一种基于基因捕获和二代测序技术的脊髓性肌萎缩症相关基因拷贝数检测试剂盒及方法与流程
本发明涉及生物医药领域,具体涉及一种检测试剂盒,尤其涉及一种基于基因捕获和二代测序技术的脊髓性肌萎缩症相关基因拷贝数的检测试剂盒。此外,本发明还涉及一种基于基因捕获和二代测序技术的脊髓性肌萎缩症相关基因拷贝数的检测方法。该方法采用目标区域捕获和二代测序,并涉及数据统计分析用于估算脊髓性肌萎缩症相关基因的拷贝数。
背景技术:
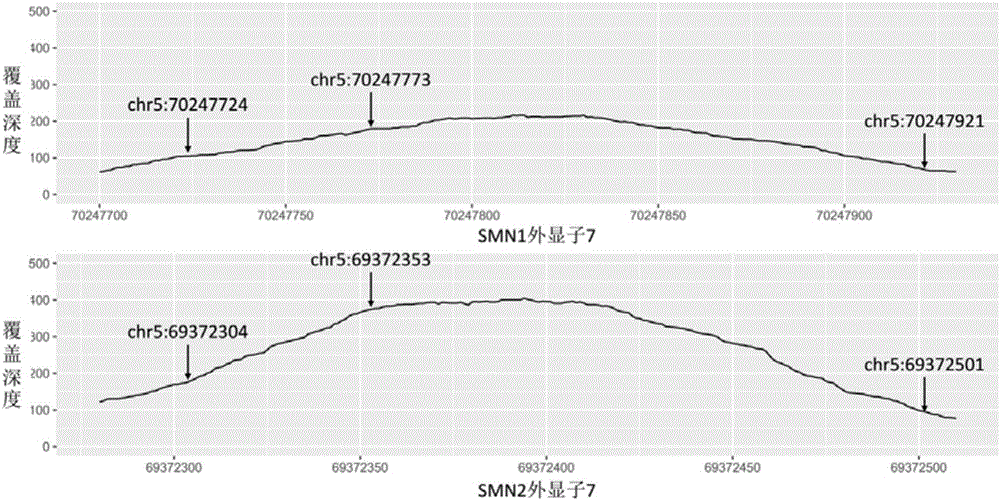
:脊髓型肌肉萎缩症(Spinalmuscularatrophy,SMA)是一类由脊髓前角运动神经元退化导致肌萎缩的疾病。根据患者的发病率和临床表现,SMA可分为四类:I型(严重型)、II型(中间型)、III型(轻型)和IV型(成人型)。SMA为常染色体隐性遗传病,发病率为1/5000-1/10000,高居致死性常染色体遗传病的第二位,携带者频率为1/35-1/80。一般正常人的第五号染色体有两个高度同源的运动神经元存活基因(survivalmotorneurongene,SMN),即靠近染色体末端的SMN1基因和靠近着丝粒的SMN2基因。SMN1和SMN2包括9个外显子:1,2a,2b,3~8,但只有外显子7和8上的两个核苷酸(外显子7:c.840C>T,外显子8:c.*239G>A)可以区分SMN1和SMN2。此外,外显子7上下游还各有一个碱基(c.835-44G>A,c.*3+100A>G)可以区分SMN1和SMN2。外显子7上单个碱基的差异影响SMN2基因的RNA剪切,使得转录出来的mRNA缺少外显子7,进而导致翻译出来的蛋白质不稳定。SMN2的主要功能就是对SMN1的有限补偿。95%~98%的患者可以检测出SMN1基因的外显子7发生纯合性缺失(homozygousdeletion),而另外约2.5%的患者是由点突变所导致。SMA携带者只有一个拷贝的SMN1外显子7,虽然自己不会发病,但如果父母双方均为携带者,那么其子代有25%可能性发病。所以,对人SMN1的外显子7拷贝数进行定量检测,有助于临床相关疾病的诊断以及新生儿SMA出生缺陷预防;而SMN2外显子7拷贝数的检测,则有助于判断SMA患者的严重程度,例如SMN2拷贝数大于2的患者的病情相对较轻。目前针对SMN1/2点突变导致脊髓型肌肉萎缩症或其携带者,有专利(专利号CN105112541A)在IonTorrent平台上采用二代测序技术检测SMN1/2上的点突变,但该二代测序方法(扩增子测序)由于PCR的偏好性会导致目标区域的测序深度不均一,且对于碱基多聚体(homopolyer)和插入缺失有较高的测序错误率,因而不能有效地用来检测SMN1/2的拷贝数变异。而针对SMN1外显子缺失的基因检测技术则包括:PCR限制性片段长度多态性(PCR-RFLP,比如文献vanderSteegeG.etc.Lancet.1995,345:985-986)、变性高效液相色谱分析(DHPLC,专利号CN1769486A)、多重连接依赖性探针扩增(MLPA)、定量PCR技术(专利号CN103789440A、CN104480206A)和三代测序(专利号CN104762398A)等。但是,PCR-RFLP只能检测纯合性缺失,而MLPA和定量PCR技术对于存在点突变的样本会造成假阳性结果。而基于三代测序检测SMA拷贝数方法,目前费用较高且通量较小。另外,用于区分SMN1和SMN2外显子7的位点相隔较近(小于200bp),二代测序技术的读长足以用于涵盖这些位点以检测SMN1和SMN2拷贝数变化。2017年,FengYM等人基于杂交捕获和二代测序技术开发了一种SMN1/2拷贝数检测方法(Genet.Med.,2017,doi:10.1038/gim.2016.215)。该方法基于SMN1/2的测序深度和同一批次样本的归一化处理,根据外显子7上的单个碱基(c.840C>T)区分SMN1和SMN2,检测两个基因的拷贝数变异。由于FengYM的方法仅利用一个外显子区域的差异位点,且只使用同一批次的数据对新样本进行结果预测,对于小样本批次的检测准确度会有较大的波动,且不能有效地利用历史累积数据提高检测方法的精确度。本发明充分利用基因捕获(genecapture-basedsequencing)的技术克服扩增子测序(AmpliconSequencing)所带来的测序不均一问题,且采用错误率更低、稳定性更好、通量更大的Illumina二代测序平台获取目标基因的序列信息,并结合自己开发的针对脊髓型肌肉萎缩症(SMA)高度同源的两个基因(SMN1和SMN2)的独特算法流程,可有效的检测出SMN1/2的7号外显子的纯合性缺失、杂合性缺失和拷贝数的增多。同时,本发明对于SMN1/2的7号外显子拷贝数变化检测,有较高的健壮性、敏感性和特异性。技术实现要素:本发明要解决的技术问题是提供一种基于基因捕获和二代测序技术的脊髓性肌萎缩症相关基因拷贝数检测试剂盒,用于解决现有方法测序深度不均一、错误率较高、稳定性不好、通量较小等问题。为此,本发明还提供该基于基因捕获和二代测序技术的脊髓性肌萎缩症相关基因拷贝数检测方法,用于解决SMN1和SMN2基因高度同源性以及外显子拷贝数变化多样性问题。为解决上述技术问题,本发明采用如下技术方案:在本发明的一方面,提供本发明公开了一种基于基因捕获和二代测序技术的脊髓性肌萎缩症相关基因拷贝数检测试剂盒,包括捕获探针,所述捕获探针由以下4个主要探针和相关对照探针组成;4个主要探针为:用于捕获SMN2基因外显子7的探针一,其序列如SEQIDNO:1所示;用于捕获SMN2基因外显子7的探针二,其序列如SEQIDNO:2所示;用于捕获SMN1基因外显子7的探针三,其序列如SEQIDNO:3所示;用于捕获SMN1基因外显子7的探针四,其序列如SEQIDNO:4所示;所述捕获探针对目标区域进行捕获,测序,通过数据分析估算SMN1基因和SMN2基因外显子7的拷贝数。所述相关对照探针可以为安捷伦ClearSeq探针组(一种捕获试剂)或定制化的探针组等本领域常用对照探针。作为本发明优选的技术方案,所述数据分析包括将测序读段使用比对软件比对到人参考基因组、去除重复序列、去除比对结果不可信的读段,计算Z-score,根据Z-score值来估算SMN1基因和SMN2基因外显子7的拷贝数。作为本发明优选的技术方案,所述去除重复序列具体使用Picard去除PCR扩增过程产生的重复序列。作为本发明优选的技术方案,所述比对结果不可信的读段为不涵盖任何一个如下所述用于区分分配到SMN1和SMN2外显子7的位点的读段:染色体chr5,坐标69372304,SMN2基因,外显子7上游44bp,核苷酸A;染色体chr5,坐标69372353,SMN2基因,外显子7,核苷酸T;染色体chr5,坐标69372501,SMN2基因,外显子7下游100bp,核苷酸G;染色体chr5,坐标70247724,SMN1基因,外显子7上游44bp,核苷酸G;染色体chr5,坐标70247773,SMN1基因,外显子7,核苷酸C;染色体chr5,坐标70247921,SMN1基因,外显子7下游100bp,核苷酸A。作为本发明优选的技术方案,所述计算Z-score具体包括如下步骤:步骤1,计算覆盖深度:将目标捕获区域划分为固定长度的区间,并计算每个区间的平均覆盖深度;所述覆盖深度是指分配至所述区间的读段数目与该区间大小的比值;步骤2,标准化覆盖深度:标准化是相对于同一个样本所有区间(SMN1和SMN2外显子7和其它相关对照探针所捕获的区间)进行计算的,公式如下:步骤3,GC(鸟嘌呤胞嘧啶)含量矫正:去除由于GC含量差异而造成的测序结果偏差,公式如下:步骤4,计算Z-score:对于一批样本中的每个样本,按如下公式计算Z-score:其中,Zi,j表示第j个样本的外显子i的Z-score值,normRD′i,j为第j个样本外显子i经步骤3计算得到的覆盖深度,和SD(normRD′i)分别为该批样本外显子i校正后覆盖深度的平均值和标准差。作为本发明优选的技术方案,所述根据Z-score值来估算SMN1基因和SMN2基因外显子7的拷贝数具体为:基于表型已知样本,习得SMN1基因和SMN2基因外显子7拷贝数和计算得到的Z-score之间的关系:copynumber=f(Z)根据该关系,估算待测样本的SMN1基因和SMN2基因外显子7的拷贝数。作为本发明优选的技术方案,所述SMN1基因拷贝数判断形式如下:所述SMN2基因拷贝数判断形式如下:如上为基于已有数据训练得到的阈值,作为缺省值;随着数据的累积,进行相应的调整,提供检测准确度。在本发明的另一方面,提供一种使用上述试剂盒检测脊髓性肌萎缩症相关基因拷贝数的方法,该方法不包括疾病的诊断方法,该方法包括如下步骤:1)从样本中提取DNA和打断;2)目标区域捕获:采用所述捕获探针对目标区域进行捕获,磁珠分离富集,PCR进行扩增,构建测序文库;3)测序;4)通过数据分析估算脊髓性肌萎缩症相关基因的拷贝数。作为本发明优选的技术方案,步骤1)中,所述样本是血液或唾液;所述打断采用超声波对提取的DNA进行打断,打断后末端补平并磷酸化,两侧加上接头。作为本发明优选的技术方案,步骤3)中,所述测序具体为:测序文库的DNA片段被杂交到测序仪的流动槽(flowcell)上并以之为模板生长DNA簇,然后用IlluminaHiSeq平台进行双端测序。与现有技术相比,本发明的有益效果在于:1)本发明充分利用基因捕获(capture-based)的技术克服扩增子测序(AmpliconSequencing)所带来的测序不均一问题。2)本发明采用了Illumina二代测序平台,使得获得的目标基因序列信息错误率更低、稳定性更好、通量更大。3)本发明通过捕获测序结合数据分析检测SMN1和SMN2外显子7拷贝数变异(缺失、正常、增加),不受检测区域碱基突变的影响,结果健壮性更好。4)针对SMN1和SMN2外显子7及其上下游三个差异碱基设计捕获探针,可更可信地将测序读段分配到相应的基因,使得结果特异性更强。5)基于Z-score的检测SMN1和SMN2外显子7拷贝数的方法,可有效利用历史累积数据,提高检测敏感性。6)本发明公开的基于二代捕获测序的拷贝数检测方法,可以便捷地和其它基于捕获测序的点突变或插入缺失检测方法进行整合,减少取样量。附图说明图1是本发明实施例1中SMN1基因和SMN2基因外显子7及其上下游示意图;图2是本发明实施例2中SMN1和SMN2的外显子7及其上下游每个碱基的覆盖情况示意图。三个差异碱基都有较好的测序覆盖深度。图3是本发明实施例2中参考样本的SMN1/2外显子7的Z-score值联合分布示意图。细直线、细虚线、粗直线、粗细线分别表示用于判断纯合性缺、杂合性缺失、拷贝数正常、拷贝数增加(≥3)的Z-score值取值范围。三角形(▲)表示一个实施方案中SMN1外显子7发生杂合性缺失,而SMN2外显子7拷贝数正常。图4是本发明实施例2中参考样本的SMN1基因外显子的Z-score值分布示意图。细直线、细虚线、粗直线、粗细线分别表示用于判断纯合性缺、杂合性缺失、拷贝数正常、拷贝数增加(≥3)的Z-score值取值范围。图5是本发明实施例2中参考样本的SMN2基因外显子的Z-score值分布示意图。细直线、细虚线、粗直线、粗细线分别表示用于判断纯合性缺、杂合性缺失、拷贝数正常、拷贝数增加(≥3)的Z-score值取值范围。具体实施方式下面结合具体实施例进一步阐明本发明,但这些实施例只是用于说明本发明,而不是来限制本发明的范围。实施例1样本测序(从样品中获得多核苷酸片段的序列信息)通过如下几个步骤对样本进行测序:1)DNA提取和打断。所用样本可以是血液也可以是唾液。DNA提取、纯化,采用超声波对提取的DNA进行打断,末端补平并磷酸化,两侧加上接头。2)目标区域捕获。本方法使用专门设计的捕获探针对目标区域进行捕获,磁珠分离富集,PCR进行扩增,构建测序文库。此处,目标区域包括SMN1/2和其它一些基因的外显子及其上下游一定范围内的碱基。其中,SMN1/2外显子7的目标捕获区域和相应探针序列如表1所述,图1显示了SMN1基因和SMN2基因外显子7及其上下游的三个差异碱基,同时,还显示了捕获区域的相关测序深度。表1.SMN1和SMN2外显子7的目标捕获区域和相应探针序列信息在本实施例中,对照探针如表2所示。其它实施过程中,对照探针不局限于此。表2.本实施例采用的对照探针3)测序。测序文库的DNA片段被杂交到测序仪的流动槽(flowcell)上并以之为模板生长DNA簇,然后在IlluminaHiSeq平台(Illumina高通量测序平台)上进行150bp双端测序。实施例2通过数据分析估算脊髓性肌萎缩症相关基因的拷贝数。本发明的数据分析涉及以下几个步骤:步骤A,将测序读段(reads)使用比对软件(BWA软件,版本:0.7.12)比对到人参考基因组(hg19)。步骤B,去除重复序列。使用Picard(一种基本序列处理工具,版本2.8)去除PCR扩增过程产生的重复序列(PCRduplicatereads)。步骤C,去除比对结果不可信的读段。此处,比对结果不可信是指:由于SMN1和SMN2高度同源,虽然比对软件将一个读段分配到其中一个基因的外显子7,但实际上该读段既可以被分配到SMN1,也可以分配到SMN2。对于被分配到SMN1/2外显子7的读段,本发明剔除那些不涵盖任何一个如表3所述位点的读段。图1展示了这些位点的相对位置。表3.用于区分分配到SMN1和SMN2外显子7的读段的位点。染色体坐标基因外显子碱基chr569372304SMN2外显子7上游44bpAchr569372353SMN2外显子7Tchr569372501SMN2外显子7下游100bpGchr570247724SMN1外显子7上游44bpGchr570247773SMN1外显子7Cchr570247921SMN1外显子7下游100bpA步骤D,计算覆盖深度(readdepth)。将目标捕获区域划分为固定长度的区间,并利用BEDtools(一种基本序列处理工具,版本:2.26)计算每个区间的平均覆盖深度。此处,覆盖深度是指分配至所述区间的读段数目与该区间大小的比值。SMN1/2外显子7及其上下游每个碱基的覆盖深度如图2所示。步骤E,标准化覆盖深度。此处,标准化是相对于同一个样本所有区间(SMN1和SMN2外显子7和其它相关对照探针所捕获的区间)进行计算的。公式如下:步骤F,GC(鸟嘌呤胞嘧啶)含量矫正。本发明进一步去除由于GC含量差异而造成的测序结果偏差。公式如下:步骤G,计算Z-score(标准分数)。对于一批样本中的每个样本,按如下公式计算Z-score。其中,Zi,j表示第j个样本的外显子i的Z-score值,normRD′i,j为第j个样本外显子i经步骤F计算得到的覆盖深度,和SD(normRD′i)分别为该批样本外显子i校正后覆盖深度的平均值和标准差。步骤H,估计SMN1/2外显子7的拷贝数。此处,基于表型已知样本,习得SMN1/2外显子7拷贝数和步骤G计算得到的Z-score之间的关系:copynumber=f(Z)基于已建立好的SMN1/2外显子7拷贝数和Z-score之间的上述关系,估算待分析样本SMN1/2外显子7的拷贝数。在本实施例中,预测值如图3三角形所示,待测样本SMN1和SMN2外显子7的Z-score值分别为-2.61和-0.93,可判断为SMN1外显子7发生杂合性缺失,SMN2外显子7拷贝数正常。步骤H中所述关系,参考图3、图4和图5,SMN1拷贝数判断形式如下:SMN2拷贝数判断形式如下:如上为基于已有数据训练得到的阈值,可作为缺省值。随着数据的累积,可以进行相应的调整,提供检测准确度。更新参考样本数据库:使用现有实验手段(MLPA、qPCR等)进一步确认待测样本的SMN1/2拷贝数后,将其添加到参考样本数据库中,并更新上述判断阈值,供下次使用。序列表<110>明码(上海)生物科技有限公司<120>一种基于基因捕获和二代测序技术的脊髓性肌萎缩症相关基因拷贝数检测试剂盒及方法<130>HJ17-12937<160>37<170>PatentInversion3.5<210>1<211>120<212>DNA<213>人工序列<400>1cuccuuaauuuaaggaaugugagcaccuuccuucuuuuugauuuugucuaaaacccugua60aggaaaauaaaggaaguuaaaaaaaauagcuauauagauauagauagcuauauauagaua120<210>2<211>120<212>DNA<213>人工序列<400>2uuccacaaaccauaaaguuuuacaaaaguaagauucacuuucauaaugcuggcagacuua60cuccuuaauuuaaggaaugugagcaccuuccuucuuuuugauuuugucuaaaacccugua120<210>3<211>120<212>DNA<213>人工序列<400>3cuccuuaauuuaaggaaugugagcaccuuccuucuuuuugauuuugucugaaacccugua60aggaaaauaaaggaaguuaaaaaaaauagcuauauagacauagauagcuauauauagaua120<210>4<211>120<212>DNA<213>人工序列<400>4uuccacaaaccauaaaguuuuacaaaaguaagauucacuuucauaaugcuggcagacuua60cuccuuaauuuaaggaaugugagcaccuuccuucuuuuugauuuugucugaaacccugua120<210>5<211>120<212>DNA<213>人工序列<400>5ccccuggagauggaaguaccccaggcaccuauacagcccuucuauagcucuccagaacug60uggaucagcucucucccaaguaagugagacuuuaucuuucuugcucggucuucugcuucu120<210>6<211>120<212>DNA<213>人工序列<400>6agugugggcaauugcagugugggcaacugcagcccggaggcaguguggcccaaaacugaa60ccccuggagauggaaguaccccaggcaccuauacagcccuucuauagcucuccagaacug120<210>7<211>120<212>DNA<213>人工序列<400>7ugugguaccccugucugcucaccauaugcuuuuguuuuagguucucccauggcgccagcc60agugugggcaauugcagugugggcaacugcagcccggaggcaguguggcccaaaacugaa120<210>8<211>120<212>DNA<213>人工序列<400>8cuuccagucaaguggauggcuccagaagcccuguuugauagaguauacacucaucagagu60gaugugugaguaacucucuuuucucuggcuuuuuccugggcuugagcugcaaaaauacug120<210>9<211>120<212>DNA<213>人工序列<400>9aagauaaauucuuuuaaauauauuuaguuuuugcauuuuccucuacauuugcaggggcgg60cuuccagucaaguggauggcuccagaagcccuguuugauagaguauacacucaucagagu120<210>10<211>120<212>DNA<213>人工序列<400>10gaaccauucaagagcuggacagauuugccaaucagauucucagcuauggagcggaacugg60augcugaccacccugugaguccauggcccguaggaugagauuuuuucagugccucuccuc120<210>11<211>120<212>DNA<213>人工序列<400>11guucugccaaucuguacucaggacguugccuucucuguguuucagugcccugguucccaa60gaaccauucaagagcuggacagauuugccaaucagauucucagcuauggagcggaacugg120<210>12<211>120<212>DNA<213>人工序列<400>12ggagcugccacugccaucggggacccuccaaaugucauuauuguuuccaaccaagagcug60aggaagaugguacguaccagcaugcuaggguugcuuccaguaaacgcacaccuccacuua120<210>13<211>120<212>DNA<213>人工序列<400>13gugcucaaccuugauccaagacaaguccugauugcagaagugaucuucacaaacauugga60ggagcugccacugccaucggggacccuccaaaugucauuauuguuuccaaccaagagcug120<210>14<211>120<212>DNA<213>人工序列<400>14uucacgauguguauagugggacuacuuucauuuuccuccauuugugacagguugugugag60gugcucaaccuugauccaagacaaguccugauugcagaagugaucuucacaaacauugga120<210>15<211>120<212>DNA<213>人工序列<400>15cuuuucaauuaagcccaauuucacuguaaauuaccucuuuaaaaugaugacuuauuuauu60uuuuagauauuaaugacugccuuggccagugucagaaugacgccuccugucggguaugua120<210>16<211>120<212>DNA<213>人工序列<400>16aguauugggcauuugggguguacauggaagcuacauccccaccucugaagaaggcguuuu60cauagaguugagucagacauccugugacagaaccauaaaaauuaauuugcgauaauucau120<210>17<211>120<212>DNA<213>人工序列<400>17aacuugcuggaagaaaacugaauagcaaacaccuuggguggaaugugcaccucaucuggc60aguauugggcauuugggguguacauggaagcuacauccccaccucugaagaaggcguuuu120<210>18<211>120<212>DNA<213>人工序列<400>18aaaaacagcuucuccaauaaugaaauaccaacuuuuaccuuuucuccaugucauugauug60aacuugcuggaagaaaacugaauagcaaacaccuuggguggaaugugcaccucaucuggc120<210>19<211>120<212>DNA<213>人工序列<400>19uucuggacacacucuucaugguaaaacuuuccacacaaggguagaaggcaccuuuuaaca60ucuuccccacucugcuuacauacaaaacagguauggauuccugagaagccaaaagaagau120<210>20<211>120<212>DNA<213>人工序列<400>20guuauacagauguggagggagcaccggaagcccuuguucugcauaacaguggguggguac60uucuggacacacucuucaugguaaaacuuuccacacaaggguagaaggcaccuuuuaaca120<210>21<211>120<212>DNA<213>人工序列<400>21ccacauaagaaauccauaccuuuagaugcagaaacauuggcuggauuagcagcaugacag60guuauacagauguggagggagcaccggaagcccuuguucugcauaacaguggguggguac120<210>22<211>120<212>DNA<213>人工序列<400>22cuuauuaaugaauauccauguucaugugaugcagaugggacuagcacacaauguaagauc60aaaauuaauguaagucuuauaauuuuauucaaguuauaugacaaaaauuuaauuuaaaag120<210>23<211>120<212>DNA<213>人工序列<400>23ugcuuuaacaucuacuuauuugaaaauguaauucuaauucuguguuucaggugcacagaa60cuuauuaaugaauauccauguucaugugaugcagaugggacuagcacacaauguaagauc120<210>24<211>120<212>DNA<213>人工序列<400>24aguugaaagccaugucucuguuggguagucggaaccaacuggcuagagcuguucugaauc60caaacccuauggacuucuguacaaaagauuuacugacuacaacaucugagagaauuguga120<210>25<211>120<212>DNA<213>人工序列<400>25ccaauuuaaacgaacuugugaauuguauuguaaucaguucucugguaacuacacaaagga60aguugaaagccaugucucuguuggguagucggaaccaacuggcuagagcuguucugaauc120<210>26<211>120<212>DNA<213>人工序列<400>26uagugcguaaugggaaaacugaguguuaccuuuccauccagacucaagagaacuuuccgg60ccaauuuaaacgaacuugugaauuguauuguaaucaguucucugguaacuacacaaagga120<210>27<211>120<212>DNA<213>人工序列<400>27aucuugaaggggaccgcaauggaggagcaaagaagaagaacuuuuuuaaacugaacaaua60aaagguaacuagcuuguuucauuuucauaguuuacauaguugcgagauuugaguaauuua120<210>28<211>120<212>DNA<213>人工序列<400>28gcgcgccugaggcucaugcauuuggcuaaugagcugcgguuucucuucaggucggaaugg60aucuugaaggggaccgcaauggaggagcaaagaagaagaacuuuuuuaaacugaacaaua120<210>29<211>120<212>DNA<213>人工序列<400>29uacagcaucuaaggcaagcugaaugcucuccaucaaucaugauauuagagacuguauuuu60auauaugacgacuuaagcuaaacuccuaaguaccugaaaugaauuaaauuaauaauuuuu120<210>30<211>120<212>DNA<213>人工序列<400>30uagcguggaucacacucaccaaaaaacaaaaacgccuuaauguucagcuuuuccugaauu60uacagcaucuaaggcaagcugaaugcucuccaucaaucaugauauuagagacuguauuuu120<210>31<211>120<212>DNA<213>人工序列<400>31cuggagacuuggugaguuguucaaguccuuugguuuccacgaaggaagacauuucaaaac60uuuuauuucuuucugaguuaagcaacaacaaaacaaaaaaggggaaggugagaaauacaa120<210>32<211>120<212>DNA<213>人工序列<400>32gacuucagcuguguucauucugcagucauucgucaaaucaaggauacucuacaaauucca60cuggagacuuggugaguuguucaaguccuuugguuuccacgaaggaagacauuucaaaac120<210>33<211>120<212>DNA<213>人工序列<400>33uagaaaugaugacauaacagauggaaaucccaaauugacuuugggauuaaucuggacaau60aauuuugcacuuucagguaagcccaaauuuucuuaauuucagcaucuaauugcuaguuuu120<210>34<211>120<212>DNA<213>人工序列<400>34uugauaaacaguugguuuuaucucuucuucacauucaaaacaggugaaauuagugaauau60uagaaaugaugacauaacagauggaaaucccaaauugacuuugggauuaaucuggacaau120<210>35<211>120<212>DNA<213>人工序列<400>35acuguaagaagaaauacggcguggcuugggaaaaguacugucagcgugugcccuaccgua60uauuuccauacaucuacuaaugcucuucuggcuuuucuacaaaauacuccugcaauucca120<210>36<211>120<212>DNA<213>人工序列<400>36auuucuacauaauuuauuucaccauguugcuuguccaccgagaagcucgugacgaguacc60acuguaagaagaaauacggcguggcuugggaaaaguacugucagcgugugcccuaccgua120<210>37<211>120<212>DNA<213>人工序列<400>37auaaaaauaucuaauacuguguacuauuauuauccacagguuuuaaccacauucugccuu60auuucuacauaauuuauuucaccauguugcuuguccaccgagaagcucgugacgaguacc120当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1