用于优化异源多聚体蛋白质复合物的装配和生产的方法与流程
相关申请
本申请要求2015年3月31日提交的美国临时申请号62/141009的权益,其各自的内容通过引用以其整体结合到本文中。
发明领域
提供了通过调节装配蛋白质复合物所需的各组分的表达水平来改进所述复合物的表达的方法。这些方法有效地限制优势链的表达,因此平衡它们的相对丰度。本文提供的方法导致在瞬时表达系统中以及在稳定转染的哺乳动物细胞中生产力和最终的双特异性收率显著增加。
发明背景
在细菌、酵母、昆虫、植物或哺乳动物细胞中的重组表达对于生产用于研究以及治疗应用的蛋白质而言是重要的。最近,通过优化多个参数例如培养基组成、发酵参数以及用于驱动编码目的重组蛋白质的基因的表达的构建体的优化,在中国仓鼠卵巢(cho)细胞中的重组蛋白质表达收率已显著提高。
一些蛋白质由若干多肽构成,这些多肽可缔合成可共价或非共价连接的复合物。抗体是这类蛋白质的实例,因为它们由通过二硫键连接的四个多肽构成(即,两条重链和两条轻链)。由于它们的商业和治疗重要性,抗体在cho细胞中的表达已成为强烈努力优化的主题,目的为使构成抗体的两种链的表达最大化。然而,在抗体之间可观察到大的差异,因为表达水平可变化达200倍。
之前的优化方法目的在于增加多肽的表达水平,以实现更高的生产收率。在由多种多肽构成的蛋白质复合物的情况下,不平衡的表达可限制需要的分子的装配,促进不需要的产物的生产和限制总体生产收率。因此,对改进蛋白质复合物的表达的方法存在需要。
发明简述
本公开内容的方法通过调节装配蛋白质复合物所需的各组分的表达水平来改进所述复合物的表达。与之前描述的方法相反,减少蛋白质复合物中一种或数种多肽的表达提高蛋白质复合物的装配和收率。该方法特别适合于优化通常依赖于多种多肽的共表达的双特异性抗体的表达和收率。一种组分的不平衡表达(太高或太低)可导致需要的终产物显著降低和不需要的副产物的生产增加。这种限制可影响igg-样双特异性形式以及基于抗体片段的形式二者。
该方法可特别适合于优化称为κλ-体的双特异性抗体的表达(fischer等,exploitinglightchainsforthescalablegenerationandplatformpurificationofnativehumanbispecificigg.nat.comms,6:6113(2015))。该技术产生全人双特异性抗体(bsab),其由共同的重链和两条不同的轻链(一条κ和一条λ)构成(参见例如wo2012/023053)。包括这三种链的专有三顺反子载体被引入哺乳动物细胞,以产生除了两种单特异性抗体iggκ和iggλ之外的双特异性抗体(κλ-体),其包含一条κ和一条λ链。
原则上,如果两种轻链以相同的速率表达和以类似的方式装配,那么这三种分子的比率应该是25%iggκ、25%iggλ和50%iggκλ。然而,有时观察到两种链的不平衡的表达水平,导致双特异性收率降低。一个解决方案可以是增加较低表达的链的表达以恢复平衡。然而,该方法已经失败(如在本文提供的有效实施例中所示)。
相比之下,本公开内容的方法有效地限制优势链的表达,因此平衡它们的相对丰度。本文公开的方法导致在瞬时表达系统中以及在稳定转染的cho细胞中生产力和最终的双特异性收率显著增加。因此,减少一种或数种多肽的表达可导致生产力总体增加。尽管本文提供的实施例使用κλ-体,但本文公开的方法可适用于其它双特异性抗体形式和由数种不同的多肽构成的任何其它蛋白质复合物。
在一些实施方案中,本公开内容提供了通过减少一种或数种多肽的表达速率,增加由数种多肽构成的蛋白质复合物的生产收率的方法。在一些实施方案中,一种多肽的表达减少通过改变转录速率、翻译速率或mrna稳定性来实现。在一些实施方案中,一种多肽的表达速率减少通过改变mrna二级结构来实现。在一些实施方案中,一种多肽的表达减少通过改变转录速率、改变翻译速率、改变mrna稳定性、改变mrna二级结构或通过任何这些因素的组合来实现。
在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过改变翻译速率来实现。在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过更改所述多肽的密码子组成来实现。在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过改变翻译速率和更改所述多肽的密码子组成来实现。
在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过改变翻译速率来实现。在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过更改所述多肽的密码子组成来实现,其通过用在用于表达蛋白质复合物的宿主细胞中较低频率使用的密码子置换某些密码子进行。在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过改变翻译速率和更改所述多肽的密码子组成来实现,其通过用在用于表达蛋白质复合物的宿主细胞中较低频率使用的密码子置换某些密码子进行。
在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过改变翻译速率来实现。在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过更改所述多肽的密码子组成来实现,其通过用在用于表达蛋白质复合物的哺乳动物宿主细胞中较低频率使用的密码子置换某些密码子进行。在一些实施方案中,蛋白质复合物中一种多肽的表达减少通过改变翻译速率和更改所述多肽的密码子组成来实现,其通过用在用于表达蛋白质复合物的哺乳动物宿主细胞中较低频率使用的密码子置换某些密码子进行。
在一些实施方案中,蛋白质复合物是多特异性抗体。在一些实施方案中,蛋白质复合物是双特异性抗体。在一些实施方案中,双特异性抗体由两条不同的轻链和共同的重链构成。
在一些实施方案中,双特异性抗体包括人λ轻链和人κ轻链。
在一些实施方案中,双特异性抗体包括第一和第二抗原结合区,各自包含至少一个互补决定区(cdr)。在一些实施方案中,第一和第二抗原结合区各自包含至少两个cdr。在一些实施方案中,第一和第二抗原结合区各自包含三个cdr。在一些实施方案中,cdr来自免疫球蛋白重链。在一些实施方案中,重链是人重链。在一些实施方案中,cdr来自λ轻链。在一些实施方案中,cdr来自κ轻链。
在一些实施方案中,第一抗原结合区包含第一免疫球蛋白重链可变结构域,和第二抗原结合区包含第二免疫球蛋白重链可变结构域。
在一些实施方案中,第一和第二免疫球蛋白重链可变结构域独立地包含人cdr、小鼠cdr、大鼠cdr、兔cdr、猴cdr、猿cdr、合成的cdr和/或人源化的cdr。在一些实施方案中,cdr是人的,并且是体细胞突变的。
在一些实施方案中,双特异性抗体包含人框架区(fr)。在一些实施方案中,人fr是体细胞突变的人fr。
在一些实施方案中,双特异性抗体通过筛选包含抗体可变区的噬菌体文库对目的抗原的反应性来获得。
在一些实施方案中,双特异性抗体的第一和/或第二抗原结合区通过用目的抗原免疫非人动物例如小鼠、大鼠、兔、猴或猿,和鉴定编码目的抗原特异性可变区的抗体可变区核酸序列来获得。
在一些实施方案中,双特异性抗体是全人双特异性抗体和对每个表位具有独立地在微摩尔、纳摩尔或皮摩尔范围内的亲和力。
在一些实施方案中,双特异性抗体在人中是无免疫原性的,或基本上无免疫原性的。在一些实施方案中,双特异性抗体缺少非天然人t-细胞表位。在一些实施方案中,ch1区的修饰在人中是无免疫原性的或基本上无免疫原性的。
在一些实施方案中,抗原结合蛋白包含重链,其中重链在人中是无免疫原性的或基本上无免疫原性的。
在一些实施方案中,重链具有不包含非天然t-细胞表位的氨基酸序列。在一些实施方案中,重链包含氨基酸序列,其蛋白水解不能形成在人中具有免疫原性的约9个氨基酸的氨基酸序列。在特别的实施方案中,所述人是用抗原结合蛋白治疗的人。在一些实施方案中,重链包含氨基酸序列,其蛋白水解不能形成在人中具有免疫原性的约13-约17个氨基酸的氨基酸序列。在特别的实施方案中,所述人是用抗原结合蛋白治疗的人。
在一些实施方案中,超过一种蛋白质复合物被共表达。在一些实施方案中,超过一种抗体被共表达。
附图简述
图1是描述在λ轻链中引入以调节其表达的突变的图示。vlcl2,野生型序列;vlcl2_0,优化的序列;vlcl2_1、vlcl2_2、vlcl2_3,具有增加水平的去优化的序列。
图2是显示在生产peak细胞的上清液中获得的igg1抗体的浓度的图,其使用octet技术测量。
图3a是全部纯化的igg的hic曲线的图。
图3b是显示对于不同的构建体并来自hic曲线的单特异性κ抗体、单特异性λ抗体和双特异性igg的不同百分比的图。
图4是显示在用captureselectiggfcxl树脂亲和纯化后单克隆和双特异性抗体的表达的等电点聚焦聚丙烯酰胺凝胶。
图5是显示来自数个cho细胞池的不同构建体的总igg生产力的一系列图。
图6a是监测在还原和变性条件下来自纯化的igg的重链和轻链大小的agilent蛋白质80芯片运行的凝胶样图示。
图6b是显示对于各构建体,对于数个cho池的总κ和λ轻链的比率的图。
图7是显示通过数个cho细胞池表达的单一κ、单一λ和双特异性抗体的%分布的一系列图。
图8是描述elisa结果的图,其表明双特异性抗体的每个臂对两个靶标(hcd19和hcd47)以及不相关对照蛋白(hil6r)的特异性结合。
详细描述
在细菌、酵母、昆虫、植物或哺乳动物细胞中的重组表达对于生产用于研究以及治疗应用的蛋白质而言是重要的。最近,通过优化多个参数例如培养基组成、发酵参数以及用于驱动编码目的重组蛋白质的基因的表达的构建体的优化,在中国仓鼠卵巢细胞中的重组蛋白质表达收率已显著提高。这些包括转录和翻译水平以及mrna二级结构和稳定性的改进。另一个重要因素是密码子选择的优化,使得其匹配表达宿主和避免由于低丰度trna导致的限制。优化方法还可包括除去序列重复、杀伤基序(killermotif)和剪接位点,并避免稳定的rna二级结构。密码子选择和gc含量可同时改变以在cho细胞或其它宿主细胞中表达。这样的改变的目的是使rna的翻译和稳定性最大化,使得所需多肽的翻译和因此表达程度最大。
一些蛋白质由若干多肽构成,这些多肽可缔合成可共价或非共价连接的复合物。抗体是这类蛋白质的实例,因为它们由通过二硫键连接的四个多肽构成(即,两条重链和两条轻链)。抗体带有由fab部分驱动的对靶标抗原的独特的特异性,同时它们可通过它们的fc部分参与免疫。癌症的许多目前使用的生物学治疗剂是针对靶癌症细胞过表达的抗原的单克隆抗体。当这样的抗体结合肿瘤细胞时,可触发数个过程,例如抗体依赖性细胞毒性(adcc)、抗体依赖性细胞吞噬或补体依赖性细胞毒性(cdc)。由于它们的商业和治疗重要性,抗体在cho细胞中的表达已成为强烈努力优化的主题,目的为使构成抗体的两种链的表达最大化。然而,在抗体之间可观察到大的差异,因为表达水平可变化达200倍。表达水平通过数个因素确定,包括轻链合成的水平以及重链和轻链的装配相容性。似乎高表达的轻链对于完整抗体的总体分泌速率是有利的(strutzenberger等,changesduringsubclonedevelopmentandageingofhumanantibody-producingrecombinantchocells,j.biotechnol.,vol.69(2-3):215-16(1999))。事实上,轻链表达减少导致重链在内质网中积聚和限制生产力。
用单克隆抗体靶向或中和单一蛋白质并不总是足以实现功效,和这限制了单克隆抗体的治疗用途。日益清楚的是,在许多疾病中,生物系统的一种组分的中和不足以提供有益效果。因此,已经开发了能够结合超过一种抗原的多特异性抗体,例如,双特异性抗体。已经描述了大量的双特异性抗体形式,和迄今为止两种双特异性抗体已被批准,同时许多其它双特异性抗体目前处于临床试验(kontermannre,brinkmannu.,bispecificantibodies,drugdiscovertoday,(2015),可获自dx.doi.org/10.1016/j.drudis.2015.02.2008)。在许多情况下,双特异性抗体由超过两种多肽构成。正确装配可基于链的随机配对,形成分子的混合物,可从其中纯化双特异性抗体。或者,链的界面可经改造,使得可优选获得需要的配对。在任何情况下,多种链的共表达意味着较高的复杂性,构成双特异性分子的链的相对表达速率和因此丰度可潜在地对总体收率和装配效率具有大的影响。
之前的优化方法目的在于增加多肽的表达水平,以实现更高的生产收率。在由多种多肽构成的蛋白质复合物的情况下,不平衡的表达可限制需要的分子的装配,促进不需要的产物的生产和限制总体生产收率。
本公开内容的方法通过调节装配蛋白质复合物所需的各组分的表达水平来改进所述复合物的表达。本公开内容的方法有效地限制优势链的表达,因此平衡它们的相对丰度。本文公开的方法导致在瞬时表达系统中以及在稳定转染的cho细胞中生产力和最终的双特异性收率显著增加。因此,减少一种或数种多肽的表达可导致生产力总体增加。
表1是描述用不同的序列优化产生的构建体和去优化水平的表格。
表1
使用的序列显示在下表1.1、1.2和1.3中。
表1.1.vhchwt(seqidno:1)和vhchopt(seqidno:2)序列
表1.2.vkckwt(seqidno:3)和vkckopt(seqidno:4)序列
表1.3.vlcl2wt(seqidno:5,显示在比对的第1行)、vlcl2opt(seqidno:6,显示在比对的第2行)、vlcl2deopt_1(seqidno:7,显示在比对的第3行)、vlcl2deopt_2(seqidno:8,显示在比对的第4行)和vlcl2deopt_3(seqidno:9,显示在比对的第5行)序列
表2是显示各构建体的以下数据的表格:总igg和纯化后的双特异性抗体量,以及通过hic测定的双特异性的比例。
表2
表3描述了对于各构建体,对于代表性的池,来自cho细胞培养上清液的总igg生产力、蛋白质a纯化后的双特异性%(通过hic)和纯化的双特异性的量。
表3
在本文提供的方法中使用的多核苷酸和其构建体可通过本领域技术人员已知的许多不同的方案经合成产生。合适的多核苷酸构建体使用标准重组dna技术纯化,例如描述于sambrook等,molecularcloning:alaboratorymanual,2nded.,(1989)coldspringharborpress,coldspringharbor,ny和在unitedstatesdept.ofhhs,nationalinstituteofhealth(nih)guidelinesforrecombinantdnaresearch中描述的现行规程下。
还提供了包含插入至载体中的本文所述的核酸的构建体,其中这样的构建体可用于许多不同的筛选应用,如下文更详细描述的。在一些实施方案中,单一载体(例如,质粒)包含单一肽展示支架的核酸编码序列。在其它实施方案中,单一载体(例如,质粒)包含两个或更多个肽展示支架的核酸编码序列。
可制备和使用病毒和非病毒载体,包括质粒,其提供生物感受器编码dna的复制和/或在宿主细胞中的表达。载体的选择将取决于需要繁殖的细胞的类型和繁殖目的。某些载体可用于扩增和制备大量的所需dna序列。其它载体适合于在培养的细胞中表达。另外其它的载体适合于在完整动物或人的细胞中转化和表达。合适的载体的选择完全在本领域的技能内。许多这样的载体可市售获得。为了制备构建体,将部分或全长的多核苷酸插入载体中,通常通过dna连接酶连接至载体中的被切割的限制酶位点。或者,需要的核苷酸序列可通过体内同源重组插入。通常,这通过在所需的核苷酸序列的侧翼上将同源性区域连接至载体来实现。同源性区域例如通过寡核苷酸的连接,或使用引物通过聚合酶链反应加入,所述引物包含同源性区域和所需核苷酸序列的一部分。
还提供了可尤其用于合成肽展示支架应用的表达盒或系统。对于表达,由本公开内容的多核苷酸编码的基因产物在任何常规表达系统中表达,包括例如细菌、酵母、昆虫、两栖动物和哺乳动物系统。合适的载体和宿主细胞描述于美国专利号5654173。在表达载体中,在合适时,多核苷酸与调节序列连接以获得所需的表达性质。这些调节序列可包括启动子(在有义链的5'端或反义链的3'端连接)、增强子、终止子、操纵基因、阻抑物和诱导物。启动子可以是调节型的或组成型的。在一些情况下,可能需要使用条件活性启动子,例如组织特异性或发育阶段特异性启动子。这些使用上文对于连接至载体所描述的技术与所需的核苷酸序列连接。可使用本领域已知的任何技术。换句话说,表达载体提供:转录和翻译起始区,其可以是诱导型或组成型的,其中编码区在转录起始区的转录控制下可操作连接;和转录和翻译终止区。这些控制区对于从中获得核酸的物种可以是天然的,或可以源自外源来源。
适合使用的真核启动子包括但不限于以下:小鼠金属硫蛋白i基因序列的启动子(hamer等,j.mol.appl.gen.1:273-288,1982);疱疹病毒的tk启动子(mcknight,cell31:355-365,1982);sv40早期启动子(benoist等,nature(london)290:304-310,1981);酵母gall基因序列启动子(johnston等,proc.natl.acad.sci.(usa)79:6971-6975,1982);silver等,proc.natl.acad.sci.(usa)81:5951-59ss,1984),cmv启动子,ef-1启动子,蜕皮激素-应答启动子,四环素-应答启动子等。
此外,启动子可以是组成型或调节型的。可诱导元件是与启动子结合起作用并且可结合阻抑物(例如,大肠杆菌中的laco/laciq阻抑系统)或诱导物(例如,酵母中的gall/gal4诱导系统)的dna序列元件。在这样的情况下,转录实质上被“关闭”,直到启动子被阻抑或诱导,此时转录被“打开”。
表达载体通常具有位于启动子序列附近的合宜的限制位点,以提供编码异源蛋白质的核酸序列的插入。可存在在表达宿主中有效的可选择标志物。表达载体可特别用于下文更详细描述的筛选方法。
可制备包含转录起始区、基因或其片段和转录终止区的表达盒。在引入dna后,包含构建体的细胞可通过可选择标志物进行选择,扩增细胞,然后用于表达。
上述表达系统可根据常规方法用于原核生物或真核生物,取决于表达的目的。在一些实施方案中,单细胞生物,例如大肠杆菌、枯草芽孢杆菌、酿酒酵母、昆虫细胞结合杆状病毒载体,或高等生物例如脊椎动物的细胞,例如,cos7细胞、hek293、cho、爪蟾卵母细胞等,可用作表达宿主细胞。在其它情况下,需要使用真核细胞,其中表达的蛋白质将获益于天然折叠和翻译后修饰。
特别的目的表达系统包括细菌、酵母、昆虫细胞和哺乳动物细胞来源的表达系统。细菌中的表达系统包括描述于chang等,nature(1978)275:615;goeddel等,nature(1979)281:544;goeddel等,nucleicacidsres.(1980)8:4057;ep0036776;美国专利号4551433;deboer等,proc.natl.acad.sci.(usa)(1983)80:21-25;和siebenlist等,cell(1980)20:269中的那些。
哺乳动物表达按dijkema等,emboj.(1985)4:761,gorman等,proc.natl.acad.sci.(usa)(1982)79:6777,boshart等,cell(1985)41:521和美国专利号4399216中所述进行。哺乳动物表达的其它特征按ham和wallace,meth.enz.(1979)58:44,barnes和sato,anal.biochem.(1980)102:255,美国专利号4767704、4657866、4927762、4560655、wo90/103430、wo87/00195和u.s.re30985中所述进行。
如本领域技术人员将理解的,适合使用的宿主细胞的类型可广泛变化。在一些实施方案中,细胞是细菌细胞、酵母细胞或哺乳动物细胞。在一些实施方案中,生物实体是细菌细胞。在一些实施方案中,细菌细胞是大肠杆菌、宋内志贺菌(shigellasonnei)、痢疾志贺菌(shigelladysenteriae)、弗氏志贺菌(shigellaflexneri)、伤寒沙门菌(salmonellatyphii)、鼠伤寒沙门菌(salmonellatyphimurium)、肠道沙门菌(salmonellaenterica)、产气肠杆菌(enterobacteraerogenes)、粘质沙雷菌(serratiamarcescens)、鼠疫耶尔森菌(yersiniapestis)、蜡样芽胞杆菌(bacilluscereus)、枯草芽孢杆菌(bacillussubtilis)或肺炎克雷伯杆菌(klebsiellapneumoniae)。
构建体可通过由本领域技术人员实施的任何一种标准方法引入宿主细胞,以产生本公开内容的细胞系。核酸构建体可例如用阳离子脂质(goddard等,genetherapy,4:1231-1236,1997;gorman等,genetherapy4:983-992,1997;chadwick等,genetherapy4:937-942,1997;gokhale等,genetherapy4:1289-1299,1997;gao和huang,genetherapy2:710-722,1995,其所有通过引用结合到本文中),使用病毒载体(monahan等,genetherapy4:40-49,1997;onodera等,blood91:30-36,1998,其所有通过引用结合到本文中),通过“裸dna”的摄取等递送。
定义
除非另外定义,结合本公开内容使用的科学和技术术语应具有本领域普通技术人员通常理解的含义。此外,除非上下文另外要求,单数术语应包括复数,和复数术语应包括单数。通常,结合本文描述的细胞和组织培养、分子生物学和蛋白质和寡或多核苷酸化学和杂交使用的命名法和其中的技术是本领域众所周知和通常使用的那些。标准技术用于重组dna和寡核苷酸合成,以及组织培养和转化(例如,电穿孔、脂质转染)。酶促反应和纯化技术根据制造商的说明书或按本领域通常实现或本文所述的进行。前述技术和程序通常按照本领域众所周知的常规方法和按本说明书全文中引用和论述的各种一般性和较具体的参考资料描述的进行。参见例如,sambrook等molecularcloning:alaboratorymanual(2ded.,coldspringharborlaboratorypress,coldspringharbor,n.y.(1989))。结合本文描述的分析化学、合成有机化学和医学和药物化学使用的命名法,以及其中的实验室程序和技术是本领域众所周知和通常使用的那些。标准技术用于化学合成、化学分析、药物制备、配制、递送和治疗患者。
如根据本公开内容所使用的,除非另外指明,以下术语应理解为具有以下含义:
本文提及的术语“多核苷酸”意指至少10个碱基长的聚合物形式的核苷酸,其为核糖核苷酸或脱氧核苷酸,或任一类型的核苷酸的修饰形式。该术语包括单链和双链形式的dna。
术语“多肽”在本文中用作一般性术语,是指具有多肽序列的天然蛋白质、片段或突变体。因此,天然蛋白质片段和突变体是多肽种类的物质。根据本公开内容的优选的多肽包括细胞因子和抗体。
如本文使用的,术语“抗体”是指免疫球蛋白分子和免疫球蛋白(ig)分子的免疫活性部分,即,包含特异性结合抗原(与其发生免疫反应)的抗原结合位点的分子。这样的抗体包括但不限于多克隆、单克隆、嵌合、单链、fab、fab’和f(ab')2片段和在fab表达文库中的抗体。所谓的“特异性结合”或“与其发生免疫反应”意指抗体与所需抗原的一个或多个抗原决定簇起反应,和不与其它多肽起反应(即结合)或以低得多亲和力(kd>10-6)与其它多肽结合。
已知基本抗体结构单位包含四聚体。每个四聚体由两个相同的多肽链对构成,每对具有一条“轻”链(约25kda)和一条“重”链(约50-70kda)。每条链的氨基末端部分包括约100-110或更多个氨基酸的可变区,主要负责抗原识别。每条链的羧基末端部分定义了恒定区,主要负责效应子功能。人轻链分类为κ和λ轻链。重链分类为μ、δ、γ、α或ε,和分别定义了作为igm、igd、igg、iga和ige的抗体同种型。在轻链和重链内,可变区和恒定区通过约12或更多个氨基酸的“j”区连接,其中重链还包括约10或更多个氨基酸的“d”区。通常参见fundamentalimmunologych.7(paul,w.,ea.,2nded.ravenpress,n.y.(1989))。每个轻链/重链对的可变区形成抗体结合位点。
本文使用的术语“单克隆抗体”(mab)或“单克隆抗体组合物”是指一群抗体分子,其仅包含一个分子种类的抗体分子,由独特的轻链基因产物和独特的重链基因产物组成。特别是,单克隆抗体的互补决定区(cdr)在该群的所有分子中是相同的。mab包含能够与抗原的特定表位发生免疫反应的抗原结合位点,特征为对其具有独特的结合亲和力。
通常,从人获得的抗体分子涉及类型igg、igm、iga、ige和igd的任何一种,其彼此不同之处在于分子中存在的重链的性质。某些类别还具有亚类,例如igg1、igg2等。此外,在人中,轻链可以是κ链或λ链。
本文使用的术语“其片段”应意指多核苷酸序列或多肽序列的区段,其小于完整序列的长度。本文使用的片段包含功能和非功能区。来自不同的多核苷酸或多肽序列的片段经交换或组合,以产生杂合体或“嵌合”分子。片段还用于调节多肽与多核苷酸序列或其它多肽的结合性质。
本文使用的术语“启动子序列”应意指包含控制转录起始和速率的基因区的多核苷酸序列。启动子序列包含rna聚合酶结合位点以及用于其它正和负调节元件的结合位点。正调节元件在启动子序列的控制下促进基因的表达。负调节元件在启动子序列的控制下阻抑基因的表达。本文使用的启动子序列存在于所调节的基因的上游或中间。具体地,相对于“第二启动子序列”的术语“第一启动子序列”是指启动子序列在表达载体内的相对位置。第一启动子序列在第二启动子序列的上游。
本文使用的术语“选择基因”应意指编码在给定的培养条件下对于细胞存活所必需的多肽的多核苷酸序列。如果细胞成功地掺入带有目的基因以及选择基因的表达载体,则细胞将产生允许其在敌对培养条件下选择性存活的要素。“选择的”细胞是在选择性压力下存活并且必须已掺入表达载体的那些。本文使用的术语“选择性压力”应意指添加要素至细胞培养基,其抑制未接受dna组合物的细胞的存活。
本文使用的术语“内源基因”应意指在细胞的基因组序列中包含的基因。本文使用的术语“外源基因”应意指在细胞的基因组序列中不包含的基因。外源基因通过本发明的方法引入细胞。本文使用的术语“转基因”应意指已经从一种生物转移至另一种生物的基因。
如本文使用的,二十种常规氨基酸和它们的缩写遵循常规用法。参见immunology-asynthesis(2ndedition,e.s.golub和d.r.gren,eds.,sinauerassociates,sunderlandmass.(1991))。二十种常规氨基酸的立体异构体(例如,d-氨基酸)、非天然氨基酸例如α-,α-二取代的氨基酸、n-烷基氨基酸、乳酸和其它非常规的氨基酸也可以是本公开内容的多肽的合适组分。非常规的氨基酸的实例包括:4羟基脯氨酸、γ-羧基谷氨酸、ε-n,n,n-三甲基赖氨酸、ε-n-乙酰基赖氨酸、o-磷酸丝氨酸、n-乙酰基丝氨酸、n-甲酰基甲硫氨酸、3-甲基组氨酸、5-羟基赖氨酸、σ-n-甲基精氨酸和其它类似的氨基酸和亚氨基酸(例如,4-羟基脯氨酸)。在本文使用的多肽表示法中,根据标准用法和惯例,左手方向是氨基端方向,和右手方向是羧基端方向。
类似地,除非另外说明,单链多核苷酸序列的左手端是5'端,双链多核苷酸序列的左手方向被称为5'方向。新生rna转录物的5'至3'添加方向被称为转录方向,在dna链上具有与rna相同序列和相对于rna转录物的5'端为5'的序列区被称为“上游序列”,在dna链上具有与rna相同序列和相对于rna转录物的3'端为3'的序列区被称为“下游序列”。
沉默或保守氨基酸置换是指具有类似侧链的残基的可交换性。例如,一组具有脂肪族侧链的氨基酸是甘氨酸、丙氨酸、缬氨酸、亮氨酸和异亮氨酸;一组具有脂肪族羟基侧链的氨基酸是丝氨酸和苏氨酸;一组具有含酰胺的侧链的氨基酸是天冬酰胺和谷氨酰胺;一组具有芳香族侧链的氨基酸是苯丙氨酸、酪氨酸和色氨酸;一组具有碱性侧链的氨基酸是赖氨酸、精氨酸和组氨酸;和一组具有含硫侧链的氨基酸是半胱氨酸和甲硫氨酸。优选的保守氨基酸置换组为:缬氨酸-亮氨酸-异亮氨酸、苯丙氨酸-酪氨酸、赖氨酸-精氨酸、丙氨酸-缬氨酸、谷氨酸-天冬氨酸和天冬酰胺-谷氨酰胺。
沉默或保守的置换是在涉及其侧链的氨基酸家族内发生的那些。遗传编码的氨基酸通常分为以下家族:(1)酸性氨基酸是天冬氨酸、谷氨酸;(2)碱性氨基酸是赖氨酸、精氨酸、组氨酸;(3)非极性氨基酸是丙氨酸、缬氨酸、亮氨酸、异亮氨酸、脯氨酸、苯丙氨酸、甲硫氨酸、色氨酸;和(4)不带电荷的极性氨基酸是甘氨酸、天冬酰胺、谷氨酰胺、半胱氨酸、丝氨酸、苏氨酸、酪氨酸。亲水性氨基酸包括精氨酸、天冬酰胺、天冬氨酸、谷氨酰胺、谷氨酸、组氨酸、赖氨酸、丝氨酸和苏氨酸。疏水性氨基酸包括丙氨酸、半胱氨酸、异亮氨酸、亮氨酸、甲硫氨酸、苯丙氨酸、脯氨酸、色氨酸、酪氨酸和缬氨酸。其它氨基酸家族包括(i)丝氨酸和苏氨酸,其为脂肪族羟基家族;(ii)天冬酰胺和谷氨酰胺,其为含酰胺家族;(iii)丙氨酸、缬氨酸、亮氨酸和异亮氨酸,其为脂肪族家族;和(iv)苯丙氨酸、色氨酸和酪氨酸,其为芳香族家族。例如,可合理地预期,单独置换亮氨酸为异亮氨酸或缬氨酸,天冬氨酸为谷氨酸,苏氨酸为丝氨酸,或氨基酸类似置换为结构相关的氨基酸,对得到的分子的结合或性质不具有大的影响,特别是如果置换不涉及框架位点内的氨基酸。氨基酸变化是否产生功能肽可通过测定多肽衍生物的特异性活性而容易地确定。测定法在本文详细描述。抗体或免疫球蛋白分子的片段或类似物可由本领域技术普通人员容易地制备。片段或类似物的优选的氨基和羧基端存在于功能结构域的边界附近。结构和功能结构域可通过比较核苷酸和/或氨基酸序列数据与公开或专有的序列数据库来鉴定。优选地,计算机比较方法用于鉴定在已知结构和/或功能的其它蛋白质中存在的序列基序或预测的蛋白质构象结构域。鉴定折叠成已知三维结构的蛋白质序列的方法是已知的。bowie等science253:164(1991)。因此,前述实例证实了本领域技术人员可识别序列基序和结构构象,其可用于定义根据本公开内容的结构和功能结构域。
沉默或保守氨基酸置换不应显著改变母体序列的结构特征(例如,置换氨基酸不应趋于打开在母体序列中存在的螺旋,或破坏母体序列特有的其它类型的二级结构)。公认的多肽二级和三级结构的实例描述于proteins,structuresandmolecularprinciples(creighton,ed.,w.h.freemanandcompany,newyork(1984));introductiontoproteinstructure(c.branden和j.tooze,eds.,garlandpublishing,newyork,n.y.(1991));和thornton等nature354:105(1991)。
本文的其它化学术语根据本领域的常规用法使用,如themcgraw-hilldictionaryofchemicalterms(parker,s.,ed.,mcgraw-hill,sanfrancisco(1985))所例示。
实施例
实施例1.在λ轻链中引入以在哺乳动物细胞中进行密码子优化和去优化的突变
抗-cd19x抗-cd47双特异性抗体44是基于κλ-体技术,其由共同的重链和两条不同的轻链构成。这些链由质粒构建体44编码(表1)。当该表达质粒转染至哺乳动物细胞时,通过三种链的随机装配产生三种分子:单特异性iggκ(包含两条相同的κ轻链)、单特异性iggλ(包含两条相同的λ轻链)和双特异性iggκλ(包含一条κ轻链和一条λ轻链)。如果两种轻链以相同的速率表达和同等装配,三种分子的理论比率应该是25%iggκ、25%iggλ和50%iggκλ。在构建体44的情况下,存在λ轻链的偏好表达,这导致亚最佳的双特异性抗体表达和收率。为了改进这种情况,已进行不同的链的优化以及去优化以调节链的相对比率。
用geneoptimizer®软件(geneart)对重链、κ和λ链进行密码子优化。通过克隆优化的或未优化的链至编码双特异性抗体44的野生型质粒,产生不同的候选物。
对过量表达的λ链进行三个不同水平的密码子去优化。产生三个构建体(3、13和19去优化的λ链),和与优化的重链和κ链组合。不同程度的去优化应用于λ轻链。构建体3、13和19包含去优化程度渐进的序列(分别为vlcl2-1、vlcl2-2和vlcl2-3,见图1)。还产生含优化的λ链的构建体17和15(表1)。
实施例2.克隆和表征在peak细胞中表达的igg
共同的重链和两种轻链(一种κ和一种λ)野生型、优化的或去优化的密码子在三个独立的cmv启动子下克隆至单一哺乳动物表达pnovi载体。在序列验证后,各构建体的igg生产力在peak细胞中使用lipofectamine2000,通过两次独立的瞬时转染评价。转染后7天,总igg表达通过octet技术评价。关于总igg生产力,除了候选物15外,在候选物之间没有观察到大的差异。对于构建体15观察到生产力降低的趋势,其中所有链已被优化(图2)。在peak细胞中生产10天后,总igg在fcxl树脂上纯化。
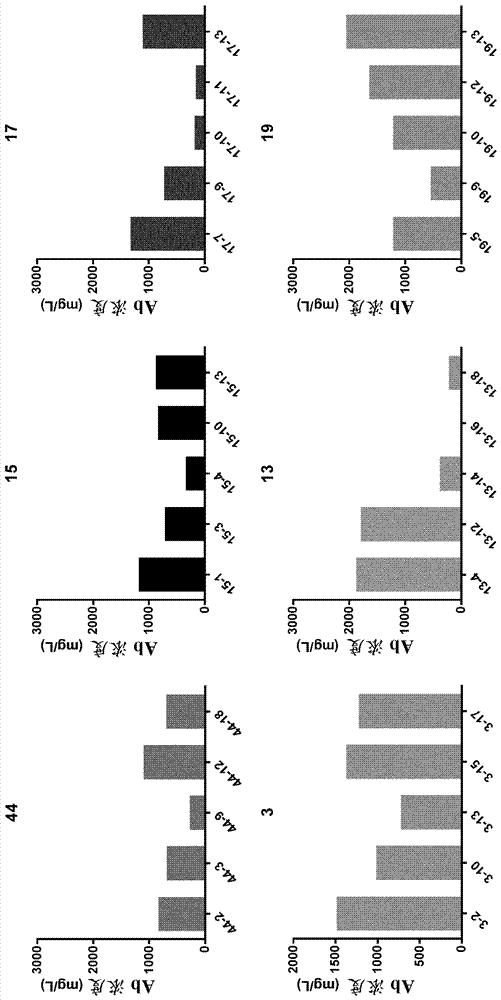
三个不同形式的igg即单特异性λ、单特异性κ和双特异性抗体的分布通过hic-hplc分析,使用propachic-10柱(dionex)测定(图3a)。应用流动相a(0.001m磷酸盐缓冲液+1m硫酸铵,ph3.5)从85%至35%的梯度,和流动相b(0.001m磷酸盐缓冲液+乙腈10%,ph3.5)从15%至100%的逐渐增加的梯度。用流动相a,ph7进行空白。hic面积峰值的分析(图3b)表明,与野生型44和优化的15和17相比,对于去优化的候选物3、13和19,双特异性百分比增加的趋势。对于3、13和19,单特异性κ和λ的比率显著不同于44。
还进行ief7-11%以评价总igg的分布(图4)。具有λ优化的候选物表明与克隆44相比,单特异性λ增加,和较低的单特异性κ和双特异性。候选物3、13和19表明单特异性κ和双特异性的显著增加。
表2概述了对于在peak细胞中表达的候选物获得的数据。对于候选物3、13和19,最终获得的双特异性百分比更高,其中双特异性比率从对于44的21.6%增加至对于候选物13的42.9%。引人注意的是,最高密码子去优化(构建体19)水平的λ链增加了双特异性抗体的生产力。
实施例3.在稳定转染的cho细胞中的igg表达
在通过电穿孔转染和用msx选择后,通过facs进行筛选。选择最高产生池以在分批进料条件下生产。通过octet技术评价不同池的总igg生产力(图5)。在通过蛋白质a纯化后,不同链的比率通过在agilent蛋白质80芯片上电泳进行评价,其在还原和变性条件下监测重链和轻链大小。
如agilent分析所示的(图6a),对于44,λ链比κ链被更多呈现。对于数个cho池,构建体3和13改进了两种轻链之间的平衡。随着λ链的去优化增加,当与初始构建体比较时比率被逆转(44对比19)。这通过计算两种轻链之间的比率证实(图6b)。因此,两种轻链之间的平衡,对于44而言其有利于λ链,被逐渐逆转,与去优化水平有关。当分析所有生产池时,在候选物13、19和候选物44之间可观察到显著的差异,其中κ轻链更多和λ轻链更少。根据这些结果,候选物3和13应显示bsab表达增加,因为两种轻链以更相等的水平表达。在通过蛋白质a纯化后,通过hic评价所有igg生产池的不同形式的igg的比率(图7)。数据显示,单特异性λ的水平随去优化水平逐渐降低,和对于单特异性κ观察到逆转模式。对于构建体3和13,双特异性水平达到最大约40%,具有非常均质的分布。相比之下,两种链之一的不平衡表达(如在44或19中)导致降低水平的双特异性生产。
为了证实针对其靶标的特异性结合,通过elisa评价所有候选物与hcd19和hcd47的结合(图8)。双特异性抗体的两种特异性靶标和不相关蛋白质(2µg/ml,在pbs中)在4℃在96-孔链霉亲和素包被的微量滴定板中包被过夜。在用pbs0.05%(v/v)tween(pbst)洗涤三次后,以2µg/ml在pbst1%bsa中稀释的纯化的抗体在37℃在板中温育30min。用pbst洗涤各孔三次,然后加入第二抗体(与辣根过氧化物酶偶联的抗人iggfc)和在37℃温育1h。四甲基联苯胺用于展现elisa和用硫酸封闭。读出450nm的吸光度。
各候选物的表达按比例放大,和在10天后收获上清液和通过以1300g离心10min澄清。纯化过程由三个亲和步骤组成。首先,将captureselectigg-ch1亲和基质(lifetechnologies)用pbs洗涤,然后加入至澄清的上清液。在4℃温育过夜后,将上清液以1000g离心10min,弃去上清液,和用pbs洗涤树脂两次。然后,将树脂转移至旋转柱,和包含50mm甘氨酸的溶液(ph2.7)用于洗脱。
收集数个洗脱流分,合并和使用50kdaamiconultracentrifugal滤器装置(merckkgaa)针对pbs脱盐。将终产物(包含来自上清液的全部人igg)使用nanodrop分光光度计(nanodroptechnologies,wilmington,de)定量,和在室温和20rpm下用合适体积的κselect亲和树脂(gehealthcare)温育15min。温育、树脂回收、洗脱和脱盐步骤按之前所述进行(fischer等,naturecomms.2015)。最后的亲和纯化步骤使用lambdafabselect亲和树脂进行。来自cho细胞池的总igg、通过hic测量的双特异性抗体百分比和纯化的双特异性生产力概述于表3。数据表明λ链的去优化和减少表达导致总igg生产力和双特异性产物的增加。优化方法导致双特异性抗体2.5倍的收率增加。
- 还没有人留言评论。精彩留言会获得点赞!