仲醇的氧化和胺化的制作方法
本申请是申请日为2012年7月27日的中国专利申请201280048033.2“仲醇的氧化和胺化”的分案申请。本发明涉及包括下述步骤的方法:a)提供仲醇,b)通过与nad(p)+依赖性的醇脱氢酶接触氧化所述仲醇,和c)使步骤a)的氧化产物与转氨酶接触,其中所述nad(p)+依赖性的醇脱氢酶和/或所述转氨酶是重组的或分离的酶,涉及用于施行所述方法的全细胞催化剂,和涉及这样的全细胞催化剂用于氧化仲醇的用途。
背景技术:
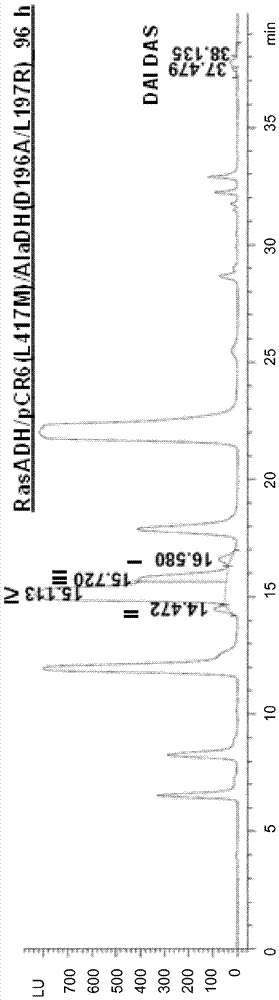
:胺类被用作化学工业的众多产品(诸如环氧树脂、聚氨酯泡沫、异氰酸酯和尤其是聚酰胺)的合成基石。后者是以重复的酰胺基为特征的一类聚合物。与化学上有关的蛋白不同,术语“聚酰胺”通常涉及合成的、商购可得的热塑性塑料。聚酰胺衍生自伯胺或仲胺,其通常在烃裂解中得到。但是,也可以使用衍生物,更精确地讲,氨基羧酸、内酰胺和二胺,用于聚合物的生产。另外,短链气态烷烃作为原料是令人感兴趣的,其可以用生物技术方法从再生原料起始得到。许多在商业上具有巨大需求的聚酰胺是从内酰胺起始制备。例如,“聚酰胺6”可以通过聚合ε-己内酰胺得到,而“聚酰胺12”可以通过聚合月桂内酰胺得到。其它商业上感兴趣的产物包括内酰胺的共聚物,例如ε-己内酰胺和月桂内酰胺的共聚物。胺类的常规化学工业生产依赖于化石原料的供给,是低效的,且在该过程中产生大量不希望的副产物,在某些合成步骤中最高达80%。这样的方法的一个例子是月桂内酰胺的制备,其通常通过丁二烯的三聚化而得到。氢化该三聚化产物环十二碳三烯,并将由此产生的环十二烷氧化成环癸酮,其随后与羟胺反应生成环十二烷酮肟(cyclododecanonoxin),其最后经由贝克曼重排转化成月桂内酰胺。考虑到这些缺点,已经开发了使用生物催化剂从再生原料起始制备胺的方法。pct/ep2008/067447描述了使用细胞生产化学相关产物,更精确地讲ω-氨基羧酸的生物体系,所述细胞具有一系列合适的酶活性且能够将羧酸转化成相应的ω-氨基。但是,在该方法中使用的得自恶臭假单胞菌(pseudomonasputida)gpo1的alkbgt-氧化酶体系的一个已知缺点是,它不能提供使脂族烷烃生成仲醇的选择性氧化。相反,产生大化量氧化产物;尤其是,更高度氧化的产物(诸如相应的醛、酮或相应的羧酸)的比例随着反应时间增加而增加(c.grant,j.m.woodley和f.baganz(2011),enzymeandmicrobialtechnology48,480-486),这相应地降低了期望的胺的收率。技术实现要素:在该背景下,本发明的目的在于,提供使用生物催化剂氧化和胺化仲醇的改进方法。另一个目的是,如下改进所述方法,即增加收率和/或降低副产物浓度。最后,需要这样的方法,即其允许基于再生原料来生产聚酰胺或用于生产聚酰胺的原材料。所述目的和其它目的通过本申请的主题和尤其是通过附随的独立权利要求的主题得以实现,其中由从属权利要求得出实施方案。根据本发明,所述目的在第一方面由包括下述步骤的方法实现:a)提供仲醇,b)通过与nad(p)+依赖性的醇脱氢酶接触氧化所述仲醇,和c)使步骤a)的氧化产物与转氨酶接触,其中所述nad(p)+依赖性的醇脱氢酶和/或所述转氨酶是重组的或分离的酶。在所述第一方面的第一实施方案中,所述仲醇是选自以下的醇:α-羟基羧酸,环烷醇,优选双(对羟基环己基)甲烷,式r1-cr2h-cr3h-oh的醇及其醚和聚醚,和仲烷醇,优选2-烷醇,其中r1选自羟基、烷氧基、氢和胺;r2选自烷基,优选甲基、乙基和丙基,和氢;且r3选自烷基,优选甲基、乙基和丙基。在所述第一方面的第二实施方案(其也是第一实施方案的一个实施方案)中,所述仲醇是下式的仲醇h3c-c(oh)h-(ch2)x-r4,其中r4选自-oh、-sh、-nh2和-coor5,x是至少3,且r5选自h、烷基和芳基。在所述第一方面的第三实施方案(其也是第一和第二实施方案的一个实施方案)中,通过用单加氧酶羟基化所述式的相应烷烃来进行步骤a),所述单加氧酶优选地是重组的或分离的。在所述第一方面的第四实施方案(其也是第二至第三实施方案的一个实施方案)中,所述nad(p)+依赖性的醇脱氢酶是具有至少一个锌原子作为辅因子的nad(p)+依赖性的醇脱氢酶。在所述第一方面的第五实施方案(其是第一至第四实施方案的一个实施方案)中,所述醇脱氢酶是得自赤红球菌(rhodococcusruber)的醇脱氢酶a(数据库代码aj491307.1)或其变体。在所述第一方面的第六实施方案(其是第一至第五实施方案的一个实施方案)中,所述单加氧酶选自:恶臭假单胞菌的alkbgt,得自热带假丝酵母(candidatropicalis)或得自鹰嘴豆(cicerarietinum)的细胞色素p450。在所述第一方面的第七实施方案(其也是第一至第六实施方案的一个实施方案)中,所述转氨酶选自特征如下的转氨酶及其变体:在与青紫色素杆菌(chromobacteriumviolaceum)atcc12472(数据库代码np_901695)的转氨酶的val224对应的氨基酸序列的位置处,其具有选自异亮氨酸、缬氨酸、苯丙氨酸、甲硫氨酸和亮氨酸的氨基酸,且在与青紫色素杆菌atcc12472(数据库代码np_901695)的转氨酶的gly230对应的氨基酸序列的位置处,其具有除了苏氨酸以外的氨基酸,且优选选自丝氨酸、半胱氨酸、甘氨酸和丙氨酸的氨基酸,或者所述转氨酶选自:河流弧菌(vibriofluvialis)(aea39183.1)的转氨酶、巨大芽孢杆菌(bacillusmegaterium)(yp001374792.1)的转氨酶、脱氮副球菌(paracoccusdenitrificans)(cp000490.1)的转氨酶及其变体。在所述第一方面的第八实施方案(其也是第一至第七实施方案的一个实施方案)中,在分离的或重组的丙氨酸脱氢酶和无机氮源(优选氨或铵盐)存在下进行步骤b)和/或步骤c)。在所述第一方面的第九实施方案(其也是第一至第八实施方案的一个实施方案)中,在包含nad(p)+依赖性的醇脱氢酶、转氨酶、单加氧酶和丙氨酸脱氢酶的组中的至少一种酶是重组的,且以具有相应酶的全细胞催化剂的形式提供。在所述第一方面的第十实施方案(其也是第九实施方案的一个实施方案)中,所有酶以一种或多种全细胞催化剂的形式提供,其中,优选地,一种全细胞催化剂具有所有必需的酶。在所述第一方面的第十一实施方案(其也是第一至第十实施方案的一个实施方案)中,在步骤b)时,优选在步骤b)和c)时,存在有机共溶剂,其具有大于-1.38、优选-0.5至1.2、更优选-0.4至0.4的logp。在所述第一方面的第十二实施方案(其也是第十一实施方案的一个实施方案)中,所述共溶剂选自不饱和脂肪酸,优选油酸。在所述第一方面的第十三实施方案(其也是第十一实施方案的一个优选实施方案)中,所述共溶剂是式r6-o-(ch2)x-o-r7的化合物,其中r6和r7各自且彼此独立地选自:甲基、乙基、丙基和丁基,且x是1-4,其中优选r6和r7各自是甲基且x是2。根据本发明,所述目的在第二方面中通过全细胞催化剂得以实现,所述全细胞催化剂具有nad(p)+依赖性的醇脱氢酶(优选地,具有至少一个锌原子作为辅因子)、转氨酶、任选的单加氧酶和任选的丙氨酸脱氢酶,其中所述酶是重组酶,其中所述醇脱氢酶优选地识别仲醇作为优选的底物。根据本发明,所述目的在第三方面中通过根据本发明的第二方面的全细胞催化剂用于氧化和胺化仲醇的用途得以实现,所述仲醇优选式h3c-c(oh)h-(ch2)x-r1,其中r1选自-oh、-sh、-nh2和-coor2,x是至少3,且r2选自h、烷基和芳基。在第三方面的第一实施方案(其是第一实施方案的一个实施方案)中,所述用途进一步包括有机共溶剂的存在,所述有机共溶剂具有大于-1.38、优选-0.5至1.2、更优选-0.4至0.4的logp,且最优选地为二甲氧基乙烷。在第三方面的第二实施方案(其是第二实施方案的一个实施方案)中,所述共溶剂选自不饱和脂肪酸,且优选地是油酸。所述第二和第三方面的其它实施方案包括本发明的第一方面的所有实施方案。本发明的发明人已经惊讶地发现,存在一组醇脱氢酶,其可以用于形成少量副产物实现仲醇的氧化。本发明的发明人此外已惊讶地发现,存在可以使用生物催化剂将醇胺化而不形成大量副产物的酶活性级联,其中不必添加或除去还原当量。本发明的发明人此外已惊讶地发现了可以令人惊讶地使用全细胞催化剂并从再生原料出发生产聚酰胺的方法。本发明的发明人此外已惊讶地发现,事先氧化后的仲醇的胺化可以特别有利地用以某些序列特性为特征的转氨酶集合来实现。根据本发明的方法可以应用于大量的工业相关的醇。合适的是,例如,α-羟基羧酸,优选可以氧化为α-酮羧酸的那些,也就是说,式rs-c(oh)h-cooh的那些,其又可以通过胺化转化成蛋白氨基酸,具体地包括必需氨基酸诸如甲硫氨酸和赖氨酸。具体例子包括这样的酸,其中rs是选自以下的取代基:h、甲基、-(ch2)4-nh2、-(ch2)3-nh-nh-nh2、-ch2-ch2-s-ch3、-ch(ch3)2、-ch2-ch(ch3)2、-ch2-(1h-吲哚-3-基)、-ch(oh)-ch3、-ch2-苯基、-ch(ch3)-ch2-ch3。其它仲醇包括2-烷醇,例如2-丙醇、2-丁醇、2-戊醇、2-己醇等。另外,考虑多元仲醇,例如烷基二醇诸如乙二醇,烷基三醇诸如甘油和季戊四醇。其它例子包括环烷醇,优选环己醇和双(对羟基环己基)甲烷,h3c-c(oh)h-(ch2)x-r4的醇,其中r4选自-oh、-sh、-nh2和-coor5,x是至少3,且r5选自h、烷基和芳基。在醇式h3c-c(oh)h-(ch2)x-r4的醇而言的情况中,碳链的长度是可变的,且x是至少3。优选地,所述碳链具有多于3个碳原子,即x=4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20或更大。众多仲醇是商购可得的,且可以以市售形式直接使用。或者,所述仲醇可以通过生物技术预先或原位制备,例如通过用合适的烷烃氧化酶、优选单加氧酶将烷烃羟基化。对此,现有技术教导了合适的酶,例如m.w.peters等人,2003。在一个特别优选的实施方案中,在式h3c-c(oh)h-(ch2)x-r4的仲醇的情况中,r4选自-oh和-coor5,x是至少11,且r5选自h、甲基、乙基和丙基。根据本发明,在所述方法的步骤b)中,使用nad(p)+依赖性的醇脱氢酶用于氧化仲醇。在该情况下,与根据本发明使用的所有的酶活性多肽一样,其可以是包含酶活性多肽的细胞或其裂解物、或处于所有纯化阶段(从粗制的裂解物至纯的多肽)的多肽的制品。本领域技术人员已知大量可以在合适的细胞中过表达酶活性多肽并进行纯化和/或分离的方法。因而,为表达多肽,可以使用本领域技术人员可得到的所有表达体系,例如pet或pgex型的载体。可以使用色谱方法用于纯化,例如提供了标记的重组蛋白的亲和色谱使用固定化的配体的纯化,所述固定化的配体为例如在组氨酸标记的情况中镍离子、在与靶蛋白融合的谷胱甘肽-s-转移酶的情况中使用固定化的谷胱甘肽或在包含麦芽糖结合蛋白的标签的情况中使用固定化的麦芽糖。可以以可溶形式或固定化地使用经纯化的酶活性多肽。本领域技术人员已知可以将多肽共价地或非共价地固定至有机或无机固相上的合适方法,例如通过巯基偶联化学(例如得自pierce的试剂盒)。在一个优选的实施方案中,所述用作全细胞催化剂或用作表达体系的细胞是原核细胞,优选细菌细胞。在另一个优选的实施方案中,其是哺乳动物细胞。在另一个优选的实施方案中,其是低等真核细胞,优选是酵母细胞。示例性的原核细胞包括埃希氏菌属(escherichia),特别是大肠杆菌(escherichiacoli),和假单胞菌属(pseudomonas)和棒状杆菌属(corynebacterium)的菌株。示例性的低等真核细胞包括酵母属(saccharomyces)、假丝酵母属(candida)、毕赤酵母属(pichia)、耶氏酵母属(yarrowia)、裂殖酵母(schizosaccharomyces)属,特别是热带假丝酵母(candidatropicalis)、粟酒裂殖酵母(schizosaccharomycespombe)、巴斯德毕赤酵母(pichiapastoris)、解脂耶氏酵母(yarrowialipolytica)和酿酒酵母菌(saccharomycescerivisiae)菌株。所述细胞可以在质粒上包含一个或多于一个编码根据本发明使用的酶的核酸序列,或者将所述核酸序列整合进其基因组中。在一个优选的实施方案中,它包含这样的质粒,所述质粒包含编码选自nad(p)+依赖性的醇脱氢酶(优选地,具有至少一个锌原子作为辅因子)、转氨酶、单加氧酶和丙氨酸脱氢酶中的至少一种酶、优选多于一种酶、最优选所有酶的核酸序列。在一个特别优选的实施方案中,所述醇脱氢酶是含锌的nad(p)+依赖性的醇脱氢酶,即所述催化活性酶包含至少一个锌原子作为辅因子,所述锌原子通过包含半胱氨酸残基的特征序列基序与所述多肽共价结合。在一个特别优选的实施方案中,所述醇脱氢酶是嗜热脂肪芽孢杆菌(bacillusstearothermophilus)的醇脱氢酶(数据库代码p42328)或其变体。本发明的教导不仅可以使用本文描述的生物大分子的精确氨基酸序列或核酸序列来完成,而且也可以使用这样的大分子的变体来完成,所述变体可以通过一个或多于一个氨基酸或核酸的缺失、添加或置换而得到。在一个优选的实施方案中,表述核酸序列或氨基酸序列的“变体”(其在下文中与本文中使用的表述“同源体”同义地和可互换地使用)是指另一个核酸-或-氨基酸序列,考虑到相应的原始野生型-核酸-或氨基酸序列,具有70、75、80、85、90、92、94、96、98、99%或更高百分比的同源性(在这里与同一性同义使用),其中,优选地,除了形成催化活性中心的那些氨基酸或者结构或折叠必需的氨基酸以外的氨基酸被删除或置换,或者后者仅仅是保守置换,例如谷氨酸替代天冬氨酸、或亮氨酸替代缬氨酸。现有技术描述了可以用于计算2个序列的同源性程度的算法,例如arthurlesk(2008),introductiontobioinformatics,第3版。在本发明的另一个优选的实施方案中,氨基酸序列或核酸序列的所述变体,优选地除了上述的序列同源性以外,基本上具有野生型分子或原始分子的相同的酶活性。例如,作为蛋白酶的酶活性多肽的变体具有与所述多肽酶相同的或基本上相同的蛋白水解活性,即催化肽键水解的能力。在一个特别的实施方案中,表述“基本上相同的酶活性”是指显著高于背景活性或/和与相对于相同底物的野生型多肽所具有的km-和/或kcat-值相差小于3个、更优选2个、还更优选1个数量级的相对于野生型-多肽的底物的活性。在另一个优选的实施方案中,表述核酸序列或氨基酸序列的“变体”包含所述核酸-或氨基酸序列的至少一个活性部分/或片段。在另一个优选的实施方案中,本文中使用的表述“活性部分”是指这样的氨基酸序列或核酸序列,其具有小于所述氨基酸序列的整个长度的长度,或者编码比所述氨基酸序列的全长更短的长度,其中具有比野生型氨基酸序列更短长度的氨基酸序列或编码的氨基酸序列基本上具有与所述野生型多肽或其变体相同的酶活性,例如作为醇脱氢酶、单加氧酶或转氨酶。在一个特殊的实施方案中,表述核酸的“变体”是这样的核酸,其互补链,优选地在严格的条件下,结合在野生型核酸上。杂交反应的严格性可由本领域技术人员容易地确定,并且通常取决于探针的长度、洗涤过程中的温度和盐浓度。通常,较长的探针需要较高的温度才能杂交,而较短的探针需要低温。杂交是否发生通常取决于变性dna与存在于其环境中的互补链对合的能力,更精确地讲,在解链温度以下。杂交反应的严格性和相应的条件更详细地描述在ausubel等人,1995中。在一个优选的实施方案中,本文中使用的表述核酸的“变体”是编码与原始核酸相同的氨基酸序列,或者在遗传密码的简并性范围内编码该氨基酸序列的变体的任意的核酸序列。数十年来,醇脱氢酶是生物化学中与酿造发酵过程有关的受到强烈关注的且在生物技术上高度相关的生物化学酶类别,其包括多种异形体集合。因而,存在恶臭假单胞菌gpo1alkj型的膜结合的、黄素依赖性的醇脱氢酶,其使用黄素辅因子替代nad+。另一组包括含铁的、对氧敏感的醇脱氢酶,其在细菌中且以无活性形式在酵母中被发现。另一组包括nad+依赖性的醇脱氢酶,包括含锌的醇脱氢酶,其中活性中心具有半胱氨酸配位的锌原子,所述锌原子固定醇底物。在一个优选的实施方案中,将本文中使用的表述“醇脱氢酶”理解为是指将醛或酮氧化为相应的伯醇或仲醇的酶。优选地,在根据本发明的方法中的醇脱氢酶是nad+依赖性的醇脱氢酶,即使用nad+作为辅因子来氧化醇或使用nadh来还原相应的醛或酮的醇脱氢酶。在最优选的实施方案中,所述醇脱氢酶是nad+依赖性的、含锌的醇脱氢酶。合适的nad+依赖性的醇脱氢酶的例子包括醇脱氢酶。在最优选的实施方案中,所述醇脱氢酶是得自赤红球菌的醇脱氢酶a(数据库代码aj491307.1)或其变体。其它例子包括真养产碱菌(ralstoniaeutropha)(acb78191.1)、短乳杆菌(lactobacillusbrevis)(yp_795183.1)、高加索酸奶乳杆菌(lactobacilluskefiri)(acf95832.1)、马肝、泛养副球菌(paracoccuspantotrophus)(acb78182.1)和矢野口鞘氨醇杆菌(sphingobiumyanoikuyae)(eu427523.1)的醇脱氢酶以及它们各自的变体。在一个优选的实施方案中,本文中使用的表述“nad(p)+依赖性的醇脱氢酶”表示nad+-和/或nadp+依赖性的醇脱氢酶。根据本发明,在步骤c)中,使用转氨酶。在一个优选的实施方案中,本文中使用的表述“转氨酶”理解为催化α-氨基从供体(优选氨基酸)向受体分子(优选α-酮羧酸)转移的酶。在一个优选的实施方案中,所述转氨酶选自具有以下特征的转氨酶及其变体:在与青紫色素杆菌(chromobacteriumviolaceum)atcc12472的转氨酶(数据库代码np_901695)的val224对应的氨基酸序列的位置处,其具有选自异亮氨酸、缬氨酸、苯丙氨酸、甲硫氨酸和亮氨酸的氨基酸,且在与青紫色素杆菌atcc12472的转氨酶(数据库代码np_901695)的gly230对应的氨基酸序列的位置处,其具有除了苏氨酸以外的氨基酸,且优选选自丝氨酸、半胱氨酸、甘氨酸和丙氨酸的氨基酸。在一个特别优选的实施方案中,所述转氨酶选自:青紫色素杆菌dsm30191的ω-转氨酶,得自恶臭假单胞菌w619、铜绿假单孢菌(pseudomonasaeruginosa)pa01、天蓝色链霉菌(streptomycescoelicolor)a3(2)和除虫链霉菌(streptomycesavermitilis)ma4680的转氨酶。在一个优选的实施方案中,本文中使用的表述“与青紫色素杆菌atcc12472的转氨酶的氨基酸序列的位置x对应的位置”是指,在所研究的分子的比对中,显得与青紫色素杆菌atcc12472的转氨酶的氨基酸序列的位置x同源的对应位置。本领域技术人员已知众多可以用于进行氨基酸序列比对的软件包和算法。示例性的软件包方法包括由embl提供的程序包clustalw,或者列出和描述在arthurm.lesk(2008),introductiontobioinformatics,第3版中。根据本发明使用的酶优选地是重组酶。在一个优选的实施方案中,将本文中使用的表述“重组的”理解为相应的核酸分子在自然界中不存在,和/或它使用基因工程方法产生。在一个优选的实施方案中,当相应的多肽由重组核酸编码时,提及重组蛋白。在一个优选的实施方案中,将本文中使用的重组细胞理解为具有至少一个重组核酸或重组多肽的细胞。本领域技术人员已知适合用于生产重组分子或细胞的方法,例如在sambrook等人,1989中描述的那些。根据本发明的教导可以使用分离的酶和使用全细胞催化剂来实行。在一个优选的实施方案中,将本文中使用的表述“全细胞催化剂”理解为提供所期望的酶活性的完整的、存活的且有代谢活性的细胞。所述全细胞催化剂可以将要代谢的底物(在本发明的情况中,醇)或由所述底物形成的氧化产物运输进细胞内部,在此处被细胞溶质酶代谢,或者其可以将目标酶呈递到它的表面上,在此处直接暴露给培养基中的底物。本领域技术人员已知众多用于生产全细胞催化剂的体系,例如从de60216245中已知。就许多应用而言,推荐使用分离的酶。在一个优选的实施方案中,本文中使用的表述“分离的”是指,所述酶以比它的天然来源更纯和/或更浓的形式存在。在一个优选的实施方案中,如果酶是多肽酶且占相应制品的质量蛋白分数多于60、70、80、90或优选95%,则认为所述酶是分离的。本领域技术人员已知众多用于测量溶液中的蛋白的质量的方法,例如借助sds-聚丙烯酰胺凝胶上的对应蛋白带的厚度的视觉估测、nmr光谱法或基于质量-光谱测定法的方法。根据本发明的方法的酶催化反应通常在溶剂或具有高的水比例的溶剂混合物中进行,优选地在用于建立与酶活性相容的ph-值的合适缓冲体系的存在下进行。但是,在疏水性原料的情况中,特别是在具有包含多于3个碳原子的碳链的醇中,有机共溶剂的额外存在是有利的,所述有机共溶剂可以介导酶与底物的接触。一种或多于一种共溶剂以占溶剂混合物或低于溶剂混合物的95、90、85、80、75、70、65、60、55、50、45、40、35、30、25、20、15、10或5体积%的总比例存在。共溶剂的疏水性在这里起重要作用。它可以由logp表示,所述logp是正辛醇-水-分配系数的以10为底的对数。优选的共溶剂具有大于-1.38、更优选-1至+2、更优选-0.8至1.5、或-0.5至0.5、或-0.4至0.4、或-0.3至0.3、或-0.25至-0.1的logp。正辛醇-水-分配系数kow或p是指示物质在1-辛醇和水的两相体系中的浓度的比例的无量纲分配系数(参见j.sangster,octanol-waterpartitioncoefficients:fundamentalsandphysicalchemistry,wileyseriesinsolutionchemistry的第2卷,johnwiley&sons,chichester,1997)。更精确地讲,kow或p表示物质在富含辛醇的相中的浓度与其在富含水的相中的浓度之比。kow值是物质的亲脂性(脂溶性)和亲水性(水溶性)之间的比例的模型指数(modellmaß)。预见到,使用物质在辛醇-水体系中的分配系数,也能够估测该物质在具有水相的其它体系中的分配系数。如果物质可更好地溶于脂性溶剂诸如正辛醇中,那么kow大于1,如果物质可更好地溶于水中,那么kow小于1。相应地,亲脂性物质的logp为正值,亲水性物质的logp为负值。由于不能测量所有化学试剂的kow,因此存在非常多样化的预测模型,例如通过定量构效关系(qsar)或通过线性自由能关系(lfer),例如描述于eugenekelloggg,abrahamdj:hydrophobicity:islogp(o/w)morethanthesumofitsparts.eurjmedchem.2000年7-8月;35(7-8):651-61或gudrunwienke,“messungundvorausberechnungvonn-octanol/wasser-verteilungskoeffizienten”,博士论文,oldenburg大学,1-172,1993。在本申请范围内,根据advancedchemistrydevelopmentinc.,toronto的方法,借助程序模块acd/logpdb确定logp。优选的共溶剂具有大于-1.38、更优选-1至+2、还更优选-0.5至0.5、-0.4至0.4、或0至1.5的logp。在一个优选的实施方案中,所述共溶剂是式alk1-o-alk2的二烷基醚,其具有大于-1.38、更优选-1至+2、更优选0至1.5的logp,其中所述2个烷基取代基alk1和alk2各自彼此独立地选自甲基、乙基、丙基、丁基、异丙基和叔丁基。在一个特别优选的实施方案中,所述共溶剂是甲基叔丁基醚(mtbe)。在最优选的实施方案中,所述共溶剂是二甲氧基乙烷(dme)。在另一个优选的实施方案中,所述共溶剂是羧酸或脂肪酸,优选具有至少6个碳原子的脂肪酸,更优选具有至少12个碳原子的脂肪酸。所述脂肪酸可以是饱和脂肪酸,例如月桂酸、肉豆蔻酸、棕榈酸、十七烷酸、硬脂酸、花生酸或山嵛酸,或不饱和脂肪酸,例如肉豆蔻脑酸、棕榈油酸、岩芹酸、油酸、反油酸、异油酸、顺-9-二十碳烯酸、二十碳-11-烯酸或芥酸。不同脂肪酸的混合物同样是可能的,例如主要含有不饱和脂肪酸的蓝刺头油。由于并非所有的脂肪酸在室温时都是显著可溶的,可能需要求助于其它措施,例如升高温度,或者,更优选地,加入其它溶剂来使它可接近水相。在一个特别优选的实施方案中,使用脂肪酸或其酯、优选甲酯、最优选月桂酸甲酯作为这样的其它溶剂。根据本发明的酶级联可以根据本发明在丙氨酸脱氢酶存在下进行。本发明的一个特别的长处是,该构型能够实现还原当量中性的反应操作,即该反应在没有供给或除去还原当量形式的电子的情况下进行,因为在醇氧化过程中由醇脱氢酶产生的nadh在制备丙氨酸时被消耗,消耗无机氮供体,优选氨或氨源。在一个优选的实施方案中,本文中使用的表述“丙氨酸脱氢酶”理解为这样的酶:其催化l-丙氨酸的转化,消耗水和nad+,形成丙酮酸、氨和nadh。优选地,所述丙氨酸脱氢酶是细胞内的丙氨酸脱氢酶,还更优选地,细菌全细胞催化剂的重组细胞内的丙氨酸脱氢酶。在一个优选的实施方案中,将具有所有需要的活性的全细胞催化剂用于根据本发明的方法中,即nad(p)+依赖性的醇脱氢酶、转氨酶和任选的单加氧酶和/或丙氨酸脱氢酶。这样的全细胞催化剂的应用具有以下优点:以单一试剂的形式使用所有活性,并且不必大规模地准备生物活性形式的酶。适合用于构建全细胞催化剂的方法是本领域技术人员已知的,尤其是用于表达一种或多于一种重组蛋白的质粒体系的构建,或编码所需重组蛋白的dna向使用的宿主细胞的染色体dna中的整合。另外,另一发明的目的是,提供用于氧化和胺化伯醇的体系。根据本发明,该目的在第四方面中通过包括下述步骤的方法实现:a)提供下式的伯醇ho-(ch2)x-r7,其中r7选自-oh、-sh、-nh2和-coor8,x是至少3,且r8选自h、烷基和芳基,b)通过使所述伯醇与nad+-依赖性的醇脱氢酶接触来氧化所述伯醇,和c)使步骤a)的氧化产物与转氨酶接触,其中所述nad+-醇脱氢酶和/或所述转氨酶是重组的或分离的酶。在第四方面的第一实施方案中,通过用单加氧酶羟基化式h-(ch2)x-r7的烷烃而进行步骤a),所述单加氧酶优选地为重组的或分离的。在第四方面的第二实施方案(其也是第一实施方案的一个实施方案)中,所述nad+依赖性的醇脱氢酶是具有至少一个锌原子作为辅因子的nad+依赖性的醇脱氢酶。在第四方面的第三实施方案(其是第二实施方案的一个实施方案)中,所述醇脱氢酶是嗜热脂肪芽孢杆菌的醇脱氢酶(数据库代码p42328)或其变体。在第四方面的第四实施方案(其是第一个至第三实施方案的一个实施方案)中,所述单加氧酶选自:得自恶臭假单胞菌的alkbgt,得自热带假丝酵母(candidatropicalis)或得自鹰嘴豆(cicerarietinum)的细胞色素p450。在第四方面的第五实施方案(其也是第一个至第四实施方案的一个实施方案)中,所述转氨酶选自特征如下的转氨酶及其变体:在与青紫色素杆菌(chromobacteriumviolaceum)atcc12472的转氨酶(数据库代码np_901695)的val224对应的氨基酸序列的位置处,其具有选自异亮氨酸、缬氨酸、苯丙氨酸、甲硫氨酸和亮氨酸的氨基酸,且在与青紫色素杆菌atcc12472的转氨酶(数据库代码np_901695)的gly230对应的氨基酸序列的位置处,其具有除了苏氨酸以外的氨基酸,且优选选自丝氨酸、半胱氨酸、甘氨酸和丙氨酸的氨基酸。在第四方面的第六实施方案(其也是第一个至第五实施方案的一个实施方案)中,在有分离的或重组的丙氨酸脱氢酶和无机氮源存在下进行步骤b)和/或步骤c)。在第四方面的第七实施方案(其也是第一个至第七实施方案的一个实施方案)中,由nad+依赖性的醇脱氢酶、转氨酶、单加氧酶和丙氨酸脱氢酶组成的组中的至少一种酶是重组酶,且以具有相应酶的全细胞催化剂的形式提供。在第四方面的第八实施方案(其也是第七实施方案的一个实施方案)中,所有酶以一种或多种全细胞催化剂的形式提供,其中,优选地,一种全细胞催化剂包含所有必要的酶。在第四方面的第九实施方案(其也是第一个至第八实施方案的一个实施方案)中,在步骤b)时,优选在步骤b)和c)时,存在有机共溶剂,其具有大于-1.38、优选-0.5至1.2、还更优选-0.4至0.4的logp。在第四方面的第十实施方案(其也是第九实施方案的一个实施方案)中,所述共溶剂选自不饱和脂肪酸,优选油酸。在第四方面的第十一实施方案(其也是第九实施方案的一个优选实施方案)中,所述共溶剂是式r9-o-(ch2)x-o-r10的化合物,其中r9和r10各自且彼此独立地选自甲基、乙基、丙基和丁基,且x是1-4,其中特别优选r8和r10各自是甲基且x是2。根据本发明,所述目的在第五方面中通过全细胞催化剂得以实现,所述全细胞催化剂具有nad+依赖性的醇脱氢酶(优选地,具有至少一个锌原子作为辅因子)、转氨酶、任选的单加氧酶和任选的丙氨酸脱氢酶,其中所述酶是重组酶。根据本发明,所述目的在第六方面中通过根据本发明的第二方面的全细胞催化剂用于氧化和胺化式ho-(ch2)x-r7的伯醇的用途得以实现,其中r7选自-oh、-sh、-nh2和-coor8,x是至少3,且r8选自h、烷基和芳基。在第六方面的第一实施方案(其是第一实施方案的一个实施方案)中,所述用途进一步包括有机共溶剂的存在,所述有机共溶剂具有大于-1.38、优选-0.5至1.2、还更优选-0.4至0.4的logp。在第六方面的第二个实施方案(其是第二实施方案的一个实施方案)中,所述共溶剂选自不饱和脂肪酸,且优选地是油酸。所述第五和第六方面的其它实施方案包含本发明的第四方面的所有实施方案。本发明的发明人已经令人惊讶地发现,存在一组醇脱氢酶,其可以用于实现形成少量副产物的伯醇的氧化。发明人此外已惊讶地发现,存在可以使用生物催化剂将醇胺化而不形成大量副产物的酶活性级联,其中不必添加或除去还原当量。发明人此外已惊讶地发现了可以令人惊讶地使用全细胞催化剂并从再生原料出发生产聚酰胺的方法。本发明的发明人此外已惊讶地发现,事先氧化后的伯醇的胺化可以特别有利地用以某些序列特性为特征的转氨酶集合来进行。根据本发明的方法可以应用于大量的工业相关的醇。在一个优选的实施方案中,其涉及可氧化和胺化成ω-氨基羧酸的ω-羟基羧酸或酯,优选甲酯。在另一实施方案中,其涉及可氧化和胺化成二胺的二醇。在另一个优选的实施方案中,所述伯醇是羟基烷基胺。在此,碳链的长度是可变的,并且x为至少3。所述碳链优选具有多于3个的c-原子,即x=4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20或更多。示例性化合物包括ω-羟基月桂酸、ω-羟基月桂酸甲酯,和链烷二醇,尤其是1,8-辛二醇和1,10-癸二醇。在一个特别优选的实施方案中,r1选自-oh和-coor2,x是至少11,且r2选自h、甲基、乙基和丙基。在最优选的实施方案中,所述伯醇是ω-羟基脂肪酸甲酯。根据本发明,在所述方法的步骤b)中,使用nad+依赖性的醇脱氢酶氧化伯醇。在该情况下,与根据本发明使用的所有的酶活性多肽一样,其可以是包含酶活性多肽的细胞或其裂解物、或处于所有纯化阶段(从粗制的裂解物至纯的多肽)的多肽的制品。本领域技术人员已知大量可以在合适的细胞中过表达酶活性多肽并进行纯化和/或分离的方法。因而,为表达多肽,可以使用本领域技术人员可得到的所有表达体系。可以使用色谱方法用于纯化,例如提供了标记的重组蛋白的亲和色谱使用固定化的配体的纯化,所述固定化的配体为例如在组氨酸标记的情况中镍离子、在与靶蛋白融合的谷胱甘肽-s-转移酶的情况中使用固定化的谷胱甘肽或在包含麦芽糖结合蛋白的标签的情况中使用固定化的麦芽糖。可以以可溶形式或固定化地使用经纯化的酶活性多肽。本领域技术人员已知可以将多肽共价地或非共价地固定化至有机或无机固相上的合适方法,例如通过巯基偶联化学(例如得自pierce或quiagen的试剂盒)。在一个优选的实施方案中,所述用作全细胞催化剂或用作表达体系的细胞是原核细胞,优选细菌细胞。在另一个优选的实施方案中,其是哺乳动物细胞。在另一个优选的实施方案中,其是低等真核细胞,优选是酵母细胞。示例性的原核细胞包括埃希氏菌属(escherichia),特别是大肠杆菌(escherichiacoli),和假单胞菌属(pseudomonas)和棒状杆菌属(corynebacterium)的菌株。示例性的低等真核细胞包括酵母属(saccharomyces)、假丝酵母属(candida)、毕赤酵母属(pichia)、耶氏酵母属(yarrowia)、裂殖酵母(schizosaccharomyces)属,特别是热带假丝酵母(candidatropicalis)、粟酒裂殖酵母(schizosaccharomycespombe)、巴斯德毕赤酵母(pichiapastoris)、解脂耶氏酵母(yarrowialipolytica)和酿酒酵母菌(saccharomycescerivisiae)菌株。在一个特别优选的实施方案中,所述醇脱氢酶是含锌的nad+依赖性的醇脱氢酶,即所述催化活性酶包含至少一个锌原子作为辅因子,所述锌原子通过包含半胱氨酸残基的特征序列基序与所述多肽共价结合。在一个特别优选的实施方案中,所述醇脱氢酶是嗜热脂肪芽孢杆菌的醇脱氢酶(数据库代码p42328)或其变体。本发明的教导不仅可以使用本文描述的生物大分子的精确氨基酸序列或核酸序列来完成,而且也可以使用这样的大分子的变体来完成,所述变体可以通过一个或多于一个氨基酸或核酸的缺失、添加或置换而得到。在一个优选的实施方案中,表述核酸序列或氨基酸序列的“变体”(其在下文中与本文中使用的表述“同源体”同义地和可互换地使用)是指另一个核酸-或氨基酸序列,考虑到相应的原始野生型-核酸-或-氨基酸序列,具有70、75、80、85、90、92、94、96、98、99%或更高百分比的同源性(在这里与同一性同义使用),其中,优选地,除了形成催化活性中心的那些氨基酸或者结构或折叠必需的氨基酸以外的氨基酸被删除或置换,或者后者仅仅是保守置换,例如谷氨酸替代天冬氨酸、或亮氨酸替代缬氨酸。现有技术描述了可以用于计算2个序列的同源性程度的算法,例如arthurlesk(2008),introductiontobioinformatics,第3版。在本发明的另一个优选的实施方案中,氨基酸序列或核酸序列的所述变体,优选地除了上述的序列同源性以外,基本上具有野生型分子或原始分子的相同的酶活性。例如,作为蛋白酶的酶活性多肽的变体具有与所述多肽酶相同的或基本上相同的蛋白水解活性,即催化肽键水解的能力。在一个特别的实施方案中,表述“基本上相同的酶活性”是指显著高于背景活性或/和与相对于相同底物的野生型多肽所具有的km-和/或kcat-值相差小于3个、更优选2个、还更优选1个数量级的相对于野生型-多肽的底物的活性。在另一个优选的实施方案中,表述核酸序列或氨基酸序列的“变体”包含所述核酸-或氨基酸序列的至少一个活性部分/或片段。在另一个优选的实施方案中,本文中使用的表述“活性部分”是指这样的氨基酸序列或核酸序列,其具有小于所述氨基酸序列的整个长度的长度,或者编码比所述氨基酸序列的全长更短的长度,其中具有比野生型氨基酸序列更短长度的氨基酸序列或编码的氨基酸序列基本上具有与所述野生型多肽或其变体相同的酶活性,例如作为醇脱氢酶、单加氧酶或转氨酶。在一个特殊的实施方案中,表述核酸的“变体”是这样的核酸,其互补链,优选地在严格的条件下,结合在野生型核酸上。杂交反应的严格性可由本领域技术人员容易地确定,并且通常取决于探针的长度、洗涤过程中的温度和盐浓度。通常,较长的探针需要较高的温度才能杂交,而较短的探针需要低温。杂交是否发生通常取决于变性dna与存在于其环境中的互补链对合的能力,更精确地讲,在解链温度以下。杂交反应的严格性和相应的条件更详细地描述在ausubel等人,1995中。在一个优选的实施方案中,本文中使用的表述核酸的“变体”是编码与原始核酸相同的氨基酸序列,或者在遗传密码的简并性范围内编码该氨基酸序列的变体的任意的核酸序列。数十年来,醇脱氢酶是生物化学中与酿造发酵过程有关的受到强烈关注的且在生物技术上高度相关的生物化学酶类别,其包括多种异形体集合。因而,存在恶臭假单胞菌gpo1alkj型的膜结合的、黄素依赖性的醇脱氢酶,其使用黄素辅因子替代nad+。另一组包括含铁的、对氧敏感的醇脱氢酶,其在细菌中且以无活性形式在酵母中被发现。另一组包括nad+依赖性的醇脱氢酶,包括含锌的醇脱氢酶,其中活性中心具有半胱氨酸配位的锌原子,所述锌原子固定醇底物。在一个优选的实施方案中,将本文中使用的表述“醇脱氢酶”理解为是指将醛或酮氧化为相应的伯醇或仲醇的酶。优选地,在根据本发明的方法中的醇脱氢酶是nad+依赖性的醇脱氢酶,即使用nad+作为辅因子来氧化醇或使用nadh来还原相应的醛或酮的醇脱氢酶。在最优选的实施方案中,所述醇脱氢酶是nad+依赖性的、含锌的醇脱氢酶。根据本发明,在步骤c)中,使用转氨酶。在一个优选的实施方案中,本文中使用的表述“转氨酶”理解为催化α-氨基从供体(优选氨基酸)向受体分子(优选α-酮羧酸)转移的酶。在一个优选的实施方案中,所述转氨酶选自具有以下特征的转氨酶及其变体:在与青紫色素杆菌(chromobacteriumviolaceum)atcc12472的转氨酶(数据库代码np_901695)的val224对应的氨基酸序列的位置处,其具有选自异亮氨酸、缬氨酸、苯丙氨酸、甲硫氨酸和亮氨酸的氨基酸,且在与青紫色素杆菌atcc12472的转氨酶(数据库代码np_901695)的gly230对应的氨基酸序列的位置处,其具有除了苏氨酸以外的氨基酸,且优选选自丝氨酸、半胱氨酸、甘氨酸和丙氨酸的氨基酸。在一个特别优选的实施方案中,所述转氨酶选自:青紫色素杆菌dsm30191的ω-转氨酶,源自恶臭假单胞菌w619、铜绿假单孢菌(pseudomonasaeruginosa)pa01、天蓝色链霉菌(streptomycescoelicolor)a3(2)和除虫链霉菌(streptomycesavermitilis)ma4680的转氨酶。在一个优选的实施方案中,本文中使用的表述“与青紫色素杆菌atcc12472的转氨酶的氨基酸序列的位置x对应的位置”是指,在所研究的分子的比对中,显得与青紫色素杆菌atcc12472的转氨酶的氨基酸序列的位置x同源的对应位置。本领域技术人员已知众多可以用于进行氨基酸序列比对的软件包和算法。示例性的软件包方法包括由embl提供的程序包clustalw(larkinetal.,2007;goujonetal.2010),或者列出和描述在arthurm.lesk(2008),introductiontobioinformatics,第3版中。根据本发明使用的酶优选地是重组酶。在一个优选的实施方案中,将本文中使用的表述“重组的”理解为相应的核酸分子在自然界中不存在,和/或它使用基因工程方法产生。在一个优选的实施方案中,当相应的多肽由重组核酸编码时,提及重组蛋白。在一个优选的实施方案中,将本文中使用的重组细胞理解为具有至少一个重组核酸或重组多肽的细胞。本领域技术人员已知适合用于生产重组分子或细胞的方法,例如在sambrook等人,1989中描述的那些。根据本发明的教导可以使用分离的酶和使用全细胞催化剂来实行。在一个优选的实施方案中,将本文中使用的表述“全细胞催化剂”理解为提供所期望的酶活性的完整的、存活的且有代谢活性的细胞。所述全细胞催化剂可以将要代谢的底物(在本发明的情况中,醇)或由所述底物形成的氧化产物运输进细胞内部,在此处被细胞溶质酶代谢,或者其可以将目标酶呈递到它的表面上,在此处直接暴露给培养基中的底物。本领域技术人员已知众多用于生产全细胞催化剂的体系,例如从de60216245中已知。就许多应用而言,推荐使用分离的酶。在一个优选的实施方案中,本文中使用的表述“分离的”是指,所述酶以比它的天然来源更纯和/或更浓的形式存在。在一个优选的实施方案中,如果酶是多肽酶且占相应制品的质量蛋白分数多于60、70、80、90或优选95%,则认为所述酶是分离的。本领域技术人员已知众多用于测量溶液中的蛋白的质量的方法,例如借助sds-聚丙烯酰胺凝胶上的对应蛋白带的厚度的视觉估测、nmr光谱法或基于质量-光谱测定法的方法。根据本发明的方法的酶催化反应通常在溶剂或具有高的水比例的溶剂混合物中进行,优选地在用于建立与酶活性相容的ph-值的合适缓冲体系的存在下进行。但是,在疏水性原料的情况中,特别是在具有包含多于3个碳原子的碳链的醇中,有机共溶剂的额外存在是有利的,所述有机共溶剂可以介导酶与底物的接触。一种或多于一种共溶剂以占溶剂混合物或低于溶剂混合物的95、90、85、80、75、70、65、60、55、50、45、40、35、30、25、20、15、10或5体积%的总比例存在。共溶剂的疏水性在这里起重要作用。它可以由logp表示,所述logp是正辛醇-水分配系数的以10为底的对数。优选的共溶剂具有大于-1.38、更优选-1至+2、还更优选-0.5至0.5、或-0.4至0.4、或-0至1.5的logp。正辛醇-水-分配系数kow或p是指示物质在1-辛醇和水的两相体系中的浓度的比例的无量纲分配系数(参见j.sangster,octanol-waterpartitioncoefficients:fundamentalsandphysicalchemistry,wileyseriesinsolutionchemistry的第2卷,johnwiley&sons,chichester,1997)。更精确地讲,kow或p表示物质在富含辛醇的相中的浓度与其在富含水的相中的浓度之比。kow值是物质的亲脂性(脂溶性)和亲水性(水溶性)之间的比例的模型指数(modellmaß)。预见到,使用物质在辛醇-水体系中的分配系数,也能够估测该物质在具有水相的其它体系中的分配系数。如果物质可更好地溶于脂性溶剂诸如正辛醇中,那么kow大于1,如果物质可更好地溶于水中,那么kow小于1。相应地,亲脂性物质的logp为正值,亲水性物质的logp为负值。由于不能测量所有化学试剂的kow,因此存在非常多样化的预测模型,例如通过定量构效关系(qsar)或通过线性自由能关系(lfer),例如描述于eugenekelloggg,abrahamdj:hydrophobicity:islogp(o/w)morethanthesumofitsparts.eurjmedchem.2000年7-8月;35(7-8):651-61或gudrunwienke,“messungundvorausberechnungvonn-octanol/wasser-verteilungskoeffizienten”,博士论文,oldenburg大学,1-172,1993。在本申请范围内,根据advancedchemistrydevelopmentinc.,toronto的方法,借助程序模块acd/logpdb确定logp。优选的共溶剂具有大于-1.38,更优选-1至+2,还更优选-0.75至1.5、或-0.5至0.5、或-0.4至0.4、或-0.3至-0.1的logp。在一个优选的实施方案中,所述共溶剂是式alk1-o-alk2的二烷基醚,其具有大于-1.38、更优选-1至+2、还更优选0至1.5的logp,其中所述2个烷基取代基alk1和alk2各自彼此独立地选自甲基、乙基、丙基、丁基、异丙基和叔丁基。在一个特别优选的实施方案中,所述共溶剂是甲基叔丁基醚(mtbe)。在最优选的实施方案中,所述共溶剂是二甲氧基乙烷(dme)。在另一个优选的实施方案中,所述共溶剂是式r10-o-(ch2)x-o-r11的化合物,其中r10和r11各自且彼此独立地选自甲基、乙基、丙基和丁基,且x是1-4,其中优选r10和r11各自是甲基且x是2。在另一个优选的实施方案中,所述共溶剂是羧酸或脂肪酸,优选具有至少6个碳原子的脂肪酸,更优选具有至少12个碳原子的脂肪酸。所述脂肪酸可以是饱和脂肪酸,例如月桂酸、肉豆蔻酸、棕榈酸、十七烷酸、硬脂酸、花生酸或山嵛酸,或不饱和脂肪酸,例如肉豆蔻脑酸、棕榈油酸、岩芹酸、油酸、反油酸、异油酸、顺-9-二十碳烯酸、二十碳-11-烯酸或芥酸。不同脂肪酸的混合物同样是可能的,例如主要含有不饱和脂肪酸的蓝刺头油。由于并非所有的脂肪酸在室温时都是显著可溶的,可能需要求助于其它措施,例如升高温度,或者,更优选地,加入其它溶剂来使它可接近水相。在一个特别优选的实施方案中,使用脂肪酸或其酯、优选甲酯、最优选月桂酸甲酯作为这样的其它溶剂。根据本发明的酶级联可以根据本发明在有丙氨酸脱氢酶存在下进行。本发明的一个特别的长处是,该构型能够实现还原当量中性的反应操作,即该反应在没有供给或除去还原当量形式的电子的情况下进行,因为在醇氧化过程中由醇脱氢酶产生的nadh在制备丙氨酸时被消耗,消耗无机氮供体,优选氨或氨源。在一个优选的实施方案中,本文中使用的表述“丙氨酸脱氢酶”理解为这样的酶:其催化l-丙氨酸的转化,消耗水和nad+,形成丙酮酸、氨和nadh。优选地,所述丙氨酸脱氢酶是细胞内的丙氨酸脱氢酶,还更优选地,细菌全细胞催化剂的重组细胞内的丙氨酸脱氢酶。在一个优选的实施方案中,将具有所有需要的活性的全细胞催化剂用于根据本发明的方法中,即nad(p)+依赖性的醇脱氢酶、转氨酶和任选的单加氧酶和/或丙氨酸脱氢酶。这样的全细胞催化剂的应用具有以下优点:以单一试剂的形式使用所有活性,并且不必大规模地准备生物活性形式的酶。适合用于构建全细胞催化剂的方法是本领域技术人员已知的,尤其是用于表达一种或多种重组蛋白的质粒体系的构建,或编码所需重组蛋白的dna向使用的宿主细胞的染色体dna中的整合。在先前的描述、权利要求书和附图中公开的本发明的特征单独地和以任意组合以本发明不同实施方案用于实现本发明可能是重要的。附图说明图1显示了包含不同转氨酶,尤其是青紫色素杆菌atcc12472的转氨酶(数据库代码np_901695,“tacv_co”)的示例性比对。在所有序列中,用下划线标记与青紫色素杆菌atcc12472的转氨酶的位置val224和gly230对应的氨基酸残基。使用clustalw进行所述比对。图2显示了由3种酶rasadh、pcr6(l417m)和aladh(d196a/l197r)催化异山梨醇和铵盐的反应96h以后的fmoc/hplc分析。所述图显示了:(a)标准品(各1mm的根据图3的氨基醇i、ii、iii和iv+各1mm的二胺dai、das和dam),(b)由rasadh、pcr6(l417m)和aladh(d196a/l197r)催化反应96h以后,(c)与(b)相同但是不含rasadh对照反应96h以后。对于衍生化,将20µl各反应样品转移至含有60µl0.5m硼酸钠ph9.0的hplc瓶中,混合均匀,并加入80µlfmoc试剂(alltechgrom)。通过加入100µleva试剂(alltechgrom),捕集多余过量的fmoc试剂。通过加入440µl50mm醋酸钠ph4.2+70%乙腈(v/v),建立hplc分析条件。色谱条件:agilentsb-c8柱(4.6×150mm);流速:1ml/min;注射体积:20µl;缓冲液a。50mm乙酸钠ph4.2+20%乙腈(v/v);缓冲液b:50mm乙酸钠ph4.2+95%乙腈(v/v);梯度:0min16%b,5min16%b,25min18%b,28min52%b,40min25%b。图3显示了以下起始底物的化学式:异山梨醇(1,4:3,6-双脱水-d-山梨醇),氨基醇的立体异构体(i至iv)和二胺终产物的立体异构形式(dai:2,5-二氨基-1,4:3,6-双脱水-2,5-双脱氧-l-艾杜糖醇,das:2,5-二氨基-1,4:3,6-双脱水-2,5-双脱氧-d-山梨醇,和dam:2,5-二氨基-1,4:3,6-双脱水-2,5-双脱氧-d-甘露醇。图4显示了由fmoc/hplc分析得到的在不同铵浓度下通过rasadh、pcr6(l417m)和aladh(d196a/l197r)催化的异山梨醇和乙酸铵的反应的单胺和二胺收率。反应条件:300mm异山梨醇,2mmnadp+,100-300mmnh4oac,5mml-丙氨酸,0.3mmplp,132µmrasadh,40µmpcr6(l417m),24µmaladh(d196a/l197r),在25mmhepes/naoh(ph8.3)中在30℃温育。图5显示了如根据实施例3在根据本发明的氧化和胺化仲醇三丙二醇时得到的样品的分析色谱图。箭头标记了代表氧化的和胺化的三丙二醇的峰。本发明还涉及以下实施方案:实施方案1.包括下述步骤的方法:a)提供仲醇,b)通过与nad(p)+依赖性的醇脱氢酶接触氧化所述仲醇,和c)使步骤a)的氧化产物与转氨酶接触,其中所述nad(p)+依赖性的醇脱氢酶和/或所述转氨酶是重组的或分离的酶。实施方案2.根据实施方案1的方法,其中所述仲醇是选自以下的醇:α-羟基羧酸,环烷醇,优选双(对羟基环己基)甲烷,式r1-cr2h-cr3h-oh的醇及其醚和聚醚,和仲烷醇,优选2-烷醇,其中r1选自羟基、烷氧基、氢和胺,r2选自烷基,优选甲基、乙基和丙基,和氢,且r3选自烷基,优选甲基、乙基和丙基。实施方案3.根据实施方案2的方法,其中所述仲醇是下式的仲醇h3c-c(oh)h-(ch2)x-r4,其中r4选自-oh、-sh、-nh2和-coor5,x是至少3,且r5选自h、烷基和芳基。实施方案4.根据实施方案1的方法,其中通过用单加氧酶羟基化所述式的相应烷烃进行步骤a),所述单加氧酶优选地是重组的或分离的。实施方案5.根据实施方案1-4中的任一项的方法,其中所述nad(p)+依赖性的醇脱氢酶是具有至少一个锌原子作为辅因子的nad(p)+依赖性的醇脱氢酶。实施方案6.根据实施方案5的方法,其中所述醇脱氢酶是赤红球菌的醇脱氢酶a(数据库代码aj491307.1)或其变体。实施方案7.根据实施方案4-6中的任一项的方法,其中所述单加氧酶选自:恶臭假单胞菌的alkbgt,得自热带假丝酵母或得自鹰嘴豆的细胞色素p450。实施方案8.根据实施方案1-7中的任一项的方法,其中所述转氨酶选自这样的转氨酶及其变体,其特征在于,在与青紫色素杆菌atcc12472的转氨酶(数据库代码np_901695)的val224对应的氨基酸序列的位置处,其具有选自异亮氨酸、缬氨酸、苯丙氨酸、甲硫氨酸和亮氨酸的氨基酸,且在与青紫色素杆菌atcc12472的转氨酶(数据库代码np_901695)的gly230对应的氨基酸序列的位置处,其具有除了苏氨酸以外的氨基酸,且优选选自丝氨酸、半胱氨酸、甘氨酸和丙氨酸的氨基酸,或者所述转氨酶选自:河流弧菌的转氨酶(aea39183.1)、巨大芽孢杆菌的转氨酶(yp001374792.1)、脱氮副球菌的转氨酶(cp000490.1)及其变体。实施方案9.根据实施方案1-8中的任一项的方法,其中在分离的或重组的丙氨酸脱氢酶和无机氮源存在下进行步骤b)和/或步骤c)。实施方案10.根据实施方案1-9中的任一项的方法,其中由nad(p)+依赖性的醇脱氢酶、转氨酶、单加氧酶和丙氨酸脱氢酶组成的组中的至少一种酶是重组的,且以具有相应酶的全细胞催化剂的形式提供。实施方案11.根据实施方案10的方法,其中所有酶以一种或多种全细胞催化剂的形式提供,且优选地,一种全细胞催化剂具有所有必要的酶。实施方案12.根据实施方案1-11中的任一项的方法,其中在步骤b)中,优选地在步骤b)和c)中,存在有机共溶剂,所述有机共溶剂具有大于-1.38、优选-0.5至1.2、还更优选-0.4至0.4的logp。实施方案13.根据实施方案12的方法,其中所述共溶剂选自不饱和脂肪酸,优选油酸。实施方案14.根据实施方案13的方法,其中所述共溶剂是式r6-o-(ch2)x-o-r7的化合物,其中r6和r7各自且彼此独立地选自甲基、乙基、丙基和丁基,且x是1-4,其中优选地r6和r7各自是甲基且x是2。实施方案15.全细胞催化剂,其具有nad(p)+依赖性的醇脱氢酶、转氨酶、任选的单加氧酶和任选的丙氨酸脱氢酶,所述nad(p)+依赖性的醇脱氢酶优选地具有至少一个锌原子作为辅因子,其中所述酶是重组酶。实施方案16.根据实施方案15的全细胞催化剂用于氧化和胺化仲醇的用途,其中所述仲醇优选地是下式的仲醇h3c-c(oh)h-(ch2)x-r4,其中r4选自-oh、-sh、-nh2和-coor5,x是至少3,且r5选自h、烷基和芳基。实施方案17.根据实施方案16的用途,进一步包括有机共溶剂的存在,所述有机共溶剂具有大于-1.38、优选-0.5至1.2、还更优选-0.4至0.4的logp。实施方案18.根据实施方案17的用途,其中所述共溶剂选自不饱和脂肪酸,优选油酸。具体实施方式实施例1:使用根据本发明的方法,与醇脱氢酶alkj相比,使用nad+依赖性的醇脱氢酶的不同底物的胺化底物:使用的底物是环己醇(1)、(s)-辛烷-2-醇(2)和(s)-4-苯基丁-2-醇(3)。酶:丙氨酸脱氢酶:在大肠杆菌中表达枯草芽孢杆菌的l-丙氨酸脱氢酶。首先,制备过夜培养物,然后将其用于接种主要培养物(lb-氨苄西林培养基)。将细胞在摇床上在30℃和120upm温育24小时。然后,在无菌条件下加入iptg(0.5mm,异丙基β-d-1-硫代吡喃半乳糖苷,sigma)进行诱导,并将培养物在20℃振摇另外24小时。将细胞离心出(8000upm,20min4℃),洗涤,并抛弃上清液。然后使用超声(1s脉冲,4s暂停,时间:10min,振幅:40%)破碎细胞,将混合物离心(20min,18000upm,4℃),并使用his-prep柱纯化酶。嗜热脂肪芽孢杆菌的醇脱氢酶(adh-ht;p42328.1))为了制备嗜热脂肪芽孢杆菌的nad+依赖性的醇脱氢酶(fiorentinog,cannior,rossim,bartoluccis:decreasingthestabilityandchangingthesubstratespecificityofthebacillusstearothermophilusalcoholdehydrogenasebysingleaminoacidreplacements.proteineng1998,11:925-930),首先制备过夜培养物(10mllb/氨苄西林培养基,氨苄西林100µg/ml,30℃,120upm),然后将其用于接种培养容器,再将其在37℃和120upm振摇约12小时。将细胞离心出(8000upm,20分钟,4℃),洗涤,抛弃上清液,并将沉淀物冻干。最后,使用超声(1s脉冲,4s暂停,时间:10min,振幅:40%)破碎细胞,并将混合物离心(20min,18000upm,4℃)和用作粗提取物。借助sds-page估测蛋白浓度。alkj-醇脱氢酶(得自食油假单胞菌(pseudomonasoleovirans)gpo1):除了使用质粒ptze03_alkj(seqidno20)和使用卡那霉素作为抗生素(50µg/ml)以外,在与嗜热脂肪芽孢杆菌的醇脱氢酶相同的条件下制备该酶。同样借助sds-page估测蛋白浓度。得自青紫色素杆菌的转氨酶cv-ωta:为了从青紫色素杆菌制备cv-ωta(u.kaulmann,k.smithies,m.e.b.smith,h.c.hailes,j.m.ward,enzymemicrob.technol.2007,41,628-637;b)m.s.humble,k.e.cassimjee,m.håkansson,y.r.kimbung,b.walse,v.abedi,h.-j.federsel,p.berglund,d.t.logan,febsjournal2012,279,779-792;c)d.koszelewski,m.göritzer,d.clay,b.seisser,w.kroutil,chemcatchem2010,2,73-77),首先制备过夜培养物(lb/氨苄西林培养基,30℃,120rpm),然后将其用于接种含有相同培养基的培养瓶,将其在37℃和120upm下振摇约3小时,直到达到在600nm为0.7的光密度。然后,加入iptg储备溶液(0.5mm),在20℃和120upm诱导3小时。将细胞离心出,抛弃上清液,并在4℃储存细胞。最后,使用超声(1s脉冲,4s暂停,时间:10min,振幅:40%)破碎细胞,将混合物离心(20min,18000upm,4℃),并将上清液用作粗提取物。实验操作:实验溶液描述在表1中。表1:实验溶液实验溶液adh-ht或alkj(粗制物)200µl转氨酶200µlaladh10µl(250u)l-丙氨酸250mmnad+2mmnh4cl21mg(500µmol)plp0.5mm6mnaoh7.5µlh2o/共溶剂400µl底物50µmol最终ph8.5总体积1.22ml将底物溶解在适当量的共溶剂(dme)中,并加入溶解在300µl水中的l-丙氨酸。在75µl水中,加入氯化铵。加入各自溶解在25µl水中的nad+和plp。通过加入7.5µl6mnaoh溶液,调节ph-值。加入转氨酶和丙氨酸脱氢酶。通过加入醇脱氢酶,开始反应。22小时以后,通过加入下述的衍生化试剂,停止反应。胺的衍生化:将200µl三乙胺和esof(琥珀酰亚胺基氧基甲酸乙酯)(80或40mg)在乙腈(500µl)中的溶液加入到500µl样品中。然后将样品在45℃振摇1小时,然后用二氯甲烷萃取,经硫酸钠干燥,并使用gc-ms测量。如果不采用丙氨酸脱氢酶,则在ph8.5(通过加入naoh来调节)下向水溶液中加入l-丙氨酸(500mm)、nad+(2mm)和plp(0.5mm)和在dme中的底物(120µl,25mm)。通过加入各200µl的醇脱氢酶(nad+依赖性的)或alkj)和转氨酶,开始反应。将样品在25℃和300upm振摇24小时。将样品如上所述进行处理,并用gc-ms进行分析。结果:n.d.未测出。总结:对于一系列在结构上不同的仲醇,在每种情况下表明,与使用醇脱氢酶alkj相比,使用嗜热脂肪芽孢杆菌的nad+依赖性的醇脱氢酶会显著更有效地进行反应。实施例2:通过醇脱氢酶、转氨酶和丙氨酸脱氢酶的偶联酶反应由异山梨醇和铵盐合成单胺和二胺下述实施例显示了使用另一种在结构上不同的底物和nadp+依赖性的醇脱氢酶的根据本发明教导的操作。使用质粒peam-rasadh(lavandera等人(2008)j.org.chem.73,6003-6005)的寡脱氧核苷酸adhfw(seqidno:35)和adhrv(seqidno:36),通过pcr扩增得自罗尔斯通氏菌属的醇脱氢酶的结构基因(seqidno:25),用限制性内切酶kpni在3’-末端处切割,最后与已经使用限制性内切酶ehei和kpni切割的表达载体pask-iba35(+)连接。通过分析限制消化和dna测序,验证得到的表达质粒pask-iba35(+)-rasadh,在其上面编码具有n-端his6-标签的醇脱氢酶。使用质粒pet21a(+)-pcr6的寡脱氧核苷酸pcr6fw(seqidno:38)和pcr6rv(seqidno:39),通过pcr扩增得自脱氮副球菌的转氨酶的基因(seqidno:37),使用限制性内切酶hindiii在3’-末端处切割,并最后与已经使用限制性内切酶ehei和hindiii切割的表达载体pask-iba35(+)连接。通过分析限制消化以及dna测序,验证得到的表达质粒pask-iba35(+)-pcr6,在其上面编码具有n-端his6-标签的转氨酶。使用寡脱氧核苷酸pcr6_l417mfw(seqidno:20)和pcr6_l417mrv(seqidno:41),根据quikchange-方法(agilent,waldbronn)借助质粒pask-iba35(+)-pcr6的定位诱变,制备编码转氨酶的酶变体l417m的质粒。借助dna测序,验证得到的表达质粒pask-iba35(+)-pcr6(l417m)。使用pask-iba35(+)-aladh(d196a/l197r)作为得自枯草芽孢杆菌的aladh(seqidno:21)的d196a/l197r突变体的表达质粒。然后将所述3种酶的表达质粒pask-iba35(+)-rasadh、pask-iba35(+)-pcr6(l417m)和pask-iba35(+)-aladh(d196a/l197r)用于转化大肠杆菌bl21。在每种情况下,在含有100μg/ml氨苄西林的lb培养介质(在5l摇瓶中2l培养体积)中在30℃在od550=0.5的指数生长期,通过加入0.2µg/mlatc来诱导3种得到的菌株的基因表达。3h的诱导时间以后,收获培养物,并将细胞溶解于40mmhepes/naohph7.5、0.5mnacl中,并在弗氏压碎匀浆器中机械破碎。将澄清的上清液施加在载有zn2+的chelatingsepharose™fastflow柱上,并使用线性咪唑/hcl浓度梯度(0-500mm,在40mmhepes/naohph7.5、0.5mnacl中)洗脱与his6标签融合的酶。通过超滤浓缩洗脱级分,并介质凝胶过滤在superdex200上在25mmhepes/naohph8.3存在下进行色谱纯化。将3种经纯化的酶直接用于胺化异山梨醇(1,4:3,6-双脱水-d-山梨醇),回收氧化还原因子nadp+和l-丙氨酸。酶试验的组成如下:试剂或酶在溶液中的终浓度hepes/naoh缓冲液ph8.325mm异山梨醇300mmnadp+2mml-丙氨酸5mm磷酸吡哆醛(plp)0.3mm乙酸铵(nh4oac)100-300mm醇脱氢酶132µm转氨酶(l417m)40µm丙氨酸脱氢酶(d196a/l197r)24µm总体积250µl在30℃温育0-96h的时段以后,通过加入过量的fmoc试剂(alltechgrom,rottenburg-hailfingen),通过具有荧光检测器的hplc(agilent1200系列;参见图2)检测并定量作为反应产物的单胺和二胺的形成。因此,使用异山梨醇也能够显示出根据本发明的氧化和胺化。这证实了在广谱底物上也能实现根据本发明的教导。实施例3:三丙二醇的氧化和胺化除了不含转氨酶的空白样品以外,向含有1mmnad+、1mmplp、5当量的l-丙氨酸、4当量的氯化铵、50mm三丙二醇的缓冲溶液(1ml50mm磷酸盐缓冲液ph7.5)中,加入得自赤红球菌的丙氨酸脱氢酶(300µl/样品,经过热处理),20µl得自河流弧菌、巨大芽孢杆菌、节杆菌属、青紫色素杆菌的转氨酶和pcr6。然后将样品在30℃和450upm下温育24小时。对于后处理,将样品在微波中在600w加热大约15秒,然后离心。进行如在实施例1中所述的检测。使用三丙二醇作为仲醇也能够检测氧化和胺化产物的形成。这证实了在广谱底物上可实现根据本发明的教导。参考文献:序列表<110>evonikdegussagmbh<120>醇的氧化<130>2011e00340de<160>43<170>patentin3.5版<210>1<211>57<212>prt<213>人工序列<220><223>序列部分<400>1valvalalaalaargtrpleugluglulysileleugluileglyala151015asplysvalalaalaphevalglygluproileglnglyalaglygly202530valilevalproproalathrtyrtrpprogluilegluargilecys354045arglystyraspvalleuleuvalala5055<210>2<211>57<212>prt<213>人工序列<220><223>序列部分<400>2alahiscysvalalagluleuglualaleuilegluarggluglyala151015aspthrilealaalapheileglygluproileleuglythrglygly202530ilevalproproproalaglytyrtrpglualaileglnthrvalleu354045asnlyshisaspileleuleuvalala5055<210>3<211>57<212>prt<213>人工序列<220><223>序列部分<400>3glnhiscysalaasplysleugluglumetileleualagluglypro151015gluthrilealaalapheileglygluproileleuglythrglygly202530ilevalproproproalaglytyrtrpglulysileglnalavalleu354045lyslystyraspvalleuleuvalala5055<210>4<211>57<212>prt<213>人工序列<220><223>序列部分<400>4aspaspleuvalglngluphegluaspargilegluserleuglypro151015aspthrilealaalapheleualagluproileleualaserglygly202530valileileproproalaglytyrhisalaargphelysalailecys354045glulyshisaspileleutyrileser5055<210>5<211>57<212>prt<213>人工序列<220><223>序列部分<400>5alagluleualaasngluleugluargilevalalaleuhisaspala151015serthrilealaalavalilevalgluprovalalaglyserthrgly202530valileleuproprolysglytyrleuglnlysleuarggluilecys354045thrlyshisglyileleuleuilephe5055<210>6<211>57<212>prt<213>人工序列<220><223>序列部分<400>6alagluleualaasngluleugluargilevalalaleuhisaspala151015serthrilealaalavalilevalgluprovalalaglyserthrgly202530valileleuproprolysglytyrleuglnlysleuarggluilecys354045thrlyshisglyileleuleuilephe5055<210>7<211>57<212>prt<213>人工序列<220><223>序列部分<400>7alahisleualaaspgluleugluargileilealaleuhisaspala151015serthrilealaalavalilevalgluprometalaglyserthrgly202530valleuvalproprolysglytyrleuglulysleuarggluilethr354045alaarghisglyileleuleuilephe5055<210>8<211>57<212>prt<213>人工序列<220><223>序列部分<400>8alahisleualaaspgluleugluargilevalalaleuhisasppro151015serthrilealaalavalilevalgluproleualaglyseralagly202530valleuvalproprovalglytyrleuasplysleuarggluilethr354045thrlyshisglyileleuleuilephe5055<210>9<211>57<212>prt<213>人工序列<220><223>序列部分<400>9valgluleualaasngluleuleulysleuilegluleuhisaspala151015serasnilealaalavalilevalgluprometserglyseralagly202530valleuvalproprovalglytyrleuglnargleuarggluilecys354045aspglnhisasnileleuleuilephe5055<210>10<211>57<212>prt<213>人工序列<220><223>序列部分<400>10ilealaleualaaspgluleuleulysleuilegluleuhisaspala151015serasnilealaalavalphevalgluproleualaglyseralagly202530valleuvalproprogluglytyrleulysargasnarggluilecys354045asnglnhisasnileleuleuvalphe5055<210>11<211>57<212>prt<213>人工序列<220><223>序列部分<400>11proalatyrseralaalapheglualaglnleualaglnhisalagly151015gluleualaalavalvalvalgluprovalvalglnglyalaglygly202530metargphehisaspproargtyrleuhisaspleuargaspilecys354045argargtyrgluvalleuleuilephe5055<210>12<211>57<212>prt<213>人工序列<220><223>序列部分<400>12gluargaspmetvalglyphealaargleumetalaalahisarghis151015gluilealaalavalileilegluproilevalglnglyalaglygly202530metargmettyrhisproglutrpleulysargilearglysilecys354045asparggluglyileleuleuileala5055<210>13<211>57<212>prt<213>人工序列<220><223>序列部分<400>13aspglncysleuarggluleualaglnleuleuglugluhishisglu151015gluilealaalaleuserileglusermetvalglnglyalasergly202530metilevalmetprogluglytyrleualaglyvalarggluleucys354045thrthrtyraspvalleumetileval5055<210>14<211>54<212>prt<213>人工序列<220><223>序列部分<400>14alaasngluileaspargilemetthrtrpgluleusergluthrile151015alaglyvalilemetgluproileilethrglyglyglyileleumet202530proproaspglytyrmetlyslysvalgluaspilecysargarghis354045glyalaleuleuilecys50<210>15<211>56<212>prt<213>人工序列<220><223>序列部分<400>15leuleuservallystyrthrargargmetilegluasntyrglypro151015gluglnvalalaalavalilethrgluvalserglnglyalaglyser202530alametproprotyrglutyrileproglnphearglysmetthrlys354045gluleuglyvalleutrpileasn5055<210>16<211>56<212>prt<213>人工序列<220><223>序列部分<400>16leuleuservallystyrthrargargmetilegluasntyrglypro151015gluglnvalalaalavalilethrgluvalserglnglyalaglyser202530alametproprotyrglutyrileproglnilearglysmetthrlys354045gluleuglyvalleutrpileasn5055<210>17<211>56<212>prt<213>人工序列<220><223>序列部分<400>17leuleuservallystyrthrargargmetilegluasntyrglypro151015gluglnvalalaalavalilethrgluvalserglnglyvalglyser202530thrmetproprotyrglutyrvalproglnilearglysmetthrlys354045gluleuglyvalleutrpileser5055<210>18<211>56<212>prt<213>人工序列<220><223>序列部分<400>18lystyralaseraspvalhisaspleuileglnpheglythrsergly151015glnvalalaglypheileglygluserileglnglyvalglyglyile202530valgluleualaproglytyrleuproalaalatyraspilevalarg354045lysalaglyglyvalcysileala5055<210>19<211>57<212>prt<213>人工序列<220><223>序列部分<400>19leualagluleuasptyralapheaspleuileaspargglnserser151015glyasnleualaalapheilealagluproileleuserserglygly202530ileilegluleuproaspglytyrmetalaalaleulysarglyscys354045glualaargglymetleuleuileleu5055<210>20<211>6949<212>dna<213>人工序列<220><223>质粒ptze03_alkj<400>1tggcgaatgggacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttacgcg60cagcgtgaccgctacacttgccagcgccctagcgcccgctcctttcgctttcttcccttc120ctttctcgccacgttcgccggctttccccgtcaagctctaaatcgggggctccctttagg180gttccgatttagtgctttacggcacctcgaccccaaaaaacttgattagggtgatggttc240acgtagtgggccatcgccctgatagacggtttttcgccctttgacgttggagtccacgtt300ctttaatagtggactcttgttccaaactggaacaacactcaaccctatctcggtctattc360ttttgatttataagggattttgccgatttcggcctattggttaaaaaatgagctgattta420acaaaaatttaacgcgaattttaacaaaatattaacgtttacaatttcaggtggcacttt480tcggggaaatgtgcgcggaacccctatttgtttatttttctaaatacattcaaatatgta540tccgctcatgaattaattcttagaaaaactcatcgagcatcaaatgaaactgcaatttat600tcatatcaggattatcaataccatatttttgaaaaagccgtttctgtaatgaaggagaaa660actcaccgaggcagttccataggatggcaagatcctggtatcggtctgcgattccgactc720gtccaacatcaatacaacctattaatttcccctcgtcaaaaataaggttatcaagtgaga780aatcaccatgagtgacgactgaatccggtgagaatggcaaaagtttatgcatttctttcc840agacttgttcaacaggccagccattacgctcgtcatcaaaatcactcgcatcaaccaaac900cgttattcattcgtgattgcgcctgagcgagacgaaatacgcgatcgctgttaaaaggac960aattacaaacaggaatcgaatgcaaccggcgcaggaacactgccagcgcatcaacaatat1020tttcacctgaatcaggatattcttctaatacctggaatgctgttttcccggggatcgcag1080tggtgagtaaccatgcatcatcaggagtacggataaaatgcttgatggtcggaagaggca1140taaattccgtcagccagtttagtctgaccatctcatctgtaacatcattggcaacgctac1200ctttgccatgtttcagaaacaactctggcgcatcgggcttcccatacaatcgatagattg1260tcgcacctgattgcccgacattatcgcgagcccatttatacccatataaatcagcatcca1320tgttggaatttaatcgcggcctagagcaagacgtttcccgttgaatatggctcataacac1380cccttgtattactgtttatgtaagcagacagttttattgttcatgaccaaaatcccttaa1440cgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttga1500gatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcg1560gtggtttgtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagc1620agagcgcagataccaaatactgtccttctagtgtagccgtagttaggccaccacttcaag1680aactctgtagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgcc1740agtggcgataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcg1800cagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctac1860accgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggaga1920aaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagctt1980ccagggggaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgag2040cgtcgatttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcg2100gcctttttacggttcctggccttttgctggccttttgctcacatgttctttcctgcgtta2160tcccctgattctgtggataaccgtattaccgcctttgagtgagctgataccgctcgccgc2220agccgaacgaccgagcgcagcgagtcagtgagcgaggaagcggaagagcgcctgatgcgg2280tattttctccttacgcatctgtgcggtatttcacaccgcatatatggtgcactctcagta2340caatctgctctgatgccgcatagttaagccagtatacactccgctatcgctacgtgactg2400ggtcatggctgcgccccgacacccgccaacacccgctgacgcgccctgacgggcttgtct2460gctcccggcatccgcttacagacaagctgtgaccgtctccgggagctgcatgtgtcagag2520gttttcaccgtcatcaccgaaacgcgcgaggcagctgcggtaaagctcatcagcgtggtc2580gtgaagcgattcacagatgtctgcctgttcatccgcgtccagctcgttgagtttctccag2640aagcgttaatgtctggcttctgataaagcgggccatgttaagggcggttttttcctgttt2700ggtcactgatgcctccgtgtaagggggatttctgttcatgggggtaatgataccgatgaa2760acgagagaggatgctcacgatacgggttactgatgatgaacatgcccggttactggaacg2820ttgtgagggtaaacaactggcggtatggatgcggcgggaccagagaaaaatcactcaggg2880tcaatgccagcgcttcgttaatacagatgtaggtgttccacagggtagccagcagcatcc2940tgcgatgcagatccggaacataatggtgcagggcgctgacttccgcgtttccagacttta3000cgaaacacggaaaccgaagaccattcatgttgttgctcaggtcgcagacgttttgcagca3060gcagtcgcttcacgttcgctcgcgtatcggtgattcattctgctaaccagtaaggcaacc3120ccgccagcctagccgggtcctcaacgacaggagcacgatcatgcgcacccgtggggccgc3180catgccggcgataatggcctgcttctcgccgaaacgtttggtggcgggaccagtgacgaa3240ggcttgagcgagggcgtgcaagattccgaataccgcaagcgacaggccgatcatcgtcgc3300gctccagcgaaagcggtcctcgccgaaaatgacccagagcgctgccggcacctgtcctac3360gagttgcatgataaagaagacagtcataagtgcggcgacgatagtcatgccccgcgccca3420ccggaaggagctgactgggttgaaggctctcaagggcatcggtcgagatcccggtgccta3480atgagtgagctaacttacattaattgcgttgcgctcactgcccgctttccagtcgggaaa3540cctgtcgtgccagctgcattaatgaatcggccaacgcgcggggagaggcggtttgcgtat3600tgggcgccagggtggtttttcttttcaccagtgagacgggcaacagctgattgcccttca3660ccgcctggccctgagagagttgcagcaagcggtccacgctggtttgccccagcaggcgaa3720aatcctgtttgatggtggttaacggcgggatataacatgagctgtcttcggtatcgtcgt3780atcccactaccgagatatccgcaccaacgcgcagcccggactcggtaatggcgcgcattg3840cgcccagcgccatctgatcgttggcaaccagcatcgcagtgggaacgatgccctcattca3900gcatttgcatggtttgttgaaaaccggacatggcactccagtcgccttcccgttccgcta3960tcggctgaatttgattgcgagtgagatatttatgccagccagccagacgcagacgcgccg4020agacagaacttaatgggcccgctaacagcgcgatttgctggtgacccaatgcgaccagat4080gctccacgcccagtcgcgtaccgtcttcatgggagaaaataatactgttgatgggtgtct4140ggtcagagacatcaagaaataacgccggaacattagtgcaggcagcttccacagcaatgg4200catcctggtcatccagcggatagttaatgatcagcccactgacgcgttgcgcgagaagat4260tgtgcaccgccgctttacaggcttcgacgccgcttcgttctaccatcgacaccaccacgc4320tggcacccagttgatcggcgcgagatttaatcgccgcgacaatttgcgacggcgcgtgca4380gggccagactggaggtggcaacgccaatcagcaacgactgtttgcccgccagttgttgtg4440ccacgcggttgggaatgtaattcagctccgccatcgccgcttccactttttcccgcgttt4500tcgcagaaacgtggctggcctggttcaccacgcgggaaacggtctgataagagacaccgg4560catactctgcgacatcgtataacgttactggtttcacattcaccaccctgaattgactct4620cttccgggcgctatcatgccataccgcgaaaggttttgcgccattcgatggtgtccggga4680tctcgacgctctcccttatgcgactcctgcattaggaagcagcccagtagtaggttgagg4740ccgttgagcaccgccgccgcaaggaatggtgcatgcaaggagatggcgcccaacagtccc4800ccggccacggggcctgccaccatacccacgccgaaacaagcgctcatgagcccgaagtgg4860cgagcccgatcttccccatcggtgatgtcggcgatataggcgccagcaaccgcacctgtg4920gcgccggtgatgccggccacgatgcgtccggcgtagaggatcgagatctcgatcccgcga4980aattaatacgactcactataggggaattgtgagcggataacaattcccctctagaaataa5040ttttgtttaactttaagaaggagatatacgatgtacgactatataatcgttggtgctgga5100tctgcaggatgtgtgcttgctaatcgtctttcggccgacccctctaaaagagtttgttta5160cttgaagctgggccgcgagatacgaatccgctaattcatatgccgttaggtattgctttg5220ctttcaaatagtaaaaagttgaattgggcttttcaaactgcgccacagcaaaatctcaac5280ggccggagccttttctggccacgaggaaaaacgttaggtggttcaagctcaatcaacgca5340atggtctatatccgagggcatgaagacgattaccacgcatgggagcaggcggccggccgc5400tactggggttggtaccgggctcttgagttgttcaaaaggcttgaatgcaaccagcgattc5460gataagtccgagcaccatggggttgacggagaattagctgttagtgatttaaaatatatc5520aatccgcttagcaaagcattcgtgcaagccggcatggaggccaatattaatttcaacgga5580gatttcaacggcgagtaccaggacggcgtagggttctatcaagtaacccaaaaaaatgga5640caacgctggagctcggcgcgtgcattcttgcacggtgtactttccagaccaaatctagac5700atcattactgatgcgcatgcatcaaaaattctttttgaagaccgtaaggcggttggtgtt5760tcttatataaagaaaaatatgcaccatcaagtcaagacaacgagtggtggtgaagtactt5820cttagtcttggcgcagtcggcacgcctcaccttctaatgctttctggtgttggggctgca5880gccgagcttaaggaacatggtgtttctctagtccatgatcttcctgaggtggggaaaaat5940cttcaagatcatttggacatcacattgatgtgcgcagcaaattcgagagagccgataggt6000gttgctctttctttcatccctcgtggtgtctcgggtttgttttcatatgtgtttaagcgc6060gaggggtttctcactagtaacgtggcagagtcgggtggttttgtaaaaagttctcctgat6120cgtgatcggcccaatttgcagtttcatttccttccaacttatcttaaagatcacggtcga6180aaaatagcgggtggttatggttatacgctacatatatgtgatcttttgcctaagagccga6240ggcagaattggcctaaaaagcgccaatccattacagccgcctttaattgacccgaactat6300cttagcgatcatgaagatattaaaaccatgattgcgggtattaagatagggcgcgctatt6360ttgcaggccccatcgatggcgaagcattttaagcatgaagtagtaccgggccaggctgtt6420aaaactgatgatgaaataatcgaagatattcgtaggcgagctgagactatataccatccg6480gtaggtacttgtaggatgggtaaagatccagcgtcagttgttgatccgtgcctgaagatc6540cgtgggttggcaaatattagagtcgttgatgcgtcaattatgccgcacttggtcgcgggt6600aacacaaacgctccaactattatgattgcagaaaatgcggcagaaataattatgcggaat6660cttgatgtggaagcattagaggctagcgctgagtttgctcgcgagggtgcagagctagag6720ttggcctggcgcgccctcgagggatcccacgtgctggtgccgcgtggcagcgcggccgca6780ctggagcaccaccaccaccaccaccaccactgagatccggctgctaacaaagcccgaaag6840gaagctgagttggctgctgccaccgctgagcaataactagcataaccccttggggcctct6900aaacgggtcttgaggggttttttgctgaaaggaggaactatatccggat6949<210>21<211>378<212>prt<213>枯草芽孢杆菌<400>21metileileglyvalprolysgluilelysasnasngluasnargval151015alaleuthrproglyglyvalserglnleuileserasnglyhisarg202530valleuvalgluthrglyalaglyleuglyserglyphegluasnglu354045alatyrgluseralaglyalagluileilealaaspprolysglnval505560trpaspalaglumetvalmetlysvallysgluproleuprogluglu65707580tyrvaltyrphearglysglyleuvalleuphethrtyrleuhisleu859095alaalagluprogluleualaglnalaleulysasplysglyvalthr100105110alailealatyrgluthrvalsergluglyargthrleuproleuleu115120125thrprometsergluvalalaglyargmetalaalaglnileglyala130135140glnpheleuglulysprolysglyglylysglyileleuleualagly145150155160valproglyvalserargglylysvalthrileileglyglyglyval165170175valglythrasnalaalalysmetalavalglyleuglyalaaspval180185190thrileilealaargasnalaaspargleuargglnleuaspaspile195200205pheglyhisglnilelysthrleuileserasnprovalasnileala210215220aspalavalalaglualaaspleuleuilecysalavalleuilepro225230235240glyalalysalaprothrleuvalthrgluglumetvallysglnmet245250255lysproglyservalilevalaspvalalaileaspglnglyglyile260265270valgluthrvalasphisilethrthrhisaspglnprothrtyrglu275280285lyshisglyvalvalhistyralavalalaasnmetproglyalaval290295300proargthrserthrilealaleuthrasnvalthrvalprotyrala305310315320leuglnilealaasnlysglyalavallysalaleualaaspasnthr325330335alaleuargalaglyleuasnthralaasnglyhisvalthrtyrglu340345350alavalalaargaspleuglytyrglutyrvalproalaglulysala355360365leuglnaspgluserservalalaglyala370375<210>22<211>1137<212>dna<213>枯草芽孢杆菌<400>22atgatcataggggttcctaaagagataaaaaacaatgaaaaccgtgtcgcattaacaccc60gggggcgtttctcagctcatttcaaacggccaccgggtgctggttgaaacaggcgcgggc120cttggaagcggatttgaaaatgaagcctatgagtcagcaggagcggaaatcattgctgat180ccgaagcaggtctgggacgccgaaatggtcatgaaagtaaaagaaccgctgccggaagaa240tatgtttattttcgcaaaggacttgtgctgtttacgtaccttcatttagcagctgagcct300gagcttgcacaggccttgaaggataaaggagtaactgccatcgcatatgaaacggtcagt360gaaggccggacattgcctcttctgacgccaatgtcagaggttgcgggcagaatggcagcg420caaatcggcgctcaattcttagaaaagcctaaaggcggaaaaggcattctgcttgccggg480gtgcctggcgtttcccgcggaaaagtaacaattatcggaggaggcgttgtcgggacaaac540gcggcgaaaatggctgtcggcctcggtgcagatgtgacgatcattgcccgtaacgcagac600cgcttgcgccagcttgatgacatcttcggccatcagattaaaacgttaatttctaatccg660gtcaatattgctgatgctgtggcggaagcggatctcctcatttgcgcggtattaattccg720ggtgctaaagctccgactcttgtcactgaggaaatggtaaaacaaatgaaacccggttca780gttattgttgatgtagcgatcgaccaaggcggcatcgtcgaaactgtcgaccatatcaca840acacatgatcagccaacatatgaaaaacacggggttgtgcattatgctgtagcgaacatg900ccaggcgcagtccctcgtacatcaacaatcgccctgactaacgttactgttccatacgcg960ctgcaaatcgcgaacaaaggggcagtaaaagcgctcgcagacaatacggcactgagagcg1020ggtttaaacaccgcaaacggacacgtgacctatgaagctgtagcaagagatctaggctat1080gagtatgttcctgccgagaaagctttacaggatgaatcatctgtggcgggtgcttaa1137<210>23<211>353<212>prt<213>大肠杆菌<400>23metleutyrthrserglnthrthrproglulysaspglnlysmetser151015metilelyssertyralaalalysglualaglyglygluleugluval202530tyrglutyraspproglygluleuargproglnaspvalgluvalgln354045valasptyrcysglyilecyshisseraspleusermetileaspasn505560glutrpglypheserglntyrproleuvalalaglyhisgluvalile65707580glyargvalvalalaleuglyseralaalaglnasplysglyleugln859095valglyglnargvalglyileglytrpthralaargsercysglyhis100105110cysaspalacysileserglyasnglnileasncysgluglnglyala115120125valprothrilemetasnargglyglyphealaglulysleuargala130135140asptrpglntrpvalileproleuprogluasnileaspilegluser145150155160alaglyproleuleucysglyglyilethrvalphelysproleuleu165170175methishisilethralathrserargvalglyvalileglyilegly180185190glyleuglyhisilealailelysleuleuhisalametglycysglu195200205valthralapheserserasnproalalysgluglngluvalleuala210215220metglyalaasplysvalvalasnserargaspproglnalaleulys225230235240alaleualaglyglnpheaspleuileileasnthrvalasnvalser245250255leuasptrpglnprotyrpheglualaleuthrtyrglyglyasnphe260265270histhrvalglyalavalleuthrproleuservalproalaphethr275280285leuilealaglyaspargservalserglyseralathrglythrpro290295300tyrgluleuarglysleumetargphealaalaargserlysvalala305310315320prothrthrgluleupheprometserlysileasnaspalailegln325330335hisvalargaspglylysalaargtyrargvalvalleulysalaasp340345350phe<210>24<211>349<212>prt<213>大肠杆菌<400>24metlysilelysalavalglyalatyrseralalysglnproleuglu151015prometaspilethrargarggluproglyproasnaspvallysile202530gluilealatyrcysglyvalcyshisseraspleuhisglnvalarg354045serglutrpalaglythrvaltyrprocysvalproglyhisgluile505560valglyargvalvalalavalglyaspglnvalglulystyralapro65707580glyaspleuvalglyvalglycysilevalaspsercyslyshiscys859095gluglucysgluaspglyleugluasntyrcysasphismetthrgly100105110thrtyrasnserprothrproaspgluproglyhisthrleuglygly115120125tyrserglnglnilevalvalhisgluargtyrvalleuargilearg130135140hisproglngluglnleualaalavalalaproleuleucysalagly145150155160ilethrthrtyrserproleuarghistrpglnalaglyproglylys165170175lysvalglyvalvalglyileglyglyleuglyhismetglyilelys180185190leualahisalametglyalahisvalvalalaphethrthrserglu195200205alalysargglualaalalysalaleuglyalaaspgluvalvalasn210215220serargasnalaaspglumetalaalahisleulysserpheaspphe225230235240ileleuasnthrvalalaalaprohisasnleuaspaspphethrthr245250255leuleulysargaspglythrmetthrleuvalglyalaproalathr260265270prohislysserprogluvalpheasnleuilemetlysargargala275280285ilealaglysermetileglyglyileprogluthrglnglumetleu290295300aspphecysalagluhisglyilevalalaaspileglumetilearg305310315320alaaspglnileasnglualatyrgluargmetleuargglyaspval325330335lystyrargphevalileaspasnargthrleuthrasp340345<210>25<211>789<212>dna<213>罗尔斯通氏菌属<400>25atggctagcagaggatcgcatcaccatcaccatcacggcgcctatcgactattaaacaaa60acagccgtcataaccggtggaaacagcggcattggcctcgccacagcgaagcgcttcgtt120gccgagggtgcctatgtattcattgtcggtcgccggcggaaggaactcgagcaggcggcc180gcagaaatcggtcggaatgtcacggcggtcaaagccgatgtgacaaagcttgaagacctg240gaccgactttacgcgattgtgcgtgagcaacggggtagcatcgacgtactatttgcgaat300tccggcgcaatcgagcaaaagacgcttgaggagattactccggaacactatgacaggact360ttcgatgtcaacgttcggggattgatcttcaccgtgcagaaggcacttcctctgctgcga420gacggcggcagcgtgatcctgacaagctcggtagccggcgtcctaggattacaggcgcac480gacacgtatagtgccgccaaggcagcggtaaggtcgctcgcgaggacatggaccactgag540ttgaaaggtcgcagcattcgtgtcaacgcggtaagcccaggggcgatcgacacgcctatc600atagaaaaccaggtctctacacaggaagaagctgacgagctgcgtgcgaaatttgcagct660gcgacgcccctgggtcgcgtcggacgacctgaagagctggcagcggccgtgttatttctt720gcatcggacgacagtagctacgtagccggcattgagctgtttgtggacggtggattgacc780caggtctaa789<210>26<211>459<212>prt<213>青紫色素杆菌atcc12472<400>26metglnlysglnargthrthrserglntrparggluleuaspalaala151015hishisleuhisprophethraspthralaserleuasnglnalagly202530alaargvalmetthrargglygluglyvaltyrleutrpaspserglu354045glyasnlysileileaspglymetalaglyleutrpcysvalasnval505560glytyrglyarglysaspphealaglualaalaargargglnmetglu65707580gluleuprophetyrasnthrphephelysthrthrhisproalaval859095valgluleuserserleuleualagluvalthrproalaglypheasp100105110argvalphetyrthrasnserglysergluservalaspthrmetile115120125argmetvalargargtyrtrpaspvalglnglylysproglulyslys130135140thrleuileglyargtrpasnglytyrhisglyserthrileglygly145150155160alaserleuglyglymetlystyrmethisgluglnglyaspleupro165170175ileproglymetalahisilegluglnprotrptrptyrlyshisgly180185190lysaspmetthrproaspglupheglyvalvalalaalaargtrpleu195200205gluglulysileleugluileglyalaasplysvalalaalapheval210215220glygluproileglnglyalaglyglyvalilevalproproalathr225230235240tyrtrpprogluilegluargilecysarglystyraspvalleuleu245250255valalaaspgluvalilecysglypheglyargthrglyglutrpphe260265270glyhisglnhispheglypheglnproaspleuphethralaalalys275280285glyleuserserglytyrleuproileglyalavalphevalglylys290295300argvalalagluglyleuilealaglyglyasppheasnhisglyphe305310315320thrtyrserglyhisprovalcysalaalavalalahisalaasnval325330335alaalaleuargaspgluglyilevalglnargvallysaspaspile340345350glyprotyrmetglnlysargtrparggluthrpheserargpheglu355360365hisvalaspaspvalargglyvalglymetvalglnalaphethrleu370375380vallysasnlysalalysarggluleupheproasppheglygluile385390395400glythrleucysargaspilephepheargasnasnleuilemetarg405410415alacysglyasphisilevalseralaproproleuvalmetthrarg420425430alagluvalaspglumetleualavalalagluargcysleugluglu435440445phegluglnthrleulysalaargglyleuala450455<210>27<211>452<212>prt<213>恶臭假单胞菌<400>27metsergluglnasnserglnthrglnalatrpglnalaleuserarg151015asphishisleualapropheseraspvallysglnleualaglulys202530glyproargileilethrseralalysglyvaltyrleutrpaspser354045gluglyasnlysileleuaspglymetalaglyleutrpcysvalala505560valglytyrglyargaspgluleualagluvalalaserglnglnmet65707580lysglnleuprotyrtyrasnleuphepheglnthralahispropro859095alaleugluleualalysalailealaaspvalalaproglnglymet100105110asnhisvalphephethrglyserglysergluglyasnaspthrval115120125leuargmetvalarghistyrtrpalaleulysglylyslysasnlys130135140asnvalileileglyargileasnglytyrhisglyserthrvalala145150155160glyalaalaleuglyglymetserglymethisglnglnglyglyval165170175ileproaspilevalhisileproglnprotyrtrppheglyglugly180185190glyaspmetthrglualaasppheglyvaltrpalaalagluglnleu195200205glulyslysileleugluvalglyvalaspasnvalalaalapheile210215220alagluproileglnglyalaglyglyvalileileproproglnthr225230235240tyrtrpprolysvallysgluileleualaargtyraspileleuphe245250255valalaaspgluvalilecysglypheglyargthrglyglutrpphe260265270glythrasptyrtyraspleulysproaspleumetthrilealalys275280285glyleuthrserglytyrileprometglyglyvalilevalargasp290295300gluvalalalysvalilesergluglyglyasppheasnhisglyphe305310315320thrtyrserglyhisprovalalaalaalavalglyleugluasnleu325330335argileleuargaspgluglnileileglnglnvalhisasplysthr340345350alaprotyrleuglnglnargleuarggluleualaasphisproleu355360365valglygluvalargglyleuglymetleuglyalailegluleuval370375380lysasplysalathrargalaargtyrgluglylysglyvalglymet385390395400ilecysargglnhiscyspheaspasnglyleuilemetargalaval405410415glyaspthrmetileilealaproproleuvalileservalgluglu420425430ileaspgluleuvalglnlysalaarglyscysleuaspleuthrtyr435440445glualavalarg450<210>28<211>452<212>prt<213>恶臭假单胞菌<400>28metsergluglnasnserglnthrglnalatrpglnalaleuserarg151015asphishisleualapropheseraspvallysglnleualaglulys202530glyproargileilethrseralalysglyvaltyrleutrpaspser354045gluglyasnlysileleuaspglymetalaglyleutrpcysvalala505560valglytyrglyargaspgluleualagluvalalaserglnglnmet65707580lysglnleuprotyrtyrasnleuphepheglnthralahispropro859095alaleugluleualalysalailealaaspvalalaproglnglymet100105110asnhisvalphephethrglyserglysergluglyasnaspthrval115120125leuargmetvalarghistyrtrpalaleulysglylyslysasnlys130135140asnvalileileglyargileasnglytyrhisglyserthrvalala145150155160glyalaalaleuglyglymetserglymethisglnglnglyglyval165170175ileproaspilevalhisileproglnprotyrtrppheglyglugly180185190glyaspmetthrglualaasppheglyvaltrpalaalagluglnleu195200205glulyslysileleugluvalglyvalaspasnvalalaalapheile210215220alagluproileglnglyalaglyglyvalileileproproglnthr225230235240tyrtrpprolysvallysgluileleualaargtyraspileleuphe245250255valalaaspgluvalilecysglypheglyargthrglyglutrpphe260265270glythrasptyrtyraspleulysproaspleumetthrilealalys275280285glyleuthrserglytyrileprometglyglyvalilevalargasp290295300gluvalalalysvalilesergluglyglyasppheasnhisglyphe305310315320thrtyrserglyhisprovalalaalaalavalglyleugluasnleu325330335argileleuargaspgluglnileileglnglnvalhisasplysthr340345350alaprotyrleuglnglnargleuarggluleualaasphisproleu355360365valglygluvalargglyleuglymetleuglyalailegluleuval370375380lysasplysalathrargalaargtyrgluglylysglyvalglymet385390395400ilecysargglnhiscyspheaspasnglyleuilemetargalaval405410415glyaspthrmetileilealaproproleuvalileservalgluglu420425430ileaspgluleuvalglnlysalaarglyscysleuaspleuthrtyr435440445glualavalarg450<210>29<211>453<212>prt<213>恶臭假单胞菌<400>29metservalasnasnproglnthrargglutrpglnthrleusergly151015gluhishisleualapropheserasptyrlysglnleulysglulys202530glyproargileilethrlysalaglnglyvalhisleutrpaspser354045gluglyhislysileleuaspglymetalaglyleutrpcysvalala505560valglytyrglyargglugluleuvalglnalaalaglulysglnmet65707580arggluleuprotyrtyrasnleuphepheglnthralahispropro859095alaleugluleualalysalailethraspvalalaproglnglymet100105110thrhisvalphephethrglyserglysergluglyasnaspthrval115120125leuargmetvalarghistyrtrpalaleulysglylysprohislys130135140glnthrileileglyargileasnglytyrhisglyserthrpheala145150155160glyalacysleuglyglymetserglymethisgluglnglyglyleu165170175proileproglyilevalhisileproglnprotyrtrppheglyglu180185190glyglyaspmetthrproaspalapheglyvaltrpalaalaglugln195200205leuglulyslysileleugluvalglygluaspasnvalalaalaphe210215220ilealagluproileglnglyalaglyglyvalileileproproglu225230235240thrtyrtrpprolysvallysgluileleualalystyraspileleu245250255phevalalaaspgluvalilecysglypheglyargthrglyglutrp260265270pheglyserasptyrtyraspleulysproaspleumetthrileala275280285lysglyleuthrserglytyrileprometglyglyvalilevalarg290295300aspthrvalalalysvalilesergluglyglyasppheasnhisgly305310315320phethrtyrserglyhisprovalalaalaalavalglyleugluasn325330335leuargileleuargaspglulysilevalglulysalaargthrglu340345350alaalaprotyrleuglnlysargleuarggluleuglnasphispro355360365leuvalglygluvalargglyleuglymetleuglyalailegluleu370375380vallysasplysalathrargserargtyrgluglylysglyvalgly385390395400metilecysargthrphecyspheaspasnglyleuilemetargala405410415valglyaspthrmetileilealaproproleuvalileserhisala420425430gluileaspgluleuvalglulysalaarglyscysleuaspleuthr435440445leuglualaileasn450<210>30<211>455<212>prt<213>球形红杆菌<400>10metargaspaspalaproasnsertrpgluserargalaaspalaser151015serphetyrglyphethraspleuproservalhisglnargglythr202530valvalleuthrhisglylysglyprotyriletyraspvalhisgly354045argalatyrleuaspalaasnserglyleutrpasnmetvalalagly505560pheasphisproglyleuileglualaalalysalaglntyrgluarg65707580pheproglytyrhisalaphepheglyargmetseraspglnthrval859095metleuserglulysleuvalgluvalserprophealaargglyarg100105110valphetyrthrasnserglyserglualaasnaspthrmetvallys115120125metleutrppheleuglyalaalagluglyhisprogluargarglys130135140ileilethrargvalasnsertyrhisglyvalthralavalserala145150155160sermetthrglylysprotyrasnserleupheglyleuproleupro165170175glypheilehisvalglycysprohistyrtrpargpheglyglnala180185190glygluthrglualagluphethrglnargleualaarggluleuglu195200205alathrileilelysgluglyproaspthrilealaglyphepheala210215220gluprovalmetglyalaglyglyvalileproprosergluglytyr225230235240pheglnalavalglnprovalleulysargtyrglyileproleuile245250255alaaspgluvalilecysglypheglyargthrglyasnthrtrpgly260265270cysglnthrtyraspphemetproaspglyileileserserlysasn275280285ilethralaglyphepheprometglyalavalileleuglyproglu290295300leualaaspargleuglnalaalaserglualavalglugluphepro305310315320hisglyphethralaserglyhisprovalglycysalailealaleu325330335lysalaileaspvalvalmetasngluglyleualagluasnvalarg340345350alaleuthrprolyspheglualaglyleualatyrleualagluasn355360365proasnileglyglutrpargglylysglyleumetglyalaleuglu370375380alavallysasplysalathrlysthrpropheproglyaspleuser385390395400valsergluargilealaasnsercysthrasphisglyleuilecys405410415argproleuglyglnserilevalleucyspropropheilemetthr420425430glualaglnmetaspglumetpheglulysleuglyalaalaleulys435440445lysvalphealagluvalala450455<210>31<211>23<212>dna<213>人工序列<220><223>引物<400>31gccatcataggggttcctaaaga23<210>32<211>30<212>dna<213>人工序列<220><223>引物<400>32actgatggtaccttaagcacccgccacaga30<210>33<211>33<212>dna<213>人工序列<220><223>引物<400>33gtgacgatcattgcccgtaacgcagaccgcttg33<210>34<211>33<212>dna<213>人工序列<220><223>引物<400>34caagcggtctgcgttacgggcaatgatcgtcac33<210>35<211>27<212>dna<213>人工序列<220><223>引物<400>35gcctatcgactattaaacaaaacagcc27<210>36<211>30<212>dna<213>人工序列<220><223>引物<400>36actgatggtaccttagacctgggtcaatcc30<210>37<211>1401<212>dna<213>脱氮副球菌<400>37atggctagcagaggatcgcatcaccatcaccatcacggcgccaaccaaccgcaaagctgg60gaagcccgggccgagacctattcgctctacggtttcaccgacatgccctcggtccatcag120cggggcacggtcgtcgtgacccatggcgaggggccctatatcgtcgatgtccatggccgc180cgctatctggatgccaattcgggcctgtggaacatggtcgcgggcttcgaccacaagggc240ctgatcgaggccgccaaggcgcaatacgaccgctttcccggctatcacgcctttttcggc300cgcatgtccgaccagaccgtgatgctgtcggaaaagctggtcgaggtctcgccattcgac360aacggccgggtcttctataccaattccggctccgaggcgaacgacaccatggtcaagatg420ctgtggttcctgcatgccgccgagggcaagccgcaaaagcgcaagatcctgacgcgctgg480aacgcctatcacggcgtgaccgcggtttcggcctcgatgaccggcaagccctacaactcg540gtcttcggcctgccgctgcccggcttcatccacctgacctgcccgcattactggcgctat600ggcgaggaaggcgagaccgaggcgcaattcgtcgcccgcctggcacgcgagcttgaggat660accatcacccgcgagggcgccgacaccatcgccggcttcttcgccgagccggtgatgggc720gcggggggggtgatcccgccggcgaagggttatttccaggccatcctgccgatcttgcgc780aagtatgacatcccgatgatctcggacgaggtgatctgcggcttcgggcgcaccggcaac840acctggggctgcctgacctacgacttcatgcccgatgcgatcatctcgtccaagaacctg900actgcgggcttcttcccgatgggcgccgtcatcctcgggcccgacctcgccaagcgggtc960gaggccgcggtcgaggcgatcgaggagttcccgcacggcttcaccgcctcgggccatccg1020gtcggctgcgccatcgcgctgaaggccatcgacgtggtgatgaacgaggggctggccgag1080aatgtccgccgcctcgcaccccgcttcgaggcggggctgaagcgcatcgccgaccgcccg1140aacatcggcgaataccgcggcatcggcttcatgtgggcgctggaggcggtcaaggacaag1200ccgaccaagacccccttcgacgccaatctttcggtcagcgagcgcatcgccaatacctgc1260accgatctggggctgatctgccggccgctgggccagtccatcgtgctgtgcccgcccttc1320atcctgaccgaggcgcagatggacgagatgttcgaaaagctggaaaaggcgctcgacaag1380gtctttgccgaggtggcctaa1401<210>38<211>23<212>dna<213>人工序列<220><223>引物<400>38gccaaccaaccgcaaagctggga23<210>39<211>33<212>dna<213>人工序列<220><223>引物<400>39actgataagcttttaggccacctcggcaaagac33<210>40<211>24<212>dna<213>人工序列<220><223>引物<400>40ctgccggccaatgggccagtccat24<210>41<211>24<212>dna<213>人工序列<220><223>引物<400>41atggactggcccattggccggcag24<210>42<211>391<212>prt<213>人工序列<220><223>具有his-标签的枯草芽孢杆菌蛋白<400>42metalaserargglyserhishishishishishisglyalaileile151015glyvalprolysgluilelysasnasngluasnargvalalaleuthr202530proglyglyvalserglnleuileserasnglyhisargvalleuval354045gluthrglyalaglyleuglyserglyphegluasnglualatyrglu505560seralaglyalagluileilealaaspprolysglnvaltrpaspala65707580glumetvalmetlysvallysgluproleuprogluglutyrvaltyr859095phearglysglyleuvalleuphethrtyrleuhisleualaalaglu100105110progluleualaglnalaleulysasplysglyvalthralaileala115120125tyrgluthrvalsergluglyargthrleuproleuleuthrpromet130135140sergluvalalaglyargmetalaalaglnileglyalaglnpheleu145150155160glulysprolysglyglylysglyileleuleualaglyvalprogly165170175valserargglylysvalthrileileglyglyglyvalvalglythr180185190asnalaalalysmetalavalglyleuglyalaaspvalthrileile195200205alaargasnalaaspargleuargglnleuaspaspilepheglyhis210215220glnilelysthrleuileserasnprovalasnilealaaspalaval225230235240alaglualaaspleuleuilecysalavalleuileproglyalalys245250255alaprothrleuvalthrgluglumetvallysglnmetlysprogly260265270servalilevalaspvalalaileaspglnglyglyilevalgluthr275280285valasphisilethrthrhisaspglnprothrtyrglulyshisgly290295300valvalhistyralavalalaasnmetproglyalavalproargthr305310315320serthrilealaleuthrasnvalthrvalprotyralaleuglnile325330335alaasnlysglyalavallysalaleualaaspasnthralaleuarg340345350alaglyleuasnthralaasnglyhisvalthrtyrglualavalala355360365argaspleuglytyrglutyrvalproalaglulysalaleuglnasp370375380gluserservalalaglyala385390<210>43<211>1176<212>dna<213>人工序列<220><223>具有his-标签的枯草芽孢杆菌蛋白<400>43atggctagcagaggatcgcatcaccatcaccatcacggcgccatcataggggttcctaaa60gagataaaaaacaatgaaaaccgtgtcgcattaacacccgggggcgtttctcagctcatt120tcaaacggccaccgggtgctggttgaaacaggcgcgggccttggaagcggatttgaaaat180gaagcctatgagtcagcaggagcggaaatcattgctgatccgaagcaggtctgggacgcc240gaaatggtcatgaaagtaaaagaaccgctgccggaagaatatgtttattttcgcaaagga300cttgtgctgtttacgtaccttcatttagcagctgagcctgagcttgcacaggccttgaag360gataaaggagtaactgccatcgcatatgaaacggtcagtgaaggccggacattgcctctt420ctgacgccaatgtcagaggttgcgggcagaatggcagcgcaaatcggcgctcaattctta480gaaaagcctaaaggcggaaaaggcattctgcttgccggggtgcctggcgtttcccgcgga540aaagtaacaattatcggaggaggcgttgtcgggacaaacgcggcgaaaatggctgtcggc600ctcggtgcagatgtgacgatcattgcccgtaacgcagaccgcttgcgccagcttgatgac660atcttcggccatcagattaaaacgttaatttctaatccggtcaatattgctgatgctgtg720gcggaagcggatctcctcatttgcgcggtattaattccgggtgctaaagctccgactctt780gtcactgaggaaatggtaaaacaaatgaaacccggttcagttattgttgatgtagcgatc840gaccaaggcggcatcgtcgaaactgtcgaccatatcacaacacatgatcagccaacatat900gaaaaacacggggttgtgcattatgctgtagcgaacatgccaggcgcagtccctcgtaca960tcaacaatcgccctgactaacgttactgttccatacgcgctgcaaatcgcgaacaaaggg1020gcagtaaaagcgctcgcagacaatacggcactgagagcgggtttaaacaccgcaaacgga1080cacgtgacctatgaagctgtagcaagagatctaggctatgagtatgttcctgccgagaaa1140gctttacaggatgaatcatctgtggcgggtgcttaa1176当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1