用于确定起始样品之特性的方法与流程
本发明涉及用于确定起始样品(startingsample)的特性(property)(例如其中存在的核酸(dna)的量)的方法。
聚合酶链反应(polymerasechainreaction,pcr)是用于扩增dna(允许检测甚至非常少量的dna)的方法。所述方法包括分别确定数量的由以下构成的循环:将反应混合物重复加热并冷却以使其中存在的样品dna(靶dna)解链并酶促复制。在继续进行反应时,在各个前一循环中(或在前面的循环中)产生的dna在各个运行循环中充当dna复制的基质(模板)。这导致dna的指数倍增(扩增),其在理想情况下在每个循环中加倍。
所谓的实时pcr(或定量pcr,qpcr)的特征在于:在运行pcr期间(即实时地)检测pcr产物(dna)的积累。出于此目的,向反应中添加通过dna复制而产生活性的初始无活性的荧光染料。在每个循环中(即“实时地”)测量荧光,并且可从其推断所扩增dna的量。
因此,qpcr可用于确定起始样品中初始存在的dna的拷贝数。该确定遵循以下一般性原则:起始拷贝数越大,越早可检测到pcr产物的显著积累。
监测pcr产物的积累通常基于检测反应混合物在受激发之后发出的且与pcr产物的量成正比的荧光辐射。
pcr技术(并且其中确切地为qpcr)在过去已在医护现场测试(point-of-caretesting)领域中建立,其中诊断检测不是在中心实验室中而是原位(例如在医院、医疗实践或药房中)进行。由于医护现场诊断在一些情况下也由未全面培训的工作人员进行,因此在此需要特别抗噪声的且尽可能客观的检测和评价技术。
由wiesner等(nucl.acidsres.,.20,5863-5864(1992))已知通过采用以下程序来评价聚合酶链反应(pcr)的数据:对于结果数据集的每个图示,其中对于众多循环值(n),为各个循环值(n)分配结果值(y),并随后通过结果值(y)的线性回归以如下形式来确定样品中的初始浓度(c)和扩增效率e:
log(结果值)=log(扩增效率)×循环值+log(初始浓度c)(lognn=logeff·n+logn0,在wiesner的符号中)。特别地,该方法在非常嘈杂的测量信号的情况下不能可靠地工作。
针对所述背景,本发明的目的是提出用于确定起始样品之特性的方法,其至少不再具有上述现有技术的缺点之一,或者其至少提出不同于现有技术的用于确定起始样品之特性的方法。
本发明从以下基本概念出发:为了确定起始样品之特性,从结果数据集确定数据集是必要的,并且数据集(特别是数据集的最后循环值)的确定具有特别的重要性,因为采用范围太宽或太窄的数据集只能不可靠地进行特性的确定。在该情况下,在众多(amultiplicityof)循环值的结果数据集中,为各个循环值分配结果值,并且在多个(apluralityof)循环值的数据集中,为各个循环值分配结果值,结果数据集中包括的所述众多循环值多于数据集中包括的所述多个循环值。
同样地,本发明从以下发现出发:当确定起始样品之特性时,必须考虑结果值中包括的测量误差。为此,本发明的一个实施方案提供了使用曲线拟合来由数据集计算将结果值表示为循环值之函数的函数的参数,所述函数包含其中初始值(c)作为参数并且其中循环值作为指数(n)的指数项,根据本发明已经认识到,所述函数具有与指数项相加的系统项。根据所述实施方案,在本发明中推断,可基于在曲线拟合中求出的初始值(c)参数来确定待确定的特性。
因此,本发明不同于wiesner等(nucl.acidsres.,.20,5863-5864(1992))的程序方法,尽管其仅认识到可由函数lognn=logeff·n+logn0(即将结果值(nn)表示为循环值(n)之函数的函数的对数)来表示数据集,所述函数在对数化之前包括其中初始值(n0)作为参数并且其中循环值(n)作为指数的指数项。然而,所述程序方法完全忽略了由用于产生数据集的系统产生的影响,并且因此不适于尽可能自动地使用。这样的在很大程度上自动化的且因而可靠的方法恰好是基于pcr的医护现场诊断所期望的。
根据本发明,已经认识到,用于产生数据集的系统的影响最好由与指数项相加的系统项来表示。只要在曲线拟合中联合考虑系统的影响和指数增长,就可以基于其可以可靠地输出待确定的特性来可靠地生成初始值(c)的值。
根据本发明的方法使用其中为多个循环值中的各个循环值分配结果值的数据集。优选地,在该情况下考虑其中多个循环值为自然数序列(特别是在以下情况下的自然数序列)的数据集:在自然数的连续中,一个自然数接着下一个自然数作为下一个循环值(例如“1,2,3,4,5,...”或“3,4,5,6,7,8,...”)。
在本发明的大多数应用中并且因此根据一个优选实施方案,数据集由一系列包含循环值和分别地分配给该循环值的结果值的数值对组成,对此,数据集中数值对的序列由记录用于产生结果值的所测量值的顺序生成。在一个特别优选的实施方案中,在序列中分别地接着第一数值对作为下一个的第二数值对为由在生成该第一数值对记录的所测量值之后下一个记录的所测量值生成的数值对。
在qpcr的情况下,结果值优选为在各个循环结束时测量的荧光强度y。所述荧光强度通常以任意单位无量纲表示。
根据本发明的方法对数据集进行曲线拟合。曲线拟合有时还称为平差计算、补偿、参数评估、匹配、回归或拟合。在一个优选实施方案中,使用最小二乘法作为曲线拟合。
根据本发明的方法,对数据集进行曲线拟合以使用数据集的数据来确定将结果值表示为循环值之函数的函数的参数,所述函数包括其中初始值(c)作为参数且其中循环值作为指数的指数项,并且所述函数具有与指数项相加的系统项。所述函数还可如下表示:
f(n)=a+cen,
f(n)为通过该函数计算的与涉及各个循环值(n)的结果值相关的值,a为系统项,并且cen为其中初始值(c)作为参数且其中循环值(n)作为指数的指数项。在一个优选实施方案中,指数项的参数e可以是扩增效率的测量结果(measure)。
在一个优选实施方案中,系统项a可由a=a+b·n关系式表示。在该情况下,参数(a)可理解为产生结果值中的背景噪声的平均值的测量结果。在一个优选实施方案中,参数(b)可用于描述所产生的结果值相对于开始变得更小或更大的效应。
在一个优选实施方案中,因此对数据集进行曲线拟合以使用数据集的数据来确定至少包括项a+b·n+cen的函数的参数。特别优选的是目的为使用数据集的数据来确定可由a+b·n+cen表示之函数的参数的数据集的曲线拟合。
在一个优选实施方案中,在一个优选实施方案中被选择为线性项(a+b·n)的项a可由另外项补充以例如形成n次多项式。由此,可在曲线拟合的过程中更准确地确定目标参数(c)。
在曲线拟合中求出的初始值(c)参数可直接表示待确定的特性。在一个优选实施方案中,为了输出待确定的特性,使在曲线拟合中求出的初始值(c)参数乘以系统特定因子s。如果例如靶向样品的初始dna量(qe)作为待确定的特性,则可使用式qe=s*c来确定所述量。系统特定因子s可借助初始dna量已知的参考样品容易地确定,并使用根据本发明的方法进行以借助由此确定的参数c和参考样品的已知初始dna量(qe)使用式qe/c=s来确定因子s。因子s还可用于以期望的单位表示参数,例如在pcr中,初始样品中dna的量可无量纲表示为拷贝数或浓度,例如g/l或mol/l。
在一个作为替代的实施方案中,起始样品之特性基于进一步的计算来获得。在已以上述方式确定系统项a之后,可通过从数据集中的每个结果值减去适用于该结果值之循环值的系统项a的值来创建经修饰的数据集。如果求出的系统项a是常数,则从数据集的每个结果值减去该常数以创建经修饰的数据集。如果系统项a是循环值的函数,例如如果a=a+b·n,则对于每个结果值,从结果值减去适用于与该结果值相对应的循环值的系统项a以创建为经修饰数据集的一部分的经修饰结果值。如果对经修饰的数据集作图,则与如果对数据集作图相比,绘制的点更加接近光滑的指数曲线,因为经修饰数据集中的数据已不受来源于系统的任何不确定性的影响。该指数曲线可表示为f(n)=cen。
在该作为替代的实施方案中,可通过对经修饰数据集的一部分进行曲线拟合(例如曲线拟合)成表达式f(n)=cen来确定初始值(c)。或者,可由经修饰的数据集创建对数数据集。为了创建对数数据集,对每个经修饰的结果值取对数以生成对数结果值。例如,可采用自然对数或底数为2的对数或底数为10的对数或任何其他合适底数的对数。对数数据集的一部分的图示近似为直线(ln(cen)=n·ln(e)+ln(c))。在进行将对数结果值曲线拟合成表达式n·ln(e)+ln(c))中,可由与纵坐标的交点求出初始值(c)。
在该作为替代的实施方案中,为了曲线拟合最佳拟合对数数据集的直线,可使用最小二乘法。在一个可能的实施方案中,对于预设数量的连续值,例如对于四个连续值,可对这些值进行直线的曲线拟。可确定从点到拟合的直线的标准偏差。在这样的方法中,选择提供最小标准偏差的连续值集和对该数值集拟合的线。由该线与纵坐标的交点取得初始值(c)。为了进一步增强所得初始值的质量,可另外地要求该线仅对在上文中讨论的方法中计算的参数e均介于预定值emin与预定值emax之间的那些连续值拟合。这样,清楚地,仅对来自指数期的数值进行曲线拟合。另外(为了验证结果)或作为确定标准偏差的替代方案,对于已考虑的所有连续值集和由其生成的所有直线集,选择具有最大倾斜度的直线。由该线与纵坐标的交点取得初始值(c)。为了进一步增强所得初始值的质量,可另外地要求该线仅对在上文中讨论的方法计算的参数e均介于预定值emin与预定值emax之间的那些连续值拟合并且提供低于预定值的标准偏差。这样,清楚地,仅对来自指数期的数值进行曲线拟合。
在pcr方法中,在一个循环期间,在系统中加热含有dna的反应混合物(样品)。典型的适用于pcr的系统是本领域技术人员公知的,一个实例为所谓的热循环仪。由于被加热至特定值,dna的双链解链。为了后续能够使反应混合物中存在的引物与单链杂交(退火),将样品冷却至适用于此的温度。这通常由系统自动进行。随后,通过反应混合物中存在的聚合酶延伸引物(dna复制)。出于此目的,还可通过系统将反应混合物调至合适的温度。这产生新的双链(扩增)。至此循环终止。随着系统的重新加热以使dna解链开始新的循环。
在实时pcr(qpcr)中,向反应混合物添加通过荧光信号来指示dna扩增的试剂。所述荧光信号可用作例如循环的结果值。可能的试剂是本领域技术人员熟悉的,一个实例为sybr绿,其嵌入经扩增的并且因此随后双链的dna中,并随后发荧光。然而,例如还可向反应混合物添加猝灭剂,其首先猝灭荧光并且在扩增之后被移除。只有这样,才可检测荧光。另一个实例为可用于产生荧光信号的水解探针。
因此,pcr方法可用于产生其中为众多循环值中的各个循环值分配结果值的结果数据集。在一个优选实施方案中,用于根据本发明的方法的数据集由结果数据集生成。因此,结果数据集中包括的众多循环值多于数据集中包括的多个循环值。在一个优选实施方案中,数据集的循环值序列为结果数据集的循环值序列的子群。
在一个实施方案中,根据本发明的方法提供了,数据集的循环值序列为结果数据集的循环值序列的子群,并且数据集的循环值序列的最后结果值如下确定:从结果数据集的起始循环值开始多个连续的三循环值序列,三个循环值根据其在结果数据集中的先后顺序在各个考虑的序列中分别表示为第一循环值、第二循环值和第三循环值,在以下情况下确定序列:
-分配给所考虑序列之第二循环值的结果值大于分配给所考虑序列之第一循环值的结果值,并且
-曲率值(z)为给所考虑序列中的最高值,所述曲率值(z)由分配给所考虑序列之第一循环值的结果值与分配给所考虑序列之第三循环值的结果值之和并减去分配给所考虑序列之第二循环值的结果值的2倍得到,
满足所述要求的序列的第二循环值用作数据集的最后循环值。
在本发明的多个应用领域中,预期结果值随着循环值的提高呈指数提高(至少对于循环值的子群)。已认识到,如果待评价的数据集仅包括直到(并且包括)从其开始结果值不再指数提高而是结果值的轮廓变平的循环值的循环值(和为其分配的结果值),则可特别良好地确定起始样品之特性。在该情况下,应试图特别准确地确定所述最后循环值。特别地,如果借助数据集来进行曲线拟合以确定所靶向特性,则再添加甚至一个循环值(和添加为其分配的结果值)可导致在曲线拟合中确定的参数显著变化。在此情况下已认识到,可通过权利要求1所述的方法来特别可靠地确定数据集的最后循环值。
在其中确定曲率值(z)的优选实施方案中,在一个甚至更优选的实施方案中可在曲率值(z)变为0时停止搜寻序列,或者作为替选地在曲率值(z)变为负值时停止搜寻序列。在其中曲率值(z)变为0或变为负值的情况下,先前为指数性的曲线的曲率已经变成平直的曲线。这可省去不得不进行更多的循环,并且因此可缩短确定初始值所需的时间。
根据本发明的方法可想到的是,对于结果数据集的随后也变为数据集的初始循环值的初始循环值,使用第一结果值,即,例如当对起始样品首次进行根据pcr方法的循环时确定的扩增的所测量值。然而,还可设想在使用结果数据集的后一循环值作为数据集的初始循环值的情况下的实施方案。该程序允许在确定结果值中排除可出现(尤其是可在对起始样品进行的pcr方法的第一循环中出现)的初始不准确性。例如,可使用第三循环作为数据集的初始循环。
在一个优选实施方案中,可预先确定最大循环值(nr)。所述最大循环值可用于检查在由结果数据集准备数据集中是否出现错误。例如,如果已达到预定的最大循环值而曲率值(z)没有变为0或负值,则可生成错误信息。例如,可选择数40作为最大循环值。
此外,可固定循环值的最小数。这也可用于检查在由结果数据集准备数据集中是否出现错误。如果确定数据集包括比最小循环值更小的循环值,则在根据本发明方法的一个优选实施方案中可向操作者生成建议。
在一个优选实施方案中,可对式中再现的参数e固定最小值emin。如果出现在曲线拟合中对参数e确定低于值emin的值,则可输出警告。
在一个优选实施方案中,可对式中再现的参数e固定最大值emax。如果出现在曲线拟合中对参数e确定高于值emax的值,则可输出警告。
在一个优选实施方案中,可固定最小结果值差δymax。如果数据集之最后循环值的结果值与数据集之初始循环值的结果值之差小于所述最小结果值差δymax,则可输出警告。
在一个优选实施方案中,当待确定的初始值(c)参数小于0时,可输出警告。
根据本发明的方法可用于评价其中可通过信号(特别是通过荧光信号)来追踪反应混合物中存在的dna的扩增的任何期望形式的pcr。唯一推断是生成具有众多循环值的结果数据集,其中可为各个循环值分配结果值。在该情况下,起始样品可以是dna,或使用本领域技术人员熟悉的方法后续转录成相应dna的其他形式的核酸(例如rna)。该形式的一个实例为使用可通过逆转录酶转录成dna并且随后通过实时pcr量化的rna。实时pcr产生根据本发明的方法所需的结果数据集。
根据本发明的方法特别适用于医护现场系统(point-of-caresystem)中需利用的pcr系统。准确地,考虑到系统的特殊性,由本发明可给出的更好拟合和由本发明确定的所测量值分布的更好表示以与操作者的资格无关的方式提高用医护现场系统进行的评价的可靠性。
在下文中借助附图更详细地解释本发明,附图仅示出了本发明的一个示例性实施方案。在附图中:
图1示出了表示结果数据集和其参数通过对由该结果数据集生成的数据集进行曲线拟合来确定的函数的图,以及
图2示出了表示对数结果数据集和对对数数据集的四个连续值拟合的直线的图。
图1中所示的图为结果数据集的图示。该结果数据集包括众多循环值,具体地自然数1至40的序列。该图示出了该结果数据集的分配给各个循环值的结果值。结果值为在各个循环结束时确定的荧光强度y。
由该结果数据集生成其中为多个循环值中的各个循环值分配结果值的数据集。该数据集的循环值序列为结果数据集的循环值序列的子群。作为初始循环值,数据集合包括循环值1,并且作为最后的循环值,数据集包括循环值24(n=24)。
数据集的循环值序列的最后循环值如下确定:从结果数据集的起始循环值(n=1)开始多个连续的三循环值序列(n=1,2,3;n=2,3,4;n=3,4,5;n=4,5,6;等),三个循环值根据其在结果数据集中的先后顺序在各个考虑的序列(例如,n=4,5,6)中分别表示为第一循环值(作为一个实例n=4)、第二循环值(在该实例中n=5)和第三循环值(在该实例中n=6),在以下情况下确定序列:
-分配给所考虑序列之第二循环值的结果值大于分配给所考虑序列之第一循环值的结果值,并且
-曲率值z为所考虑序列中的最高值,所述曲率值z由分配给所考虑序列之第一循环值的结果值与分配给所考虑序列之第三循环值的结果值之和并减去分配给该所考虑序列之第二循环值的结果值的2倍得到。
满足所述要求的序列的第二循环值用作数据集的最后循环值,在此循环值n=24。
图1还包括函数的图示。该函数为:
f(n)=a+bn+cen=a(n)+cen。
该函数的参数(a)、(b)、(c)、e在对数据集进行曲线拟合的过程中实现。在该情况下,该图中再现的参数(左上)以同样方式确定。
待确定的特性(特别是起始样品中分子的摩尔量),可由由此确定初始值c的参数2.611e-07确定。
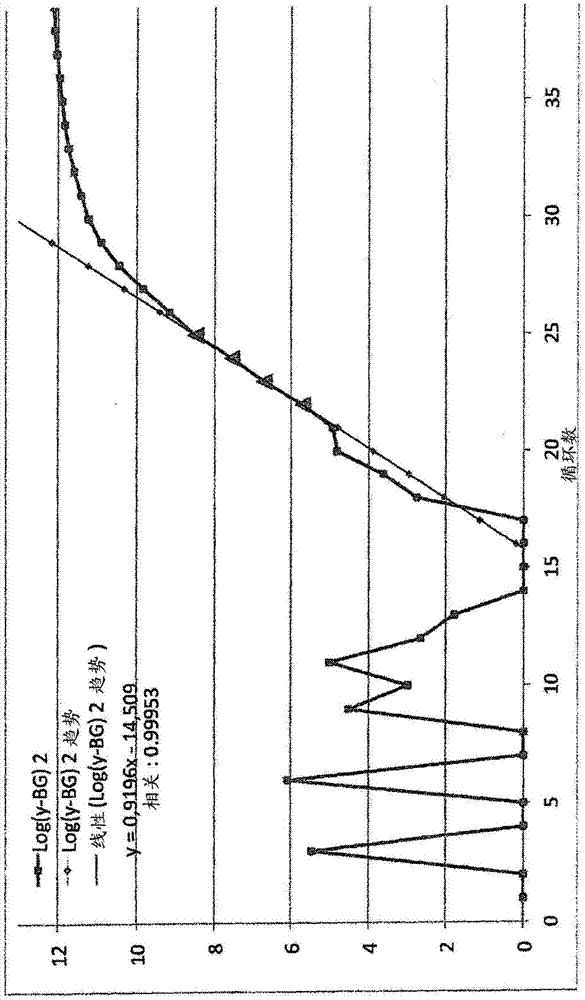
图2示出了对数数据集的图示。在已以上述方式确定系统项a(n)之后,通过从数据集中的每个结果值减去适用于该结果值之循环值的系统项a(n)的值来创建经修饰的数据集。由经修饰的数据集,通过对每个经修饰的结果值取底数为2的对数来创建对数数据集。如从图2可以看出,对数数据集的一部分的图示近似为直线(ln(cen)=n·ln(e)+ln(c)),而另一些部分示出了可变值。在对这些部分进行将对数结果值曲线拟合成表达式n·ln(e)+ln(c)时,可由与纵坐标的交点求出初始值(c)。
在该作为替代的实施方案中,为了曲线拟合成最佳拟合对数数据集的直线,使用最小二乘法。在一个可能的实施方案中,对于四个连续值,可对这些值进行直线的曲线拟合。可确定从点到拟合的直线的标准偏差。在这样的方法中,选择提供最小标准偏差的连续值集和对该数值集拟合的线。由该线与纵坐标的交点取得初始值(c)。如从图2可以看出,对于第一循环值,四个连续值的对数结果值仅可拟合成具有大标准偏差的直线。然而,在对数数据集的图示中,存在可见于图1中的对应于指数期的特征性数值系列。在该特征性数值系列中,图2中的值可接近于直线。为了确定值(c),选择对其拟合具有最小标准偏差的直线的四个值的系列,并且由该直线与纵坐标的交点取得值(c)。
另外(为了验证结果)或作为确定标准偏差的替代方案,对于已考虑的所有连续值集和由其创建的所有直线集,选择具有最大倾斜度的直线。为了进一步增强质量,要求线仅倾斜于在上文中讨论的方法计算的参数e均介于预定emin与预定emax之间的那些连续值并且提供低于预定值的标准偏差。由该线与纵坐标的交点取得初始值(c)。
- 还没有人留言评论。精彩留言会获得点赞!