用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒的制作方法
本发明涉及用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒。
背景技术:
目前已证实CYP2C19不但参与抗癫痫药物的代谢,而且很多的临床重要药物都是它的底物。人类对药物的氧化代谢能力可分为2种表型,一种为强代谢型,另一种为弱代谢型,后者主要是由于CYP2C19*2和CYP2C19*3这两个缺陷型等位基因引起的。由于不同个体存在药物代谢方面的差异,因而给药后可能会出现严重的不良反应或药物剂量不足,从而导致治疗的失败。CYP2C19 在体内可催化一系列药物,如 S-美芬妥英(S-mephenytoin,S-MP)、奥美拉唑(omeprazole,OPZ)、地西汁(diazepam,DZ)、去甲地西汁(demethyldiazepam )、丙米嗪(imipramine,IMI)、甲苯磺丁脲(tolbutamide,D860)、苯巴比妥(phenobarbital,PB),氯胍(proguanil)和二氯胍(chlorproguanil)等。
CYP2C19 rs4986893(CYP2C19*3)是第四外显子第636位处的碱基发生变异(G>A),使212位原来编码色氨酸的密码子变为终止密码子,从而只产生CYP2C19前4个外显子的编码产物:仅由211个氨基酸组成的没有活性的蛋白质。
技术实现要素:
本发明提供了用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒,检测结果能够用于CYP2C19 rs4986893相关的药物个体化治疗。
本发明的第一个目的是提供用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒,所述试剂盒包括引物对和PCR检测反应试剂;其中,所述引物对为(1)或(2)中的一种:
(1)上游引物:CYP2C19-F 5'- CATCAGGATTGTAAGCACCCCC-3'
下游引物:CYP2C19-R 5'- TTTCTCAGGAAGCAAAAAACTTGG-3';
(2)与(1)中的互补序列。
上述引物的衍生序列也在本发明的保护范围,所述衍生序列为向5’端和/或3’端方向延伸一致数个碱基或删减一致数个碱基得到的序列。
作为优选,所述PCR检测反应试剂包括含EvaGreen 的Green-2-Go qPCRMastermix。
作为优选,所述PCR扩增时的反应体系为:
Green-2-Go qPCRMastermix(含EvaGreen) 5μl
引物F(10μM) 0.1μl
引物R(10μM) 0.1μl
模板(50ng/μl) 0.5μl
ddH2O 4.3μl
总体积 10μl。
作为优选,所述试剂盒还包括标准品,所述标准品为重组阴性质粒和重组阳性质粒,所述重组阴性质粒的核苷酸序列为序列表SEQ ID No.1,所述重组阳性质粒的核苷酸序列为序列表中SEQ ID No.2。
本发明的第二个目的是提供一种检测CYP2C19基因SNP位点rs4986893基因型的方法,步骤如下:
(1)构建重组阴性质粒和重组阳性质粒:所述重组阴性质粒的核苷酸序列为序列表中SEQ ID No.1,所述重组阳性质粒的核苷酸序列参见序列表中SEQ ID No.2;
(2)构建PCR扩增时的引物对,所述引物对为a或b中的一种:
a、上游引物:CYP2C19-F 5'- CATCAGGATTGTAAGCACCCCC-3'
下游引物:CYP2C19-R 5'- TTTCTCAGGAAGCAAAAAACTTGG-3';
b、与a中的互补序列;
(3)提取待测样本的外周血基因组DNA,对重组阴性质粒、重组阳性质粒和待测样本的DNA均使用步骤(2)所述引物,且在同一条件下进行PCR扩增和HRM分析,收集数据;
作为优选,所述HRM分析的条件为:94℃ 90s;60℃ 30s;83-94℃收集数据,温度上升速率为0.06℃/s;
(4)根据收集数据绘制高分辨率熔解曲线,根据重组阴性质粒、重组阳性质粒的熔解曲线判断待测样本CYP2C19基因SNP位点rs4986893的基因型:
与重组阴性质粒的熔解曲线重合则CYP2C19基因SNP位点rs4986893的基因型为GG;
与重组阳性质粒的熔解曲线重合则CYP2C19基因SNP位点rs4986893的基因型为AA;
在重组阴性质粒和重组阳性质粒之间的则CYP2C19基因SNP位点rs4986893的基因型为GA。
作为优选,所述PCR扩增时的反应体系为:
Green-2-Go qPCRMastermix(含EvaGreen) 5μl
引物F(10μM) 0.1μl
引物R(10μM) 0.1μl
模板(50ng/μl) 0.5μl
ddH2O 4.3μl
总体积 10μl。
作为优选,所述PCR扩增时的反应条件为:94℃预变性3min;94℃变性10s;60℃退火/延伸20s;40个循环。
本发明的第三个目的是提供上述试剂盒的使用方法,步骤如下:
(1)提取待测样本的外周血基因组DNA,对重组阴性质粒、重组阳性质粒和待测样本的DNA均使用相同引物,且在同一条件下进行PCR扩增和HRM分析,收集数据;
所述HRM分析的条件为:94℃ 90s;60℃ 30s;83-94℃收集数据,温度上升速率为0.06℃/s;
(2)根据收集数据绘制高分辨率熔解曲线,根据重组阴性质粒、重组阳性质粒的熔解曲线判断待测样本CYP2C19基因SNP位点rs4986893的基因型:
与重组阴性质粒的熔解曲线重合则CYP2C19基因SNP位点rs4986893的基因型为GG;
与重组阳性质粒的熔解曲线重合则CYP2C19基因SNP位点rs4986893的基因型为AA;
在重组阴性质粒和重组阳性质粒之间的则CYP2C19基因SNP位点rs4986893的基因型为GA。
本发明的第四个目的是提供上述试剂盒在制备与CYP2C19 rs4986893相关的药物个体化治疗试剂中的应用。
本发明的试剂盒能够准确检测CYP2C19基因SNP位点rs4986893的基因型,灵敏度高,特异性好,检测快速;应用本发明的试剂盒对CYP2C19基因SNP位点rs4986893基因型的分型与测序结果完全一致,能够用于CYP2C19 rs4986893相关的药物个体化治疗,对后续研究具有重要意义。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明的HRM方法灵敏度实验结果。
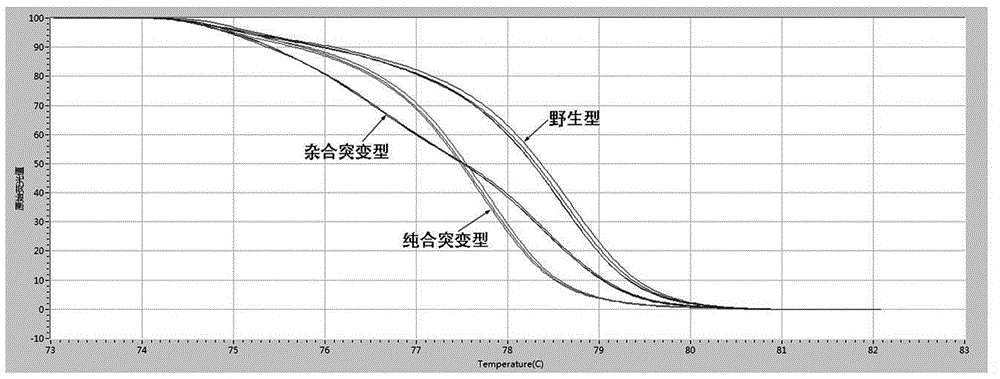
图2为样本用本发明的HRM方法分析结果。
图3为样本的CYP2C19 rs4986893(c.636G>A)位点的测序结果;其中a代表野生型序列,b代表纯合突变型序列,c为杂合突变序列。
具体实施方式
以下的实施例便于更好地理解本发明,但并不限定本发明。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的试验材料,如无特殊说明,均为市售。本申请所用引物和所用序列合成及测序工作均由生工生物工程(上海)股份有限公司完成。
实施例1 CYP2C19 rs4986893标准品的制备
要建立HRM分析方法,首先必须制备方法所需的外部标准品,标准品应包含高度保守和特异性的序列,要保证反应的高特异性。本发明合成包含CYP2C19 rs4986893(c.636G>A)位点的野生型和纯合突变型DNA序列,利用基因重组技术将其克隆到pMD18-T载体中,构建出重组质粒pMD18-T-rs4986893的野生型和纯合突变型,并进行相应的PCR鉴定和测序鉴定,最后经定量作为待建立方法的标准品:野生型重组质粒为重组阴性质粒,纯合突变型重组质粒为重组阳性质粒,为下一步的方法及评估奠定基础。
一、重组阴性和阳性质粒pMD18-T-rs4986893的构建和转化
1.合成CYP2C19 rs4986893(c.636G>A)野生型和纯合突变型DNA序列,本发明合成的序列200bp,序列如下:
(1)野生型序列
ATAAAGATCAGCAATTTCTTAACTTGATGGAAAAATTGAATGAAAACATCAGGATTGTAAGCACCCCCTGGATCCAGGTAAGGCCAAGTTTTTTGCTTCCTGAGAAACCACTTACAGTCTTTTTTTCTGGGAAATCCAAAATTCTATATTGACCAAGCCCTGAAGTACATTTTTGAATACTACAGTCTTGCCTAGACAGC
其中标有下划线的碱基为基因突变位点。
(2)纯合突变型序列
ATAAAGATCAGCAATTTCTTAACTTGATGGAAAAATTGAATGAAAACATCAGGATTGTAAGCACCCCCTGAATCCAGGTAAGGCCAAGTTTTTTGCTTCCTGAGAAACCACTTACAGTCTTTTTTTCTGGGAAATCCAAAATTCTATATTGACCAAGCCCTGAAGTACATTTTTGAATACTACAGTCTTGCCTAGACAGC
其中标有下划线的碱基为基因突变位点。
2.连接反应:将上述合成的DNA片段与pMD18-T进行连接,采用如下连接体系进行配制:
pMD18-T 1μL
DNA 2μL
SolutionI 5μL
ddH2O 2μL
总体积 10μL
配制完成后置于16℃进行过夜连接反应。
3. pMD18-T-rs4986893质粒的转化以及PCR鉴定
(1)从-80℃的超低温冰箱中取出冻存的DH5α感受态细胞,置于冰盒上使其解冻;
(2)取步骤2得到的连接产物10μL加入50μL的DH5α感受态细胞中,轻轻摇匀后置冰浴30分钟;
(3)42℃水浴热激90秒,热激后立即置冰上冷却2min;
(4)于1.5ml EP管中加入预冷的1ml的不含抗性的LB液体培养基吹打混匀后,37℃ 120转/分轻摇培养90min;
(5)将上述培养液短暂离心吸去900μl后取剩余的100μl涂布于含Amp抗生素的LB平板上,正面向上放置30min,待菌液完全被培养基吸收后,倒置培养皿37℃恒温箱培养过夜;
(6)从平板上挑取单克隆菌落于500μL Amp抗性LB液体培养基的1.5ml EP管中,37℃ 220rpm振荡培养5-6小时;
(7)取1μL作为模板进行菌液PCR鉴定。将鉴定为阳性的菌液加入到20ml的LB液体培养基中进行扩摇;
(8)用引物CYP2C19-F和CYP2C19-R扩增上述稀释菌液,PCR产物采用2%琼脂糖凝胶电泳,通过检测PCR产物鉴定阳性转化子。
引物序列为HRM分析所用引物,序列如下:
上游引物:CYP2C19-F 5'- CATCAGGATTGTAAGCACCCCC-3'
下游引物:CYP2C19-R 5'- TTTCTCAGGAAGCAAAAAACTTGG-3'
体系如下:
10×PCR buffer 2μL
dNTP(2.5μM) 2μL
引物F(5μM) 1.5μL
引物R(5μM) 1.5μL
模板 2μL
Taq酶(5U) 0.5μL
ddH2O 10.5μL
总体积 20μL。
扩增程序/反应条件:94℃预变性5min;94℃ 30s、60℃ 30s、72℃ 30sec,35个循环;72℃ 10min。
4.重组阴性和阳性质粒的提取
采用北京百泰克公司生产的质粒制备试剂盒提取重组质粒,测定浓度和纯度,同时吸取一部分纯化质粒送至上海生物工程有限公司进行测序,确定插入片段的基因序列与目的序列一致。
二、标准品的获取和定量
(1)将步骤一得到的冻存的含有重组质粒pMD18-T-rs4986893的大肠杆菌DH5α100μl接种于15ml氨苄抗性的LB液体培养基中,37℃ 220rpm培养14-16h;
(2)采用北京百泰克生物科技有限公司生产的质粒制备试剂盒提取重组质粒;
(3)利用北京百泰克生物科技有限公司的超微量紫外可见分光光度计(ND5000)对提取的质粒测定浓度,根据A260/A280判断质粒的纯度。A260/A280=1.78。
实施例2 HRM-PCR检测CYP2C19rs4986893方法的建立
一、待测样本的制备
提取30例样本的血液基因组DNA,用作CYP2C19基因PCR扩增的模板。血液基因组DNA的提取步骤如下:
(1)取1ml全血,加入3ml TE,颠倒混匀后静置10min,8000rpm离心5分钟,弃上清液;
(2)重复上述步骤2-3次至沉淀为白色;
(3)加入900μl 10%SDS和10μl 10mg/ml蛋白酶K,55℃水浴1h;
(4)将离心管冷却至室温,加入等体积的酚/氯仿/异戊醇(25:24:1)混匀,12000rpm离心10min;
(5)小心吸取上清后再加入等体积酚/氯仿/异戊醇(25:24:1)混匀,12000rpm离心10min;
(6)取上清,加入两倍体积的无水乙醇,上下颠倒混匀,12000rpm离心10min,弃上清;
(7)加500μl 70%的乙醇洗涤沉淀,短暂离心后弃上清,开盖干燥至乙醇完全挥发;
(8)加50μl双蒸水或TE溶解DNA,-20℃保存。
二、特异性引物的设计与合成
本发明通过对NCBI数据库中CYP2C19rs4986893基因序列进行检索,选取适合设计引物的片段序列为靶目标,设计了一组HRM-PCR引物。
本发明选取的扩增序列如下:
其中标有下划线的碱基为基因突变位点。
该引物序列如下:
上游引物:CYP2C19-F 5'- CATCAGGATTGTAAGCACCCCC-3'
下游引物:CYP2C19-R 5'- TTTCTCAGGAAGCAAAAAACTTGG-3'
扩增片段大小为:61bp。扩增的核苷酸序列为:
三、HRM-PCR反应体系和反应条件
分别以待测样本DNA、重组阴性质粒和重组阳性质粒为模板,以上述引物CYP2C19-F和CYP2C19-R为扩增引物,采用如下述体系和反应条件进行PCR扩增。
PCR体系:
Green-2-Go qPCRMastermix(含EvaGreen) 5μl
引物F(10μM) 0.1μl
引物R(10μM) 0.1μl
模板(50ng/μl) 0.5μl
ddH2O 4.3μl
总体积 10μl。
其中引物采用CYP2C19-F和CYP2C19-R,HRM-PCR采用生工生物(上海)Green-2-Go qPCRMastermix试剂盒。HRM分析仪为百源基因ASA-9600实时荧光定量PCR仪。
PCR扩增程序:
94℃预变性3min;94℃变性10s;60℃退火/延伸20s;40个循环。
HRM分析:
94℃ 90s
60℃ 30sec
83-94℃收集数据,温度上升速率为0.06℃/s。
四、结果分析
根据收集数据绘制高分辨率熔解曲线,根据重组阴性质粒、重组阳性质粒的熔解曲线判断待测样本CYP2C19基因SNP位点rs4986893的基因型:
与重组阴性质粒的熔解曲线重合则CYP2C19基因SNP位点rs4986893的基因型为GG;
与重组阳性质粒的熔解曲线重合则CYP2C19基因SNP位点rs4986893的基因型为AA;在重组阴性质粒和重组阳性质粒之间的则CYP2C19基因SNP位点rs4986893的基因型为GA。
五、HRM灵敏度实验
将重组阳性质粒和重组阴性质粒均稀释至50ng/μl,然后二者混合,以重组阳性质粒占比例依次为50%、25%、12.5%、5%、2%和1%进行梯度稀释,按照上述HRM-PCR反应体系和参数进行扩增,分析突变检出范围,即灵敏度。
反应体系如下:
Green-2-Go qPCRMastermix(含EvaGreen) 5μl
引物F(10μM) 0.1μl
引物R(10μM) 0.1μl
模板(50ng/μl) 0.5μl
ddH2O 4.3μl
总体积 10μl。
PCR扩增程序:
94℃预变性3min;94℃变性10s;60℃退火/延伸20s;40个循环;
HRM分析:
94℃ 90s
60℃ 30sec
83-94℃收集数据,温度上升速率为0.06℃/s。
结果见图1,实验数据显示,当阳性质粒与阴性质粒体积比分别为1:1、1:3、1:7、1:19、1:49和1:99时,均能检测出阳性质粒,所以本发明所用HRM检测方法的灵敏度为1%。
实施例3 应用本发明的检测方法检测样本CYP2C19 rs4986893基因型
以实施例2步骤中的检测试剂盒和检测方法,对30例样本进行HRM分析,与重组阳性质粒和重组阴性质粒熔解曲线对照比较,依此确定样本中的突变类型,并根据HRM分析结果针对每种基因型随机挑选1个样本在生工生物(上海)进行Sanger测序验证。
HRM分析结果参见表1和图2,数据显示30例样本中CYP2C19基因rs4986893为G>A杂合突变型有7例,G>A纯合突变型6例,其余16例为野生型。
Sanger测序结果参见图3:其中a为样本编号2的测序结果,b为样本编号11的测序结果,c为样本编号20的测序结果;Sanger测序结果与本发明方法检测的结果完全一致。
表1应用本发明的方法对样本CYP2C19基因rs4986893的分析结果
实施例4 用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒
本发明的用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒包括以下组分:
(1)CYP2C19rs4986893标准品:重组阴性质粒和重组阳性质粒,按照实施例1中的方法制备;
(2)引物:该引物序列为:
上游引物:CYP2C19-F 5'- CATCAGGATTGTAAGCACCCCC-3'
下游引物:CYP2C19-R 5'- TTTCTCAGGAAGCAAAAAACTTGG-3';
(3)含饱和荧光染料Eva Green的PCR扩增试剂。
应用该试剂盒检测CYP2C19基因SNP位点rs4986893基因型的方法与实施例2相同。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
序列表
<110> 苏州百源基因技术有限公司
<120> 用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒
<170> PatentIn version 3.5
<210> 1
<211> 200
<212> DNA
<213> 人工序列
<400> 1
ataaagatca gcaatttctt aacttgatgg aaaaattgaa tgaaaacatc aggattgtaa 60
gcaccccctg gatccaggta aggccaagtt ttttgcttcc tgagaaacca cttacagtct 120
ttttttctgg gaaatccaaa attctatatt gaccaagccc tgaagtacat ttttgaatac 180
tacagtcttg cctagacagc 200
<210> 2
<211> 200
<212> DNA
<213> 人工序列
<400> 2
ataaagatca gcaatttctt aacttgatgg aaaaattgaa tgaaaacatc aggattgtaa 60
gcaccccctg aatccaggta aggccaagtt ttttgcttcc tgagaaacca cttacagtct 120
ttttttctgg gaaatccaaa attctatatt gaccaagccc tgaagtacat ttttgaatac 180
tacagtcttg cctagacagc 200
<210> 3
<211> 144
<212> DNA
<213> 人工序列
<400> 3
gatcagcaat ttcttaactt gatggaaaaa ttgaatgaaa acatcaggat tgtaagcacc 60
ccctggatcc aggtaaggcc aagttttttg cttcctgaga aaccacttac agtctttttt 120
tctgggaaat ccaaaattct atat 144
<210> 4
<211> 61
<212> DNA
<213> 人工序列
<400> 4
catcaggatt gtaagcaccc cctggatcca ggtaaggcca agttttttgc ttcctgagaa 60
a 61
- 还没有人留言评论。精彩留言会获得点赞!
- 用于基因产品的检索方法与流程
- 一种用于检测TNF‑a基因SNP位点rs1799724基因型的扩增引物、试剂盒、方法及其应用与流程
- 用于基因样本储存的多功能系统的制作方法与工艺
- 一种适用于鼠尾藻新型采苗附着基的缓释肥营养制剂的制作方法与工艺
- 一种适用于水域软基的上覆泥密封真空预压装置的制作方法
- 一种适用于发电机组的液压注胶枪的制作方法与工艺
- 一种适用于软基条件下的丁坝的制作方法与工艺
- 用于检测CYP2C19基因SNP位点rs4986893基因型的试剂盒的制作方法与工艺
- 用于检测JAG2基因SNP位点rs2238286基因型的试剂盒的制作方法与工艺
- 用于检测GATA4基因SNP位点rs867858基因型的试剂盒的制作方法与工艺