多核苷酸条形码生成的制作方法
交叉引用
本申请要求2013年2月8日提交的美国临时专利申请号61/762,435、2013年3月15日提交的美国临时专利申请号61/800,223、2013年6月27日提交的美国临时专利申请号61/840,403和2013年7月10日提交的美国临时专利申请号61/844,804的权益,所述申请为所有目的通过引用以其整体并入本文。
背景技术
多核苷酸条形码在包括下一代测序技术在内的大量应用中具有实用性。这样的条形码通常含有独特的标识符序列,后者在以充分的多样性和规模生产时可能是极其昂贵的。合成单多核苷酸条形码的成本是合成过程中每个碱基的成本和多核苷酸长度的函数。因此,合成多个各自具有不同序列的条形码的成本等于每个碱基的成本乘以每个分子的碱基数,再乘以该多个条形码内的分子数。当前,合成dna序列要花费每个碱基约0.10美元。对于包含上万个至数百万个条形码的条形码文库,该成本太过高昂。因此,非常需要改善的生成条形码文库的方法。
技术实现要素:
本公开内容提供了用于生成多核苷酸条形码的方法、组合物、系统和试剂盒以及这类多核苷酸条形码的用途。这类多核苷酸条形码可以用于任何合适的应用。
本公开内容的一个方面提供了包含一个或多个多核苷酸的文库,每个多核苷酸包含条形码序列,其中该多核苷酸布置在一个或多个分区内,并且其中该文库包含至少约1,000个不同的条形码序列。
在一些情况下,所述条形码序列是至少约5个核苷酸的长度。另外,该条形码序列可以是随机的多核苷酸序列。
而且,所述分区可以平均包含约1个多核苷酸、约0.5个多核苷酸或约0.1个多核苷酸。所述分区可以是小滴、胶囊、孔或珠子。
另外,所述文库可以包含至少约10,000个不同的条形码序列、至少约100,000个不同的条形码序列、至少约500,000个不同的条形码序列、至少约1,000,000个不同的条形码序列、至少约2,500,00个不同的条形码序列、至少约5,000,000个不同的条形码序列、至少约10,000,000个、至少约25,000,000个、至少约50,000,000个或至少约100,000,000个不同的条形码序列。
在一些情况下,所述分区可以包含相同多核苷酸的多个拷贝。
另外,所述多核苷酸中的每一个可以包含选自固定序列、针对测序引物的退火序列和对于与靶多核苷酸的连接相容的序列的序列。
在一些情况下,所述多核苷酸中的每一个是malbac引物。
本公开内容的另一方面提供了合成包含条形码序列的多核苷酸的文库的方法,该方法包括;a)合成多个包含条形码序列的多核苷酸;b)将该多核苷酸分隔至多个分区内,从而生成分区的多核苷酸;c)扩增该分区的多核苷酸,从而生成扩增的多核苷酸;以及d)分离包含该扩增的多核苷酸的分区。在一些情况下,所述合成包括在偶联反应中包括腺嘌呤、胸腺嘧啶、鸟嘌呤和胞嘧啶的混合物。
而且,所述分隔可以包括进行有限稀释,从而生成稀释的多核苷酸。在一些情况下,所述分隔进一步包括对所述稀释的多核苷酸进行分区。
另外,所述扩增可以通过选自聚合酶链反应、不对称聚合酶链反应、乳液pcr(epcr)、包括使用珠子的epcr、包括使用水凝胶的epcr、基于退火和成环的多重扩增循环(malbac)、单引物等温扩增及其组合的方法来进行。在一些情况下,所述扩增使用rna引物来进行,并且可以包括将扩增的多核苷酸暴露于rna酶h。
在一些情况下,所述包含条形码序列的多核苷酸中的每一个是malbac引物。
在一些情况下,所述分离可以通过流动辅助的分选来进行。
另外,可以由多核苷酸形成发夹结构,该多核苷酸选自包含条形码序列的多核苷酸和扩增的多核苷酸。在一些情况下,方法可以进一步包括在未退火的区域内切割发夹结构。
而且,选自所述包含条形码序列的多核苷酸、所述分区的多核苷酸和所述扩增的多核苷酸的多核苷酸可以附接至珠子上。
所述方法可以进一步包括使扩增的多核苷酸与部分互补序列退火。所述部分互补序列可以包含条形码序列。
所述方法可以进一步包括将扩增的多核苷酸中的至少一个附接至靶序列。该靶序列可以被片段化。在一些情况下,该靶序列通过选自机械剪切和酶处理的方法被片段化。该机械剪切可以由超声诱导。在一些情况下,所述酶选自限制酶、片段化酶和转座酶。另外,所述附接可以通过选自连接和扩增的方法进行。
在一些情况下,所述扩增是用malbac引物进行的malbac扩增,从而生成malbac扩增产物。在一些情况下,所述malbac引物包含扩增的多核苷酸。在一些情况下,所述malbac引物包含不是所述扩增的多核苷酸的多核苷酸。在这样的情况下,所述方法可以进一步包括将malbac扩增产物附接至扩增的多核苷酸。
另外,每个分区可以平均包含约1个包含条形码序列的多核苷酸、0.5个包含条形码序列的多核苷酸或0.1个包含条形码序列的多核苷酸。而且,所述分区可以选自小滴、胶囊和孔。
在一些情况下,所述文库包含至少约1,000个不同的条形码序列、至少约10,000个不同的条形码序列、至少约100,000个不同的条形码序列、至少约500,000个不同的条形码序列、至少约1,000,000个不同的条形码序列、至少约2,500,00个不同的条形码序列、至少约5,000,000个不同的条形码序列、至少约10,000,000个、至少约25,000,000个、至少约50,000,000个或至少约100,000,000个不同的条形码序列。
在一些情况下,所述分区包含相同的包含条形码序列的多核苷酸的多个拷贝。
而且,所述包含条形码序列的多核苷酸可以包含选自固定序列、针对测序引物的退火序列和对于与靶多核苷酸的连接相容的序列的序列。
本公开内容的另一方面提供了一种包含至少约1,000个珠子的文库,其中所述至少约1,000个珠子中的每个珠子包含不同的条形码序列。在一些情况下,所述不同的条形码序列可以包括在包含固定序列和/或针对测序引物的退火序列的多核苷酸中。在一些情况下,所述不同的条形码序列可以是至少约5个核苷酸或至少约10个核苷酸的长度。在一些情况下,所述不同的条形码序列可以是随机多核苷酸序列或者可以组合地生成。
而且,所述1,000个珠子中的每一个可以包含不同条形码序列的多个拷贝。例如,所述1,000个珠子中的每一个可以包含不同条形码序列的至少约100,000个、至少约1,000,000个或至少约10,000,000个拷贝。在一些情况下,所述文库可以进一步包含两个或更多个包含相同条形码序列的珠子。在一些情况下,所述1,000个珠子中的至少两个珠子可以包含相同的条形码序列。此外,所述至少约1,000个珠子包含至少约10,000个或至少约100,000个珠子。
另外,所述文库可以包含至少约1,000个、至少约10,000个、至少约100,000个、至少约1,000,000个、至少约2,500,000个、至少约5,000,000个、至少约10,000,000个、至少约25,000,000个、至少约50,000,000个或至少约100,000,000个不同的条形码序列。
在一些情况下,所述至少约1,000个珠子可以跨多个分区分布。在一些情况下,所述分区可以是乳液的小滴。在一些情况下,所述1,000个珠子中的每一个珠子可以包括在不同的分区中。在一些情况下,所述不同的分区可以是乳液的小滴。在一些情况下,所述1,000个珠子中的两个或更多个珠子可以包括在不同的分区中。在一些情况下,所述不同的分区可以是乳液的小滴。在一些情况下,所述1,000个珠子可以是水凝胶珠子。
本公开内容的另一方面提供了本文描述的文库、组合物、方法、装置或试剂盒在对物质进行分区、对寡核苷酸进行分区、物质从分区中的刺激选择性释放、在分区中进行反应(例如,连接和扩增反应)、进行核酸合成反应、对核酸进行条形码化、为测序准备多核苷酸、多核苷酸测序、突变检测、神经系统病症诊断、糖尿病诊断、胎儿非整倍性诊断、癌症突变检测和法医学、疾病检测、医学诊断、低输入核酸应用、循环肿瘤细胞(ctc)测序、多核苷酸取相、从少量细胞对多核苷酸进行测序、分析基因表达、从细胞对多核苷酸进行分区或其组合中的用途。
援引并入
在本说明书中提到的所有出版物、专利和专利申请均为所有目的通过引用而并入本文,其程度如同具体地和单独地指出各个单独的出版物、专利或专利申请通过引用而并入。
附图说明
本公开内容的方法、组合物、系统和装置的新特征在所附的权利要求中具体阐述。通过参考以下对其中利用了本发明方法、组合物、系统和装置的原理的说明性实施方案加以阐述的详细描述和附图,将会获得对本公开内容的特征和优点的更好的理解,附图中:
图1示意性地描绘了示例性叉状衔接子。
图2示意性地描绘了条形码区域的示例性布置。
图3描绘了连接至靶多核苷酸的相对末端的两个叉状衔接子的示例性序列。
图4是用于产生实施例1中描述的叉状衔接子的示意性示例方法。
图5是实施例2中描述的在胶囊内的胶囊的示意性示例。
图6是实施例3中描述的在胶囊内的胶囊的示意性示例。
图7是可根据实施例4的方法产生的产物(或中间体)的示意性示例。
图8a-c描绘了实施例4中描述的示例性序列。
图9a-j描绘了实施例5中描述的示例性序列。
图10a-e描绘了实施例6中描述的示例性序列。
图11a-d示意性地描绘了实施例7中描述的方法和结构。
图12示意性地描绘了通过示例性流动聚焦方法产生胶囊。
图13示意性地描绘了通过示例性流动聚焦方法产生在胶囊内的胶囊。
图14a-e示意性地描绘了实施例8中描述的方法和结构。
图15a-e示意性地描绘了实施例9中描述的方法和结构。
图16示意性地描绘了实施例10中描述的方法和结构。
图17示意性地描绘了实施例11中描述的在胶囊内的胶囊。
图18示意性地描绘了实施例12中描述的在胶囊内的胶囊。
图19a-e描绘了实施例13中描述的示例性序列。图19f描绘了实施例13中描述的示例性方法和结构。
图20示意性地描绘了实施例14中描述的在胶囊内的胶囊。
图21a-c示意性地描绘了实施例15中描述的方法和结构。
图22示意性地描绘了实施例16中描述的在胶囊内的胶囊。
图23示意性地描绘了实施例17中描述的在胶囊内的胶囊。
具体实施方式
虽然本文已经显示并描述了本发明的多种实施方案,但是对本领域技术人员来说显而易见的是,这些实施方案仅通过举例的方式来提供。本领域技术人员在不背离本发明的情况下可以想到许多变化、改变和替换。应当理解,可以采用本文所述的本发明实施方案的各种替代方案。
本公开内容提供了用于生成多核苷酸条形码的方法、组合物、系统和试剂盒以及这类多核苷酸条形码的用途。这类多核苷酸条形码可以用于任何合适的应用。在一些情况下,本公开内容中提供的多核苷酸条形码可以在下一代测序反应中使用。下一代测序反应包括全基因组的测序、特定序列如单核苷酸多态性(snp)和其他突变的检测、核酸(例如脱氧核糖核酸)插入的检测和核酸缺失的检测。
除非另有说明,否则本文描述的方法、组合物、系统和试剂盒的应用可以结合有机化学、聚合物技术、微流体、分子生物学、重组技术、细胞生物学、生物化学和免疫学的任何常规技术。这样的常规技术包括孔和微孔构建、胶囊生成、乳液生成、点印、微流体装置构建、聚合物化学、限制性消化、连接、克隆、多核苷酸测序和多核苷酸序列装配。合适的技术的具体的、非限制性的说明在本公开内容通篇描述。然而,也可以使用等同的程序。对某些技术的描述可见于标准实验室手册,如genomeanalysis:alaboratorymanualseries(第i-iv卷),usingantibodies:alaboratorymanual,cells:alaboratorymanual,pcrprimer:alaboratorymanual,和molecularcloning:alaboratorymanual(均来自coldspringharborlaboratorypress),和“oligonucleotidesynthesis:apracticalapproach”1984,irlpresslondon,全部为了所有目的而通过引用以其整体并入本文。
i.定义
本文所用的术语仅仅是为了描述具体实施方案的目的,而并非旨在限制。
如本文使用的,单数形式“一个”、“一种”和“该”也意图包括复数形式,除非上下文明确指出不是这样。此外,就术语“包括”、“含有”、“具有”、“有”、“带有”、“如”或其变化形式在说明书和/或权利要求中的使用来说,这些术语并非限制性的,且旨在以类似于术语“包含”的方式包含在内。
如本文所用的术语“约”通常是指在特定应用的背景中比指定数值大或小15%的范围。例如,约10将包括从8.5到11.5的范围。
如本文所用的术语“条形码”通常是指可以附接至分析物以传递关于该分析物的信息的标记。例如,条形码可以是附接至在特定分区内包含的靶多核苷酸的片段上的多核苷酸序列。该条形码然后可以用靶多核苷酸的片段进行测序。多个序列上相同条形码的存在可以提供关于该序列的起源的信息。例如,条形码可以指示序列来自于特定分区和/或基因组的邻近区域。这尤其可以用于在测序前合并数个分区时的序列装配。
如本文使用的,术语“bp”通常是指“碱基对”的缩写。
如本文使用的,术语“微孔”通常是指容积小于1ml的孔。根据应用,微孔可以制成多种容积。例如,微孔可以制成适合容纳本文描述的任何分区体积的大小。
如本文使用的,术语“分区”可以是动词或名词。当用作动词(例如,“进行分区”)时,该术语通常是指物质或样品(例如,多核苷酸)在可用来将一个级分(或子部分)与另一个隔离开的容器之间的分级(例如,细分)。使用名词“分区”提及这样的容器。例如,可以使用微流体、稀释、分配等进行分区。分区可以是,例如,孔、微孔、孔洞、小滴(例如,乳液中的小滴)、乳液的连续相、试管、斑点、胶囊、珠子、稀溶液中的珠子的表面,或任何其他用于将样品的一个级分与另一个级分隔离开的合适的容器。分区也可以包含另一个分区。
如本文使用的,术语“多核苷酸”或“核酸”通常是指包含多个核苷酸的分子。示例性的多核苷酸包括脱氧核糖核酸、核糖核酸及其合成类似物,包括肽核酸。
如本文使用的,术语“物质”通常是指能够与本公开内容的方法、组合物、系统、装置和试剂盒一起使用的任何物质。物质的实例包括试剂、分析物、细胞、染色体、标记分子或成组分子、条形码和包含任何这样的物质的任何样品。可以使用任何合适的物质,如在本公开内容中的其他部分更加充分讨论的。
ii.多核苷酸条形码化
某些应用,例如多核苷酸测序,可以依赖于独特的标识符(“条形码”)来鉴定序列的起源,以及,例如,从经测序的片段装配较大的序列。因此,可能希望在测序前向多核苷酸片段上添加条形码。条形码可以是多种不同的形式,包括多核苷酸条形码。根据具体应用,条形码可以以可逆或不可逆的方式附接至多核苷酸片段上。另外,条形码可以允许在测序过程中对单个多核苷酸片段进行鉴别和/或量化。
可以将条形码加载至分区中以使得向特定分区中引入一个或多个条形码。在一些情况下,每个分区可以含有不同组的条形码。这可以通过将条形码直接分配至分区中,或者通过将条形码置于在另一分区内包含的分区中来完成。
可以以预期的或预测的每个待条形码化的物质(例如,多核苷酸片段、多核苷酸链、细胞等)上的条形码的比例,将条形码加载到分区内。在一些情况下,将条形码加载到分区内,以使得每个物质加载约0.0001、0.001、0.1、1、2、3、4、5、6、7、8、9、10、20、50、100、500、1000、5000、10000或200000个条形码。在一些情况下,将条形码加载到分区内,以使得每个物质加载多于约0.0001、0.001、0.1、1、2、3、4、5、6、7、8、9、10、20、50、100、500、1000、5000、10000或200000个条形码。在一些情况下,将条形码加载到分区内,以使得每个物质加载少于约0.0001、0.001、0.1、1、2、3、4、5、6、7、8、9、10、20、50、100、500、1000、5000、10000或200000个条形码。
当每个多核苷酸片段存在多于一个条形码时,这样的条形码可以是相同条形码的拷贝,或者可以是不同的条形码。例如,可将附接过程设计成将多个相同的条形码附接至单个多核苷酸片段上,或将多个不同的条形码附接至该多核苷酸片段上。
本文所提供的方法可以包括向分区中加载对于条形码与多核苷酸片段的附接而言所必需的试剂。在连接反应的情况下,可以将包括限制酶、连接酶、缓冲液、衔接子、条形码等的试剂加载到分区中。在通过扩增进行条形码化的情况下,可以将包括引物、dna聚合酶、dntp、缓冲液、条形码等的试剂加载到分区中。在转座子介导的条形码化(例如nextera)的情况下,可以将包括转座体(即,转座酶和转座子末端复合物)、缓冲液等的试剂加载到分区中。在malbac介导的条形码化的情况下,可以将包括malbac引物、缓冲液等的试剂加载到分区中。如本公开内容通篇所描述的,这些试剂可以直接地或经由另一分区加载到分区内。
条形码可以利用粘端或平端连接至多核苷酸片段。条形码化的多核苷酸片段也可以通过用包含条形码的引物扩增多核苷酸片段而生成。在一些情况下,多核苷酸片段的malbac扩增可以用来生成条形码化的多核苷酸片段。用于malbac的引物可以包含或者可以不包含条形码。在malbac引物不包含条形码的情况下,可以通过其他扩增方法如pcr将条形码添加至malbac扩增产物上。条形码化的多核苷酸片段也可以使用转座子介导的方法生成。对于本公开内容讨论的任何其他物质,根据测定或过程的需要,这些模块可以包含在相同或不同的分区内。
在一些情况下,条形码可以从设计用于以模块形式装配的较小组分组合地装配。例如,1a、1b和1c这三个模块可以组合地装配以产生条形码1abc。这样的组合装配可以显著地降低合成多个条形码的成本。例如,由3个a模块、3个b模块和3个c模块组成的组合系统可以仅从9个模块生成3*3*3=27个可能的条形码序列。
在一些情况下,如本公开内容的其他部分进一步描述的,可以通过混合两种寡核苷酸并使其杂交以产生退火的或部分退火的寡核苷酸(例如,叉状衔接子)而组合地装配条形码。这些条形码可以包含一种或多种核苷酸的突出端,以利于与待条形码化的多核苷酸片段的连接。在一些情况下,反义链的5'端可以被磷酸化以便确保双链连接。使用这种方法,可以通过例如混合寡核苷酸a和b、a和c、a和d、b和c、b和d等来装配不同的模块。如本公开内容的其他部分更详细描述的,退火的寡核苷酸也可以合成为具有发夹环的单分子,该发夹环可以在连接至待条形码化的多核苷酸后切割。
如本公开内容的其他部分更详细描述的,多核苷酸彼此之间的附接可以依赖于杂交相容的突出端。例如,a与t之间的杂交通常用来确保片段之间的连接相容性。在一些情况下,a突出端可以通过用酶如taq聚合酶处理来产生。在一些情况下,可以使用限制酶产生具有单碱基3'突出端的切割产物,该突出端可以是例如a或t。留下单碱基3'突出端的限制酶的实例包括mnii、hphi、hpy188i、hpyav、hpych4iii、mboii、bcivi、bmri、ahdi和xcmi。在其他情况下,可以用限制酶生成不同的突出端(例如,5'突出端、大于单碱基的突出端)。可以用来生成突出端的限制酶包括bfucl、taqαi、bbvi、bccl、bceal、bcodi、bsmai和bsmfi。
iii.分区的条形码文库的生成
在一些情况下,本公开内容提供了生成分区的条形码文库的方法以及按照这样的方法产生的文库。在一些情况下,本文提供的方法结合dna序列的随机合成、分隔成分区、分隔的序列的扩增,以及扩增的分隔的序列的分离以提供包含在分区内的条形码的文库。
a.多核苷酸条形码的随机合成
在一些情况下,本文描述的方法利用多核苷酸合成的随机方法,包括dna合成的随机方法。在随机dna合成过程中,可以将a、c、g和/或t的任意组合添加到偶联步骤中,以使得该偶联步骤中每种类型的碱基偶联至产物的子集。如果a、c、g和t以相等的浓度存在,则大约四分之一的产物将掺入每种碱基。连续的偶联步骤,以及偶联反应的随机性质,使得能够生成4n个可能的序列,其中n是多核苷酸中碱基的数目。例如,长度为6的随机多核苷酸的文库可具有46=4,096个成员的多样性,而长度为10的文库将具有1,048,576个成员的多样性。因此,能够生成非常大且复杂的文库。这些随机序列可以充当条形码。
任何合适的合成碱基也可以与本发明一起使用。在一些情况下,可以改变每个偶联步骤中包括的碱基以便合成优选的产物。例如,在每个偶联步骤中存在的碱基数目可以是1、2、3、4、5、6、7、8、9、10或更多。在一些情况下,在每个偶联步骤中存在的碱基数目可以是至少1、2、3、4、5、6、7、8、9、10或更多。在一些情况下,在每个偶联步骤中存在的碱基数目可以少于2、3、4、5、6、7、8、9或10。
也可以改变单个碱基的浓度以便合成优选的产物。例如,任何碱基可以以另一碱基的浓度的约0.1、0.5、1、5或10倍的浓度存在。在一些情况下,任何碱基可以以另一碱基的浓度的至少约0.1、0.5、1、5或10倍的浓度存在。在一些情况下,任何碱基可以以另一碱基的浓度的低于约0.1、0.5、1、5或10倍的浓度存在。
根据应用,随机多核苷酸序列的长度可以是任何合适的长度。在一些情况下,随机多核苷酸序列的长度可以是4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20个或更多个核苷酸。在一些情况下,随机多核苷酸序列的长度可以是至少4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20个或更多个核苷酸。在一些情况下,随机多核苷酸序列的长度可以少于4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个核苷酸。
在一些情况下,所述文库由成员的数目来定义。在一些情况下,文库可以包含约256、1024、4096、16384、65536、262144、1048576、4194304、16777216、67108864、268435456、1073741824、4294967296、17179869184、68719476736、2.74878*1011或1.09951*1012个成员。在一些情况下,文库可以包含至少约256、1024、4096、16384、65536、262144、1048576、4194304、16777216、67108864、268435456、1073741824、4294967296、17179869184、68719476736、2.74878*1011或1.09951*1012个成员。在一些情况下,文库可以包含少于约256、1024、4096、16384、65536、262144、1048576、4194304、16777216、67108864、268435456、1073741824、4294967296、17179869184、68719476736、2.74878*1011或1.09951*1012个成员。在一些情况下,该文库是条形码文库。在一些情况下,条形码文库可以包含至少约1000、10000、100000、1000000、2500000、5000000、10000000、25000000、50000000或100000000个不同的条形码序列。
随机条形码文库还可以包含其他多核苷酸序列。在一些情况下,这些其他多核苷酸序列在性质上是非随机的,并且包括例如引物结合位点、用于生成叉状衔接子的退火位点、固定序列,和能够与靶多核苷酸序列退火,因而能够对多核苷酸序列进行条形码化的区域。
b.多核苷酸向分区内的分隔
在包含随机条形码序列的多核苷酸合成后,将多核苷酸分区到单独的区室中以生成包含条形码序列的分区的多核苷酸的文库。可以使用任何合适的分隔方法和任何合适的分区或分区内的分区。
在一些情况下,通过稀释包含随机条形码序列的多核苷酸的混合物以使得特定体积的该稀释液平均含有少于一个多核苷酸来进行分区。然后可以将该特定体积的稀释液转移至分区。在任何多个分区中,每个分区因此有可能具有一个或零个多核苷酸分子。
在一些情况下,可以进行稀释以使得每个分区包含约0.001、0.01、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1、2个或更多个分子。在一些情况下,可以进行稀释以使得每个分区包含至少约0.001、0.01、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1、2个或更多个分子。在一些情况下,可以进行稀释以使得每个分区包含少于约0.001、0.01、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1或2个分子。
在一些情况下,约10%、20%、30%、40%、50%、60%、70%、80%或90%的分区包含指定数目的分子。在一些情况下,至少约10%、20%、30%、40%、50%、60%、70%、80%或90%的分区包含指定数目的分子。在一些情况下,少于约10%、20%、30%、40%、50%、60%、70%、80%或90%的分区包含指定数目的分子。
在一些情况下,约10%、20%、30%、40%、50%、60%、70%、80%或90%的分区包含一个或更少的多核苷酸。在一些情况下,至少约10%、20%、30%、40%、50%、60%、70%、80%或90%的分区包含一个或更少的多核苷酸。在一些情况下,少于约10%、20%、30%、40%、50%、60%、70%、80%或90%的分区包含一个或更少的多核苷酸。
在一些情况下,分区是孔、微孔、孔洞、小滴(例如,乳液中的小滴)、乳液的连续相、试管、斑点、胶囊、珠子的表面,或任何其他用于将样品的一个级分与另一个级分隔离的合适的容器。在分区包括珠子的情况下,用于扩增的引物可以附接至该珠子。分区在本公开内容的其他部分更详细地描述。
c.分区的多核苷酸的扩增
然后扩增如上所述分区的多核苷酸,以便生成对于靶多核苷酸序列的条形码化而言足够的材料。可以使用任何合适的扩增方法,包括聚合酶链反应(pcr)、连接酶链反应(lcr)、解旋酶依赖性扩增、指数后线性pcr(late-pcr)、不对称扩增、数字pcr、简并寡核苷酸引物pcr(dop-pcr)、引物延伸预扩增pcr(pep-pcr)、连接介导的pcr、滚环扩增、多重置换扩增(mda)和单引物等温扩增(spia)、乳液pcr(epcr)、包括使用珠子的epcr、包括使用水凝胶的epcr、基于退火和成环的多重扩增循环(malbac)及其组合。malbac方法描述于例如zong等人,science,338(6114),1622-1626(2012),其通过引用以其整体并入本文。
在一些情况下,例如,生成单链产物的扩增方法(例如,不对称扩增、spia和late-pcr)可能是优选的。在一些情况下,生成双链产物的扩增方法(例如,标准pcr)可能是优选的。在一些情况下,扩增方法将指数扩增分区的多核苷酸。在一些情况下,扩增方法将线性扩增分区的多核苷酸。在一些情况下,扩增方法将首先指数扩增然后线性扩增多核苷酸。而且,单一类型的扩增可以用来扩增多核苷酸,或者可以用不同类型的扩增的顺序步骤来完成扩增。例如,epcr可以与其他轮次的epcr组合,或者可以与不同类型的扩增组合。
进行扩增直到产生适量的包含条形码的多核苷酸。在一些情况下,可以进行扩增10、15、20、25、30、35、40、45、50、55、60个或更多个循环。在一些情况下,可以进行扩增至少10、15、20、25、30、35、40、45、50、55、60个或更多个循环。在一些情况下,可以进行扩增少于10、15、20、25、30、35、40、45、50、55或60个循环。
在一些情况下,可以进行扩增直到在每个分区中产生特定量的多核苷酸产物。在一些情况下,进行扩增直到多核苷酸产物的量为约10,000,000,000、5,000,000,000、1,000,000,000、500,000,000、100,000,000、50,000,000、10,000,000、5,000,000、1,000,000、500,000、400,000、300,000、200,000或100,000个分子。在一些情况下,进行扩增直到多核苷酸产物的量为至少约100,000、200,000、300,000、400,000、500,000、1,000,000、5,000,000、10,000,000、50,000,000、100,000,000、500,000,000、1,000,000,000、5,000,000,000或10,000,000,000个分子。在一些情况下,进行扩增直到多核苷酸产物的量少于约10,000,000,000、5,000,000,000、1,000,000,000、500,000,000、100,000,000、50,000,000、10,000,000、5,000,000、1,000,000、500,000、400,000、300,000、200,000或100,000个分子。
d.包含扩增的序列的分区的分离
如上所述,在一些情况下,对包含条形码的多核苷酸进行分区,以使得每个分区含有平均少于一个多核苷酸序列。因此,在一些情况下,分区的一部分将不含有多核苷酸,因此不能含有扩增的多核苷酸。因此,可能希望将包含多核苷酸的分区与不包含多核苷酸的分区分隔开。
在一种情况下,使用能够鉴别包含多核苷酸的分区的基于流动的分选方法,将包含多核苷酸的分区与不包含多核苷酸的分区分隔开。在一些情况下,可以使用多核苷酸的存在的指示物,以便区分包含多核苷酸的分区与不包含多核苷酸的分区。
在一些情况下,可以使用核酸染料来鉴别包含多核苷酸的分区。示例性的染料包括嵌入染料、小沟结合剂、大沟结合剂、外部结合物和双嵌入剂。这类染料的具体实例包括sybr绿、sybr蓝、dapi、碘化丙锭、sybr金、溴化乙锭、吖啶、原黄素、吖啶橙、吖啶黄素、荧光香豆素(fluorcoumanin)、玫瑰树碱、道诺霉素、氯喹、偏端霉素d、色霉素、二胺乙基苯菲啶(homidium)、光辉霉素、钌聚吡啶、氨茴霉素、菲啶和吖啶、溴化乙锭、碘化丙啶、碘化己锭、二氢乙锭、乙锭同型二聚体-1和-2、单叠氮乙锭、acma、吲哚、咪唑(例如、hoechst33258、hoechst33342、hoechst34580和dapi)、吖啶橙(也能够嵌入)、7-aad、放线菌素d、lds751、羟茋巴脒、sytox蓝、sytox绿、sytox橙、popo-1、popo-3、yoyo-1、yoyo-3、toto-1、toto-3、jojo-1、lolo-1、bobo-1、bobo-3、po-pro-1、po-pro-3、bo-pro-1、bo-pro-3、to-pro-1、to-pro-3、to-pro-5、jo-pro-1、lo-pro-1、yo-pro-1、yo-pro-3、picogreen、oligreen、ribogreen、sybr金、sybr绿i、sybr绿ii、sybrdx、syto-40、-41、-42、-43、-44、-45(蓝色)、syto-13、-16、-24、-21、-23、-12、-11、-20、-22、-15、-14、-25(绿色)、syto-81、-80、-82、-83、-84、-85(橙色)、syto-64、-17、-59、-61、-62、-60和-63(红色)。
在一些情况下,可以使用分离方法如颗粒的磁性分离或沉降。这样的方法可以包括,例如,将待扩增的多核苷酸、对应于所述待扩增的多核苷酸的引物和/或扩增的多核苷酸产物附接至珠子上的步骤。在一些情况下,待扩增的多核苷酸、对应于所述待扩增的多核苷酸的引物和/或多核苷酸产物向珠子上的附接可以经由对光不稳定的连接体例如pc氨基c6来进行。在使用对光不稳定的连接体的情况下,可以利用光来从珠子上释放连接的多核苷酸。该珠子可以是,例如,磁珠或胶乳珠子。珠子然后可允许通过例如磁性分选或沉降来分离。胶乳颗粒的沉降可以例如通过在比胶乳更稠的液体如甘油中离心来进行。在一些情况下,可以使用密度梯度离心。
珠子可以具有均匀的大小或不均匀的大小。在一些情况下,珠子的直径可以是约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm。珠子可以具有至少约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm的直径。在一些情况下,珠子可以具有小于约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm的直径。在一些情况下,珠子可以具有约0.001μm至1mm、0.01μm至900μm、0.1μm至600μm、100μm至200μm、100μm至300μm、100μm至400μm、100μm至500μm、100μm至600μm、20μm至50μm、150μm至200μm、150μm至300μm或150μm至400μm的直径。
在一些情况下,可以利用包含多核苷酸的分区与不包含多核苷酸的分区之间的差异电荷,例如通过对分区进行电泳或介电电泳来分离包含多核苷酸的分区。
在一些情况下,基于渗透压的差异,可以利用分区的选择性膨胀或收缩来鉴别包含多核苷酸的分区。在一些情况下,包含多核苷酸的分区可以通过流动分级分离、溶剂萃取、差别解链(例如,使用核酸探针)或冷冻来分离。
包含多核苷酸的分区的分离提供了具有显著多样性的分区的多核苷酸条形码的文库,同时仅导致一次批量合成的费用。
iv.包含条形码的衔接子的生成
在本公开内容中描述的条形码可以具有多种结构。在一些情况下,本公开内容的条形码是衔接子的一部分。通常,“衔接子”是用来使条形码能够附接到靶多核苷酸上的结构。衔接子可以包含,例如,条形码,对于与靶多核苷酸的连接相容的多核苷酸序列,和功能序列如引物结合位点和固定区域。
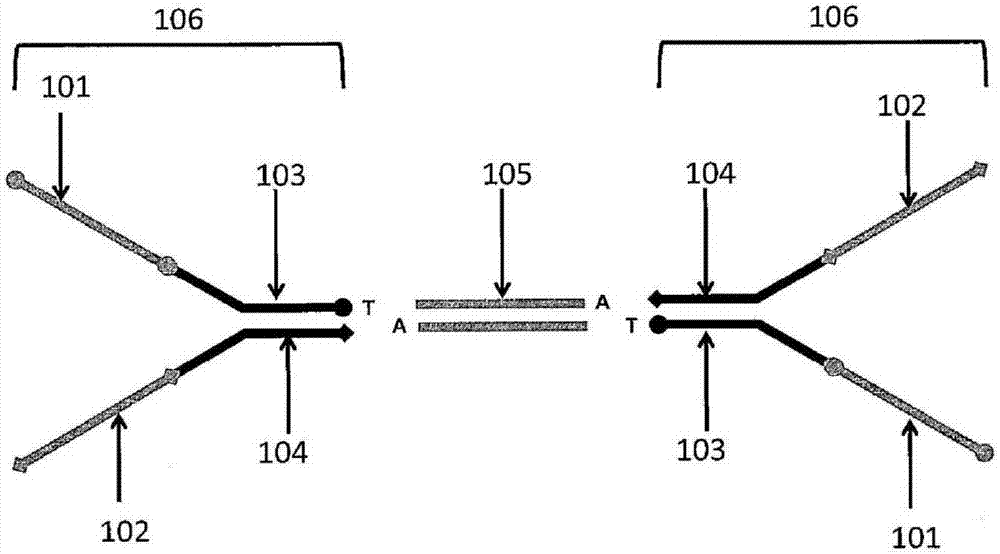
在一些情况下,衔接子是叉状衔接子。在图1中以图形方式示出了叉状衔接子的一个实例。参照图1,在靶多核苷酸105的相对侧上示出了两个拷贝的叉状衔接子结构106。每个叉状衔接子包含第一固定区域101、第二固定区域102、第一测序引物区域103、第二测序引物区域104和彼此退火的一对部分互补的区域(在103和104内)。测序引物区域或固定区域可以用来将条形码化的多核苷酸固定到例如珠子的表面上。测序引物区域可以用作例如测序引物的退火位点。在一些情况下,可以设计突出端以便能够与靶序列相匹配。在图1中,这对退火的多核苷酸103和104具有3'-t突出端,该突出端与靶多核苷酸105上的3'-a突出端相匹配。条形码可以包括在叉状衔接子的任何合适的部分中。在包含条形码的叉状衔接子与靶序列105附接后,测序引物区域103和104能够用来对靶多核苷酸进行测序。叉状衔接子结构的另一个实例包括在illuminatm文库制品中使用的叉状衔接子和可从newenglandbiolabstm获得的用于illumina的
图2示出了条形码区域在图1所示的叉状衔接子内的放置的三个示意性实例。在一个实例中,条形码205(bc1)置于第一固定区域201内或第一固定区域201与第一测序引物区域203之间。在另一个实例中,条形码206(bc2)置于第一测序引物区域203内或与之邻近。在又一个实例中,条形码207(bc3)置于第二固定区域202内或第二固定区域202与第二测序引物区域204之间。尽管图2在靶序列的两端都示出了条形码,但这不是必需的,因为每个靶序列只有一个条形码对于某些应用是足够的。然而,如本公开内容的其他部分所述,也可以使用每个靶序列超过一个条形码。
图3提供了连接至靶多核苷酸(nnn)的相对端的两个叉状衔接子的示例性序列(seqidno:1和seqidno:22),并在序列水平上显示了每个叉状衔接子的条形码区域(粗体,核苷酸30-37、71-77、81-87和122-129)。在图3中,核苷酸1-29代表第一叉状衔接子的固定区域,核苷酸38-70代表第一叉状衔接子的测序引物区域,核苷酸78-80(nnn)代表任意长度的靶多核苷酸,核苷酸88-120代表第二叉状衔接子的测序引物区域,而核苷酸129-153代表第二叉状衔接子的固定区域。
v.分区
a.分区的一般特性
如本公开内容通篇所述,本公开内容的某些方法、组合物、系统、装置和试剂盒可以利用某些物质向单独的分区内的细分(分区)。分区可以是,例如,孔、微孔、孔洞、小滴(例如,乳液中的小滴)、乳液的连续相、试管、斑点、胶囊、珠子的表面,或任何其他用于隔离样品或物质的一个级分的合适的容器。分区可以用来容纳用于进一步处理的物质。例如,如果物质是多核苷酸分析物,则进一步的处理可以包括切割、连接和/或用作为试剂的物质进行条形码化。可以用任何数目的装置、系统或容器来容纳、支持或包含分区。在一些情况下,可以用微孔板来容纳、支持或包含分区。可以使用任何合适的微孔板,例如,具有96、384或1536个孔的微孔板。
每个分区还可以含有任何其他合适的分区或包容在任何其他合适的分区中。例如,孔、微孔、孔洞、珠子的表面或管可包含小滴(例如,乳液中的小滴)、乳液中的连续相、斑点、胶囊或任何其他合适的分区。小滴可以包含胶囊、珠子或另一小滴。胶囊可以包含小滴、珠子或另一胶囊。这些描述仅是说明性的,还想到所有合适的组合和复数。例如,任何合适的分区可以包含多个相同或不同的分区。在一个实例中,孔或微孔包含多个小滴和多个胶囊。在另一个实例中,胶囊包含多个胶囊和多个小滴。想像到分区的所有组合。表1显示了可以彼此组合的分区的非限制性实例。
表1.可以彼此组合的分区的实例。
本文描述的任何分区可以包含多个分区。例如,分区可以包含1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000或50000个分区。分区可以包含至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000或50000个分区。在一些情况下,分区可以包含少于3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000或50000个分区。在一些情况下,每个分区可以包含2-50、2-20、2-10或2-5个分区。
分区可以包含任何合适的物质或物质的混合物。例如,在一些情况下,分区可以包含试剂、分析物、样品、细胞及其组合。包含其他分区的分区可以在相同的分区中包含某些物质以及在不同的分区中包含某些物质。根据特定过程的需要,物质可以分布在任何合适的分区之间。例如,表1中的任何分区可以含有至少一种第一物质,且表1中的任何分区可以含有至少一种第二物质。在一些情况下,第一物质可以是试剂,而第二物质可以是分析物。
在一些情况下,物质是从细胞中分离的多核苷酸。例如,在一些情况下,利用任何合适的方法(例如可商购的试剂盒)从细胞中分离多核苷酸(例如,基因组dna、rna等)。可以对多核苷酸进行量化。然后可以将量化的多核苷酸分配到如本文所述的多个分区中。根据量化和测定的需要,多核苷酸的分区可以在预定的覆盖量下进行。在一些情况下,所有或大多数(例如,至少50%、60%、70%、80%、90%或95%)分区不包含重叠的多核苷酸,使得在多个分区间形成非重叠片段的单独的混合物。分区的多核苷酸然后可以按照本领域已知的或本公开内容描述的任何合适的方法来处理。例如,可以对分区的多核苷酸进行片段化、扩增、条形码化等。
物质可以使用多种方法进行分区。例如,可以将物质稀释并在多个分区间进行分配。可以对包含物质的介质进行终末稀释,以使得分区的数目超过物质的数目。也可以在形成乳液或胶囊之前,或在将物质点印至基底上之前使用稀释。物质的数目与分区的数目之比可以是约0.1、0.5、1、2、4、8、10、20、50、100或1000。物质的数目与分区的数目之比可以是至少约0.1、0.5、1、2、4、8、10、20、50、100或1000。物质的数目与分区的数目之比可以小于约0.1、0.5、1、2、4、8、10、20、50、100或1000。物质的数目与分区的数目之比可以为约0.1-10、0.5-10、1-10、2-10、10-100、100-1000或更大。
也可以使用压电小滴生成(例如,bransky等人,labonachip,2009,9,516-520)或表面声波(例如,demirci和montesano,labonachip,2007,7,1139-1145)进行分区。
使用的分区的数目可以根据应用而不同。例如,分区的数目可以是约5、10、50、100、250、500、750、1000、1500、2000、2500、5000、7500或10,000、20000、30000、40000、50000、60000、70000、80000、90000、100,000、200000、300000、400000、500000、600000、700000、800000、900000、1,000,000、2000000、3000000、4000000、5000000、10000000、20000000或更多。分区的数目可以是至少约5、10、50、100、250、500、750、1000、1500、2000、2500、5000、7500、10,000、20000、30000、40000、50000、60000、70000、80000、90000、100,000、200000、300000、400000、500000、600000、700000、800000、900000、1,000,000、2000000、3000000、4000000、5000000、10000000、20000000或更多。分区的数目可以少于约5、10、50、100、250、500、750、1000、1500、2000、2500、5000、7500、10,000、20000、30000、40000、50000、60000、70000、80000、90000、100,000、200000、300000、400000、500000、600000、700000、800000、900000、1,000,000、2000000、3000000、4000000、5000000、10000000、20000000。分区的数目可以是约5-10000000、5-5000000、5-1,000,000、10-10,000、10-5,000、10-1,000、1,000-6,000、1,000-5,000、1,000-4,000、1,000-3,000或1,000-2,000。
被分区的不同条形码或不同组条形码的数目可以根据例如待分区的特定条形码和/或应用而不同。不同组条形码可以是,例如,相同条形码在各组中有差异的成组相同条形码。或者不同组条形码可以是,例如,每一组就其包含的条形码而言有差异的成组不同条形码。例如,可以对约1、5、10、50、100、1000、10000、20,000、30,000、40,000、50,000、60,000、70,000、80,000、90,000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000、100000000个或更多个不同的条形码或不同组的条形码进行分区。在一些实例中,可以对至少约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000、100000000个或更多个不同的条形码或不同组的条形码进行分区。在一些实例中,可以对少于约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000或100000000个不同的条形码或不同组的条形码进行分区。在一些实例中,可以对约1-5、5-10、10-50、50-100、100-1000、1000-10000、10000-100000、100000-1000000、10000-1000000、10000-10000000或10000-100000000个条形码进行分区。
条形码可以以特定密度进行分区。例如,可以对条形码进行分区以使得每个分区含有约1、5、10、50、100、1000、10000、20,000、30,000、40,000、50,000、60,000、70,000、80,000、90,000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000或100000000个条形码/分区。可以对条形码进行分区以使得每个分区含有至少约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000、100000000个或更多个条形码/分区。可以对条形码进行分区以使得每个分区含有少于约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000或100000000个条形码/分区。可以对条形码进行分区以使得每个分区含有约1-5、5-10、10-50、50-100、100-1000、1000-10000、10000-100000、100000-1000000、10000-1000000、10000-10000000或10000-100000000个条形码/分区。
可以对条形码进行分区以使得相同的条形码以特定密度分区。例如,可以对相同的条形码进行分区以使得每个分区含有约1、5、10、50、100、1000、10000、20,000、30,000、40,000、50,000、60,000、70,000、80,000、90,000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000或100000000个相同的条形码/分区。可以对条形码进行分区以使得每个分区含有至少约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000、100000000个或更多个相同的条形码/分区。可以对条形码进行分区以使得每个分区含有少于约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000或100000000个相同的条形码/分区。可以对条形码进行分区以使得每个分区含有约1-5、5-10、10-50、50-100、100-1000、1000-10000、10000-100000、100000-1000000、10000-1000000、10000-10000000或10000-100000000个相同的条形码/分区。
可以对条形码进行分区以使得不同的条形码以特定密度分区。例如,可以对不同的条形码进行分区以使得每个分区含有约1、5、10、50、100、1000、10000、20,000、30,000、40,000、50,000、60,000、70,000、80,000、90,000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000或100000000个不同的条形码/分区。可以对条形码进行分区以使得每个分区含有至少约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000、100000000个或更多个不同的条形码/分区。可以对条形码进行分区以使得每个分区含有少于约1、5、10、50、100、1000、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200,000、300,000、400,000、500,000、600,000、700,000、800,000、900,000、1000000、2000000、3000000、4000000、5000000、6000000、7000000、8000000、9000000、10000000、20000000、50000000或100000000个不同的条形码/分区。可以对条形码进行分区以使得每个分区含有约1-5、5-10、10-50、50-100、100-1000、1000-10000、10000-100000、100000-1000000、10000-1000000、10000-10000000或10000-100000000个不同的条形码/分区。
用于对条形码进行分区的分区的数目可以变化,例如,取决于应用和/或待分区的不同条形码的数目。例如,用于对条形码进行分区的分区的数目可以是约5、10、50、100、250、500、750、1000、1500、2000、2500、5000、7500或10,000、20000、30000、40000、50000、60000、70000、80000、90000、100,000、200000、300000、400000、500000、600000、700000、800000、900000、1,000,000、2000000、3000000、4000000、5000000、10000000、20000000或更多。用于对条形码进行分区的分区的数目可以是至少约5、10、50、100、250、500、750、1000、1500、2000、2500、5000、7500、10,000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200000、300000、400000、500000、600000、700000、800000、900000、1000000、2000000、3000000、4000000、5000000、10000000、20000000或更多。用于对条形码进行分区的分区的数目可以少于约5、10、50、100、250、500、750、1000、1500、2000、2500、5000、7500、10,000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200000、300000、400000、500000、600000、700000、800000、900000、1000000、2000000、3000000、4000000、5000000、10000000或20000000。用于对条形码进行分区的分区的数目可以是约5-10000000、5-5000000、5-1,000,000、10-10,000、10-5,000、10-1,000、1,000-6,000、1,000-5,000、1,000-4,000、1,000-3,000或1,000-2,000。
如上所述,可以对不同的条形码或不同组的条形码(例如,每组包含多个相同的条形码或不同的条形码)进行分区,以使得每个分区包含不同的条形码或不同的条形码组。在一些情况下,每个分区可以包含不同组的相同条形码。当对不同组的相同条形码进行分区时,每个分区中相同条形码的数目可以变化。例如,约100,000个或更多个不同组的相同条形码可以在约100,000个或更多个不同的分区中进行分区,使得每个分区包含不同组的相同条形码。在每个分区中,每组条形码的相同条形码的数目可以是约1,000,000个相同的条形码。在一些情况下,不同组条形码的数目可以等于或基本等于分区的数目。不同条形码或不同条形码组的任何合适的数目(包括本文其他部分描述的待分区的不同条形码或不同条形码组的数目)、每个分区中条形码的数目(包括本文其他部分描述的每个分区中条形码的数目)和分区的数目(包括本文其他部分描述的分区的数目)可以组合起来以生成被分区的条形码的多样性文库,其中每个分区具有大数目的条形码。因此,应当理解,可以用任何上述的每个分区的条形码密度以及任何上述的分区数目提供任何上述不同数目的条形码。
分区的容积可以根据应用而不同。例如,本公开内容描述的任何分区(例如孔、斑点、小滴(例如,在乳液中)和胶囊)的容积可以是约1000μl、900μl、800μl、700μl、600μl、500μl、400μl、300μl、200μl、100μl、50μl、25μl、10μl、5μl、1μl、900nl、800nl、700nl、600nl、500nl、400nl、300nl、200nl、100nl、50nl、25nl、10nl、5nl、2.5nl、1nl、900pl、800pl、700pl、600pl、500pl、400pl、300pl、200pl、100pl、50pl、25pl、10pl、5pl、1pl、900fl、800fl、700fl、600fl、500fl、400fl、300fl、200fl、100fl、50fl、25fl、10fl、5fl、1fl或0.5fl。分区的容积可以是至少约1000μl、900μl、800μl、700μl、600μl、500μl、400μl、300μl、200μl、100μl、50μl、25μl、10μl、5μl、1μl、900nl、800nl、700nl、600nl、500nl、400nl、300nl、200nl、100nl、50nl、25nl、10nl、5nl、5nl、2.5nl、1nl、900pl、800pl、700pl、600pl、500pl、400pl、300pl、200pl、100pl、50pl、25pl、10pl、5pl、1pl、900fl、800fl、700fl、600fl、500fl、400fl、300fl、200fl、100fl、50fl、25fl、10fl、5fl、1fl或0.5fl。分区的容积可以小于约1000μl、900μl、800μl、700μl、600μl、500μl、400μl、300μl、200μl、100μl、50μl、25μl、10μl、5μl、1μl、900nl、800nl、700nl、600nl、500nl、400nl、300nl、200nl、100nl、50nl、25nl、10nl、5nl、5nl、2.5nl、1nl、900pl、800pl、700pl、600pl、500pl、400pl、300pl、200pl、100pl、50pl、25pl、10pl、5pl、1pl、900fl、800fl、700fl、600fl、500fl、400fl、300fl、200fl、100fl、50fl、25fl、10fl、5fl、1fl或0.5fl。分区的容积可以是约0.5fl-5pl、10pl-10nl、10nl-10μl、10μl-100μl或100μl-1ml。
在不同分区中的流体体积可存在可变性。更具体地,在一组分区之间,不同分区的容积可以变化至少(或至多)+或-1%、2%、3%、4%、5%、10%、20%、30%、40%、50%、60%、70%、80%、90%、100%、200%、300%、400%、500%或1000%。例如,孔(或其他分区)可以包含为第二孔(或其他分区)内的流体体积的至多80%的流体体积。
特定物质也可以靶向至特定分区。例如,在一些情况下,捕获试剂(例如,寡核苷酸探针)可以固定在或置于分区内以捕获特定物质(例如,多核苷酸)。例如,捕获寡核苷酸可以固定在珠子的表面上,以捕获包含具有互补序列的寡核苷酸的物质。
物质也可以以特定密度进行分区。例如,可以对物质进行分区,以使得每个分区含有约1、5、10、50、100、1000、10000、100000或1000000个物质/分区。可以对物质进行分区,以使得每个分区含有至少约1、5、10、50、100、1000、10000、100000、1000000个或更多个物质/分区。可以对物质进行分区,以使得每个分区含有少于约1、5、10、50、100、1000、10000、100000或1000000个物质/分区。可以对物质进行分区,以使得每个分区含有约1-5、5-10、10-50、50-100、100-1000、1000-10000、10000-100000或100000-1000000个物质/分区。
可以对物质进行分区,以使得至少一个分区包含在该分区内独特的物质。这可能适用于约1%、5%、10%、20%、30%、40%、50%、60%、70%、80%、90%或更多的分区。这可能适用于至少约1%、5%、10%、20%、30%、40%、50%、60%、70%、80%、90%或更多的分区。这可能适用于少于约1%、5%、10%、20%、30%、40%、50%、60%、70%、80%或90%的分区。
b.孔作为分区
在一些情况下,使用孔作为分区。孔可以是微孔。孔可包含介质,该介质包含一个或多个物质。物质可以以多种配置包含在孔内。在一个实例中,将物质直接分配到孔中。直接分配到孔中的物质可以覆盖有层,该层例如是可溶解的、可熔化的或可渗透的。该层可以是,例如,油、蜡、膜等。该层可以在将另外的物质引入孔中之前或之后溶解或熔化。可以在任何时间点,例如在添加任何物质之后,用密封层对孔进行密封。
在一个实例中,将用于样品处理的试剂直接分配到孔中,并用可溶解的、可熔化的或可渗透的层覆盖。将包含待处理的分析物的样品引入到层的顶部。该层溶解或熔化,或者分析物(或试剂)扩散通过该层。将孔密封,并在用于分析物处理的合适的条件下温育。随后可回收处理的分析物。
在一些情况下,孔包含其他分区。孔可包含任何合适的分区,包括,例如,另外的孔、斑点、小滴(例如,乳液中的小滴)、胶囊、珠子等。每个分区可以作为单个分区或多个分区存在,并且每个分区可包含相同的物质或不同的物质。
在一个实例中,孔包含胶囊,该胶囊包含用于样品处理的试剂。可使用液体介质将胶囊加载至孔中,或在不使用液体介质(例如,基本上干燥)的情况下将胶囊加载至孔中。如本公开内容的其他地方所述的,胶囊可含有一个或多个胶囊,或其他分区。可将包含待处理的分析物的样品引入到孔中。可将孔密封,并可施加刺激以使胶囊的内容物释放至孔中,从而导致试剂与待处理的分析物之间的接触。可将孔在用于处理分析物的合适的条件下温育。随后可回收处理的分析物。尽管该实例描述了其中试剂在胶囊中并且分析物在孔中的实施方案,但相反的配置——即,试剂在孔中并且分析物在胶囊中——也是可能的。
在另一个实例中,孔包含乳液,且乳液的小滴包含含有用于样品处理的试剂的胶囊。包含待处理的分析物的样品包含在乳液的小滴内。将孔密封,并施加刺激以使胶囊的内容物释放至小滴中,从而导致试剂与待处理的分析物之间的接触。将孔在用于处理分析物的合适的条件下温育。随后可回收处理的分析物。尽管该实例描述了其中试剂在胶囊中并且分析物在小滴中的实施方案,但相反的配置——即,试剂在小滴中并且分析物在胶囊中——也是可能的。
可将孔布置成阵列,例如,微孔阵列。根据单个孔的尺寸和基底的大小,孔阵列可包含一定范围的孔密度。在一些情况下,孔密度可以为10个孔/cm2、50个孔/cm2、100个孔/cm2、500个孔/cm2、1000个孔/cm2、5000个孔/cm2、10000个孔/cm2、50000个孔/cm2或100000个孔/cm2。在一些情况下,孔密度可以为至少10个孔/cm2、50个孔/cm2、100个孔/cm2、500个孔/cm2、1000个孔/cm2、5000个孔/cm2、10000个孔/cm2、50000个孔/cm2或100000个孔/cm2。在一些情况下,孔密度可以小于10个孔/cm2、50个孔/cm2、100个孔/cm2、500个孔/cm2、1000个孔/cm2、5000个孔/cm2、10000个孔/cm2、50000个孔/cm2或100000个孔/cm2。
c.斑点作为分区
在一些情况下,使用斑点作为分区。斑点可以例如通过将物质分配到表面上而制得。物质可以以多种配置包含在斑点内。在一个实例中,通过将物质包含在用于形成斑点的介质中而将物质直接分配到斑点中。直接分配到斑点上的物质可以覆盖有层,该层例如是可溶解的、可熔化的或可渗透的。该层可以是,例如,油、蜡、膜等。该层可以在将另外的物质引入斑点上之前或之后溶解或熔化。可以在任何时间点,例如在添加任何物质之后,通过覆盖物来密封斑点。
在一个实例中,将用于样品处理的试剂直接分配到斑点上,例如载玻片上,并用可溶解的、可熔化的或可渗透的层覆盖。将包含待处理的分析物的样品引入到层的顶部。该层溶解或熔化,或者分析物(或试剂)扩散通过该层。将斑点密封,并在用于分析物处理的合适的条件下温育。随后可回收处理的分析物。
如本公开内容的其他地方(例如,表1)所述,也可将斑点布置在孔内。在一些情况下,可将多个斑点布置在孔内,使得每个斑点的内容物不会混合。这样的配置可能是有用的,例如,当期望阻止物质彼此接触时。在一些情况下,孔可包含2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多个斑点。在一些情况下,孔可包含至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30个或更多个斑点。在一些情况下,孔可包含少于2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个斑点。在一些情况下,孔可包含2-4、2-6、2-8、4-6、4-8、5-10或4-12个斑点。在将物质(例如,包含分析物的介质)加入到孔中时,斑点中的物质可以混合。此外,使用分开的斑点来容纳不同的物质(或物质的组合)也可用于防止用来将斑点置于孔内的装置的交叉污染。
在一些情况下,斑点包含其他分区。斑点可包含任何合适的分区,包括,例如,另外的斑点、小滴(例如,乳液中的小滴)、胶囊、珠子等。每个分区可以作为单个分区或多个分区存在,并且每个分区可包含相同的物质或不同的物质。
在一个实例中,斑点包含胶囊,该胶囊包含用于样品处理的试剂。如本公开内容的其他地方所述,胶囊可含有一个或多个胶囊,或其他分区。将包含待处理的分析物的样品引入到斑点中。将斑点密封,并施加刺激以使胶囊的内容物释放至斑点中,从而导致试剂与待处理的分析物之间的接触。将斑点在用于处理分析物的合适的条件下温育。随后可回收处理的分析物。尽管该实例描述了其中试剂在胶囊中并且分析物在斑点中的实施方案,但相反的配置——即,试剂在斑点中并且分析物在胶囊中——也是可能的。
在另一个实例中,斑点包含乳液,且乳液的小滴包含含有用于样品处理的试剂的胶囊。包含待处理的分析物的样品包含在乳液的小滴内。将斑点密封,并施加刺激以使胶囊的内容物释放至小滴中,从而导致试剂与待处理的分析物之间的接触。将斑点在用于处理分析物的合适的条件下温育。随后可回收处理的分析物。尽管该实例描述了其中试剂在胶囊中并且分析物在小滴中的实施方案,但相反的配置——即,试剂在小滴中并且分析物在胶囊中——也是可能的。
斑点可以具有均匀的大小或不均匀的大小。在一些情况下,斑点的直径可以为约0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm、1mm、2mm、5mm或1cm。斑点可以具有至少约0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm、1mm、1mm、2mm、5mm或1cm的直径。在一些情况下,斑点可以具有小于约0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm、1mm、1mm、2mm、5mm或1cm的直径。在一些情况下,斑点可以具有约0.1μm至1cm、100μm至1mm、100μm至500μm、100μm至600μm、150μm至300μm、或150μm至400μm的直径。
可以将斑点布置成阵列,例如斑点阵列。根据单个斑点的尺寸和基底的大小,斑点阵列可包含一定范围的斑点密度。在一些情况下,斑点密度可以为10个斑点/cm2、50个斑点/cm2、100个斑点/cm2、500个斑点/cm2、1000个斑点/cm2、5000个斑点/cm2、10000个斑点/cm2、50000个斑点/cm2或100000个斑点/cm2。在一些情况下,斑点密度可以为至少10个斑点/cm2、50个斑点/cm2、100个斑点/cm2、500个斑点/cm2、1000个斑点/cm2、5000个斑点/cm2、10000个斑点/cm2、50000个斑点/cm2或100000个斑点/cm2。在一些情况下,斑点密度可以小于10个斑点/cm2、50个斑点/cm2、100个斑点/cm2、500个斑点/cm2、1000个斑点/cm2、5000个斑点/cm2、10000个斑点/cm2、50000个斑点/cm2或100000个斑点/cm2。
d.乳液作为分区
在一些情况下,使用乳液中的小滴作为分区。例如,可通过任何合适的方法,包括本领域中已知的方法制备乳液。(参见,例如,weizmann等人,naturemethods,2006,3(7):545-550;weitz等人,美国公开号2012/0211084)。在一些情况下,可使用碳氟化合物包水乳液。这些乳液可以掺入含氟表面活性剂,诸如含聚乙二醇(peg)的寡聚全氟聚醚(pfpe)。(holtz等人,labonachip,2008,8(10):1632-1639)。在一些情况下,可以在微流体流动聚焦装置中形成单分散乳液。(garstecki等人,appliedphysicsletters,2004,85(13):2649-2651)。
物质可容纳在乳液中的小滴内,该乳液包含,例如,形成小滴的第一相(例如,油或水)和第二(连续)相(例如,水或油)。乳液可以是单乳液,例如,油包水或水包油乳液。乳液可以是双乳液,例如水包油包水或油包水包油乳液。更高阶的乳液也是可能的。该乳液可容纳在任何合适的容器,包括本公开内容中描述的任何合适的分区中。
在一些情况下,乳液中的小滴包含其他分区。乳液中的小滴可包含任何合适的分区,包括,例如,另外的小滴(例如,乳液中的小滴)、胶囊、珠子等。每个分区可作为单个分区或多个分区存在,并且每个分区可包含相同的物质或不同的物质。
在一个实例中,乳液中的小滴包含胶囊,该胶囊包含用于样品处理的试剂。如本公开内容的其他地方所述的,胶囊可含有一个或多个胶囊,或其他分区。包含待处理的分析物的样品包含在小滴内。施加刺激以使胶囊的内容物释放至小滴中,从而导致试剂与待处理的分析物之间的接触。将小滴在用于处理分析物的合适的条件下温育。随后可回收处理的分析物。尽管该实例描述了其中试剂在胶囊中并且分析物在小滴中的实施方案,但相反的配置——即,试剂在小滴中并且分析物在胶囊中——也是可能的。
乳液中的小滴可以具有均匀的大小或不均匀的大小。在一些情况下,乳液中的小滴的直径可以为约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm。小滴可以具有至少约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm的直径。在一些情况下,小滴可以具有小于约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm的直径。在一些情况下,小滴可以具有约0.001μm至1mm、0.01μm至900μm、0.1μm至600μm、100μm至200μm、100μm至300μm、100μm至400μm、100μm至500μm、100μm至600μm、150μm至200μm、150μm至300μm、或150μm至400μm的直径。
乳液中的小滴也可具有特定的密度。在一些情况下,小滴不如水性流体(例如,水)稠密;在一些情况下,小滴比水性流体稠密。在一些情况下,小滴不如非水性流体(例如,油)稠密;在一些情况下,小滴比非水性流体稠密。小滴可以具有约0.05g/cm3、0.1g/cm3、0.2g/cm3、0.3g/cm3、0.4g/cm3、0.5g/cm3、0.6g/cm3、0.7g/cm3、0.8g/cm3、0.81g/cm3、0.82g/cm3、0.83g/cm3、0.84g/cm3、0.85g/cm3、0.86g/cm3、0.87g/cm3、0.88g/cm3、0.89g/cm3、0.90g/cm3、0.91g/cm3、0.92g/cm3、0.93g/cm3、0.94g/cm3、0.95g/cm3、0.96g/cm3、0.97g/cm3、0.98g/cm3、0.99g/cm3、1.00g/cm3、1.05g/cm3、1.1g/cm3、1.2g/cm3、1.3g/cm3、1.4g/cm3、1.5g/cm3、1.6g/cm3、1.7g/cm3、1.8g/cm3、1.9g/cm3、2.0g/cm3、2.1g/cm3、2.2g/cm3、2.3g/cm3、2.4g/cm3或2.5g/cm3的密度。小滴可以具有至少约0.05g/cm3、0.1g/cm3、0.2g/cm3、0.3g/cm3、0.4g/cm3、0.5g/cm3、0.6g/cm3、0.7g/cm3、0.8g/cm3、0.81g/cm3、0.82g/cm3、0.83g/cm3、0.84g/cm3、0.85g/cm3、0.86g/cm3、0.87g/cm3、0.88g/cm3、0.89g/cm3、0.90g/cm3、0.91g/cm3、0.92g/cm3、0.93g/cm3、0.94g/cm3、0.95g/cm3、0.96g/cm3、0.97g/cm3、0.98g/cm3、0.99g/cm3、1.00g/cm3、1.05g/cm3、1.1g/cm3、1.2g/cm3、1.3g/cm3、1.4g/cm3、1.5g/cm3、1.6g/cm3、1.7g/cm3、1.8g/cm3、1.9g/cm3、2.0g/cm3、2.1g/cm3、2.2g/cm3、2.3g/cm3、2.4g/cm3或2.5g/cm3的密度。在其他情况下,小滴密度可以为最大约0.7g/cm3、0.8g/cm3、0.81g/cm3、0.82g/cm3、0.83g/cm3、0.84g/cm3、0.85g/cm3、0.86g/cm3、0.87g/cm3、0.88g/cm3、0.89g/cm3、0.90g/cm3、0.91g/cm3、0.92g/cm3、0.93g/cm3、0.94g/cm3、0.95g/cm3、0.96g/cm3、0.97g/cm3、0.98g/cm3、0.99g/cm3、1.00g/cm3、1.05g/cm3、1.1g/cm3、1.2g/cm3、1.3g/cm3、1.4g/cm3、1.5g/cm3、1.6g/cm3、1.7g/cm3、1.8g/cm3、1.9g/cm3、2.0g/cm3、2.1g/cm3、2.2g/cm3、2.3g/cm3、2.4g/cm3或2.5g/cm3。这些密度可反映任何特定流体(例如,水性流体、水、油等)中胶囊的密度。
e.胶囊作为分区
在一些情况下,使用胶囊作为分区。可通过任何合适的方法制备胶囊,包括本领域中已知的方法,包括乳化聚合(weitz等人(美国公开号2012/0211084))、采用聚合电解质的逐层装配、凝聚、内相分离和流动聚焦。任何合适的物质可容纳在胶囊内。该胶囊可容纳在任何合适的容器中,包括本公开内容中描述的任何合适的分区中。
在一些情况下,胶囊包含其他分区。胶囊可包含任何合适的分区,包括,例如,另外的胶囊、乳液中的小滴、珠子等。每个分区可以作为单个分区或多个分区存在,并且每个分区可包含相同的物质或不同的物质。
在一个实例中,外层胶囊包含内层胶囊。内层胶囊包含用于样品处理的试剂。将分析物包封在内层胶囊与外层胶囊之间的介质中。施加刺激以使内层胶囊的内容物释放至外层胶囊中,从而导致试剂与待处理的分析物之间的接触。将外层胶囊在用于处理分析物的合适的条件下温育。随后可回收处理的分析物。尽管该实例描述了其中试剂在内层胶囊中并且分析物在内层胶囊与外层胶囊之间的介质中的实施方案,但相反的配置——即,试剂在内层胶囊与外层胶囊之间的介质中并且分析物在内层胶囊中——也是可能的。
胶囊可预先形成并通过注射以试剂来填充。例如,在abate等人(proc.natl.acad.sci.u.s.a.,2010,107(45),19163-19166)和weitz等人(美国公开号2012/0132288)中描述的皮量注射(picoinjection)方法可用于将试剂引入到本文所述的胶囊的内部。通常,皮量注射将在胶囊壳硬化之前进行,例如通过在胶囊壳形成之前,将物质注射入胶囊前体如乳液的小滴的内部。
胶囊可以具有均匀的大小或不均匀的大小。在一些情况下,胶囊的直径可以为约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm。胶囊可以具有至少约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm的直径。在一些情况下,胶囊可以具有小于约0.001μm、0.01μm、0.05μm、0.1μm、0.5μm、1μm、5μm、10μm、50μm、100μm、150μm、200μm、300μm、400μm、500μm、600μm、700μm、800μm、900μm或1mm的直径。在一些情况下,胶囊可以具有约0.001μm至1mm、0.01μm至900μm、0.1μm至600μm、100μm至200μm、100μm至300μm、100μm至400μm、100μm至500μm、100μm至600μm、150μm至200μm、150μm至300μm、或150μm至400μm的直径。
胶囊还可具有特定的密度。在一些情况下,胶囊不如水性流体(例如,水)稠密;在一些情况下,胶囊比水性流体稠密。在一些情况下,胶囊不如非水性流体(例如,油)稠密;在一些情况下,胶囊比非水性流体稠密。胶囊可以具有约0.05g/cm3、0.1g/cm3、0.2g/cm3、0.3g/cm3、0.4g/cm3、0.5g/cm3、0.6g/cm3、0.7g/cm3、0.8g/cm3、0.81g/cm3、0.82g/cm3、0.83g/cm3、0.84g/cm3、0.85g/cm3、0.86g/cm3、0.87g/cm3、0.88g/cm3、0.89g/cm3、0.90g/cm3、0.91g/cm3、0.92g/cm3、0.93g/cm3、0.94g/cm3、0.95g/cm3、0.96g/cm3、0.97g/cm3、0.98g/cm3、0.99g/cm3、1.00g/cm3、1.05g/cm3、1.1g/cm3、1.2g/cm3、1.3g/cm3、1.4g/cm3、1.5g/cm3、1.6g/cm3、1.7g/cm3、1.8g/cm3、1.9g/cm3、2.0g/cm3、2.1g/cm3、2.2g/cm3、2.3g/cm3、2.4g/cm3或2.5g/cm3的密度。胶囊可以具有至少约0.05g/cm3、0.1g/cm3、0.2g/cm3、0.3g/cm3、0.4g/cm3、0.5g/cm3、0.6g/cm3、0.7g/cm3、0.8g/cm3、0.81g/cm3、0.82g/cm3、0.83g/cm3、0.84g/cm3、0.85g/cm3、0.86g/cm3、0.87g/cm3、0.88g/cm3、0.89g/cm3、0.90g/cm3、0.91g/cm3、0.92g/cm3、0.93g/cm3、0.94g/cm3、0.95g/cm3、0.96g/cm3、0.97g/cm3、0.98g/cm3、0.99g/cm3、1.00g/cm3、1.05g/cm3、1.1g/cm3、1.2g/cm3、1.3g/cm3、1.4g/cm3、1.5g/cm3、1.6g/cm3、1.7g/cm3、1.8g/cm3、1.9g/cm3、2.0g/cm3、2.1g/cm3、2.2g/cm3、2.3g/cm3、2.4g/cm3或2.5g/cm3的密度。在其他情况下,胶囊密度可以为最大约0.7g/cm3、0.8g/cm3、0.81g/cm3、0.82g/cm3、0.83g/cm3、0.84g/cm3、0.85g/cm3、0.86g/cm3、0.87g/cm3、0.88g/cm3、0.89g/cm3、0.90g/cm3、0.91g/cm3、0.92g/cm3、0.93g/cm3、0.94g/cm3、0.95g/cm3、0.96g/cm3、0.97g/cm3、0.98g/cm3、0.99g/cm3、1.00g/cm3、1.05g/cm3、1.1g/cm3、1.2g/cm3、1.3g/cm3、1.4g/cm3、1.5g/cm3、1.6g/cm3、1.7g/cm3、1.8g/cm3、1.9g/cm3、2.0g/cm3、2.1g/cm3、2.2g/cm3、2.3g/cm3、2.4g/cm3或2.5g/cm3。这些密度可反映任何特定流体(例如,水性流体、水、油等)中胶囊的密度。
1.通过流动聚焦产生胶囊
在一些情况下,胶囊可通过流动聚焦产生。流动聚焦是这样的一种方法,通过该方法与第二流体不混溶的第一流体流入第二流体中。参照图12,包含单体、交联剂、引发剂和水性表面活性剂的第一(例如,水性)流体1201流入到包含表面活性剂和促进剂的第二(例如,油)流体1202中。在微流体装置的t型接合点1203处进入第二流体后,第一流体的小滴脱离第一流体流,并且由于第一流体中的单体、交联剂和引发剂与第二流体中的促进剂混合,胶囊壳开始形成1204。由此,形成胶囊。随着胶囊向下游行进,壳由于更多地暴露于促进剂而变得更厚。也可以利用改变试剂的浓度来改变胶囊壳的厚度和渗透性。
可通过例如,在第一流体中包含物质来包封物质,或其他分区如小滴。将物质包含在第二流体中可使物质嵌入胶囊的壳中。当然,根据特定样品处理方法的需要,也可以将相反转——即,第一相可以是油相而第二相可以是水相。
2.通过流动聚焦产生在胶囊内的胶囊
在一些情况下,可通过流动聚焦产生在胶囊内的胶囊。参照图13,包含胶囊、单体、交联剂、引发剂和水性表面活性剂的第一(例如,水性)流体1301流入到包含表面活性剂和促进剂的第二(油)流体1302中。在微流体装置的t型接合点1303处进入第二流体后,第一流体的小滴脱离第一流体流,并且由于第一流体中的单体、交联剂和引发剂与第二流体中的促进剂混合,第二胶囊壳开始在胶囊周围形成1304。由此,形成在胶囊内的胶囊。随着胶囊向下游行进,壳由于更多地暴露于促进剂而变得更厚。也可以利用改变试剂的浓度来改变第二胶囊壳的厚度和渗透性。
可通过例如,在第一流体中包含物质来包封物质。将物质包含在第二流体中可使物质嵌入胶囊的第二壳中。当然,根据特定样品处理方法的需要,也可以将相反转——即,第一相可以是油相而第二相可以是水相。
3.胶囊的批量产生
在一些情况下,可使用胶囊前体,如乳液中的小滴,批量产生胶囊。可通过任何合适的方法,例如,通过产生具有包含单体、交联剂、引发剂和表面活性剂的小滴的乳液而形成胶囊前体。然后可将促进剂添加至介质中,从而导致胶囊形成。对于流动聚焦的方法,可通过改变反应物的浓度和暴露于促进剂的时间来改变壳的厚度。然后可将胶囊洗涤并回收。对于本文所述的任何方法,可将物质,包括其他分区,包封在胶囊内,或者如果合适,包封在壳内。
在另一个实例中,在乳液产生过程期间,可将乳液的小滴暴露于存在于出口孔中的促进剂。例如,可通过任何合适的方法,如图12中示出的流动聚焦方法形成胶囊前体。可将促进剂包含在位于t型接合点的出口处的介质(例如,位于图12的水平通道的极右端处的介质)中,而非将促进剂包含在第二流体1202中。当乳液小滴(即,胶囊前体)离开通道时,其接触包含促进剂的介质(即,出口介质)。如果胶囊前体具有小于出口介质的密度的密度,则胶囊前体将上升通过介质,从而确保对流和扩散暴露于促进剂并减小在通道出口处聚合的可能性。
vi.物质
本公开内容的方法、组合物、系统、装置和试剂盒可与任何合适的物质一起使用。物质可以是,例如,在样品处理中使用的任何物质,如试剂或分析物。示例性的物质包括全细胞、染色体、多核苷酸、有机分子、蛋白质、多肽、碳水化合物、糖类、糖、脂质、酶、限制酶、连接酶、聚合酶、条形码、衔接子、小分子、抗体、荧光团、脱氧核苷三磷酸(dntp)、双脱氧核苷三磷酸(ddntp)、缓冲液、酸性溶液、碱性溶液、对温度敏感的酶、对ph敏感的酶、对光敏感的酶、金属、金属离子、氯化镁、氯化钠、锰、水性缓冲液、温和的缓冲液、离子缓冲液、抑制剂、糖类、油、盐、离子、去污剂、离子型去污剂、非离子型去污剂、寡核苷酸、核苷酸、dna、rna、肽多核苷酸、互补dna(cdna)、双链dna(dsdna)、单链dna(ssdna)、质粒dna、粘粒dna、染色体dna、基因组dna、病毒dna、细菌dna、mtdna(线粒体dna)、mrna、rrna、trna、nrna、sirna、snrna、snorna、scarna、微rna、dsrna、核酶、核糖开关和病毒rna、锁核酸(lna)的全部或一部分、锁核酸核苷酸、任何其他类型的核酸类似物、蛋白酶、核酸酶、蛋白酶抑制剂、核酸酶抑制剂、螯合剂、还原剂、氧化剂、探针、生色团、染料、有机物、乳化剂、表面活性剂、稳定剂、聚合物、水、小分子、药物、放射性分子、防腐剂、抗生素、适体等。总之,所使用的物质将根据特定的样品处理需要而变化。
在一些情况下,分区包含具有相似属性的一组物质(例如,一组酶、一组矿物质、一组寡核苷酸、不同条形码的混合物、相同条形码的混合物)。在其他情况下,分区包含物质的不均匀混合物。在一些情况下,物质的不均匀混合物包含对于进行特定反应所必需的所有组分。在一些情况下,这样的混合物包含除了对于进行反应所必需的1、2、3、4、5种或更多种组分外,对于进行该反应所必需的所有组分。在一些情况下,这样的附加组分包含在不同的分区内,或在分区之内或周围的溶液内。
物质可以是天然存在的或合成的。物质可存在于使用本领域已知的任何方法获得的样品中。在一些情况下,样品可在分析其中的分析物之前进行处理。
物质可以从任何合适的位置获得,包括从生物体、全细胞、细胞制品和来自任何生物体、组织、细胞或环境的无细胞组合物获得。物质可从环境样品、活检物、抽出物、福尔马林固定包埋的组织、空气、农业样品、土壤样品、石油样品、水样品或灰尘样品获得。在一些情况下,物质可从体液获得,该体液可以包括血液、尿液、粪便、血清、淋巴、唾液、粘膜分泌物、汗液、中枢神经系统液、阴道液或精液。物质也可从生产的产品如化妆品、食品、个人护理产品等获得。物质可以是实验操作的产物,该实验操作包括重组克隆、多核苷酸扩增、聚合酶链反应(pcr)扩增、纯化方法(如基因组dna或rna的纯化)和合成反应。
在一些情况下,物质可根据质量来量化。物质可以以约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000ng、1μg、5μg、10μg、15μg或20μg的质量提供。物质可以以至少约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000ng、1μg、5μg、10μg、15μg或20μg的质量提供。物质可以以少于约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000ng、1μg、5μg、10μg、15μg或20μg的质量提供。物质可以以范围为约1-10、10-50、50-100、100-200、200-1000、1000-10000ng、1-5μg或1-20μg的质量提供。如本公开内容的其他地方所述,如果物质为多核苷酸,则可使用扩增来增加多核苷酸的量。
也可将多核苷酸量化为“基因组当量”。基因组当量是等同于从中获得靶多核苷酸的生物体的一个单倍体基因组的多核苷酸的量。例如,单个二倍体细胞含有两个基因组当量的dna。多核苷酸可以以范围为约1-10、10-50、50-100、100-1000、1000-10000、10000-100000或100000-1000000个基因组当量的量提供。多核苷酸可以以至少约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200000、300000、400000、500000、600000、700000、800000、900000或1000000个基因组当量的量提供。多核苷酸可以以少于约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、50、100、500、1000、1500、2000、2500、3000、3500、4000、4500、5000、5500、6000、6500、7000、7500、8000、8500、9000、9500、10000、20000、30000、40000、50000、60000、70000、80000、90000、100000、200000、300000、400000、500000、600000、700000、800000、900000或1000000个基因组当量的量提供。
多核苷酸还可以根据所提供的序列覆盖的量来量化。序列覆盖的量是指代表重构序列中给定核苷酸的读取值的平均数。通常,区域被测序的次数越多,所获得的序列信息就越准确。多核苷酸可以以提供约0.1x-10x、10x-50x、50x-100x、100x-200x或200x-500x的序列覆盖范围的量提供。多核苷酸可以以提供至少约0.1x、0.2x、0.3x、0.4x、0.5x、0.6x、0.7x、0.8x、0.9x、1.0x、5x、10x、25x、50x、100x、125x、150x、175x或200x的序列覆盖的量提供。多核苷酸可以以提供小于约0.2x、0.3x、0.4x、0.5x、0.6x、0.7x、0.8x、0.9x、1.0x、5x、10x、25x、50x、100x、125x、150x、175x或200x的序列覆盖的量提供。
在一些情况下,物质在特定步骤之前或之后引入到分区中。例如,可在将细胞样品分区到分区中之后,将裂解缓冲试剂引入到分区中。在一些情况下,顺序引入试剂和/或包含试剂的分区,使得不同的反应或操作在不同的步骤发生。还可在穿插有反应或操作步骤的步骤中加载试剂(或包含试剂的分区)。例如,可将包含用于分子(例如,核酸)片段化的试剂的胶囊加载到孔中,接着进行片段化步骤,该步骤之后可以是包含用于连接条形码(或其他独特标识符,例如,抗体)的试剂的胶囊的加载以及随后的条形码与片段化的分子的连接。
vii.分析物和其他物质的处理
在一些情况下,本公开内容的方法、组合物、系统、装置和试剂盒可用于处理含有物质例如分析物的样品。可进行任何合适的处理。
a.靶多核苷酸的片段化
在一些情况下,本公开内容的方法、组合物、系统、装置和试剂盒可用于多核苷酸片段化。多核苷酸的片段化被用作包括多核苷酸测序在内的多种方法中的步骤。通常以长度描述的多核苷酸片段的大小(根据每个片段中核苷酸的线性数目来量化)可根据靶多核苷酸的来源、用于片段化的方法和期望的应用而变化。可使用单个片段化步骤或多个片段化步骤。
使用本文所述的方法产生的片段可以为约1-10、10-20、20-50、50-100、50-200、100-200、200-300、300-400、400-500、500-1000、1000-5000、5000-10000、10000-100000、100000-250000或250000-500000个核苷酸的长度。使用本文所述的方法产生的片段可以为至少约10、20、100、200、300、400、500、1000、5000、10000、100000、250000、500000个或更多个核苷酸的长度。使用本文所述的方法产生的片段可以为小于约10、20、100、200、300、400、500、1000、5000、10000、100000、250000、500000个核苷酸的长度。
使用本文所述的方法产生的片段可以具有约1-10、10-20、20-50、50-100、50-200、100-200、200-300、300-400、400-500、500-1000、1000-5000、5000-10000、10000-100000、100000-250000或250000-500000个核苷酸的平均长度或中值长度。使用本文所述的方法产生的片段可以具有至少约10、20、100、200、300、400、500、1000、5000、10000、100000、250000、500000个或更多个核苷酸的平均长度或中值长度。使用本文所述的方法产生的片段可以具有小于约10、20、100、200、300、400、500、1000、5000、10000、100000、250000、500000个核苷酸的平均长度或中值长度。
许多片段化方法是本领域中已知的。例如,可通过物理、机械或酶方法进行片段化。物理片段化可包括将靶多核苷酸暴露于热或紫外线。机械破坏可用于将靶多核苷酸机械地剪切成所需范围的片段。机械剪切可通过本领域中已知的许多方法来完成,包括靶多核苷酸的重复移液、超声处理(例如,使用超声波)、空腔化和雾化。还可使用酶方法对靶多核苷酸进行片段化。在一些情况下,可使用酶如使用限制酶进行酶消化。
尽管在本公开内容的上文或任何其他地方参照“靶”多核苷酸对前述段落和本公开内容的一些段落中所述的片段化方法进行了描述,但这并不意味着限制。本文所述或本领域中已知的任何片段化方法均可应用于本发明中使用的任何多核苷酸。在一些情况下,该多核苷酸可以是靶多核苷酸,如基因组。在其他情况下,该多核苷酸可以是希望将其进一步片段化的靶多核苷酸的片段。在另外的其他情况下,进一步片段化的片段仍可以再进一步片段化。任何合适的多核苷酸可根据本文所述的方法进行片段化。
限制酶可用于进行靶多核苷酸的特异性或非特异性片段化。本公开内容的方法可使用一种或多种类型的限制酶,其通常被描述为i型酶、ii型酶和/或iii型酶。ii型和iii型酶通常是可商购的并且是本领域公知的。ii型和iii型酶识别双链多核苷酸序列内的核苷酸碱基对的特定序列(“识别序列”或“识别位点”)。在结合并识别这些序列后,ii型和iii型酶切割该多核苷酸序列。在一些情况下,切割将产生具有被称为“粘端”的突出单链dna部分的多核苷酸片段。在其他情况下,切割将不会产生具有突出端的片段,从而形成“平端”。本公开内容的方法可以包括使用产生粘端或平端的限制酶。
限制酶可识别靶多核苷酸中的多个识别位点。一些限制酶(“精确切割物”)只识别单个识别位点(例如,gaattc)。其他限制酶更混杂,并识别多于一个识别位点,或多个识别位点。一些酶在识别位点内的单个位置切割,而其他酶可能在多个位置切割。一些酶在识别位点内的相同位置切割,而其他酶在可变的位置切割。
本公开内容提供了选择一种或多种限制酶来产生所需长度的片段的方法。多核苷酸片段化可用计算机(insilico)模拟,并且可对片段化进行优化以获得在特定大小范围内的多核苷酸片段的最大数目或分数,同时使得在不期望大小范围内的片段的数目或分数减至最小。可应用优化算法来选择两种或更多种酶的组合以产生具有所需片段数量分布的所需片段大小。
多核苷酸可同时或顺序地暴露于两种或更多种限制酶。这可以通过,例如,向分区添加多于一种限制酶,或通过向分区添加一种限制酶、进行消化、灭活该限制酶(例如,通过热处理)并随后加入第二种限制酶来完成。任何合适的限制酶可在本文提出的方法中单独或组合使用。
在一些情况下,物质是一种为“稀有切割物(rare-cutter)”的限制酶。如本文所用的术语“稀有切割物”通常是指具有仅稀有地在基因组中出现的识别位点的酶。通过用限制酶切割假设的随机基因组而产生的限制性片段的大小可以近似于4n,其中n是在酶的识别位点中的核苷酸的数目。例如,具有由7个核苷酸组成的识别位点的酶将每47bp切割一次基因组,产生约16,384bp的片段。稀有切割物酶通常具有包含6个或者更多个核苷酸的识别位点。例如,稀有切割物酶可具有包含或由6、7、8、9、10、11、12、13、14或15个核苷酸组成的识别位点。稀有切割物酶的实例包括noti(gcggccgc)、xmaiii(cggccg)、sstii(ccgcgg)、sali(gtcgac)、nrui(tcgcga)、nhei(gctagc)、nb.bbvci(cctcagc)、bbvci(cctcagc)、asci(ggcgcgcc)、asisi(gcgatcgc)、fsei(ggccggcc)、paci(ttaattaa)、pmei(gtttaaac)、sbfi(cctgcagg)、sgrai(crccggyg)、swai(atttaaat)、bspqi(gctcttc)、sapi(gctcttc)、sfii(ggccnnnnnggcc)、cspci(caannnnngtgg)、absi(cctcgagg)、ccini(gcggccgc)、fspai(rtgcgcay)、maubi(cgcgcgcg)、mrei(cgccggcg)、mssi(gtttaaac)、palai(ggcgcgcc)、rgai(gcgatcgc)、rigi(ggccggcc)、sdai(cctgcagg)、sfaai(gcgatcgc)、sgfi(gcgatcgc)、sgrdi(cgtcgacg)、sgsi(ggcgcgcc)、smii(atttaaat)、srfi(gcccgggc)、sse2321(cgccggcg)、sse83871(cctgcagg)、lgui(gctcttc)、pcisi(gctcttc)、aari(cacctgc)、ajui(gaannnnnnnttgg)、aloi(gaacnnnnnntcc)、bari(gaagnnnnnntac)、ppii(gaacnnnnnctc)、psri(gaacnnnnnntac)和其他稀有切割物酶。
在一些情况下,多核苷酸可以同时进行片段化和条形码化。例如,可使用转座酶(例如,nextera)对多核苷酸进行片段化并向该多核苷酸添加条形码。
viii.刺激响应性
在一些情况下,刺激可以用于触发物质从分区的释放。通常,刺激可导致对分区结构如孔壁、斑点的组分、小滴(例如,乳液中的小滴)的稳定性或胶囊壳的破坏。这些刺激在诱导分区释放其内容物方面是特别有用的。由于分区可包含在另一分区内,并且各个分区可对不同的刺激有响应(或无响应),因此刺激响应性可用来将一个分区(例如,对刺激有响应的分区)的内容物释放到另一个分区(例如,对该刺激无响应或对该刺激较有较低响应的分区)中。
在一些情况下,可以通过施加溶解内层胶囊的刺激将内层胶囊的内容物释放到外层胶囊的内容物中,从而产生含有混合样品的胶囊。当然,该实施方案仅仅是说明性的,并且刺激响应性可以用于将任何合适的分区的内容物释放到任何其他合适的分区、介质或容器(关于分区内的分区的更具体的实例参见,例如,表1)中。
可以使用的刺激的实例包括化学刺激、本体变化(bulkchange)、生物刺激、光、热刺激、磁刺激、向孔中添加介质及其任意组合,如下文更充分描述的。(参见,例如,esser-kahn等人,(2011)macromolecules44:5539-5553;wang等人,(2009)chemphyschem10:2405-2409)。
a.化学刺激和本体变化
许多化学触发物可以用来触发分区的破裂(例如,plunkett等人,biomacromolecules,2005,6:632-637)。这些化学变化的实例可以包括但不限于ph介导的分区组分完整性的变化,通过交联键的化学裂解引起的分区组分的崩解,以及触发的分区组分的解聚。本体变化也可用于触发分区的破裂。
溶液ph的变化,如ph的下降,可通过许多不同的机制触发分区的破裂。酸的加入可通过多种机制引起分区的一部分的降解或分解。质子的加入可以分解分区组分中的聚合物的交联,破坏分区组分中的离子键或氢键,或在分区组分中产生纳米孔以允许内部内容物渗漏至外部。ph的变化也可以使乳液去稳定,从而导致小滴的内容物的释放。
在一些实例中,分区由包含酸可降解的化学交联剂如缩酮的材料生产。ph的降低,特别是降至低于5的ph,可诱使缩酮转化成酮和两个醇并促进分区的破裂。在其他实例中,分区可以由包含一种或多种对ph敏感的聚合电解质的材料生产。ph的降低可破坏这类分区的离子键或氢键相互作用,或在其中产生纳米孔。在一些情况下,由包含聚合电解质的材料制成的分区包含当ph变化时扩张和收缩的带电荷的、基于凝胶的芯。
构成分区的交联材料的破坏可以通过多种机制来完成。在一些实例中,分区可以与诱导氧化、还原或其他化学变化的各种化学品接触。在一些情况下,可以使用还原剂,如β-巯基乙醇,使得分区的二硫键破裂。另外,可以加入酶,以裂解形成分区的材料中的肽键,从而导致分区的完整性的丧失。
解聚也可以用于破坏分区。可加入化学触发物,以促进保护头基的移除。例如,触发物可导致聚合物内的碳酸酯或氨基甲酸酯的头基的移除,而这又引起解聚和物质从分区内部的释放。
在又一个实例中,化学触发物可包括渗透触发物,从而溶液中的离子或溶质浓度的变化诱发用于形成分区的材料的膨胀。膨胀可引起内压的积聚,使得分区破裂以释放其内容物。膨胀也可以引起材料的孔径的增大,从而使分区内包含的物质扩散出,反之亦然。
也可以通过本体或物理变化,如压力诱发的破裂、熔化或孔隙率的变化,使分区释放其内容物。
b.生物刺激
也可利用生物刺激来触发分区的破裂。通常,生物触发物类似于化学触发物,但许多实例使用生物分子或在生命系统中常见的分子,如酶、肽、糖类、脂肪酸、核酸等。例如,分区可以由包含具有肽交联的聚合物的材料制成,该肽交联对由特异性蛋白酶引起的裂解是敏感的。更具体地,一个实例可以包括由包含gflgk肽交联的材料制成的分区。在加入生物触发物如蛋白酶组织蛋白酶b时,壳壁的肽交联被裂解并释放胶囊的内容物。在其他情况下,蛋白酶可以被热活化。在另一实例中,分区包含含有纤维素的组分。水解酶壳聚糖的加入用作对纤维素键的裂解、包含壳聚糖的分区的组分的解聚以及其内部内容物的释放的生物触发物。
c.热刺激
当施加热刺激时,也可以诱使分区释放其内容物。温度的变化可引起分区的多种变化。热的变化可以导致分区的熔化以使得分区的一部分崩解,或乳液的破裂。在其他情况下,热可以增加分区的内部组分的内压,使得分区破裂或爆破。在另一些情况下,热可以将分区转变成皱缩的脱水状态。热也可以作用于用作构建分区的材料的热敏感性聚合酶。
在一个实例中,分区由包含热敏感性水凝胶的材料制成。在施加热,如高于35℃的温度时,水凝胶材料收缩。材料的突然收缩增大压力并破坏分区。
在一些情况下,用来产生分区的材料可以包含二嵌段聚合物或具有不同热敏性的两种聚合物的混合物。一种聚合物可能在施加热后特别可能收缩,而另一种则是更加热稳定的。当向这样的壳壁施加热时,热敏性聚合物可以收缩,而另一种则保持不变,从而引起孔隙的形成。在另一些情况下,用来产生分区的材料可以包含磁性纳米颗粒。暴露于磁场可导致热的生成,从而导致分区的破裂。
d.磁刺激
在用来产生分区的材料中包含磁性纳米颗粒可以允许触发分区的破裂,如上所述,以及使得能够将这些分区引导至其他分区(例如,将胶囊引导至阵列中的孔)。在一个实例中,将fe3o4纳米颗粒引入用来产生分区的材料中在振荡磁场刺激的存在下触发破裂。
e.电和光刺激
分区也可由于电刺激而破裂。类似于前一节中描述的磁性颗粒,电敏感性颗粒可以允许分区的触发破裂以及其他功能,如在电场中的对齐或氧化还原反应。在一个实例中,由包含电敏感性材料的材料制成的分区在电场中对齐,使得可以控制内部试剂的释放。在其他实例中,电场可以在可增大孔隙率的分区内诱发氧化还原反应。
光刺激也可以用于破坏分区。许多光触发物是可能的,并可包括使用多种分子(如纳米颗粒和能够吸收特定范围波长的光子的生色团)的系统。例如,金属氧化物涂层可以用来产生某些分区。对涂覆有sio2/tio2的分区的紫外线照射可导致分区壁的崩解。在又一实例中,可以在用来产生分区的材料中引入光开关材料(photoswitchablematerials),如偶氮苯基团。在施加紫外线或可见光时,诸如这些的化学物质在光子吸收时经历可逆的顺式至反式异构化。在该方面,光开关的引入导致分区的一部分的崩解,或分区的一部分的孔隙率的增大。
f.刺激的施加
本公开内容的装置、方法、组合物、系统和试剂盒可以与提供这样的触发物或刺激的任何设备或装置组合使用。例如,如果刺激是热刺激,则装置可以与加热的或热控制的板组合使用,其允许对孔的加热并可诱发胶囊的破裂。对于热刺激可以使用诸多热传递方法中的任何方法,包括但不限于通过辐射传热、对流传热或传导传热施加热。在其他情况下,如果刺激是生物酶,则该酶可以注入到装置中,使得它沉积至各个孔中。在另一方面,如果刺激是磁场或电场,则装置可与磁板或电板组合使用。
ix.应用
a.多核苷酸测序
通常,本文提供的方法和组合物可用于制备多核苷酸片段以用于下游应用如测序。测序可以通过任何可用的技术进行。例如,测序可以通过经典sanger测序方法进行。测序方法还可以包括:高通量测序、焦磷酸测序、合成测序、单分子测序、纳米孔测序、连接测序、杂交测序、rna-seq(illumina)、数字基因表达(helicos)、下一代测序、单分子合成测序(smss)(helicos)、大规模平行测序、克隆单分子阵列(solexa)、鸟枪法测序、maxim-gilbert测序、引物步移法以及本领域中已知的任何其他测序方法。
在一些情况下,对不同数目的片段进行测序。例如,在一些情况下,对约30%-90%的片段进行测序。在一些情况下,对约35%-85%、40%-80%、45%-75%、50%-70%、55%-65%或50%-60%的片段进行测序。在一些情况下,对至少约30%、40%、50%、60%、70%、80%或90%的片段进行测序。在一些情况下,对少于约30%、40%、50%、60%、70%、80%或90%的片段进行测序。
在一些情况下,装配来自片段的序列以提供关于比单个序列读取值更长的原始靶多核苷酸的连续区域的序列信息。单个序列读取值可以是约10-50、50-100、100-200、200-300、300-400个或更多个核苷酸的长度。
条形码标签的身份可用来排列来自单个片段的序列以及区分单元型。例如,在单个片段的分区过程中,可以将亲本多核苷酸片段分隔至不同的分区中。随着分区数目的增加,来自母本和父本单元型两者的片段包含在同一分区内的可能性变得小到可以忽略不计。因此,可以装配并排列来自同一分区中的片段的序列读取值。
b.多核苷酸取相
本公开内容还提供了用于以可使得能够生成取相或连接信息的方式制备多核苷酸片段的方法和组合物。这样的信息可以允许检测序列中的连接的遗传变异,包括被长多核苷酸段隔开的遗传变异(例如,snp、突变、插入缺失(indel)、拷贝数变异、颠换、易位、倒位等)。术语“插入缺失”是指导致共定位的插入和缺失以及核苷酸的净增加或损失的突变。“微插入缺失(microindel)”是导致1-50个核苷酸的净增加或损失的插入缺失。这些变异可能以顺式或反式关系存在。在顺式关系中,两个或更多个遗传变异存在于同一多核苷酸或链中。在反式关系中,两个或更多个遗传变异存在于多个多核苷酸分子或链上。
本文提供的方法可以用来确定多核苷酸取相。例如,可以对多核苷酸样品(例如,横跨给定基因座或多个基因座的多核苷酸)进行分区以使得每个分区存在多核苷酸的至多一个分子。然后可以对多核苷酸进行片段化、条形码化和测序。可以检查序列的遗传变异。检测到用两个不同条形码标记的同一序列中的遗传变异可以指示这两个遗传变异源自dna的两条单独的链,反映出反式关系。相反地,检测到用相同条形码标记的两个不同的遗传变异可以指示这两个遗传变异来自dna的同一条链,反映出顺式关系。
相位信息对多核苷酸片段的表征可能至关重要,尤其是当多核苷酸片段源自患有或疑似患有特定疾病或病症(例如,遗传性隐性疾病,如囊性纤维化、癌症等)或处于其风险中的受试者时。该信息可以能够区分以下可能性:(1)两个遗传变异位于dna的同一条链上的同一基因内,以及(2)两个遗传变异位于同一基因内但位于dna的单独的链上。可能性(1)可以指示该基因的一个拷贝是正常的并且该个体没有该疾病,而可能性(2)可以指示该个体具有或将发展成该疾病,尤其是当这两个遗传变异在存在于同一基因拷贝内时损害基因的功能时。类似地,相位信息还可以能够区分以下可能性:(1)两个遗传变异,各自位于dna的同一条链上的不同基因内,以及(2)两个遗传变异,各自位于不同基因内但位于dna的单独的链上。
c.从少量细胞对多核苷酸进行测序
本文提供的方法还可以用来以使得能够获得细胞特异性信息的方式制备细胞内含有的多核苷酸。该方法使得能够从极小的样品如包含约10-100个细胞的样品检测遗传变异(例如,snp、突变、插入缺失、拷贝数变异、颠换、易位、倒位等)。在一些情况下,在本文描述的方法中可以使用约1、5、10、20、30、40、50、60、70、80、90或100个细胞。在一些情况下,在本文描述的方法中可以使用至少约1、5、10、20、30、40、50、60、70、80、90或100个细胞。在其他情况下,在本文描述的方法中可以使用至多约5、10、20、30、40、50、60、70、80、90或100个细胞。
在一个实例中,方法包括对细胞样品(或粗细胞提取物)进行分区以使得每个分区存在至多一个细胞(或一个细胞的提取物),裂解细胞,通过本文所述的任何方法对细胞内包含的多核苷酸进行片段化,将片段化的多核苷酸附接至条形码,合并,并测序。
如本文其他部分所述,条形码和其他试剂可以包含在分区(例如,胶囊)内。这些胶囊可以在细胞加载之前、之后或同时加载到另一分区(例如,孔)内,使得每个细胞与不同的胶囊接触。该技术可以用来将独特条形码附接至从每个细胞获得的多核苷酸。然后可以将所得的标记的多核苷酸合并且测序,并可以使用条形码追踪多核苷酸的起源。例如,可以确定具有相同条形码的多核苷酸起源于相同细胞,同时可以确定具有不同条形码的多核苷酸起源于不同细胞。
本文描述的方法可以用于检测致癌突变在整个癌性肿瘤细胞群体中的分布。例如,一些肿瘤细胞可以具有癌基因(例如,her2、braf、egfr、kras)在两个等位基因中的突变或扩增(纯合的),另外一些肿瘤细胞可以具有在一个等位基因中的突变(杂合的),而再一些肿瘤细胞可能不具有突变(野生型)。本文所述的方法可以用来检测这些差异,并且还可以量化纯合、杂合和野生型细胞的相对数目。例如,这样的信息可用于对特定癌症进行分期和/或用于随时间监测癌症的进展及其治疗。
在一些实例中,本公开内容提供了鉴别两个不同癌基因(例如,kras和egfr)中的突变的方法。如果相同细胞包含具有两个突变的基因,这可以指示癌症的更具侵袭性的形式。与此相反,如果突变位于两个不同的细胞中,这可以指示该癌症是更加良性的或不到晚期。
d.基因表达的分析
本公开内容的方法可适用于处理样品以用于检测基因表达的变化。样品可包含细胞、mrna或由mrna反转录的cdna。样品可以是包含来自数个不同细胞或组织的提取物的合并样品,或者包含来自单个细胞或组织的提取物的样品。
可将细胞直接置于分区(例如,微孔)中并裂解。裂解后,可使用本发明的方法对细胞的多核苷酸进行片段化和条形码化以供测序。多核苷酸也可以在将其引入在本发明的方法中使用的分区中之前从细胞提取。mrna的逆转录可在本文所述的分区中,或在这样的分区的外部进行。cdna测序可提供随时间或在暴露于特定条件后特定细胞中的特定转录物的丰度的指示。
上面提出的方法相比于当前的多核苷酸处理方法提供了几个优势。第一,操作者之间的可变性大大降低。第二,该方法可在具有低成本并可容易地制造的微流体装置中进行。第三,靶多核苷酸的受控片段化使使用者能制备具有确定和合适长度的多核苷酸片段。这有助于对多核苷酸进行分区,并且由于过大片段的存在,还减少了序列信息丢失的程度。所述方法和系统还提供了保持所处理的多核苷酸的完整性的简易工作流程。此外,限制酶的使用使得使用者能够产生dna突出端(“粘端”),其可针对与衔接子和/或条形码的相容性而设计。
e.从细胞对多核苷酸如染色体的分区
在一个实例中,本公开内容提供的方法、组合物、系统、装置和试剂盒可用于从细胞对多核苷酸(包括全部染色体)进行分区。在一个实例中,将单个细胞或多个细胞(例如,2、10、50、100、1000、10000、25000、50000、100000、500000、1000000个或更多个细胞)加载至具有裂解缓冲液和蛋白酶k的容器中,并温育指定的一段时间。多个细胞的使用将使得能够进行多核苷酸取相,例如,通过将每个待分析的多核苷酸在其自己的分区中进行分区。
温育后,例如通过将细胞裂解物流动聚焦至胶囊中,对细胞裂解物进行分区。如果将要进行取相,则进行流动聚焦,使得每个胶囊仅包含单个分析物(例如,单个染色体),或仅包含任何特定染色体的单个拷贝(例如,第一染色体的一个拷贝和第二染色体的一个拷贝)。在一些情况下,可将多个染色体包封在相同的胶囊内,只要这些染色体不是相同的染色体。在温和流动下进行包封,以使多核苷酸的剪切减至最小。胶囊可以是多孔的,以允许洗涤胶囊的内容物以及将试剂引入胶囊中,同时将多核苷酸(例如,染色体)保持在胶囊内。然后可根据本公开内容中提供的或本领域已知的任何方法,处理包封的多核苷酸(例如,染色体)。胶囊壳保护包封的多核苷酸(例如,染色体)免遭剪切和进一步的降解。当然,也可将该方法应用于任何其他的细胞组分。
如上所述,胶囊壳可用于保护多核苷酸免遭剪切。然而,胶囊也可用作分区,以能够进行多核苷酸或其他分析物的区室化剪切。例如,在一些情况下,多核苷酸可包封在胶囊内,随后经历超声剪切或任何其他合适的剪切。胶囊壳可配置为在剪切下保持完整,而包封的多核苷酸可受到剪切,但仍将保留在胶囊内。在一些情况下,水凝胶小滴可用于达到相同的目的。
f.癌症突变检测和法医学
本文所述的通过分区中基于扩增的条形码化方案的条形码化方法可用于由降解的样品如福尔马林固定、石蜡包埋的(ffpe)组织切片产生条形码文库。本文所述的方法可以能够鉴定分区内的源自相同初始分子的所有扩增子。确实,通过采用分区条形码化,可以保留关于独特起始多核苷酸的信息。由于可以区分来自不同的原始分子的扩增子,因此这样的鉴定可有助于文库复杂性的确定。此外,本文所述的方法可允许评估独特的覆盖,这可有助于确定变体判定(calling)灵敏度。这些优势在癌症突变检测和法医学中可能是特别有用的。
g.低输入dna应用(循环肿瘤细胞(ctc)测序)
本文所述的条形码化方法可用于低多核苷酸输入应用,例如,循环肿瘤细胞(ctc)的核酸的测序。例如,在分区内进行的本文所述的malbac方法可有助于在低多核苷酸输入应用中获得良好的数据质量和/或有助于过滤掉扩增错误。
x.试剂盒
在一些情况下,本公开内容提供了包含用于产生分区的试剂的试剂盒。该试剂盒可包含用于产生分区和在分区内的分区的任何合适的试剂和说明。
在一个实例中,试剂盒包含用于在乳液中的小滴内产生胶囊的试剂。例如,试剂盒可包含用于产生胶囊的试剂、用于产生乳液的试剂和关于将胶囊引入到乳液的小滴中的说明。如本公开内容通篇所说明的,可将任何合适的物质掺入小滴和/或胶囊中。本公开内容的试剂盒还可提供这些物质中的任何物质,如预分区的包含条形码的多核苷酸。相似地,如本公开内容通篇所述,可将胶囊设计成在施加刺激时释放其内容物至乳液的小滴中。
在另一个实例中,试剂盒包含用于产生在胶囊内的胶囊的试剂。例如,试剂盒可包含用于产生内层胶囊的试剂、用于产生外层胶囊的试剂和关于产生在胶囊内的胶囊的说明。如本公开内容通篇所说明的,可将任何合适的物质掺入到内层和/或外层胶囊中。本公开内容的试剂盒还可提供这些物质中的任何物质,如预分区的包含条形码的多核苷酸。相似地,如本公开内容通篇所述,可将内层胶囊设计成在施加刺激时释放其内容物至外层胶囊中。
xi.装置
在一些情况下,本公开内容提供了包含用于处理分析物的分区的装置。装置可以是如本公开内容的其他地方所述的微孔阵列或微斑点阵列(microspotarray)。装置可以以包含任何合适的分区的形式形成。在一些情况下,装置包含多个孔,或多个斑点。当然,装置中的任何分区也可容纳其他分区,如胶囊、乳液中的小滴等。
装置可由任何合适的材料形成。在一些实例中,装置由选自熔融二氧化硅、钠钙玻璃、硼硅酸盐玻璃、聚(甲基丙烯酸甲酯)、蓝宝石、硅、锗、环烯烃共聚物、聚乙烯、聚丙烯、聚丙烯酸酯、聚碳酸酯、塑料及其组合的材料形成。
在一些情况下,装置包含供流体向分区内和在分区间流动的通道。可使用任何合适的通道。装置可包含流体入口和流体出口。入口和出口可附接至液体处理装置,以将物质引入装置中。可在引入任何物质之前或之后对装置进行密封。
可在装置的不同部分中使用亲水性和/或疏水性的材料。例如,在一些情况下,本公开内容的装置包含分区,该分区具有包含亲水性材料的内表面。在一些情况下,分区的外表面包含疏水性材料。在一些情况下,流体流动路径用亲水性或疏水性材料包覆。
可以理解,本公开内容提供了本文所述的任何组合物、文库、方法、装置和试剂盒用于特定用途或目的(包括本文所述的各种应用、用途和目的)的应用。例如,本公开内容提供了本文所述的组合物、方法、文库、装置和试剂盒在对物质进行分区、对寡核苷酸进行分区、物质从分区中的刺激选择性释放、在分区中进行反应(例如,连接和扩增反应)、进行核酸合成反应、对核酸进行条形码化、为测序准备多核苷酸、多核苷酸测序、核苷酸取相、从少量细胞对多核苷酸进行测序、分析基因表达、从细胞对多核苷酸进行分区、突变检测、神经系统病症诊断、糖尿病诊断、胎儿非整倍性诊断、癌症突变检测和法医学、疾病检测、医学诊断、低输入核酸应用如循环肿瘤细胞(ctc)测序或其组合中的用途。
本发明提供了包括但不限于以下实施方案:
1.一种包含至少约1,000个珠子的文库,其中所述至少约1,000个珠子中的每个珠子包含不同的条形码序列。
2.如实施方案1所述的文库,其中所述不同的条形码序列包括在包含固定序列和/或针对测序引物的退火序列的多核苷酸中。
3.如实施方案1所述的文库,其中所述不同的条形码序列为至少约5个核苷酸的长度。
4.如实施方案1所述的文库,其中所述不同的条形码序列为至少约10个核苷酸的长度。
5.如实施方案1所述的文库,其中所述不同的条形码序列是随机多核苷酸序列。
6.如实施方案1所述的文库,其中所述不同的条形码序列是组合地生成的。
7.如实施方案1所述的文库,其中所述1,000个珠子中的每一个包含所述不同的条形码序列的多个拷贝。
8.如实施方案1所述的文库,其中所述1,000个珠子中的每一个包含所述不同的条形码序列的至少约100,000个拷贝。
9.如实施方案1所述的文库,其中所述1,000个珠子中的每一个包含所述不同的条形码序列的至少约1,000,000个拷贝。
10.如实施方案1所述的文库,其中所述1,000个珠子中的每一个包含所述不同的条形码序列的至少约10,000,000个拷贝。
11.如实施方案1所述的文库,其进一步包含两个或更多个包含相同的条形码序列的珠子。
12.如实施方案1所述的文库,其中所述1,000个珠子中的至少两个珠子包含相同的条形码序列。
13.如实施方案1所述的文库,其中所述至少约1,000个珠子包含至少约10,000个珠子。
14.如实施方案1所述的文库,其中所述至少约1,000个珠子包含至少约100,000个珠子。
15.如实施方案1所述的文库,其中所述文库包含至少约1,000个不同的条形码序列。
16.如实施方案1所述的文库,其中所述文库包含至少约10,000个不同的条形码序列。
17.如实施方案1所述的文库,其中所述文库包含至少约100,000个不同的条形码序列。
18.如实施方案1所述的文库,其中所述文库包含至少约1,000,000个不同的条形码序列。
19.如实施方案1所述的文库,其中所述文库包含至少约2,500,000个不同的条形码序列。
20.如实施方案1所述的文库,其中所述文库包含至少约5,000,000个不同的条形码序列。
21.如实施方案1所述的文库,其中所述文库包含至少约10,000,000个不同的条形码序列。
22.如实施方案1所述的文库,其中所述文库包含至少约25,000,000个不同的条形码序列。
23.如实施方案1所述的文库,其中所述文库包含至少约50,000,000个不同的条形码序列。
24.如实施方案1所述的文库,其中所述文库包含至少约100,000,000个不同的条形码序列。
25.如实施方案1所述的文库,其中所述至少约1,000个珠子跨多个分区分布。
26.如实施方案25所述的文库,其中所述分区是乳液的小滴。
27.如实施方案1或8-10中任一项所述的文库,其中所述1,000个珠子中的每一个珠子包括在不同的分区中。
28.如实施方案27所述的文库,其中所述不同的分区是乳液的小滴。
29.如实施方案1所述的文库,其中所述1,000个珠子中的两个或更多个珠子包括在不同的分区中。
30.如实施方案29所述的文库,其中所述不同的分区是乳液的小滴。
31.如实施方案1所述的文库,其中所述1,000个珠子是水凝胶珠子。
32.一种合成包含条形码序列的多核苷酸的文库的方法,所述方法包括:
a.合成多个包含条形码序列的多核苷酸;
b.将所述多核苷酸分隔至多个分区内,从而生成分区的多核苷酸;
c.扩增所述分区的多核苷酸,从而生成扩增的多核苷酸;以及
d.分离包含扩增的多核苷酸的分区。
33.如实施方案32所述的方法,其中所述合成包括在偶联反应中包括腺嘌呤、胸腺嘧啶、鸟嘌呤和胞嘧啶的混合物。
34.如实施方案32所述的方法,其中所述分隔包括进行有限稀释,从而生成稀释的多核苷酸。
35.如实施方案34所述的方法,其中所述分隔进一步包括对所述稀释的多核苷酸进行分区。
36.如实施方案32所述的方法,其中所述分区中的每一个平均包含约1个包含条形码序列的多核苷酸。
37.如实施方案32所述的方法,其中所述分区中的每一个平均包含约0.5个包含条形码序列的多核苷酸。
38.如实施方案32所述的方法,其中所述分区中的每一个平均包含约0.1个包含条形码序列的多核苷酸。
39.如实施方案32所述的方法,其中所述扩增通过选自聚合酶链反应、不对称聚合酶链反应、乳液pcr(epcr)、包括使用珠子的epcr、包括使用水凝胶的epcr、基于退火和成环的多重扩增循环(malbac)、单引物等温扩增及其组合的方法进行。
40.如实施方案32所述的方法,其中所述扩增是使用rna引物进行的。
41.如实施方案40所述的方法,其进一步包括使所述扩增的多核苷酸暴露于rna酶h。
42.如实施方案32所述的方法,其中所述包含条形码序列的多核苷酸中的每一个是malbac引物。
43.如实施方案32所述的方法,其中所述分离是通过流动辅助的分选进行的。
44.如实施方案32所述的方法,其中由多核苷酸形成发夹结构,该多核苷酸选自所述包含条形码序列的多核苷酸和所述扩增的多核苷酸。
45.如实施方案44所述的方法,其进一步包括在未退火的区域内切割所述发夹结构。
46.如实施方案32所述的方法,其中选自所述包含条形码序列的多核苷酸、所述分区的多核苷酸和所述扩增的多核苷酸的多核苷酸附接至珠子上。
47.如实施方案32所述的方法,其进一步包括使所述扩增的多核苷酸与部分互补序列退火。
48.如实施方案47所述的方法,其中所述部分互补序列包含条形码序列。
49.如实施方案32所述的方法,其进一步包括将所述扩增的多核苷酸中的至少一个附接至靶序列。
50.如实施方案49所述的方法,其中所述靶序列被片段化。
51.如实施方案50所述的方法,其中所述靶序列通过选自机械剪切和酶处理的方法被片段化。
52.如实施方案51所述的方法,其中所述机械剪切由超声诱导。
53.如实施方案51所述的方法,其中所述酶选自限制酶、片段化酶和转座酶。
54.如实施方案49所述的方法,其中所述附接通过选自连接和扩增的方法进行。
55.如实施方案54所述的方法,其中所述扩增是用malbac引物进行的malbac扩增,从而生成malbac扩增产物。
56.如实施方案55所述的方法,其中所述malbac引物包含所述扩增的多核苷酸。
57.如实施方案55所述的方法,其中所述malbac引物包含不是所述扩增的多核苷酸的多核苷酸。
58.如实施方案57所述的方法,其进一步包括将所述malbac扩增产物附接至所述扩增的多核苷酸。
59.如实施方案32所述的方法,其中所述分区选自小滴、胶囊和孔。
60.如实施方案32所述的方法,其中所述文库包含至少约1,000个不同的条形码序列。
61.如实施方案32所述的方法,其中所述分区包含相同的包含条形码序列的多核苷酸的多个拷贝。
62.如实施方案32所述的方法,其中所述包含条形码序列的多核苷酸进一步包含选自固定序列、针对测序引物的退火序列和对于与靶多核苷酸的连接相容的序列的序列。
63.如实施方案32所述的方法,其中所述文库包含至少约100,000个不同的条形码序列。
64.如实施方案32所述的方法,其中所述文库包含至少约500,000个不同的条形码序列。
65.如实施方案32所述的方法,其中所述文库包含至少约1,000,000个不同的条形码序列。
66.如实施方案32所述的方法,其中所述文库包含至少约2,500,000个不同的条形码序列。
67.如实施方案32所述的方法,其中所述文库包含至少约5,000,000个不同的条形码序列。
68.如实施方案32所述的方法,其中所述文库包含至少约10,000,000个不同的条形码序列。
69.如实施方案32所述的方法,其中所述文库包含至少约25,000,000个不同的条形码序列。
70.如实施方案32所述的方法,其中所述文库包含至少约50,000,000个不同的条形码序列。
71.如实施方案32所述的方法,其中所述文库包含至少约100,000,000个不同的条形码序列。
72.如实施方案1-31中任一项所述的文库或如实施方案32-71中任一项所述的方法在对物质进行分区、对寡核苷酸进行分区、物质从分区中的刺激选择性释放、在分区中进行反应(例如,连接和扩增反应)、进行核酸合成反应、对核酸进行条形码化、为测序准备多核苷酸、多核苷酸测序、突变检测、神经系统病症诊断、糖尿病诊断、胎儿非整倍性诊断、癌症突变检测和法医学、疾病检测、医学诊断、低输入核酸应用、循环肿瘤细胞(ctc)测序、多核苷酸取相、从少量细胞对多核苷酸进行测序、分析基因表达、从细胞对多核苷酸进行分区或其组合中的用途。
实施例
实施例1:通过不对称pcr和添加部分互补通用序列产生包含条形码序列的叉状衔接子的文库
本实施例提供了用于制备包含与下一代测序技术(例如,illumina)兼容的条形码序列的叉状衔接子的方法。在该实施例中,条形码置于位置207中,如图2所示。
参照图4,合成包含第一固定区域402、条形码区域403和第一测序引物区域404的单链衔接子-条形码多核苷酸序列401。条形码区域403是通过在每一偶联步骤中包含等摩尔浓度的a、g、t和c而合成的七个核苷酸的随机序列。
合成后,将单链衔接子-条形码多核苷酸401稀释到油包水乳液中的水性小滴内,使得每个小滴平均包含0.1个多核苷酸。该小滴还包含用于通过不对称pcr扩增单链衔接子-条形码多核苷酸401的试剂(例如,聚合酶、引物、dntp、缓冲液、盐)和dna嵌入染料(例如,溴化乙锭)。反向引物以多于正向引物的量存在,或反之亦然,使得不对称扩增能够进行。扩增该多核苷酸,并且该反应继续进行通过指数期扩增410(产生双链产物405)和线性期扩增411(产生单链产物406)。
将小滴在荧光辅助细胞分选仪(facs)412上分选以收集包含扩增的多核苷酸的小滴。将部分互补通用序列407添加至分区以产生部分退火的叉状结构413。部分互补通用序列407包含第二固定区域408和第二测序引物区域409,后者包含与待测序的多核苷酸靶标上的a突出端(未示出)相容的t突出端。
实施例2:用片段化酶(fragmentase)进行的片段化和条形码化
如实施例1中所述或通过本公开内容中描述的任何其他方法合成、分区、扩增并分选包含第一固定区域402、条形码区域403和第一测序引物区域404的单链衔接子-条形码多核苷酸序列(例如,图4:401)。在包含单链衔接子-条形码多核苷酸序列的小滴上进行界面聚合,以产生多个包含单链衔接子-条形码多核苷酸序列406的文库的胶囊,其中文库中的每一个(或大多数)序列在其各自的条形码区域403的序列上不同。因此,产生了包封的单链衔接子-条形码多核苷酸的文库。
制备了两种混合物。混合物z1包含靶多核苷酸(即,待片段化和条形码化的多核苷酸)、片段化酶(例如,nebnextdsdnafragmentase)和部分互补通用序列(例如,图4:407)。第二混合物z2包含如上所述产生的包封的单链衔接子-条形码多核苷酸的文库,以及足以活化片段化酶的浓度的氯化镁。混合物z1、z2,或者z1和z2两者还包含t4聚合酶、taq聚合酶和热稳定连接酶。
将混合物z1和z2合并,并且根据本公开内容的其他地方所述的方法,如流动聚焦,形成在胶囊内的胶囊。图5示出了根据上述方法产生的在胶囊内的胶囊。外层胶囊501包含内层胶囊502和介质504。内层胶囊502是包封的单链衔接子-条形码多核苷酸的文库中的一员。因此,内层胶囊502包含单链衔接子-条形码多核苷酸503的多个拷贝,后者可用于将相同的条形码附接至分区如外层胶囊501内的多核苷酸。
介质504包含上述混合物z1和混合物z2的内容物。更具体而言,介质504包含靶多核苷酸505、部分互补通用序列506以及包含片段化酶、t4聚合酶、taq聚合酶、热稳定连接酶、氯化镁和合适的缓冲液的酶混合物507。
在产生胶囊内的胶囊并将胶囊内的胶囊暴露于合适的条件后,酶处理靶多核苷酸。更具体而言,片段化酶对靶多核苷酸进行片段化并且t4聚合酶使得片段化的靶多核苷酸的末端成为平端。然后热灭活片段化酶和t4聚合酶,并使用刺激使内层胶囊502破裂,释放其内容物至外层胶囊501中。taq聚合酶向片段化的、平端化的靶多核苷酸上添加3’-a突出端。单链衔接子-条形码多核苷酸503与部分互补通用序列506杂交,从而形成具有与在片段化的靶多核苷酸上的3’-a突出端相容的3’-t突出端的叉状衔接子。热稳定连接酶将叉状衔接子连接至片段化的靶多核苷酸,从而产生条形码化的靶多核苷酸。然后使外层胶囊501破裂,将来自所有外层胶囊的样品合并,并对靶多核苷酸进行测序。随后在测序前,根据需要可进行另外的准备步骤(例如,本体扩增(bulkamplification)、大小选择等)。
在一些情况下,混合物z1包含部分互补通用序列506的多个版本,其中每个版本具有其自身的样品特异性条形码。
此外,尽管上述实施例使用了热稳定连接酶来将包含条形码序列的叉状衔接子附接至靶多核苷酸,但是也可使用pcr来完成该步骤,如本公开内容的其他地方所述。
实施例3:通过超声处理进行的片段化和条形码化
如实施例2中所述或通过本公开内容中描述的任何其他合适的方法产生包封的单链衔接子-条形码多核苷酸的文库。将靶多核苷酸(即,待片段化的多核苷酸)分区到胶囊中。将包含靶多核苷酸的胶囊配置成能抵抗超声应力。使包含靶多核苷酸的胶囊暴露于超声应力(例如,covaris聚焦超声发生器(covarisfocused-ultrasonicator)),并对靶多核苷酸进行片段化,从而产生片段化的靶多核苷酸胶囊。
制备混合物z1,其包含包封的单链衔接子-条形码多核苷酸(例如,图4:406)的文库、片段化的靶多核苷酸胶囊、部分互补通用序列(例如,图4:407)、酶混合物(t4聚合酶、taq聚合酶和热稳定连接酶)和合适的缓冲液。根据本公开内容的其他地方所述的方法,如流动聚焦,产生在胶囊内的胶囊。
图6示出了根据上述方法产生的在胶囊内的胶囊。外层胶囊601包含多个内层胶囊602和605以及介质604。内层胶囊602和605分别包括包含单链衔接子-条形码多核苷酸603的胶囊和包含片段化的靶多核苷酸606的胶囊。内层胶囊602包含单链衔接子-条形码多核苷酸603的多个拷贝,后者可用于将相同的条形码附接至分区内的多核苷酸,诸如包含在内层胶囊605内的片段化的多核苷酸606。
介质604含有上述混合物z1的内容物。更具体而言,介质604包含部分互补通用序列607、酶混合物(t4聚合酶、taq聚合酶和热稳定连接酶)608和合适的缓冲液。
使包含片段化的靶多核苷酸606的内层胶囊605暴露于刺激以使其破裂并释放其内容物至外层胶囊601的内容物中。t4聚合酶使得片段化的靶多核苷酸的末端成为平端;taq聚合酶向片段化的、平端化的靶多核苷酸上添加3’-a突出端。然后热灭活t4聚合酶和taq聚合酶,并且施加刺激以将内层胶囊602的内容物释放至外层胶囊601中。单链衔接子-条形码多核苷酸603与部分互补通用序列607杂交,从而形成具有与片段化的靶多核苷酸上的3’-a突出端相容的3’-t突出端的叉状衔接子。热稳定连接酶将叉状衔接子连接至片段化的靶多核苷酸,从而产生条形码化的靶多核苷酸。然后使外层胶囊601破裂,将来自所有外层胶囊的样品合并,并对靶多核苷酸进行测序。
如实施例2中所述,在一些情况下,z1可包含部分互补通用序列607的多个版本。此外,尽管该实施例示出了通过使用热稳定连接酶对靶多核苷酸进行加条形码,但也可以使用pcr来完成该步骤。
实施例4:通过单引物等温扩增(spia)和限制消化产生叉状衔接子
本实施例示出了通过spia和限制消化合成叉状衔接子。图7提供了可根据本实施例的方法产生的产物(或中间体)的实例。参照图7,示出了发夹衔接子701(seqidno:2),其可用作如本公开内容的其他地方所述的叉状衔接子的前体。在该实施例中,使用spia将发夹衔接子合成为单链扩增产物。发夹衔接子701包含双链区域702、用于at连接的3’-t突出端703和可被限制酶切割的区域704(即,在位置33与34之间)。发夹衔接子可包含条形码区域和功能区域,诸如固定区域和用于测序引物退火的区域。
对衔接子的切割(例如,在位置33与34之间)产生了图8a中示出的叉状衔接子(seqidno:3-4)。通过引入与待切割的区域互补的寡核苷酸序列并将退火的衔接子暴露于限制酶来切割衔接子。图8a中示出的叉状衔接子区域与靶多核苷酸的连接产生了图8b中示出的结构(seqidno:5-6)。参照图8,图8b中的序列的加下划线部分包含具有3’-a突出端的靶多核苷酸,该3’-a突出端对于与图8a中示出的叉状衔接子的连接相容。
然后通过聚合酶链反应扩增图8b中所示的序列(seqidno:5-6)以产生图8c中所示的seqidno:7(seqidno:5的扩增产物)和seqidno:8(seqidno:6的扩增产物)。在图8c中,seqidno:7代表seqidno:5的扩增产物,其将第一固定序列(加下划线的5’部分)和第二固定序列(加下划线的3’部分)添加至seqidno:5。seqidno:8代表seqidno:6的扩增产物,其用不同的序列(加下划线的3’部分和加下划线的5’部分)替换seqidno:6的未杂交部分。此外,seqidno:8在多核苷酸的5’未杂交区域内包含六个核苷酸的条形码(tagtgc;加粗的)。因此扩增产物包含条形码化的靶多核苷酸序列(由111表示)、固定序列和条形码。
实施例5:通过单引物等温扩增(spia)和限制消化产生另外的叉状衔接子
本实施例示出了通过spia和限制消化合成如图9a中所示的叉状衔接子(seqidno:9-10),其中n代表a、t、g或c。图9b显示了单链形式的叉状衔接子(seqidno:11),其中该单链形式能够形成发夹结构。在星号指示的位置处切割发夹结构产生图9a中所示的叉状衔接子。
用于spia的模板将是图9c中所示的序列(seqidno:12)。在图9c中,“r”代表rna区域。图9d示出了由图9c中的序列形成的发夹结构。用聚合酶处理图9d中的序列(seqidno:12)以将核苷酸添加至3’末端,从而产生图9e中所示的序列(seqidno:13)。然后用rna酶h处理图9e中的序列(seqidno:13),该rna酶h降解与dna杂交的rna,从而产生图9f中的序列(seqidno:14)。
然后在seqidno:14上进行链置换spia。链置换扩增中的引物具有rrrrrrrrrrrrr(即,r13)的形式。该引物为rna引物,其比seqidno:14(即,n12)(图9f)的未杂交的3’末端长一个碱基。更具体而言,如图9f中所示,seqidno:14的3’末端含有十二个n核苷酸。该rna引物含有13个核苷酸。该rna引物的核苷酸2-13与seqidno:14的十二个未杂交的n核苷酸互补。该rna引物的核苷酸1与第一杂交的碱基(从3’至5’)(在这种情况下为t)互补。该rna引物置换a并产生图9g中所示的双链延伸产物(seqidno:15-16)。由于仅存在一条引物,因此该反应产生单链产物的多个拷贝。用rna酶h处理单链扩增产物以产生图9h中所示的单链扩增产物(seqidno:17)。图9i示出了该序列的5’-3’形式(seqidno:17)。图9j示出了该序列的发夹形式(seqidno:17)。
然后将图9j中示出的发夹衔接子连接至具有3’-a突出端的片段化的多核苷酸。通过添加与该区域互补的寡核苷酸并用限制酶切割,在图9j中由曲线分开的a与c残基之间切割发夹。这产生叉状衔接子。然后如实施例4中所述进行pcr扩增,以将固定区域和条形码添加到附接至靶多核苷酸的叉状衔接子上。
实施例6:通过指数pcr和杂交产生包含条形码的叉状衔接子
本实施例示出了通过杂交产生包含条形码的叉状衔接子。图10a示出了图8a中提供的示例性叉状衔接子。如实施例4中所述,可将该衔接子连接至靶多核苷酸,随后可进行扩增反应以添加另外的功能序列,包括条形码。然而,也可在将叉状衔接子附接至靶多核苷酸之前,将条形码(和其他功能序列)直接掺入到叉状衔接子中。例如,图10b示出了添加有第一固定区域(加下划线的)和七个核苷酸的条形码区域(加粗/加下划线的;“n”)的图10a的叉状衔接子。
图10b的条形码化的叉状衔接子如下产生:首先合成作为单链的seqidno:18。如本公开内容通篇所述,使用a、g、t和c的等摩尔混合物产生条形码区域中的多样性。如实施例1中所述进行基于小滴的pcr。然而,使用一条dna引物和一条rna引物来扩增小滴中的seqidno:18。如实施例1中所述,在嵌入染料的存在下进行扩增,并且分离包含扩增的seqidno:18的小滴。图10c示出了双链扩增产物。seqidno:19的加下划线部分是来源于rna引物的rna链。然后用rna酶h处理图10c中所示的序列,该rna酶h消化加下划线的rna区域,产生图10d中所示的构建体。为产生叉状构建体,将部分互补通用序列(seqidno:21)添加到图10d中所示的构建体中,从而产生图10e中所示的产物。采用该方法的优势在于,相比于由spia提供的多核苷酸的线性扩增,其使用了由指数pcr提供的显著更高水平的多核苷酸扩增。
实施例7:双索引方法
本实施例示出了合成用于双索引读取的条形码的方法。双索引读取是使用附接至每条链的条形码对双链片段的两条链的读取。图11示出了用于双索引方法的条形码的合成实例,以及在胶囊中的胶囊的配置中使用条形码的实例。
如图11a中所示,合成包含第一固定区域1102、第一条形码区域1103和第一测序引物区域1104的第一单链衔接子-条形码多核苷酸序列1101。平行地,如图11b中所示,合成包含第二固定区域1132、第二条形码区域1133和第二测序引物区域1134的第二单链衔接子-条形码多核苷酸序列1131。在一些情况下,条形码区域1103和1133具有相同的序列。在其他情况下,条形码区域1103和1133具有不同的序列或部分不同的序列。
合成后,平行地将单链衔接子-条形码多核苷酸1101(图11a)和1131(图11b)稀释到油包水乳液中的水性小滴中。该小滴还包含用于通过不对称pcr(例如,聚合酶、引物、dntp、缓冲液、盐)和dna嵌入染料(例如,溴化乙锭)分别扩增单链衔接子-条形码多核苷酸1101(图11a)和1131(图11b)的试剂。反向引物以多于正向引物的量存在,或反之亦然,从而使得不对称扩增能够进行。对多核苷酸1101(图11a)和1131(图11b)进行扩增,并且该反应继续进行分别通过指数期扩增1110(产生双链产物1105(图11a)和1135(图11b))以及线性期扩增1111(产生单链产物1106(图11a)和1136(图11b))。
将小滴在荧光辅助细胞分选仪(facs)1112上进行分选以收集包含扩增的多核苷酸的小滴。
然后分别在包含单链衔接子-条形码多核苷酸序列1106和1136的小滴上进行界面聚合,以产生两种类型的胶囊1120(图11a)和1150(图11b),每一种胶囊分别包含单链衔接子-条形码多核苷酸序列1106或1136中的一个。
制备两种混合物。混合物z1包含靶多核苷酸(即,待片段化并加条形码的多核苷酸)1170和片段化酶(例如,nebnextdsdnafragmentase)。第二混合物z2包含如上所述产生的胶囊1120和1180,以及足以活化片段化酶的浓度的氯化镁。混合物z1、z2,或者z1和z2两者还包含t4聚合酶、taq聚合酶和热稳定连接酶。
将混合物z1和z2合并,并且根据本公开内容的其他地方所述的方法,如流动聚焦,形成在胶囊内的胶囊。图11c示出了根据上述方法产生的在胶囊内的胶囊。外层胶囊1160包含胶囊1120和1150以及介质1190。因此,胶囊1120和1150各自分别包含单链衔接子-条形码多核苷酸1106和1136的多个拷贝,并可用于将条形码1103和1133附接至分区内的多核苷酸,诸如在外层胶囊1160的介质1190中的靶多核苷酸1170。
介质1190含有上述混合物z1和混合物z2的内容物。更具体而言,介质1190包含靶多核苷酸1170和包含片段化酶、t4聚合酶、taq聚合酶、热稳定连接酶、氯化镁和合适的缓冲液的酶混合物1180。
在产生胶囊内的胶囊并使胶囊内的胶囊暴露于合适的条件后,酶处理靶多核苷酸。更具体而言,片段化酶对靶多核苷酸进行片段化并且t4聚合酶使片段化的靶多核苷酸的末端成为平端。然后热灭活片段化酶和t4聚合酶,并使用刺激使胶囊1120和1150破裂,从而释放其内容物至外层胶囊1160的介质1190中。taq聚合酶向片段化的、平端化的靶多核苷酸上添加3’-a突出端。单链衔接子-条形码多核苷酸1106与单链衔接子-条形码多核苷酸1136杂交,从而形成包含条形码区域1103和1133的叉状衔接子,该叉状衔接子具有与在片段化的靶多核苷酸上的3’-a突出端(未示出)相容的3’-t突出端。热稳定连接酶将叉状衔接子连接到片段化的靶多核苷酸,从而产生条形码化的靶多核苷酸。然后使外层胶囊1160破裂,将来自所有外层胶囊的样品合并,并对靶多核苷酸进行测序。
此外,尽管上述实施例使用热稳定连接酶将包含条形码序列的叉状衔接子连接到靶多核苷酸,但如本公开内容的其他地方所述,也可使用pcr来完成该步骤。
实施例8:通过珠子乳液pcr和添加部分互补通用序列产生包含条形码序列的叉状衔接子
如图14a所示,合成包含第一固定区域1402、条形码区域1403和第一测序引物区域1404的单链衔接子-条形码序列1401。合成后,将单链衔接子-条形码序列1401稀释到油包水乳液中的水性小滴中,使得每个小滴平均包含1个多核苷酸。该小滴还包含通过光不稳定连接体连接至rna引物1406的一个或多个拷贝的第一珠子1405,该rna引物1406与包含在第一测序引物区域1404中的序列互补;与包含在第一固定区域1402中的序列(未示出)互补的dna引物;以及对于单链衔接子-条形码序列1401的扩增所必需的试剂(例如,聚合酶、dntp、缓冲液、盐)。对该多核苷酸进行扩增1407,产生均附接至第一珠子1405上的双链产物1408,以形成结构1420并且在溶液中(未示出)。
然后破乳,并将乳液组分合并以形成产物混合物。如图14b所示,然后将释放的珠子用合适的介质洗涤1409(通过离心)数次,用氢氧化钠(naoh)处理1410以使附接至第一珠子1405上的双链产物变性,随后进一步进行洗涤1411。在对结构1420进行变性1410和洗涤1411后,所得结构1430包含单链衔接子-条形码序列1401的单链互补序列1412,该单链互补序列1412包含互补固定区域1413、互补条形码区域1414和互补测序引物区域1415。如所示,互补测序引物区域1415包含rna引物1406。然后将结构1430重悬浮于合适的介质中。
接着,如图14c中所示,将包含与互补固定区域1413互补的dna多核苷酸1417的一个或多个拷贝的第二珠子1416添加至介质中。通过互补dna多核苷酸1417和单链互补序列1412的互补固定区域1413,第二珠子1416与单链互补序列1412结合。该单链互补序列现在在一个末端与第一珠子1405结合,而在其另一末端与第二珠子1416结合,以形成结构1440。
如图14d所示,然后使用甘油梯度对结构1440进行离心1418以将结构1440与不包含在结构1440中的结构1430分离。在第二珠子1416为磁性的情况下,可使用磁性分离作为替代手段。然后用naoh处理1419产物以使来自第二珠子1416的单链互补序列1412变性,从而导致结构1430再生。然后使结构1430经历数轮洗涤(通过离心),以去除第二珠子1416。附接至结构1430的单链互补序列1412代表单链条形码衔接子。
如图14e所示,可使用单链互补序列1412产生叉状衔接子。为产生叉状衔接子1450,然后用光使单链互补序列1412从结构1430中释放1424,随后与通用互补序列1426组合1425,或先与通用互补序列1426组合1425随后从结构1430中释放1424。为产生可连接的末端,使用rna酶h来消化单链互补序列1412的rna引物1406,并使用iis型限制酶在通用互补序列1426上产生单碱基t突出端。该t突出端与在待测序的多核苷酸靶标上的a突出端(未示出)相容。
实施例9:通过珠子乳液pcr和添加部分互补通用序列产生包含条形码序列的叉状衔接子
如图15a所示,合成包含第一固定区域1502、条形码区域1503和第一测序引物区域1504的单链衔接子-条形码序列1501。合成后,将单链衔接子-条形码序列1501稀释到油包水乳液中的水性小滴中,使得每个小滴平均包含1个多核苷酸。该小滴还包含通过光不稳定连接体连接至rna引物1506的一个或多个拷贝的第一珠子1505,该rna引物1506与包含在第一固定区域1502中的序列互补;与包含在第一测序引物区域1502中的序列(未示出)互补的dna引物;以及对于单链衔接子-条形码序列1501的扩增所必需的试剂(例如,聚合酶、dntp、缓冲液、盐)。对该多核苷酸进行扩增1507,产生均附接至第一珠子1505上的双链产物1508,以形成结构1520并且在溶液中(未示出)。
然后破乳,并将乳液组分合并以形成产物混合物。如图15b所示,然后将释放的珠子用合适的介质洗涤1509(通过离心)数次,用氢氧化钠(naoh)处理1510以使附接至第一珠子1505上的双链产物变性,随后进一步洗涤1511。在对结构1520进行变性1510和洗涤1511后,所得结构1430包含单链衔接子-条形码序列1501的单链互补序列1512,该单链互补序列1512包含互补固定区域1513、互补条形码区域1514和互补测序引物区域1515。如所示,互补测序引物区域1515包含rna引物1506。然后将结构1530重悬浮于合适的介质中。
接着,如图15c中所示,将包含与互补测序引物区域1515互补的dna多核苷酸1517的一个或多个拷贝的第二珠子1516添加至介质中。通过互补dna多核苷酸1517和单链互补序列1512的互补测序引物区域1515,第二珠子1416与单链互补序列1512结合。该单链互补序列现在在一个末端与第一珠子1505结合,而在其另一末端与第二珠子1516结合,以形成结构1540。
如图15d所示,然后使用甘油梯度对结构1540进行离心1518以将结构1540与不包含在结构1540中的结构1530分离。在第二珠子1516为磁性的情况下,可使用磁性分离作为替代手段。然后用naoh处理1519产物以使来自第二珠子1516的单链互补序列1512变性,从而导致结构1530再生。然后使结构1530经历数轮洗涤(通过离心),以去除第二珠子1516。附接至结构1530的单链互补序列1512代表单链条形码衔接子。
如图15e所示,可使用单链互补序列1512产生叉状衔接子。为产生叉状衔接子1550,然后任选地用光使单链互补序列1512从结构1530中释放1524,随后与通用互补序列1526组合1525。为产生可连接的末端,使用iis型限制酶在通用互补序列1526上产生单碱基t突出端。该t突出端与在待测序的多核苷酸靶标上的a突出端(未示出)相容。
实施例10:通过珠子乳液pcr产生叉状衔接子模板条形码序列以及由其衍生的衔接子
如图16所示,根据实施例8、实施例9中所述的方法,或本文所述的任何其他方法,产生包含与磁珠(1601)结合的单链衔接子-条形码序列1602的结构1600。接着,通过本文所述的方法,例如,界面聚合,将结构1600分区到胶囊(或可替代地,另一种乳液)1620中。胶囊1620还包含用于通过不对称pcr扩增单链衔接子-条形码序列1602的试剂(例如,聚合酶、引物、dntp、缓冲液、盐)。反向引物以多于正向引物的量存在,或反之亦然,从而使得不对称扩增能够进行。对单链衔接子-条形码序列1602进行扩增1603,并且该反应继续进行通过线性期扩增1604,这产生与单链条形码衔接子-模板1602互补的单链衔接子产物1605。在此时,胶囊1620既包含溶液中的单链衔接子1605又包含与磁珠(1601)结合的单链衔接子-条形码序列1602。然后通过磁性分离1606将胶囊1620与不包含珠子(并因此不包含模板1602和单链衔接子1605)的胶囊分离。可以使胶囊1620破裂并且如实施例9中所述产生叉状衔接子。
实施例11:用珠子乳液pcr加条形码以及用片段化酶进行片段化
如图17所示,根据实施例8、实施例9中所述的方法,或本文所述的任何其他方法,产生包含与磁珠(1701)结合的单链衔接子-条形码序列1702的结构1700。在包含结构1700的小滴上进行界面聚合,以产生包含通过光不稳定连接体附接至珠子1701上的单链衔接子-条形码序列1702的胶囊1704。
制备两种混合物。混合物z1包含靶多核苷酸(即,待片段化并加条形码的多核苷酸)、片段化酶(例如,nebnextdsdnafragmentase)和部分互补通用序列。第二混合物z2包含如上所述产生的胶囊1704,和足以活化片段化酶的浓度的氯化镁。混合物z1、z2,或者z1和z2两者还包含t4聚合酶、taq聚合酶和热稳定连接酶。
将混合物z1和z2合并,并且根据本公开内容的其他地方所述的方法,如流动聚焦,形成在胶囊内的胶囊。图17示出了根据上述方法产生的在胶囊内的胶囊。外层胶囊1703包含内层胶囊1704和介质1705。内层胶囊1704是包封的、与珠子结合的单链条形码衔接子的文库中的一员。因此,内层胶囊1704包含结构1700的多个拷贝,结构1700可用于产生游离的单链衔接子-条形码序列1702并将相同的条形码衔接子附接至分区如外层胶囊1703内的多核苷酸。
介质1705含有上述混合物z1和混合物z2的内容物。更具体而言,介质1705包含靶多核苷酸1706、部分互补通用序列1707以及包含片段化酶、t4聚合酶、taq聚合酶、热稳定连接酶、氯化镁和合适的缓冲液的酶混合物1708。
在产生胶囊内的胶囊并使胶囊内的胶囊暴露于合适的条件后,酶处理靶多核苷酸。更具体而言,片段化酶对靶多核苷酸进行片段化并且t4聚合酶使得片段化的靶多核苷酸的末端成为平端。然后热灭活片段化酶和t4聚合酶,并使用刺激使内层胶囊1704破裂,释放其内容物至外层胶囊1703中。taq聚合酶向片段化的、平端化的靶多核苷酸上添加3’-a突出端。单链衔接子-条形码序列1702与部分互补通用序列1707杂交,并通过光从珠子上释放,从而形成具有与在片段化的靶多核苷酸上的3’-a突出端相容的3’-t突出端的叉状衔接子。热稳定连接酶将叉状衔接子连接到片段化的靶多核苷酸,从而产生条形码化的靶多核苷酸。然后使外层胶囊1703破裂,将来自所有外层胶囊的样品合并,并对靶多核苷酸进行测序。在测序前,根据需要可进行另外的准备步骤(例如,本体扩增、大小选择等)。
在一些情况下,z1可包含部分互补通用序列1707的多个版本。此外,尽管该实施例示出了通过使用热稳定连接酶对靶多核苷酸加条形码,但也可以使用pcr完成该步骤。
实施例12:用珠子乳液pcr加条形码以及通过超声处理进行片段化
如图18所示,根据实施例8、实施例9中所述的方法,或本文所述的任何其他方法,产生包含与磁珠(1801)结合的单链衔接子-条形码序列1802的结构1800。在包含结构1800的小滴上进行界面聚合,以产生包含通过光不稳定连接体附接至珠子1801上的单链衔接子-条形码序列1802的胶囊1803。将靶多核苷酸(即,待片段化的多核苷酸)分区到胶囊1804中。将包含靶多核苷酸的胶囊1804配置成能抵抗超声应力。使包含靶多核苷酸的胶囊1804暴露于超声应力(例如,covaris聚焦超声发生器),并对靶多核苷酸进行片段化,从而产生片段化的靶多核苷酸胶囊。
制备混合物z1,其包含胶囊1803、片段化的靶多核苷酸胶囊1804、部分互补通用序列1805、酶混合物(t4聚合酶、taq聚合酶和热稳定连接酶)1806和合适的缓冲液。根据本公开内容的其他地方所述的方法,如流动聚焦,产生在胶囊内的胶囊。
图18示出了根据上述方法产生的在胶囊内的胶囊。外层胶囊1807包含胶囊1803和1804以及介质1808。内层胶囊1803和1804分别包括包含结构1800的胶囊和包含片段化的靶多核苷酸1809的胶囊。内层胶囊1803包含结构1800的多个拷贝,结构1800可用于产生游离的单链条形码衔接子1802并将相同的条形码衔接子附接至分区内的多核苷酸,诸如包含在内层胶囊1804内的片段化的多核苷酸1809。
介质1808含有上述混合物z1的内容物。更具体而言,介质1808包含部分互补通用序列1805、酶混合物(t4聚合酶、taq聚合酶和热稳定连接酶)1806和合适的缓冲液。
使包含片段化的靶多核苷酸1809的内层胶囊1804暴露于刺激,以使其破裂并释放其内容物至外层胶囊1807的内容物中。t4聚合酶使得片段化的靶多核苷酸的末端成为平端;taq聚合酶向片段化的、平端化的靶多核苷酸上添加3’-a突出端。然后热灭活t4聚合酶和taq聚合酶,并且施加刺激以将内层胶囊1803的内容物释放至外层胶囊1807中。单链衔接子-条形码序列1802与部分互补通用序列1805杂交,并且采用光使衔接子从珠子上释放,形成具有与在片段化的靶多核苷酸上的3’-a突出端相容的3’-t突出端的叉状衔接子。热稳定连接酶将该叉状衔接子连接至片段化的靶多核苷酸,从而产生条形码化的靶多核苷酸。然后使外层胶囊1807破裂,将来自所有外层胶囊的样品合并,并对靶多核苷酸进行测序。
在一些情况下,z1可包含部分互补通用序列1807的多个版本。此外,尽管该实施例示出了通过使用热稳定连接酶对靶多核苷酸加条形码,但也可以使用pcr完成该步骤。
实施例13:用基于退火和成环的多重扩增(malbac)进行的条形码化
如图19a所示,制备包含seqidno.22的引物。该引物包含条形码区域(表示为“条形码”)、引物测序区域(命名为“引发序列”)和可能包含a、t、c或g的任何组合的八个核苷酸的可变区域(表示为“nnnnnnnn”)。将图19中所示的引物与靶多核苷酸(由图19中的环表示)连同具有链置换活性的聚合酶(例如,vent、exo+deepvent、exo–deepvent)一起组合到分区(例如,胶囊、乳液的小滴等)内。在一些情况下,使用非链置换聚合酶(例如,taq、pfuultra)。然后对该分区进行malbac扩增。合适的malbac循环条件是已知的,并在例如,zong等人,science,338(6114),1622-1626(2012)中描述,该文献通过引用以其全文并入本文。
产生如图19b中所示的seqidno.23的环状malbac产物。环状malbac产物包含图19a中所示的原始引物、将在环中条形码化定向的靶多核苷酸以及与原始引物序列互补并杂交的区域。该分区被破坏并且回收内容物。在一些情况下,产生多个分区。这些分区被全体破坏,回收每一个分区的内容物,随后将其合并。
接着,用限制酶(例如,bfucl或相似的酶)处理图19b中示出的所产生的malbac产物以在malbac产物上产生4-碱基对的突出端(在这种情况下,为以斜体显示的gatc)。该结构由seqidno.24表示,并在图19c中示出。图19d中显示的seqidno.25的叉状衔接子包含与在malbac产物上产生的突出端互补的突出端(在这种情况下,为以斜体显示的ctag)。叉状衔接子与图19c中的malbac产物混合,并且这些互补区域杂交。使用热稳定连接酶将叉状衔接子和malbac产物连接在一起,以形成图19e中seqidno.26的所需结构。可使用另外的扩增方法(例如,pcr)将另外的区域(例如,固定区域、另外的条形码等)添加至叉状衔接子。
在一些情况下,可能期望其他碱基对突出端(例如,1个碱基对的突出端-10个碱基对的突出端)。需要时,用于产生这些突出端的限制酶可用作替代物,包括本文中所述的那些。在一个实例中,使用taqαi在malbac产物上产生两个碱基对的突出端。
作为备选,可设计图19a中所示的引物,使得rna引物序列置于条形码区域的5’,以便使用rna酶产生突出端。如图19f中所示,malbac产物1900包含置于条形码区域1902的5’的rna引物序列1901。malbac产物1900还包含测序引物区域1903、靶多核苷酸1904、互补测序引物区域1905、互补条形码区域1906和与rna引物序列1901互补的区域1907。用rna酶h1908处理malbac产物1900,并且消化rna引物区域序列1901以在malbac产物1900上产生2-6碱基对的突出端1909以生成结构1920。然后将通用互补区域1910添加至包含与结构1910上的突出端互补的区域的结构1910。然后通用互补区域1910与结构1920杂交,并使用热稳定连接酶将通用互补区域1910与结构1920连接。
实施例14:用基于退火和成环的多重扩增(malbac)进行的条形码化
如图20所示,使用例如界面聚合或本文所述的任何其他方法将包含条形码区域的模板2000与对于pcr所必需的试剂2001组合到胶囊2002内。使用pcr由模板2000产生malbac引物。接着,将胶囊2000包封到还包含混合物2004的外层胶囊2003中,该混合物2004包含待条形码化的靶多核苷酸2005和对于malbac扩增所必需的试剂2006(例如,deepvent聚合酶、dntp、缓冲液)。在胶囊2002恰当地暴露于被设计用于破坏胶囊2002的刺激时,胶囊2002被破坏,胶囊2002的内容物与混合物2004的内容物混合。靶多核苷酸2005的malbac扩增开始,产生与图19f中示为1900的所述产物相似的malbac产物。
然后用合适的刺激破坏外层胶囊2003,并回收内容物。然后用合适的限制酶处理malbac产物,并以如实施例13中所述的方式偶联到叉状衔接子上。然后根据需要进行另外的下游准备步骤(例如,本体扩增、大小选择等)。
实施例15:用基于退火和成环的多重扩增(malbac)进行的条形码化
如图21a所示,制备malbac引物2100。malbac引物2100包含序列引发区域2101和8-核苷酸的可变区域1902。引物2100与靶多核苷酸2103连同具有链置换活性的聚合酶(例如,vent、exo+deepvent、exo–deepvent)一起组合到分区(例如,胶囊、乳液等)内。在一些情况下,使用非链置换聚合酶(例如,taq、pfuultra)。然后对该分区进行malbac扩增2104。
产生环状malbac产物2110,其包含测序引发区域2101、靶多核苷酸2103和互补序列引发区域2105。然后使在图21b中以线性形式2120显示的malbac产物2110与包含测序引物区域2106、条形码区域2107和固定区域2108的另一条引物2130接触。使用不对称数字pcr产生引物2130。通过使用pcr单循环,用引物产生包含引物2130并因此包含条形码区域2107的双链产物2140。
然后可使双链产物2140变性,随后与图21c中所示的另一引物2150接触。引物2150包含条形码区域2109、测序引物区域2111和固定区域2112。在引物2113和2114的存在下,另外数轮pcr可将条形码区域2109添加至附接至条形码区域2107的靶多核苷酸的末端。随后根据需要进行另外的下游准备步骤(例如,本体扩增、大小选择等)。
实施例16:用基于退火和成环的多重扩增(malbac)进行的条形码化
如图22所示,使用例如界面聚合或本文所述的任何其他方法将包含条形码区域的引物模板2200与对于pcr所必需的试剂2201组合到胶囊2202内。然后使用pcr由模板2200产生引物。接着,将胶囊2200包封到还包含混合物2204的外层胶囊2003中,该混合物2004包含待条形码化的靶多核苷酸2205、对于malbac扩增所必需的试剂2206(例如,deepvent聚合酶、dntp、缓冲液)和不包含条形码的malbac引物2207(与实施例15中所述的malbac引物2100相似)。靶多核苷酸2205的malbac扩增开始,产生与图21a中示为2110的所述产物相似的malbac产物。随后在胶囊2202恰当地暴露于被设计用于破坏胶囊2202的刺激时,胶囊2202被破坏,胶囊2202的内容物与混合物2004的内容物混合。使用由模板2200产生的引物开始pcr单循环,产生与实施例15中所述的产物相似的条形码化的产物。
然后用合适的刺激破坏外层胶囊2203,并回收内容物。然后根据需要进行另外的下游准备步骤(例如,本体扩增、大小选择、附加条形码的添加等)。
实施例17:用转座酶和tagmentation进行的条形码化
如图23所示,如实施例1中所述,或通过本公开内容中描述的任何其他方法,合成、分区、扩增并分选单链衔接子-条形码多核苷酸序列2300。在包含单链衔接子-条形码多核苷酸序列的小滴上进行界面聚合,以产生胶囊2301。
制备两种混合物。混合物z1包含靶多核苷酸2302(即,待片段化并加条形码的多核苷酸)、转座酶2303和部分互补通用序列2304。第二混合物z2包含如上所述产生的胶囊2301,和如本文其他地方所述的对于pcr所必需的试剂2305。
将混合物z1和z2合并,并且根据本公开内容的其他地方所述的方法,如流动聚焦,形成在胶囊内的胶囊。图23示出了根据上述方法产生的在胶囊内的胶囊。外层胶囊2306包含胶囊2301和介质2307。胶囊2301是包封的单链衔接子-条形码多核苷酸的文库中的一员。因此,胶囊2301包含单链衔接子-条形码多核苷酸2300的多个拷贝,后者可用于将相同条形码附接至分区如外层胶囊2306内的多核苷酸。
介质2307含有上述混合物z1和混合物z2的内容物。更具体而言,介质2307包含靶多核苷酸2302、部分互补通用序列2304和对于pcr所必需的试剂2305,包括热启动taq。
在产生在胶囊内的胶囊并使在胶囊内的胶囊暴露于合适的条件后,转座酶处理靶多核苷酸。更具体而言,转座酶通过tagmentation对靶多核苷酸进行片段化,并用共同引发序列对其进行标记。然后将标记的靶多核苷酸加热以补平由转座酶产生的靶核苷酸中的任何缺口。然后热灭活转座酶,并使用刺激以使内层胶囊2301破裂,释放其内容物至外层胶囊2306中。通过加热外层胶囊2306至95℃活化热启动taq。该反应继续进行有限循环pcr以将单链衔接子-条形码多核苷酸序列2300添加至靶多核苷酸2302。然后使外层胶囊2306破裂,并对靶多核苷酸进行测序。
根据上文应当理解,虽然已示出和描述了特定实施方式,但可以对其进行各种修改,并且这些修改是本发明所设想到的。本说明书中提供的具体实施例并非意图限制本发明。虽然已参照上述说明书对本发明进行了描述,但此处的优选实施方案的说明和图示并不意味着以限制性的意义来解释。此外,应当理解,本发明的所有方面均不限于本文阐述的具体描述、构造或相对比例,这些取决于各种条件和变量。对本发明实施方案的形式和细节的各种修改对本领域技术人员来说将是显而易见的。因此可以预期,本发明也应涵盖任何这样的修改、变化和等同物。意图以所附权利要求限定本发明的范围,由此涵盖这些权利要求的范围内的方法和结构及其等同物。
序列表
<110>10x基因组学有限公司
<120>多核苷酸条形码生成
<130>43487-706.601
<140>pct/us2014/015427
<141>2014-02-07
<150>61/844,804
<151>2013-07-10
<150>61/840,403
<151>2013-06-27
<150>61/800,223
<151>2013-03-15
<150>61/762,435
<151>2013-02-08
<160>37
<170>patentinversion3.5
<210>1
<211>77
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>1
aatgatacggcgaccaccgagatctacactagatcgcacactctttccctacacgacgct60
cttccgatctgatctaa77
<210>2
<211>66
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>2
gatcggaagagcacacgtctgaactccagtcacacactctttccctacacgacgctcttc60
cgatct66
<210>3
<211>33
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>3
acactctttccctacacgacgctcttccgatct33
<210>4
<211>33
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>4
gatcggaagagcacacgtctgaactccagtcac33
<210>5
<211>67
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>misc_feature
<222>(33)..(34)
<223>这些位置的核苷酸被未公开的条形码化的靶多核苷酸序列隔开
<400>5
acactctttccctacacgacgctcttccgatctagatcggaagagcacacgtctgaactc60
cagtcac67
<210>6
<211>67
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>misc_feature
<222>(33)..(34)
<223>这些位置的核苷酸被未公开的条形码化的靶多核苷酸序列隔开
<400>6
acactctttccctacacgacgctcttccgatctagatcggaagagcacacgtctgaactc60
cagtcac67
<210>7
<211>122
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成多核苷酸
<220>
<221>misc_feature
<222>(58)..(59)
<223>这些位置的核苷酸被未公开的条形码化的靶多核苷酸序列隔开
<400>7
aatgatacggcgaccaccgagatctacactctttccctacacgacgctcttccgatctag60
atcggaagagcacacgtctgaactccagtcacatcacgatctcgtatgccgtcttctgct120
tg122
<210>8
<211>122
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成多核苷酸
<220>
<221>misc_feature
<222>(64)..(65)
<223>这些位置的核苷酸被未公开的条形码化的靶多核苷酸序列隔开
<400>8
caagcagaagacggcatacgagatcgtgatgtgactggagttcagacgtgtgctcttccg60
atctagatcggaagagcgtcgtgtagggaaagagtgtagatctcggtggtcgccgtatca120
tt122
<210>9
<211>42
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(34)..(41)
<223>a、c、t或g
<400>9
acactctttccctacacgacgctcttccgatctnnnnnnnnt42
<210>10
<211>42
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(1)..(8)
<223>a、c、t或g
<400>10
nnnnnnnnagatcggaagagcacacgtctgaactccagtcac42
<210>11
<211>84
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(1)..(8)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(76)..(83)
<223>a、c、t或g
<400>11
nnnnnnnnagatcggaagagcacacgtctgaactccagtcacacactctttccctacacg60
acgctcttccgatctnnnnnnnnt84
<210>12
<211>88
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<223>组合的dna/rna分子的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(1)..(12)
<223>a、c、u或g
<220>
<221>修饰的_碱基
<222>(14)..(21)
<223>a、c、t或g
<400>12
nnnnnnnnnnnnannnnnnnnagatcggaagagcgtcgtgtagggaaagagtgtgtgact60
ggagttcagacgtgtgctcttccgatct88
<210>13
<211>109
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<223>组合的dna/rna分子的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(1)..(12)
<223>a、c、u或g
<220>
<221>修饰的_碱基
<222>(14)..(21)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(89)..(96)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(98)..(109)
<223>a、c、t或g
<400>13
nnnnnnnnnnnnannnnnnnnagatcggaagagcgtcgtgtagggaaagagtgtgtgact60
ggagttcagacgtgtgctcttccgatctnnnnnnnntnnnnnnnnnnnn109
<210>14
<211>97
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(2)..(9)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(77)..(84)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(86)..(97)
<223>a、c、t或g
<400>14
annnnnnnnagatcggaagagcgtcgtgtagggaaagagtgtgtgactggagttcagacg60
tgtgctcttccgatctnnnnnnnntnnnnnnnnnnnn97
<210>15
<211>96
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(2)..(9)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(76)..(83)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(85)..(96)
<223>a、c、t或g
<400>15
annnnnnnngatcggaagagcacacgtctgaactccagtcacacactctttccctacacg60
acgctcttccgatctnnnnnnnntnnnnnnnnnnnn96
<210>16
<211>96
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<223>组合的dna/rna分子的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(1)..(13)
<223>a、c、u或g
<220>
<221>修饰的_碱基
<222>(14)..(21)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(88)..(95)
<223>a、c、t或g
<400>16
nnnnnnnnnnnnnnnnnnnnnagatcggaagagcgtcgtgtagggaaagagtgtgtgact60
ggagttcagacgtgtgctcttccgatcnnnnnnnnt96
<210>17
<211>83
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(1)..(8)
<223>a、c、t或g
<220>
<221>修饰的_碱基
<222>(75)..(82)
<223>a、c、t或g
<400>17
nnnnnnnnagatcggaagagcgtcgtgtagggaaagagtgtgtgactggagttcagacgt60
gtgctcttccgatcnnnnnnnnt83
<210>18
<211>70
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(30)..(36)
<223>a、c、t或g
<400>18
aatgatacggcgaccaccgagatctacacnnnnnnnacactctttccctacacgacgctc60
ttccgatctt70
<210>19
<211>70
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(35)..(41)
<223>a、c、t或g
<400>19
aagatcggaagagcgtcgtgtagggaaagagtgtnnnnnnngtgtagatctcggtggtcg60
ccgtatcatt70
<210>20
<211>56
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(21)..(27)
<223>a、c、t或g
<400>20
gtcgtgtagggaaagagtgtnnnnnnngtgtagatctcggtggtcgccgtatcatt56
<210>21
<211>34
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>21
agatcggaagagcacacgtctgaactccagtcac34
<210>22
<211>73
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>22
ttagatcagatcggaagagcacacgtctgaactccagtcactaaggcgaatctcgtatgc60
cgtcttctgcttg73
<210>23
<211>36
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>misc_feature
<222>(18)..(19)
<223>这些位置的核苷酸被未公开的条形码和引物测序区域隔开
<400>23
acgacgctcttccgatctagatcggaagagcgtcgt36
<210>24
<211>6
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>misc_feature
<222>(5)..(6)
<223>这些位置的核苷酸被未公开的条形码和引物测序区域隔开
<400>24
gatcta6
<210>25
<211>33
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>25
gatcggaagagcacacgtctgaactccagtcac33
<210>26
<211>67
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>misc_feature
<222>(33)..(34)
<223>这些位置的核苷酸被未公开的条形码和引物测序区域隔开
<400>26
acactctttccctacacgacgctcttccgatctagatcggaagagcacacgtctgaactc60
cagtcac67
<210>27
<211>13
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(5)..(9)
<223>a、c、t、g、未知的或其他
<400>27
ggccnnnnnggcc13
<210>28
<211>12
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(4)..(8)
<223>a、c、t、g、未知的或其他
<400>28
caannnnngtgg12
<210>29
<211>14
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(4)..(10)
<223>a、c、t、g、未知的或其他
<400>29
gaannnnnnnttgg14
<210>30
<211>13
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(5)..(10)
<223>a、c、t、g、未知的或其他
<400>30
gaacnnnnnntcc13
<210>31
<211>13
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(5)..(10)
<223>a、c、t、g、未知的或其他
<400>31
gaagnnnnnntac13
<210>32
<211>12
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(5)..(9)
<223>a、c、t、g、未知的或其他
<400>32
gaacnnnnnctc12
<210>33
<211>13
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>修饰的_碱基
<222>(5)..(10)
<223>a、c、t、g、未知的或其他
<400>33
gaacnnnnnntac13
<210>34
<211>5
<212>prt
<213>人工序列
<220>
<223>人工序列的描述:合成肽
<400>34
glypheleuglylys
15
<210>35
<211>153
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成多核苷酸
<220>
<221>修饰的_碱基
<222>(78)..(80)
<223>a、c、t、g、未知的或其他
<400>35
aatgatacggcgaccaccgagatctacactagatcgcacactctttccctacacgacgct60
cttccgatctgatctaannnttagatcagatcggaagagcacacgtctgaactccagtca120
ctaaggcgaatctcgtatgccgtcttctgcttg153
<210>36
<211>26
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<220>
<221>misc_feature
<222>(18)..(19)
<223>这些位置的核苷酸被未公开的条形码和引物测序区域隔开
<220>
<221>修饰的_碱基
<222>(19)..(26)
<223>a、c、t或g
<400>36
acgacgctcttccgatctnnnnnnnn26
<210>37
<211>28
<212>dna
<213>人工序列
<220>
<223>人工序列的描述:合成寡核苷酸
<400>37
acactctttccctacacgacgctcttcc28
- 还没有人留言评论。精彩留言会获得点赞!