分子标志物STAC2在口腔鳞状细胞癌中的应用的制作方法
本发明属于生物医药领域,涉及分子标志物STAC2在口腔鳞状细胞癌中的应用。
背景技术:
口腔鳞状细胞癌(oral squamous cell carcinoma,OSCC)是口腔颌面外科较常见的恶性肿瘤,其发病率、致死率均位于口腔颌面部的恶性肿瘤中位居首位。因其恶性程度较高,且易发生淋巴结转移,因此预后较差,并且术后也经常会继发颌面部的畸形,在临床上对于医生制定治疗方案造成很大难度,更重要的是对患者的生存质量造成极大的影响。在我国,鳞癌多发生于40-60岁的成人,男性多于女性部位以舌、颊、牙龈、腭、上颌窦为常见。鳞癌常向区域淋巴结转移,晚期可发生远处转移。
肿瘤是一种分子水平的疾病,从基因蛋白水平进行肿瘤的研究是最终途径。分子靶向治疗始于20世纪末,它指在细胞分子水平上,针对已明确的致癌位点设计相应的治疗药物,药物特异地与致癌位点相结合,使肿瘤细胞死亡,而不损伤正常的组织细胞。分子靶向治疗调控肿瘤相关基因、干预肿瘤异常的信号通路或阻断其能量通路,具有高特异性、低毒性和高治疗指数等特点。寻找可干预的分子靶点其实就是寻找肿瘤细胞与正常细胞在生物化学、分子间的差异,包括数量和活性的差异。这些靶点包括生长因子及其受体、癌基因、抑癌基因、肿瘤血管生成因子、端粒及端粒酶、蛋白激酶、DNA拓扑异构酶、法尼基蛋白转移酶、组蛋白去乙酸化酶、DNA引物酶、泛素化途径调控因子等。
目前口腔鳞状细胞癌的发病机制尚不完全清楚,临床上也并没有用于口腔鳞状细胞癌诊治的有效的分子标志物,寻找新的分子标志物对于口腔鳞状细胞癌的机制研究以及临床应用都具有重要的意义。
技术实现要素:
为了弥补现有技术的不足,本发明的目的在于提供一种口腔鳞状细胞癌的生物标志物,灵敏和特异性的实现口腔鳞状细胞癌的诊断和治疗。
为了实现上述目的,本发明采用如下技术方案:
本发明提供了分子标志物在制备诊断口腔鳞状细胞癌的产品中的应用,所述分子标志物为STAC2。
进一步,所述产品通过测定样本中STAC2基因或其同源物的变化进行诊断。
其中,STAC2基因或其同源物的变化可以通过芯片、印迹法、RT-PCR、实时定量PCR、FISH法、CGH法或阵列CGH法、亚硫酸氢盐测序法、COBRA法进行测定。印迹法包括Northern、Southern、Western印迹法。Southern印迹法是将从样本得到的基因组DNA分离并固定,通过检测DNA与STAC2基因的杂交来测定样本中的STAC2基因;Northern印迹法是一种将由样本中获得的mRNA分离、固定,通过检测mRNA与STAC2基因的杂交来检测该基因的mRNA;Western印迹法是一种将样本中的蛋白分离、固定,通过检测抗体与STAC2蛋白的免疫反应来分析基因的表达程度。
本发明提供了一种诊断口腔鳞状细胞癌的产品,所述产品能够通过检测样本中STAC2基因的表达水平来诊断口腔鳞状细胞癌。
进一步,所述产品包括芯片、试剂盒或制剂。其中,所述芯片包括基因芯片、蛋白质芯片;所述基因芯片包括固相载体以及固定在固相载体的寡核苷酸探针,所述寡核苷酸探针包括用于检测STAC2基因转录水平的针对STAC2基因的寡核苷酸探针;所述蛋白质芯片包括固相载体以及固定在固相载体的STAC2蛋白的特异性抗体;所述试剂盒包括基因检测试剂盒和蛋白免疫检测试剂盒;所述基因检测试剂盒包括用于检测STAC2基因转录水平的试剂;所述蛋白免疫检测试剂盒包括STAC2蛋白的特异性抗体。
本发明提供了STAC2基因在制备治疗口腔鳞状细胞癌的药物组合物中的应用。
进一步,所述药物组合物包括STAC2基因和/或其表达产物的抑制剂。所述抑制剂包括抑制STAC2基因表达的物质、抑制STAC2基因表达产物稳定性的物质、和/或抑制STAC2基因表达产物活性的物质。
进一步,所述抑制剂包括针对STAC2基因的siRNA、shRNA、反义寡核苷酸和/或针对STAC2蛋白的抗体、配体。优选的,所述抑制剂为siRNA。
本发明还提供了一种治疗口腔鳞状细胞癌的药物组合物,所述药物组合物包含上面所述的STAC2的抑制剂。
本发明提供了一种组合药物,所述组合药物包括上述的药物组合物、和含抗肿瘤剂的药物组合物。
进一步,抗肿瘤剂的药物组合物包括但不限于免疫治疗剂如西妥昔单克隆抗体,化学治疗剂或化学放射性治疗剂如卡波铂或者是一种相关类别的铂类药物、紫杉烷或者是一种类别的紫衫烷,或者是两者。
本发明还提供了一种抑制细胞增殖的方法,所述方法是将针对STAC2基因的siRNA、shRNA、反义寡核苷酸或功能缺失型基因在体外导入到肿瘤细胞中。
本发明的优点和有益效果:
本发明首次发现了与口腔鳞状细胞癌发生发展相关的生物标志物—STAC2,通过检测受试者STAC2的变化,来实现口腔鳞状细胞癌的早期诊断。
本发明提供了治疗口腔鳞状细胞癌的分子靶标,通过靶向于分子标志物来治疗疾病具有敏感性和特异性。
本发明对口腔鳞状细胞癌的机制研究提供了一定的理论基础。
附图说明
图1显示利用QPCR检测STAC2基因在口腔鳞状细胞癌组织中的表达情况;
图2显示利用QPCR检测STAC2基因在口腔鳞状细胞癌细胞中的表达情况;
图3显示利用QPCR检测siRNA对STAC2基因表达的影响;
图4显示MTT法检测STAC2对口腔鳞状细胞癌细胞增殖活性的影响;
图5显示利用transwell小室检测STAC2基因对口腔鳞状细胞癌细胞侵袭的影响。
具体的实施方式
本发明首次发现了STAC2与口腔鳞状细胞癌的发生发展相关,并验证了STAC2在口腔鳞状细胞癌中高表达。STAC2可作为口腔鳞状细胞癌的独立预测因子,也可以和其他的基因标志物联合应用。
本发明中术语“生物标志物”是其在组织或细胞中的表达水平与正常或健康细胞或组织的表达水平相比发生改变的任何基因或蛋白。
本领域技术人员将认识到,本发明的实用性并不局限于对本发明的标志物基因的任何特定变体的基因表达进行定量。作为非限制性的实例,标志物基因可具有SEQ ID NO.1或SEQ ID NO.2指定的编码序列或氨基酸序列。在一些实施方案中,其具有与所列的序列至少85%相同或相似的cDNA序列或氨基酸序列,诸如上述所列的序列至少90%、91%、92%、93%、94%、95%、96%、97%、98%或至少99%相同或相似的cDNA序列或氨基酸序列。
本文所述的生物标志物包括基因和蛋白。此类生物标志物包括含有编码生物标志物的核酸序列或此序列的互补序列的完整或部分序列的DNA。生物标志物核酸还包括含有所关注的任何核酸序列的完整或部分序列的RNA。生物标志物蛋白是由本发明的DNA生物标志物编码的或对应于本发明的DNA生物标志物的蛋白。生物标志物蛋白包含任何生物标志物蛋白或多肽的完整或部分氨基酸序列。生物标志物基因和蛋白的片段和变体也包括在本发明的范围内。
所谓“片段”是指多核苷酸的一部分或氨基酸序列并因而编码的蛋白的一部分。为生物标志物核苷酸序列的片段的多核苷酸通常包含至少10、15、20、50、75、100、150、200、250、300、350、400、450、500、550、600、650、700、800、900、1,000、1,100、1,200、1,300或1,400个连续的核苷酸,或最多存在于本文所公开的全长生物标志物多核苷酸中的核苷酸个数。生物标志物多核苷酸的片段将通常编码至少15、25、30、50、100、150、200或250个连续氨基酸,或存在于本发明的全长生物标志物蛋白中的氨基酸的总数。
“变体”旨在表示基本上相似的序列。一般来讲,本发明的特定生物标志物的变体将具有通过序列比对程序测定的与所述生物标志物至少约40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更高的序列同一性。
本发明可以利用本领域内已知的任何方法测定基因表达。本领域技术人员应当理解,测定基因表达的手段不是本发明的重要方面。可以在转录或翻译(即蛋白)水平上检测生物标志物的表达水平。
在一些实施方案中,在转录水平上检测生物标志物的表达水平。利用核酸杂交技术进行具体DNA和RNA测量的多种方法是本领域技术人员已知的。一些方法涉及电泳分离(例如,用于检测DNA的Southern印迹和用于检测RNA的Northern印迹),但是也可以在不利用电泳分离的情况下进行DNA和RNA的测量(例如,通过斑点印迹)。基因组DNA(例如,来自人)的Southern印迹可用于筛选限制性片段长度多态性(RFLP),以检测影响本发明多肽的遗传病症的存在。可以检测所有形式的RNA,包括但不限于信使RNA(mRNA)、微RNA(miRNA)、核糖体RNA(rRNA)和转运RNA(tRNA)。
本发明中术语“探针”指能与另一分子的特定序列或亚序列或其它部分结合的分子。除非另有指出,“探针”通常指能通过互补碱基配对与另一多核苷酸(往往称为“靶多核苷酸”)结合的多核苷酸探针。根据杂交条件的严谨性,探针能和与该探针缺乏完全序列互补性的靶多核苷酸结合。探针可作直接或间接的标记,其范围包括引物。杂交方式,包括,但不限于:溶液相、固相、混合相或原位杂交测定法。
作为探针,可以使用荧光标记、放射标记、生物素标记等对癌检测用多核苷酸进行了标记的标记探针。多核苷酸的标记方法本身是公知的。可通过如下方法检查试样中是否存在受试核酸:固定受试核酸或者其扩增物,与标记探针进行杂交,洗涤,以及然后测定与固相结合的标记。备选地,还可固定癌检测用多核苷酸,使受试核酸与其杂交,然后应用标记探针等检测结合于固相上的受试核酸。在这种情况下,结合于固相上的癌检测用多核苷酸也称为探针。使用多核苷酸探针测定受试核酸的方法在本领域也是公知的。可以如下进行该方法:在缓冲液中使多核苷酸探针与受试核酸在Tm或者其附近(优选在±4℃以内)接触用于杂交,洗涤,然后测定杂交的标记探针或者与固相探针结合的模板核酸。
在作为探针使用的多核苷酸的大小优选为18个或更多个核苷酸、更优选为20个或更多个核苷酸,以及编码区域的全长或更少。作为引物使用时,该多核苷酸大小优选为18个或更多个核苷酸,以及50个或更少核苷酸。
术语“芯片”也称为“阵列”,指包含连接的核酸或肽探针的固体支持物。阵列通常包含按照不同的已知位置连接至基底表面的多种不同的核酸或肽探针。这些阵列,也称为“微阵列”,通常可以利用机械合成方法或光引导合成方法来产生这些阵列,所述光引导合成方法合并了光刻方法和固相合成方法的组合。阵列可以包含平坦的表面,或者可以是珠子、凝胶、聚合物表面、诸如光纤的纤维、玻璃或任何其它合适的基底上的核酸或肽。可以以一定的方式来包装阵列,从而允许进行全功能装置的诊断或其它方式的操纵。
本发明中使用的针对上述STAC2蛋白质的抗体只要能够发挥抗肿瘤活性就可以是任何种类的抗体,包含例如,单克隆抗体、多克隆抗体、重组抗体、例如合成抗体、多特异性抗体(例如双特异性抗体、三特异性抗体等)、人源化抗体、嵌合抗体、单链抗体(scFv)等人抗体,它们的抗体片段、例如Fab、F(ab’)2、Fv等。这些抗体及其片段还可以通过本领域技术人员公知的方法制备。在本发明中,期望是能够与STAC2蛋白质特异性地结合的抗体,优选是单克隆抗体,但只要能够稳定地生产均质的抗体,则也可以是多克隆抗体。另外,在受试者是人的情况下,为了避免或抑制排斥反应,优选为人抗体或人源化抗体。
制作了嵌合抗体或人源化抗体之后,可以将可变区(例如,FR)和/或恒定区中的氨基酸用其他氨基酸替换等。氨基酸的替换例如是小于15个、小于10个、8个以下、7个以下、6个以下、5个以下、4个以下、3个以下、或2个以下的氨基酸、优选1~5个氨基酸、更优选1或2个氨基酸的替换,替换抗体应与未替换抗体在功能上等同。
STAC2蛋白质的片段具有从作为抗体所识别的最小单位的表位(抗原决定簇)的氨基酸长到小于该蛋白质的全长的长度。表位是指在哺乳动物、优选人中具有抗原性或免疫原性的肽片段,其最小单位由约7~12个氨基酸、例如8~11个氨基酸组成。
在本发明中,所述用RT-PCR诊断口腔鳞状细胞癌的产品至少包括一对特异扩增STAC2基因的引物;所述用实时定量PCR诊断口腔鳞状细胞癌的产品至少包括一对特异扩增STAC2基因的引物。在一些实施方案中,所述用实时定量PCR诊断管鳞癌的产品至少包括的一对特异扩增STAC2基因的引物序列如SEQ ID NO.3和SEQ ID NO.4所示。
本发明中的基因芯片或基因检测试剂盒还可用于检测包括STAC2基因在内的多个基因(例如,与口腔鳞状细胞癌相关的多个基因)的表达水平。所述蛋白芯片或蛋白免疫检测试剂盒可用于检测包括STAC2蛋白在内的多个蛋白质(例如与口腔鳞状细胞癌相关的多个蛋白质)的表达水平。将口腔鳞状细胞癌的多个标志物同时进行检测,可大大提高口腔鳞状细胞癌诊断的准确率。
本发明术语siRNA是一种小RNA分子(21-25核苷酸),由Dicer(RNAaseⅢ家族中对双链RNA具有特异性的酶)加工而成,它是siRISC的主要成员,激发与之互补的目标mRNA的沉默。siRNA的制备可采用多种方法,比如:化学合成法、体外转录、酶切长链dsRNA、载体表达siRNA、PCR合成siRNA表达元件等,这些方法的出现为研究者提供了可选择的空间,可以更好地获得基因沉默效率。
作为该siRNA分子的一种表达形式,可将其制备成DNA表达框形式,比如:U6启动子-siRNA转录模板-H1启动子。在本发明中,可将siRNA分子、表达siRNA分子的DNA表达框、或者包含siRNA分子表达框的质粒作为药物直接给药于受药者身上特定部位,比如肿瘤组织。
在一些实施方案中,siRNA分子采用化学法合成的。在具体的实施方案中,合成的siRNA分子的序列如SEQ ID NO.9和SEQ ID NO.10所示。
本发明中的药物组合物还包括药学上可接受的载体,这类载体包括(但并不限于):稀释剂、赋形剂如乳糖、氯化钠、葡萄糖、尿素、淀粉、水等、填充剂如淀粉、蔗糖等;粘合剂如单糖浆、葡萄糖溶液、淀粉溶液、纤维素衍生物、藻酸盐、明胶和聚乙烯吡咯烷酮;湿润剂如甘油;崩解剂如干淀粉、海藻酸钠、海带多糖粉末、琼脂粉末、碳酸钙和碳酸氢钠;吸收促进剂季铵化合物、十二烷基硫酸钠等;表面活性剂如聚氧化乙烯山梨聚糖脂肪酸酯、十二烷基硫酸钠、硬脂酸单甘油酯、十六烷醇等;致湿剂如甘油、淀粉等;吸附载体如淀粉、乳糖、斑脱土、硅胶、高岭土和皂粘土等;润滑剂如滑石粉、硬脂酸钙和镁、聚乙二醇、硼酸粉末等。
本发明的药物组合物可以使用不同的添加剂进行制备,例如缓冲剂、稳定剂、抑菌剂、等渗剂、螯合剂、pH控制剂及表面活性剂。本发明的药物还可包括药学上可接受的涂层材料包括(但不限于),快速分解涂层材料、染色剂、肠溶性聚合物、增塑剂、水溶性聚合物、水不溶性聚合物、染料、色素、其他崩散剂。
本发明的药物还可与其他治疗口腔鳞状细胞癌的药物联用,其他治疗性化合物可以与主要的活性成分同时给药,甚至在同一组合物中同时给药。还可以以单独的组合物或与主要的活性成分不同的剂量形式单独给予其它治疗性化合物。主要成分的部分剂量可以与其它治疗性化合物同时给药,而其它剂量可以单独给药。在治疗过程中,可以根据症状的严重程度、复发的频率和治疗方案的生理应答,调整本发明药物组合物的剂量。
本发明的药物的剂型可以为多种形式,可以配制成软膏、乳膏剂、混悬剂、洗剂、散剂、溶液剂、糊剂、凝胶剂、喷雾剂、气雾剂或油剂等,只要适合于相应疾病的给药、并且恰当地保持STAC2基因或其表达产物的抑制剂分子的活性。比如,对于注射用给药系统,剂型可以是冻干粉。
本发明所述的药物组合物也可以脂质体输送系统形式给药,如小单层囊泡、大单层囊泡和多层囊泡。脂质体可有多种磷脂形成,如胆甾醇、硬脂基胺或磷脂酰胆碱。
本发明所述携带基因的载体是本领域已知的各种载体,如市售的载体、包括质粒、粘粒、噬菌体、病毒等。表达载体向宿主细胞中的导入可以使用电穿孔法、磷酸钙法、脂质体法、DEAE葡聚糖法、显微注射、病毒感染、脂质体转染、与细胞膜透过性肽的结合等周知的方法。
本发明中术语“治疗”是指改善与疾病或病症例如实体癌相关的症状,包括阻止或延迟疾病症状的发作和/或减少疾病或病症的严重度或频率。
本发明中术语“抑制细胞增殖”是指杀死细胞或永久性地或临时性地阻止或减缓细胞的生长。如果在施用基因产物或表达产物的抑制剂后,受试者中癌细胞的数目保持恒定或减少,那么可推断此类细胞的增殖被抑制。如果癌细胞的绝对数目增加但肿瘤生长速率减小也可推断癌细胞的增殖被抑制。
本发明中术语“样本”包括细胞、组织、脏器、脑脊液、体液(血液、淋巴液等)、消化液、咳痰、肺胞支气管清洗液、尿、粪便等。在一些实施方案中,所述样本为组织、血液。
在本发明中,生物标志物的“高表达”或“过表达”或“表达上调”是指生物标志物的表达高出10%、20%、30%、40%、50%、60%、70%、80%、90%、100%、200%、300%、400%、500%或更多。
下面结合附图和实施例对本发明作进一步详细的说明。以下实施例仅用于说明本发明而不用于限制本发明的范围。实施例中未注明具体条件的实验方法,通常按照常规条件,例如Sambrook等人,分子克隆:实验室手册(New York:Cold Spring HarborLaboratory Press,1989)中所述的条件,或按照制造厂商所建议的条件。
实施例1 筛选与口腔鳞状细胞癌相关的基因标志物
1、样品收集
各收集6例周围正常粘膜组织和口腔鳞状细胞癌组织,均经病理学诊断证实,所有患者术前未接受任何形式的治疗。手术切下的样本于液氮中冻存,患者均知情同意,上述所有标本的取得均通过组织伦理委员会的同意。
2、RNA样品的制备(利用QIAGEN的组织RNA提取试剂盒进行操作)
取出冻存于液氮中的组织样本,把组织样本放入已预冷的研钵中进行研磨,按照试剂盒中的说明书提取分离RNA。具体如下:
1)加入Trizol,室温放置5min;
2)加入氯仿0.2ml,用力振荡离心管,充分混匀,室温下放置5-10min;
3)12000rpm离心15min,将上层水相移到另一新的离心管中(注意不要吸到两层水相之间的蛋白物质),加入等体积的-20℃预冷的异丙醇,充分颠倒混匀,置于冰上10min;
4)12000rpm高速离15min后小心弃掉上清液,按1ml/ml Trizol的比例加入75%DEPC乙醇洗涤沉淀(4℃保存),洗涤沉淀物,振荡混匀,4℃,12000rpm离心5min;
5)弃去乙醇液体,室温下放置5min,加入DEPC水溶解沉淀;
6)用Nanodrop2000紫外分光光度计测量RNA纯度及浓度,冻存于-70℃冰箱。
3、逆转录和标记
用Low RNA Input Linear Amplification Kit将mRNA逆转录成cDNA,同时用Cy3分别标记实验组和对照组。
4、杂交
基因芯片采用Aglient公司的人全基因组表达谱芯片,每张芯片包括45015个寡核苷酸,其中有43376个人基因探针和1639个实验控制探针。按芯片使用说明书的步骤进行,温度在65℃,经17h 10r/min滚动杂交,37℃洗片。
5、数据处理
杂交后芯片用Agilent扫描仪扫描,分辨率为5μm,扫描仪自动以100%和10%PMT各扫描1次,2次结果Agilent软件自动合并。扫描图像数据采用FeatureExtraction进行处理分析,得到的原始数据应用Bioconductor程序包进行后续数据处理。最后Ratio值为实验组和对照组。差异基因筛选标准:ratio≥4为上调基因,ratio≤0.25为下调基因。
6、结果
与正常粘膜组织相比,STAC2基因在口腔鳞状细胞癌组织中的表达量显著上调。
实施例2 QPCR测序验证STAC2基因的差异表达
1、对STAC2基因差异表达进行大样本QPCR验证。按照实施例1中的样本收集方式选择正常粘膜组织和口腔鳞状细胞癌组织各80例。
2、RNA提取步骤如实施例1所述。
3、逆转录:
1)反应体系:
表1 逆转录反应体系
2)逆转录反应条件
按照RNA PCR Kit(AMV)Ver.3.0中逆转录反应条件进行。
42℃60min,99℃2min,5℃5min。
3)聚合酶链反应
1)引物设计
根据Genebank中STAC2基因和GAPDH基因的编码序列设计QPCR扩增引物,由博迈德生物公司合成。具体引物序列如下:
STAC2基因:
正向引物为5’-ATCGTAGGAAACTCCAAACAG-3’(SEQ ID NO.3);
反向引物为5’-ATCTCCTCAGAGCACCAG-3’(SEQ ID NO.4)。
管家基因GAPDH的引物序列为:
正向引物:5’-CTCTGGTAAAGTGGATATTGT-3’(SEQ ID NO.5)
反向引物:5’-GGTGGAATCATATTGGAACA-3’(SEQ ID NO.6)
2)按照表1配制25μl PCR反应体系:
表2 PCR反应体系
3)PCR反应条件:94℃4min,(94℃20s,60℃30s、72℃30s)×30个循环。以SYBR Green作为荧光标记物,在Light Cycler荧光定量PCR仪上进行PCR反应,通过融解曲线分析和电泳确定目的条带,ΔΔCT法进行相对定量,每个样进行3次重复实验。
5、统计学方法
以GAPDH为内参,计算口腔鳞状细胞癌组织与正常粘膜组织荧光定量RT-PCR的实验结果,采用SPSS18.0统计软件来进行统计分析,两者之间的差异采用t检验,以P<0.05具有统计学差异。
6、结果
结果如图1所示,与周围正常粘膜组织相比,STAC2基因在口腔鳞状细胞癌组织中表达上调,差异具有统计学意义(P<0.05),同RNA-sep结果一致。
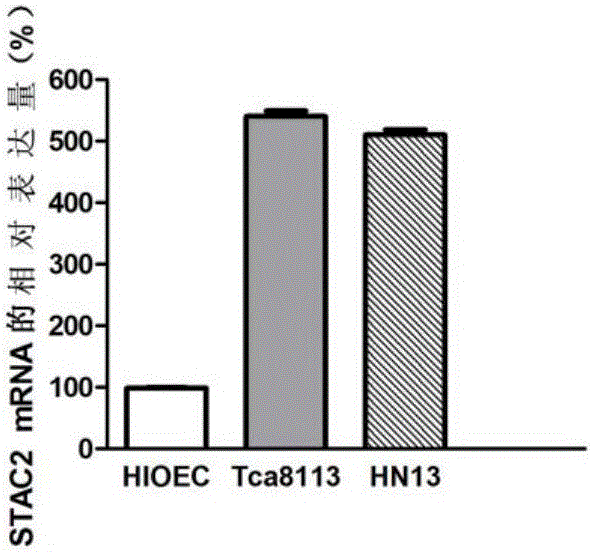
实施例3 STAC2基因在口腔鳞状细胞癌细胞系中的差异表达
1、细胞培养
口腔鳞状细胞癌细胞系Tca8113、HN13,正常粘膜上皮细胞系HIOEC购自于上海交通大学附属第九人民医院。HIOEC的培养基为K-SFM;Tca8113、HN13的培养基为DMEM;以含10%胎牛血清和1%P/S的培养基在37℃、5%CO2、相对湿度为90%的培养箱中培养。2-3天换液1次,使用0.25%含EDTA的胰蛋白酶常规消化传代。
2、细胞总RNA的提取
1)当细胞达80-90%融合时终止培养,0.25%胰蛋白酶消化收集细胞于1.5m1EP管中,每管中加入lm1Trizol缓慢摇动破碎细胞,冰上放置10min。
2)去蛋白,去DNA:每个1.5m1EP管加入0.2ml三氯甲烷,摇晃15s,室温放置10min。4℃,12000rpm离心15min。
剩余操作步骤同组织中RNA提取过程。
3、逆转录
具体步骤同实施例2.
4、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,两者之间的差异采用t检验,认为当P<0.05时具有统计学意义。
5、结果
结果如图2所示,与正常粘膜上皮细胞相比,STAC2基因在口腔鳞状细胞癌细胞Tca8113、HN13中表达均上调,差异具有统计学意义(P<0.05),同RNA-sep结果一致。
实施例4 STAC2基因的沉默
1、细胞培养
人口腔鳞状细胞癌细胞株Tca8113,以含10%胎牛血清和1%P/S的培养基DMEM在37℃、5%CO2、相对湿度为90%的培养箱中培养。2-3天换液1次,使用0.25%含EDTA的胰蛋白酶常规消化传代。
2、siRNA设计
针对STAC2基因的siRNA序列:
阴性对照siRNA序列(siRNA-NC):
正义链为5’-UUCUCCGAACGUGUCACGU-3’(SEQ ID NO.7)
反义链为5’-ACGUGACACGUUCGGAGAA-3’(SEQ ID NO.8)
siRNA1-STAC2:
正义链为5’-AAAUUAGCUGGGAAGAAGCCA-3’(SEQ ID NO.9)
反义链为5’-GCUUCUUCCCAGCUAAUUUUG-3’(SEQ ID NO.10)
siRNA2-STAC2:
正义链为5’-UCUACUUGAACAGAUAGUCUC-3’(SEQ ID NO.11)
反义链为5’-GACUAUCUGUUCAAGUAGAAA-3’(SEQ ID NO.12)
将细胞按4×104/孔接种到六孔细胞培养板中,在37℃、5%CO2培养箱中细胞培养24h,在无双抗、含10%FBS的DMEM培养基中,转染按照脂质体转染试剂2000(购自于Invitrogen公司)的说明书转染。
将实验分为三组:对照组(Tca8113)、阴性对照组(siRNA-NC)和实验组(siRNA1-STAC2、siRNA2-STAC2),其中阴性对照组siRNA与STAC2基因的序列无同源性,浓度为20nM/孔,同时分别进行转染。
3、QPCR检测STAC2基因的转录水平
3.1细胞总RNA的提取
具体步骤同实施例3。
3.2逆转录 步骤同实施例2。
3.3 QPCR扩增 步骤同实施例2。
4、统计学方法
实验都是按照重复3次来完成的,结果数据都是以平均值±标准差的方式来表示,采用SPSS18.0统计软件来进行统计分析的,干扰STAC2基因表达组与对照组之间的差异采用t检验,认为当P<0.05时具有统计学意义。
5、结果
结果如图3显示,相比TCA8113、转染空载siRNA-NC、siRNA2-STAC2组,siRNA1-STAC2组能够显著降低STAC2基因的表达,差异具有统计学意义(P<0.05)。
实施例5 ELISA检测Tca8113细胞中STAC2的蛋白表达
应用双抗体夹心酶标免疫(Enzyme-Linked Immunosorbent Assay,ELISA)分析法测定Tca8113细胞上清中STAC2蛋白水平。RNA干扰后第六天,分别收集三组Tca8113细胞的上清液,按照ELISA试剂盒操作流程定量检测肿瘤细胞上清液中STAC2的浓度。
1、配置浓度为70000pg/ml的标准品,10倍稀释后,再进行2倍倍比稀释,共有7个稀释度。
2、加样:分别设空白孔、标准孔、待测样品孔。空白孔加样品稀释液50μl,余孔分别加不同浓度梯度的标准品和待测样品各50μl。轻轻晃动混匀,酶标板加上盖,37℃反应2h。
3、弃去液体,晾干。每孔加200μl VEGF-C结合物。37℃,120min后,弃去孔内液体,晾干,PBS洗板3次。
4、依序每孔加底物溶液200μl,37℃避光显色30min。
5、依序每孔加终止溶液50μl,终止反应。
6、用酶联仪在450nm波长依序测量各孔的光密度(OD值)。所有标准品和待测样品的OD值均需减去零孔的OD值以得到校正值。
7、计算样品的实际浓度。
8、结果如下表3所示,siRNA沉默Tca8113细胞的STAC2基因,STAC2的蛋白含量也相应降低,说明沉默STAC2基因可以抑制STAC2基因的表达。
表3 ELISA检测不同组别细胞中的STAC2蛋白的表达
实施例6 MTT法检测Tca8113细胞增殖活性
应用MTT(Methyl thiazolyl tetrazolium,甲基噻唑基四唑)法检测STAC2基因沉默后对Tca8113细胞增殖活性的影响。
1、细胞培养 将Tca8113细胞按1×103/孔接种于96孔板,每孔100μ1,37℃,5%CO2孵箱内孵育培养。
2、细胞转染 步骤同实施例3。
3、MTT检测
1)分别于转染1~7天时,弃掉各孔培养基,加入MTT(5mg/ml)20μl。继续常规培养4h。
2)吸去混合液,每孔加入DMSO 200μl,震荡10min使结晶充分溶解。在酶联免疫仪上测490nm处的光吸收值,记录结果。
4、以时间为横轴,光吸收值(OD)为纵轴绘制细胞生长曲线。
5、结果:
结果如图4所示,与对照相比,转染siRNA1-STAC2组的细胞增殖显著降低。
实施例7 Transwell细胞体外侵袭实验
RNA干扰后第六天收集不同组别的Tca8113细胞,重悬于培养液中,使细胞终浓度为2×106/ml,吸取100μl细胞悬液加入Transwell小室中。应用Transwell小室方法观察STAC2基因沉默对Tca8113细胞侵袭性的影响。
1、将Matrigel(4μg/μl)放入4℃融化,准备冰盒(冰浴环境)。Matrigel用DMEM稀释8倍后使用。在Transwell小室滤膜(8μm孔径)的外表面涂8μg人纤粘连蛋白,置超净台内风干。
2、在6孔Transwell小室滤膜的内表面铺以100μ1/孔的Matrigel胶,37℃、5%CO2孵箱内孵育1h,形成一个基质屏障层备用。
3、在6孔板每孔内加入含20%FBS的DMEM培养液2.5m1。
4、收集对数生长期的细胞,重悬于培养液中,终浓度为2×106/ml。
5、将细胞悬液加入Transwell小室中,每孔100μ1,将小室浸于6孔板的条件培养基中,37℃、5%CO2孵箱内孵育24h。
6、将Transwell小室取出,滤膜用甲醇固定1min。
7、HE染色:苏木精染色3min,水洗;伊红染色10~30s,水洗。并用棉签擦掉未穿过膜的细胞。
8、显微镜下观察、照相并计数侵袭细胞数,每膜计数上下左右中5个不同视野的透过细胞数,计算平均值。每组平行设3个滤膜。
9、数据处理
用SPSS18.0软件对数据进行统计学分析。计量资料用均数±标准差表示。多个样本均数比较采用单因素方差分析,P<0.05为差异有统计学意义。
10、结果
结果如图5所示,Tca8113、siRNA1-STAC2、siRNA-NC组细胞在transwell小室中培养24h后,siRNA1-STAC2组聚碳酸酯膜下室面的细胞数显著减少。
上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。
SEQUENCE LISTING
<110> 北京泱深生物信息技术有限公司
<120> 分子标志物STAC2在口腔鳞状细胞癌中的应用
<160> 12
<170> PatentIn version 3.5
<210> 1
<211> 1236
<212> DNA
<213> 人源
<400> 1
atgaccgaga tgagcgagaa ggagaacgaa ccggatgacg cggccaccca cagcccccca 60
gggaccgtct ccgccctcca ggaaaccaag ctccagcgat tcaagcgctc cctctccctc 120
aagaccatcc tccgaagtaa gagcttggag aacttcttcc ttcgctcggg ctctgagctc 180
aagtgcccca ccgaggtgct gctgacgccc ccaaccccac tgccccctcc ctccccacca 240
cccacagcct cggacagggg cctggctacc ccatccccct ccccatgccc agtcccacgc 300
cccctggcag cgctcaaacc agtgaggctg cacagcttcc aggaacatgt cttcaagcga 360
gctagccctt gtgagctgtg ccaccagctc atcgtaggaa actccaaaca gggcttgcga 420
tgtaagatgt gcaaagtcag cgtccacctc tggtgctctg aggagatctc ccaccagcaa 480
tgcccaggca agacgtccac ctccttccgc cgcaacttca gttcccctct cctggtgcat 540
gagccgccac cagtctgtgc cacaagcaaa gagtccccac ccactgggga cagtgggaag 600
gtggaccctg tctacgagac cctgcgctat ggcacctccc tggcactgat gaaccgctcc 660
agtttcagca gcacctctga gtccccgaca aggagcctga gtgagcggga tgagctgacc 720
gaggatgggg aaggcagcat ccgcagctct gaggaggggc ctggtgacag tgcatctcca 780
gtattcacag ccccagcaga gagtgaaggg ccaggaccag aggagaagag tcctggacag 840
cagctcccca aagccaccct gcggaaggat gtggggccca tgtactccta cgttgcactc 900
tacaagtttc tgccccagga gaacaatgat ctggctctgc agcctggaga tcggatcatg 960
ctggtggatg actctaacga ggactggtgg aagggcaaga tcggcgaccg ggttggcttc 1020
ttcccagcta attttgtgca acgggtgagg ccaggcgaga atgtttggcg ctgctgccaa 1080
cccttctccg ggaacaagga acagggttac atgagcctca aggagaacca gatctgcgtg 1140
ggcgtgggca gaagcaagga tgctgacggc ttcatccgcg tcagcagtgg caagaagcgg 1200
ggcctggtgc cagtcgacgc cctgactgag atctga 1236
<210> 2
<211> 411
<212> PRT
<213> 人源
<400> 2
Met Thr Glu Met Ser Glu Lys Glu Asn Glu Pro Asp Asp Ala Ala Thr
1 5 10 15
His Ser Pro Pro Gly Thr Val Ser Ala Leu Gln Glu Thr Lys Leu Gln
20 25 30
Arg Phe Lys Arg Ser Leu Ser Leu Lys Thr Ile Leu Arg Ser Lys Ser
35 40 45
Leu Glu Asn Phe Phe Leu Arg Ser Gly Ser Glu Leu Lys Cys Pro Thr
50 55 60
Glu Val Leu Leu Thr Pro Pro Thr Pro Leu Pro Pro Pro Ser Pro Pro
65 70 75 80
Pro Thr Ala Ser Asp Arg Gly Leu Ala Thr Pro Ser Pro Ser Pro Cys
85 90 95
Pro Val Pro Arg Pro Leu Ala Ala Leu Lys Pro Val Arg Leu His Ser
100 105 110
Phe Gln Glu His Val Phe Lys Arg Ala Ser Pro Cys Glu Leu Cys His
115 120 125
Gln Leu Ile Val Gly Asn Ser Lys Gln Gly Leu Arg Cys Lys Met Cys
130 135 140
Lys Val Ser Val His Leu Trp Cys Ser Glu Glu Ile Ser His Gln Gln
145 150 155 160
Cys Pro Gly Lys Thr Ser Thr Ser Phe Arg Arg Asn Phe Ser Ser Pro
165 170 175
Leu Leu Val His Glu Pro Pro Pro Val Cys Ala Thr Ser Lys Glu Ser
180 185 190
Pro Pro Thr Gly Asp Ser Gly Lys Val Asp Pro Val Tyr Glu Thr Leu
195 200 205
Arg Tyr Gly Thr Ser Leu Ala Leu Met Asn Arg Ser Ser Phe Ser Ser
210 215 220
Thr Ser Glu Ser Pro Thr Arg Ser Leu Ser Glu Arg Asp Glu Leu Thr
225 230 235 240
Glu Asp Gly Glu Gly Ser Ile Arg Ser Ser Glu Glu Gly Pro Gly Asp
245 250 255
Ser Ala Ser Pro Val Phe Thr Ala Pro Ala Glu Ser Glu Gly Pro Gly
260 265 270
Pro Glu Glu Lys Ser Pro Gly Gln Gln Leu Pro Lys Ala Thr Leu Arg
275 280 285
Lys Asp Val Gly Pro Met Tyr Ser Tyr Val Ala Leu Tyr Lys Phe Leu
290 295 300
Pro Gln Glu Asn Asn Asp Leu Ala Leu Gln Pro Gly Asp Arg Ile Met
305 310 315 320
Leu Val Asp Asp Ser Asn Glu Asp Trp Trp Lys Gly Lys Ile Gly Asp
325 330 335
Arg Val Gly Phe Phe Pro Ala Asn Phe Val Gln Arg Val Arg Pro Gly
340 345 350
Glu Asn Val Trp Arg Cys Cys Gln Pro Phe Ser Gly Asn Lys Glu Gln
355 360 365
Gly Tyr Met Ser Leu Lys Glu Asn Gln Ile Cys Val Gly Val Gly Arg
370 375 380
Ser Lys Asp Ala Asp Gly Phe Ile Arg Val Ser Ser Gly Lys Lys Arg
385 390 395 400
Gly Leu Val Pro Val Asp Ala Leu Thr Glu Ile
405 410
<210> 3
<211> 21
<212> DNA
<213> 人工序列
<400> 3
atcgtaggaa actccaaaca g 21
<210> 4
<211> 18
<212> DNA
<213> 人工序列
<400> 4
atctcctcag agcaccag 18
<210> 5
<211> 21
<212> DNA
<213> 人工序列
<400> 5
ctctggtaaa gtggatattg t 21
<210> 6
<211> 20
<212> DNA
<213> 人工序列
<400> 6
ggtggaatca tattggaaca 20
<210> 7
<211> 19
<212> RNA
<213> 人工序列
<400> 7
uucuccgaac gugucacgu 19
<210> 8
<211> 19
<212> RNA
<213> 人工序列
<400> 8
acgugacacg uucggagaa 19
<210> 9
<211> 21
<212> RNA
<213> 人工序列
<400> 9
aaauuagcug ggaagaagcc a 21
<210> 10
<211> 21
<212> RNA
<213> 人工序列
<400> 10
gcuucuuccc agcuaauuuu g 21
<210> 11
<211> 21
<212> RNA
<213> 人工序列
<400> 11
ucuacuugaa cagauagucu c 21
<210> 12
<211> 21
<212> RNA
<213> 人工序列
<400> 12
ucuacuugaa cagauagucu c 21
- 还没有人留言评论。精彩留言会获得点赞!