心脑血管疾病药物相关基因分型检测引物组、试剂盒及检测方法与流程
本发明涉及基因工程及分子生物学领域,更具体地说,涉及一种心脑血管疾病药物相关基因分型检测引物组、试剂盒及检测方法。
背景技术:
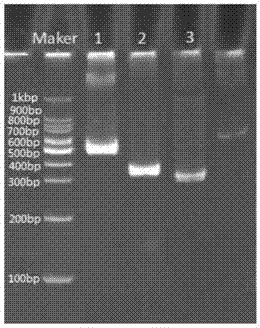
:研究表明,目前广泛使用的心脑血管疾病药物,例如华法林、洛沙坦、氯吡格雷、普拉格雷、替卡格雷、美托洛尔、叶酸等针对不同个体基因类型有不同的治疗效果。cyp4f2*3多态性与华法林稳态剂量相关。cyp4f2*3多态性可导致酶活性降低,维生素k浓度升高,华法林的抗凝效果增强。携带cyp4f2*3等位基因的个体应用华法林时出血的风险显著增加。cpic指南建议降低cyp4f2*3纯合子基因型个体华法林及香豆素类抗凝药(醋硝香豆素、苯丙香豆素)的用药剂量。华法林是深静脉血栓、心房纤颤等疾病的一线用药,血药浓度过高或敏感性增加可导致严重出血事件。cyp2c9*2和cyp2c9*3多态性均导致cyp2c9酶活性降低,使华法林口服清除率下降,因此华法林的给药剂量针对这类个体需相应降低。中国人群中cyp2c9*2的频率为0%,cyp2c9*3的频率为3%。美国fda推荐在使用华法林前进行cyp2c9基因检测。测定cyp2c9*3等位基因可用于指导中国人群确定华法林的起始用药剂量,并预测药物毒性,结合国际标准化比值(inr)检测值,估计华法林的维持剂量,确保用药安全。血管紧张素ⅱ受体拮抗剂是一类高血压治疗药物。在国内主要使用的有洛沙坦,其在体内主要经cyp2c9代谢活化为具有降压作用的代谢产物e-3174。携带cyp2c9*3等位基因的个体服用洛沙坦后e-3174的生成减少,洛沙坦的代谢率降低,导致洛沙坦的降压作用下降,需适当增加用药剂量以增强降压疗效。维生素k氧化还原酶是抗凝药物华法林的作用靶点。vkorc1基因rs9923231多态性可影响vkorc1的表达,是导致华法林用药剂量个体差异的主要原因之一。vkorc1-1639a等位基因个体对华法林的敏感性较高,应降低用药剂量。vkorc1-1639a等位基因在亚洲人群中的等位基因频率为91.17%。美国fda建议结合vkorc1和cyp2c9基因型考虑华法林的初始用药剂量。临床上也可根据考虑了vkorc1和cyp2c9基因型、年龄、身高、体重、种族、是否合用肝药酶诱导剂和是否合用胺碘酮等因素的剂量计算公式确定华法林初始用药剂量。氯吡格雷又名波立维,是一种抗血小板药物,广泛用于急性冠脉综合征、缺血性脑血栓等引起的并发症。氯吡格雷主要经cyp2c19代谢活化后发挥抗血小板效应。cyp2c19遗传变异可导致酶活性的个体差异,使人群出现超快代谢者(um)、快代谢者(em)、中间代谢者(im)和慢代谢者(pm)4种表型。em个体只携带cyp2c19*1等位基因,im个体携带cyp2c19*2或cyp2c19*3杂合子基因型;pm个体包括cyp2c19*2/*2、cyp2c19*2/*3和cyp2c19*3/*3基因型。cyp2c19pm个体应用常规剂量的氯吡格雷后体内活性代谢物生产减少,对血小板的抑制作用下降。美国fda和美国心脏病学会建议cyp2c19*1/*1基因型个体应用氯吡格雷有效,可常规使用;cyp2c19*2或*3基因型个体对氯吡格雷疗效降低,建议更换成普拉格雷或替卡格雷;cyp2c19*2或*3突变型纯合子个体应用氯吡格雷效果差,建议换用普拉格雷或替卡格雷。β受体阻滞剂在临床上主要用于治疗高血压和心绞痛,如美托洛尔具有良好的抗高血压、抗心肌缺血及保护心脏的作用。美托洛尔通过cyp2d6单一途径代谢。中国人群中cyp2d6*10是最常见的导致酶活性降低的等位基因,等位基因频率为53%。cyp2d6*10基因型个体酶活性降低,服用美托洛尔会导致血药浓度增加。推荐临床检测个体cyp2d6基因型以确定美托洛尔的治疗剂量,对于携带有cyp2d6*10的个体,推荐美托洛尔剂量减少20%-50%。硝酸甘油通过aldh2代谢活化为活性成分一氧化氮。aldh2*2多态性导致aldh2酶活性下降,杂合子个体酶活性仅为野生型个体的10%,突变纯合子个体酶活性缺失。因此,携带aldh2*2等位基因的个体代谢硝酸甘油的能力下降,硝酸甘油抗心肌缺血的效应减弱。亚洲人群中aldh2*2等位基因的携带率为30~50%。携带aldh2*2等位基因的心绞痛个体应尽可能改用其他急救药物,避免硝酸甘油含服无效。《h型高血压诊断与治疗专家共识》明确指出,h型高血压就是伴hcy升高(血hcy≥10μmol/l)的高血压。叶酸缺乏和(或)hcy/叶酸代谢途径中关键酶的缺陷或基因突变是导致血hcy水平升高的主要原因。mthfr677tt基因型是冠心病和脑卒中的独立危险因素。他汀类药物通过有机阴离子转运多肽1b1(oatp1b1)在肝细胞被摄取和清除。oatp1b1由slco1b1基因编码,该基因第5号外显子c.521t>c多态性是亚洲人群中的主要遗传变异,等位基因频率为10~15%,该多态性使他汀类药物如普伐他汀、阿托伐他汀和罗素伐他汀等的血药浓度升高,引起严重不良反应。slco1b1基因的另一个多态性c.388a>g与血浆阿托伐他汀浓度偏低有关,且与辛伐他汀相关肌病的发病风险降低有关。为降低他汀类药物严重不良反应的发生风险,建议临床上根据slco1b1基因型调整他汀类药物的剂量,选择合适的他汀类药物进行治疗。abcg2基因c.421c>a多态性导致abcg2转运蛋白对罗素伐他汀的转运活性降低,进而导致他汀类药物的浓度增加,降脂反应增强。为了减少他汀类药物的肌肉毒性,加拿大卫生研究院研究建议临床根据个体的年纪和转运体的基因型(slco1b1基因和abcg2基因)调整他汀类药物的剂量,选择合适的他汀类药物进行治疗。通过对个体的上述基因进行检测,得到特定位点的基因型,以基因检测结果作为中间结果的信息的方法,不属于疾病的诊断方法;以基因型的检测结果来确定药物的选择,就可以实现个体化用药,避免对免疫抑制剂不良反应。目前对基因突变和基因多态性的检测,常见有直接测序法、基因芯片杂交法、taqman荧光探针法、等位基因特异性扩增法(amplificationrefractorymutationsystemrealtimepcr,arms-rtpcr)、等位基因特异性扩增法(amplificationrefractorymutationsystemrealtimepcr,arms-rtpcr)等。上述方法灵敏度低、假阳性率高、耗时较长,通量小。因此,需要一种灵敏度高,假阳性率低,且检测周期短的检测cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点突变的试剂盒及检测方法。技术实现要素:本发明的目的在于提供一种心脑血管疾病药物相关基因分型检测引物组、试剂盒及检测方法,旨在解决现有技术中心脑血管疾病药物相关基因分型检测灵敏度低、假阳性率高、周期长,通量小的技术问题。一种心脑血管疾病药物相关基因分型检测引物组,包括用于对多个心脑血管疾病药物相关基因待测位点中的至少一个进行特异性扩增的引物组,所述多个心脑血管疾病药物相关基因待测位点包括cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点,所述引物组包括rs1799853引物组、rs1057910引物组、rs2108622引物组、rs9923231引物组、rs4244285引物组、rs4986893引物组、rs1065852引物组、rs671引物组、rs1801133引物组、rs4149056引物组、rs2306283引物组和rs2231142引物组中的至少一个,所述rs1799853引物组包括rs1799853上游引物seqidno:1和rs1799853下游引物seqidno:2,所述rs1057910引物组包括rs1057910上游引物seqidno:3和rs1057910下游引物seqidno:4,所述rs2108622引物组包括rs2108622上游引物seqidno:5和rs2108622下游引物seqidno:6,所述rs9923231引物组包括rs9923231上游引物seqidno:7和rs9923231下游引物seqidno:8,所述rs4244285引物组包括rs4244285上游引物seqidno:9和rs4244285下游引物seqidno:10,所述rs4986893引物组包括rs4986893上游引物seqidno:11和rs4986893下游引物seqidno:12,所述rs1065852引物组包括rs1065852上游引物seqidno:13和rs1065852下游引物seqidno:14,所述rs671引物组包括rs671上游引物seqidno:15和rs671下游引物seqidno:16,所述rs1801133引物组包括rs1801133上游引物seqidno:17和rs1801133下游引物seqidno:18,所述rs4149056引物组包括rs4149056上游引物seqidno:19和rs4149056下游引物seqidno:20,所述rs2306283引物组包括rs2306283上游引物seqidno:21和rs2306283下游引物seqidno:22,所述rs2231142引物组包括rs2231142上游引物seqidno:23和rs2231142下游引物seqidno:24。一种心脑血管疾病药物相关基因分型检测试剂盒,包括上述心脑血管疾病药物相关基因分型检测引物组。优选的,所述试剂盒还包括接头,所述接头上含有标签序列,所述接头用于直接与含rs1799853位点、rs1057910位点、rs2108622位点、rs9923231位点、rs4244285位点、rs4986893位点、rs1065852位点、rs671位点、rs1801133位点、rs4149056位点、rs2306283位点、rs2231142位点的扩增产物连接。优选的,所述接头包括第一接头seqidno:25和第二接头seqidno:27。优选的,所述试剂盒还包括库扩增引物组,包括库扩增上游引物seqidno:29和库扩增下游引物seqidno:30。较佳实施例中库扩增上游引物seqidno:29和库扩增下游引物seqidno:30同时作为文库分子的普通扩增和单分子扩增的引物。优选的,所述试剂盒还包括测序引物,所述测序引物用于对含rs1799853位点、rs1057910位点、rs2108622位点、rs9923231位点、rs4244285位点、rs4986893位点、rs1065852位点、rs671位点、rs1801133位点、rs4149056位点、rs2306283位点、rs2231142位点的分子进行测序,所述测序引物包括barcode测序引物seqidno:31、5’测序引物seqidno:32和3’测序引物seqidno:33。一种心脑血管疾病药物相关基因分型检测方法,包括以下步骤:a、利用引物组,分别对含cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点中至少一个位点的样本进行扩增,得扩增产物;所述引物组包括所述引物组包括rs1799853引物组、rs1057910引物组、rs2108622引物组、rs9923231引物组、rs4244285引物组、rs4986893引物组、rs1065852引物组、rs671引物组、rs1801133引物组、rs4149056引物组、rs2306283引物组和rs2231142引物组中的至少一个,所述rs1799853引物组包括rs1799853上游引物seqidno:1和rs1799853下游引物seqidno:2,所述rs1057910引物组包括rs1057910上游引物seqidno:3和rs1057910下游引物seqidno:4,所述rs2108622引物组包括rs2108622上游引物seqidno:5和rs2108622下游引物seqidno:6,所述rs9923231引物组包括rs9923231上游引物seqidno:7和rs9923231下游引物seqidno:8,所述rs4244285引物组包括rs4244285上游引物seqidno:9和rs4244285下游引物seqidno:10,所述rs4986893引物组包括rs4986893上游引物seqidno:11和rs4986893下游引物seqidno:12,所述rs1065852引物组包括rs1065852上游引物seqidno:13和rs1065852下游引物seqidno:14,所述rs671引物组包括rs671上游引物seqidno:15和rs671下游引物seqidno:16,所述rs1801133引物组包括rs1801133上游引物seqidno:17和rs1801133下游引物seqidno:18,所述rs4149056引物组包括rs4149056上游引物seqidno:19和rs4149056下游引物seqidno:20,所述rs2306283引物组包括rs2306283上游引物seqidno:21和rs2306283下游引物seqidno:22,所述rs2231142引物组包括rs2231142上游引物seqidno:23和rs2231142下游引物seqidno:24;b、随机片段化所述扩增产物,获得多个双链核酸片段;c、在双链核酸片段的一端连接具有酶切识别序列的第一接头;d、将双链核酸片段酶切至预设长度获得库片段;e、将第一接头的一端固定在磁珠上提纯库片段;f、在库片段第一接头的另一端连接第二接头,得到文库分子;g、采用第二代高通量基因测序技术对所述文库分子进行测序,确定待测位点的基因型。优选的,步骤g进一步包括使用库扩增上游引物seqidno:29、库扩增下游引物seqidno:30对文库分子进行扩增的步骤。优选的,步骤b之后进一步包括提取多个双链核酸片段中长度为30-200bp的步骤。优选的,步骤b之后进一步包括对多个双链核酸片段进行末端修复的步骤。优选的,步骤g使用测序引物进行连接测序,所述测序引物包括barcode测序引物seqidno:31、5’测序引物seqidno:32和3’测序引物seqidno:33。本发明提供的心脑血管疾病药物相关基因分型检测引物组,能够对含待测位点的片段进行特异性扩增,降低了扩增多个靶位点的复杂性,提高了对待测位点扩增的特异性和灵敏度,降低了假阳性率;同时,采用第二代高通量基因测序技术,建立同一反应体系对心脑血管疾病药物多个相关基因的位点进行分型测试,使得对待测位点的检测周期短,通量高。附图说明图1是本发明第四实施例中部分基因片段扩增的琼脂糖凝胶电泳检测图。图2是本发明第四实施例中酶切获得部分库片段的琼脂糖凝胶电泳检测图。图3是本发明第四实施例部分中文库分子的琼脂糖凝胶电泳检测图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。本发明提出第一实施例,一种心脑血管疾病药物相关基因分型检测引物组,用于对含待测位点的核酸片段进行特异性扩增,所述多个心脑血管疾病药物相关基因待测位点包括cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点,所述引物组包括rs1799853引物组、rs1057910引物组、rs2108622引物组、rs9923231引物组、rs4244285引物组、rs4986893引物组、rs1065852引物组、rs671引物组、rs1801133引物组、rs4149056引物组、rs2306283引物组和rs2231142引物组中的至少一个,其中所述rs1799853引物组包括rs1799853上游引物seqidno:1和rs1799853下游引物seqidno:2,所述rs1057910引物组包括rs1057910上游引物seqidno:3和rs1057910下游引物seqidno:4,所述rs2108622引物组包括rs2108622上游引物seqidno:5和rs2108622下游引物seqidno:6,所述rs9923231引物组包括rs9923231上游引物seqidno:7和rs9923231下游引物seqidno:8,所述rs4244285引物组包括rs4244285上游引物seqidno:9和rs4244285下游引物seqidno:10,所述rs4986893引物组包括rs4986893上游引物seqidno:11和rs4986893下游引物seqidno:12,所述rs1065852引物组包括rs1065852上游引物seqidno:13和rs1065852下游引物seqidno:14,所述rs671引物组包括rs671上游引物seqidno:15和rs671下游引物seqidno:16,所述rs1801133引物组包括rs1801133上游引物seqidno:17和rs1801133下游引物seqidno:18,所述rs4149056引物组包括rs4149056上游引物seqidno:19和rs4149056下游引物seqidno:20,所述rs2306283引物组包括rs2306283上游引物seqidno:21和rs2306283下游引物seqidno:22,所述rs2231142引物组包括rs2231142上游引物seqidno:23和rs2231142下游引物seqidno:24。本方案提供的心脑血管疾病药物相关基因分型检测引物组,能够特异性扩增含cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点,所述引物组包括rs1799853引物组、rs1057910引物组、rs2108622引物组、rs9923231引物组、rs4244285引物组、rs4986893引物组、rs1065852引物组、rs671引物组、rs1801133引物组、rs4149056引物组、rs2306283引物组和rs2231142引物组中的一个或多个,扩增产物可以用于进行心脑血管疾病药物相关基因分型检测,可以系统方便的同时进行多种相关基因分型检测。本发明提出第二实施例,一种心脑血管疾病药物相关基因分型检测试剂盒,含有上述第一实施例的心脑血管疾病药物相关基因分型检测引物组。优选的,所述试剂盒还包括对上述引物组扩增后的产物进行随机片段化的片段化酶。本实施例中,片段化酶将扩增产物随机片段化为200-50kbp,获得多个双链核酸片段。优选的,所述试剂盒还包括第一接头seqidno:25、所述第一接头seqidno:25用于直接与多个双链核酸片段的一端连接,所述第一接头seqidno:25上含有标签序列,标签序列为nnnn,其中n为a、g、c或t。优选的,所述第一接头还包含与测序引物序列互补的序列、扩增引物的序列以及酶切识别序列ctgaag。替代实施例中,第一接头seqidno:25还可以为seqidno:26。优选的,所述试剂盒还包括acui酶,用于将连接第一接头的。由于所述第一接头seqidno:25包含ctgaag序列,采用acui酶对扩增产物进行切割,可将多个双链核酸片段切割为13bp的库片段,并形成粘性末端,该粘性末端在后续连接接头的过程中连接效率更高。优选的,所述第一接头seqidno:25上含有生物素标记,用于使其固定在含亲和素的磁珠上,利用该生物素标记,可以在连接反应结束后,很方便的将酶切为13bp的库片段分离出来。优选的,所述试剂盒还包括第二接头seqidno:27,所述第二接头seqidno:27用于连接库片段连接第一接头seqidno:25的另一端,以获得文库分子。替代实施例中,第二接头seqidno:27还可以为seqidno:28。优选的,所述试剂盒还包括对文库分子进行单分子扩增的库扩增上游引物seqidno:29、库扩增下游引物seqidno:30。优选的,所述试剂盒还包括荧光标记的寡聚核苷酸探针和无荧光标记的寡聚核苷酸探针。优选的,所述试剂盒还包括测序引物,所述测序引物包括对文库分子进行测序的barcode测序引物seqidno:31、5’测序引物seqidno:32和3’测序引物seqidno:33。优选的,本方案的测序引物适用于采用连接测序法对待测位点进行检测,本方案使得测序探针可连接在测序引物的5’末端。优选的,所述试剂盒还包括连接酶。在连接酶的作用下,所述扩增产物和第一接头seqidno:25之间以及库片段和第二接头seqidno:27之间能够稳定的连接。优选的,所述试剂盒还包括连接缓冲液。本发明提供的试剂盒,对心脑血管疾病药物相关多个基因的多个位点分别构建随机短标签文库分子,通过对文库分子进行二代测序后和标准序列匹配识别待测位点的基因类型,本发明的分型测序方法避免了扩增出现异常导致基因分型不准确的问题,充分利用了二代高通量连接测序法的优势,不同位点和不同标本建立相同的反应体系制作文库分子后统一进行测序,不仅效率高而且成本低。当采用本发明的试剂盒对在同一体系中对不同样本的同一待测位点进行检测时,由于在测序过程中使用的测序引物是相同的,因此需要采用含不同标签序列的接头分别连接不同的样本,通过对标签序列进行测序,从而无需对样本进行多次测序即可有效区分不同样本的测序结果。本发明提出第三实施例,一种心脑血管疾病药物相关基因分型检测方法,包括以下步骤:a、利用引物组,分别对含cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点中至少一个位点的样本进行扩增,得扩增产物;所述引物组包括rs1799853引物组、rs1057910引物组、rs2108622引物组、rs9923231引物组、rs4244285引物组、rs4986893引物组、rs1065852引物组、rs671引物组、rs1801133引物组、rs4149056引物组、rs2306283引物组和rs2231142引物组中的至少一个,所述rs1799853引物组包括rs1799853上游引物seqidno:1和rs1799853下游引物seqidno:2,所述rs1057910引物组包括rs1057910上游引物seqidno:3和rs1057910下游引物seqidno:4,所述rs2108622引物组包括rs2108622上游引物seqidno:5和rs2108622下游引物seqidno:6,所述rs9923231引物组包括rs9923231上游引物seqidno:7和rs9923231下游引物seqidno:8,所述rs4244285引物组包括rs4244285上游引物seqidno:9和rs4244285下游引物seqidno:10,所述rs4986893引物组包括rs4986893上游引物seqidno:11和rs4986893下游引物seqidno:12,所述rs1065852引物组包括rs1065852上游引物seqidno:13和rs1065852下游引物seqidno:14,所述rs671引物组包括rs671上游引物seqidno:15和rs671下游引物seqidno:16,所述rs1801133引物组包括rs1801133上游引物seqidno:17和rs1801133下游引物seqidno:18,所述rs4149056引物组包括rs4149056上游引物seqidno:19和rs4149056下游引物seqidno:20,所述rs2306283引物组包括rs2306283上游引物seqidno:21和rs2306283下游引物seqidno:22,所述rs2231142引物组包括rs2231142上游引物seqidno:23和rs2231142下游引物seqidno:24;b、随机片段化所述扩增产物,获得多个双链核酸片段;c、在双链核酸片段的一端连接具有酶切识别序列的第一接头;d、将双链核酸片段酶切至预设长度获得库片段;e、将第一接头的一端固定在磁珠上提纯库片段;f、在库片段连接第一接头的另一端连接第二接头,得到文库分子;g、采用第二代高通量基因测序技术对所述文库分子进行测序,确定待测位点的基因型。优选的,步骤b之后进一步包括提取多个双链核酸片段中长度为30-200bp的步骤。优选的,步骤b之后进一步包括对多个双链核酸片段进行末端修复的步骤。优选的,所述步骤g包括以下步骤:g1、利用无荧光标记的寡核苷酸探针,对文库分子进行一次连接测序;g2、利用荧光探针对文库分子进行连接测序,确定待测位点的基因型。需要说明的是,所述无荧光标记的寡核苷酸探针与连接测序技术中所使用的荧光探针相比,序列完全相同,区别仅在于无荧光标记。本方案的检测方法,在测序过程中加入无荧光标记的寡核苷酸探针,能够有效减少连接测序中出现的错误信号,提高了对待测位点检测的准确性。每一次连接测序均包括以下步骤:测序引物锚定,冲洗(除去多余的未锚定的测序引物),连接探针,冲洗(除去多余探针,连接酶等),采图(获得探针上荧光标记所对应位置的序列信息),变性洗脱连接产物(以便下一次连接测序反应中测序引物的锚定)。步骤e1中的连接测序反应,使用无荧光标记的寡核苷酸探针,可以不进行采图步骤,以减少实验步骤,提高实验效率。本方案设计的测序引物,在测序过程中连接第一接头与测序引物序列互补的序列,使得在测序过程中,仅需较少次数的测序即可确定待测位点的基因型。优选的,本方案的测序引物尤其适用于采用连接测序法,在测序过程中,测序探针连接在该测序引物5’末端。相对于现有技术,本实施例的心脑血管疾病药物相关基因分型检测方法同时对心脑血管疾病药物相关多个基因的多个位点分别构建随机短标签文库分子,通过对文库分子进行二代测序后和标准序列匹配识别多个待测位点的基因类型,本发明的分型检测方法避免了扩增出现异常导致基因分型不准确的问题,充分利用了二代高通量连接测序法的优势,不同位点和不同标本分别制作文库分子后统一进行测序,不仅效率高而且成本低。由于文库分子需要测序的碱基数量不多,因此测序的时间和效率都明显提高。当采用本发明的试剂盒在同一体系中对相同样本的多个待测位点进行检测时,可以使用相同的标签序列的接头以及相同的测序引物,使得测序方法较为简单。当在同一体系中有不同样本时,采用含不同标签序列的接头分别连接不同的样本,通过对标签序列进行测序,从而无需对样本进行多次测序即可有效区分不同样本的测序结果。本发明提供了第四实施例,一种心脑血管疾病药物相关基因分型检测方法,以两人的血液基因组dna为模板,分别检测各模板cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点。具体包括步骤a-g。步骤a、针对上述两个样本,配制两个反应体系,采用第一实施例的引物组分别对不同样本的cyp2c9基因rs1799853位点、cyp2c9基因rs1057910位点、cyp4f2基因rs2108622位点、vkorc1基因rs9923231位点、cyp2c19基因rs4244285位点、cyp2c19基因rs4986893位点、cyp2d6基因rs1065852位点、aldh2基因rs671位点、mthfr基因rs1801133位点、slco1b1基因rs4149056位点、slco1b1基因rs2306283位点、abcg2基因rs2231142位点的基因片段进行扩增。1)反应体系如下:pcrcomponents实际加样体积(μl)hottaqmix25dnatemplate0.3引物组上游引物(10μm)1引物组下游引物(10μm)1dnso0.8ddh2021.9totalvolume50ul2)设置反应程序:95℃条件下持续15分钟;95℃条件下持续30秒,58℃条件下持续30秒,72℃条件下持续30秒,一共35个循环;72℃条件下持续5分钟;10℃条件下保持,扩增反应完成后,得到扩增产物。如图1所示,1-3泳道分别为含rs9923231位点的vkorc1基因片段扩增结果、含rs2231142位点的abcg2基因片段扩增结果含rs2306283位点的slco1b1基因片段扩增结果,分别在571bp、345bp、263bp出现目标条带,扩增产物符合要求。步骤b、随机片段化所述扩增产物,获得多个双链核酸片段;一实施方式中,具体实验步骤如下:1)在冰盒上向0.2ml离心管中加入以下体系:组分体积步骤a扩增产物(dna,1-5μg)1-16μl10×fragmentbuffer2μlfragmentenzyme2μlddh2o适量总体积20μl2)涡旋振荡混匀,短暂离心后,37℃孵育40min,加入5µlterminator终止酶反应;取1.5mlep管,将反应液转移至1.5mlep管中,加入1μl糖原,100μl醋酸铵,750μl冻存无水乙醇,混匀,-80℃放置60min或过夜;3)14000rpm4℃离心15min;4)弃上清,加入200μl75%乙醇,4℃14000rpm离心5min;5)重复步骤3)一次;6)弃乙醇,短暂离心,用移液器小心吸取残留乙醇,避免吸到沉淀,将ep管室温晾干(5-10min);7)加入30μl预热的ddh2o,室温静置5min,直至沉淀溶解;8)nanodrop测浓度,4℃短暂保存或-20℃冻存。优选的,步骤b之后进一步包括提取多个双链核酸片段中长度为30-200bp的步骤。优选的,步骤b之后进一步包括对多个双链核酸片段进行末端修复的步骤,具体实验步骤如下:1)向0.2ml离心管中加入:组分体积dna(步骤b产物≥400ng)10-15μlendingrepairbuffer5μlendingrepairenzyme2μlddh2oupto25μl总体积25μl2)涡旋混匀,短暂离心后在pcr仪中运行以下程序,并设置105℃热盖。20℃加热20分钟;72℃加热10分钟;保存温度4℃。步骤c、在双链核酸片段的一端连接具有酶切识别序列的第一接头;一实施例中具体实验如下:1)末端修复完成后加入0.5µl10ng/µl第一接头和1.5µlligationenzyme,用枪吸打混合均匀;2)在pcr仪上运行20℃,10min;72℃,10min;hold4℃,并设置105℃热盖;3)将核酸纯化磁珠涡旋混匀,取45μl磁珠加至连接第一接头后的产物中,用枪吹打混匀后室温静置5min;4)磁铁吸附,待磁珠吸附到管壁的一边,且溶液澄清后,小心吸取上清并丢弃,注意不要吸到磁珠;5)加入200µl70%无水乙醇用枪吹打混匀,磁铁吸附,待磁珠吸附到管壁的一边,且溶液澄清后,小心吸取上清并丢弃,注意不要吸到磁珠;6)重复步骤4)两次。将离心管稍加离心使残留液体集于管底,用10µl枪头吸尽残留液体并丢弃;7)敞开管盖静置5min挥发多余无水乙醇;8)加入20µlddh2o,用枪头吹打混匀,室温静置3~5min。磁铁吸附,吸取上清液体至新的0.2ml离心管中,注意不要吸到磁珠。样品可存储于4℃,如当天不用存储于-20℃保存。步骤d、将双链核酸片段酶切至预设长度获得库片段;一实施例中,具体实验如下:1)向0.2ml离心管中加入:组分体积dna(步骤c产物)15μlcuttingbuffera2.5μlcuttingbufferb(需稀释)7μlcuttingenzyme0.5μl总体积25μl2)涡旋振荡混匀,短暂离心后,37℃孵育15min,加入1.0µlterminator终止反应。如图2所示,1-3泳道分别为含rs9923231位点的vkorc1基因片段、含rs2231142位点的abcg2基因片段、以及含rs2306283位点的slco1b1基因片段酶切后的电泳结果;4-6泳道分别为含rs9923231位点的vkorc1基因片段、含rs2231142位点的abcg2基因片段、以及含rs2306283位点的slco1b1基因片段酶切前的电泳结果,分别在571bp、263bp、345bp出现目标条带,酶切产物符合要求。步骤e、将第一接头的一端固定在磁珠上提纯库片段,一实施例中,具体实验如下:1)将结合磁珠涡旋振荡混匀,转移2µl磁珠于0.2ml离心管中,加入10µlsolutionbuffer混匀,磁铁吸附,待磁珠吸附到管壁的一边,且溶液澄清后,小心吸取上清并丢弃,注意不要吸到磁珠;2)取25µl2×bwbuffer以及25µl酶切产物(步骤d)加入上述0.2ml离心管中涡旋振荡混匀,短暂离心后,30℃孵育15min;3)磁铁吸附,待磁珠吸附到管壁的一边,且溶液澄清后,小心吸取上清并丢弃,注意不要吸到磁珠;4)加入100µlsolutionbuffer用枪吹打混匀,磁铁吸附,待磁珠吸附到管壁的一边,且溶液澄清后,小心吸取上清并丢弃,注意不要吸到磁珠;5)按照上一步骤用100µlsolutionbuffer重复洗涤3次(共4次);6)加入10µlsolutionbuffer重悬。步骤f、在库片段连接第一接头的另一端连接第二接头,形成文库分子。一实施例中,具体实验如下:1)在步骤e产物中分别加入:组分体积ddh2o32μlligationbuffer5μladapterr(10ng/µl)1μlligationenzyme1μl总体积50μl2)涡旋振荡混匀,短暂离心后,16℃孵育5min,加入2µlterminator终止反应,磁铁吸附,待磁珠吸附到管壁的一边,且溶液澄清后,小心吸取上清并丢弃,注意不要吸到磁珠;3)加入100µlsolutionbuffer用枪吹打混匀,磁铁吸附,待磁珠吸附到管壁的一边,且溶液澄清后,小心吸取上清并丢弃,注意不要吸到磁珠;4)按照上一步骤用100µlsolutionbuffer重复洗涤3次(共4次);5)加入20µlsolutionbuffer重悬。本实施例中,文库分子扩增与验证的实验步骤如下:1)按下表体系配制5管pcr反应液:组分体积dna(步骤6产物)2μlprimer1(10μm)1μlprimer2(10μm)1μlpcrpremix12.5μlddh2o8.5μl总体积25μl2)涡旋振荡混匀。短暂离心后,在pcr仪上运行94℃,2min;(94℃,10s;60℃,10s)循环20次;72℃,2min;保持10℃,并设置105℃热盖;3)磁铁吸附磁珠,将液体转移至新的1.5ml离心管中,加入300µlbindingbuffer和400µl异丙醇涡旋振荡混匀,短暂离心后,加入到核酸纯化柱中,8000rpm离心1min,倒掉收集管内液体;4)加入700µlwashingbuffer,8000rpm离心1min,倒掉收集管内液体;5)重复步骤3)一次;6)倒掉收集管内液体,13000rpm离心2min;离心柱敞口转移至新的1.5ml离心管中,静置3min,让酒精充分挥发;7)向柱膜中央加入30µlsolutionbuffer,静置2min,12000rpm离心2min,收集离心管内液体,qubit测定浓度;8)取5µl回收产物,12%page胶,180v电泳40min检测或取5µl回收产物,再加入5µlddh2o,用qsep100检测。验证结果:文库电泳检测目的条带单一(文库片段大小为113bp),允许10%的接头直连带(约100bp)存在。参阅图3,1-3泳道分别为vkorc1基因片段文库分子、abcg2基因片段文库分子、以及slco1b1基因片段文库分子的电泳结果,分别出现了3条113bp的目标条带,与理论预期文库分子大小完全相符,说明本发明的方法可以实现对待测序样本的建库。步骤e、采用第二代高通量基因测序技术对所述文库分子进行测序,确定待测位点的基因型。较佳实施例中,采用连接测序对所述文库分子进行测序,包括以下步骤:1)同一反应体系对文库分子进行普通扩增;2)同一反应体系对文库分子进行单分子扩增;3)测序引物锚定,冲洗(除去多余的未锚定的测序引物);4)连接探针,冲洗(除去多余探针,连接酶等);5)采图(获得探针上荧光标记所对应位置的序列信息),变性洗脱连接产物(以便下一次连接测序反应中测序引物的锚定)。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。序列表<110>武汉康昕瑞基因健康科技有限公司<120>心脑血管疾病药物相关基因分型检测引物组、试剂盒及检测方法<160>33<170>siposequencelisting1.0<210>1<211>22<212>dna<213>人工序列(artificialsequence)<400>1gaatcaggcttagcaaatggac22<210>2<211>20<212>dna<213>人工序列(artificialsequence)<400>2gctctcagcttcaaaccccc20<210>3<211>22<212>dna<213>人工序列(artificialsequence)<400>3gctggtttatggcagttacaca22<210>4<211>23<212>dna<213>人工序列(artificialsequence)<400>4ggcttaccttgggaatgagatag23<210>5<211>22<212>dna<213>人工序列(artificialsequence)<400>5gaccaacccaaccgtactctat22<210>6<211>19<212>dna<213>人工序列(artificialsequence)<400>6gagtgctcacagcctcacg19<210>7<211>23<212>dna<213>人工序列(artificialsequence)<400>7tctacttcctcacttcttccttg23<210>8<211>23<212>dna<213>人工序列(artificialsequence)<400>8gatgctgtttctcacatctactc23<210>9<211>22<212>dna<213>人工序列(artificialsequence)<400>9caaaagcaggtataagtctagg22<210>10<211>22<212>dna<213>人工序列(artificialsequence)<400>10ggagtaatgcttgagaagcata22<210>11<211>21<212>dna<213>人工序列(artificialsequence)<400>11tggcaatcatttagcttcacc21<210>12<211>21<212>dna<213>人工序列(artificialsequence)<400>12ggagggctttggagtttagtg21<210>13<211>23<212>dna<213>人工序列(artificialsequence)<400>13cccatttggtagtgaggcaggta23<210>14<211>22<212>dna<213>人工序列(artificialsequence)<400>14aaagtcccttctgctgacacca22<210>15<211>21<212>dna<213>人工序列(artificialsequence)<400>15taacccataacccccaagagt21<210>16<211>24<212>dna<213>人工序列(artificialsequence)<400>16agaagtgacaagagagggtaaaga24<210>17<211>18<212>dna<213>人工序列(artificialsequence)<400>17tggaaggtgcaagatcag18<210>18<211>18<212>dna<213>人工序列(artificialsequence)<400>18gtccagaacttgcacagc18<210>19<211>18<212>dna<213>人工序列(artificialsequence)<400>19tccattagacccttttcc18<210>20<211>18<212>dna<213>人工序列(artificialsequence)<400>20gtggaataggggagactc18<210>21<211>20<212>dna<213>人工序列(artificialsequence)<400>21aacctgtgttgttaatgggc20<210>22<211>20<212>dna<213>人工序列(artificialsequence)<400>22cccagcatgtgttttaagag20<210>23<211>20<212>dna<213>人工序列(artificialsequence)<400>23tgcattctatttgggtgtac20<210>24<211>20<212>dna<213>人工序列(artificialsequence)<400>24gattaacagggtcattcaag20<210>25<211>50<212>dna<213>人工序列(artificialsequence)<400>25cctacttgcagttgctattaccnnnncacctaactgctgaagtagtcggt50<210>26<211>46<212>dna<213>人工序列(artificialsequence)<400>26ccgactacttcagcagttaggtgnnnnggtaatagcaactgcaagt46<210>27<211>53<212>dna<213>人工序列(artificialsequence)<400>27atcatatgaggaaccccaggcaggcagcacgagctgtccatcgatcctggaga53<210>28<211>55<212>dna<213>人工序列(artificialsequence)<400>28tctccaggatcgatggacagctcgtgctgcctgcctggggttcctcatatgatnn55<210>29<211>22<212>dna<213>人工序列(artificialsequence)<400>29cctacttgcagttgctattacc22<210>30<211>24<212>dna<213>人工序列(artificialsequence)<400>30tctccaggatcgatggacagctcg24<210>31<211>19<212>dna<213>人工序列(artificialsequence)<400>31ggtaatagcaactgcaagt19<210>32<211>20<212>dna<213>人工序列(artificialsequence)<400>32accgactacttcagcagtta20<210>33<211>20<212>dna<213>人工序列(artificialsequence)<400>33ggaccccaaggagtatacta20当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1