’端带有可化学切割的部分,而无需该碱基修饰X。
图2中,X或U并不意味着必须是一个碱基,也可以是多个碱基或一个序 列段。
实施例1
参照图3,本实施例中DNA接头序列为单链序列。
从ssDNA出发,在ssDNA一个末端连接该单链的DNA接头序列。
加入与该DNA接头序列部分特异互补的引物,以与该DNA接头序列形成互补的双链。
在DNA聚合酶的作用下,将ssDNA形成双链DNA(dsDNA)。
纯化后,利用现有的NGS平台,进行建库、测序等操作。
实施例2
参照图4,本实施例中DNA接头序列为部分双链序列,并且3’端为平端。
从ssDNA出发,在ssDNA一个末端连接该部分双链的的DNA接头序列。
由于DNA接头序列带有部分双链模板,可以直接加入DNA聚合酶,在DNA聚合酶的作用下,将ssDNA形成双链DNA(dsDNA)。
纯化后,利用现有的NGS平台,进行建库、测序等操作。
实施例3
参照图5,本实施例中DNA接头序列为部分双链序列,与实施例2不同之处在于,正链3’端缩进。
从ssDNA出发,在ssDNA一个末端连接该部分双链的的DNA接头序列。
由于DNA接头序列带有部分双链模板,可以直接加入DNA聚合酶,在DNA聚合酶的作用下,将ssDNA形成双链DNA(dsDNA)。
纯化后,利用现有的NGS平台,进行建库、测序等操作。
实施例4
参照图6,本实施例中DNA接头序列为部分双链序列,与实施例2不同之处在于,正链3’端突出。
从ssDNA出发,在ssDNA一个末端连接该部分双链的的DNA接头序列。
由于DNA接头序列带有部分双链模板,可以直接加入DNA聚合酶,在DNA聚合酶的作用下,将ssDNA形成双链DNA(dsDNA)。
纯化后,利用现有的NGS平台,进行建库、测序等操作。
实施例5
参照图7,本实施例中DNA接头序列为部分双链序列,与实施例2不同之处在于,正链和反链在3’端形成茎环,并且正链和反链上在靠近3’端的位置含有尿嘧啶U。
从ssDNA出发,在ssDNA一个末端连接该部分双链的的DNA接头序列。
由于正链和反链带有U,因此,需要使用特异性切割尿嘧啶的酶(如NEB公司的USERTM Enzyme)进行处理,去除接头中的茎环。然后加入DNA聚合酶,在DNA聚合酶的作用下,将ssDNA形成双链DNA(dsDNA)。
纯化后,利用现有的NGS平台,进行建库、测序等操作。
实施例6
参照图8,本实施例中DNA接头序列为部分双链序列,与实施例5不同之处在于,反链上在靠近3’端的位置含有甲基化修饰碱基X。
从ssDNA出发,在ssDNA一个末端连接该部分双链的的DNA接头序列。
使用特异性切割甲基化修饰DNA的酶(如MspJI等)进行处理,去除接头中的茎环。然后加入DNA聚合酶,在DNA聚合酶的作用下,将ssDNA形成双链DNA(dsDNA)。
纯化后,利用现有的NGS平台,进行建库、测序等操作。
实施例7
由于对药物安全性的特殊要求,目前寡核苷酸药物过程中,每批次合成的药物均需要进行重复的安全性检测,成本高,花费时间长。本发明可用于合成的寡核苷酸药物的质量检测,具体方法如下:
首先,记录合格批次的寡核苷酸药物中活性核苷酸序列以及可能存在的杂质的含量和种类。
将后续批次合成的寡核苷酸药物粗产品进行纯化,分离出纯化产品和杂质产品;
一般情况下,纯化产品中会不可避免的含有部分杂质,而杂质中也会存在部分目标产物,因此,本发明可以使用纯化产品或者杂质产品作为初始ssDNA待测样品。
按照上述实施例1-6中任意一种方法,进行NGS定量和定性检测,将检测结果与合格批次的结构进行对比,如果二者相符,则该批次合成的寡核苷酸药物 为合格产品,因此可以大大简化不同批次合成药物检测流程和降低检测成本。
通过上述实施例可以看出,本发明具有如下优点:
1)对于ssDNA的序列测定,特别是较短ssDNA的序列测定,目前缺乏很好的技术手段,暂时只有Gansauge等人在2013年发明的用于ssDNA的序列测定的方案;该方案比较适合于较少量的ssDNA的序列测定,而且特别不适合对ssDNA中序列的定量分析。与之相比,本发明只使用一个特定设计的接头,而且在出发ssDNA量可以保证的情况下,无需进行PCR扩增,可以直接进行NGS序列测定,保证了覆盖效率和绝对定量的优势。
2)Gansauge等人在2013年发明的技术方案,目前只适用于Illumina平台,与其它NGS平台匹配的不好,这也限制了该方案的使用范围。但本发明方法可以与目前所有的NGS平台匹配。
以上对本发明的具体实施例进行了详细描述,但其只是作为范例,本发明并不限制于以上描述的具体实施例。对于本领域技术人员而言,任何对本发明进行的等同修改和替代也都在本发明的范畴之中。因此,在不脱离本发明的精神和范围下所作的均等变换和修改,都应涵盖在本发明的范围内。
SEQUENCE LISTING
<110> 王金,赵国屏
<120> 一种检测DNA序列的方法
<140> 201510198849.9
<141> 2015-04-24
<160> 1
<170> PatentIn version 3.3
<210> 1
<211> 18
<212> DNA
<213> Unknown
<220>
<223> 归位内切酶识别和酶切的DNA核心序列
<400> 1
attaccctgt tatcccta 18
- 还没有人留言评论。精彩留言会获得点赞!