一种端粒信息编码方法与流程
本发明属于信息编码领域,具体涉及一种端粒信息编码方法。
背景技术:
随着社会科技的发展,人们在越来越注重于自身健康的同时,这些健康信息也正逐渐与现代科技相结合,从而实现对自身健康信息的适时采集、评估和交流,以便于通过信息的数据化,来针对性的对健康信息中的缺陷进行后期改善,最终整体提升社会的健康水平。端粒位于染色体的末端,用于保护染色体末端免于融合和退化,并防止细胞分裂过程中的dna脱落。细胞每次分裂后,端粒就会缩短,因为它们在每个复制周期中丢失了一部分;当端粒无法再缩短时,细胞也就达到了衰老状态;此时,细胞不可逆地停止分裂,并立即激活凋亡机制,即细胞走向凋亡。测定端粒的长度,可显然的获知我们的生理年龄。是否可将端粒信息进行编码,从而在信息交流时能够由该编码而直接的获得当前信息人的生理年龄等特征信息,以便于利用信息流的高效传输性及交换性,来快速化的实现对特定样本区人群甚至特定信息人的信息化比对目的,最终实现针对性的健康缺陷改善效果,为本领域近年来所亟待解决的技术难题。
技术实现要素:
本发明的目的是克服上述现有技术的不足,提供一种端粒信息编码方法,目的在于用于迅速而高效的实现对特定样本区人群甚至特定信息人的自动化的信息比对,最终利于提升社会整体健康水平。
为实现上述目的,本发明采用了以下技术方案:
一种端粒信息编码方法,其特征在于包括以下步骤:
1)、计算受试者的样本端粒的长度;
2)、按已有的不同年龄、不同性别的受试者的端粒长度来建立样本数据库;
按性别将样本数据库分为两组,第一组为男性,第二组为女性;并将年龄记为x0,其中
针对男性组数据,应用统计软件对受试者的样本端粒长度与对应的受试者年龄进行回归分析,得下式:
trf1=a1x0+b1
针对女性组数据,应用统计软件对受试者的样本端粒长度与对应的受试者年龄进行回归分析,得下式:
trf0=a0x0+b0;
3)、在受试者t岁、t+k岁时各进行一次端粒长度检测,对应的样本的端粒长度分别为trf(t)、trf(t+k),并依序执行以下子步骤:
a、计算样本的细胞年龄
受试者t+k岁时的细胞年龄ca(t+k)为:
b、计算样本的端粒长度年平均变化程度
受试者在t岁到t+k岁时期端粒长度年平均变化程度δt,k为:
c、端粒信息码的建立
记高斯函数为gauss(x)=不超过x的最大整数;
则m5是不小于0,不超过35的整数;
记min(x,y)=x与y中较小数;
则m4是不小于0,不超过35的整数;
计算m5和m4,再将m5和m4的数值按照三十六进制转换为三十六进制符号,并按m5m4的顺序拼在一起,则得到一个两位字符串,该两位字符串即为端粒信息码。
优选的,所述1)步骤中,计算受试者的样本端粒的长度包括以下子步骤:
a、抽取外周血3~5ml置入0.5mol/ledtak2抗凝的离心管中于-20℃冷冻保存;
b、采用饱和酚-氯仿法抽提外周血白细胞基因组dna,选取od260/od280值介于1.8~2.0之间的作为实验样品,0.8%琼脂糖凝胶电泳后紫外线下观察dna的完整性;
c、采用罗氏公司端粒长度检测试剂盒telotagggtelomerelengthassay,基因组dna采用限制性内切酶hinfi、rsai混合酶切2h,于0.8%琼脂糖凝胶5v/cm电泳4h后,将凝胶变性、中和,以虹吸印迹法将dna转移至带正电的尼龙膜上,120℃烘烤20min;42℃预杂交1h后,加入地高辛标记的端粒探针杂交3h;洗膜后进行化学发光显影,所得x线片经光密度扫描成像,采用端粒长度分析软件telomeric1.2进行分析,根据下列公式计算各样本端粒长度:
其中li为i点marker长度;
odi为i点的光密度值。
本发明的有益效果在于:
1)、通过上述编码模型的建立,从而将受试者也即特定信息人或者受试者人群也即样本区人群的杂乱的原始信息进行信息化梳理,进而实现了对样本区人群内的人与人之间以及特定信息人在指定年龄段的健康数据的比对功能。甚至可通过数据库的建立,从而获得当今社会此时的细胞年龄及端粒长度年平均变化程度的平均值。每当有新的样本进入数据库,均可将其信息进行编码后,将端粒信息码的两位字符与上述细胞年龄及端粒长度年平均变化程度的平均值转化后的三十六进制字符进行对比,从而判断当前样本所属人也即受试者的衰老程度和活力程度,以便于决定是否需针对性的进行后期调养和锻炼。由于该类编码模型为纯信息化的字符编码,因此甚至可将之应用到区块链上,从而成为区块链baas平台的基础,最终可依托baas平台而实现不同人甚至不同人群的信息交流的便捷化及高效化功能。
附图说明
图1为本发明的模型布局对照表;
图2为三十六进制的数字与字符对照表;
图3为人脸图像采集顺序码计算时所需对应的14位数字顺序表。
具体实施方式
为便于理解,此处结合图1-3,对本发明的具体结构及工作方式作以下进一步描述:
本发明的设计初衷,是将其应用于身份信息编码模型内,从而结合现有的国别码、语种码乃至信用码及健康码等,从而实现普通码与类似端粒信息码等的生物码的混编功能。该混编后的结合码,包含了受试者的国别、语种、健康程度、信用度、端粒信息等大量信息,从而尤其方便将其应用于区块链baas平台等信息化平台内,从而实现便捷化和高效化的信息交流功能。
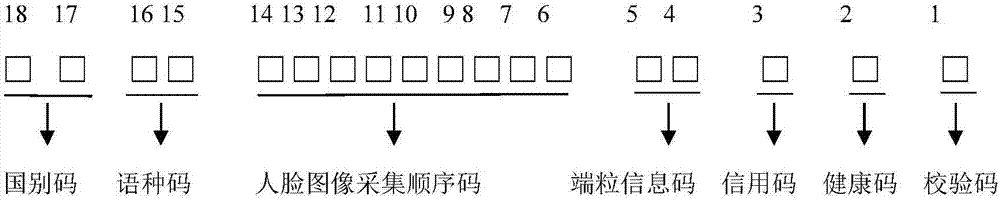
对于身份信息编码模型,如图1所示,包括由左至右依序布置的静态码、动态码和校验码,其中:
静态码包括受试者的国别码、语种码以及人脸图像采集顺序码;其中:
国别码为两位,引用iso3166-1;语种码为两位,引用iso693-1。而具体操作时,可考虑人脸图像采集顺序码根据受试者采集人脸图像时的时间(精确到分钟)加最末两位分配码来形成。人脸图像采集顺序码获取过程包括以下步骤:
1)、需先获得受试者采集人脸图像时的时间,通常为北京时间;包括年份、月份、日期、时钟及分钟,个位数须在左侧以0补成两位数。
2)、将年份减去2000后所得四位数,位数不足在左侧以0补成四位数,再将其与月份、日期、时钟及分钟按原顺序排列。
3)、补入两位数顺序号,从而形成14位的数字,如图3所示。顺序号根据受试者在同一分钟内采集图像的先后次序及其性别而定。更具体而言,受试者若为男性,则顺序号末位为奇数,不足两位数的在左侧以0补成两位数,即某时点01为第1位采集图像的男性,03为第2位采集图像的男性,以此类推。受试者若为女性,则顺序号末位为偶数,不足两位数的在左侧以0补成两位数,即某时点00为第1位采集图像的女性,02为第2位采集图像的女性,以此类推。例如某受试者是2018年7月1日23时45分第22位女性被采集者,其对应的14位数字为00180701234542。这其实就类似于身份证号,倒数五到十二位为出生日期,而倒数一到四则为性别号。
4)、将3)中14位数字进行三十六进制转换后形成八位的人脸图像采集顺序码,不足九位的在左侧以0补成九位。
动态码包括受试者的端粒信息码、信用码以及健康码。
所述信用码为一位,信用分为现有技术,或者说应用现有第三方技术可获得,获得相应信用分为cre(cremax分制,即信用分满分为cremax);
记高斯函数为gauss(x)=不超过x的最大整数,按下述公式计算出m3:
再将m3按照三十六进制转换为三十六进制符号,即得相应的信用码。
所述健康码为一位,健康分同样为现有技术,或者说应用现有第三方技术可获得,获得相应健康分为hea(heamax分制,即健康分满分为heamax);
按下述公式计算出m2:
再将m2按照三十六进制转换为三十六进制符号,即得相应的健康码。
而所述端粒信息码为两位,获取过程包括以下步骤:
1)、计算受试者的样本端粒的长度,包括以下子步骤:
a、抽取外周血3~5ml置入0.5mol/ledtak2抗凝的离心管中于-20℃冷冻保存;
b、采用饱和酚-氯仿法抽提外周血白细胞基因组dna,选取od260/od280值介于1.8~2.0之间的作为实验样品,0.8%琼脂糖凝胶电泳后紫外线下观察dna的完整性;
c、采用罗氏公司端粒长度检测试剂盒telotagggtelomerelengthassay,基因组dna采用限制性内切酶hinfi、rsai混合酶切2h,于0.8%琼脂糖凝胶5v/cm电泳4h后,将凝胶变性、中和,以虹吸印迹法将dna转移至带正电的尼龙膜上,120℃烘烤20min;42℃预杂交1h后,加入地高辛标记的端粒探针杂交3h;洗膜后进行化学发光显影,所得x线片经光密度扫描成像,采用端粒长度分析软件telomeric1.2进行分析,根据下列公式计算各样本端粒长度:
其中li为i点marker长度;
odi为i点的光密度值。
2)、按已有的不同年龄、不同性别的受试者的端粒长度来建立样本数据库;
按性别将样本数据库分为两组,第一组为男性,第二组为女性;并将年龄记为x0,其中
针对男性组数据,应用统计软件对受试者的样本端粒长度与对应的受试者年龄进行回归分析,得下式:
trf1=a1x0+b1
针对女性组数据,应用统计软件对受试者的样本端粒长度与对应的受试者年龄进行回归分析,得下式:
trf0=a0x0+b0。
3)、在受试者t岁、t+k岁时各进行一次端粒长度检测,对应的样本的端粒长度分别为trf(t)、trf(t+k),并依序执行以下子步骤:
a、计算样本的细胞年龄
受试者t+k岁时的细胞年龄ca(t+k)为:
实际计算时,若ca(t+k)≤t+k,即细胞年龄比实际年龄小,意味着受试者在细胞层面上比同龄人年轻,即受试者比同龄人更有活力。而若ca(t+k)>t+k,即细胞年龄比实际年龄大,意味着受试者在“细胞层面”上比同龄人年老,即受试者没有同龄人有活力,此时需要考虑进行针对性的调养和后期锻炼,以期望在下一次测试时细胞年龄ca(t+k)值能尽可能的小于或等于当前年龄值。
b、计算样本的端粒长度年平均变化程度
受试者在t岁到t+k岁时期端粒长度年平均变化程度δt,k为:
实际计算时,若|δt,k|数值越大,表明端粒变短的速率越快,表明受试者衰老地越快。而如果|δt,k|≤|δt,0|,则表明受试者比同龄人衰老得慢,反之表明受试者比同龄人衰老得快。通过受试者在t岁到t+k岁时期端粒长度年平均变化程度δt,k,也能确定受试者是否需要考虑进行针对性的调养和后期锻炼,以降低端粒变短速率。
c、端粒信息码的建立
记
则m5是不小于0,不超过35的整数;
记min(x,y)=x与y中较小数;
则m4是不小于0,不超过35的整数。
计算m5和m4,再将m5和m4的数值按照三十六进制转换为三十六进制符号,并按m5m4的顺序拼在一起,则得到一个两位字符串,该两位字符串即为端粒信息码。
在对端粒信息码解读时,如果第一位字符在三十六进制字符转换表中位置越靠前(或者说m5数值越小),则表明受测者细胞活力越好(或者说受测者细胞越“年轻”);如果第二位字符在三十六进制字符转换表中位置越靠前(或者说m4数值越小),表明受测者衰老得越慢。
校验码的获取过程如下:
由于此时动态码与静态码全部获知,也即如图1所示的由右至左数的第2~17位均已知晓,此时将该2~17位数字设为:
m18m17m16m15m14m13m12m11m10m9m8m7m6m5m4m3m2
其中mj代表字符,2≤j≤18;
step1:根据三十六进制的字符转换表将mj反向转换为数字mj;
step2:针对每个mj,按以下公式计算权值ωj:
ωj=mod(2j-1,37)
其中,mod(x,37)表示整数x被37除所得的余数;
step3:按以下公式计算m1:
step4:根据三十六进制的字符转换表将数字m1转换为字符m1,该m1即为校验码。
为便于进一步理解本发明,此处给出以下具体实施例:
根据已有的含1091例不同年龄、不同性别的人的外周血细胞端粒长度数据的数据库,按本发明所述各步骤建模,获得:
a1=-0.0605,b1=14.166,a0=-0.06,b0=14.126
取
实施例1
某男性受试者甲,45岁时测得的端粒长度为11.59kb,其47岁测得的端粒长度为11.45kb,从而根据本发明所述各步骤而获得:
m5=10,m4=16。
根据图2所示的三十六进制字符转换表,得到受试者甲在47岁时端粒信息码为ag。
实施例2
某男性受试者乙,44岁时测得的端粒长度为11.75kb,其47岁测得的端粒长度为11.49kb,从而根据本发明所述各步骤而获得:
m5=10,m4=27。
根据图2所示的三十六进制字符转换表,得到受试者乙在47岁时端粒信息码为ar。
实施例3
某男性受试者丙45岁时测得的端粒长度为11.34kb,其47岁测得的端粒长度为11.11kb,从而根据本发明所述各步骤而获得:
m5=12,m4=27。
根据图2所示的三十六进制字符转换表,得到受试者丙在47岁时端粒信息码为cr。
结论:
由上述实施例1及实施例2可知:47岁时,受试者甲和乙端粒信息码第一位同为a,表明两人的细胞活力水平相同,换句话说两人的细胞同样“年轻”;受试者甲的端粒信息码第二位为a,受试者乙的端粒信息码第二位为r,图2所示字符转换表中字符a排在字符r前面,表明甲衰老得比乙慢。两者对比,建议乙应当通过健康锻炼或调整饮食等方式,有意识地来干预自己的衰老速度。
由上述实施例2及实施例3可知:47岁时,受试者乙的端粒信息码第一位为a,受试者丙的端粒信息码第一位为c,图2所示字符转换表中字符a排在字符c前面,表明乙的细胞活力比丙好,或者说乙的细胞比丙“年轻”。乙和丙端粒信息码第二位同为r,表明二者衰老速度相同。两者对比,建议乙应当通过健康锻炼或调整饮食等方式,有意识地来提升自己的细胞活力。
实施例4:
本实施例为身份信息编码模型的具体实施例,以便于阅读者从宏观上更为理解上述内容:
受试者甲,男,国籍为中国,母语为汉语,人脸图像采集于北京时间2017年5月12日9时8分,其是该时点第14位男性被采集者。45岁时测得的端粒长度为11.59kb,其47岁测得的端粒长度为11.45kb。47岁时甲的信用分为85(百分制),健康分为76.3(百分制)。
根据本发明所述各步骤而获得:
国别码为cn;
语种码为zh;
图像采集顺序码计算步骤中的14位数字为,00170512090827,对应的图像采集顺序码为026byhvbf;
端粒码计算步骤中的m5=10,m4=16,对应的端粒码为ag;
信用码计算步骤中的m3=30,对应的信用码为u;
健康码计算步骤中的m2=27,对应的信用码为r;
校验码计算步骤中的m1=26,对应的校验码为q;
进而获得甲在47岁时的全码为cnzh026byhvbfagurq。
如果在系统中输入甲的全码为cnzh226byhvbfagurq,则系统根据校验码计算规则对该全码的前17位进行计算,得出校验码位应为u,与q不同,系统则会提示输入有误,从而实现校验功能。
- 还没有人留言评论。精彩留言会获得点赞!