抑制和/或敲除基因在提高单克隆抗体的表达量中的应用的制作方法
本发明涉及生物
技术领域:
,特别涉及抑制和/或敲除基因在提高单克隆抗体的表达量中的应用。
背景技术:
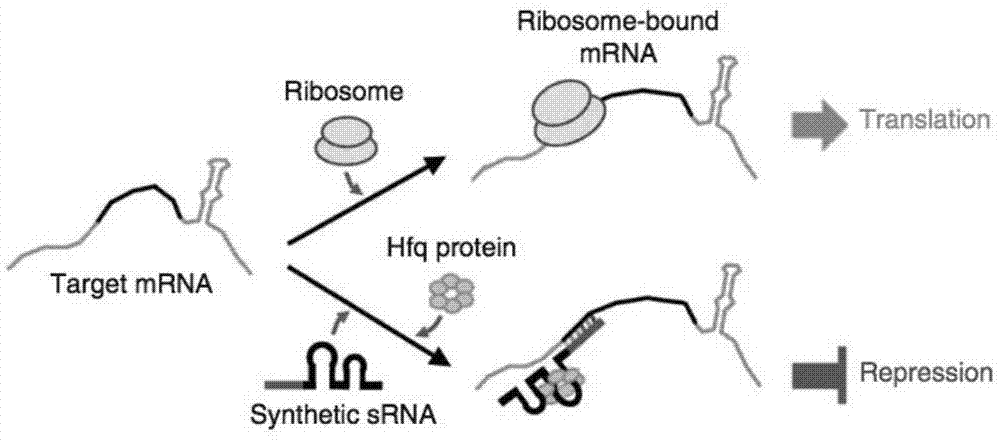
:抗体是指一类可以与抗原特异性结合,用来识别和鉴定抗原的免疫球蛋白。抗体分为多克隆抗体和单克隆抗体。与多克隆抗体相比,单克隆抗体最大的不同在于其单一的特异性;即它只能与一个特定的抗原决定簇识别并结合。随着生物技术的迅猛发展,重组蛋白药物市场发展迅速,且经济价值逐年增加。其中,重组抗体是增长最快、经济价值最大的群体。自2010年以来,抗体药物的年销售额每年增长8%以上。2017年,全球治疗性抗体市场已达1000亿美元。目前,已有200多种抗体药物进入iii期临床研究。美国fda批准了50多种单克隆抗体药物,其中免疫球蛋白g(igg)类型占比最大。这些数据清楚地表明生产单克隆抗体是生物医学领域中最重要的问题之一。目前,单克隆抗体主要是在哺乳动物细胞系中产生。然而,哺乳动物细胞系有诸多限制,例如,生长周期长、投资成本高、下游纯化难等。而与哺乳细胞相比,大肠杆菌表达系统具有生长时间短、易于进行分子操作、可以实现高密度发酵、成本低廉等优势,成为生产单克隆抗体的潜在替代宿主,并快速发展。目前,已有两种在大肠杆菌中生产的单克隆抗体片段被美国fda批准上市:genentech公司生产的lucentis(通用名ranibizumab)和usb公司生产的cimzia(通用名certolizumabpegol)。其中,lucentis用于治疗糖尿病性视网膜病变;cimzia用于治疗中重度类风湿性关节炎。srnas(smallregulatoryrnas)指非编码rna,长度一般在几十至几百个核苷酸之间,其可以在翻译水平上调控基因的表达。目前发现srna广泛存在于原核生物、真核生物乃至哺乳动物等不同的生物体中。如图1所示为人工合成srna的作用机制。当srna不存在时,核糖体(ribosome)与靶mrna(targetmrna)结合,mrna可以正常进行后续的翻译(translation);而当srna存在时,srna有与靶mrna互补的序列(srna的红色部分),其竞争性阻断核糖体与靶mrna的特异性结合,从而有效抑制(repression)靶mrna的翻译,达到调控基因表达的目的。人工合成的srna(syntheticsrna)设计简单并且可以快速调节原核染色体基因的表达,而不需要复杂的工程。蛋白酶是催化蛋白质肽链水解的一类酶的总称,分布广泛。目前,现有的一些研究开发了蛋白酶缺陷菌株来减少单克隆抗体片段或其他蛋白质的降解。但是缺少大肠杆菌中蛋白酶对完整igg抗体影响的研究,尤其是不同类型的蛋白酶对于igg的作用大小,以及蛋白酶的位置对igg抗体的影响,都需要通过大量的实验研究进行确定。技术实现要素:有鉴于此,本发明提供了抑制和/或敲除基因在提高单克隆抗体的表达量中的应用。本发明以e.colimg1655为出发菌株,利用srna技术抑制蛋白酶基因,减少蛋白酶的形成,从而减少蛋白酶对igg及其片段的降解,进而间接提高igg抗体的产量,为将来的工业化生产提供理论依据。为了实现上述发明目的,本发明提供以下技术方案:本发明提供了抑制和/或敲除基因在提高单克隆抗体的表达量中的应用;所述基因具有如下所示的核苷酸序列中的任意一项:i、具有基因degq和/或degs的核苷酸序列;ii、具有如i所示的核苷酸序列经修饰、取代、缺失或添加一个或多个碱基获得的核苷酸序列;iii、与如i所示的核苷酸序列具有至少80%同源性的序列或翻译后所得蛋白与基因degq和/或degs表达的蛋白功能相同或相近的核苷酸序列;iv、如i、ii或iii所示序列的互补序列。在本发明的一些具体实施方案中,所述单克隆抗体为igg。在本发明的一些具体实施方案中,所述基因为蛋白酶基因。在本发明的一些具体实施方案中,所述抑制采用srnas。利用srna技术抑制蛋白酶基因,减少蛋白酶的形成,从而减少蛋白酶对igg及其片段的降解,进而间接提高igg抗体的产量。在本发明的一些具体实施方案中,所述srnas包括pr启动子、与所述基因序列互补的核苷酸序列、srna支架序列和转录终止子。在此基础上,本发明还提供了srnas接收盒,包括pr启动子(如seqidno.22所示)、与目的序列互补的核苷酸序列(在本发明的一些具体实施方案中,如seqidno.23所示)、srna支架序列(如seqidno.24所示)和转录终止子(如seqidno.25所示)。在本发明的一些具体实施方案中,所述与目的序列互补的核苷酸序列的合成方法为:在所述目的序列的正向引物5’端加上粘性末端ttgc,在所述目的序列的反向引物5’端加上粘性末端gaaa,扩增,获得所述与目的序列互补的核苷酸序列。本发明还提供了表达模块,包括本发明所述的srnas接收盒和基因;所述基因具有如下所示的核苷酸序列中的任意一项:i、具有基因degq和/或degs的核苷酸序列;ii、具有如i所示的核苷酸序列经修饰、取代、缺失或添加一个或多个碱基获得的核苷酸序列;iii、与如i所示的核苷酸序列具有至少80%同源性的序列或翻译后所得蛋白与基因degq和/或degs表达的蛋白功能相同或相近的核苷酸序列;iv、如i、ii或iii所示序列的互补序列。本发明还提供了表达载体,包括所述的表达模块。本发明还提供了菌株,包括所述的表达载体。在上述研究的基础上,本发明还提供了所述的srnas接收盒、所述的表达模块、所述的表达载体和/或所述的菌株在提高单克隆抗体的表达量中的应用。在本发明的一些具体实施方案中,所述单克隆抗体为igg。本发明以e.colimg1655为出发菌株,利用srna技术抑制蛋白酶基因,减少蛋白酶的形成,从而减少蛋白酶对igg及其片段的降解,进而间接提高igg抗体的产量,为将来的工业化生产提供理论依据。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。图1示人工合成srna的作用机制;图2(a)示gfp表达的质粒示意图;图2(b)示gfp表达的gfp/od600结果图;图3(a)示共表达蛋白酶srna的质粒示意图;图3(b)示蛋白酶对单克隆抗体表达的影响;图4示图3(b)示蛋白酶对单克隆抗体表达的影响中degs的生物学统计结果,其中,1.00-为野生型数据,2.00-为改造后数据;p=0.018<0.05;图5示图3(b)示蛋白酶对单克隆抗体表达的影响中degq的生物学统计结果,其中,1.00-为野生型数据,2.00-为改造后数据;p=0.010<0.05。具体实施方式本发明公开了抑制和/或敲除基因在提高单克隆抗体的表达量中的应用,本领域技术人员可以借鉴本文内容,适当改进工艺参数实现。特别需要指出的是,所有类似的替换和改动对本领域技术人员来说是显而易见的,它们都被视为包括在本发明。本发明的方法及应用已经通过较佳实施例进行了描述,相关人员明显能在不脱离本
发明内容、精神和范围内对本文所述的方法和应用进行改动或适当变更与组合,来实现和应用本发明技术。所用的大肠杆菌菌株和质粒在所有实验中,大肠杆菌transt1用于基因克隆,大肠杆菌mg1655用于单抗表达。单抗基因连接到包含pbr322复制子的p2a4载体中。单抗基因:p2a4空质粒载体的蛋白表达区域是由lacuv5启动子引导的,后面连接乳糖操纵子,之后有一段核糖体结合位点,之后的序列中包含ecori、xbai、ndei、spei和psti酶切位点。通过用ndei和spei酶切空质粒载体后连接上述体外合成的单抗基因。名词及术语解释e.coli:大肠杆菌单克隆抗体:简称单抗srna(s):是原核生物中短的非编码rna,其可以在转录后水平上精确控制靶基因的反式表达。美国fda:食品药品监督管理局igg:免疫球蛋白g轻链(lc):单克隆抗体的轻链区域,由vl和cl构成重链(hc):单克隆抗体的重链区域,由vh,ch1,ch2和ch3区域构成pcr:聚合酶链式反应pbs:磷酸缓冲盐溶液degq:丝氨酸内切蛋白酶,位于周质空间degs:丝氨酸内切蛋白酶,位于周质空间hepes:4-羟乙基哌嗪乙磺酸lb培养基:5g/l酵母提取物;10g/l蛋白胨;10g/l氯化钠mrna:信使rna,是由dna的模板链转录而来,携带遗传信息并能指导蛋白质合成的一类单链核糖核酸tir:translationinitiationregion,翻译起始区域转录:指遗传信息从基因(dna)转移到rna,在rna聚合酶的作用下形成一条与dna模板链序列互补的mrna的过程翻译:指根据遗传密码的中心法则,将成熟的mrna中核苷酸序列解码,并生产对应的特定氨基酸序列的过程gfp:greenfluorescentprotein,绿色荧光蛋白iptg:异丙基硫代半乳糖苷本发明提供的抑制和/或敲除基因在提高单克隆抗体的表达量中的应用中所用原料及试剂均可由市场购得。下面结合实施例,进一步阐述本发明:实施例1基因的体外合成和扩增单抗的轻链和重链氨基酸序列(来源于人源)从ncbi数据库获得,在jcat网站中对序列进行了优化,并在优化的序列中避免了xbai,ndei,spei和hindiii限制性酶切位点。轻链(如seqidno.20所示)和重链(如seqidno.21所示)基因均在体外合成。所用的大肠杆菌菌株和质粒在所有实验中,大肠杆菌transt1用于基因克隆,大肠杆菌mg1655用于单抗表达。单抗基因连接到包含pbr322复制子的p2a4载体中。单抗基因:p2a4空质粒载体的蛋白表达区域是由lacuv5启动子引导的,后面连接乳糖操纵子,之后有一段核糖体结合位点,序列中包含ecori、xbai、ndei、spei和psti等一系列酶切位点;其中,启动子和操纵子位于ecori和xbai酶切位点之间,核糖体结合位点位于xbai和ndei酶切位点之间。首先通过用ndei和spei酶切将轻链(lc)和重链(hc)的基因分别连接入p2a4质粒空载体上;然后将含有重链(hc)的p2a4,通过xbai和psti酶切,连接到含有轻链(lc)的p2a4质粒载体上,从而将轻链(lc)和重链(hc)基因连接到同一个p2a4质粒上。在这个质粒上,轻链和重链前面均有一段核糖体结合位点,轻链在前,重链在后,并且通用一个lacuv5启动子进行诱导表达。srna的设计和组装设计一对20-30nt寡核苷酸,在正向引物5’端加上粘性末端ttgc,在反向引物5’端加上粘性末端gaaa。例如,如果序列如seqidno.1所示:accgactaatgcatactttgtcat,那么这两个引物是:a.正向引物(如seqidno.2所示):5’-ttgcaccgactaatgcatactttgtcat-3’b.反向引物(如seqidno.3所示):5’-gaaaatgacaaagtatgcattagtcggt-3’pcr反应如下:a.将一对寡核苷酸重悬于水中,使其浓度为100μmb.将5μl正向引物、5μl反向引物和90μl30mmhepes(ph=7.8)混合c.放入pcr仪中,95℃5min,然后以0.1℃/秒的速度降至4℃即可获得srna序列。srna接收体连接到含有p15a复制子的p3c5载体中。srna接收体含有pr启动子、srna支架序列和转录终止子。使用goldengate方法将srna序列连接到srna接收体上。p3c5空质粒载体序列中包含ecori、xbai、ndei、spei和psti等一系列酶切位点。通过用xbai和spei酶切将srna接收体连接到p3c5质粒空载体上。注:goldengate方法中srna接收体质粒指含有srna接收体的p3c5质粒。goldengate反应混合液:srna接收体质粒——1μl(100ng)srna序列——0.5μl(上述pcr的产物稀释十倍)t4ligasebuffer——2μlt4ligase——1μlbsai——1μl水——14.5μlgoldengatepcr程序:1.37℃10min,然后16℃10min,步骤1循环10次;2.50℃5min;3.65℃20min;4.降温至4℃。本实验所用引物见表1。表1本实验所用引物及其对应序列实施例2摇瓶发酵将单个大肠杆菌细胞在lb液体培养基和适当的抗生素(100μg/ml氨苄青霉素和/或34μg/ml氯霉素)中培养,37℃和220rpm下过夜培养;将培养物以1:100比例转接入50ml新鲜lb培养基(250ml摇瓶)中,并在37℃下生长。当600nm处的光密度(od600)达到约0.6时,培养箱温度降至25℃,平衡温度20分钟。加入异丙基硫代半乳糖苷(iptg),使其终浓度为1mm,细胞在25℃下生长16小时。实施例3单克隆抗体的纯化将发酵后的培养物,6500rpm和4℃收集并离心。细胞用0.01mpbs(ph=7.2-7.4)洗涤。用pbs重悬细胞并进行超声破碎处理,5s脉冲,10s间歇,总工作时间为20分钟。然后,将细胞裂解物在10,000rpm和4℃下离心30分钟,收集上清液。然后使用0.45μm滤膜进行过滤。在本实验中,抗体纯化磁珠试剂盒用于纯化单克隆抗体。1.样品处理:取抗体含量约0.1-0.15mg的样品置于新的1.5mlep管中,加入抗体结合缓冲液至总体积为500μl(如样品体积大于500μl,则无需加入),混合均匀。2.磁珠预处理:将抗体纯化磁珠涡旋震荡30s,使磁珠充分重悬;取100μl磁珠悬液置于另一新的1.5mlep管中.对磁珠悬液进行磁性分离(使磁珠被吸附在管壁至溶液澄清;该操作描述以下省略,弃上清液。从磁性分离器上取下ep管,管中磁珠可直接用于抗体分离)。3.抗体吸附:在步骤2预处理的磁珠管中加入步骤1处理的样品溶液,涡旋震荡均匀,在室温下(约25℃)置于翻转混合仪上,促使样品和磁珠充分接触并吸附,翻转约15min后进行磁性分离,移弃上清液。4.磁珠洗涤:向ep管中加入1ml抗体结合缓冲液,振荡重悬磁珠后进行磁性分离,移弃上清液;该操作重复两次。5.抗体洗脱:在上述完成磁珠洗涤的ep管中加入1ml抗体结合缓冲液,涡旋震荡迅速重悬,然后在室温下置于翻转混合仪上,翻转10min后进行磁性分离,收集上清液至新的ep管。6.抗体透析:因抗体洗脱缓冲液含有较高浓度的盐分,收集的抗体溶液不能直接用于sds-page检测,但可以用抗体洗脱缓冲液调零进行抗体浓度测定。抗体洗脱缓冲液呈偏酸性,用自行配制的中性低盐溶液立即对收集的抗体溶液进行透析处理,以降低抗体失活率,获得较高活性和稳定性的抗体溶液。所述自行配制的中性低盐溶液为0.01mpbs溶液:氯化钠137mmol/l;氯化钾2.7mmol/l;磷酸氢二钠10mmol/l;磷酸二氢钾2mmol/l。实施例4sds-page发酵后,将1ml待测试的培养液吸出,以10,000rpm离心2分钟,弃去上清液。用0.01mpbs溶液洗涤细胞3次,弃去上清液。再用200ulpbs重悬细胞。然后将适量的上样缓冲液加入重悬溶液中并充分混合。将混合液煮沸10分钟并放置在-80℃储存。点样前,用12,000rpm离心2min,然后吸取适量的上清液上样点胶。实施例5elsia(酶联免疫吸附剂测定)1.稀释样品(此步骤选做)。2.每孔加入100μlassaybuffer,分别将10μl样品或不同浓度标准品加入相应孔中,轻轻摇板进行简单混合,用封板膜封住反应孔,室温下(18-25度)孵化30min。3.揭掉封板膜,吸弃孔内液体。用300μl稀释的washbuffer洗涤3次,在干净的纸上拍干。4.每孔加入100μl准备好的hrpconjugate。5..用新的封板膜密封。室温孵化30min。6..重复步骤3。7.每孔加入100μltmbsubstratesolution。8.黑暗条件下室温孵化10分钟(不封膜)。9.加入100μlstopsolution停止反应。轻轻摇板进行简单混合,孔内颜色由蓝变黄。10.以空白孔调零,30min内使用酶标仪在450nm测定每孔的吸光度。效果例人工合成srna技术本发明以绿色荧光蛋白(greenfluorescentprotein,简称gfp)为例用来检验人工合成srna调控基因表达的作用。如图2a所示,选用lacuv5启动子在大肠杆菌中表达gfp基因(p2a4gfp-uv5质粒),如seqidno.26所示;同时,共表达p3c5srna-gfp质粒,用来检验srna抑制gfp基因表达的效果。其中,sgfp采用pr启动子进行表达,sgfp指抑制gfp表达的srna,它包括与绿色荧光蛋白mrna的翻译起始区域(从atg开始的20-30个核苷酸)互补的核苷酸序列,srna支架结构核苷酸序列和转录终止子。如图2b、表2所示,含有p2a4gfp-uv5质粒的大肠杆菌菌株发酵培养得到的gfp/od600结果(大肠杆菌菌株加入诱导剂iptg的终浓度分别为0.01mm、0.1mm和1mm,并在25℃条件下诱导gfp表达16小时)。其中,白色柱代表空白对照组,只含有p2a4gfp-uv5质粒的大肠杆菌,没有共表达srna;灰色柱代表实验组,含有p2a4gfp-uv5和p3c5srna-gfp质粒的大肠杆菌,共表达了srna。通过gfp/od600结果说明当共表达srna时,gfp表达量降低;证明srna可以有效的抑制gfp基因的表达,即人工合成srna可以有效的调控基因表达。后续实验也采用同样的方法调控基因的表达。表2空白对照sgfpiptg(mm)gfp/od600标准偏差gfp/od600标准偏差0.011359107563370.13029848775313873322111062蛋白酶对大肠杆菌中igg抗体表达的影响蛋白酶可以降解蛋白质和肽,所以,减少蛋白酶降解蛋白质也是一种间接提高蛋白质产量的方法。因此,我们研究了蛋白酶对大肠杆菌表达igg抗体的影响。表3本实验涉及到的大肠杆菌蛋白酶及其所处位置rpoh为rna聚合酶,又名δ32因子,负责正调控所有能量依赖蛋白酶的表达;lon是dna结合atp依赖性蛋白酶,属于丝氨酸蛋白酶;degp、degs和degq均为丝氨酸内切蛋白酶,属于丝氨酸蛋白酶;ompt又名外膜蛋白酶vii,属于丝氨酸蛋白酶;ftsh是atp依赖性锌金属蛋白酶,属于金属蛋白酶。与上述调控gfp的方式相同,本实验仍然采用srnas来抑制蛋白酶基因的表达,以degq和degs为例,如图3a所示。其中,sdegq和sdegs均采用pr启动子表达;sdegq和sdegs分别含有degq和degs基因mrna翻译起始区域互补的核苷酸序列,其余结构与sgfp相同。如图3b、表4所示为蛋白酶对大肠杆菌表达igg抗体的elisa结果,其中wt代表空白对照组。elisa结果证实蛋白酶对igg的表达有影响。当degs基因或degq基因被抑制时,igg产量有所提高。然而,当抑制其他五种蛋白酶基因时,对igg表达并没有积极影响。结果表明degs和degq对igg具有降解作用。可能的原因是单克隆抗体片段、degs和degq均分泌到周质空间中,导致degs和degq可以降解片段,进而影响igg抗体的表达。因此,蛋白酶对蛋白质的降解不仅取决于它们的类型,还和它们在大肠杆菌中的位置有关。igg抗体分泌到周质空间,degq和degs也是分泌到周质空间;degq和degs蛋白酶与igg抗体均分泌到周质空间这个位置,因此认为蛋白酶对蛋白质的降解与位置有关,即当蛋白酶所处位置(胞质或细胞膜或周质空间等)与目标蛋白质分泌的位置相同时,蛋白酶可能会降解目标蛋白质。表4od450均值标准偏差wt0.2430.012degs0.2860.015degq0.290.013rpoh0.2050.022lon0.150.01degp0.2020.008ompt0.2090.009ftsh0.1670.006生物学统计结果见图4、图5。其中,degs与野生型数据相比,p=0.018<0.05;degq与野生型数据相比,p=0.010<0.05,表明当degs基因或degq基因被抑制时,igg产量显著提高(p<0.05)。以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。序列表<110>天津大学;扬州奥锐特药业有限公司;扬州联澳生物医药有限公司<120>抑制和/或敲除基因在提高单克隆抗体的表达量中的应用<130>mp1819694<160>26<170>siposequencelisting1.0<210>1<211>24<212>dna<213>人工序列(artificialsequence)<400>1accgactaatgcatactttgtcat24<210>2<211>28<212>dna<213>人工序列(artificialsequence)<400>2ttgcaccgactaatgcatactttgtcat28<210>3<211>28<212>dna<213>人工序列(artificialsequence)<400>3gaaaatgacaaagtatgcattagtcggt28<210>4<211>28<212>dna<213>人工序列(artificialsequence)<400>4ttgcgaaaagttcttctcctttacgcat28<210>5<211>28<212>dna<213>人工序列(artificialsequence)<400>5gaaaatgcgtaaaggagaagaacttttc28<210>6<211>28<212>dna<213>人工序列(artificialsequence)<400>6ttgccagtgctaatgtggtttttttcat28<210>7<211>28<212>dna<213>人工序列(artificialsequence)<400>7gaaaatgaaaaaaaccacattagcactg28<210>8<211>28<212>dna<213>人工序列(artificialsequence)<400>8ttgccaacagctgggtttgttttttcat28<210>9<211>28<212>dna<213>人工序列(artificialsequence)<400>9gaaaatgaaaaaacaaacccagctgttg28<210>10<211>28<212>dna<213>人工序列(artificialsequence)<400>10ttgcggaacgtaagagcttcacaaacat28<210>11<211>28<212>dna<213>人工序列(artificialsequence)<400>11gaaaatgtttgtgaagctcttacgttcc28<210>12<211>28<212>dna<213>人工序列(artificialsequence)<400>12ttgctaaactttgcattttgtcagtcat28<210>13<211>28<212>dna<213>人工序列(artificialsequence)<400>13gaaaatgactgacaaaatgcaaagttta28<210>14<211>25<212>dna<213>人工序列(artificialsequence)<400>14ttgcttcagaacgctcaggattcat25<210>15<211>25<212>dna<213>人工序列(artificialsequence)<400>15gaaaatgaatcctgagcgttctgaa25<210>16<211>25<212>dna<213>人工序列(artificialsequence)<400>16ttgctcccagaagtttcgcccgcat25<210>17<211>25<212>dna<213>人工序列(artificialsequence)<400>17gaaaatgcgggcgaaacttctggga25<210>18<211>28<212>dna<213>人工序列(artificialsequence)<400>18ttgcccagagtattaggtttttcgccat28<210>19<211>28<212>dna<213>人工序列(artificialsequence)<400>19gaaaatggcgaaaaacctaatactctgg28<210>20<211>714<212>dna<213>人工序列(artificialsequence)<400>20atgaaaaagaacatagcgtttcttcttgcatctatgttcgttttttctattgctacaaac60gcgtatgcagacatcctgctgacccagtctccggttatcctgtctgtttctccgggtgaa120cgtgtttctttctcttgccgtgcttctcagtctatcggtaccaacatccactggtaccag180cagcgtaccaacggttctccgcgtctgctgatcaaatacgcttctgaatctatctctggt240atcccgtctcgtttctctggttctggttctggtaccgacttcaccctgtctatcaactct300gttgaatctgaagacatcgctgactactactgccagcagaacaacaactggccgaccacc360ttcggtgctggtaccaaactggaactgaaacgtaccgttgctgctccgtctgttttcatc420ttcccgccgtctgacgaacagctgaaatctggtaccgcttctgttgtttgcctgctgaac480aacttctacccgcgtgaagctaaagttcagtggaaagttgacaacgctctgcagtctggt540aactctcaggaatctgttaccgaacaggactctaaagactctacctactctctgtcttct600accctgaccctgtctaaagctgactacgaaaaacacaaagtttacgcttgcgaagttacc660caccagggtctgtcttctccggttaccaaatctttcaaccgtggtgaatgctaa714<210>21<211>1412<212>dna<213>人工序列(artificialsequence)<400>21atgaaaaagaacatagcgtttcttcttgcatctatgttcgttttttctattgctacaaac60gcgtatgcacaggttcagctgaaacagtctggtccgggtctggttcagccgtctcagtct120ctgtctatcacctgcaccgtttctggtttctctctgaccaactacggtgttcactgggtt180cgtcagtctccgggtaaaggtctggaatggctgggtgttatctggtctggtggtaacacc240gactacaacaccccgttcacctctcgtctgtctatcaacaaagacaactctaaatctcag300gttttcttcaaaatgaactctctgcagtctaacgacaccgctatctactactgcgctcgt360gctctgacctactacgactacgaatttgcttactggggtcagggtactctcgttaccgta420agcgctgcttctaccaaaggtccgtctgttttcccgctggctccgtcttctaaatctacc480tctggtggtaccgctgctctgggttgcctggttaaagactacttcccggaaccggttacc540gtttcttggaactctggtgctctgacctctggtgttcacaccttcccggctgttctgcag600tcttctggtctgtactctctgtcttctgttgttaccgttccgtcttcttctctgggtacc660cagacctacatctgcaacgttaaccacaaaccgtctaacaccaaagttgacaaacgtgtt720gaaccgaaatctgacaaaacccacacctgcccgccgtgcccggctccggaactgctgggt780ggtccgtctgttttcctgttcccgccgaaaccgaaagacaccctgatgatctctcgtacc840ccggaagttacctgcgttgttgttgacgtttctcacgaagacccggaagttaaattcaac900tggtacgttgacggtgttgaagttcacaacgctaaaaccaaaccgcgtgaagaacagtac960aactctacctaccgtgttgtttctgttctgaccgttctgcaccaggactggctgaacggt1020aaagaatacaaatgcaaagtttctaacaaagctctgccggctccgatcgaaaaaaccatc1080tctaaagctaaaggtcagccgagggagccgcaggtatacaccctcccgccgtctcgtgac1140gaactgaccaaaaaccaggtttctctgacctgcctggttaaaggtttctacccgtctgac1200atcgctgttgaatgggaatctaacggtcagccggaaaacaactacaaaaccaccccgccg1260gttctggactctgacggttctttcttcctgtactctaaactgaccgttgacaaatctcgt1320tggcagcagggtaacgttttctcttgctctgttatgcacgaagctctgcacaaccactac1380acccagaaatctctgtctctgtctccgggtaa1412<210>22<211>49<212>dna<213>pr启动子(prpromoter)<400>22taacaccgtgcgtgttgactattttacctctggcggtgataatggttgc49<210>23<211>17<212>dna<213>人工序列(artificialsequence)<400>23agagaccaaaggtctcg17<210>24<211>79<212>dna<213>srna支架序列(srnascaffoldsequence)<400>24tttctgttgggccattgcattgccactgattttccaacatataaaaagacaagcccgaac60agtcgtccgggcttttttt79<210>25<211>134<212>dna<213>转录终止子(transcriptionterminator)<400>25ctcgagccaggcatcaaataaaacgaaaggctcagtcgaaagactgggcctttcgtttta60tctgtttttgtcggtgaacgctctctactagagtcacactggctcaccttcgggtgggcc120tttctgcgtttata134<210>26<211>720<212>dna<213>绿色荧光蛋白(gfp)<400>26atgcgtaaaggagaagaacttttcactggagttgtcccaattcttgttgaattagatggt60gatgttaatgggcacaaattttctgtcagtggagagggtgaaggtgatgcaacatacgga120aaacttacccttaaatttatttgcactactggaaaactacctgttccgtggccaacactt180gtcactactttcggttatggtgttcaatgctttgcgagatacccagatcacatgaaacag240catgactttttcaagagtgccatgcccgaaggttatgtacaggaaagaactatatttttc300aaagatgacgggaactacaagacacgtgctgaagtcaagtttgaaggtgatacccttgtt360aatagaatcgagttaaaaggtattgattttaaagaagatggaaacattcttggacacaaa420ttggaatacaactataactcacacaatgtatacatcatggcagacaaacaaaagaatgga480atcaaagttaacttcaaaattagacacaacattgaagatggaagcgttcaactagcagac540cattatcaacaaaatactccaattggcgatggccctgtccttttaccagacaaccattac600ctgtccacacaatctgccctttcgaaagatcccaacgaaaagagagaccacatggtcctt660cttgagtttgtaacagctgctgggattacacatggcatggatgaactatacaaataataa720当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1