引入了异种基因的重组微生物和使用所述微生物从甲酸和二氧化碳产生有用材料的方法与流程
本发明涉及引入了异源基因的重组微生物和使用所述微生物从甲酸和二氧化碳产生有用物质的方法。更具体地,本发明涉及如下重组微生物,通过将异源基因引入具有循环代谢途径的微生物中,并且同时同化两分子甲酸和一分子二氧化碳,其能够有效地合成一分子丙酮酸;以及使用所述微生物从甲酸和二氧化碳产生有用物质的方法。
背景技术:
为了开发碳固定技术以缓解气候变化,将由一个碳组成的化合物(如二氧化碳)转化为碳数更高的有机物质的研究正在积极开展。由一个碳组成的化合物(c1化合物)的转化研究大致可以分为化学方法和生物方法。其中,化学方法使用基于金属催化剂和非金属催化剂的电化学反应来进行。通过此类反应,二氧化碳转化为非气态的碳化合物(如甲醇和甲酸),并且相关研究的例子包括使用碳纳米管催化剂进行转化(kumar等人,nat.comm.2819,2013)、使用铁催化剂进行转化(christopher等人,angew.chem.int.ed.49:50,9777-9780,2010)以及使用合金催化剂进行转化(studt等人,nat.chem.,6,320-324,2014)等。使用这些化学方法进行转化有速度相对较快的优点,但局限性在于通过c1化合物转化工艺获得的产物是单个碳的物质(如甲酸和甲醇),而不是含有多个碳原子的有用化合物。
关于生物转化方法,正在开展研究,目的是将气态的c1化合物转化为非气态的化合物以及将c1化合物转化为由几个碳原子组成的有用化合物。在前一种情况下,已经对自然界中存在的代谢途径的使用及其改进(pct/us2008/083056)、新代谢途径的设计(schwander等人,science,354:6314,900-904,2016)等进行了研究。后一种情况的例子包括使用甲醇同化微生物产生有用化合物(us2003/0124687a1)、从甲酸产生具有三个碳原子的化合物(us2013/0196359a1)等。然而,这些研究的局限性在于,由于其效率低下,难以在生物体的内部条件下鉴定其效果,而且它们是否能以与活生物体内的天然代谢途径相兼容的方式发挥作用还没有得到证实。
因此,为了克服上述生物c1化合物转化工艺的局限性,从而开发高效的c1化合物转化工艺的研究正在工业上兴起。具体地,在c1化合物中,甲酸的益处在于它对生物体的毒性比其他c1化合物要相对较小,并且就反应动力学而言,与c1化合物相比有利于同化(合成代谢)反应,并且可以通过化学方法从二氧化碳容易快速地合成。然而,甲基杆菌属(methylobacterium)(一种有代表性的甲酸同化细菌)的遗传信息仅在2009年报道过,也就是说,应用甲酸的基础研究只是最近才进行的,并且甲酸转化的研究还处于初期阶段。目前,有关甲酸同化(合成代谢)的研究仍处于使用酶信息数据库展示和设计代谢途径的水平(us2015/0218528a1;arrenbar-even.,biochemistry,55:28,3851-3863),并且还没有报道过证明甲酸同化(合成代谢)的案例。
因此,本发明人已经设计了一种新颖的代谢途径,用于将c1化合物(甲酸)转化为具有多个碳原子的有用化合物,并且尝试在生物体的体内条件下证明所述代谢途径。结果,本发明人已经开发了一种循环代谢途径,其涉及同时有效地同化甲酸和二氧化碳,从而当引入源自甲基杆菌属、红杆菌属(rhodobacter)、绿屈挠菌属(chloroflexus)、醋酸杆菌属(acetobacterium)、玫瑰杆菌属(roseobacter)和曼氏杆菌属(mannheimia)的新颖基因时产生单个分子的乙酰coa作为循环代谢途径的产物,并且已经鉴定到,当进一步引入丙酮酸甲酸裂解酶的逆反应时,作为循环代谢途径的产物获得的乙酰coa结合到单个分子的甲酸上以产生作为c3化合物的丙酮酸。此外,本发明人还已经开发了一种代谢途径,其通过使用源自甲基杆菌属微生物的新颖基因和源自埃希氏杆菌属(escherichia)微生物的基因有效地同化甲酸和二氧化碳,能够产生甘氨酸、丝氨酸和丙酮酸,并且已经鉴定到,甘氨酸、丝氨酸和丙酮酸是使用相应的代谢途径从甲酸和二氧化碳产生的。基于这些发现,已经完成了本发明。
技术实现要素:
【技术问题】
因此,本发明的一个目的是提供用于从甲酸和二氧化碳产生有用物质(包括c3化合物)的重组微生物。
本发明的另一个目的是提供使用重组微生物从甲酸和二氧化碳产生有用物质(包括c3化合物)的方法。
【技术方案】
根据本发明的一个方面,提供了通过将编码参与甲酸同化途径的酶的基因或含有所述基因的重组载体引入具有中心碳同化途径的宿主微生物中而获得的重组微生物。
根据本发明的另一个方面,提供了用于产生具有作为中间产物的c3化合物的有用化合物的方法,其包括:(a)以甲酸和二氧化碳为碳源培养重组微生物,以产生具有作为中间产物的c3化合物的有用物质;以及(b)回收所得的有用物质。
【附图说明】
现在将详细参考本发明的优选实施方案,其实施例在附图中阐明。在可能的情况下,在整个附图中将使用相同的附图标记指代相同或相似的部分。
图1显示了参与大肠杆菌(e.coli)的中心碳同化途径的基因、辅酶和能量转移物质;
图2a显示了在本发明中开发的甲酸同化途径,并且图2b显示了野生型对照组(dh5αwt)和重组微生物实验组(dh5αthf)之间的甲酸同化效率的比较结果,其中,在图2b中,“m+0”表示相应的氨基酸的原始质量数,并且“m+1以上”表示相应的氨基酸含有同位素时的质量数,并且由于在自然系统中有预定的同位素比率,在野生型对照组中也存在预定的m+1以上氨基酸比率;
图3显示了野生型对照组(dh5αwt)和重组微生物(dh5αthf)的甲酸同化量的定量分析(a)及其同化效率(b)的结果;
图4显示了在本发明中开发的甲酸同化途径和中心碳同化途径相连的代谢途径(a)以及野生型对照(dh5αwt)和实验重组微生物(dh5αst1和dh5αst2)之间的甲酸同化与中心碳代谢的程度的比较结果(b);
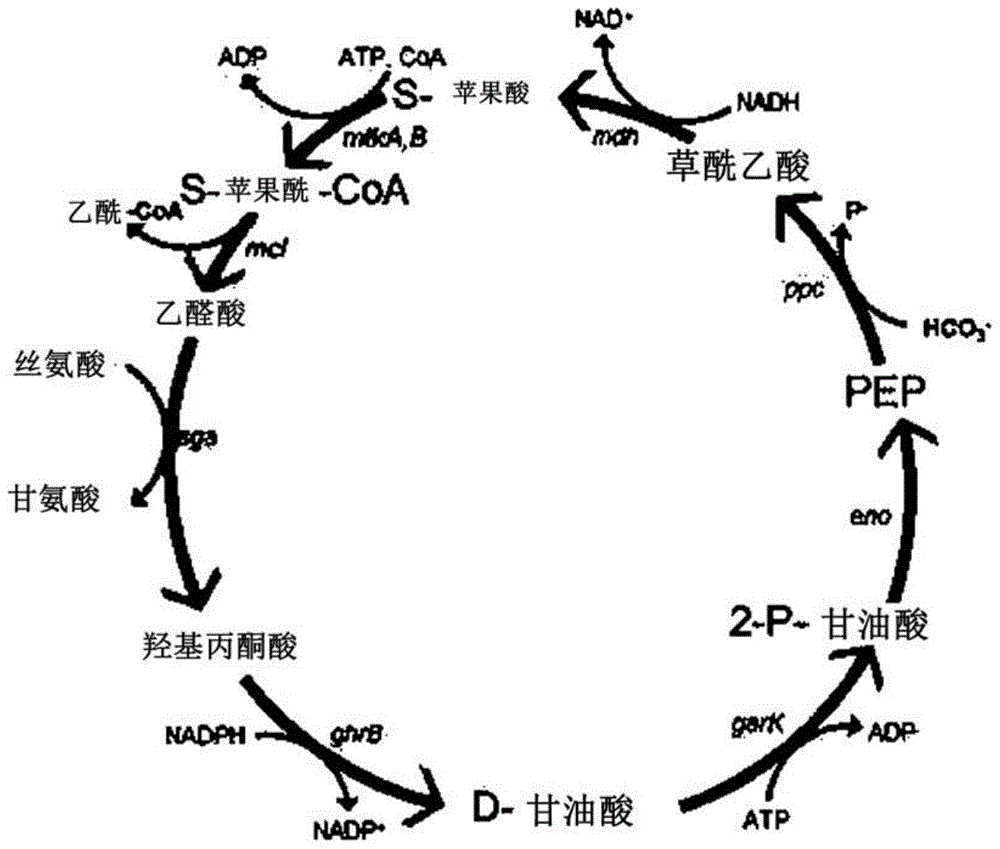
图5显示了在本发明中开发的新颖循环代谢途径以及参与所述途径各个步骤的基因、辅酶和能量转移物质;
图6显示了在本发明中开发的使用甲酸和二氧化碳产生c3化合物的五个实施方案(a~e)的循环代谢途径;
图7显示了为将新颖循环代谢途径引入根据本发明实施方案的微生物中而产生的合成操纵子和包含所述操纵子的质粒基因图谱;
图8显示了根据本发明实施方案的使用甲酸和二氧化碳合成甘氨酸、丝氨酸和丙酮酸的新颖代谢途径;
图9显示了为在作为模型微生物的大肠杆菌中构建根据本发明实施方案的使用甲酸和二氧化碳合成甘氨酸、丝氨酸和丙酮酸的新颖代谢途径而产生的合成操纵子;
图10显示了在引入了根据本发明实施方案的新颖代谢途径的重组大肠杆菌中从甲酸和二氧化碳合成的甘氨酸(c1,橙色)的比例和从葡萄糖合成的甘氨酸(glu,淡蓝色)的比例;
图11显示了在引入了根据本发明实施方案的新颖代谢途径的重组大肠杆菌中从甲酸和二氧化碳合成的丝氨酸(c1,橙色)的比例和从葡萄糖合成的丝氨酸(glu,淡蓝色)的比例;
图12显示了在引入了根据本发明实施方案的新颖代谢途径的重组大肠杆菌中从甲酸和二氧化碳合成的丙酮酸的比例;并且
图13显示了根据本发明实施方案产生的五种类型的质粒图谱。
【具体实施方式】
除非另有定义,否则本文使用的所有技术术语和科学术语具有与本发明所属领域的技术人员所理解的相同的含义。通常,本文使用的命名法是本领域熟知的,并且是通常使用的。
本发明人首先通过实验鉴定了能够从甲酸和二氧化碳合成由三个或更多个碳原子组成的化合物的新颖循环代谢途径。也就是说,本发明人设计了图6所示的循环代谢途径,并构建了含有用于在微生物中表达的合成操纵子的质粒,以便所述代谢途径可以在主题(宿主)微生物中实施。由于将其转化到主题(宿主)微生物中,本发明人已经鉴定到,甲酸和二氧化碳可以在微生物内有效地同化并转化为c3化合物。
具体地,本发明人构建了用于同化甲酸的新颖循环代谢途径,并且已经鉴定到,当将代谢途径引入宿主微生物中时,甲酸通过代谢途径被同化。此外,本发明人已经发现,当使用参与从外来微生物引入的代谢途径的一些酶时,甲酸的同化效率显著提高(图2)。
因此,在一个方面,本发明涉及通过将编码参与甲酸同化途径的酶的基因或含有所述基因的重组载体引入具有中心碳同化途径的宿主微生物中而获得的重组微生物。
在本发明中,中心碳同化途径是在微生物中固定二氧化碳的循环途径。参与大肠杆菌的中心碳同化途径的基因、辅酶和能量转移物质如图1所示。
在本发明中,甲酸同化途径可以与中心碳同化途径组合,以合成c3或更多碳的化合物。宿主微生物固有地具有中心碳同化途径i);或者具有从外部引入的中心碳同化途径ii)。
在本发明中参与甲酸同化途径的酶可以是选自以下的任何一种的基因:甲酸四氢叶酸连接酶、次甲基四氢叶酸环水解酶和亚甲基四氢叶酸脱氢酶,但不限于此。
在本发明中,基因可以源自选自以下的任何一种:甲基杆菌属、玫瑰杆菌属、红杆菌属、绿屈挠菌属、醋酸杆菌属、曼氏杆菌属、埃希氏杆菌属和拟南芥属(arabidopsis),但不限于此。
在本发明中,编码甲酸四氢叶酸连接酶的基因可以是由seqidno:7表示的核酸分子,编码次甲基四氢叶酸环水解酶的基因可以是由seqidno:8或seqidno:19表示的核酸分子,并且编码亚甲基四氢叶酸脱氢酶的基因可以是由seqidno:9表示的核酸分子,但不限于此。
同时,本发明人已经证实被甲酸同化途径同化的甲酸是否被同化到糖酵解中(糖酵解是宿主微生物的中心碳代谢过程之一)。本发明人还已经发现,当用异源基因取代参与主要碳代谢的部分基因时,同化效率得到提高(图4和5)。
因此,在另一个方面,本发明涉及对宿主微生物的中心碳同化途径有改进的重组微生物。
在本发明中,参与中心碳同化途径并选自以下的至少一种酶可以被取代、进一步引入或扩增:丝氨酸乙醛酸转氨酶、苹果酰coa裂解酶、苹果酸coa连接酶、琥珀酰coa:(s)-苹果酸coa转移酶、磷酸烯醇丙酮酸羧激酶和羟基丙酮酸还原酶,但不限于此。
被取代或进一步引入的酶可以是源自选自以下的任何一种的酶:甲基杆菌属、玫瑰杆菌属、红杆菌属、绿屈挠菌属、醋酸杆菌属、曼氏杆菌属、埃希氏杆菌属和拟南芥属,但不限于此。
在本发明中,参与中心碳同化途径的酶可以被以下中的一种取代:
i)由选自以下的核酸分子编码的丝氨酸乙醛酸转氨酶:由seqidno:6表示的核酸分子、由seqidno:13表示的核酸分子、由seqidno:16表示的核酸分子和由seqidno:21表示的核酸分子;
ii)由选自以下的核酸分子编码的苹果酰coa裂解酶:由seqidno:5表示的核酸分子、由seqidno:14表示的核酸分子和由seqidno:15表示的核酸分子;
iii)由选自以下的核酸分子编码的苹果酸coa连接酶:由seqidno:3表示的核酸分子、由seqidno:4表示的核酸分子、由seqidno:11表示的核酸分子和由seqidno:12表示的核酸分子;
iv)由以下编码的琥珀酰coa:(s)-苹果酸coa转移酶:由seqidno:17表示的核酸分子或由seqidno:18表示的核酸分子;
v)由以下编码的磷酸烯醇丙酮酸羧激酶:由seqidno:20表示的核酸分子;和/或
vi)由以下编码的羟基丙酮酸还原酶:seqidno:10的核酸分子,但不限于此。
在本发明的一个实施方案中,关于酶,参与图1所示的埃希氏杆菌属的中心碳同化途径的酶可以被图6(a)至6(e)所示的酶取代。
在本发明中,可以将基因以含有合成操纵子的质粒的形式转化到宿主微生物中(参见图7),并且合成操纵子可以包含选自以下的至少一种:甲基杆菌属微生物的甲酸四氢叶酸连接酶、次甲基四氢叶酸环水解酶、亚甲基四氢叶酸脱氢酶、丝氨酸乙醛酸转氨酶、苹果酰coa裂解酶、苹果酸coa连接酶和羟基丙酮酸还原酶;红杆菌属微生物的苹果酰coa硫酯酶和苹果酰coa裂解酶;绿屈挠菌属微生物的琥珀酰coa:(s)-苹果酸coa转移酶;醋酸杆菌属微生物的次甲基四氢叶酸环水解酶;玫瑰杆菌属微生物的苹果酸coa连接酶;和曼氏杆菌属微生物的磷酸烯醇丙酮酸羧激酶,但不限于此。
同时,当甲酸同化途径与宿主微生物的中心碳同化途径组合时,二氧化碳和甲酸转化为乙酰coa。本发明人已经发现,通过进一步引入基于丙酮酸甲酸裂解酶的代谢途径,甲酸可以进一步被同化以产生c3化合物(图6)。
因此,在另一个方面,本发明涉及具有c3化合物合成代谢途径的重组微生物,其中甲酸同化途径与中心碳同化途径组合,并且向其中进一步引入丙酮酸甲酸裂解酶。
在本发明中,重组微生物可以进一步引入编码丙酮酸甲酸裂解酶的基因或含有所述基因的重组载体。
在本发明中,编码丙酮酸甲酸裂解酶的基因可以是由seqidno:22表示的核酸分子,但不限于此。
在本发明中开发的另一种类型的中心碳同化途径是在微生物中固定甲酸和二氧化碳的途径,并且图8显示了参与甲酸和二氧化碳同化途径的基因、辅酶和能量转移物质。
在本发明中,甲酸和二氧化碳同化途径从二氧化碳和甲酸合成一分子甘氨酸,并且从甘氨酸和一分子甲酸合成一分子丝氨酸。所合成的丝氨酸经丝氨酸脱氨酶转化为丙酮酸,并且从丙酮酸合成c3或更长的化合物。宿主微生物通过外部引入甲酸和二氧化碳同化途径而具有碳同化能力。
也就是说,本发明证实了通过甲酸和二氧化碳同化途径可以从甲酸和二氧化碳合成丝氨酸和甘氨酸,并且确认了通过改变基因表达强度和缺失宿主微生物中的特定基因来提高同化效率(图10和11)。
此外,本发明证实了通过甲酸和二氧化碳同化途径可以从甲酸和二氧化碳合成丙酮酸,并且确认了通过改变基因表达强度和缺失宿主微生物中的特定基因来提高同化效率(图12)。
在本发明中,可以将基因以含有合成操纵子的质粒的形式转化到宿主微生物中(参见图9),并且可以产生合成操纵子以便包含选自以下的至少一种:甲基杆菌属微生物的甲酸四氢叶酸连接酶、次甲基四氢叶酸环水解酶和亚甲基四氢叶酸脱氢酶;醋酸杆菌属微生物的次甲基四氢叶酸环水解酶;和埃希氏杆菌属微生物的甘氨酸裂解复合物和丝氨酸脱氨酶。
将含有合成操纵子的质粒转化到宿主微生物中的结果表明,引入了这种新颖代谢途径的重组微生物对从甲酸和二氧化碳合成甘氨酸、丝氨酸和丙酮酸的能力表现出相当大的改进。
因此,在另一个方面,本发明涉及具有合成c3化合物的代谢途径的重组微生物,其中通过引入新颖代谢途径而从甲酸和二氧化碳合成甘氨酸、丝氨酸和丙酮酸。
本发明涉及通过将编码参与甲酸同化途径的酶的基因或含有所述基因的重组载体引入具有中心碳同化途径的宿主微生物中而具有改进的甲酸和二氧化碳同化的重组微生物。酶是选自以下的至少一种的基因:甲酸四氢叶酸连接酶、次甲基四氢叶酸环水解酶和亚甲基四氢叶酸脱氢酶。
在本发明中,编码甲酸四氢叶酸连接酶的基因是由seqidno:7表示的核酸分子,编码次甲基四氢叶酸环水解酶的基因是由seqidno:8或seqidno:19表示的核酸分子,并且编码亚甲基四氢叶酸脱氢酶的基因是由seqidno:9表示的核酸分子,但本发明不限于此。
在本发明中,甘氨酸裂解复合物可以被增强、扩增或进一步引入重组微生物中,并且构成甘氨酸裂解复合物的基因的表达可以通过用选自trc启动子、tac启动子、t7启动子、lac启动子和trp启动子的任何一种强启动子取代固有启动子来增强,或者通过质粒过表达系统过表达。甘氨酸裂解复合物可以是由seqidno:63表示的核酸分子,但不限于此。
在本发明的一个实施方案中,甘氨酸裂解复合物被增强、扩增或进一步引入的重组微生物是通过质粒过表达系统过表达由seqidno:63表示的甘氨酸裂解复合物或者用强启动子取代位于甘氨酸裂解复合物的gcvt基因上游的固有启动子而产生的{seqidno:67(ncbi信息:nc_000913.3区域3049125-3050667被seqidno:68取代,并且改变的序列与启动子相对应}。
在本发明中,重组微生物的特征可以在于gcvr基因被缺失,并且gcvr基因可以是由seqidno:66表示的核酸分子,但本发明不限于此。
在本发明中,丝氨酸脱氨酶可以被增强、扩增或进一步引入重组微生物中,并且丝氨酸脱氨酶可以是由seqidno:69表示的核酸分子,但本发明不限于此。
在本发明中,宿主微生物可以固有地具有中心碳同化途径i);或者可以具有从外部引入的中心碳同化途径ii)。
在本发明中,基因可以源自选自以下的任何一种:甲基杆菌属、玫瑰杆菌属、红杆菌属、绿屈挠菌属、醋酸杆菌属、曼氏杆菌属、埃希氏杆菌属和拟南芥属,但本发明不限于此。
在本发明中,重组微生物能够对从甲酸和二氧化碳同化的丙酮酸、甘氨酸或丝氨酸进行生物合成,但本发明不限于此。
在本发明中,重组微生物可以选自埃希氏杆菌属、曼氏杆菌属、红杆菌属和甲基杆菌属,但本发明不限于此。
本发明的基因可以在编码区中以许多方式经历变异,只要从编码区表达的蛋白质的氨基酸序列没有改变即可,并且可以经历变异或修饰,只要基因的表达在编码区以外的区域中不受影响即可,并且此类改变或修饰的基因也落入本发明的范围内。
因此,本发明还包括具有与所述基因基本上相同的碱基序列的多核苷酸以及所述基因的片段。术语“基本上相同的多核苷酸”意指编码具有与在本发明中使用的酶的功能相同的功能的酶的基因,而不考虑序列的同源性。术语“基因片段”也意指编码具有与在本发明中使用的酶的功能相同的功能的酶的基因,而不考虑片段的长度。
此外,蛋白质(其是本发明基因的表达产物)的氨基酸序列可以从诸如各种微生物等生物资源获得,只要不影响相应的酶的效价和活性即可,并且这些生物资源也落入本发明的范围内。
因此,本发明还包括具有与所述蛋白质基本上相同的氨基酸序列的多肽以及所述多肽的片段。术语“基本上相同的多肽”意指具有与在本发明中使用的蛋白质的功能相同的功能的蛋白质,而不考虑氨基酸序列的同源性。术语“多肽片段”也意指具有与在本发明中使用的蛋白质的功能相同的功能的蛋白质,而不考虑片段的长度。
如本文所用,术语“载体”意指含有与调控序列可操作地连接的能够在合适的宿主中表达dna的dna序列的dna产物,并且可以是质粒、噬菌体颗粒或简单的潜在基因组插入物。一旦载体转化到适当的宿主中,它就可以独立于宿主的基因组进行复制并发挥作用,或者可以经常与基因组本身整合。由于质粒是最常用的载体类型,术语“质粒”和“载体”有时在本发明的整个说明书中可互换使用。为了本发明的目的,优选使用质粒载体。可以用于此目的的典型质粒载体包含(a)用于有效地进行复制以便使每个宿主细胞包含几个至几百个质粒载体的复制起点、(b)用于筛选质粒载体转化的宿主细胞的抗生素抗性基因和(c)插入外源dna片段的限制酶切割位点。即使不存在适当的限制酶切割位点,载体和外源dna也可以根据常规方法使用合成的寡核苷酸衔接子或接头容易地连接。连接后,载体应当转化到适当的宿主细胞中。使用氯化钙法或电穿孔可以容易地进行转化(neumann等人,emboj.,1:841,1982)。
根据本发明,本领域熟知的表达载体可以用作增强或过表达基因的载体。
当一个核苷酸序列与另一个核苷酸序列基于功能关系对齐时,它与其是“可操作地连接的”。这可以是以这样的方式连接的一个或多个基因和一个或多个调节序列,以便当合适的分子(例如,转录激活蛋白)与一个或多个调节序列连接时能够进行基因表达。例如,当作为参与多肽分泌的前蛋白表达时,前序列或分泌前导序列的dna与多肽的dna可操作地连接;并且当启动子或增强子影响序列的转录时,其与编码序列可操作地连接;或者当核糖体结合位点影响序列的转录时,其与编码序列可操作地连接;或者当定位以促进翻译时,核糖体结合位点与编码序列可操作地连接。通常,“可操作地连接”意指连接的dna序列与其接触,或者分泌前导序列与其接触并存在于阅读框中。然而,增强子不需要接触。这些序列的连接是通过在方便的限制酶位点连接(ligation/linkage)来进行的。当不存在此类位点时,根据常规方法使用合成寡核苷酸衔接子或接头。如本领域熟知的,为了提高转基因在宿主细胞中的表达水平,基因应当与在所选择的表达宿主中发挥作用的转录/翻译表达调控序列可操作地连接。优选地,表达调控序列和相应的基因包含在含有细菌选择标记物和复制起点的一种重组载体中。当宿主细胞是真核细胞时,重组载体应当在真核表达宿主中还包含有用的表达标记物。
用上述重组载体转化的宿主细胞构成本发明的另一个方面。如本文所用,术语“转化”意指将dna引入宿主中并允许dna通过染色体外因子或染色体整合可复制。
应当理解的是,并非所有载体在表达本发明的dna序列时都同样地发挥作用。同样,并非所有宿主针对同一表达系统都同样地发挥作用。然而,在没有过度的实验负担且不背离本发明的范围的情况下,本领域技术人员将能够在各种载体、表达调控序列和宿主之间进行适当的选择。例如,应当在考虑宿主的情况下选择载体,因为载体应当在宿主中复制。还应当考虑载体的复制次数、控制复制次数的能力以及由相应的载体编码的其他蛋白质的表达,如抗生素标记物的表达。
此外,在本发明中引入的基因可以引入宿主细胞的基因组中并作为染色体因子存在。对于本领域技术人员而言清楚的是,甚至将基因插入宿主细胞的基因组中也与将重组载体引入宿主细胞中具有相同的效果。
任何宿主微生物都可以用作本发明的宿主微生物而没有限制,并且宿主微生物优选地是埃希氏杆菌属、曼氏杆菌属、红杆菌属或甲基杆菌属微生物。
本发明人还已经通过将上述循环代谢途径与丙酮酸甲酸裂解酶的逆反应组合而开发了合成c3化合物的代谢途径,并且鉴定到,代谢途径使甲酸和二氧化碳能够有效地固定到c3化合物中。
因此,在另一个方面,本发明涉及能够产生c3化合物的重组微生物,其中将编码丙酮酸甲酸裂解酶的基因或含有所述基因的重组载体进一步引入重组微生物中。
在本发明中,丙酮酸甲酸裂解酶具有将丙酮酸分解成甲酸和乙酰coa的正向反应活性以及其逆反应活性,并且具有优异的逆反应活性,其中逆转化反应的转化数为280/sec,并且以前的研究已经证明,丙酮酸可以通过所述酶的逆反应合成(zelcbuch等人,biochemistry,55:17,2423-2426,2016)。丙酮酸甲酸裂解酶固有地存在于作为宿主微生物的大肠杆菌中,但是当依赖于固有表达时,难以将表达量维持在预定水平以上,因为酶的表达受培养条件的调控。因此,为了合成稳定的c3化合物,在本发明中,基于质粒进一步引入酶,或者使用强启动子控制酶过表达。
在本发明中,编码丙酮酸甲酸裂解酶的基因可以是由seqidno:22表示的核酸分子。
在本发明中,基因可以被选自以下的任何一种强启动子过表达:trc启动子、tac启动子、t7启动子、lac启动子、bba23100合成启动子和trp启动子。
在另一个方面,本发明涉及使用重组微生物产生具有作为中间产物的c3化合物的有用物质的方法。
根据本发明的用于产生有用物质的方法包括:(a)以甲酸和二氧化碳为碳源培养重组微生物,以产生具有作为中间产物的c3化合物的有用物质;以及(b)回收所得的有用物质。在本发明中,c3化合物可以是丙酮酸。有用物质的例子包括醇、氨基酸、有机酸、烯烃和聚合单体。更具体地,c3化合物包括但不限于具有3个或更多个碳原子的直链或支链醇、异丁醇、丙醇、己醇、庚醇、辛醇、壬醇、癸醇、叔丁醇、1-戊醇、2-戊醇、3-戊醇、2-甲基-1-丁醇、3-甲基-1-丁醇、2-甲基-2-丁醇、腐胺、l-鸟氨酸、精氨酸、多环芳烃(pah)、聚乳酸、聚乳酸共乙醇酸、聚(2-羟基异戊酸共乳酸)、聚羟基丁酸酯(phb)、4-羟基丁酸酯、生物柴油、汽油、烯烃、5-氨基戊酸、γ-丁酸、3-羟基丙酸、3-氨基丙酸、丙烯酸、1,3-二氨基丙烷、己内酰胺、苏氨酸、缬氨酸、异亮氨酸、富马酸、苹果酸、琥珀酸、神经酰胺、虾青素、水飞蓟宾、番茄红素、叶黄素、视黄醇等。丙酮酸是在大多数微生物属(包括埃希氏杆菌属)中通过糖酵解在生物质(包括糖脂和木材)分解过程中形成的中间体。丙酮酸是通过微生物中的天然代谢途径处于碳重排反应中心的物质,因此,可以通过微生物的天然代谢途径或从外部引入的其他代谢途径,转化为据报道能够在微生物中产生的所有有用物质,这对于本领域技术人员而言是清楚的。因此,本发明包括可以使用由根据本发明的重组微生物产生的丙酮酸合成的所有物质。
在另一个方面,本发明涉及使用重组微生物产生c3化合物的方法。
根据本发明的方法包括:(a)以甲酸和二氧化碳为碳源培养重组微生物,以产生c3化合物;以及(b)回收所产生的c3化合物,其中c3化合物为丙酮酸、丝氨酸或甘氨酸,但不限于此。
在下文中,将参考以下实施例更加详细地描述本发明。然而,对于本领域技术人员而言清楚的是,以下实施例仅出于说明本发明的目的来提供,而不应当解释为限制本发明的范围。
实施例1:用于引入外源基因的重组质粒的产生以及重组大肠杆菌的产生
为了构建甲酸和二氧化碳同化途径和高效合成c3化合物,使用重组质粒将必需的基因引入作为靶微生物的大肠杆菌(escherichiacoli)中。用于构建同化途径的质粒是p10099a质粒,其包含氨苄西林抗性基因、pbr322复制起点和合成启动子bba_23100。使用质粒为模板以及seqidno:1和seqidno:2的引物进行pcr,然后回收并纯化扩增后的基因片段以制备用作产生重组质粒的质粒骨架的基因片段。
[seqidno:1]:
5'-actgataagcctttcggtaaggtacccggggatcctctag-3'
[seqidno:2]:
5'-tcgtgtaagtgtctcaacaagagctcgaattcgctagcac-3'
通过以下方式制备质粒产生所需的外源基因片段:使用作为模板的具有相应的基因的微生物的基因组dna和使用设计用于扩增基因的引物进行pcr,然后收集并纯化扩增后的基因片段,并且相应的基因和引物序列显示于下表1和2中。
[表1]
待扩增的外源基因的ncbi信息和源自的微生物
[表2]
用于扩增外源基因片段的引物序列
用于构建同化途径的另一种质粒是包含氯霉素抗性基因和复制起点p15a以及合成启动子bba_23100的质粒。使用质粒为模板以及seqidno:1和seqidno:2的引物进行pcr,然后回收并纯化扩增后的基因片段以制备用作产生重组质粒的质粒骨架的基因片段。
通过以下方式制备质粒产生所需的外源基因片段:使用作为模板的具有相应的基因的微生物的基因组dna和使用设计用于扩增基因的引物进行pcr,然后收集并纯化扩增后的基因片段,并且相应的基因和引物序列显示于下表3和4中。
[表3]
待扩增的外源基因的ncbi信息和源自的微生物
[表4]
用于扩增外源基因片段的引物序列
使用通常用于组装基因片段的gibson组装方法(gibson等人,nat.methods,6:5,343-345,2009)扩增质粒骨架基因片段和扩增后的基因片段,,而且构建的每个质粒含有一个或多个上述表1或表3中列出的外源基因。此外,在重组菌株中,gcvr基因(seqidno:66,ncbi信息:nc_000913.3,区域2599906-2600478)被缺失,而且构成甘氨酸裂解复合物的基因的启动子被改变{seqidno:67(ncbi信息:nc_000913.3区域3049125-3050667)被取代,如seqidno:68所示}。使用本领域常用的同源重组方法产生具有基因缺失和取代的重组菌株(datsenko等人,pnas,97:12,6640-6645,2000)。在本发明中制备的代表性质粒如表5和图13所示。
[表5]
将通过上述方法产生的重组质粒转化到大肠杆菌中以制备重组大肠杆菌。在本发明中使用的大肠杆菌是大肠杆菌dh5α(invitrogen,usa),并且使用本领域常用的化学转化方法转化到大肠杆菌中。在本发明中产生的代表性重组大肠杆菌显示于下表6中。
[表6]
实施例2:使用碳同位素分析鉴定甲酸和二氧化碳的同化
进行碳同位素分析以证实在实施例1中产生的重组大肠杆菌是否能有效地同化甲酸和二氧化碳。为了证实甲酸的同化,使用作为对照组的野生型大肠杆菌(dh5αwt)和在实施例1中产生的重组大肠杆菌中引入了通过由seqidno:7表示的核酸分子编码的甲酸四氢叶酸连接酶、通过由seqidno:8表示的核酸分子编码的次甲基四氢叶酸环水解酶和通过由seqidno:9表示的核酸分子编码的亚甲基四氢叶酸脱氢酶的重组大肠杆菌(dh5αthf)进行实验。
为了证实同化后的甲酸是否与中心碳同化途径相连,使用进一步引入了通过由seqidno:6、3、16或21表示的核酸分子编码的丝氨酸乙醛酸转氨酶的重组大肠杆菌进行实验。此外,为了证实同化后的甲酸是否与中心碳同化途径相连以及是否有效地以与二氧化碳一起合成乙酰coa,使用引入了由seqidno:5或15的核酸分子编码的苹果酰coa裂解酶和进一步引入了通过由seqidno:3、4、11或12表示的核酸分子编码的苹果酸coa连接酶的重组微生物进行实验。
对于碳同位素分析,将对照和实验大肠杆菌在含有用13c碳同位素标记的甲酸盐和碳酸氢盐离子的m9培养基中培养(参见下表7中所示的组成),然后分析培养溶液中所含的大肠杆菌细胞样品和乙酸样品。在强酸性且高温的条件下水解构成大肠杆菌的所有蛋白质后,使用气相色谱/质谱使用大肠杆菌细胞样品分析构成大肠杆菌的氨基酸的质量数(zamboni等人,nat.protocols,4:6,878-892,2009)。通过冻干培养溶液、将培养溶液中含有的乙酸分离成乙酸盐和使用气相色谱/质谱分析法进行分析,分析培养溶液中所含的乙酸样品。
[表7]
m9培养基的组成
实施例2-1:通过甲酸同化途径进行的甲酸同化的鉴定
在本发明中开发的循环甲酸和二氧化碳同化途径中甲酸的同化是通过在两种循环代谢途径中四氢叶酸和甲酸之间的键合进行的,如图1所示。在甲酸和四氢叶酸之间的键合之后,四氢叶酸通过三种代谢途径再生,并且甲酸衍生的碳被同化到丝氨酸中。此外,作为所述途径的中间体之一的亚甲基四氢叶酸也被用作甲硫氨酸合成代谢途径的中间体,因此沿着甲硫氨酸合成代谢途径甲硫氨酸也被甲酸衍生的碳标记。
如图2所示,甲酸同化的分析结果表明,在实施例1中产生的重组大肠杆菌(dh5αthf)菌株在大肠杆菌中所含的90%的总甲硫氨酸中含有同位素,而野生型对照组(dh5αwt)在31%的总甲硫氨酸含有同位素。在重组大肠杆菌(dh5αthf)中存在的丝氨酸的同位素包含比例的测量结果显示,观察到100%的总丝氨酸含有同位素。在野生型对照组(dh5αwt)中存在的丝氨酸的同位素包含比例的测量结果显示,观察到35%的总丝氨酸含有同位素。
同时,野生型对照(dh5αwt)和重组大肠杆菌(dh5αthf)的甲酸同化的定量分析以及同化效率的比较结果表明,重组大肠杆菌(dh5αthf)使用甲酸作为主要碳源,而野生型对照(dh5αwt)几乎不使用甲酸(图3)。结果,可以看出重组大肠杆菌(dh5αthf)表现出比野生型对照组(dh5αwt)高约10倍的甲酸同化效率(δfa/δglu)。
从以上结果可以看出,与野生型对照的同化效率相比,根据本发明的重组大肠杆菌表现出显著改进的同化效率。
实施例2-2:甲酸中心碳代谢(ccm)同化的鉴定
证实通过在本发明中开发的循环甲酸和二氧化碳同化代谢途径同化的甲酸是否被同化到大肠杆菌的中心碳代谢(ccm)中。通过实施例2-1的代谢途径同化的甲酸衍生的碳通过丝氨酸乙醛酸转氨酶迁移到3-羟基丙酮酸,并通过一系列反应与丙酮酸的位置3处的碳相对应。此时,丙酮酸中存在的碳同位素的比例可以通过分析丙氨酸和缬氨酸来确定(zelcbuch等人,biochemistry,第55卷:17,2423-2426,2016)。基于此原理,分析了丙酮酸中所含的碳同位素。结果,如图4所示,在具有循环甲酸和二氧化碳同化途径的重组大肠杆菌(dh5αst2)的情况下,检测到同位素的量分别占总丙氨酸和缬氨酸的29%和28.2%。在野生型大肠杆菌的情况下,检测到同位素的量分别占总丙氨酸和缬氨酸的23.7%和26.2%。因此,同位素分析表明,本发明的重组微生物有效地诱导了将通过循环甲酸和二氧化碳同化途径同化的甲酸同化到大肠杆菌的中心碳代谢(ccm)中的过程。
实施例2-3:通过二氧化碳同化产生乙酰coa和再生乙醛酸的鉴定
通过测量实施例1的重组大肠杆菌和野生型大肠杆菌产生的乙酸中碳同位素的含量,对通过二氧化碳同化过程(这是在本发明中开发的循环甲酸和二氧化碳同化途径的循环过程的最后一部分)产生乙酰coa和再生乙醛酸进行了鉴定。也就是说,二氧化碳衍生的碳对应于通过在本发明中开发的循环甲酸和二氧化碳同化途径合成的乙酰coa的位置1处的碳。通常,乙酰coa在大肠杆菌中按一定比例转化为乙酸。因此,乙酸分析提供了乙酰coa中同位素含量的分析。
基于此原理的乙酰coa中碳同位素含量的分析结果表明,与野生型大肠杆菌相比,具有代谢途径的重组大肠杆菌(dh5αst3)在乙酸中具有增加的同位素含量。因此,可以看出,根据本发明的重组大肠杆菌对二氧化碳同化和乙醛酸再生而言是有效的。
实施例3:使用碳同位素分析鉴定通过循环代谢途径产生丙酮酸
将丙酮酸甲酸裂解酶进一步引入循环代谢途径中以鉴定丙酮酸是否通过所述酶的逆反应从乙酰coa和甲酸合成,这可以通过碳同位素分析来鉴定。也就是说,当提供质量数为13的碳同位素标记的甲酸和二氧化碳时,通过相应的循环代谢途径和丙酮酸甲酸裂解酶的逆反应合成的丙酮酸在位置1和3处具有甲酸衍生的碳,并且在位置2处具有二氧化碳衍生的碳。
基于此原理,通过与在实施例2-2中使用的碳同位素分析相同的方法分析丙酮酸。结果,可以看出,在具有在本发明中产生的循环代谢途径的重组大肠杆菌(dh5αst2)的情况下,与野生型大肠杆菌相比,缬氨酸和丙氨酸中相应的氨基酸的原始质量数增加3或更多的氨基酸比例显著增加。
实施例4:使用碳同位素分析鉴定从甲酸和二氧化碳产生甘氨酸、丝氨酸和丙酮酸
进行碳同位素分析以证实在实施例1中产生的重组大肠杆菌是否可以同化甲酸和二氧化碳以产生甘氨酸、丝氨酸和丙酮酸。为了证实甲酸同化,使用作为对照组的野生型大肠杆菌(dh5αwt)和在实施例1中产生的重组大肠杆菌中引入了通过由seqidno:7表示的核酸分子编码的甲酸四氢叶酸连接酶、通过由seqidno:8表示的核酸分子编码的次甲基四氢叶酸环水解酶、通过由seqidno:9表示的核酸分子编码的亚甲基四氢叶酸脱氢酶和通过由seqidno:63表示的核酸分子编码的甘氨酸裂解复合物的重组大肠杆菌(dh5αrg2)进行实验。
为了证实甲酸和二氧化碳同化效率的提高,使用通过缺失重组大肠杆菌(dh5αrg2)中的gcvr基因(seqidno:66,ncbi信息:nc_000913.3,区域2599906-2600478)并改变构成甘氨酸裂解复合物的基因的启动子{用seqidno:68取代seqidno:67(ncbi信息:nc_000913.3区域3049125-3050667)}而获得的重组大肠杆菌(dh5αrg4)进行实验。
对于碳同位素分析,将对照和实验大肠杆菌在含有用13c碳同位素标记的甲酸盐和碳酸氢盐离子的m9培养基中培养(参见上表7中所示的组成),然后分析大肠杆菌细胞样品。在强酸性且高温的条件下水解构成大肠杆菌的所有蛋白质后,使用气相色谱/质谱使用大肠杆菌细胞样品分析构成大肠杆菌的氨基酸的质量数(zamboni等人,nat.protocols,4:6,878-892,2009)。
实施例4-1:从甲酸和二氧化碳合成甘氨酸、丝氨酸和丙酮酸的鉴定
重组大肠杆菌(dh5αrg2)通过图8所示的代谢途径从一分子甲酸和一分子二氧化碳合成甘氨酸。在使用上表7中描述的m9培养基培养重组大肠杆菌后,分析大肠杆菌细胞样品。结果,可以确认86%的总甘氨酸是从甲酸和二氧化碳合成的。此外,56%的总丝氨酸是从甲酸和二氧化碳合成的,并且3.5%的总丙酮酸是从甲酸和二氧化碳合成的。使用强启动子产生了具有改进的甲酸同化途径表达的重组大肠杆菌(dh5αrg3),以提高甲酸和二氧化碳的同化效率,并测量了从甲酸合成的甘氨酸、丝氨酸和丙酮酸的比例。然而,未观察到与上述产生的重组大肠杆菌(dh5αrg2)的效果相比其效果的改进。
实施例4-2:通过在重组大肠杆菌中进行基因缺失和启动子修饰改进甲酸和二氧化碳的同化效率
为了改进从甲酸合成甘氨酸、丝氨酸和丙酮酸,通过改变重组大肠杆菌(dh5αrg2)中控制甘氨酸裂解复合物表达的控制基因(gcvr)和甘氨酸裂解复合物的启动子来制备重组菌株(dh5αrg4)。分析了从甲酸和二氧化碳合成甘氨酸、丝氨酸和丙酮酸。结果,可以看出,分别从甲酸和二氧化碳合成了96%、86%和7.3%的甘氨酸、丝氨酸和丙酮酸。
总之,基于上述实施例,根据本发明的重组大肠杆菌通过在本发明中鉴定的循环代谢途径有效地作用于甲酸和二氧化碳的同化,并且丙酮酸甲酸裂解酶的进一步引入显著地提高了丙酮酸合成效率。此外,可以看出,甘氨酸、丝氨酸和丙酮酸可以通过甲酸和二氧化碳同化代谢途径从甲酸和二氧化碳高效合成。
尽管已经详细地描述了本发明的具体配置,但是本领域技术人员将理解,此详细描述是出于说明目的作为优选实施方案提供的,而不应当解释为限制本发明的范围。因此,本发明的实质范围由提交的所附权利要求及其等同物限定。
【符号说明】
合成启动子100:bba23100合成启动子
ftfl:seqidno:7,甲酸四氢叶酸连接酶
fch:seqidno:8,次甲基四氢叶酸环水解酶
mtda:seqidno:9,亚甲基四氢叶酸脱氢酶
rrnbt:rrnb终止子
apr:氨苄西林抗性基因
pbr322起点:pbr322复制起点
mtka(cm4):seqidno:3,苹果酸coa连接酶β亚基
mtkb(cm4):seqidno:4,苹果酸coa连接酶α亚基
mcl:seqidno:5,苹果酰coa裂解酶
sga:seqidno:6,丝氨酸乙醛酸转氨酶
cmr:氯霉素抗性基因
p15a:p15a复制起点
p23100:bba23100合成启动子
sgaat:seqidno:21,丝氨酸乙醛酸转氨酶
rrnbt1t2:rrnb终止子
succ2op:seqidno:17,琥珀酰coa:(s)-苹果酸coa转移酶
sucd2op:seqidno:18,琥珀酰coa:(s)-苹果酸coa转移酶
gcvt:seqidno:63,甘氨酸裂解复合物中的t亚基
gcvh:seqidno:63,甘氨酸裂解复合物中的h亚基
gcvp:seqidno:63,甘氨酸裂解复合物中的p亚基
trc-pro:trc启动子
laciq:突变型laci阻遏物
【工业实用性】
本发明提供了引入了新颖循环代谢途径的新颖微生物,通过所述途径可以从甲酸和二氧化碳合成c3或更高碳的有机化合物,从而使用二氧化碳(其在自然界中是丰富的)和甲酸(其具有低毒性且从反应动力学角度来看适于同化(合成代谢)反应并且可以容易且快速地从二氧化碳合成)有效地合成作为c3有机化合物的丙酮酸。结果,本发明在经济地产生有机碳化合物、减少二氧化碳(其是全球变暖的主要原因)和从作为中间产物的丙酮酸合成各种高附加值化合物方面是有效的。
序列表
<110>韩国科学技术院
<120>引入了异种基因的重组微生物和使用所述微生物从甲酸和二氧化碳产生有用材料的方法
<130>pf-b2236
<140>pct/kr2017/013171
<141>2017-11-20
<150>kr10-2016-0157502
<151>2016-11-24
<160>69
<170>patentin版本3.5
<210>1
<211>40
<212>dna
<213>人工序列
<220>
<223>用于构建重组质粒的正向引物
<400>1
actgataagcctttcggtaaggtacccggggatcctctag40
<210>2
<211>40
<212>dna
<213>人工序列
<220>
<223>用于构建重组质粒的反向引物
<400>2
tcgtgtaagtgtctcaacaagagctcgaattcgctagcac40
<210>3
<211>1173
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>3
atggacgttcacgagtaccaagccaaggagctgctcgcgagcttcggggtcgccgtcccg60
aagggcgccgtggctttcagcccggatcaagcggtctacgcggcgaccgagctcggcggc120
tcgttctgggcggtgaaggctcagatccatgccggcgcgcgcggcaaggcgggcgggatc180
aagctctgccgcacctacaacgaagtgcgcgacgccgcccgcgacctactgggaaaacgc240
ctcgtgacgcttcagaccggccccgagggcaagccggtgcagcgcgtctacgtcgagacc300
gccgacccgttcgagcgtgaactctatctcggctacgtcctcgatcgaaaggccgagcgc360
gtccgtgtcatcgcctcccagcgcggcggcatggatatcgaagagatcgccgccaaggag420
cccgaggcgctgatccaggtcgtggtcgagccggcggtgggcctgcagcagttccaggcc480
cgcgagatcgcgttccagctcggcctcaacatcaagcaggtctcggccgcggtgaagacc540
atcatgaacgcctaccgggcgttccgcgactgcgacggcaccatgctggagatcaacccg600
ctcgtcgtcaccaaggacgaccgggttctggcactcgacgccaagatgtccttcgacgac660
aacgccctgttccgccgccgcaacatcgcggacatgcacgacccgtcgcagggcgatccc720
cgcgaggcccaggctgccgagcacaatctcagctatatcggcctcgagggcgaaatcggc780
tgcatcgtcaacggcgcgggtctggccatggcgaccatggacatgatcaagcatgcgggc840
ggcgagccggcaaacttcctggatgtgggcggcggcgccagcccggatcgcgtcgccacg900
gcgttccgcctcgttctgtcggaccgcaacgtgaaggcgatcctcgtcaacatcttcgct960
ggcatcaaccgctgcgactgggtcgcggagggcgtggtcaaggctgcgcgcgaggtgaag1020
atcgacgtgccgctgatcgtgcggctcgccggcacgaacgtcgatgaaggcaagaagatc1080
ctcgccgaaagcgggctcgacctcatcaccgccgacacccttacggaagccgcgcgcaag1140
gctgtcgaagcctgccacggcgccaagcactga1173
<210>4
<211>891
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>4
atgagcattctcatcgacgagaagaccccgatcctggtccagggcatcacgggcgacaag60
ggaaccttccacgccaaggagatgatcgcctacggctccaacgtcgtcggcggcgtcacc120
ccgggcaagggcggcaagacccattgcggcgtgccggtgttcaacaccgtcaaggaggcc180
gtagaggcgaccggcgccaccacctcgatcaccttcgtggcgcctcccttcgcggcggac240
gcgatcatggaggcggccgatgctggcctcaagcttgtctgctcgatcaccgacggcatc300
cccgctcaggacatgatgcgggtgaaacgctacctccggcgctatccgaaggagaagcgc360
acgatggtggtgggcccgaactgcgcgggcatcatctcgcccggcaagtcgatgctcggc420
atcatgcccggtcacatctacctcccgggcaaggtcggcgtcatctcccgctccggaacc480
ctcggctacgaggccgcggcgcagatgaaggagctcggcatcggcatctcgacctccgtc540
ggcatcggcggcgatccgatcaacggctcctccttcctcgaccacctcgctctgttcgag600
caggatcccgagacggaagccgtgttgatgatcggcgagatcggcggtccgcaggaggcc660
gaggcctcggcctggatcaaggagaacttttccaagcccgtgattggcttcgtggcgggc720
ctcaccgcccccaagggccgccgcatggggcatgccggcgcgatcatctcggcgaccggc780
gacagcgccgcggagaaggccgagatcatgcgctcctacggcctgaccgtggcgcccgat840
ccgggctccttcggcagcaccgtagccgacgtgctcgcccgcgcggcgtga891
<210>5
<211>975
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>5
atgagcttcaccctgatccagcaggccaccccgcgcctgcaccgctcggaactcgcggtt60
cccggctccaacccgaccttcatggagaagtcggccgcctcgaaggccgacgtgatcttc120
ctcgacctcgaggacgcggttgcgcccgacgacaaggagcaggcccgcaagaacatcatc180
caggccctcaatgacctggattggggcaacaagaccatgatgatccgcatcaacggtctc240
gacacccactacatgtaccgcgacgtggtggacatcgtggaggcctgcccgcgcctcgac300
atgatcctgatccccaaggtcggcgtgccggccgacgtctacgccatcgacgtgctgacg360
acgcagatcgagcaggccaagaagcgcgagaaaaagatcggcttcgaagtgctgatcgag420
accgcgctcggcatggccaatgtcgaggcgatcgcgacctcgtctaagcgccttgaggcg480
atgtccttcggtgtcgccgactacgccgcctccacccgcgcccgctccaccgtgatcggc540
ggcgtcaatgccgattacagcgtgctcaccgacaaggacgaggccggcaaccgccagact600
cactggcaggatccgtggctgttcgcccagaaccggatgctggtcgcctgccgcgcctac660
ggcctgcgcccgatcgacggtcccttcggcgacttctccgatccggacggctacacctcg720
gccgctcgccgctgcgccgcgctcggcttcgagggcaagtgggcgatccacccctcgcag780
atcgatctggccaacgaggtcttcaccccctccgaggccgaggtcaccaaggcccgccgc840
atcctggaagccatggaagaggccgccaaggccggccgcggcgccgtctcgctcgacggc900
cgcctcatcgacatcgcctcgatccgcatggccgaggcgctgatccagaaggccgacgcg960
atgggcggaaagtaa975
<210>6
<211>1209
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>6
atggcggcaacgagacgtccgggacgcaaccacctgttcgttcccggcccgaccaacatc60
ccggaccgggtgatgcgcgccatgatggtgcagtccgaggatcaccgctcggtcgatttc120
ccgtcgctgacgaagccgctgttcgaggacaccaagaaggtgttcggctcgaccgaaggc180
acgatcttcctgttcccggcctccggcacgggcatctgggaatcggcgctgtccaacacg240
ctcgcccgcggcgacaaggtggtggccgcccgcttcggccagttcagccatctctggatc300
gacatggcccagcgcctcggcctggacgtcgtcgtccaggaggaggagtggggcaccggc360
gccaagcccgagaagatcgaggaggccctgcgcgccgacaagaaccatgagatcaaggcc420
gtcatggtggtccataacgagaccgcgaccggcgtgacctccaacatcggcgccgtgcgc480
aaggcgatcgacgccgccggccacccggccctgctgttcgtcgacggcgtgtcctccatc540
ggctcgctgcccttcaaggccgacgagtggaaggtcgactgcgccatcgccggctcccag600
aagggcctgatgctgcccgccggcctcggcgtgatttgcgtcagccagaaggcgctcaag660
gccgccgagggccagtccggccgcaacgaccggctcgcccgcgtctacttcgactgggaa720
gaccagaagaagcagaacccgaccggctacttcccctacaccccgccgctgccgctgctc780
tacggcctgcgcgaggcgctcgcctgcctgttcgaggaaggcctggagaacgtctaccac840
cgccacgccgtgctcggtgaggcgacccgtcaggccgtcgcggcctggggcctgaagacc900
tgcgccaagtcgccggagtggaactccgacaccgtcaccgccatcctggcgcccgagggt960
gtggacgcggccaagatcatcaagcacgcctatgtgcgctacaacctcgcgctcggcgcc1020
ggcctgtcccaggtcgcgggcaaggtgttccgcatcggtcacgtcggcgacctgaacgaa1080
ctctcgctgctcggcgccatcgccggtgccgagatgtcgctcatcgacaacggcgtgaag1140
gtgacccccggttcgggtgttgccgccgcctccagctacctgcgcgagaacccgctcgcc1200
aaggcttga1209
<210>7
<211>1674
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>7
atgccctcagatatcgagatcgcccgcgcggcgaccctgaagccgatcgcccaggtcgcc60
gaaaagctcggcatcccggacgaggcgcttcacaattacggcaagcacatcgccaagatc120
gaccacgacttcatcgcctcgctcgagggtaagcccgagggcaagctggtgctcgtcacc180
gcgatctcgccgacgcctgcgggcgagggcaagaccaccacgactgtggggctcggcgac240
gcgctcaaccgcatcggcaagcgggcggtgatgtgcctgcgcgagccctcgctcggcccc300
tgcttcggcatgaagggcggcgcggccggtggcggcaaggcgcaggtcgtgccgatggag360
cagatcaacctgcacttcaccggcgacttccacgccatcacctcggcgcactcgctcgcc420
gccgctctgatcgacaaccacatctactgggccaacgagctcaacatcgacgtgcgccgc480
atccactggcgccgcgtggtcgacatgaacgaccgagcgctgcgcgcgatcaaccagtcg540
ctcggcggcgtcgccaacggctttccgcgtgaggacggcttcgacatcaccgtcgcctcc600
gaggtgatggcggtgttctgcctcgccaagaatctggctgacctcgaagagcggctcggc660
cgcatcgtcatcgccgagacccgcgaccgcaagccggtgacgctggccgacgtgaaggcg720
accggtgcgatgaccgttctcctcaaggacgcgcttcagccgaacctcgtgcagacgctg780
gagggcaacccggccctgatccatggcggcccgttcgccaacatcgcccacggctgcaac840
tcggtgatcgccacccgcaccggcctgcggctggccgactacaccgtcaccgaggccggc900
ttcggcgcggatctcggcgcggagaagttcatcgacatcaagtgccgccagaccggcctc960
aagccctcgtcggtggtgatcgtcgccacgatccgcgccctcaagatgcatggcggcgtc1020
aacaagaaggatctccaggctgagaacctcgacgcgctggagaagggcttcgccaacctc1080
gagcgccacgtgaataacgtccggagcttcggcctgccggtggtggtgggtgtgaaccac1140
ttcttccaggacaccgacgccgagcatgcccggttgaaggagctgtgccgcgaccggctc1200
caggtcgaggcgatcacctgcaagcactgggcggagggcggcgcgggcgccgaggcgctg1260
gcgcaggccgtggtgaagctcgccgagggcgagcagaagccgctgaccttcgcctacgag1320
accgagacgaagatcaccgacaagatcaaggcgatcgcgaccaagctctacggcgcggcc1380
gacatccagatcgagtcgaaggccgccaccaagctcgccggcttcgagaaagacggctac1440
ggcaaattgccggtctgcatggccaagacgcagtactcgttctcgaccgacccgaccctg1500
atgggcgcgccctcgggccacctcgtctcggtgcgcgacgtgcgcctctcggcgggcgcc1560
ggcttcgtcgtggtgatctgcggtgagatcatgaccatgccgggtctgccaaaagtgccg1620
gcggcggacaccatccgcctggacgccaacggtcagatcgacgggctgttctag1674
<210>8
<211>627
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>8
atggccggcaacgagacgatcgaaacattcctcgacggcctggcgagctcggccccgacc60
cccggcggcggcggtgccgccgcgatctccggcgccatgggcgcggcgctggtgtcgatg120
gtgtgcaacctcaccatcggcaagaagaagtatgtcgaggtcgaggccgacctgaagcag180
gtgctggagaagtcggaaggcctgcgccgcacgctcaccggcatgatcgccgacgacgtc240
gaggctttcgacgcggtgatgggcgcctacgggctgccgaagaacaccgacgaagagaag300
gccgcccgcgccgccaagattcaagaggcgctcaaaaccgcgaccgacgtgccgctcgcc360
tgctgccgcgtctgccgcgaggtgatcgacctggccgagatcgtcgccgagaagggcaat420
ctcaacgtcatctcggatgccggcgtcgccgtgctctcggcctatgccggcctgcgctcg480
gcggcccttaacgtctacgtcaacgccaagggcctcgacgaccgcgccttcgccgaggag540
cggctgaaggagctggagggcctactggccgaggcgggcgcgctcaacgagcggatctac600
gagaccgtgaagtccaaggtaaactga627
<210>9
<211>867
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>9
atgtccaagaagctgctcttccagttcgacaccgatgccacgccgagcgtcttcgacgtc60
gtcgtcggctacgacggcggtgccgaccacatcaccggctacggcaacgtcacgcccgac120
aacgtcggcgcctatgtcgacggcacgatctacacccgcggcggcaaggagaagcagtcg180
acggcgatcttcgtcggcggcggcgacatggcggccggcgagcgggtgttcgaggcggtg240
aagaagcgcttcttcggcccgttccgcgtgtcctgcatgctggattcgaacggctccaac300
acgaccgctgcggcgggcgtggcgctcgtcgtcaaggcggcgggcggctcggtcaagggc360
aagaaggccgtcgtgctcgcgggcaccggcccggtcggcatgcgctcggcggcgctgctt420
gccggcgagggcgccgaggtcgtgctgtgcgggcgcaagctcgacaaggcgcaggccgcg480
gccgattccgtgaacaagcgcttcaaggtgaacgtcaccgcggccgagaccgcggacgac540
gcttcgcgtgccgaggccgtgaagggcgcccatttcgtcttcaccgccggtgcgatcggc600
cttgaactgctgccgcaggcagcctggcagaacgagagttcgatcgagatcgtggccgac660
tacaacgcccagccgccgctcggcatcggcgggatcgatgcgaccgacaaaggcaaggaa720
tacggcggaaagcgcgccttcggtgcgctcggcatcggcggcttgaagctcaagctgcac780
cgcgcctgcatcgccaagctgttcgagtcgagcgaaggcgtcttcgacgccgaggagatc840
tacaagctggccaaggaaatggcctga867
<210>10
<211>945
<212>dna
<213>扭脱甲基杆菌(methylobacteriumextorquens)
<400>10
atgacaaagaaagtcgtcttcctcgatcgcgagtcgctcgacgcgaccgtgcgcgaattc60
aacttcccgcacgagtacaaggaatacgagtcgacctggacgccggaggagatcgtcgag120
cgccttcagggcgccgagatcgcgatgatcaacaaggtgccgatgcgcgccgacacgctg180
aagcagcttcccgacctgaagctgatcgcggtggctgccacgggcacggacgtcgtcgat240
aaggctgcggccaaggcgcagggcatcacggtcgtcaacatccgcaactacgccttcaac300
accgtgcccgagcacgtggtcggcttgatgttcgccctgcgccgggcgatcgtgccttac360
gccaactcggtgcgccggggcgattggaacaagtcgaagcagttctgctacttcgattac420
ccgatctacgacatcgccggctcgacgctcggcatcatcggctacggcgcgctcggcaag480
tcgatcgccaagcgggccgaggccctcggcatgaaggtgctcgccttcgacgtgttcccg540
caggacgggctagtggatctcgatacgatcctgacccagtccgacgtcatcacgctgcac600
gtgccgctgacgcccgacaccaagaacatgatcggggccgagcagctcaagaagatgaag660
cggtccgcgatcctcatcaacaccgcccgcggcgggctggtggacgaggcggccttgctc720
caggcgctcaaggacggcaccatcggcggcgccggcttcgacgtcgtggcccaggagccc780
ccgaaggacggcaacatcctctgcgacgccgacctgccgaacctgatcgtcaccccgcac840
gtggcctgggcgagcaaggaggcgatgcagatcctcgccgaccagctcgtggacaacgtc900
gaggccttcgtcgcgggcaagccgcagaacgtcgtcgaggcgtaa945
<210>11
<211>2084
<212>dna
<213>脱氮玫瑰杆菌(roseobacterdenitrificans)
<400>11
atggatatccacgagtaccaagcgaaagaagttcttgctaatttcggggtcgctgtgccg60
gatggcgctttggcgtacagcccggaacaggcatcctaccgcgcacgcgagctcggcggt120
gaaagatgggttgttaaggcccagatacacgccggcgggcgcggcaaggcgggcggcgta180
aaagtctgtgaaagcgacgtcgaaatccagaaagcatccgaagagatgtttggcaaaaag240
atgatcacgcatcagaccggaccagaaggcaaaggcatctaccgcgtctatgtcgaggct300
gcggtgccgatagatcgcgagatttatctgggctttgttcttgatcgtacgacgcaacgg360
gtcatgatcgttgcaagtgccgaaggcggtatggagattgaagaaatctctgaaaaacgc420
cccgaaagcatcgttcgggcgattgtggagcctgccgttggtctgcgcgaatttcagtgc480
cgccagattgcattcaaattgggcgtcgatgcgggtctgacacagcagatggtgcgtacc540
ttgcaaggctgttatcgggcttttaccgagctggacgcgaccatggtggagatcaaccct600
ttggtcattaccgcagacaatcgcgtgattgcgctggatgccaagatgacttttgacgac660
aatgcgttgttccgccacccacagatcagcgaattgcgcgacaaatcgcaagaggatccg720
cgcgaaagccgggctgccgatcgcggtctgtcctatgtcggtctggacggcaatatcggc780
tgcatcgtgaacggggctggccttgccatggcgacgatggacacgatcaaactggccggt840
ggggagcctgcgaatttcctcgatatcggcggtggggccacgcccgaacgtgtggccaag900
gctttccggctggtgctgtcggacaagagcgtgcaggcgatcttggtcaatatctttgca960
gggatcaaccgctgtgactgggtggccgaaggcgtcgtgcaggccctcagggaagtgcag1020
gtcgatgtgcccgtgatcgtgcgactggccggcaccaatgtggaggaagggcagaagatt1080
ctcgcccaatccggcctgccgatcatccgcgcaaccactctgatggaagccgccgagcgc1140
gcggtcggtgcgtggcagaatgacctgtcgcagggtacaagaatgagggccgtatcatga1200
gcatacttcttgatagcgacaccaaagtcattgtgcagggcatcaccggcaagatggccc1260
gcttccacaccaaggatatgctcgaatacggcactaacgtcgtcggtggcgtggtccctg1320
gcaagggcggcgaaacggtcgaaggcgtgcctgtctttgacaccgttgaagaggcggtcg1380
cgcaaaccggggcggaggcgtcgctggttttcgtcccgccgcctttcgcggctgatagca1440
ttatggaagccgcagatgcgggaattcagtactgcgtctgcatcacggacggtatccccg1500
cacaggacatgatccgtgtgaaacgctacatgtaccgctatccgaaagagcgccgcatgg1560
tgctcaccggaccaaactgtgccggcacgatcagcccgggcaaggcgctgctgggcatca1620
tgccggggcatatctacctgcaaggccacgtgggtatcgtgggacgttcaggcacgctgg1680
gctatgaggcggccgcacaactcaaggaacgcggcatcggtgtttccacttcggtgggga1740
ttggcggcgacccgatcaatggttcatcgttcaaagacattctgcagcgttttgaagaag1800
acgaagacacccatgtgattgcgatgatcggagagatcggcggaccgcaagaagcggaag1860
cagccgaatacatccgcgcgcatgtgaccaaaccggttgtggcctatgtcgcgggcctga1920
ccgctcctaaggggcgcaccatgggccatgcgggcgcgatcatctcggcctttggcgaaa1980
gtgcgagcgaaaaggtcgaaatcctgtcggcggcaggcgtcacggttgccgaaaacccgg2040
ctgtcatcggtgagacaatcgccaaagtgatggaggccgcgtga2084
<210>12
<211>2090
<212>dna
<213>脱氮玫瑰杆菌(roseobacterdenitrificans)
<400>12
atggatatccacgaataccaagcaaaggaaattctcgccagtttcggcgtagatgttccg60
cccggtgcgttggcctacagccctgaacaagcggcatatcgggcgcgcgaacttggcggg120
gaccgctgggtcgtcaaggcgcaggtgcacgcaggtggccgcggcaaggcgggcggcgtg180
aaggtgtgcgacagcgacgtcgagattcacaagacctgcgagggcctgtttggccgcaag240
ctggtgacgcatcagaccggaccggagggcaagggcatttaccgcgtctatgtcgaaggt300
gccgtgccgatcgaacgcgagatttacctcgggttcgttctggaccgcacgtcgcagcgt360
gtcatgatcgtcgcctctgccgaagggggcatggagatcgaggatatctcggccgacaag420
cccgacagcattgtgcgcgacaccgtggaaccggcggttggtctgcaggatttccaatgc480
cgccagatcgcgttcaagctgggcattgatccggccttgacgcagcgcatggtgcgcacg540
ttgcagggctgctaccgggcatttcgcgaatatgacgccacgatggtcgaggtcaatccg600
ctcgttgtgaccggtgacaatcgtattctggcgctggatgccaagatgacctttgacgac660
aacgcgttgttccgccacccacagatcagcgaattgcgcgacaaatcgcaagaggacccg720
cgcgaaagccgggctgccgatcgcggtctgtcctatgttggcctggacggcaatatcggc780
tgcatcgtgaacggggctggccttgccatggcgacgatggacacgatcaaactggccggt840
ggggagcctgcgaacttcctcgatatcggtggtggggccacgcccgaacgtgtggccaag900
gctttccggctggtgctgtcggacaagagcgtgcaggcgatcctcgtcaatatctttgcg960
gggatcaaccgctgtgactgggtggccgaaggcgtcgtgcaggccctcagggaggtgcag1020
gtcgatgtgcccgtaatcgtgcgactggccggcaccaacgtggaggaagggcagaagatc1080
ctcgcccaatccggcctgccgatcatccgtgcaaccacattgatggaagccgccgagcgc1140
gcggtcggtgcgtggcagaatgacctttcccaaaataccaaagtgaggcttgcgacatga1200
gcatttttattgatgcaaacacacccgtcatcgtgcagggcattaccggcaagatggcgc1260
gttttcacacggctgacatgatcgcctatggcaccaacgtcgtcggtggcgtggtccccg1320
gcaagggcggccagacggttgagggcgtgccggttttcgatacagtcgaggacgcggtta1380
ccgccaccggggcggaggcgtcgctggttttcgtcccgccgccttttgcggctgacagca1440
ttatggaagccgcagatgcgggaattcagtactgcgtctgcatcacggacggtatccccg1500
cacaggacatgatccgtgtgaaacgctatatgtaccgctatccaaaagaccgccgcatgg1560
tgctcaccggaccgaattgcgctggcacgatcagcccgggcaaggcgctgctgggcatca1620
tgccggggcatatctatctgcccggtcatgtgggcatcatcggacgctccggcacgttgg1680
gctatgaggccgctgctcagctcaaggaacatgggatcggcgtttcaacctccgtcggaa1740
tcggcggtgatccgatcaacggatcgtccttccgggacatccttgagcgcttcgaggccg1800
atgatgaaacccatgtgatctgcatgatcggagagatcggcgggccgcaggaagccgaag1860
ccgccgcctacattcgcgatcacgtcaccaagccggtgattgcctatgttgcaggcctga1920
ctgcaccgaaagggcgcaccatgggccatgcgggcgcgatcatctccgcctttggagaaa1980
gtgcgagcgaaaaggtcgaaatcctgtcggcggcaggcgtcacggttgccgaaaacccgg2040
ccgtcattggcgataccattgccggcgtcctgaggaaggaggccgcatga2090
<210>13
<211>1233
<212>dna
<213>脱氮玫瑰杆菌(roseobacterdenitrificans)
<400>13
atgacccaaaaaagcaacctgtctgccgggcgggagtatctcgcgattccggggccttcc60
gtaattcctgatgcggtattgcaggccatgcaccgcgcagcgccgaacatctatgccggt120
gccttgcctgacatgatgccgggccttgtcgccgacctgcgccgcgttgcgcgcacccgc180
catcatgttgcgatttacatcggcaacgggcatgcggcatgggaggcagcactggccaat240
gtcattggcgcgggggatcgggtgctggtccctgccacgggcagttttggccatgattgg300
ggggatatggccgcggggcttggggcagaggttgaaacgctcgattttggcaaggcgtcg360
gccatggatatggcgcggatcggcgaggcgctcaaggcggatagatcacatgccatcaag420
gcggttctggcggtgcatgtggacacatcaagctcggtgcgcaatgatattgcagccctg480
cgcgcggtgatggatgaggccgggcatcccgcgttgttgatggtggattgcattgcgtca540
ctgggctgcgacgtgttcgagatggacgactggggcgtggatgtgatggtcactgcctgt600
caaaaggggctgatggtgccaccgggcatggctttcgtctttttcaacgacaaggctggc660
gaggttcgacggcaaatgccgagggtcagccgctattgggattggaccccgcgcgccgca720
cctgacctgttttatcaatactggaacgggacagcgcccacgcatcatgtctacggtctg780
cgggctgccttggacatgatccacgccgaaggaatcgaagctgtgtggcggcgtcacgaa840
gtgctcgcacatgcgatctgggcggcttgcagcgcatggggcgcaggtggcagtctggcc900
ttcaatgtggccgaaccggatgcgcgcagccgggctgttacgtcactgaaacttgaaagc960
ccgcaggccaccgcgctgcgcgactggactgaaaaccagcttggcttgacccttggcatc1020
ggacttggcatggcgacacggggcgatccggcatggcatgggtttttccggttgggtcac1080
atgggtcacatcaacggccacatgatcatggggatgctcggcggcgtggatgcgggtttg1140
aaagcgctggacattccgcacgggccgggcgcgcttgaggctgcatccaccgtgattgcc1200
accggtcagttgtcggcgggggcgtcggagtag1233
<210>14
<211>858
<212>dna
<213>类球红杆菌(rhodobactersphaeroides)
<400>14
atggcgcatcaggctcatcccttccgctccgtgctctacattcccggctcgaaggagcgg60
gcgctggagaaggcgcagggccttgccgccgatgcgatcatcttcgacctcgaggatgct120
gtcgcccatgacgagaagatccacgcgcgcgcgctcctgaagaccacgctcgagaccgtc180
gattacggccatcgcttccgcatcgtgagggtgaacgggatggacaccgagtggggccgc240
gcggatctcgaggccttcgcggaggcaaaggcggacgcgatcctcattcccaaggtctcg300
cgggcggcggatctggaggcggtggcggccctcgtgcccgacctgccgctctgggccatg360
atggagacggcgcagggcatgctcaacgccgccgagatcgcggcccacccgcgcctcacc420
ggcatggtgatgggcacgaacgacctcgccaaggagctcggcagccgctaccggcccgac480
cgtctggcgatgcaggcggggctcggcctctgcctgctcgcggcccgcgcccatgggctc540
accatcgtcgacggcgtctacaatgccttcaaggacgaggagggcctgcgggccgaatgc600
gagcagggccgcgacatgggcttcgacggcaagacgctgatccatcccgcccagctcgag660
atcgcgaacgcggtcttttcgccctcgccggccgagatcgagctggccaaccgccagatc720
gccgccttcgaggaggcagaacgccacgggcagggcgtggccgttgtggatggcaagatc780
gtcgagaacctgcatatcgtgaccgcgcggcagactctggccaaggccgaggcgattgcc840
gcgttcagggcaagctga858
<210>15
<211>957
<212>dna
<213>类球红杆菌(rhodobactersphaeroides)
<400>15
atgagcttccgccttcagcccgcgccgcctgcccgtccgaaccgctgccagctgttcggc60
cccggctcccggcccgcgctgttcgagaagatggcggcctccgcggcggacgtgatcaac120
ctcgacctcgaggattcggtggcgcccgacgacaaggcgcaggcccgcgcgaacatcatc180
gaggcgatcaacgggctcgactggggccgcaagtatctctcggtccgcatcaacggtctg240
gacacgcccttctggtatcgcgacgtcgtggacctgctcgaacaggccggcgaccggctc300
gaccagatcatgatcccgaaggtcggctgcgcggcggatgtttatgcggtcgatgctctg360
gtcacggccatcgagcgcgccaagggccgcaccaagcccctgagcttcgaggtcatcatc420
gaatcggccgcgggcatcgcccatgtcgaggaaatcgcggcctcctcgccgcgcctgcag480
gccatgagcctcggcgccgccgatttcgcagcctcgatggggatgcagacgacaggtatc540
ggtggcacgcaggaaaactactacatgttgcatgacgggcagaagcactggtcggacccg600
tggcactgggcgcaggcggccatcgtggcggcctgccggacccacgggatcctgccggtg660
gacggcccgttcggcgatttttccgacgatgagggcttccgcgcgcaggcccgccgctcg720
gccactctggggatggtgggcaaatgggccatacatcccaaacaggtggccctcgcgaac780
gaagttttcaccccttccgagacggccgtgaccgaagcgcgcgagatcctcgcggcgatg840
gatgcggccaaggcgaggggcgagggcgccacggtctacaagggaagacttgttgacatc900
gcgtccatcaaacaggcagaagtgatcgtaaggcaggcagaaatgatctcggcctga957
<210>16
<211>1203
<212>dna
<213>类球红杆菌(rhodobactersphaeroides)
<400>16
atgtcgcttgcgcacggccgtccctatcttgccattcccggcccctccgccatgccggac60
cgggtgctgaacgccatgcaccgtgccgcgcccaacatctacgaaggcgccctgcacgag120
atggtggccagcctctggccggatctgaagcgcattgccggcaccgagcatcaggtggcg180
ctctatatcgcgaacggccacggcgcgtgggaggcggcgaacgccaacctcttcagccgc240
ggcgaccgggcgctggtgctggccaccggccgcttcggtcacggctgggccgagagcgcc300
cgcgcgctcggcgtcgatgtgcagctgatcgacttcggccgggccgcgcccgccgatccc360
gcccggctggaggaggcgctgcgggcggaccccgggcatcggatcaaggcggtgctggtg420
acccatgtcgacacggccacctcgatccgcaacgacgtggccgcgctccgcgccgccatc480
gatgccgtgggccatccggcgctgctcgcggtcgattgcatcgcctcgctcgcctgcgac540
gaatatcgcatggacgaatggggggccgacgtgaccgtcggcgcgagccagaaggggttg600
atgaccccgccggggctgggcttcgtctggtattccgaccgcgcgctggaacggtgccgc660
gcctcggatctgcgcacgccctactgggactggacgccccgcagcttcggcaccgaattc720
tggcagcatttctgcggcaccgcgccgacgcatcacctctacgggttgcgggcggcgctc780
gacatgatcctcgaggagggactgcccgcggtctgggcgcgccacgaggcgctggcgcgg840
gcggtctggacggccttcgaccgctggggcgcgggcaatcccgagatcgcgctcaacgtg900
gccgatgccgcgtgccgcggccgctcggtgacggcggcccggatgggcgcgccccatgcg960
acgcggctgcgggaatggaccgagacgcgggcgggcgtgacgctcggcatcggcctcggc1020
atggcgctgccctcggagcccgcctaccacgggttcctccgcgtcgcgcacatgggccat1080
gtaaacgcccacatgacgctcggcgcgctcgcggtgatggaggcgggcctcgcagcgctc1140
gagatcccgcacggggagggggcgctggccgctgccgccgccagcctcggcgcggcggcc1200
tga1203
<210>17
<211>1368
<212>dna
<213>橙色绿屈挠菌(chloroflexusaurantiacus)
<400>17
atggcgaaagcttcgcgcctgacacgttccacaggtcagccgacggaagtttccgaagga60
caggtgaccgggacctctgaaatgccaccaactggcgaagagccctcagggcatgccgaa120
tccaagcctcccgcatcagaccctatgtctacccccggaaccggtcaggaacaacttcca180
ctgtcgggcattcgcgtcattgacgttgggaactttttggctggaccttacgcggcgtct240
attttgggtgagtttggagccgaagttcttaaaattgaacaccctcttgggggcgacccc300
atgcgccgcttcggtacagccacagcccgccatgacgccaccttggcctggctgtctgaa360
gcccgcaaccgcaagagcgtgactattgacttgcgtcaacaggaaggggttgcattgttc420
ttaaagttggttgcaaagagcgatattcttatcgagaactttcgtcctggaacaatggaa480
gagtggggattaagttggcctgtgttgcaagcgaccaatccgggcttgattatgcttcgc540
gtgtctggttacggccaaacgggcccatatcgccgtcgttcagggttcgctcatatcgct600
catgctttctctgggctttcctatttagctgggttccccggcgaaacacctgtgttacca660
ggcaccgcaccattaggtgattatattgcatctttatttggggcaattggtatcttgatt720
gcgttacgtcacaaagagcaaactggccgtggccaattgattgacgtgggcatctatgaa780
gccgtattccgtattttagatgaaattgcgccagcttatggcttgttcggtaaaattcgt840
gagcgtgagggtgcagggtcttttattgcagtgcctcatggtcactttcgcagcaaagac900
ggtaagtgggtggccattgcatgcactactgacaaaatgtttgaacgtcttgcagaagcc960
atggaacgtccagagttagcatcccctgaattgtatggagatcaacgcaaacgtctggcc1020
gcgcgcgacatcgtaaaccaaatcacaattgaatgggtagggagcctgacacgtgatgaa1080
gttatgcgccgctgcttggaaaaagaggtgccggtgggaccattaaactcaattgctgac1140
atgttcaatgacgagcactttcttgcccgcggtaatttcgcttgcattgaagcggaaggc1200
atcggagaagtagttgttccgaacgtcatcccacgtctttcggagacaccgggtcgcgtt1260
actaatttgggcccacctttgggaaatgccacgtatgaggtactgcgtgaactgttagac1320
atttccgcggaggagatcaagcgcttacgcagccgtaagattatctag1368
<210>18
<211>1218
<212>dna
<213>橙色绿屈挠菌(chloroflexusaurantiacus)
<400>18
atggacgggactactaccaccttaccactggccggtatccgcgtcatcgacgcggctaca60
gttatcgccgcaccgttctgcgctacgcttttgggtgagtttggtgctgacgtcttaaag120
gtcgaacatcccatcggaggggatgccttgcgccgttttggtacgccaaccgcgcgtggc180
gacacgcttacatggcttagtgaatctcgtaataaacgttccgtgaccctgaatcttcag240
cacccggaaggggctcgtgttttcaaagagcttattgctcatagcgatgttttgtgcgag300
aacttccgtcccggaacattagaaaaatggggtttgggttgggatgtcctttccaaaatc360
aatccgcgccttatcatgctgcgcgtaactggatacggccagacgggaccataccgcgac420
cgtccgggtttcgcccgcattgctcacgcagtcggtggtattgcgtatttggctggcatg480
cccaaaggtacgccagtaacgcctgggtctacaacgttggccgattacatgacgggtttg540
tatggttgcattggcgttctgcttgctctgcgccaccgtgaacaaacggggcgcggccaa600
tacatcgacgccgcattatacgaaagcgtcttccgctgctcagacgagctggtacctgcc660
tacggaatgtaccgtaaagtacgcgaacgtcacggttcacactacaacgaattcgcttgt720
cctcatggacatttccaaacgaaagatggtaaatgggtagcaattagctgcgcgactgac780
aagttattcgcgcgtctggctaatgccatgggccgcccggaacttgcctcctcgagcgtc840
tacggagaccagaaggtgcgtttggcccacgcgagcgatgttaacgaaatcgtccgcgac900
tggtgttctagcctgacccgtgccgaggtcctggaacgctgctacgctacggccacgccc960
gccgcgcctttgaacgatattgctgatttcttcggtgaccgccatgtgcacgctcgccgt1020
aacttagtagctatcgatgctgaagatttaggagaaaccttgattatgccgaatgtagta1080
cccaagttatccgagacaccgggaagtatccgcagtttaggacctaaattaggagaacat1140
accgaggaggtattaaaggaaattttaggtatgtgtgatgaacaaatcaatgacctgcgt1200
tccaaacgtgtcatttag1218
<210>19
<211>906
<212>dna
<213>伍氏醋酸杆菌(acetobacteriumwoodii)
<400>19
atggcagcaaaattattaagtggaaaagaagttagcgagtcaatgctcgctgaagtacta60
aaagatgcgaatgaattaaaagcaaaaggcattaccgtaaaaatggcaatcatgcgcgtt120
ggtgaagacccaggttccatttcttatgaaaaaagtattatcaccagaatgggaaaatca180
aatatcgaagttgaatcggtacaattcccaattgatgtaacagaagctgattttattgcc240
aaacttcaatcaatcaacgaagataaaaacattcattcagtattaatattccaacctctt300
cccgatcaaatcgacgctgaaaaaataaaatatctgttaagtcctgaaaaagatccagat360
gctcttaatccaacaaacttaggaaaactaatgattgctgatgaaagaggattttttcca420
tgtaccgctgaaggcgttatggaaatgtttaaattctataatattgatgttaagggcaaa480
gacgttgttgttattaacaactctaacgtgttaggaaaaccactgacaattatgttaaca540
aacgaattcgcaaccgtcacaatgtgtcatgtatttacaaaagatacggcttcttacacc600
aagaaagccgatattgttgtaaccgcatgtggtatttacggtttggttaaaccagacatg660
ttaagcgaagattgtattttaattgacgtggcaatggctcaaatgaaagatgaaaacaaa720
gaatttgttttaaatgaagaaggcaagaaaatcagaacgggtgatgctcatgttgactgt780
ttaaacaaagtcgcaatgattacttctgctaccccaggttgtggcggtggaaccggtcca840
attaccacagctttattagctaaacatgtgatcaaagcctgtaaaatgcaaaacggctta900
ttatag906
<210>20
<211>1617
<212>dna
<213>产琥珀酸曼氏杆菌(mannheimiasucciniciproducens)
<400>20
atgacagatcttaatcaattaactcaagaacttggtgctttaggtattcatgatgtacaa60
gaagttgtgtataacccgagctatgaacttctttttgcggaagaaaccaaaccaggttta120
gaaggttatgaaaaaggtactgtgactaatcaaggagcggttgctgtaaataccggtatt180
ttcaccggtcgttctccgaaagataaatatatcgttttagacgacaaaactaaagatacc240
gtatggtggaccagcgaaaaagttaaaaacgataacaaaccaatgagccaagatacctgg300
aacagtttgaaaggtttagttgccgatcaactttccggtaaacgtttatttgttgttgac360
gcattctgcggcgcgaataaagatacgcgtttagctgttcgtgtggttactgaagttgca420
tggcaggcgcattttgtaacaaatatgtttatccgcccttcagcggaagaattaaaaggt480
ttcaaacctgatttcgtggtaatgaacggtgcaaaatgtacaaatcctaactggaaagaa540
caagggttaaattccgaaaacttcgttgcgttcaacattacagaaggcgttcaattaatc600
ggcggtacttggtacggtggtgaaatgaaaaaaggtatgttctcaatgatgaactacttc660
ttaccgcttcgtggtattgcatcaatgcactgttccgcaaacgttggtaaagacggcgat720
accgcaattttcttcggtttgtcaggcacaggtaaaacgacattatcaacagatcctaaa780
cgtcaactaatcggtgatgacgaacacggttgggacgatgaaggcgtatttaacttcgaa840
ggtggttgctacgcgaaaaccattaacttatccgctgaaaacgagccggatatctatggc900
gctatcaaacgtgacgcattattggaaaacgtggttgttttagataacggtgacgttgac960
tatgcagacggttccaaaacagaaaatacacgtgtttcttatccgatttatcacattcaa1020
aatatcgttaaacctgtttctaaagctggtccggcaactaaagttatcttcttgtctgcc1080
gatgcattcggtgtattaccgccggtgtctaaattaactccggaacaaaccaaatactat1140
ttcttatccggtttcactgcgaaattagcgggtacggaacgcggtattacagagcctaca1200
ccaacattctctgcatgttttggtgcggcttttttaagcttgcatccgacacaatatgcc1260
gaagtgttagtaaaacgtatgcaagaatcaggtgcggaagcgtatcttgttaatacaggt1320
tggaacggtaccggcaaacgtatctcaattaaagatacccgtggtattattgatgcaatt1380
ttagacggctcaattgataaagcggaaatgggctcattaccaatcttcgatttctcaatt1440
cctaaagcattacctggtgttaaccctgcaatcttagatccgcgcgatacttatgcggat1500
aaagcgcaatgggaagaaaaagctcaagatcttgcaggtcgctttgtgaaaaactttgaa1560
aaatataccggtacggcggaaggtcaggcattagttgctgccggtcctaaagcataa1617
<210>21
<211>1206
<212>dna
<213>拟南芥(arabidopsisthaliana)
<400>21
atggactatatgtatggaccagggagacaccatctgtttgtaccaggaccagtgaacata60
ccggaaccggtaatccgggcgatgaaccggaacaacgaggattaccggtcaccagccatt120
ccggcgcttacgaaaacattgttggaggatgttaagaagatattcaagaccacatcaggg180
acaccttttctgtttcccacgaccgggactggtgcttgggagagtgccttgaccaacacg240
ttatctcctggagacaggattgtttcgtttctgattggacaatttagcttgctctggatt300
gaccagcagaagaggcttaatttcaatgttgatgtggttgagagtgattggggacaaggt360
gctaatctccaagtcttggcctcaaagctctcacaagacgagaatcataccatcaaagcc420
atttgcattgtccacaacgagaccgcgaccggagttaccaatgacatctctgctgtccgc480
acactcctcgatcactacaagcatccggctttgctgctagtggacggtgtttcgtccatc540
tgcgcgcttgatttccgaatggatgagtggggagtggacgtggccttgactgggtctcag600
aaagccttatctcttccaacaggacttggtattgtctgcgccagtcctaaagctttggaa660
gctaccaaaacttctaaatctctcaaagtattctttgactggaatgactaccttaagttt720
tacaagctaggaacctattggccatacacaccttccattcaacttctctacggtcttaga780
gctgctcttgatcttatctttgaggaaggacttgagaacatcatcgcccgccatgctcgt840
ttgggaaaggccaccaggcttgcggtggaagcatgggggctgaaaaactgcacacagaag900
gaggaatggataagtaacacagtgacagcagttatggtgcctccgcatatagacggttcg960
gagattgtgagaagggcatggcagaggtacaacttaagtcttggtcttggtctcaacaaa1020
gtggctggaaaggttttcagaattggacatctaggaaatgtgaatgagttgcaacttctc1080
gggtgtcttgcgggagtggagatgatactgaaggatgttggatacccagttgtaatggga1140
agtggagttgcagctgcctctacttatcttcagcaccacattcctctcattccctctaga1200
atctaa1206
<210>22
<211>2283
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>22
atgtccgagcttaatgaaaagttagccacagcctgggaaggttttaccaaaggtgactgg60
cagaatgaagtaaacgtccgtgacttcattcagaaaaactacactccgtacgagggtgac120
gagtccttcctggctggcgctactgaagcgaccaccaccctgtgggacaaagtaatggaa180
ggcgttaaactggaaaaccgcactcacgcgccagttgactttgacaccgctgttgcttcc240
accatcacctctcacgacgctggctacatcaacaagcagcttgagaaaatcgttggtctg300
cagactgaagctccgctgaaacgtgctcttatcccgttcggtggtatcaaaatgatcgaa360
ggttcctgcaaagcgtacaaccgcgaactggatccgatgatcaaaaaaatcttcactgaa420
taccgtaaaactcacaaccagggcgtgttcgacgtttacactccggacatcctgcgttgc480
cgtaaatctggtgttctgaccggtctgccagatgcatatggccgtggccgtatcatcggt540
gactaccgtcgcgttgcgctgtacggtatcgactacctgatgaaagacaaactggcacag600
ttcacttctctgcaggctgatctggaaaacggcgtaaacctggaacagactatccgtctg660
cgcgaagaaatcgctgaacagcaccgcgctctgggtcagatgaaagaaatggctgcgaaa720
tacggctacgacatctctggtccggctaccaacgctcaggaagctatccagtggacttac780
ttcggctacctggctgctgttaagtctcagaacggtgctgcaatgtccttcggtcgtacc840
tccaccttcctggatgtgtacatcgaacgtgacctgaaagctggcaagatcaccgaacaa900
gaagcgcaggaaatggttgaccacctggtcatgaaactgcgtatggttcgcttcctgcgt960
actccggaatacgatgaactgttctctggcgacccgatctgggcaaccgaatctatcggt1020
ggtatgggcctcgacggtcgtaccctggttaccaaaaacagcttccgtttcctgaacacc1080
ctgtacaccatgggtccgtctccggaaccgaacatgaccattctgtggtctgaaaaactg1140
ccgctgaacttcaagaaattcgccgctaaagtgtccatcgacacctcttctctgcagtat1200
gagaacgatgacctgatgcgtccggacttcaacaacgatgactacgctattgcttgctgc1260
gtaagcccgatgatcgttggtaaacaaatgcagttcttcggtgcgcgtgcaaacctggcg1320
aaaaccatgctgtacgcaatcaacggcggcgttgacgaaaaactgaaaatgcaggttggt1380
ccgaagtctgaaccgatcaaaggcgatgtcctgaactatgatgaagtgatggagcgcatg1440
gatcacttcatggactggctggctaaacagtacatcactgcactgaacatcatccactac1500
atgcacgacaagtacagctacgaagcctctctgatggcgctgcacgaccgtgacgttatc1560
cgcaccatggcgtgtggtatcgctggtctgtccgttgctgctgactccctgtctgcaatc1620
aaatatgcgaaagttaaaccgattcgtgacgaagacggtctggctatcgacttcgaaatc1680
gaaggcgaatacccgcagtttggtaacaatgatccgcgtgtagatgacctggctgttgac1740
ctggtagaacgtttcatgaagaaaattcagaaactgcacacctaccgtgacgctatcccg1800
actcagtctgttctgaccatcacttctaacgttgtgtatggtaagaaaacgggtaacacc1860
ccagacggtcgtcgtgctggcgcgccgttcggaccgggtgctaacccgatgcacggtcgt1920
gaccagaaaggtgcagtagcctctctgacttccgttgctaaactgccgtttgcttacgct1980
aaagatggtatctcctacaccttctctatcgttccgaacgcactgggtaaagacgacgaa2040
gttcgtaagaccaacctggctggtctgatggatggttacttccaccacgaagcatccatc2100
gaaggtggtcagcacctgaacgttaacgtgatgaaccgtgaaatgctgctcgacgcgatg2160
gaaaacccggaaaaatatccgcagctgaccatccgtgtatctggctacgcagtacgtttc2220
aactcgctgactaaagaacagcagcaggacgttattactcgtaccttcactcaatctatg2280
taa2283
<210>23
<211>53
<212>dna
<213>人工序列
<220>
<223>用于mtka扩增的正向引物
<400>23
ttgttgagacacttacacgaaggaggaattcatggacgttcacgagtaccaag53
<210>24
<211>20
<212>dna
<213>人工序列
<220>
<223>用于mtka扩增的反向引物
<400>24
tcagtgcttggcgccgtggc20
<210>25
<211>51
<212>dna
<213>人工序列
<220>
<223>用于mtkb扩增的正向引物
<400>25
tgccacggcgccaagcactgaaggaggaattcatgagcattctcatcgacg51
<210>26
<211>18
<212>dna
<213>人工序列
<220>
<223>用于mtkb扩增的反向引物
<400>26
tcacgccgcgcgggcgag18
<210>27
<211>50
<212>dna
<213>人工序列
<220>
<223>用于mcl扩增的正向引物
<400>27
ctcgcccgcgcggcgtgaaggaggaattcatgagcttcaccctgatccag50
<210>28
<211>19
<212>dna
<213>人工序列
<220>
<223>用于mcl扩增的反向引物
<400>28
ttactttccgcccatcgcg19
<210>29
<211>50
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的正向引物
<400>29
cgcgatgggcggaaagtaaaggaggaattcatggcggcaacgagacgtcc50
<210>30
<211>19
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的反向引物
<400>30
tcaagccttggcgagcggg19
<210>31
<211>51
<212>dna
<213>人工序列
<220>
<223>用于ftfl扩增的正向引物
<400>31
cccgctcgccaaggcttgaaggaggaattcatgccctcagatatcgagatc51
<210>32
<211>19
<212>dna
<213>人工序列
<220>
<223>用于ftfl扩增的反向引物
<400>32
ctagaacagcccgtcgatc19
<210>33
<211>51
<212>dna
<213>人工序列
<220>
<223>用于fch扩增的正向引物
<400>33
gatcgacgggctgttctagaggaggaattcatggccggcaacgagacgatc51
<210>34
<211>21
<212>dna
<213>人工序列
<220>
<223>用于fch扩增的反向引物
<400>34
tcagtttaccttggacttcac21
<210>35
<211>53
<212>dna
<213>人工序列
<220>
<223>用于mtda扩增的正向引物
<400>35
gtgaagtccaaggtaaactgaaggaggaattcatgtccaagaagctgctcttc53
<210>36
<211>40
<212>dna
<213>人工序列
<220>
<223>用于mtda扩增的反向引物
<400>36
tcatccgccaaaacagccaagtcaggccatttccttggcc40
<210>37
<211>52
<212>dna
<213>人工序列
<220>
<223>用于hpra扩增的正向引物
<400>37
ttgttgagacacttacacgaaggaggaattcatgacaaagaaagtcgtcttc52
<210>38
<211>42
<212>dna
<213>人工序列
<220>
<223>用于hpra扩增的反向引物
<400>38
tcatccgccaaaacagccaagttacgcctcgacgacgttctg42
<210>39
<211>53
<212>dna
<213>人工序列
<220>
<223>用于mtkab1扩增的正向引物
<400>39
ttgttgagacacttacacgaaggaggaattcatggatatccacgaataccaag53
<210>40
<211>21
<212>dna
<213>人工序列
<220>
<223>用于mtkab1扩增的反向引物
<400>40
tcatgcggcctccttcctcag21
<210>41
<211>53
<212>dna
<213>人工序列
<220>
<223>用于mtkab2扩增的正向引物
<400>41
ttgttgagacacttacacgaaggaggaattcatggatatccatgaataccaag53
<210>42
<211>22
<212>dna
<213>人工序列
<220>
<223>用于mtkab2扩增的反向引物
<400>42
tcacgcggcctccatcactttg22
<210>43
<211>52
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的正向引物
<400>43
ttgttgagacacttacacgaaggaggaattcatgacccaaaaaagcaacctg52
<210>44
<211>41
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的反向引物
<400>44
tcatccgccaaaacagccaagctactccgacgcccccgccg41
<210>45
<211>51
<212>dna
<213>人工序列
<220>
<223>用于mcl1扩增的正向引物
<400>45
ttgttgagacacttacacgaaggaggaattcatggcgcatcaggctcatcc51
<210>46
<211>20
<212>dna
<213>人工序列
<220>
<223>用于mcl1扩增的反向引物
<400>46
tcagcttgccctgaacgcgg20
<210>47
<211>51
<212>dna
<213>人工序列
<220>
<223>用于mcl2扩增的正向引物
<400>47
ccgcgttcagggcaagctgaaggaggaattcatgagcttccgccttcagcc51
<210>48
<211>20
<212>dna
<213>人工序列
<220>
<223>用于mcl2扩增的反向引物
<400>48
tcaggccgagatcatttctg20
<210>49
<211>51
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的正向引物
<400>49
ttgttgagacacttacacgaaggaggaattcatgtcgcttgcgcacggccg51
<210>50
<211>41
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的反向引物
<400>50
tcatccgccaaaacagccaagtcaggccgccgcgccgaggc41
<210>51
<211>20
<212>dna
<213>人工序列
<220>
<223>用于smta扩增的正向引物
<400>51
ttgttgagacacttacacga20
<210>52
<211>20
<212>dna
<213>人工序列
<220>
<223>用于smta扩增的反向引物
<400>52
ctagataatcttacggctgc20
<210>53
<211>20
<212>dna
<213>人工序列
<220>
<223>用于smtb扩增的正向引物
<400>53
gcagccgtaagattatctag20
<210>54
<211>20
<212>dna
<213>人工序列
<220>
<223>用于smtb扩增的反向引物
<400>54
ctaaatgacacgtttggaac20
<210>55
<211>52
<212>dna
<213>人工序列
<220>
<223>用于fold扩增的正向引物
<400>55
gtgaagtccaaggtaaactgaaggaggaattcatggcagcaaaattattaag52
<210>56
<211>40
<212>dna
<213>人工序列
<220>
<223>用于fold扩增的反向引物
<400>56
tcatccgccaaaacagccaagctataataagccgttttgc40
<210>57
<211>54
<212>dna
<213>人工序列
<220>
<223>用于pcka扩增的正向引物
<400>57
ttgttgagacacttacacgaaggaggaattcatgacagatcttaatcaattaac54
<210>58
<211>20
<212>dna
<213>人工序列
<220>
<223>用于pcka扩增的反向引物
<400>58
ttatgctttaggaccggcag20
<210>59
<211>51
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的正向引物
<400>59
ttgttgagacacttacacgaaggaggaattcatggactatatgtatggacc51
<210>60
<211>42
<212>dna
<213>人工序列
<220>
<223>用于sga扩增的反向引物
<400>60
tcatccgccaaaacagccaagttagattctagagggaatgag42
<210>61
<211>51
<212>dna
<213>人工序列
<220>
<223>用于pfl扩增的正向引物
<400>61
agaacgtcgtcgaggcgtaaaggaggaattcatgacgaatcgtatctctcg51
<210>62
<211>20
<212>dna
<213>人工序列
<220>
<223>用于pfl扩增的反向引物
<400>62
ttacagctgatgcgctgtcc20
<210>63
<211>4500
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>63
atggcacaacagactcctttgtacgaacaacacacgctttgcggcgctcgcatggtggat60
ttccacggctggatgatgccgctgcattacggttcgcaaatcgacgaacatcatgcggta120
cgtaccgatgccggaatgtttgatgtgtcacatatgaccatcgtcgatcttcgcggcagc180
cgcacccgggagtttctgcgttatctgctggcgaacgatgtggcgaagctcaccaaaagc240
ggcaaagccctttactcggggatgttgaatgcctctggcggtgtgatagatgacctcatc300
gtctactactttactgaagatttcttccgcctcgttgttaactccgccacccgcgaaaaa360
gacctctcctggattacccaacacgctgaacctttcggcatcgaaattaccgttcgtgat420
gacctttccatgattgccgtgcaagggccgaatgcgcaggcaaaagctgccacactgttt480
aatgacgcccagcgtcaggcggtggaagggatgaaaccgttctttggcgtgcaggcgggc540
gatctgtttattgccaccactggttataccggtgaagcgggctatgaaattgcgctgccc600
aatgaaaaagcggccgatttctggcgtgcgctggtggaagcgggtgttaagccatgtggc660
ttgggcgcgcgtgacacgctgcgtctggaagcgggcatgaatctttatggtcaggagatg720
gacgaaaccatctctcctttagccgccaacatgggctggaccatcgcctgggaaccggca780
gatcgtgactttatcggtcgtgaagccctggaagtgcagcgtgagcatggtacagaaaaa840
ctggttggtctggtgatgaccgaaaaaggcgtgctgcgtaatgaactgccggtacgcttt900
accgatgcgcagggcaaccagcatgaaggcattatcaccagcggtactttctccccgacg960
ctgggttacagcattgcgctggcgcgcgtgccggaaggtattggcgaaacggcgattgtg1020
caaattcgcaaccgtgaaatgccggttaaagtgacaaaacctgtttttgtgcgtaacggc1080
aaagccgtcgcgtgatttacttttttggagattgattgatgagcaacgtaccagcagaac1140
tgaaatacagcaaagaacacgaatggctgcgtaaagaagccgacggcacttacaccgttg1200
gtattaccgaacatgctcaggagctgttaggcgatatggtgtttgttgacctgccggaag1260
tgggcgcaacggttagcgcgggcgatgactgcgcggttgccgaatcggtaaaagcggcgt1320
cagacatttatgcgccagtaagcggtgaaatcgtggcggtaaacgacgcactgagcgatt1380
ccccggaactggtgaacagcgaaccgtatgcaggcggctggatctttaaaatcaaagcca1440
gcgatgaaagcgaactggaatcactgctggatgcgaccgcatacgaagcattgttagaag1500
acgagtaacggctttattcctcttctgcgggagaggatcagggtgaggaaaatttatgcc1560
tcaccctcactctcttcgtaaggagagaggttcacaattcactgcacgtttcaggaacca1620
tcgctcatgacacagacgttaagccagcttgaaaacagcggcgcttttattgaacgccat1680
atcggaccggacgccgcgcaacagcaagaaatgctgaatgccgttggtgcacaatcgtta1740
aacgcgctgaccggccagattgtgccgaaagatattcaacttgcgacaccaccgcaggtt1800
ggcgcaccggcgaccgaatacgccgcactggcagaactcaaggctattgccagtcgcaat1860
aaacgcttcacgtcttacatcggcatgggttacaccgccgtgcagctaccgccggttatc1920
ctgcgtaacatgctggaaaatccgggctggtataccgcgtacactccgtatcaacctgaa1980
gtctcccagggccgccttgaagcactgctcaacttccagcaggtaacgctggatttgact2040
ggactggatatggcctctgcttctcttctggacgaggccaccgctgccgccgaagcaatg2100
gcgatggcgaaacgcgtcagcaaactgaaaaatgccaaccgcttcttcgtggcttccgat2160
gtgcatccgcaaacgctggatgtggtccgtactcgtgccgaaacctttggttttgaagtg2220
attgtcgatgacgcgcaaaaagtgctcgaccatcaggacgtcttcggcgtgctgttacag2280
caggtaggcactaccggtgaaattcacgactacactgcgcttattagcgaactgaaatca2340
cgcaaaattgtggtcagcgttgccgccgatattatggcgctggtgctgttaactgcgccg2400
ggtaaacagggcgcggatattgtttttggttcggcgcaacgcttcggcgtgccgatgggc2460
tacggtggcccacacgcggcattctttgcggcgaaagatgaatacaaacgctcaatgccg2520
ggccgtattatcggtgtatcgaaagatgcagctggcaataccgcgctgcgcatggcgatg2580
cagactcgcgagcaacatatccgccgtgagaaagcgaactccaacatttgtacttcccag2640
gtactgctggcaaacatcgccagcctgtatgccgtttatcacggcccggttggcctgaaa2700
cgtatcgctaaccgcattcaccgtctgaccgatatcctggcggcgggcctgcaacaaaaa2760
ggtctgaaactgcgccatgcgcactatttcgacaccttgtgtgtggaagtggccgacaaa2820
gcgggcgtactgacgcgtgccgaagcggctgaaatcaacctgcgtagcgatattctgaac2880
gcggttgggatcacccttgatgaaacaaccacgcgtgaaaacgtaatgcagcttttcaac2940
gtgctgctgggcgataaccacggcctggacatcgacacgctggacaaagacgtggctcac3000
gacagccgctctatccagcctgcgatgctgcgcgacgacgaaatcctcacccatccggtg3060
tttaatcgctaccacagcgaaaccgaaatgatgcgctatatgcactcgctggagcgtaaa3120
gatctggcgctgaatcaggcgatgatcccgctgggttcctgcaccatgaaactgaacgcc3180
gccgccgagatgatcccaatcacctggccggaatttgccgaactgcacccgttctgcccg3240
ccggagcaggccgaaggttatcagcagatgattgcgcagctggctgactggctggtgaaa3300
ctgaccggttacgacgccgtttgtatgcagccgaactctggcgcacagggcgaatacgcg3360
ggcctgctggcgattcgtcattatcatgaaagccgcaacgaagggcatcgcgatatctgc3420
ctgatcccggcttctgcgcacggaactaaccccgcttctgcacatatggcaggaatgcag3480
gtggtggttgtggcgtgtgataaaaacggcaacatcgatctgactgatctgcgcgcgaaa3540
gcggaacaggcgggcgataacctctcctgtatcatggtgacttatccttctacccacggc3600
gtgtatgaagaaacgatccgtgaagtgtgtgaagtcgtgcatcagttcggcggtcaggtt3660
taccttgatggcgcgaacatgaacgcccaggttggcatcacctcgccgggctttattggt3720
gcggacgtttcacaccttaacctacataaaactttctgcattccgcacggcggtggtggt3780
ccgggtatgggaccgatcggcgtgaaagcgcatttggcaccgtttgtaccgggtcatagc3840
gtggtgcaaatcgaaggcatgttaacccgtcagggcgcggtttctgcggcaccgttcggt3900
agcgcctctatcctgccaatcagctggatgtacatccgcatgatgggcgcagaagggctg3960
aaaaaagcaagccaggtggcaatcctcaacgccaactatattgccagccgcctgcaggat4020
gccttcccggtgctgtataccggtcgcgacggtcgcgtggcgcacgaatgtattctcgat4080
attcgcccgctgaaagaagaaaccggcatcagcgagctggatattgccaagcgcctgatc4140
gactacggtttccacgcgccgacgatgtcgttcccggtggcgggtacgctgatggttgaa4200
ccgactgaatctgaaagcaaagtggaactggatcgctttatcgacgcgatgctggctatc4260
cgcgcagaaattgaccaggtgaaagccggtgtctggccgctggaagataacccgctggtg4320
aacgcgccgcacattcagagcgaactggtcgccgagtgggcgcatccgtacagccgtgaa4380
gttgcggtattcccggcaggtgtggcagacaaatactggccgacagtgaaacgtctggat4440
gatgtttacggcgaccgtaacctgttctgctcctgcgtaccgattagcgaataccagtaa4500
<210>64
<211>52
<212>dna
<213>人工序列
<220>
<223>用于gcv扩增的正向引物
<400>64
ttgttgagacacttacacgaaggaggaattcatggcacaacagactcctttg52
<210>65
<211>42
<212>dna
<213>人工序列
<220>
<223>用于gcv扩增的反向引物
<400>65
tcatccgccaaaacagccaagttactggtattcgctaatcgg42
<210>66
<211>573
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>66
ttgacactgtcatcgcaacattatctggtgatcactgcgttgggtgccgatcgccctgga60
attgtgaacaccatcacccgtcatgtcagtagttgcggctgtaatattgaagacagtcgc120
ctggcgatgctgggagaagagttcacgtttattatgctgctttccggttcatggaatgcc180
attactctgattgaatcaacgttaccgttgaaaggtgccgaactggatcttttaatcgtg240
atgaagcgcacgacggcgcgtccgcgtccgccaatgccagcatctgtctgggttcaggtc300
gatgtggcagactccccgcatttaattgaacgcttcacagcacttttcgacgcgcatcat360
atgaacattgcggagctggtgtcgcgcacgcaacctgctgaaaatgaacgggctgcgcag420
ttgcatattcagataaccgcccacagccccgcatctgcggacgcagcaaatattgagcaa480
gcgttcaaagccctatgtacagaactcaatgcacaaggcagtattaacgtcgtcaattat540
tcccaacatgatgaacaggatggagttaagtaa573
<210>67
<211>1543
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>67
aaaatttctcctctgttgtttatttgatacccatcacactttcatctcccggttttttcg60
ccgggagattttcctcatttgaaataaactaatttcacctccgttttcgcattatatttt120
ctaatgccattattttttgatttagtgttttttgacatttttttagctcttaatattgtc180
ttattcaaattgactttctcatcacatcatctttgtatagaaactggtgtattttttggt240
tttttattctgtcgcgatttttgcattttttaaccataagctaatgtgatgatcaatttt300
accttatggttaacagtctgtttcggtggtaagttcaggcaaaagagaacgattgcgttg360
gggaccgggagtggctccgatgctgggtttcgtggtgataatttcaccatgaaaaagttg420
tcagccccgcttattcaatgaggacaagatggcacaacagactcctttgtacgaacaaca480
cacgctttgcggcgctcgcatggtggatttccacggctggatgatgccgctgcattacgg540
ttcgcaaatcgacgaacatcatgcggtacgtaccgatgccggaatgtttgatgtgtcaca600
tatgaccatcgtcgatcttcgcggcagccgcacccgggagtttctgcgttatctgctggc660
gaacgatgtggcgaagctcaccaaaagcggcaaagccctttactcggggatgttgaatgc720
ctctggcggtgtgatagatgacctcatcgtctactactttactgaagatttcttccgcct780
cgttgttaactccgccacccgcgaaaaagacctctcctggattacccaacacgctgaacc840
tttcggcatcgaaattaccgttcgtgatgacctttccatgattgccgtgcaagggccgaa900
tgcgcaggcaaaagctgccacactgtttaatgacgcccagcgtcaggcggtggaagggat960
gaaaccgttctttggcgtgcaggcgggcgatctgtttattgccaccactggttataccgg1020
tgaagcgggctatgaaattgcgctgcccaatgaaaaagcggccgatttctggcgtgcgct1080
ggtggaagcgggtgttaagccatgtggcttgggcgcgcgtgacacgctgcgtctggaagc1140
gggcatgaatctttatggtcaggagatggacgaaaccatctctcctttagccgccaacat1200
gggctggaccatcgcctgggaaccggcagatcgtgactttatcggtcgtgaagccctgga1260
agtgcagcgtgagcatggtacagaaaaactggttggtctggtgatgaccgaaaaaggcgt1320
gctgcgtaatgaactgccggtacgctttaccgatgcgcagggcaaccagcatgaaggcat1380
tatcaccagcggtactttctccccgacgctgggttacagcattgcgctggcgcgcgtgcc1440
ggaaggtattggcgaaacggcgattgtgcaaattcgcaaccgtgaaatgccggttaaagt1500
gacaaaacctgtttttgtgcgtaacggcaaagccgtcgcgtga1543
<210>68
<211>1503
<212>dna
<213>人工序列
<220>
<223>来自seqidno.67的启动子替代
<400>68
cccatcagatccactagtggcctatgcggccgcggatctgccggtctccctatagtgaga60
tctggcacgacaggtttcccgactggaaagcgggcagtgagcgcaacgcaattaatgtga120
gttagcgcgaattgatctggtttgacagcttatcatcgactgcacggtgcaccaatgctt180
ctggcgtcaggcagccatcggaagctgtggtatggctgtgcaggtcgtaaatcactgcat240
aattcgtgtcgctcaaggcgcactcccgttctggataatgttttttgcgccgacatcata300
acggttctggcaaatattctgaaatgagctgttgacaattaatcatccggctcgtataat360
gtgtggaattgtgagcggataacaatttcacacaggaaacagaccatgatggcacaacag420
actcctttgtacgaacaacacacgctttgcggcgctcgcatggtggatttccacggctgg480
atgatgccgctgcattacggttcgcaaatcgacgaacatcatgcggtacgtaccgatgcc540
ggaatgtttgatgtgtcacatatgaccatcgtcgatcttcgcggcagccgcacccgggag600
tttctgcgttatctgctggcgaacgatgtggcgaagctcaccaaaagcggcaaagccctt660
tactcggggatgttgaatgcctctggcggtgtgatagatgacctcatcgtctactacttt720
actgaagatttcttccgcctcgttgttaactccgccacccgcgaaaaagacctctcctgg780
attacccaacacgctgaacctttcggcatcgaaattaccgttcgtgatgacctttccatg840
attgccgtgcaagggccgaatgcgcaggcaaaagctgccacactgtttaatgacgcccag900
cgtcaggcggtggaagggatgaaaccgttctttggcgtgcaggcgggcgatctgtttatt960
gccaccactggttataccggtgaagcgggctatgaaattgcgctgcccaatgaaaaagcg1020
gccgatttctggcgtgcgctggtggaagcgggtgttaagccatgtggcttgggcgcgcgt1080
gacacgctgcgtctggaagcgggcatgaatctttatggtcaggagatggacgaaaccatc1140
tctcctttagccgccaacatgggctggaccatcgcctgggaaccggcagatcgtgacttt1200
atcggtcgtgaagccctggaagtgcagcgtgagcatggtacagaaaaactggttggtctg1260
gtgatgaccgaaaaaggcgtgctgcgtaatgaactgccggtacgctttaccgatgcgcag1320
ggcaaccagcatgaaggcattatcaccagcggtactttctccccgacgctgggttacagc1380
attgcgctggcgcgcgtgccggaaggtattggcgaaacggcgattgtgcaaattcgcaac1440
cgtgaaatgccggttaaagtgacaaaacctgtttttgtgcgtaacggcaaagccgtcgcg1500
tga1503
<210>69
<211>1365
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>69
atgattagtctattcgacatgtttaaggtggggattggtccctcatcttcccataccgta60
gggcctatgaaggcaggtaaacagttcgtcgatgatctggtcgaaaaaggcttactggat120
agcgttactcgcgttgccgtggacgtttatggttcactgtcgctgacgggtaaaggccac180
cacaccgatatcgccattattatgggtcttgcaggtaacgaacctgccaccgtggatatc240
gacagtattcccggttttattcgcgacgtagaagagcgcgaacgtctgctgctggcacag300
ggacggcatgaagtggatttcccgcgcgacaacgggatgcgttttcataacggcaacctg360
ccgctgcatgaaaacggtatgcaaatccacgcctataacggcgatgaagtcgtctacagc420
aaaacttattattccatcggcggcggttttatcgtcgatgaagaacactttggtcaggat480
gctgccaacgaagtaagcgtgccgtatccgttcaaatctgccaccgaactgctcgcgtac540
tgtaatgaaaccggctattcgctgtctggtctcgctatgcagaacgaactggcgctgcac600
agcaagaaagagatcgacgagtatttcgcgcatgtctggcaaaccatgcaggcatgtatc660
gatcgcgggatgaacaccgaaggtgtactgccaggcccgctgcgcgtgccacgtcgtgcg720
tctgccctgcgccggatgctggtttccagcgataaactgtctaacgatccgatgaatgtc780
attgactgggtaaacatgtttgcgctggcagttaacgaagaaaacgccgccggtggtcgt840
gtggtaactgcgccaaccaacggtgcctgcggtatcgttccggcagtgctggcttactat900
gaccactttattgaatcggtcagcccggacatctatacccgttactttatggcagcgggc960
gcgattggtgcattgtataaaatgaacgcctctatttccggtgcggaagttggttgccag1020
ggcgaagtgggtgttgcctgttcaatggctgctgcgggtcttgcagaactgctgggcggt1080
agcccggaacaggtttgcgtggcggcggaaattggcatggaacacaaccttggtttaacc1140
tgcgacccggttgcagggcaggttcaggtgccgtgcattgagcgtaatgccattgcctct1200
gtgaaggcgattaacgccgcgcggatggctctgcgccgcaccagtgcaccgcgcgtctcg1260
ctggataaggtcatcgaaacgatgtacgaaaccggtaaggacatgaacgccaaataccgc1320
gaaacctcacgcggtggtctggcaatcaaagtccagtgtgactaa1365
- 还没有人留言评论。精彩留言会获得点赞!